摘要:本文整理自淘宝闪购(饿了么)大数据架构师王沛斌老师在 Flink Forward Asia 2025 城市巡回上海站的分享。
引言
在数字化转型的浪潮中,企业对实时数据处理的需求日益增长。传统的实时数仓架构在面对业务快速变化和数据规模爆炸性增长时,逐渐暴露出数据孤岛、成本高企、研发效率低下等问题。淘宝闪购(饿了么)作为阿里巴巴集团重要的本地生活服务平台,在数据架构演进过程中积累了丰富的实践经验。
本文将从三个维度深入分析淘宝闪购(饿了么)基于 Apache Flink 和 Paimon的 Lakehouse 生产实践:回顾实时数仓的演进历程(前世),深入解析湖仓应用的落地实践(今生),并展望未来的技术发展方向(未来)。
一、实时数仓演进之路:从烟囱式架构到统一平台
1.1 淘宝闪购(饿了么)大数据架构现状
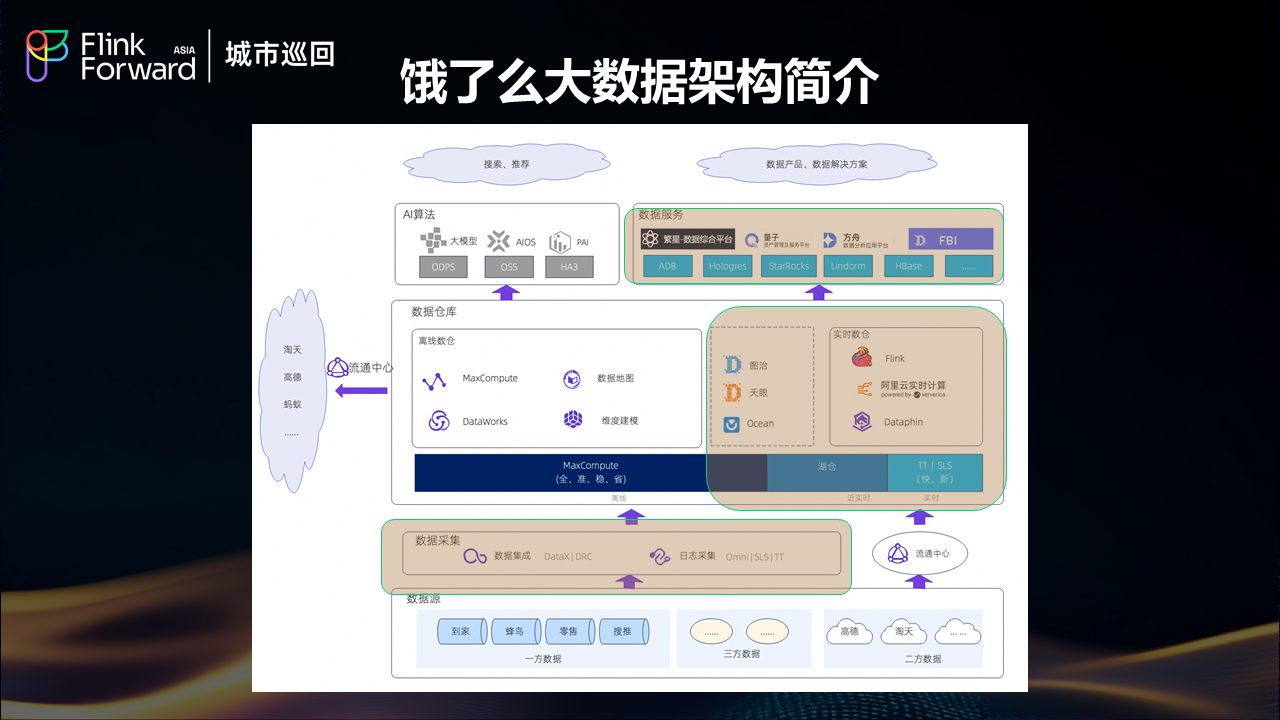
淘宝闪购(饿了么)的大数据架构经历了从分散到集中、从烟囱式到平台化的发展历程。作为服务亿万用户的本地生活平台,饿了么每天产生海量的订单、用户行为、商户运营等多维度数据,这些数据的实时处理和分析直接影响着平台的运营效率和用户体验。
1.2 实时数仓架构的三个发展阶段
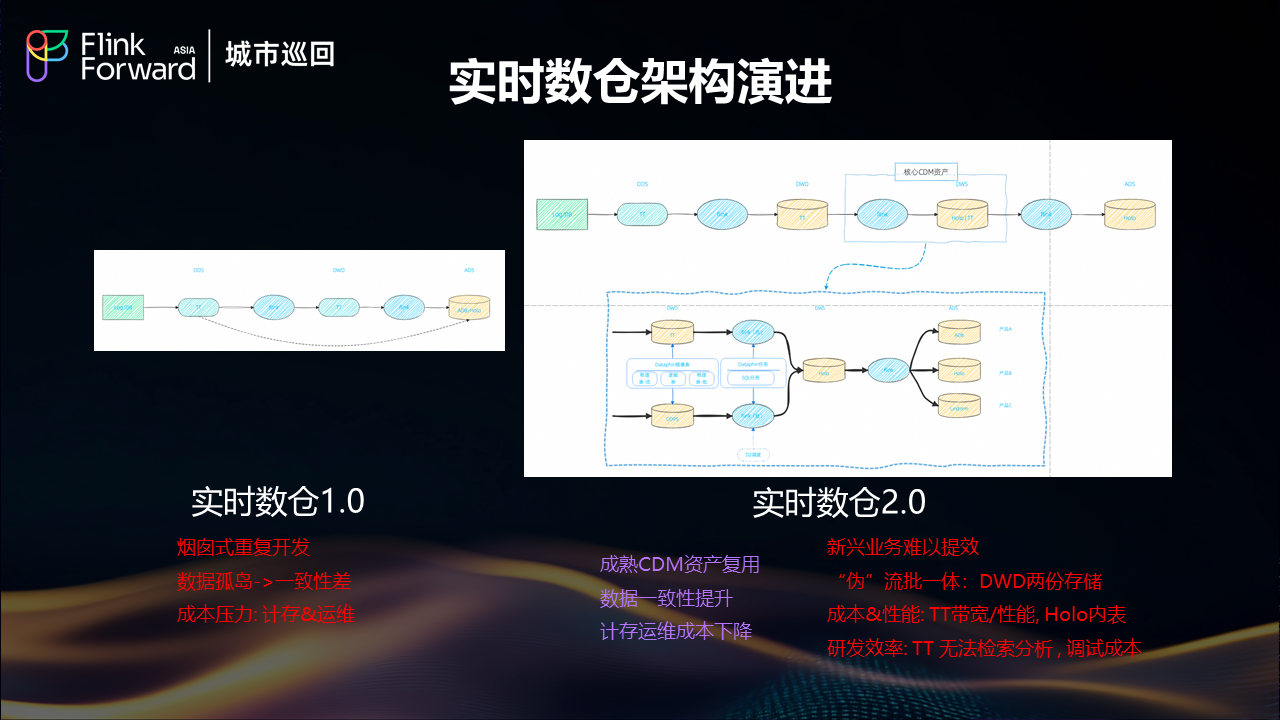
实时数仓 1.0:烟囱式重复开发时代
在早期阶段,饿了么面临着典型的烟囱式开发问题。各业务线独立构建实时处理链路,导致了严重的数据孤岛现象。由于缺乏统一的数据标准和处理规范,不同系统间数据一致性差异显著,给业务决策带来了困扰。同时,重复的基础设施建设和运维工作带来了巨大的成本压力,包括计算存储资源的重复投入和运维人力的分散投入。
实时数仓 2.0:初步整合与新挑战
为了解决 1.0 时代的问题,饿了么开始推进数据中台建设,通过成熟的 CDM 资产复用,显著提升了数据一致性,降低了计算存储和运维成本。然而,随着业务的快速发展,新的挑战开始显现。
2.0 架构虽然在一定程度上实现了数据复用,但仍然面临"伪"流批一体的问题。DWD 层需要维护两份存储,分别支持流式和批处理场景,这种重复存储不仅增加了成本,也带来了数据同步的复杂性。在成本和性能方面,TT(消息队列服务)存在带宽和性能瓶颈,而 Hologres 内表的性能优化也面临限制。研发效率方面,TT 无法支持检索分析功能,调试成本居高不下,新兴业务难以快速响应。
1.3 Lakehouse探索与技术选型
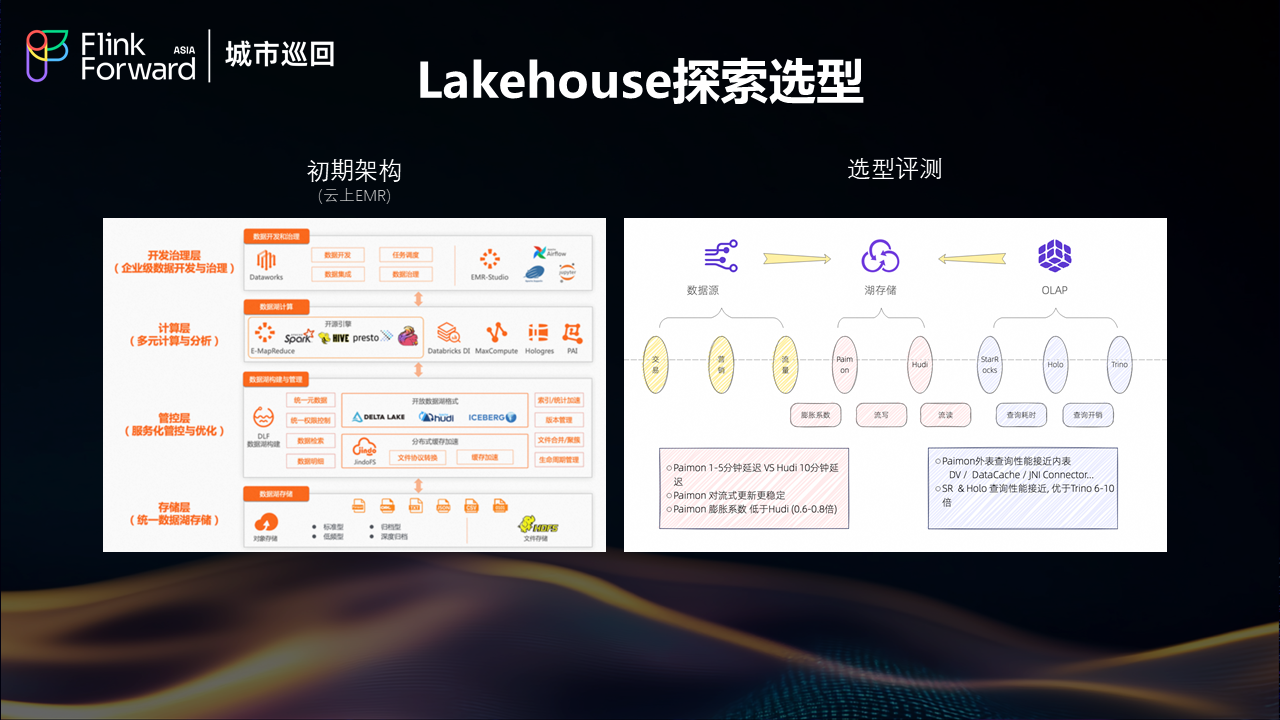
面对 2.0 架构的局限性,饿了么开始探索 Lakehouse 架构。初期基于云上 EMR 进行了大量的选型评测工作,重点对比了不同湖存储格式和 OLAP 引擎的性能表现。
关键技术选型对比
经过大约十轮的深度测试,饿了么得出了几个重要结论:
湖存储格式对比:Paimon vs Hudi
从对比测试结果来看,Paimon 在多个关键指标上显著优于 Hudi。首先是端到端延迟表现,Paimon 能够提供更低的数据处理延迟,这对于实时业务场景至关重要。在流式更新的稳定性方面,Paimon 表现出更好的一致性和可靠性。此外,在写放大控制方面,Paimon 的优化策略更加有效,能够显著降低存储系统的负载压力。
OLAP 引擎性能评估
在 OLAP 层面的测试中,StarRocks 和 Hologres 各有千秋,两者的查询性能表现接近,但都显著优于 Trino。特别值得注意的是,通过引入 Deletion Vector 和 Data Cache 等性能特性,StarRocks 和 Hologres 查询 Paimon 外表的性能能够接近内表水平,这样基本能够满足现阶段的 OLAP 查询需求。
架构兼容性挑战
明确了 Flink+Paimon+StarRocks/Hologres 这三大 lakehouse 引擎,由于我们原有的大数据架构主要做阿里弹内内部部署 与云上 EMR 的生态还是难以完美兼容,这对我们内部快速应用带来了一定障碍.所以我们亟需一套好用的研发平台。
二、Alake 平台赋能:一站式湖仓开发的关键转折
2.1 Alake项目背景与价值
幸运的是,在这个关键时刻饿了么遇到了阿里内部的 Alake 项目。Alake 是阿里巴巴内部从 Data Warehouse 向 Lakehouse 转变,并在后期逐步演进到 Data +AI 的大数据平台架构的关键载体。
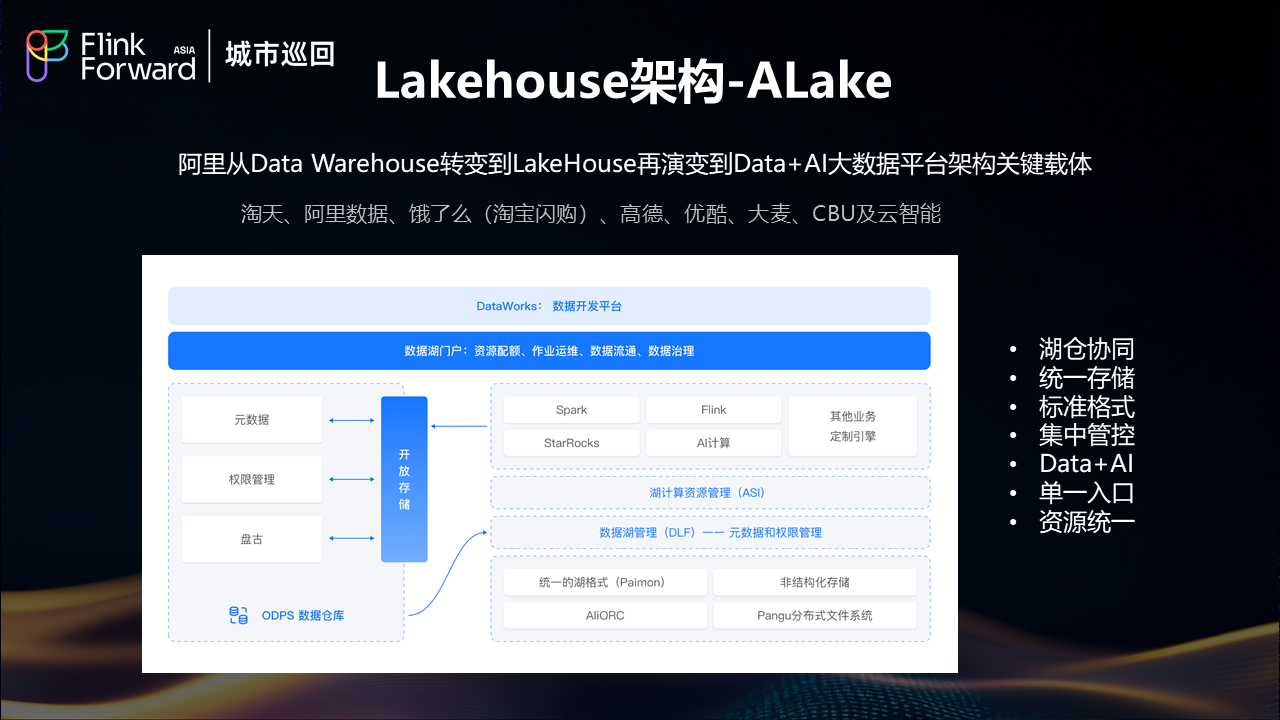
Alake 目前已在淘宝、天猫、阿里云、饿了么、高德等多个业务单元得到广泛应用,其成熟度和稳定性经过了大规模生产环境的验证。
2.2 Alake平台核心能力
一站式开发平台
Alake 为饿了么提供了基于 DataWorks 的一站式湖仓开发平台。由于饿了么此前的离线数仓也是基于 DataWorks 开发,这种技术栈的一致性使得研发团队能够快速、便捷地迁移到湖仓架构,显著降低了迁移门槛和学习成本。
湖计算资源统一管理
Alake的一个核心优势是实现了湖计算资源的统一管理。Spark、StarRocks、Flink 等所有计算相关的资源都可以在 Alake 平台上进行统一管理和调度。这种资源池化的设计支持灵活的资源调度,例如今天 Spark 使用 1000 个 CU,明天可以快速调整挪出 500 个 CU 给 Flink 使用,这种动态资源分配能力大大提升了资源利用效率。
统一湖存储格式
Alake在底层构建了统一的湖存储格式,基于Paimon和Pangu实现了无限扩展的存储能力。这种统一存储架构的最大价值在于消除了数据搬迁的需求,避免了因存储容量限制导致的数据孤岛问题。所有数据都存储在统一的湖存储中,不同计算引擎可以直接访问,实现了真正的存储与计算分离。
数据湖元数据管理(DLF)
Alake 在数据湖层面提供了优秀的 DLF(Data Lake Formation)元数据管理服务。通过 DLF,湖仓的元数据可以与原有的数据安全和权限管理系统无缝对接,同时支持与 ODPS 元数据的互通,实现了跨系统的数据流通能力。
三、湖仓架构落地实践:分钟级实时数据Pipeline
3.1 整体架构设计
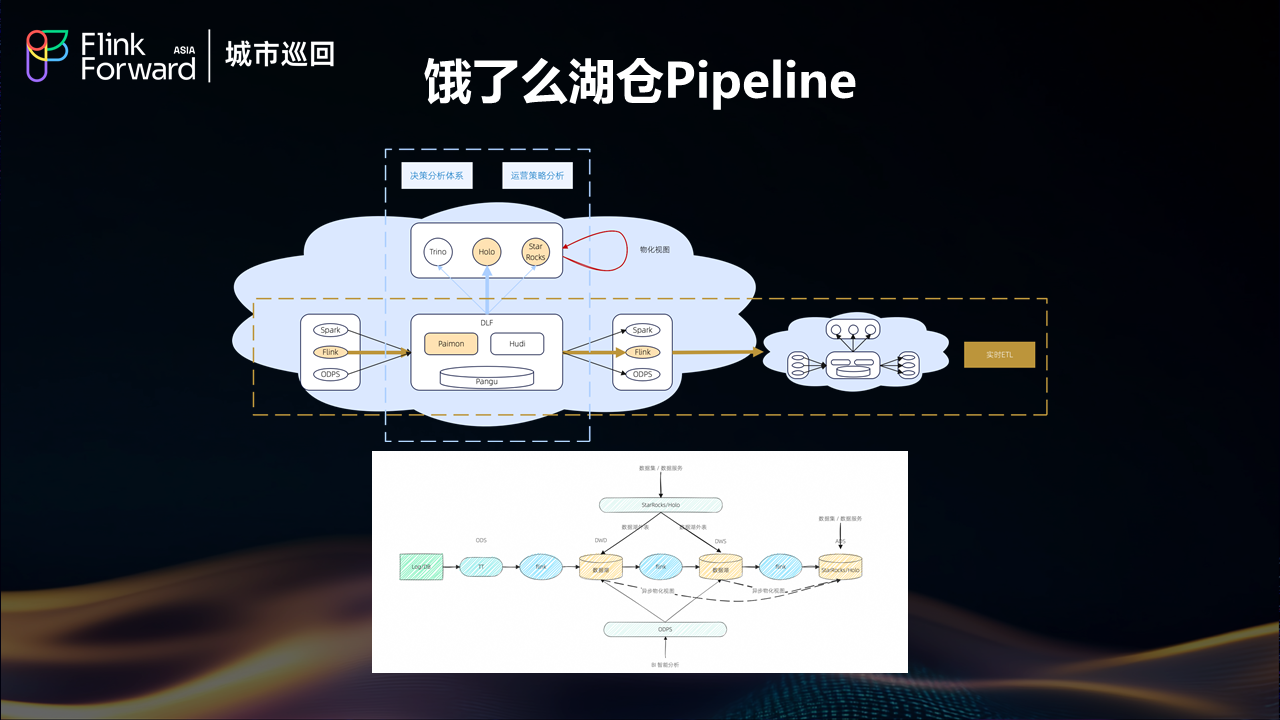
有了强大的引擎+人性化的研发平台后, 我们就在 24 年下半年就基于 ALake 结合具体业务场景开始规模化的构建了自己的 Streaming Lakehouse pipeline, 大致方案如下:
基于Paimon流读流写的ETL链路:实现分钟级的端到端流式处理能力
SR/Holo外表/MV的数据服务链路:提供低延迟的即席分析能力
Spark/ODPS的离线批处理:支持传统的BI智能分析范式
3.2 传统实时数仓vs湖仓架构对比
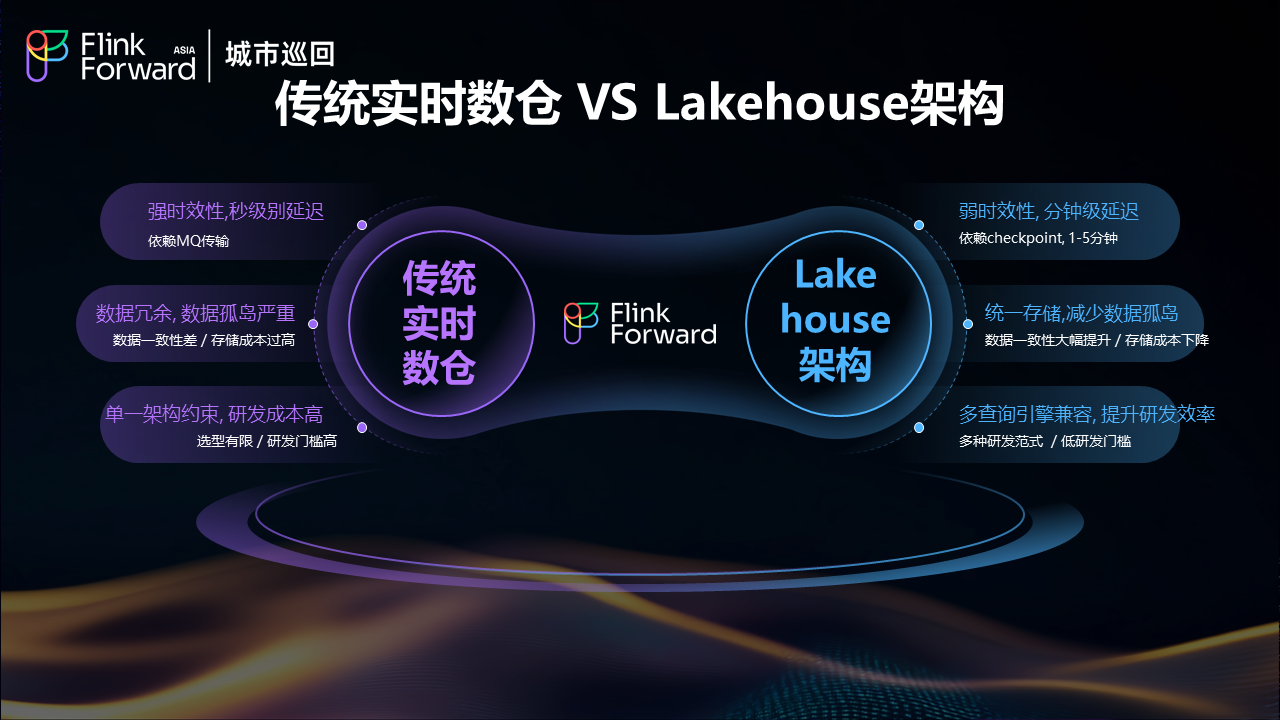
数据一致性与存储优化
传统实时数仓架构面临数据冗余和数据孤岛严重的问题,不同系统间数据一致性差,存储成本过高。湖仓架构通过统一存储显著减少了数据孤岛,数据一致性得到大幅提升,存储成本明显下降。
时效性与研发效率平衡
传统架构虽然能够提供强时效性的秒级延迟,但受限于单一架构约束,研发成本高,技术选型有限,研发门槛较高。湖仓架构虽然在时效性上有所妥协,实现分钟级延迟(依赖 checkpoint 机制,通常为1-5分钟),但通过多查询引擎兼容性,显著提升了研发效率,提供多种研发范式,大幅降低了研发门槛。
3.3 生产规模与稳定性验证
规模化运行成果
从湖仓的整体规模来看,饿了么实现了十倍以上的规模增长。目前大约有 15 万以上的 CU 在运行,包括湖仓的流处理和批处理工作负载。这种规模化的部署验证了湖仓架构的可扩展性和实用性。
大促稳定性认证
在每周一次累计十多次的大促活动过程中,湖仓的稳定性得到了充分验证和认证。这种高强度、大并发的业务场景对系统稳定性提出了极高要求,湖仓架构能够在这种压力下保持稳定运行,证明了其在生产环境中的可靠性。
技术栈多样化发展
对于数仓团队而言,整体的数据链路现在实现了非常多样化的发展。团队不再局限于以前单一的离线链路或 Flink 流处理链路,现在拥有多种技术选型可供使用,这种技术栈的丰富性为不同业务场景提供了更好的适配能力。
四、典型应用场景:淘宝闪购业务实践
4.1 业务背景与挑战
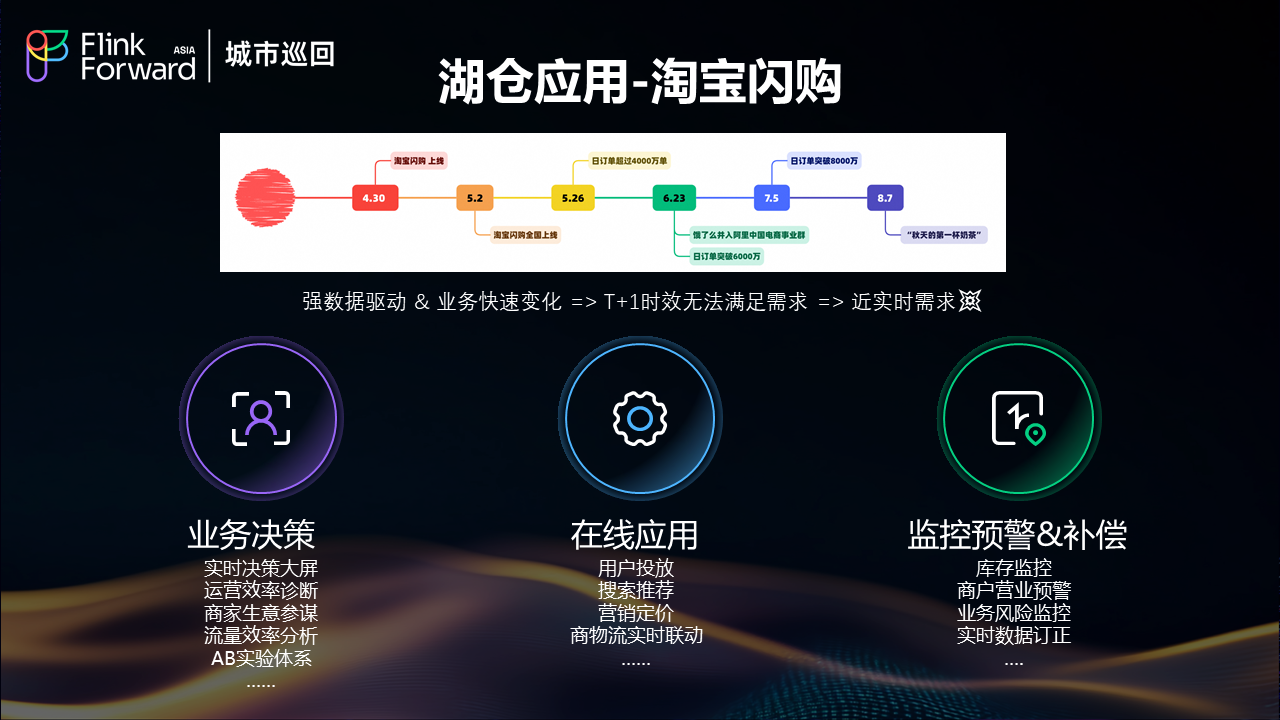
淘宝闪购作为饿了么湖仓架构的重要应用场景,具有强数据驱动特征和业务快速变化的特点。传统的T+1时效已无法满足业务需求,近实时的数据处理能力成为业务成功的关键因素。
在线应用需求
在线应用场景包括用户投放、搜索推荐、营销定价、商物流实时联动等多个维度。这些场景都需要基于最新的数据状态进行决策,任何延迟都可能影响用户体验和业务效果。
业务决策支持
业务决策层面需要实时决策大屏、运营效率诊断、商家生意参谋、流量效率分析、AB实验体系等多种数据产品。这些应用要求数据不仅要实时,还要准确、一致。
监控预警体系
监控预警方面涵盖了库存监控、商户营业预警、业务风险监控、实时数据订正等关键场景。这些场景对数据的时效性和准确性都有极高要求。
4.2 解决方案设计思路
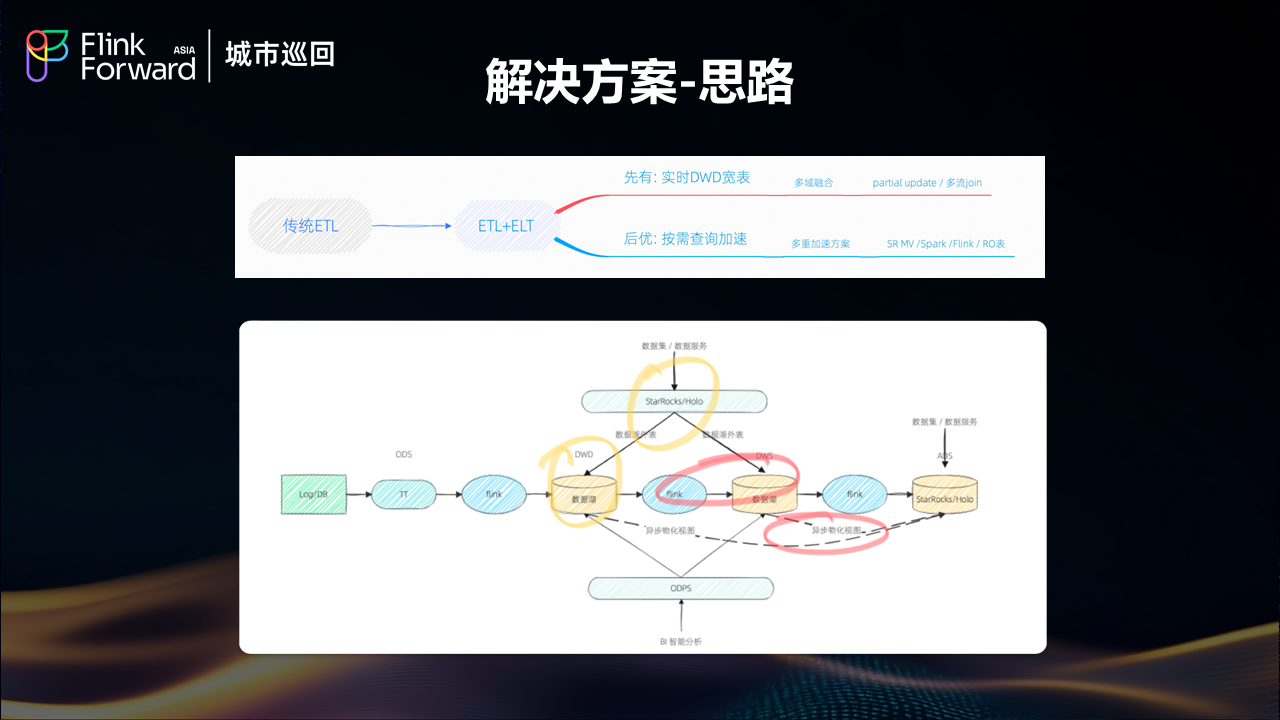
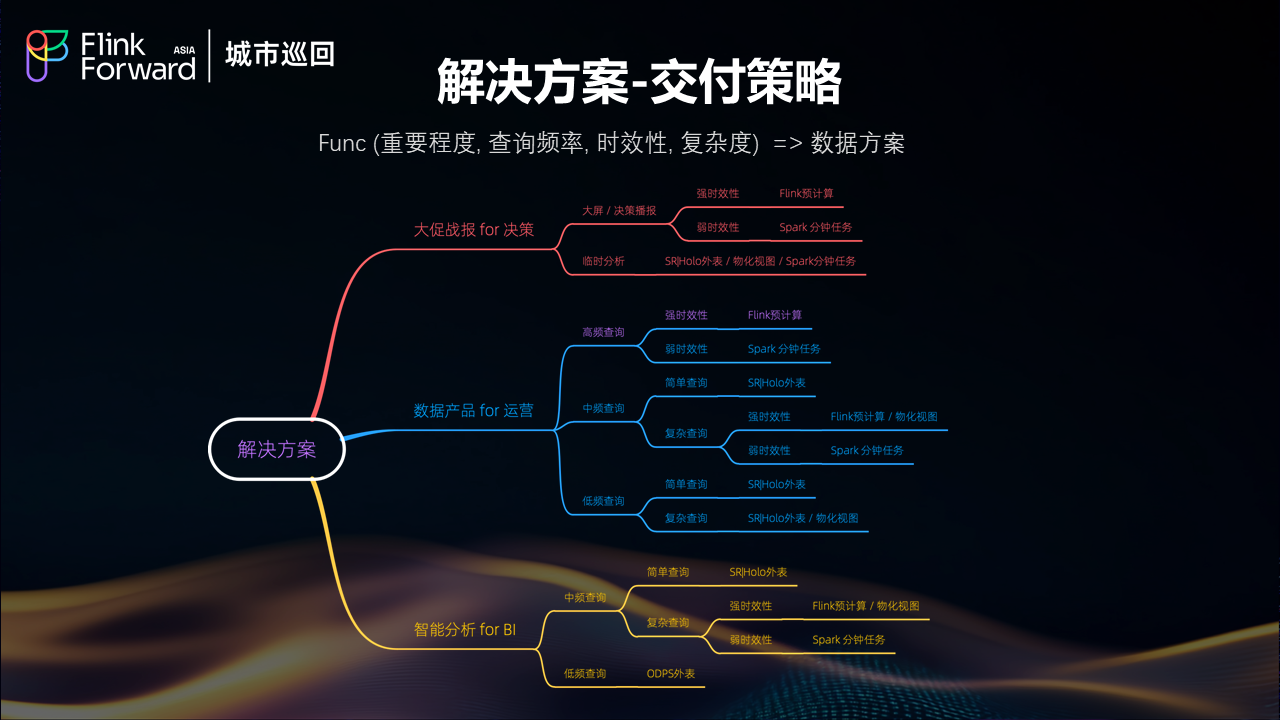
面对多样化的业务需求,饿了么采用了基于功能重要程度、查询频率、时效性要求、复杂度等多维度评估的交付策略。通过 Func(重要程度, 查询频率, 时效性, 复杂度)函数来确定最适合的数据解决方案。
4.3 典型案例分析
UV统计场景优化
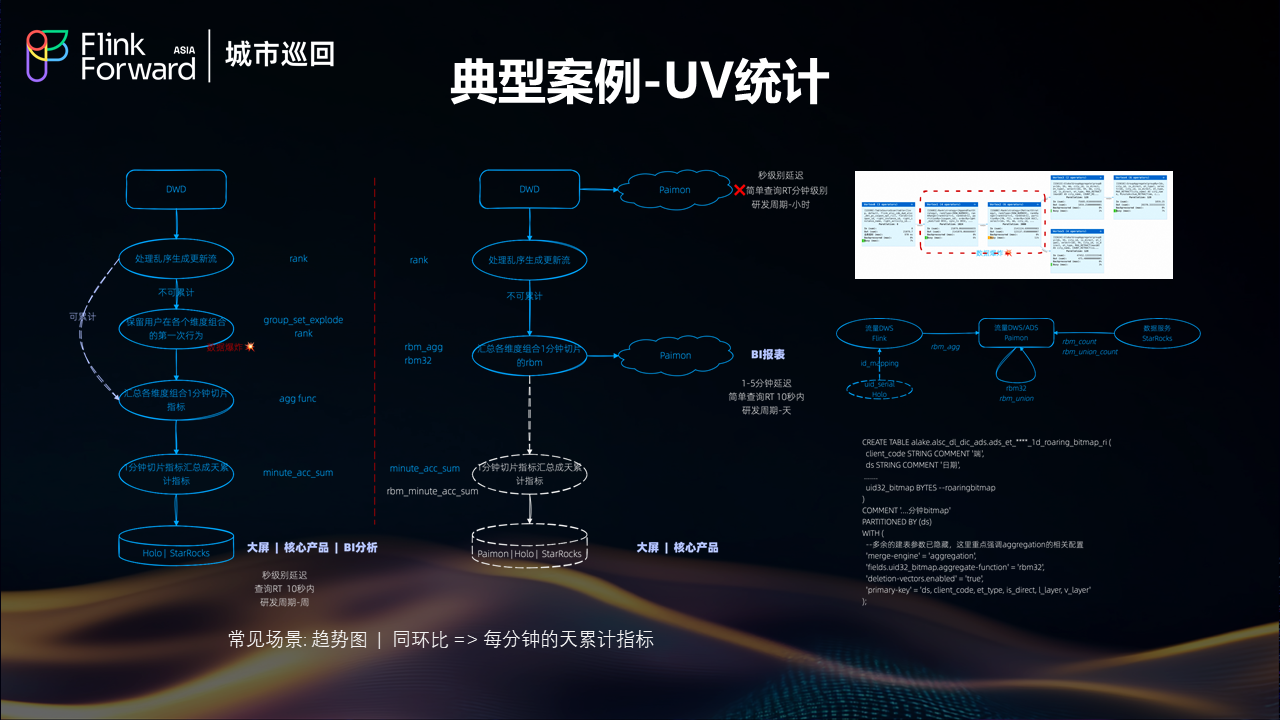
UV 统计是一个典型的实时分析场景,常见于趋势图和同环比分析。挑战在于需要计算每分钟的天累计指标,这要求系统既要处理增量数据,又要维护准确的累计状态。
湖仓架构通过 Flink 的状态管理能力和 Paimon 的增量更新机制,实现了高效的 UV 去重和累计计算,既保证了计算的准确性,又满足了分钟级的时效性要求。
近实时AB实验
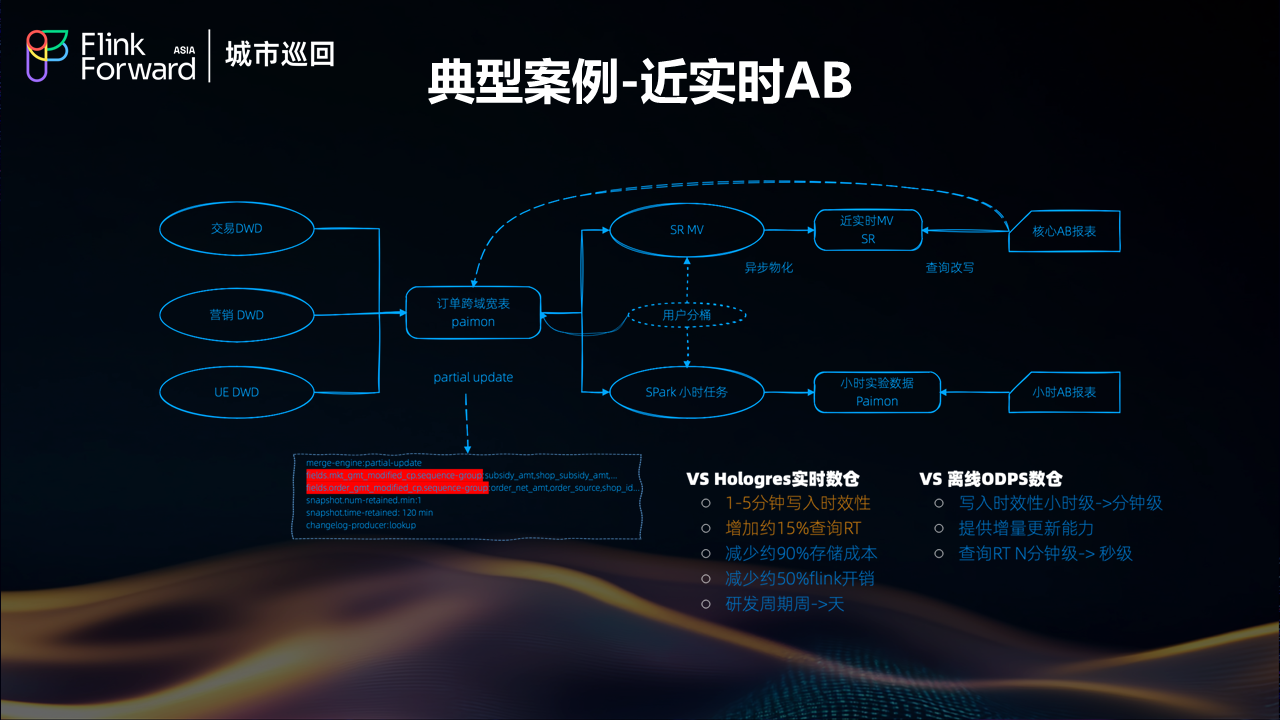
AB 实验系统对数据的实时性和准确性都有极高要求。传统架构下,实验数据的延迟可能影响实验效果的及时评估。湖仓架构通过实时数据流和统一存储,实现了 AB 实验数据的近实时处理,使得实验效果能够快速反馈,大大提升了产品迭代效率。
4.4 应用实践小结
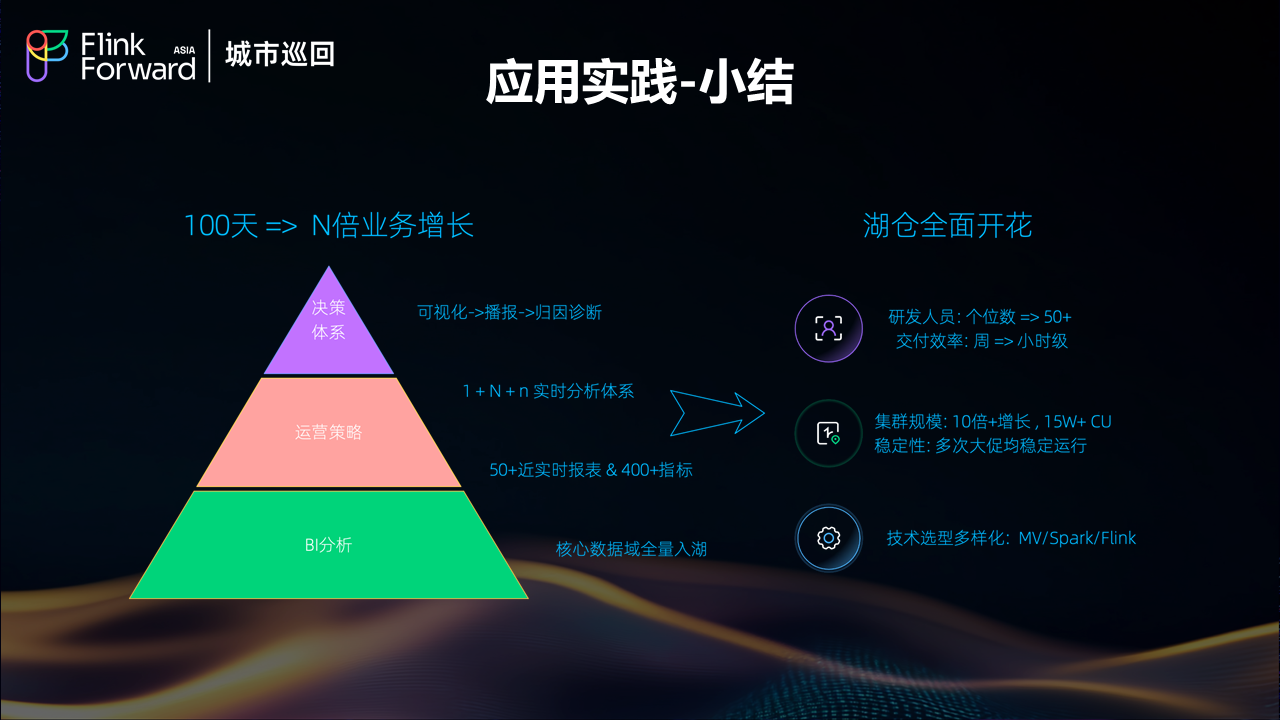
通过淘宝闪购等业务场景的实践验证,湖仓架构在支持多样化业务需求方面表现出色。无论是在线应用的实时响应,还是业务决策的数据支持,或是监控预警的及时性,都得到了有效保障。
五、未来规划与技术展望
5.1 核心技术发展方向
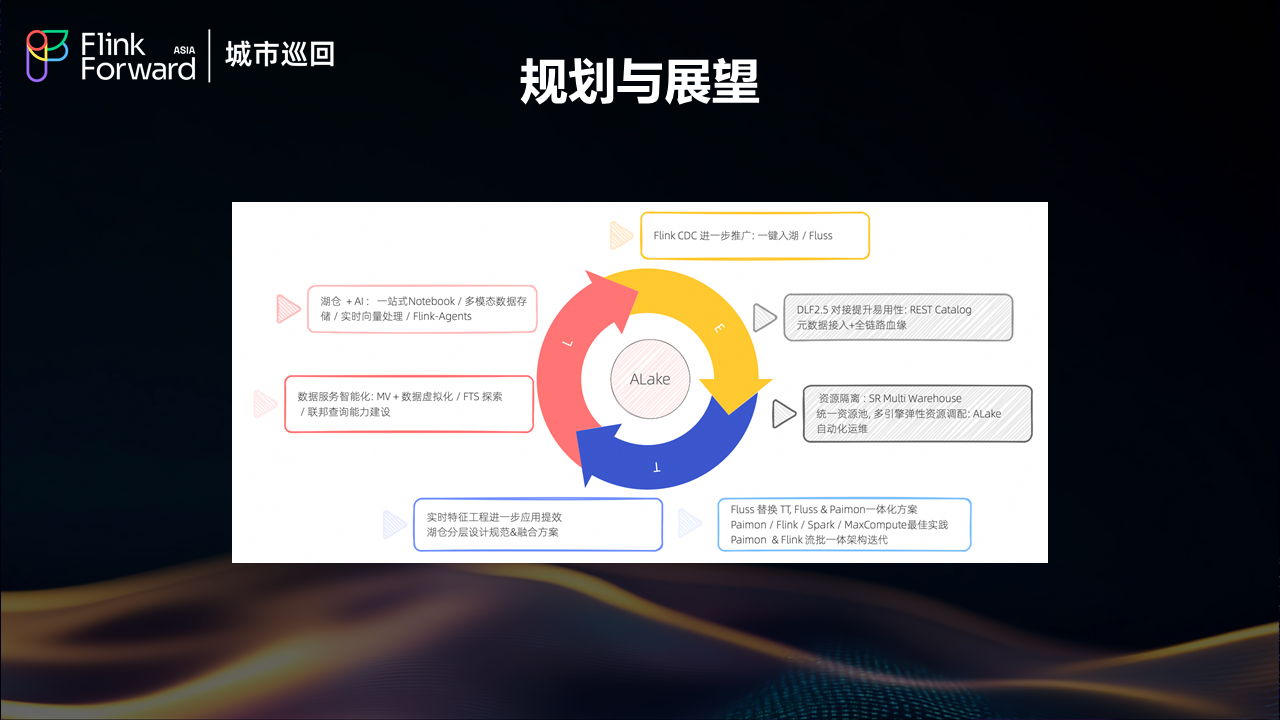
饿了么的湖仓架构未来规划主要聚焦于三个核心技术链路和基础架构的持续优化。在众多可能的发展方向中,团队最关心和最想推进的重点项目是引入 Fluss 技术。
Fluss 技术引入计划
引入 Fluss 的主要动机有两个方面:首先是希望能够替换现有的 TT 方案;其次,Fluss 已经为团队勾勒了一个美好的技术蓝图。Fluss 与 Paimon 的结合能够实现热数据与温数据的一体化融合,这种融合将使得之前的"伪"流批一体方案升级为"真流批一体"方案,这是团队非常期待落地探索的技术方向。
湖仓与AI能力融合
湖仓与 AI 的结合一直是团队想要探索的重要方向。目前在 Alake 平台上已经有一些简单的 notebook 环境,可以支持基础的数据科学和简单的 AI 能力。但是更深层次的AI能力整合仍需要进一步发掘,特别是需要找到更多的落地场景来验证和完善这种结合的价值。
5.2 未来愿景与目标
饿了么对湖仓架构未来发展提出了四个重要愿景:

真正的流批一体
实现真正的流批一体架构,让数据流动像血液一样自然,消除批处理和流处理之间的界限。这不仅是技术架构的统一,更是数据处理范式的根本性变革。
智能化数据服务
构建智能化的数据服务体系,让数据工程师从"数据搬运工"转变为"智囊团"。通过自动化和智能化的数据处理流程,释放工程师的创造力,专注于更高价值的数据洞察和业务创新。
湖仓AI深度融合
推动湖仓与AI的深度融合,让数据不仅被分析,更能主动"思考"和"预测"。这种融合将为业务决策提供更加智能的支持,实现从被动响应到主动预判的转变。
开放生态体系
拥抱更加开放的生态体系,让不同的技术能够和谐共存,发挥各自优势。避免技术栈的单一化,通过开放的架构设计支持多样化的业务需求。
5.3 基于 Fluss & Paimon 的流批一体畅想
在具体的技术实现路径上,饿了么特别关注基于 Fluss 和 Paimon 的流批一体解决方案。这种组合有望实现真正意义上的流批统一,为未来的数据架构发展奠定坚实基础。
结论
饿了么基于 Flink 和 Paimon 的 Lakehouse 生产实践,不仅是一次成功的技术架构升级,更是企业数字化转型过程中的重要里程碑。从实时数仓的演进历程,到湖仓架构的落地实践,再到未来技术发展的前瞻规划,这个完整的实践案例为行业提供了宝贵的参考价值。
核心成果总结
通过湖仓架构的实施,饿了么实现了多个重要突破:数据一致性得到大幅提升,存储成本显著下降,研发效率明显改善,系统稳定性经受了大促考验。特别是 15 万以上 CU 规模的稳定运行,证明了湖仓架构在大规模生产环境中的可行性。
技术选型经验
在技术选型方面,Paimon 相对于 Hudi 在端到端延迟、流式更新稳定性、写放大控制等关键指标上的优势,为湖仓架构的成功奠定了基础。同时,Alake 平台的一站式开发环境和统一资源管理能力,大大降低了迁移成本和运维复杂度。
业务价值验证
通过淘宝闪购等典型业务场景的应用验证,湖仓架构在支持实时决策、在线应用、监控预警等多样化需求方面表现出色,真正实现了技术服务业务的价值转化。
未来发展方向
面向未来,饿了么的湖仓架构将继续朝着真正的流批一体、智能化数据服务、湖仓AI深度融合、开放生态体系等方向发展。特别是Fluss技术的引入和湖仓AI能力的深度融合,将为数据架构的下一轮创新提供强劲动力。
这个实践案例表明,湖仓架构不仅是技术趋势,更是企业数据能力提升的重要路径。随着技术的不断成熟和应用场景的日益丰富,湖仓架构必将在更多企业的数字化转型中发挥关键作用。
关于阿里云DLF
阿里云数据湖构建(Data Lake Formation,简称 DLF)是一款全托管的统一元数据和数据存储及管理平台,为淘宝闪购(饿了么)提供元数据管理、权限管理、存储管理、存储优化、版本管理、冷热分层等功能。DLF 基于 Lakehouse 湖仓一体架构,以 Paimon 为核心 Lakehouse Format,兼容 Iceberg,构建统一多模态湖表存储服务,支持结构化、半结构化、非结构化等多模态数据存储、管理、优化,通过智能算法和存储结构优化大幅提升数据读写及存储效率,如果大家对这个产品感兴趣,也欢迎到阿里云官网搜索新版 DLF 进行体验。
关于演讲者
王沛斌 现任饿了么大数据架构师,专注于大数据平台架构设计和湖仓技术实践。在实时数仓架构演进、流批一体化技术、湖仓生产落地等领域具有丰富的实战经验。主导了饿了么从传统实时数仓向现代湖仓架构的完整转型,在大规模生产环境下验证了湖仓技术的可行性和价值。













)





