论文基本信息
题目: Cost-Efficient Prompt Engineering for Unsupervised Entity Resolution
作者: Navapat Nananukul, Khanin Sisaengsuwanchai, Mayank Kejriwal
机构: University of Southern California, Information Sciences Institute, Los Angeles, CA, United States of America
发表地点与年份: arXiv 预印本,2024 年
关键词术语: large language models, prompt engineering, unsupervised entity resolution, inter-consistency of prompting
摘要(详细复述)
背景:实体消岐(Entity Resolution, ER)是识别不同数据源中指向同一真实实体的记录的任务,传统方法依赖大量人工特征工程和训练数据筛选。
方案概述:本研究探索使用大型语言模型(LLM)如 GPT-3.5 作为无监督 ER 的相似性函数,通过六种不同的提示工程方法(包括单属性、多属性、JSON 格式、相似度评分和少样本示例)在电子商务数据集上进行实验。
主要结果/提升:实验表明,GPT-3.5 在无监督 ER 上表现良好(F1 分数超过 80%),但更复杂、昂贵的提示方法未必优于简单方法。例如,单属性提示(single-attr)在成本降低 37% 的情况下,性能与多属性方法相近。
结论与意义:LLM 为 ER 提供了一种领域无关的解决方案,但提示设计需权衡成本与性能;简单方法在特定假设下可高效工作。
研究背景与动机
学术/应用场景与痛点:ER 广泛应用于医疗、电商等领域,但传统方法依赖领域专家进行特征工程和规则设计,成本高且泛化性差。
主流路线与局限:
- 机器学习方法:使用 SVM、决策树等分类器,需标注数据和特征工程。
- 深度学习方法:如 BERT,自动学习表示但仍需训练数据。
- 规则方法:基于相似度阈值和预定义规则,依赖专家知识,难以优化。
代表工作与局限:
| 方法类型 | 优点 | 不足 |
|---|---|---|
| 机器学习 | 可学习复杂模式 | 需标注数据、特征工程 |
| 深度学习 | 自动特征学习 | 计算开销大、需训练数据 |
| 规则方法 | 无需训练数据 | 规则设计繁琐、泛化性差 |
问题定义(形式化)
输入:两个实体集合 E1E_1E1 和 E2E_2E2(或单个集合 EEE),每个实体 eee 表示为 (id,Aid)(id, A_{id})(id,Aid),其中 AidA_{id}Aid 是属性键值对字典。
输出:所有匹配的实体对 (ei,ej)(e_i, e_j)(ei,ej)(ei∈E1e_i \in E_1ei∈E1, ej∈E2e_j \in E_2ej∈E2),即重复项。
目标函数:最大化 F1 分数(精确率和召回率的调和平均)。
评测目标:使用精确率、召回率、F1 分数评估性能,成本通过 OpenAI API 的 token 消耗计算。
创新点
- 系统化提示工程评估:首次针对无监督 ER 任务,系统比较六种提示方法(包括单属性、多属性、JSON 结构、相似度评分、少样本)的性能和成本。
- 成本-性能权衡分析:证明简单提示(如单属性)在成本显著降低(37%)的情况下,性能与复杂方法相当,挑战了“更复杂提示必然更好”的假设。
- 一致性研究:通过统计检验(如 t-test)和混淆矩阵分析不同提示方法输出的一致性,发现方法间在重复项上存在显著分歧。
方法与核心思路
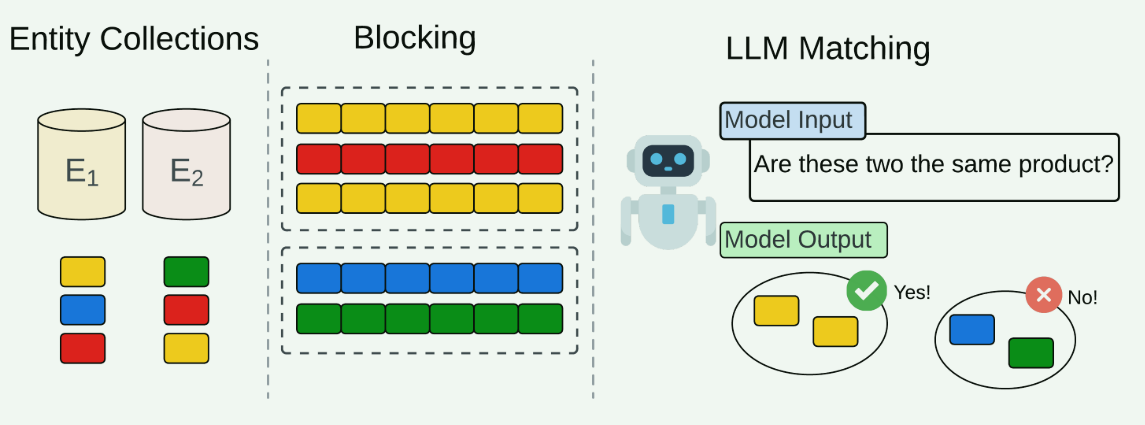
这是一个典型的ER工作流程的说明性示例,但使用LLM作为相似性(或“匹配”)函数。每个实体集合代表一个结构化的ER数据集,各个实体使用彩色方框表示。如第3节中所解释的,首先应用分块来将相似的实体聚类成块,以减少比较所有实体对的二次复杂性。只有共享块的实体被配对并提交给LLM,以做出它们是否匹配(是)或不匹配(否)的最终决定。
整体框架
研究采用标准 ER 工作流,但使用 LLM(GPT-3.5)作为相似性函数。工作流包括:
- 阻塞(Blocking):减少实体对比较数量(本研究假设完美阻塞,直接使用标注对)。
- 相似性计算:通过提示工程让 LLM 判断实体对是否匹配。
步骤分解
- 构建提示模板:包含三个核心组件——候选对、ER 指令、输出格式。
- 设计提示模式:通过修改组件生成六种模式(见下文)。
- 调用 LLM:发送提示,解析返回的决策或相似度。
- 后处理:对于相似度模式(multi-sim),选择最优阈值 θ\thetaθ 最大化 F1。
- 评估:计算精确率、召回率、F1 和成本。
模块与交互
- 候选对表示模块:处理实体属性(单属性、多属性拼接、JSON 结构化)。
- 指令模块:控制 LLM 行为(直接决策、生成相似度、添加角色描述)。
- 示例模块(仅少样本模式):注入标注示例引导 LLM。
- 输出解析模块:提取 LLM 返回的决策或相似度。
公式与符号
核心评估公式:
Precision=∣TP∣∣TP∣+∣FP∣ \text{Precision} = \frac{|\text{TP}|}{|\text{TP}| + |\text{FP}|} Precision=∣TP∣+∣FP∣∣TP∣
Recall=∣TP∣∣TP∣+∣FN∣ \text{Recall} = \frac{|\text{TP}|}{|\text{TP}| + |\text{FN}|} Recall=∣TP∣+∣FN∣∣TP∣
F1=2×Precision×RecallPrecision+Recall \text{F1} = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=Precision+Recall2×Precision×Recall
其中 TP、FP、FN 分别表示真阳性、假阳性、假阴性。
伪代码
Input: 实体对集合 P, 提示模式 M
Output: 预测标签列表 L
for each pair (e_i, e_j) in P:prompt = construct_prompt(e_i, e_j, M) // 根据模式构建提示response = call_gpt3.5(prompt) // 调用 LLMif M == "multi-sim":score = extract_similarity(response) // 提取相似度else:label = extract_decision(response) // 提取决策L.append(label)
if M == "multi-sim":θ = find_optimal_threshold(P_scores) // 选择最大化 F1 的阈值L = [1 if score >= θ else 0 for score in P_scores]
return L
伪代码描述:该流程遍历所有实体对,根据提示模式构建提示并调用 GPT-3.5;对于相似度模式,先提取分数再通过阈值二值化;其他模式直接提取决策标签。
复杂度分析
- 时间复杂度:O(∣P∣×t)O(|P| \times t)O(∣P∣×t),其中 ∣P∣|P|∣P∣ 是实体对数量,ttt 是 LLM 响应时间(常数)。
- 空间复杂度:O(∣P∣)O(|P|)O(∣P∣) 存储结果。
- 资源开销:成本由 token 数量决定,多属性提示比单属性昂贵 37%。
关键设计选择
- 使用预训练 LLM:无需微调,利用先验知识处理跨领域 ER。
- 强调成本效率:针对工业级 ER 需处理百万对实体,简单提示可显著降低成本。
- 结构化 JSON 实验:假设机器可读格式提升性能,但结果相反,说明 LLM 更适应自然语言。
实验设置
数据集:
- WDC Computers:1,100 对(300 重复),7 个属性。
- Amazon-Google Products (AG):11,460 对(1,166 重复),3 个属性(含文本描述)。
对比基线:六种提示方法(无外部基线,内部比较)。
评价指标:精确率、召回率、F1(定义见公式),成本(美元)。
实现细节:
- 框架:OpenAI GPT-3.5 API。
- 硬件:未说明。
- 超参数:未说明(如温度)。
- 随机性:少样本示例随机选择,但种子未说明。
实验结果与分析
主结果:下表汇总两种数据集上六种方法的性能(F1)和成本(美元),最佳性能加粗:
| 提示模式 | WDC F1 | WDC 成本 | AG F1 | AG 成本 |
|---|---|---|---|---|
| multi-attr | 0.91 | $3.04 | 0.87 | $0.93 |
| single-attr | 0.94 | $2.19 | 0.81 | $0.59 |
| multi-json | 0.81 | $3.23 | 0.69 | $0.99 |
| few-shot | 0.96 | $3.75 | 0.87 | $1.36 |
| multi-sim | 0.71 | $3.11 | 0.95 | $0.95 |
| no-persona | 0.97 | $2.01 | 0.71 | $0.68 |
关键发现:
- 单属性提示:在 WDC 上 F1 最高(0.94),成本降低 37%;在 AG 上 F1 略降(0.81 vs 0.87)。
- JSON 格式有害:multi-json 在两组数据上 F1 均下降(WDC: 0.91→0.81, AG: 0.87→0.69)。
- 相似度评分不稳定:multi-sim 在 AG 上表现最佳(0.95),但在 WDC 上最差(0.71)。
- 角色描述重要性:no-persona(无角色)在 AG 上性能显著下降(F1=0.71 vs 0.87)。
消融实验:通过对比 multi-attr(基线)、single-attr(减属性)、no-persona(减角色)进行隐含消融,显示角色和属性选择的影响。
统计显著性:t-test 表明 no-persona 与其他方法在多数情况下差异显著(p < 0.05)。
一致性分析:表 4 和表 5 显示,方法间在重复项上分歧较大(如 multi-json 误判 46% 的 multi-sim 正确对)。
误差分析与失败案例
错误类别:
- 技术术语混淆:如 RAM 通道数(Quad vs Dual)和时序格式(CL16 vs 16-16-16-19)导致误判。
- 模型编号歧义:细微差异(如 SDCFXPS-128GB-X46 vs SDCFXPS-128GB)导致幻觉(LLM 错误声称编号相同)。
- 信息过载:多属性提示有时引入噪声(如测试速度 2800MHz 与 2400MHz 冲突)。
边界条件:LLM 在“简单”对上稳健(明显匹配/不匹配),但在细节差异上表现不佳。
复现性清单
代码/数据:数据通过 Google Drive 链接公开(见原文 Data Availability)。
模型权重:使用 OpenAI GPT-3.5 API,非开源模型。
环境与依赖:未说明。
运行命令:未说明。
许可证:未说明。
结论与未来工作
结论:GPT-3.5 可作为无监督 ER 的可行方案,但提示设计需谨慎;简单方法常更经济。
未来工作:
- 探索 LLM 用于阻塞(blocking)步骤。
- 研究更高效的提示策略(如动态属性选择)。
- 开源数据促进进一步研究。
注:部分细节(如超参数、代码环境)未在原文中说明,以“未说明”标注。
?为什么Vision Pro离不开它?)



)
函数)

)











