🌟 各位看官好,我是egoist2023!
🌍 Linux == Linux is not Unix !
🚀 今天来学习C语言缓冲区和内核缓存区的区别以及缓存类型。
👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦!

目录
书接上文
引入
什么是缓冲区
为什么要引入缓冲区
缓冲类型
FILE结构体
扩展
cout和cerr分开
将文件内核缓冲区刷新到磁盘
语言级缓冲区的意义
总结
书接上文
上文我们深入拆解了 Linux “一切皆文件” 设计哲学的核心支撑:从进程task_struct中的files_struct结构出发,明确了文件描述符(FD)作为 “数组下标” 的本质与分配规则;更通过struct file与file_operations结构体的分析,揭示了 Linux 如何以 “上层统一接口(如read/write)、下层设备差异化实现” 的 “类 C++ 多态” 思路,让进程能以一致视角访问异构资源,极大简化了开发复杂度。
然而,当我们聚焦于这些统一接口的实际 I/O 执行细节时会发现:用户空间与内核空间的频繁切换、高速 CPU 与低速外设(磁盘、网络卡等)的速度鸿沟、以及 “单次小数据 I/O” 带来的硬件调度低效,都会成为制约资源访问性能的关键瓶颈。为了解决这些矛盾、在 “统一接口” 的基础上进一步优化 I/O 效率,Linux 引入了缓冲区(Buffer/Cache) 机制 —— 它既是衔接 “用户进程” 与 “底层文件 / 设备” 的核心中间层,也是 “一切皆文件” 哲学在性能层面的重要延伸。接下来,我们将深入解析缓冲区的设计逻辑、实现机制及其在 I/O 流程中的关键作用。
引入
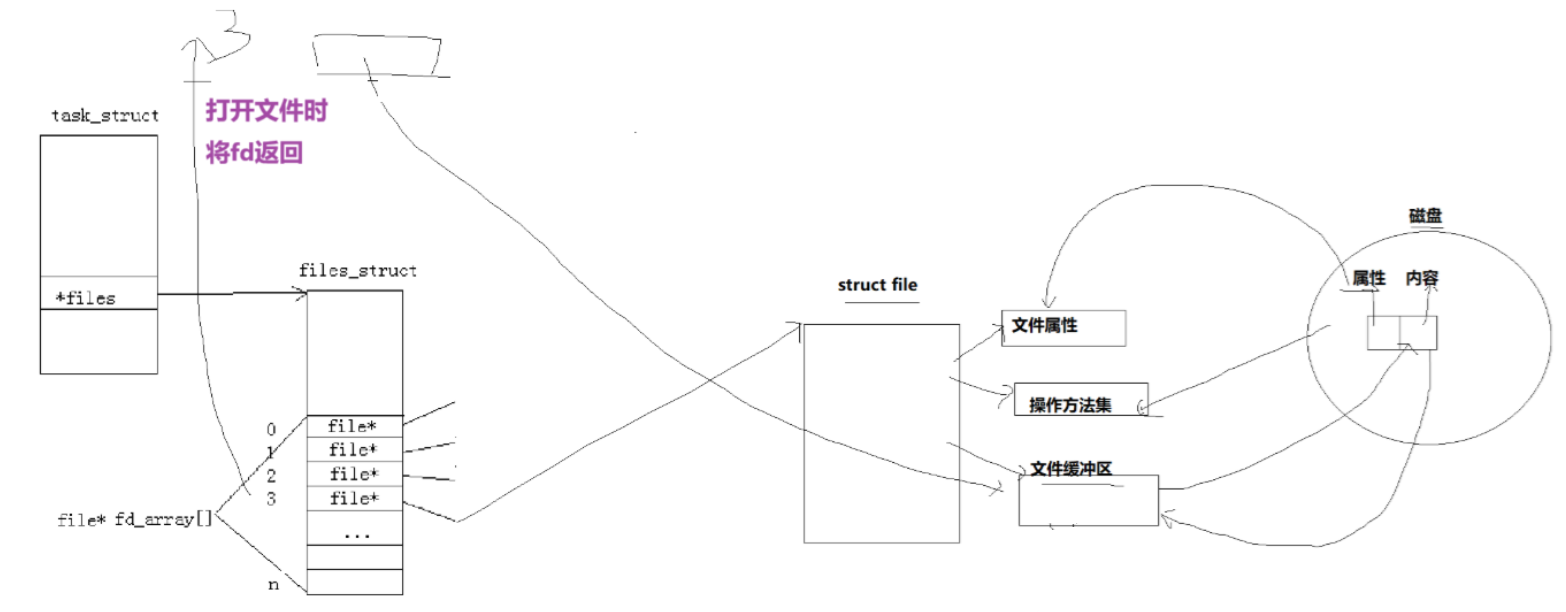 根据前面所学,一个进程要打开文件必须要通过OS进行打开,操作系统为了管理所打开的⽂件,都会为这个⽂件创建⼀个file结构体,内部就要加载一个文件的属性和内容,属性加载到文件属性 ,内容加载到文件缓冲区中。这里的缓冲区指的是文件内核缓冲区。
根据前面所学,一个进程要打开文件必须要通过OS进行打开,操作系统为了管理所打开的⽂件,都会为这个⽂件创建⼀个file结构体,内部就要加载一个文件的属性和内容,属性加载到文件属性 ,内容加载到文件缓冲区中。这里的缓冲区指的是文件内核缓冲区。
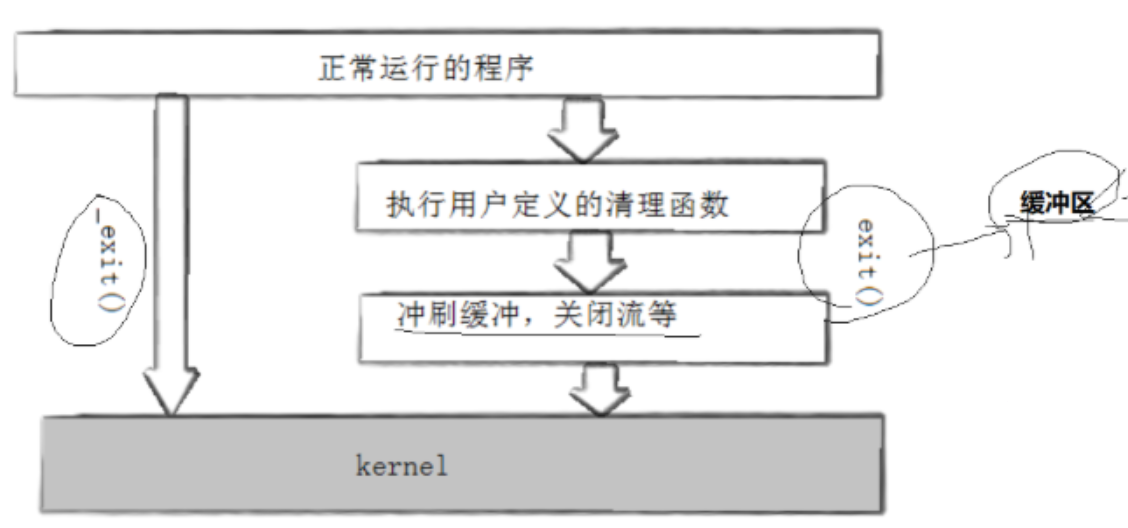
在进程·柒章节,我们讲了三种退出场景,对exit和_exit做了对比,exit属于库函数,终止进程时会主动刷新缓冲区。这里的缓冲区指的是C语言库提供的缓冲区。
什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输⼊设备还是输出设备,分为输⼊缓冲区和输出缓冲区。
简单来说,缓冲区的本质就是一段内存空间
为什么要引入缓冲区
这里提供一段小故事供大家进行理解:
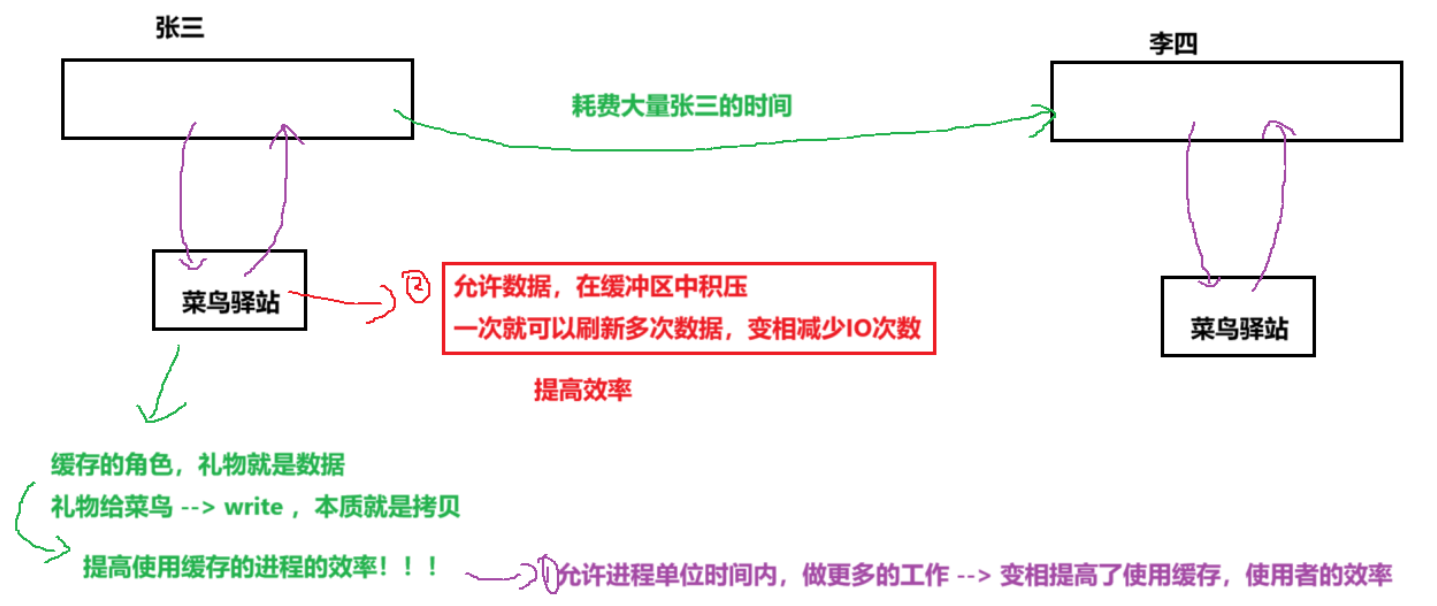
事件一:假期之余,张三买了一台大疆action5pro的运动相机记录生活。李四恰巧这几天要出外旅游,打算租台相机拍拍vlog,听闻朋友张三买了台action5pro。李四给张三呼电话:老朋友啊!听闻你这几天买了台相机,这几天打算出外玩玩,可否借你相机一用。热情的张三对朋友也是极为真诚,直接答应了,说道:李四啊!在家里等我一下,我现在开车就把相机送你那。
张三到李四的家费了半天的时间。
事件二:待张三回来后,发现街拍套装忘给李四送过去了,但此时他自己也有事情要做。张三想了一想,要不把自己的东西放菜鸟驿站上寄送,由快递员代替他讲街拍套装送到李四那的菜鸟驿站。
快递员从张三的菜鸟驿站到李四的菜鸟驿站也是需要花费半天的时间。只不过这个动作主体由张三替换成了快递员。这意味着什么呢?张三可以在这段本是要他送货的时间转移到了快递员,允许自己做更多的工作了。
事件三:我们清楚菜鸟驿站的货并不是一收到货就马上派送的,可以等货多了再进行派送。
相机和街拍套装就是数据,是缓存的角色;
菜鸟驿站就是所谓的缓冲区;
将数据给菜鸟本质就是拷贝;
菜鸟驿站允许等货多了再进行派送就是允许数据在缓冲区中积压。这样做的目的一次就可以刷新多次数据,变相减少IO次数。
读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。
为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作⼤ 快于对磁盘的操作,故应⽤缓冲区可⼤ 提⾼计算机的运⾏速度。⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是⼀块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和⾼速的CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作。
缓冲类型
由于我们的缓冲区是允许数据进行积压的,那么肯定有自身的一套积压规则存在:
标准I/O提供了3种类型的缓冲区。
- 全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通常使⽤全缓冲的⽅式访问。
- ⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024。
- ⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
除了上述列举的默认刷新⽅式,下列特殊情况也会引发缓冲区的刷新:
缓冲区满时;
执行fflush语句;

验证stderr是否带缓冲区:
int main()
{close(2);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0) {perror("open");return 0;}perror("hello world");close(fd);return 0;
}将2号⽂件描述符重定向⾄⽂件,由于stderr没有缓冲区,“hello world”不⽤fflush就可以写⼊⽂件。
cat log.txt
hello world : Success
FILE结构体
printf("hello linux,hello everyone!");
sleep(3);
return 0;在上面这段代码中,printf执行完毕后,并未打印到显示器上,而是3s后显示。那么在sleep期间,我们的数据在哪呢?毫无疑问,在缓存区中。
是什么缓冲区呢?C语言库提供的缓冲区。那这个缓冲区又在哪呢?FILE结构体中。
- struct FILE 本质是一个结构体
- C语言上,输入输出格式化
- C访问文件,都是通过FILE访问的,包括stdin,stdout, stderr!
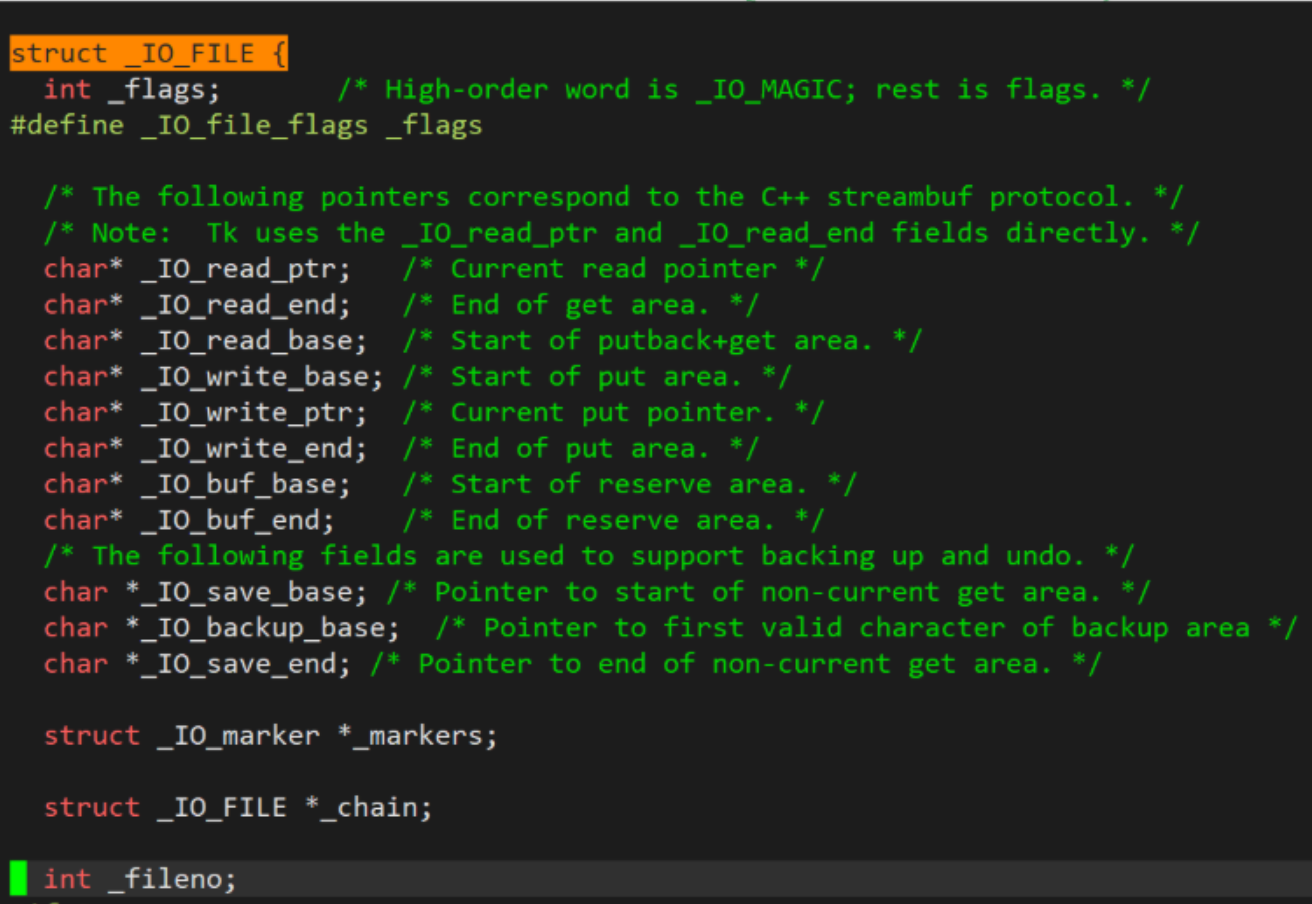
FILE结构体内部为我们维护:语言级别的缓冲区空间!
struct FILE
{int fd;char *inbuffer;char *outbuffer;
}
如何理解printf,scanf 的格式化过程?
int a = 123456;
printf("%d", a);- 格式化
- 格式化结果刷新到FILE缓冲区中
- 检测是否需要刷新
- 满足条件时调用write系统调用刷新到文件内核缓冲区中
文件内核缓冲区的刷新方式比较特殊,是单独的执行流,这里不做考虑。
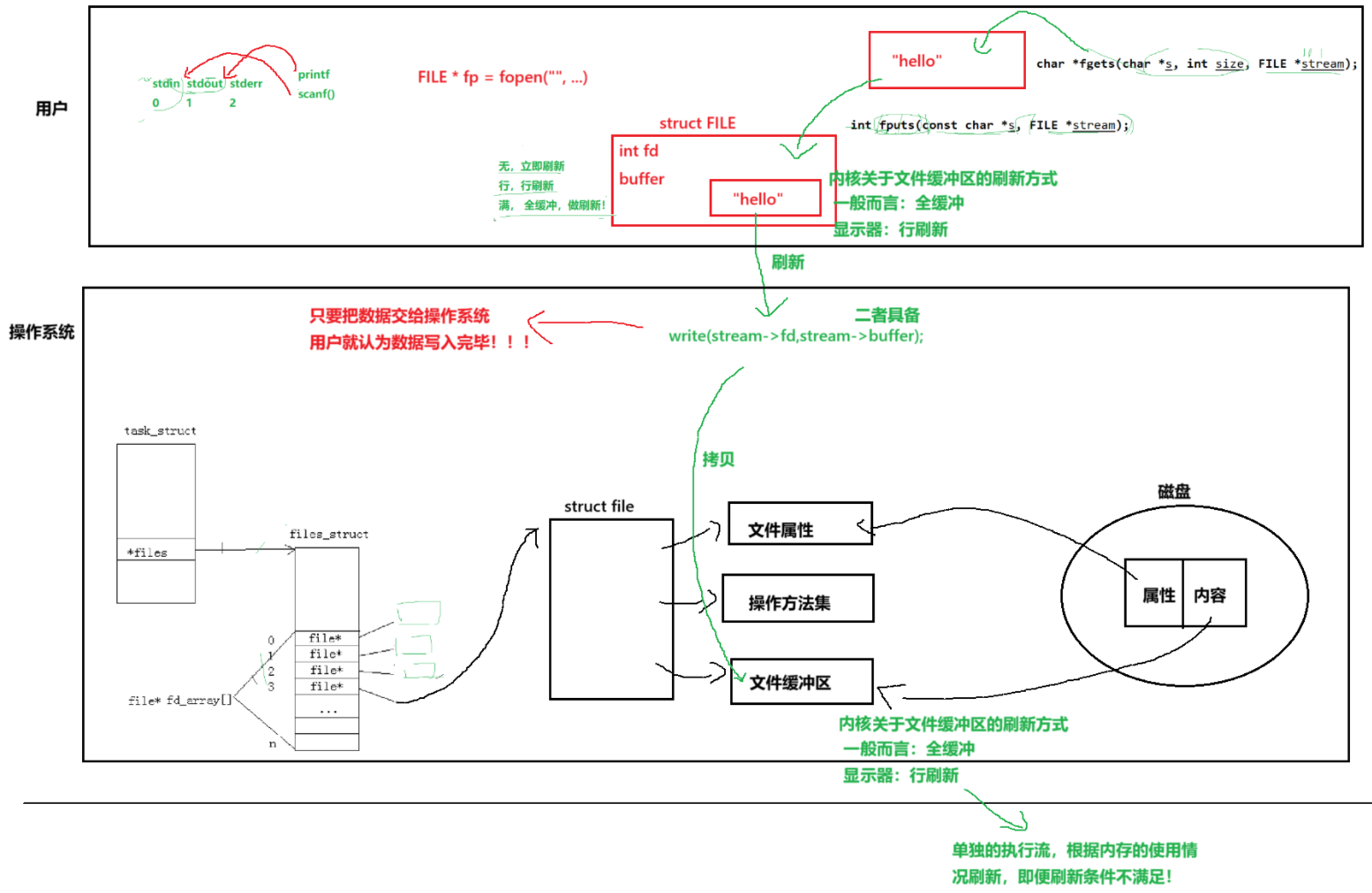 由此我们也可以回答上一章节留下的疑惑,为什么close该文件后,并没有显示打印的内容。
由此我们也可以回答上一章节留下的疑惑,为什么close该文件后,并没有显示打印的内容。
int main()
{close(1);int fd = open("log.txt",O_CREAT | O_WRONLY | O_TRUNC,0666);if(fd<0){perror("fd");return 1;}printf("hello file,fd:%d\n",fd); // stdout -> 1close(fd);return 0;
}一般向普通文件写入是全缓冲。此时程序还没结束,文件被关闭了,而我们的内容还在FILE内缓冲区中,没有刷新到文件内核缓冲区中,所以没有显示打印内容。
那为什么fflush刷新呢?想必底层是调用write系统调用,实际上就是如此。
fflush底层调用write系统调用,将FILE内缓冲区强制刷新到文件内核缓冲区中,文件内核缓冲区在刷新出来给我们看到。(由语言到内核的过程)
扩展

int main()
{//C提供const char *s1 = "hello printf\n";printf(s1);const char *s2 = "hello fprintf\n";fprintf(stdout,s2);const char *s3 = "hello fwrite\n";fwrite(s3,strlen(s3),1,stdout);//系统const char *s4 = "hello write[syscall]\n";write(1,s4,strlen(s4));//创建子进程fork();return 0;
}在上面这段程序当中, 执行过程是:调用printf、fprintf、fwrite三个C库函数和系统调用write,再创建一个子进程,我们来观察两种情况:
情况1:向显示器进行写入 --> 刷新策略:行刷新
由于是行刷新策略,当遇到换⾏符时语言级缓冲区会自动刷新到文件内核缓冲区中,因此是有规律地刷新到文件内核缓冲区中,此时创建子进程,之后程序结束需要情况语言级缓冲区,但缓冲区上并没有数据。最终文件内核缓冲区再刷新出去,向显示器写入数据,给我们看到符合我们需求的结果。
情况2:向文件进行写入 --> 刷新策略:全缓冲
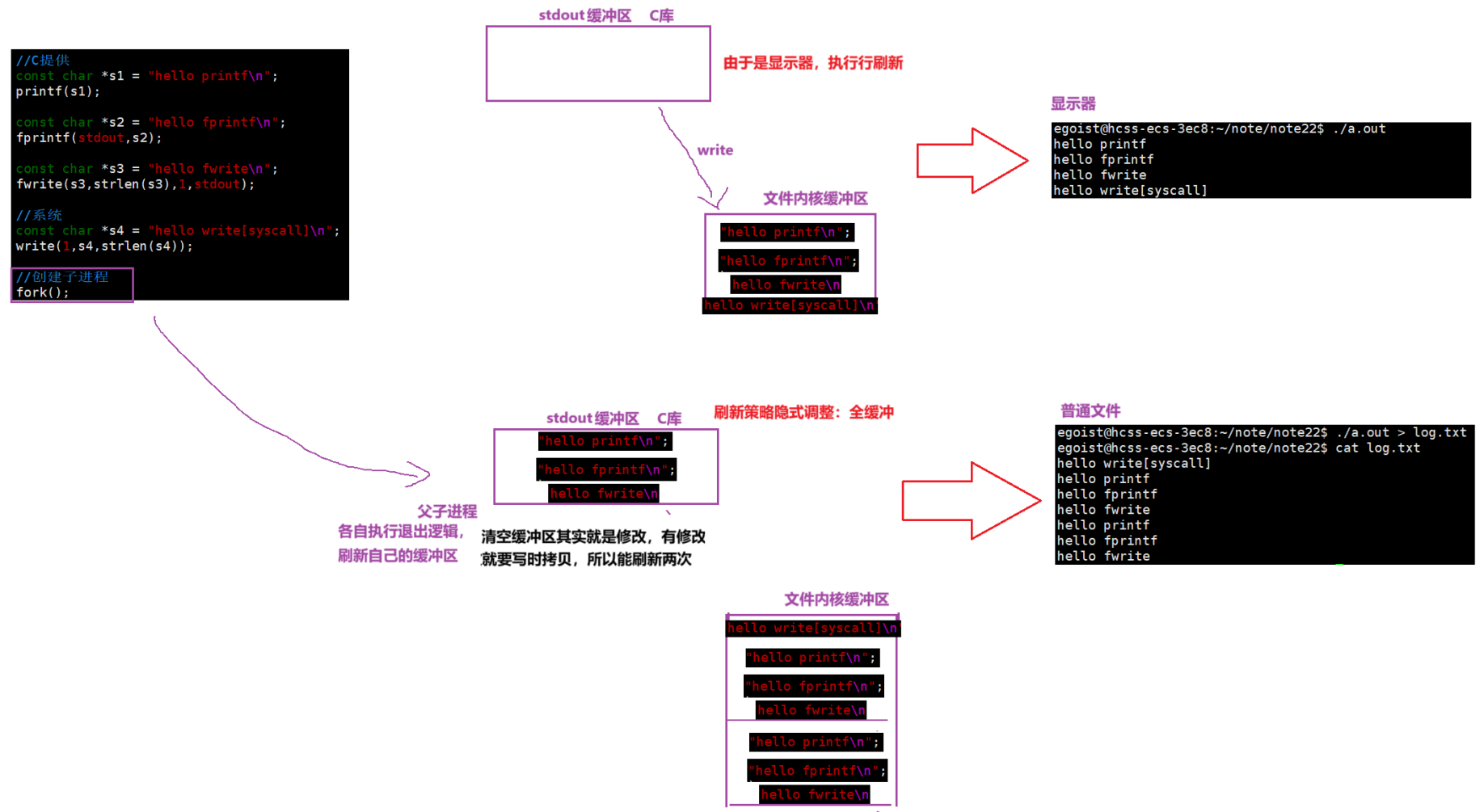
但当向文件进行写入时,打印结果并不是符合我们所想的,为什么同样的代码会有两种不同的结果呢?
首先,向文件进行写入一般的刷新策略是全缓冲,前三个都是C语言提供的库函数,因此都是向FILE内缓冲区进行写入,而write是系统调用,写到文件内核缓冲区中,因此先看到write[syscall]这个结果并不例外。
但是为什么有两段同样的打印结果呢?
write结束后,此时会调用fork创建子进程,之后程序就结束了。由于程序结束了,就需要清空缓冲区,而此时我们是父子进程啊,而子进程清空缓冲区实际上就是修改数据啊,修改就要发生写时拷贝,并不会影响父进程的缓冲区。父进程再进行清空缓冲区,呈现出刷新两次的结果。(即父子进程各自执行退出逻辑,刷新自己的缓冲区)
cout和cerr分开
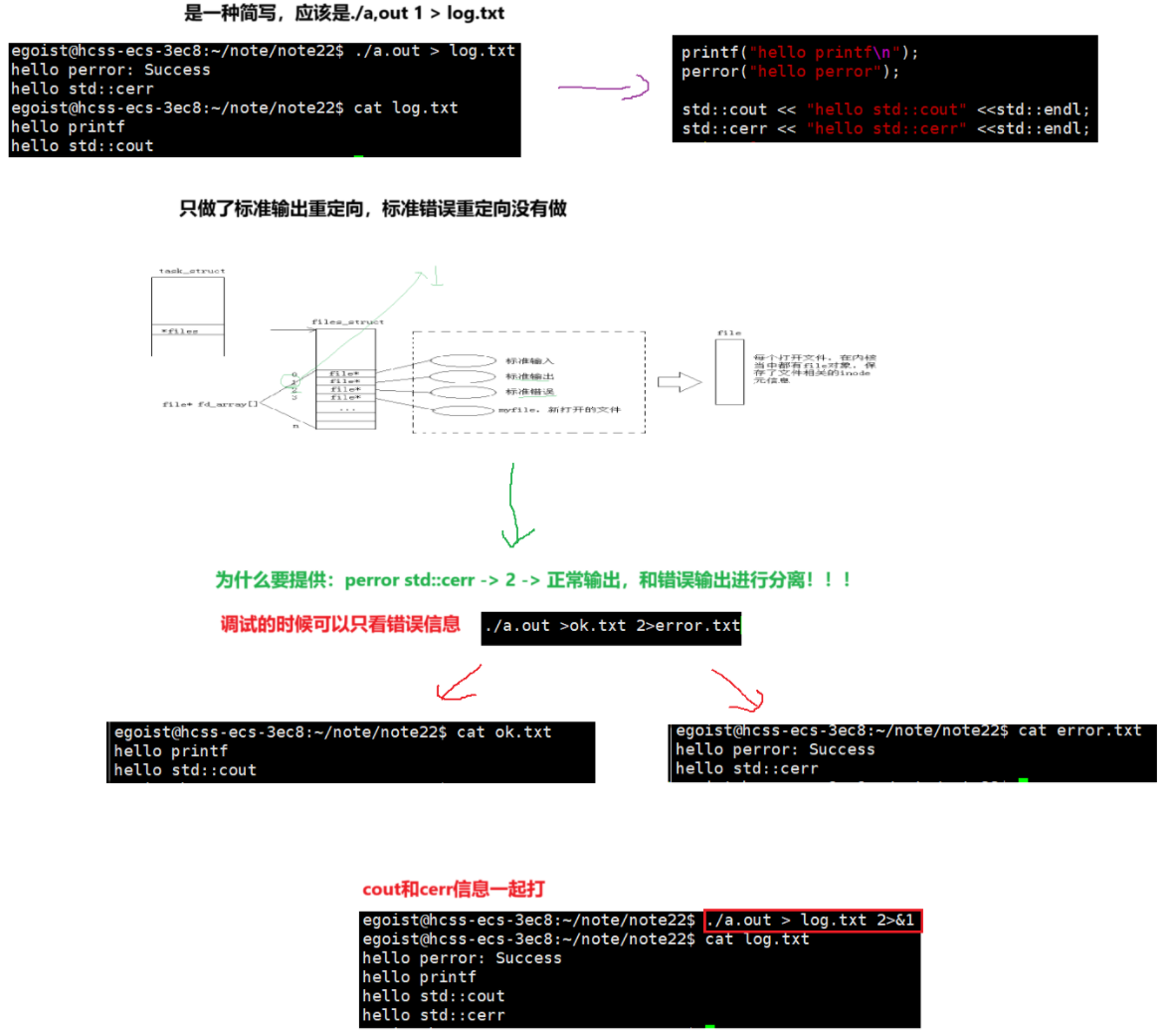
将文件内核缓冲区刷新到磁盘
int fsync(int fd);
强制将指定文件描述符(
fd)对应的文件的所有已修改数据和元数据从操作系统缓存(如页缓存)刷新到磁盘。
语言级缓冲区的意义
- IO相关函数与系统调⽤接⼝对应,并且库函数封装系统调⽤,所以本质上,访问⽂件都是通过fd访问的,而调用系统调用是有成本的(浪费时间)。
- 就拿C语言的malloc来说,我们在造vector轮子时,说过扩容尽量往1.5倍和2倍去靠,是为了减少扩容次数,频繁扩容只是原因之一,并不是重点。malloc底层调用了系统调用,这意味着会频繁调用系统调用,要花费操作系统的时间。
- C语言为什么要提供缓冲区呢?FILE结构体内的缓冲区允许积压,加速IO函数的调用频率。而使用C语言IO接口,提高了效率,进而使单位时间内,执行C代码行数就变多了,从而也反向提高了IO接口的效率。
总结
本文深入探讨了Linux系统中缓冲区的设计原理与实现机制。文章从Linux"一切皆文件"的哲学出发,分析了缓冲区作为衔接用户进程与底层设备的关键中间层,如何通过减少系统调用次数、平衡CPU与低速I/O设备的速度差异来提升系统性能。内容涵盖缓冲区的三种类型(全缓冲、行缓冲、无缓冲)、FILE结构体实现原理,并通过具体代码示例演示了不同缓冲策略下的I/O行为差异。文章特别解析了C语言缓冲区与内核缓冲区的交互机制,包括缓冲区刷新时机、父子进程间的缓冲区复制问题等,最终阐明了缓冲区设计在平衡统一接口与高效I/O访问之间的重要意义。





)










)



