目录
1.网络层
2.数据链路层
1.网络层
我们知道,我们的消息为了从A端发送到B端,达成远距离传输,我们为此设计了很多协议层,分别是应用层,传输层,网络层,数据链路层,网卡,传输层确保我们数据的可靠性与安全送达,而我们对网络层的定位是:IP提供个一种把数据从A端送到B端的能力。
如果说TCP能够保证我们数据的可靠性,那么我们的IP就能够让我们的数据在不同的主机间进行传输。
一个形象的比喻是,假如张三是一个学霸,它的数学特别好,有能力考到150分,这个有能力的意思是有很大概率考到150分,并不能确保一定能考到150分,那张三学校的教导主任为了让张三的成绩每次都是150分,它的做法是假如张三这次考试没有考到150分,那么我就让全校重考,知道张三数学考到150分。张三有考150分的能力,加上教导主任的助力,实现了张三每次的成绩都是150分,那么我们的TCP/IP也是类似的,IP提供了一种把数据从A端传输到B端的能力,但是不能保证传输的过程不丢包,那么万一我们的IP丢包了,我们的TCP就要保证数据的可靠性,进行重传,具体的实现不就是没有收到应答,就有超时重传和快重传的机制吗?
IP是是什么?
IP=网络地址+主机地址
我们路由的本质就是实现不同子网间的信息传递!
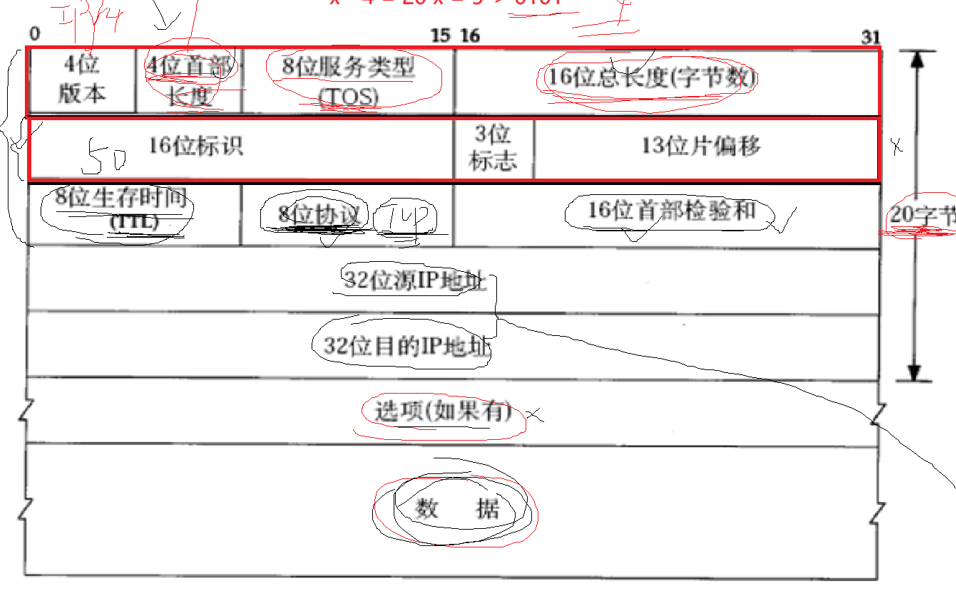
要认识IP,就得认识他的报头,我们讲解TCP的时候说过,一个协议要解决的2个问题就是,如何把报头和有效载荷进行分离,如何向上交付的问题,也就是如何分用。
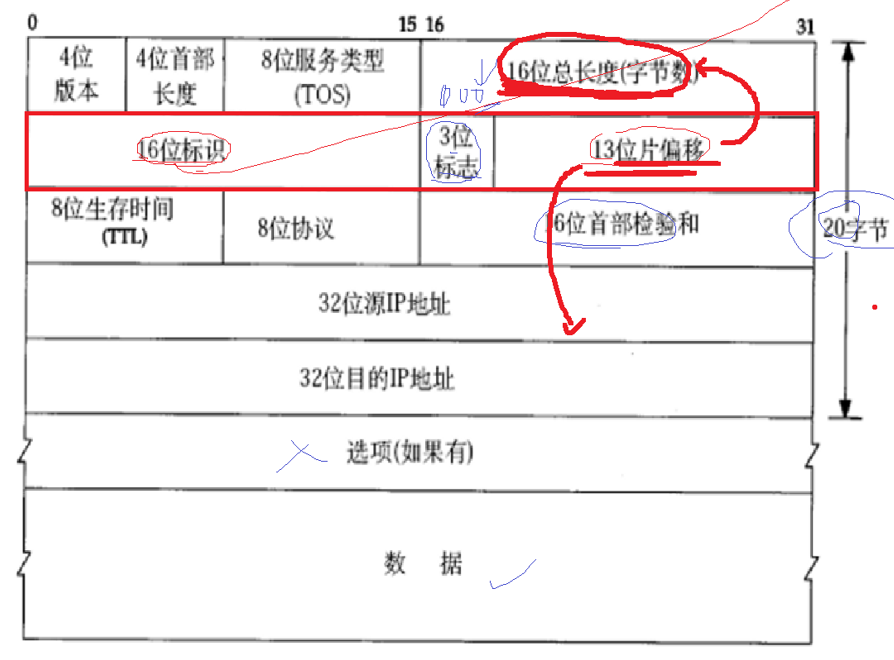
看着下面的IP报头,我们来解读一下,首先16位字节总长度是我们报文的总长度,由于IP的报头长度是固定的,那么我们知道16位总长度,那么我们就可以知道了报头和有效载荷的分界线,我们读到一个完整的IP报头就可以对报头和有效载荷进行分离了。
这是没有选项的情况,如果有选项,我们就需要看一下四位首部长度,那么减去的就是4位首部长度,因为4位首部长度里面是报头+选项的总长度。
第二个问题,如何向上交付,8位协议里面有上层协议的类型。
那么我们IP报文在传输的过程中,由于网络拓补结构的复杂,可能会出现环路问题,会出现永生报文,我们不允许这种情况的出现,所以我们报头有一个参数是8位生存时间,每进行一次路由器传输,它的数字--,减到0的时候这个报文就被丢弃掉。
IP是远距离传输的过程还会出现信号减弱,所以我们有集线器,每经过一次集线器,它的信号就被放大了,确保了我们远距离传输。
下面来说我们的32位IP地址,和我们的学号一样,学号是经过精心设计的,拿这你的学号就可以知道你是哪个专业,哪个院,哪个班,,就可以找到你这个人,身份证不也是一样吗?你的身份证里有你的地区,有你的出生日期,也是被精心设计的呀,一个身份证对应的就是一个人,我们的IP也是类似的,IP=网络号+主机号。
我们同一个子网内我们IP的网络号是相同的,如果我想要进行查找,我本质就是进行IP的淘汰,比如我的目的IP是1.0,同时有2.0,3.0,4.0等多个子网,我们一下就会淘汰掉许多IP,提高了我们的效率,如果我们不这样设计一个一个去找,就是线性查找,效率非常的低下,我们的红黑树为什么高效,不就是它查找一次淘汰一般的数据吗?
因为线性查找低效,所以我们要提高效率,为了提高效率,我们精心设计了IP,所以同学们,我们发现不仅仅是计算机是这样,我们的身份证等等不都是这样吗?
了解完了IP的报头我们还需要进一步了解我们的IPV4,你不是说我的IPV4有32个比特位吗?它不就是2的32次方吗?既然IP是唯一的,那我现在的设备超过了这个2的32次方,我不就无法进行标识唯一性了吗?你给我解释一下。
起初,我们的IP划分的时候没有想到互联网会像现在这么普及到千家万户,所以它开始设计的就比较少,而且划分的时候比较糙。
你看假如我把一个网络号划给一个子网,它的子网内就不可能有2的24次方台主机,这样的划分造成了大量的IP浪费,为了减少浪费,我们引入了子网掩码,就是IP地址与子网掩码按位与之后有几个1,就有几位是网络号!

子网掩码的本质就是:提高我们的IP利用效率!我们的IP设计没有一处是多余的,都是经过精心的设计的,20个字节的报头就能表示这么多东西,实在是厉害。
下面的IP地址与我们的子网掩码按位与之后就是我们的网络号。28位表示网络号,4位表示网络号。
其中我们的主机地址全0表示网络地址,全F表示广播。所以我们实际表示的主机数还要减去2!

说完了IP的这些之后,我想问你有没有发现我们的家庭网络的IP都是192.多少多少,而且不同的网络之间IP是可以进行重复的,怎么回事,你不是说IP不可以重复吗?但是我看到的明明可以重复呀!
其实我们除了我们的公网IP之后,还有我们的私网IP,它们只能用来构建子网,不能出现在公网。

那谁来帮助我们组件子网,家庭路由器帮助我们对子网进行组件,所以路由器不仅有组件网络的功能,也有路由的功能。
我们平时接触的IP都是子网IP,都不是公网IP。
为了解释这种现象,我们可以这么理解,我们家庭路由器都是只有私网IP,我们的运营商的路由器有一个私有IP有一个公网IP,我们的路由器把消息转发给运营商的路由器,由它帮助我们进行公网的转发,所以我们发的消息都会经过运营商的检测,你一旦访问一些不科学的网站,就会把你的访问请求报文直接丢弃掉,所以想要科学上网,就需要PIAN过运营商。
这样的设计让我们私网IP之间可以进行重复,大大减少了IP不足的压力。
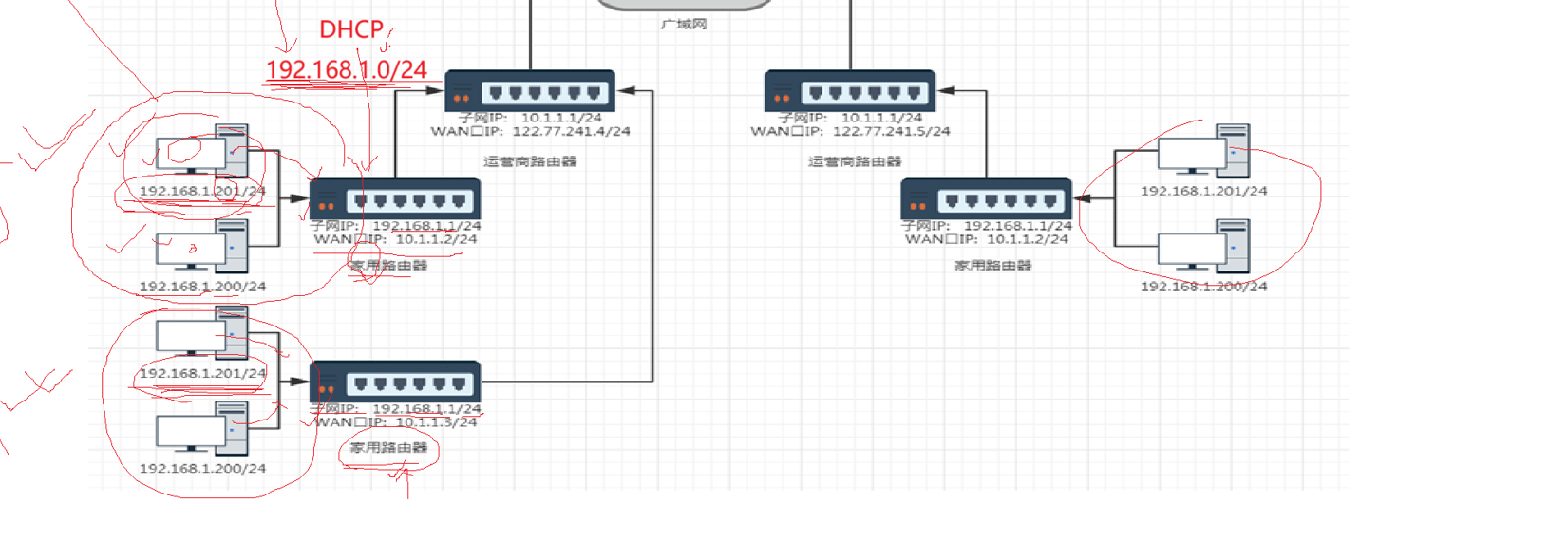
家用路由器的本质就是由运营商搭建的一个子网,我们国家的基础设施就是联通移动电信来搭建的,光纤入户就是让我们用户接入网络,这样就有需求产生,有需求就会有市场,这样经济就发展起来了。
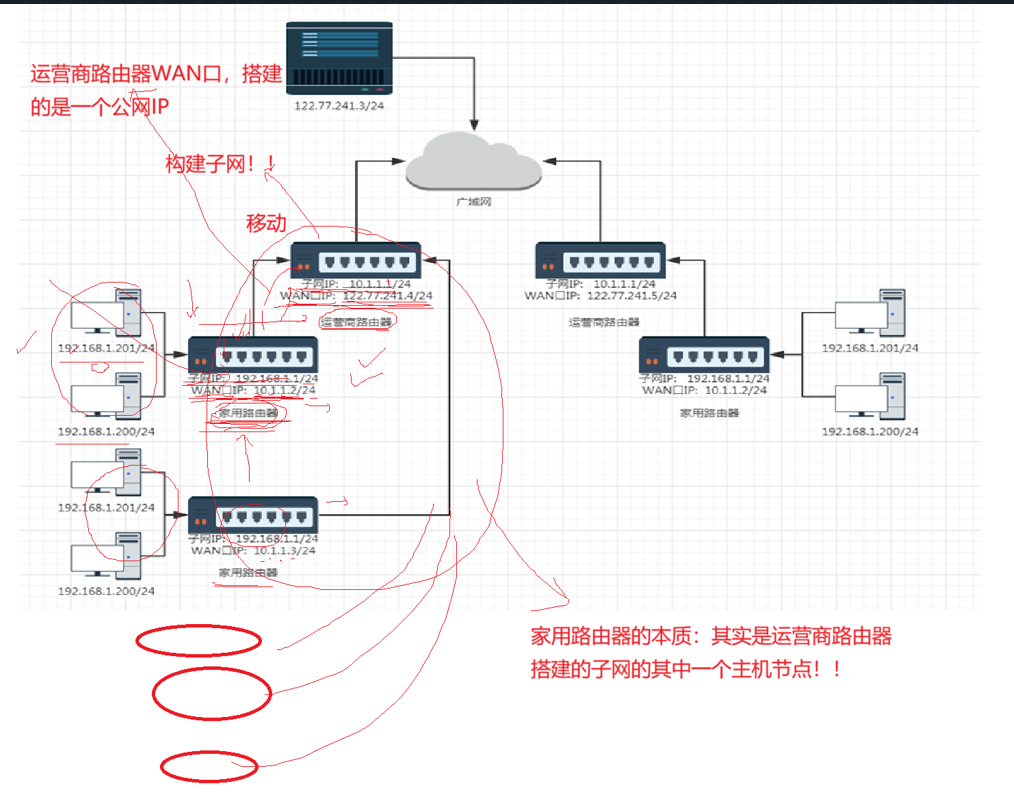
所以我们想进行短视频的请求,就是进行转发,从一个子网到另一个子网,但是我们的公网不存在私人IP,所以这样的转发是不正确的。我们需要对我们的IP进行替换。
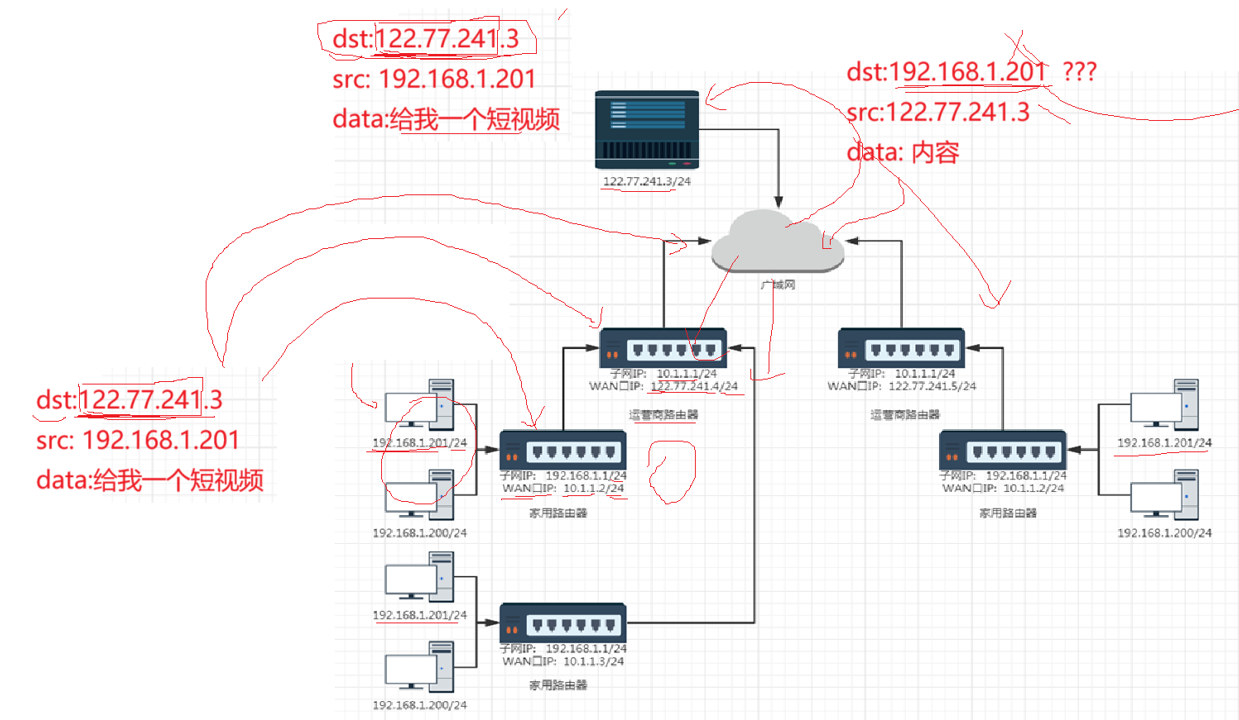
下面的图才是正确的转发过程,源IP不断被转换,知道发到公网,然后回来的时候还发到我们的运营商路由器会进行查表,返回到我们的私人IP。具体的过程还得
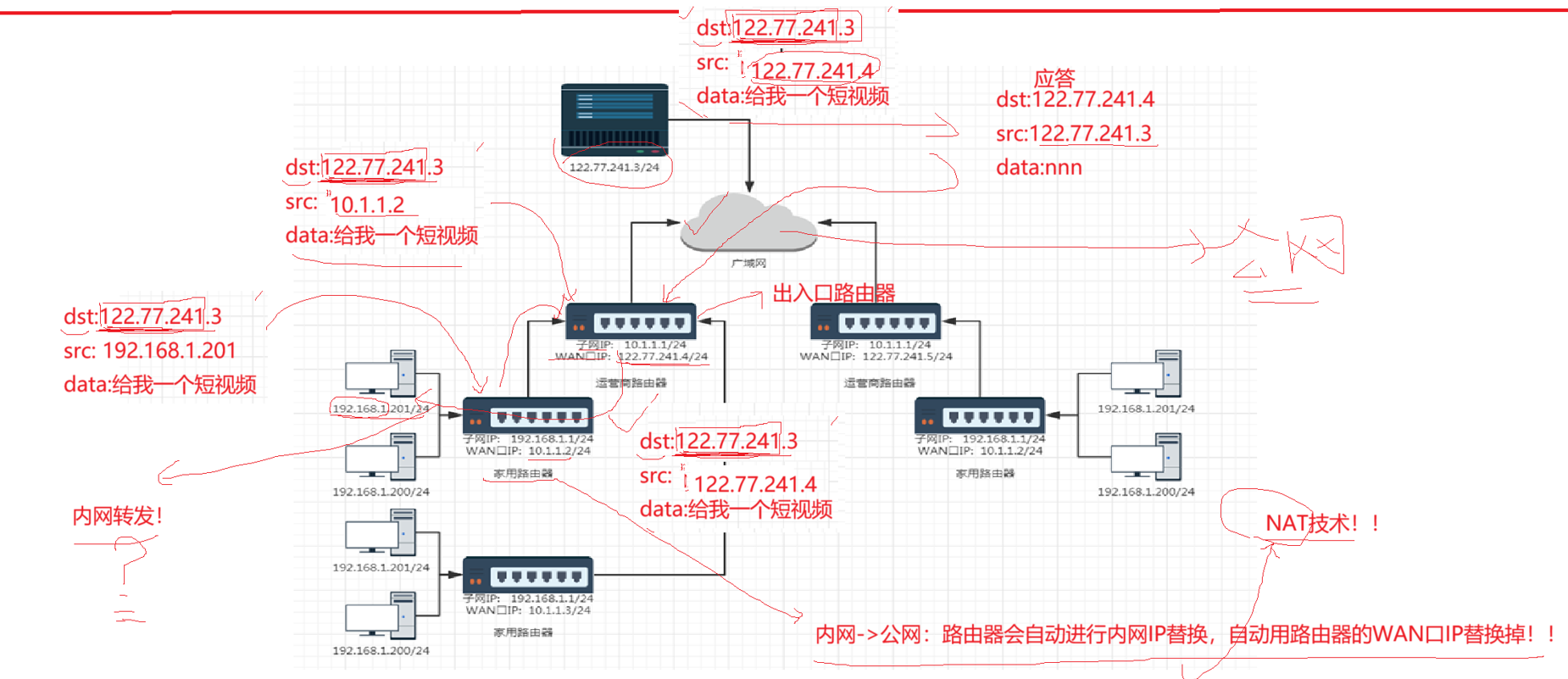
总而言之,我们的个人是通过运营商来访问公网的。
要想了解IP的整个机制,就需要了解一下我们的IP子网划分是怎么样进行的。
首先我们国家与国家之间会有一个国际路由器,我们简化模型,假设俄罗斯的网络地址是1.0,美国是2.0,英国是3.0,中国是5.0,俄罗斯想发一条消息给中国,它会把目的IP与子网掩码进行按位与,然后查表,进行跳跃,国与国之间的国际路由器就是一个子网,
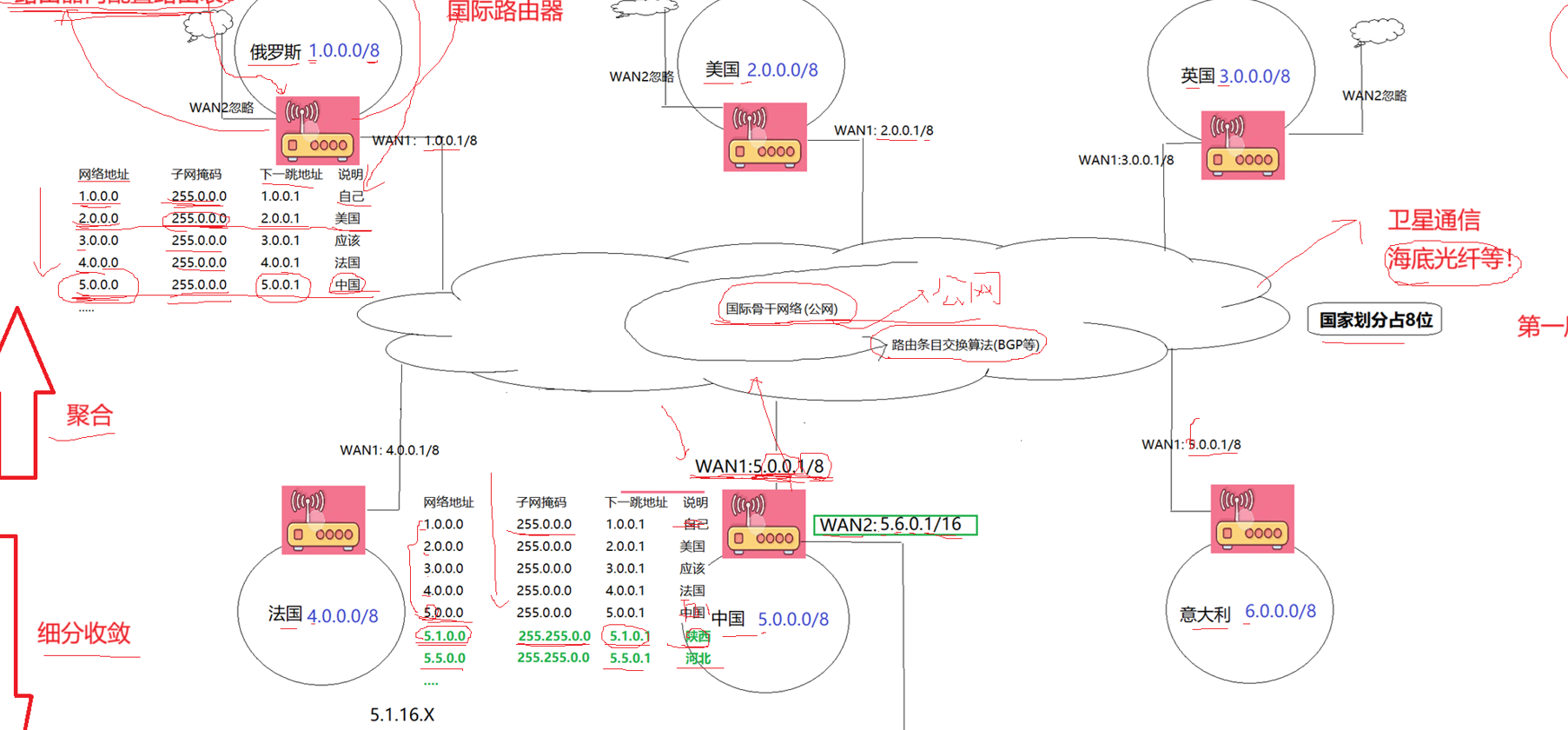
然后中国有许多省份,我们会为每个省份划分一个IP,这是第二次子网划分,每个省内的每个市分发一个IP,这是第三次子网划分,市的IP就相当于我们之前的出入口的路由器,市下面全部都是一个一个的私人IP,就去构建一个一个子网了。
IP能够找到我们的主机就是因为我们的IP被统一设计过了。
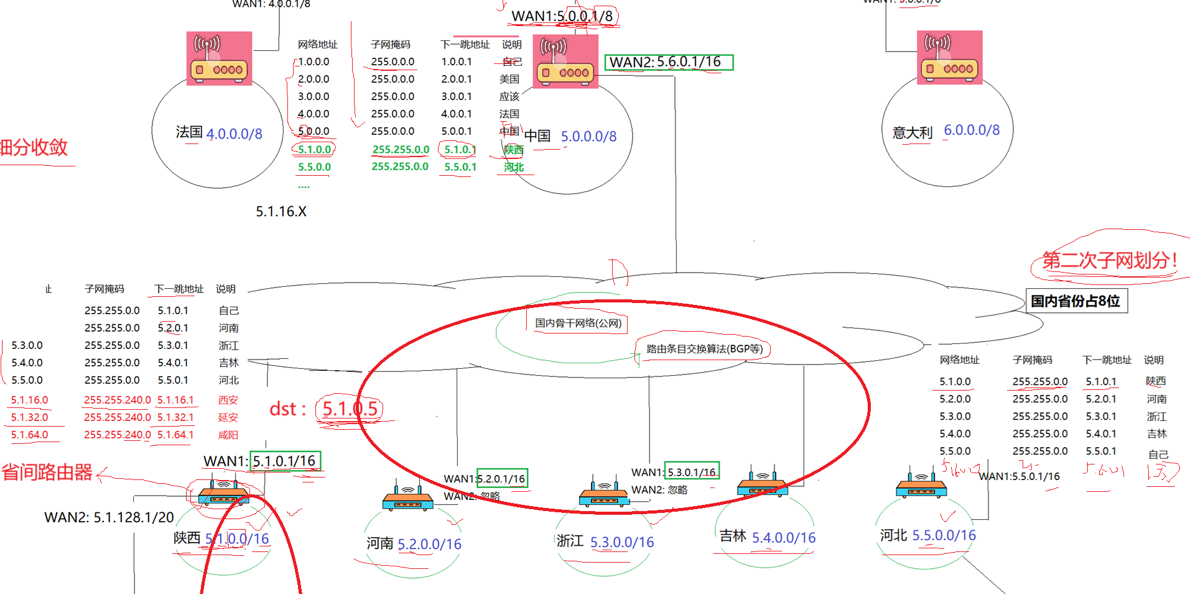
我们的网络=内网+公网,公网有限,我们大部分接触的网络IP都是内网IP。

我们的IP报头里面还有一个13位偏移位,这是因为链路层规定,交给链路层的报文大小不要超过1500字节。所以如果超过我们的网络层需要进行切分。传过去之后再进行合并。
学习网络的本质就是学习报文的整个生命周期,因为我们的IP报文超过规定的大小需要切分,所以我们的IP报头里面有一个表示IP的唯一标识位,如果分片了,标识位就是一样的,
还有一个偏移量是为了让我们的分片之后进行检查是否有丢包的分片。
我们IP分片的过程,和我们的传输层没有关系,不需要让传输层知道,分片和组装的过程都是在你的网络层进行的,不要让上层知道。
分片不是简单的对每个报文进行分片,还要为每个报文进行报头的添加。由一个IP报文变为多个IP报文。
有一个问题是13位偏移量如何表示16位总长度,这是因为我们13位偏移量会右移3位,也就是2的3次方,这样就是16位了,所以这就要求我们的偏移量必须是8的倍数。

报文有分片就要组装,我们分片后就要讨论如何组装的问题。
1.有的分片,有的IP报文根本就没有分片,如何挑出来报文的分片。
如果一个报文分片了,第一个报文,偏移量为0的报文,第三个标志位一定为1,表示还有更多标志位。
如果是最后一个,那它的偏移量一定大于0,并且第三个标志位为0,表示没有更多分片了。
2.挑出来分片的报文了,如何确保它们的完整?
完整就是有头有尾有中间,根据头部和尾部的特性可以知道,那么如何知道中间的呢?
一个报文的偏移量等于它前面报文的有效载荷+前面报文的偏移量,按照升序排序,就能发现是否有缺失的,如果有,丢弃整个报文进行重传。
我们知道了这么多分片和组装的策略,但是并不意味着我们要多进行分片,这是迫不得已进行分片和组装,你想我一个IP报文传输成功的概率大,还是一群IP报文传输成功的概率大,肯定是一个IP报文传输的概率大,所以我们分片之后一个IP报文丢失就要丢掉整个报文,不利于我们可靠的传输,丢包之后我们的传输层还要进行重传。非常低耗时啊。
所以我们要尽量减少分片,要减少分片就要让我们的传输层尽量传输少于我们的链路层最大接受报文的量,所以我们的传输是用滑动窗口进行分段传输而不是把整个滑动窗口的字节全部传输过去,这样做会变相增大丢包率。
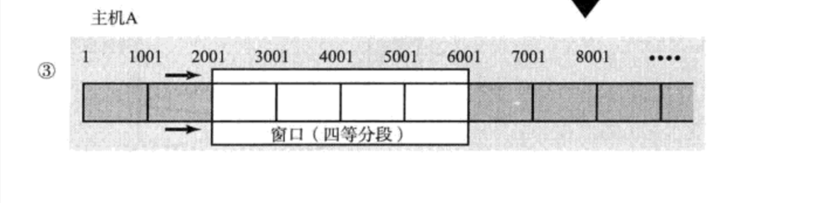
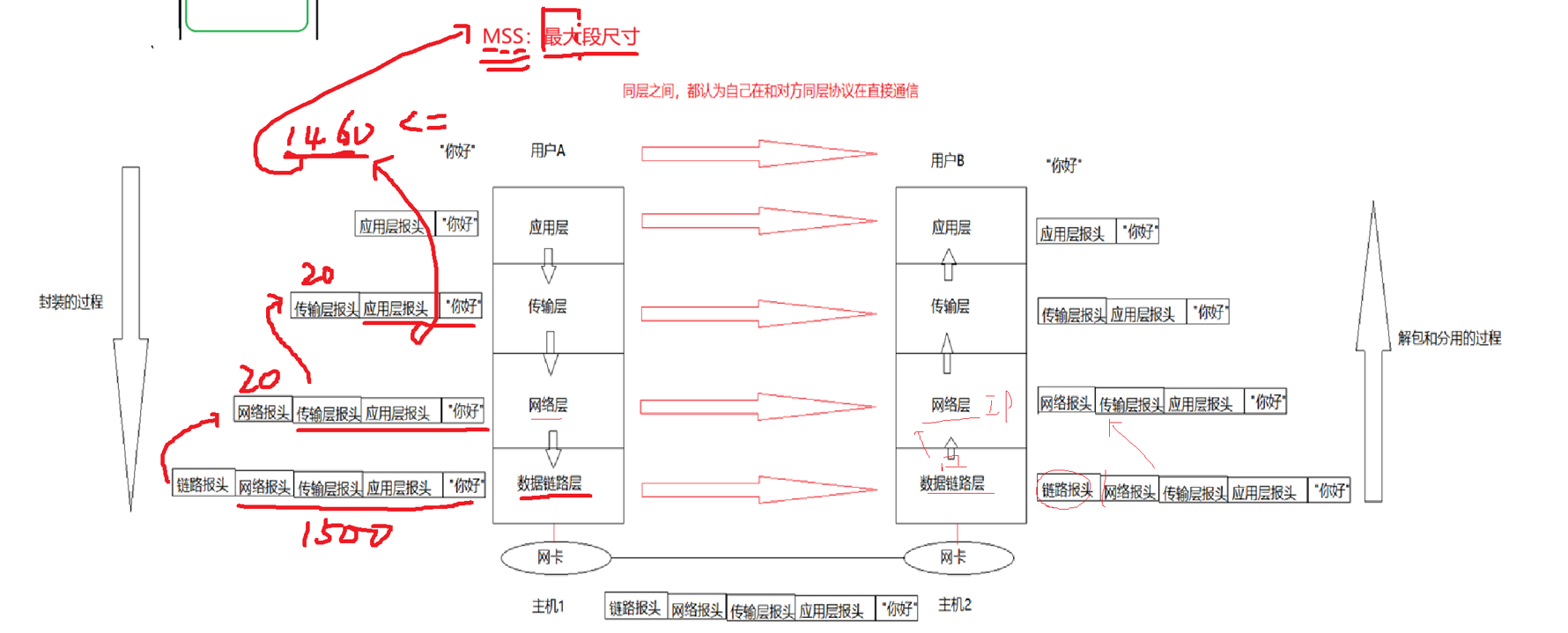
所以传输层需要选择合适的数据大小进行传输。什么是合适的数据大小呢?
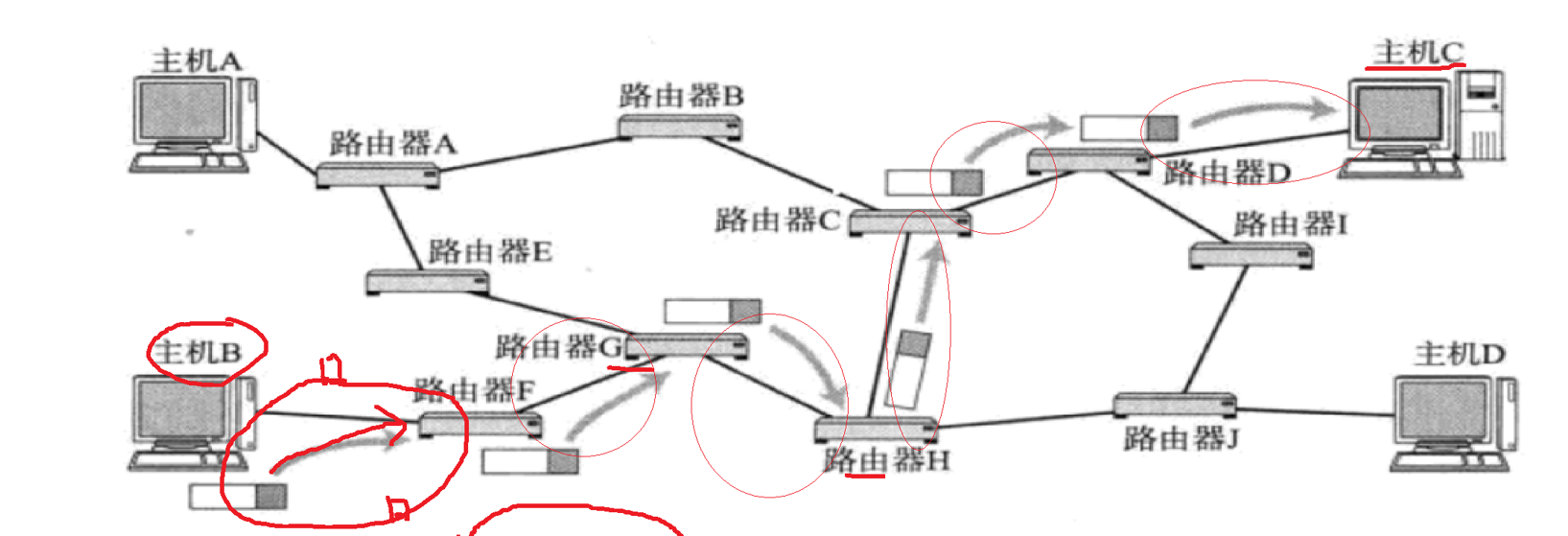
子网传输中,为什么要把数据要给路由器F,这是因为我的IP报文的网络地址是路由器F,目的IP决定的,目的IP决定你往哪个路由器进行传输。
如何把数据交给F就是局域网通信的问题,这是由数据链路层解决的。
2.数据链路层
数据链路层有:
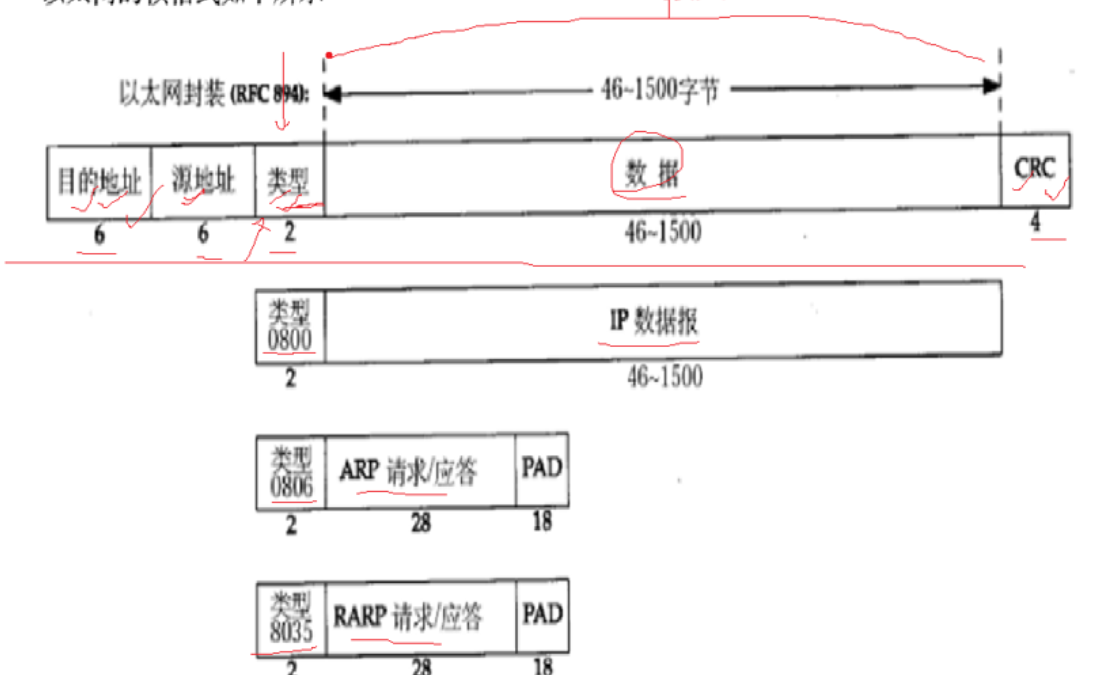
目的地址就是目的MAC地址,源IP地址就是源MAC地址,类型就是说明该报文向上交付给谁。
CRC进行数据校验,检查数据是否传输正确,不正确丢掉进行重传。
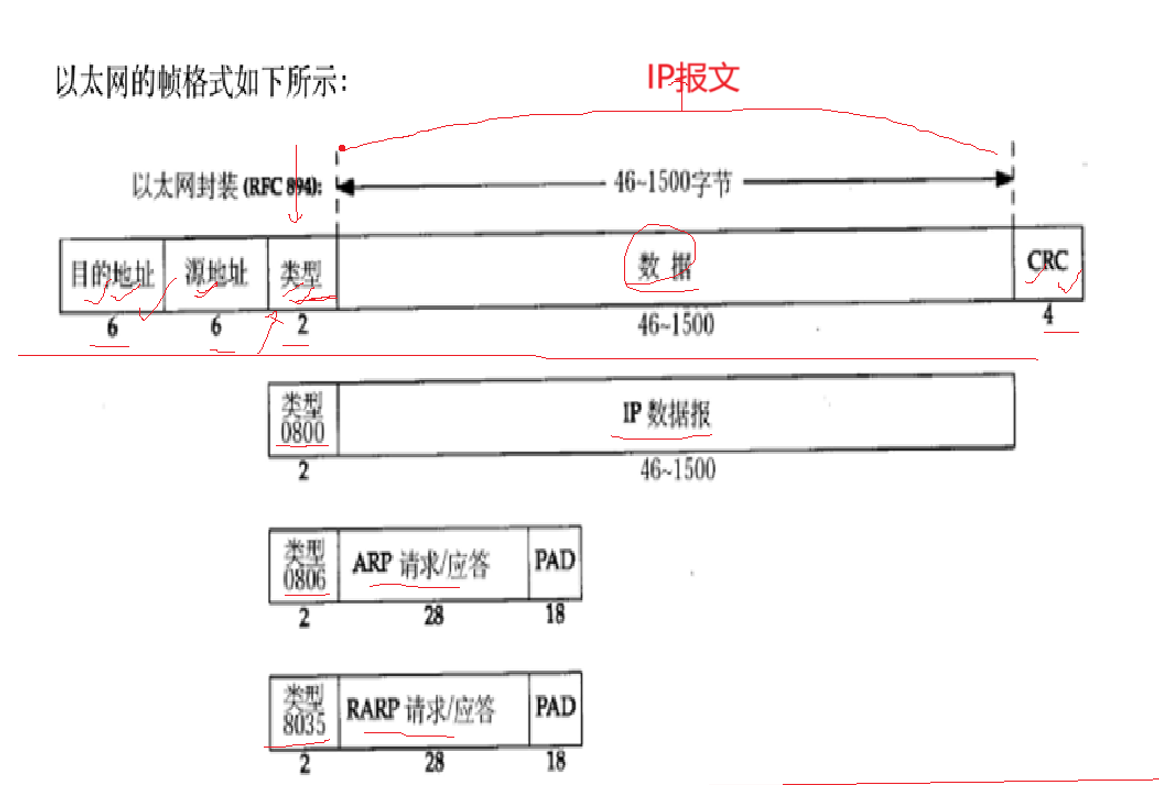
MAC数据帧并不是越大越好,局域网进行通信,会发送碰撞,为了保证数据的正确传输就有碰撞避免和碰撞检测,发送碰撞就要进行重传。
一个MAC数据帧太大了,在网络间停留的时间长,容易发生碰撞。但是太小了比如1字节,它传的数据还没有报头大,效率太低,所以MAC帧数据不能太高也不能太低,科学家进行大量的实验发现46-1500字节是最为合适的,所以我们的传输最大值为1500字节,如果不够46字节会补够46字节。
一个数据帧在进行转发的时候需要知道目的MAC地址,和源MAC地址,源MAC地址肯定知道,那么问题就是我们的目的MAC地址,所以会出现我们的ARP协议获取局域网内特性的MAC地址。
大致的过程是我们的会把我们的MAC帧的目的地址设为全F,发给局域网内所有的主机,然后所有的主机收到,拆掉MAC帧报头,然后里面有ARP报头,ARP报头里面就有
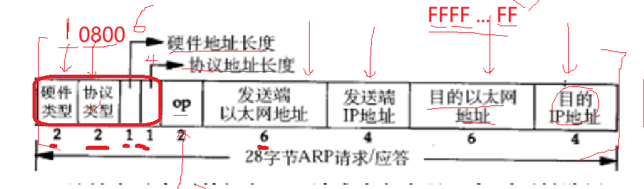
发送方会把OP设为1,表示发送,硬件类型0800代表的上层交付给IP协议,目的MAC地址设为全F,然后对应的IP主机收到报文会对我们的发送方进行应答,然后我们发送方就收到了目的MAC地址就可以进行路由传输了。
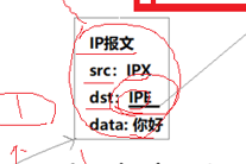
我们知道的IP报文会进行转发,我的问题是,当我们到达我们的子网路由器入口的时候,我的IP报文里面有源IP和目的IP,但是我们如果要进行转发还需要知道我们的目的MAC地址,就比如下面这个IP报文,它的目的IP是IPX,它的源IP是我们的IPE,而我们的路由器则是R,我们已经到了子网的入口,下一步我要将我的IP报文交给我们的数据链路层。
数据链路层有我们的以太网目的地址,也就是我们的目的MAC地址,还有以太网源地址,也就是源MAC地址,还有帧类型,说明报文是应该交付向上交付给谁,但是我们不知道我们IPE的MAC地址,我们只知道它的IP地址,所以我们为了知道我们的IPE的MAC地址,就有ARP协议。

ARP的报文有硬件类型,一般是1表示以太网,协议类型表示要转化的地址,0800代表IP,OP代表是请求还是应答报文,发送端以太网地址就是本主机的MAC地址,发送端IP地址就是本主机的IP地址,目的以太网地址就是不知道的,设为全F,我们知道目的IP地址的。这样我们的ARP报文里面就把目的以太网地址空出来了。
该通信是局域网内通信,我们的数据链路层会把这个报文发给该局域网内所有的主机,所有的主机都会收到该报文,该报文会进行填充。
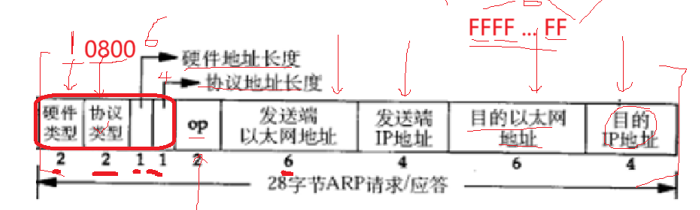
下面就是我们数据链路层填充好的协议,这个报文会发给该局域网内所有的主机,然后其他主机收到这个报文,根据协议,发现我们的目的MAC地址是全F表示任意主机,帧类型是08-06,代表ARP协议,即这个报文不应该直接交付给IP,而是先交给ARP协议栈,嗯,交给ARP了然后,主机会看它的OP字段,判断他是请求报文还是应答报文,看到该报文是请求报文,再去对比发送的目的IP地址,发现目的IP和自己不一样,丢弃,发现目的IP和自己一样就会对我们的目的MAC地址进行填充,然后就会进行应答。

你看,应答的时候它就成了发送报文的一方,它的以太网目的MAC自己就知道,以太网源MAC地址,就是它自己的MAC地址吗,你说它能不知道吗?
帧类型就是选择0806,0806代表了ARP应答,硬件类型选择以太网,协议类型就是0800,表示向上交付给的是IP,OP写为2,代表该ARP报文是应答报文,发送端以太网地址改为MACE,IP为IPE,目的以太网地址改为MACR,目的IP改为IPR,这样我们就把这个报文发给局域网内所有的主机。
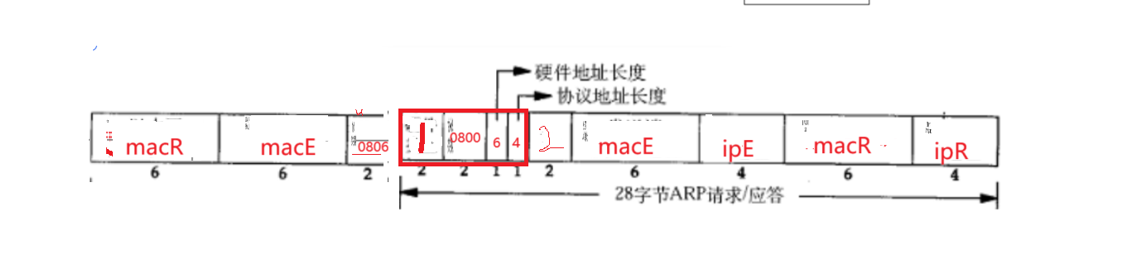
与路由器R发过来的请求报文相比,这次我们的开头的目的地址不再是全F,这样当其他不匹配的目的地址收到该报文的时候,在数据链路层直接丢弃掉,不必到了ARP层再进行丢弃,发的时候全部受到了ARP,不匹配的在ARP层才丢弃,但是回复的时候不匹配的主机在数据链路的MAC层就会被丢掉,当我们的路由器R拆掉报头,拿到ARP的报头,先看OP层发现它是2,就明白了它是一个应答报文,我们要的MAC地址就是ARP中的发送端的MAC地址,至此,我们拿到了目标主机的MAC地址,源IP,目的IP,源MAC,目的MAC也有了,可以开始进行向指定的主机进行发送了。
发送的过程中,我们的ARP不过也是数据链路层的一个协议。



)






)





:H264中的SEI)



