当自然语言处理领域因Transformer而焕发新生时,计算机视觉却长期困于卷积神经网络的架构桎梏。直到ViT(Vision Transformer)的横空出世,才真正打破了视觉与语言之间的壁垒。它不仅是技术的革新,更是范式革命的开始:图像不再是像素的矩阵,而是视觉词汇的序列。随后,MAE以掩码重建的巧思将自监督学习推向新高度,而Swin Transformer则以分层结构与滑动窗口的智慧,让Transformer在视觉任务中既高效又强大。这篇笔记将带你深入这三篇里程碑论文的核心,揭示它们如何共同构建了一个通向通用智能的多模态未来。
本笔记系统精读了三篇计算机视觉领域的革命性论文:ViT、MAE和Swin Transformer。它们分别解决了Transformer在视觉任务中的三大核心挑战:架构适配、自监督预训练和计算效率与层次建模。
-
ViT(Vision Transformer) 首次将纯Transformer应用于图像分类,通过将图像分割为块(Patch)序列并直接输入Encoder,证明了在大规模数据上Transformer可超越CNN。其关键突破在于摒弃了卷积的归纳偏置(局部性、平移等变性),仅依靠注意力机制实现全局建模,为多模态统一奠定了基础。
-
MAE(Masked Autoencoder) 借鉴BERT的掩码语言模型思想,但针对视觉信号的高冗余度,提出高比例掩码(如75%)和不对称编解码架构。编码器仅处理可见块,轻量解码器重建像素,显著降低了预训练成本并学习了高质量表征,证明了自监督在视觉领域的巨大潜力。
-
Swin Transformer 通过分层结构(模拟CNN的多尺度特征)和移动窗口自注意力(将计算复杂度从平方降为线性),解决了ViT在高分辨率图像(如检测、分割)上的计算瓶颈。其滑动窗口机制既保留了全局建模能力,又实现了高效计算,成为通用视觉主干网络的标杆。
这三项工作标志着视觉领域已从CNN时代迈入Transformer时代,其核心思想——序列化建模、自监督学习、层次化设计——不仅推动了视觉技术的发展,更为视觉与语言的统一建模提供了关键路径。未来的多模态智能系统,必将构建于此基础之上。
目录
1. ViT - CV版的Transformer
1.1 摘要 + 导言 + 结论
1.2 架构
1.3 Experiments 实验结果
2. MAE - CV版的BERT
2.1 摘要 + 导言
2.2 Approach 方法
操作流程
2.3 Experiments 实验结果
3. Swin Transformer ViT结合CNN(分层结构+滑动窗口)
3.1 摘要 + 导言 + 结论
3.2 Method 方法
3.2.1 Overall Architecture
3.2.2 Shifted Window based Self-Attention 滑动窗口自注意力
3.3 Experiments 实验结果
1. ViT - CV版的Transformer
ViT论文逐段精读【论文精读】
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
将图像视为由“单词”(patches)组成的“句子”。具体做法是把一张图像分割成固定大小的图像块(例如16x16像素),每个图像块就类似于自然语言处理(NLP)中的一个单词 token。然后将这些图像块组成的序列直接输入标准的Transformer架构(具体是Transformer Encoder)进行图像分类。
1.1 摘要 + 导言 + 结论
Transformer、注意力机制在NLP大火,但在CV领域 注意力机制只是用于CNN架构中的组件改变,本文将纯Transformer应用于图像块序列。在基准数据集(ImageNet、CIFAR-100、VTAB等)表现很好 并训练计算资源显著减少。
一个224*224的图片 5w个像素点 如果把每个像素点拉直作为一个独立单元,算注意力是 n^2复杂度,就太高了。可以把16*16的图像作为 一个单元;一共14*14 = 196个单元。
ViT 是很好的挖坑之作 未来很多用Transformer做CV。Transformer 在 NLP和CV上都适用 为后来多模态 打通CV和NLP。
1.2 架构
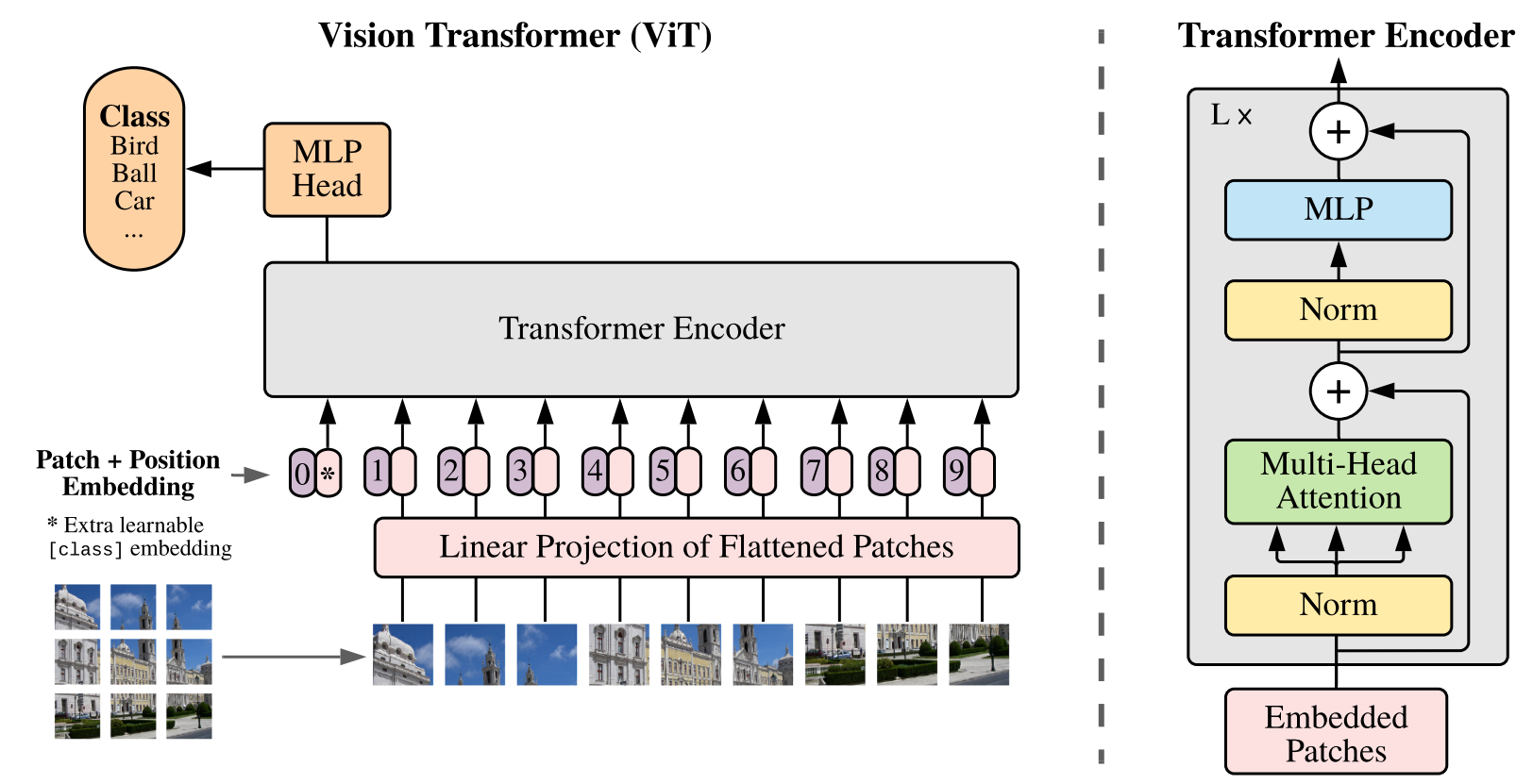
Patch:单个图片 224*224*3 分成 14*14=196个 16*16*3=768;
embedding 乘上一个 768*d 的矩阵;(196*768) * (768*d) -> 196*d
在最开头加上一个分类字符 [cls](similar to BERT's [class] token) 即变成197*d
因为和别的位置两两自注意力,这个[cls]实则包含了其他位置的所有信息;把这个送个MLP分类。
CNN inductive biases 归纳偏置:
- 局部性:假设图像中有意义的特征(如边缘、纹理、角落)通常由相邻的像素组成,而非相距甚远的像素。因此,卷积核只关注一个小窗口(如3x3)内的局部信息。
- 平移等变性:意味着一个物体在图像中移动后,其对应的特征也会在特征图中发生同样的移动。卷积操作在任何位置都是共享参数的,它不关心特征具体在图像的哪个位置。
- 空间层次结构:复杂的、全局的特征(如一张脸)是由简单的、局部的特征(如眼睛、鼻子、嘴巴)逐步组合而成的。通过池化层(Pooling Layers) 和逐步增加感受野的卷积层堆叠来实现。
而ViT 没有使用归纳偏置 而是:
-
Patch Extraction:将一张图像简单地切割成一系列固定大小的图像块(Patches),然后将每个块展平成一个向量。这可以看作是模型唯一需要做的关于“图像是2D网格”的假设。
-
学习添加位置编码:由于Transformer本身是置换不变(Permutation-Invariant)的(即不关心输入序列的顺序),ViT需要显式地添加位置编码(Position Embedding) 来告诉模型“每个图像块在原始图像中的位置信息”。这个位置关系不是硬编码的规律,而是需要模型从数据中学习的参数。
-
送入标准Transformer编码器:之后的过程就和处理一堆单词没有任何区别了。自注意力机制是全局的——从第一层开始,每个块(token)就可以和图像中任何位置的块进行交互和集成信息。它没有“局部性”的假设,也没有通过卷积来强制实现“平移等变性”。
1.3 Experiments 实验结果
不同大小的ViT 和 BiT-L(ResNet152x4)比,训练时间大大缩短,并且最大的ViT 结果全面超过了。
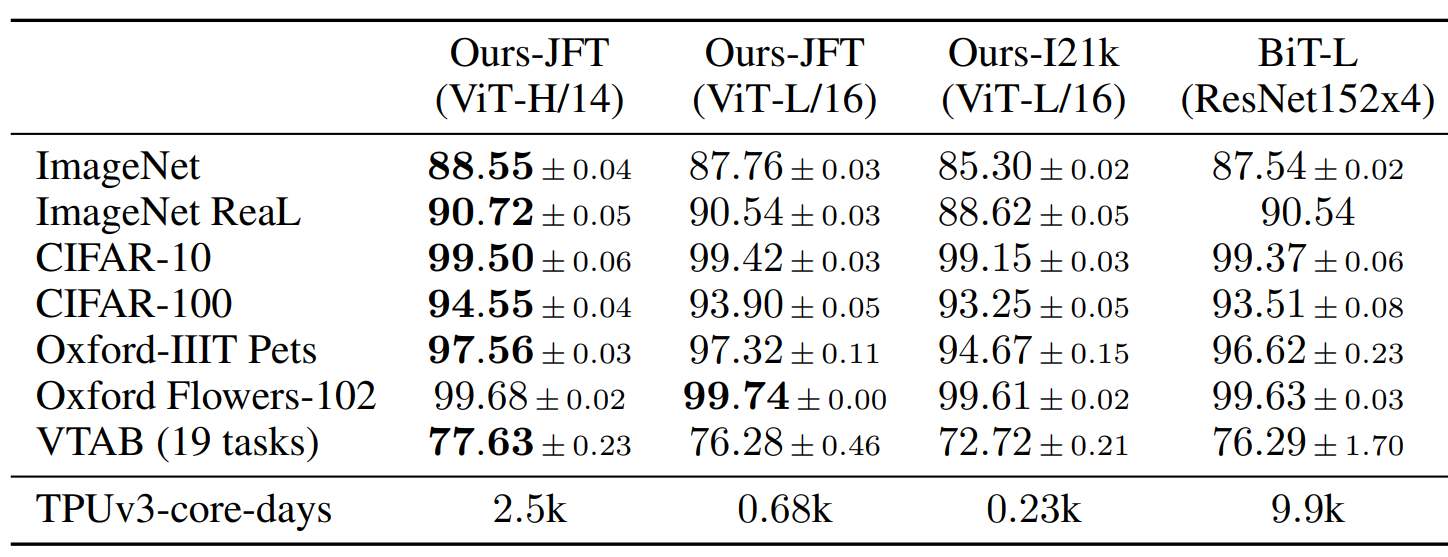
在多大的训练集上效果比较好呢? 灰色的线 BiT代表不同大小的残差神经网络(灰色部分可看做对比的ReSNet的水平)。
不同大小的彩色圆点 代表不同大小的ViT。 小规模比不上残差神经网络,大规模上效果好。
验证注意力机制的有效性:

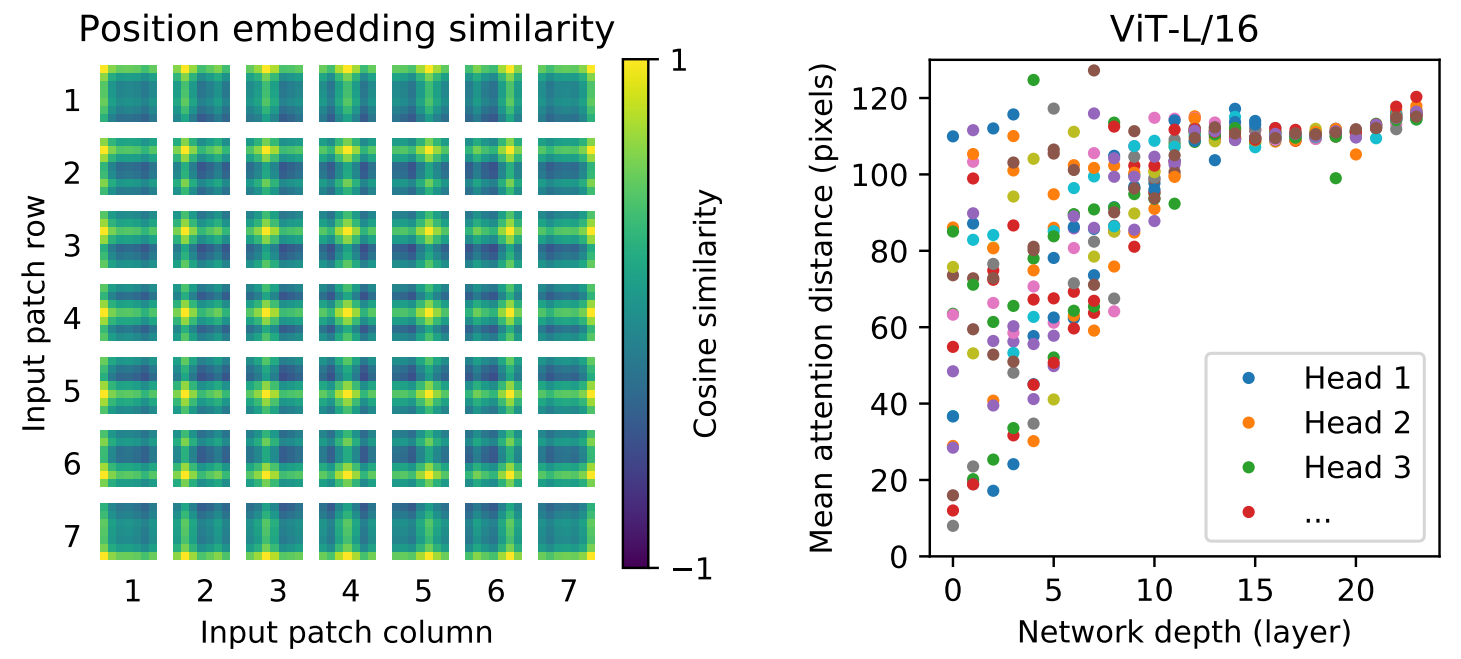
左图:标注出Attention 对应的位置
中图:位置编码 黄点代表相似度高的 可以看出已经学到对应的位置了。
右图:证明Attention 在最开始 depth比较浅的时候 就可以有比较高的pixels 注意到全局(CNN最初只能注意局部)
2. MAE - CV版的BERT
MAE 论文逐段精读【论文精读】
Masked Autoencoders Are Scalable Vision Learners
2.1 摘要 + 导言
掩码自编码器(MAE)是可扩展的计算机视觉自监督学习器。我们的MAE方法非常简单:随机掩码输入图像块并重建缺失像素。该方法基于两个核心设计:其一,我们设计了非对称的编码器-解码器架构,其中编码器仅处理可见图像块(不含掩码标记),同时配备轻量级解码器,根据潜在表征和掩码标记重建原始图像;其二,我们发现对输入图像实施高比例掩码(如75%)能产生具有挑战性且意义丰富的自监督任务,在提升精度的同时让编码器仅处理少量图像块(如25%),使总体预训练时间减少3倍以上并降低内存消耗,从而轻松将MAE扩展至大型模型。这两种设计的结合使我们能够高效训练大规模模型。
标记数据稀缺 -> 自监督;自编码方法在视觉领域的进展仍落后于NLP,痛点:
(i)ViT 为 CV补上了架构的鸿沟([cls] 嵌入 这些)
(ii)信息密度差异:语言是人类产生的高度语义化和信息密集的信号。当训练模型仅预测句子中少量缺失词时,该任务就能引发复杂的语言理解。相反,图像是具有强烈空间冗余的自然信号——例如,无需对部件、物体和场景进行高层理解,仅凭相邻图像块即可重建缺失区域。为克服这种差异并促进学习有用特征,我们证明一种简单策略在计算机视觉中非常有效:对随机图像块实施极高比例的掩码。该策略大幅降低冗余度,创建了需要超越低级图像统计的整体理解能力的挑战性自监督任务。(图像冗余多 所以要相对语言 多掩码)
(iii)解码器作用差异:将潜在表征映射回输入的自编码器解码器,在文本与图像重建中扮演不同角色。在视觉领域,解码器重建像素,因此其输出语义级别低于常见识别任务。这与语言领域形成鲜明对比——解码器预测的缺失词包含丰富语义信息。虽然BERT的解码器可以非常简单(如MLP),但我们发现对于图像而言,解码器设计对决定学习到的潜在表征的语义水平起着关键作用。(图像解码器需要比语言的更复杂)
例子:左为masked;中为MAE复原的;右为图像本来的

2.2 Approach 方法
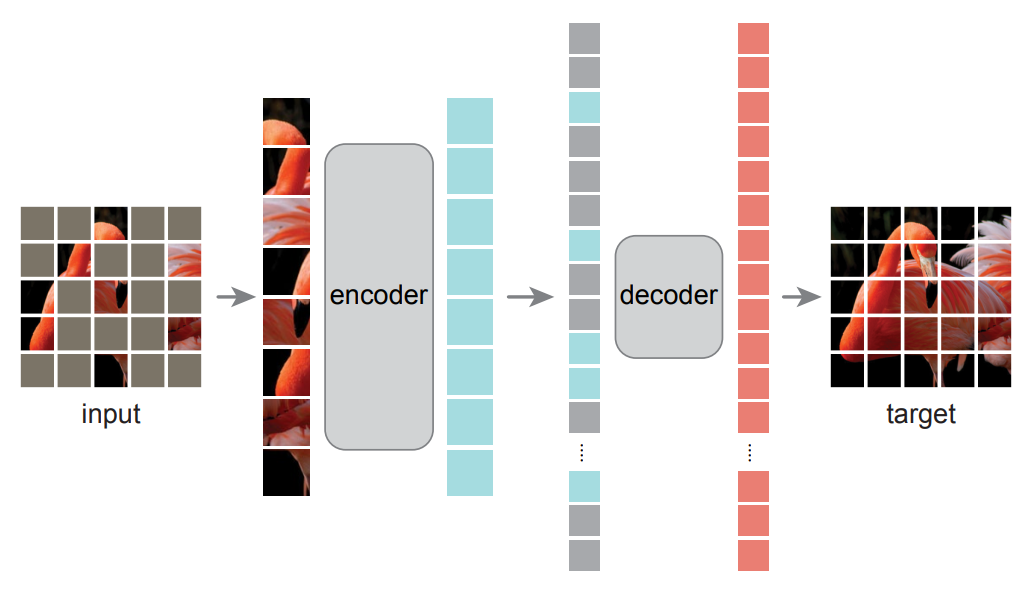
掩码:挑一个小子集作为基础 其他都掩码掉 (高度稀疏的输入 -> 高效编码器)
编码器:对未掩码的小部分块 进入类似ViT的结构;
解码器(仅用于预训练)可以看到未被掩码的,也可以看到masked的(用一个 共享的 可学习的向量表示)
损失函数:计算像素空间中原图与重建图像在掩码区域上的均方误差(MSE)
对每个图像块归一化后 训练效果更好。
操作流程
1. 线性投影添加位置编码
2. 随机打乱,按比例移除 列表后半部分,前部分给编码器
3. 编码后,掩码列表补全到列表后方,并对完整列表进行逆乱序操作(把2 随机打乱 变换回去)再进行解码
2.3 Experiments 实验结果
ViT-Large 原始与加正则化;baseline MAE
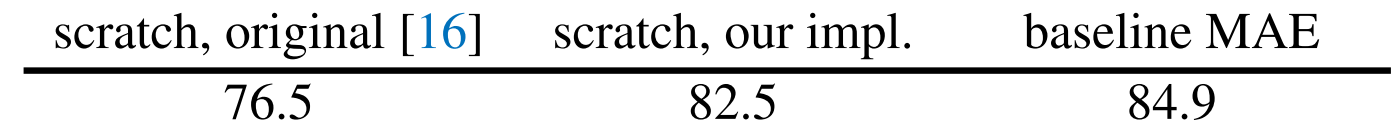
encoder、decoder深度 mask的比例和采样方式、重建目标、数据增强的一些参数比较。
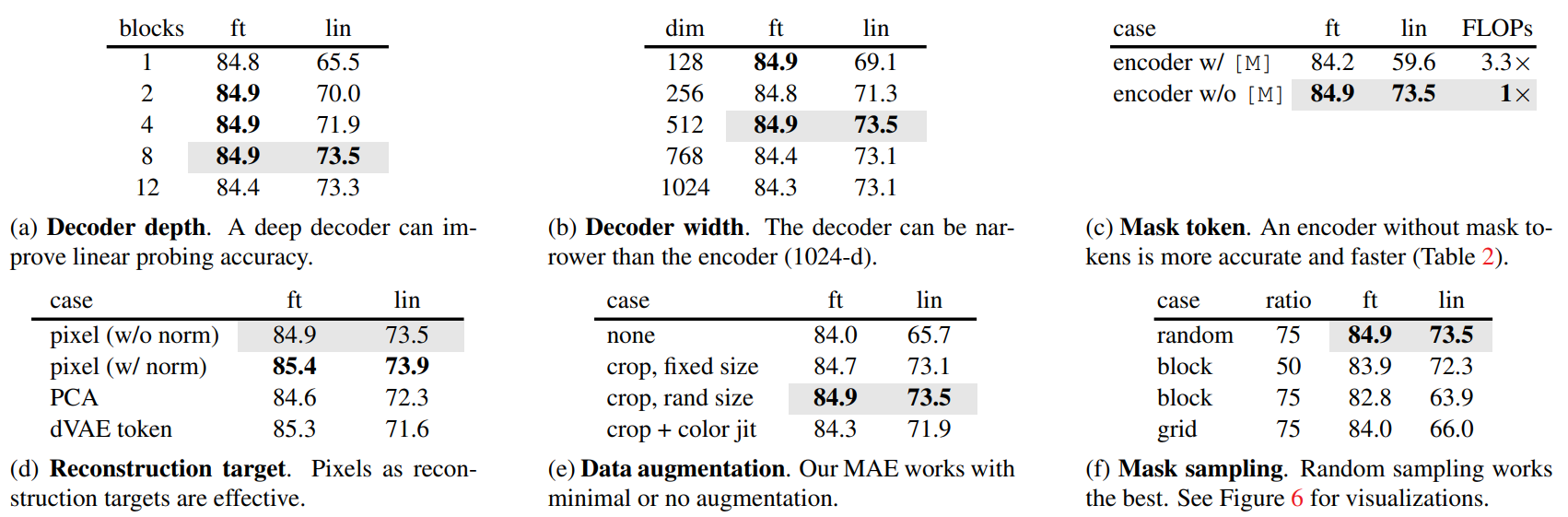
很好的性质 轮数越多效果越好
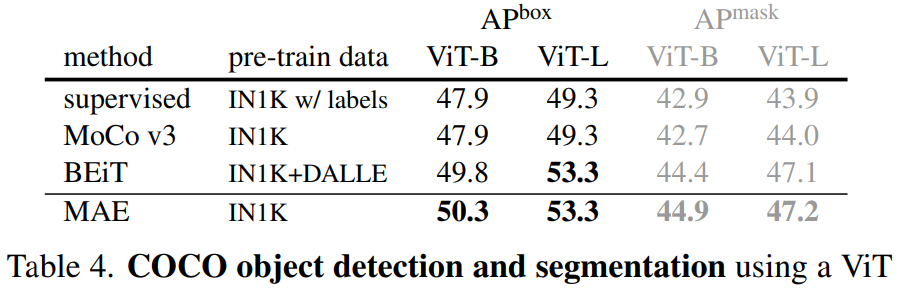
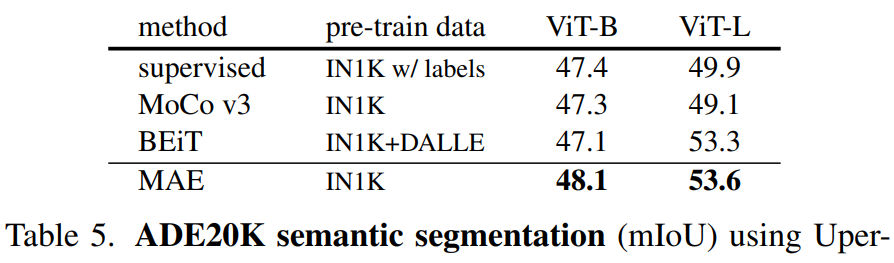
迁移学习 在别的CV任务上的能力:
目标检测COCO 语义分割ADE20K
3. Swin Transformer ViT结合CNN(分层结构+滑动窗口)
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer论文精读【论文精读】
3.1 摘要 + 导言 + 结论
目标提出 Swin Transformer 作为 general-purpose backbone for computer vision 计算机视觉的通用主干网络
NLP中的Transformer用于视觉领域存在两大难题:
-
尺度变化大:图像中的物体(视觉实体)大小可以千差万别(如一张图里既有巨大的天空又有微小的飞鸟)。
-
分辨率过高:图像由大量像素组成,而文本中的单词数量相对少得多。Transformer的自注意力机制计算复杂度是序列长度的平方,直接处理图像像素会导致计算量无法承受。
我们通过两个关键创新来解决上述挑战:分层结构 和 移动窗口。
移动窗口 (Shifted Windows):
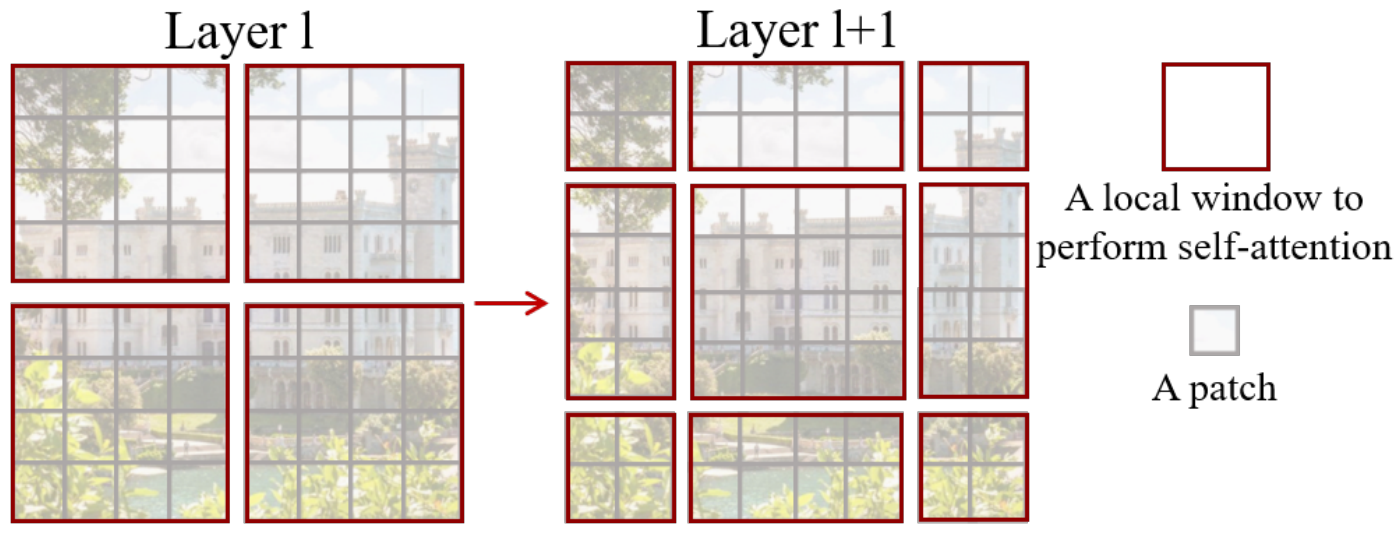
-
效率: 将自注意力计算限制在不重叠的局部窗口内。例如,将图像分成许多小块,只计算每个小块内部像素之间的关系。这极大地降低了计算复杂度。
-
连接性: 移动窗口的机制使得在下一层中,窗口的边界会发生偏移,从而让不同窗口之间的像素能够进行交互cross-window connection,获取全局信息。如果不平移的话 一个patch只能看到内部而看不到全局,上例每次往右下方平移两格。
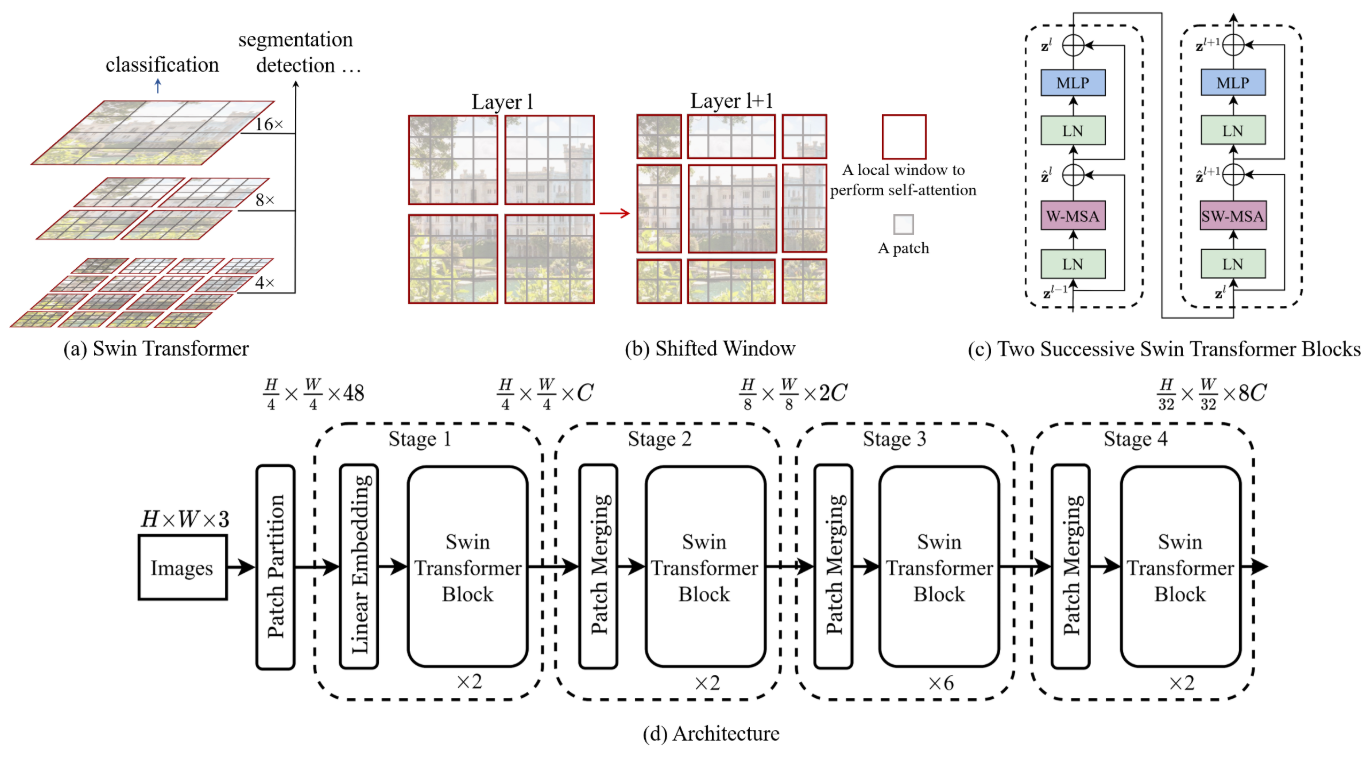
分层结构 (Hierarchical Architecture):
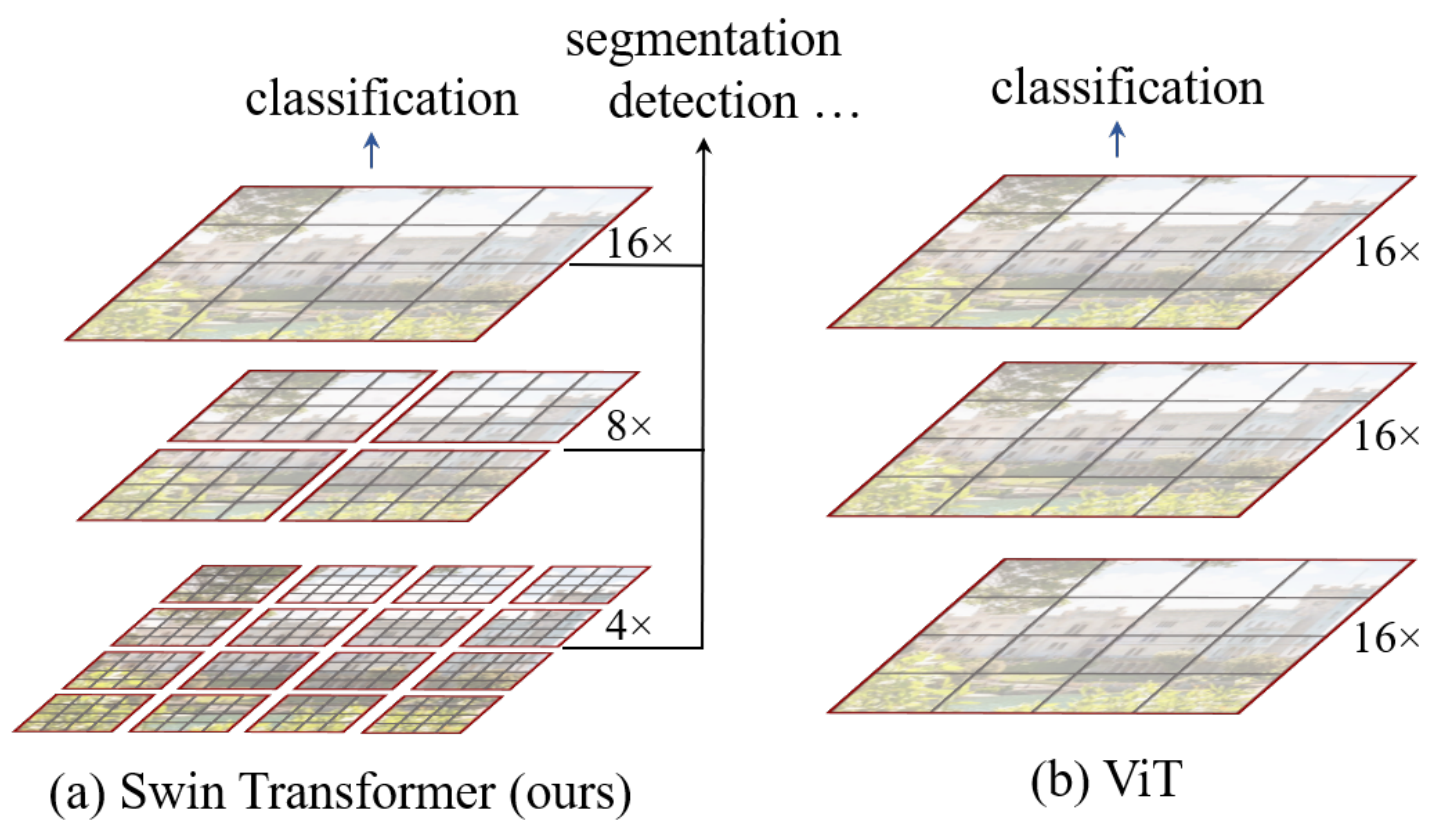
-
多尺度建模: 像CNN一样,随着网络加深,逐渐合并merge patches(起到CNN中pooling的作用),形成特征图(如
16x16->8x8->4x4)。这使其能够灵活处理不同尺度的物体。 -
线性复杂度: 得益于局部窗口注意力,其计算复杂度与图像大小呈线性关系,而不是平方关系,使其能处理高分辨率图像,降低计算复杂度。
最终目标:CV NLP大一统,多模态模型发展 unified modeling of vision and language signals.
后续研究 这个滑动窗口自注意力是否可以用到CV上。
3.2 Method 方法
3.2.1 Overall Architecture
模拟CNN过程的Transformer。分为不同的几个阶段stage。
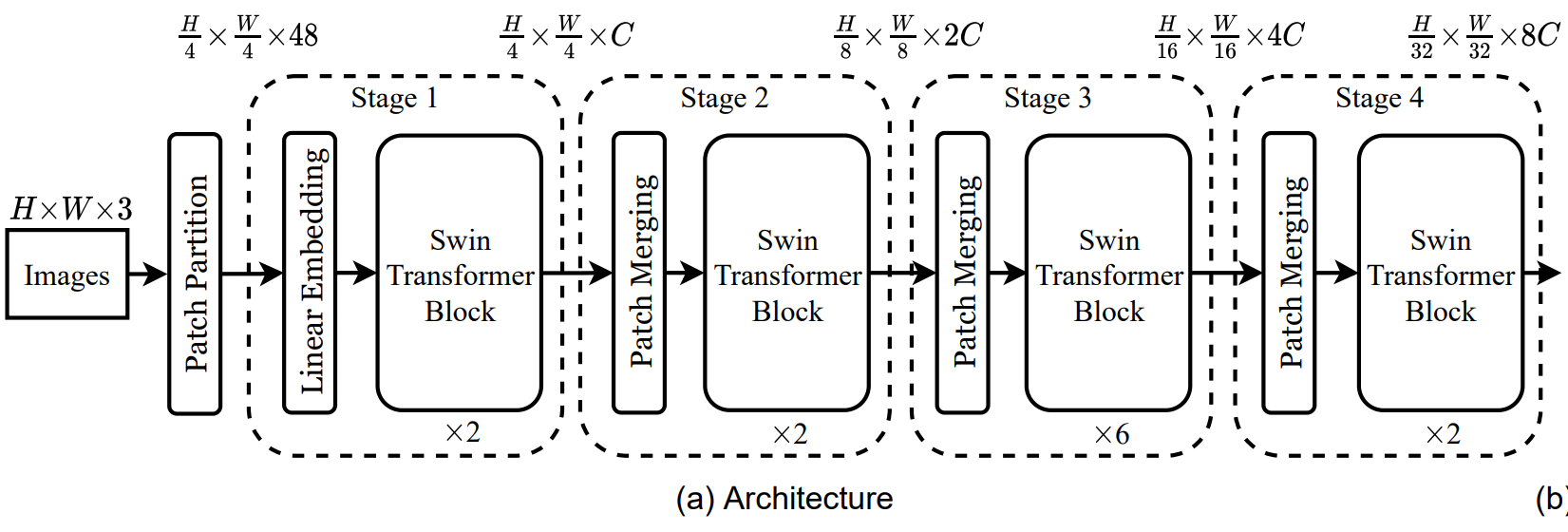
后面都设 H=W=224=14*16 的情况
最初patch划分为 4*4;4*4*3=48 变成56*56*48
Linear Embedding 把48放缩为C 56*56拉直为3136;即为3136*C
3136 相比于ViT中 14*14=196的情况 太长了,需要进行窗口自注意力(经过 Swin Transformer Block 尺度不变)
patch merging操作(类似池化) 行列数减半,通道数翻4倍 再用1*1卷积 变成翻2倍。

3.2.2 Shifted Window based Self-Attention 滑动窗口自注意力
密集预测 / 高分辨率图像 全局自注意力 平方级别复杂度太高。
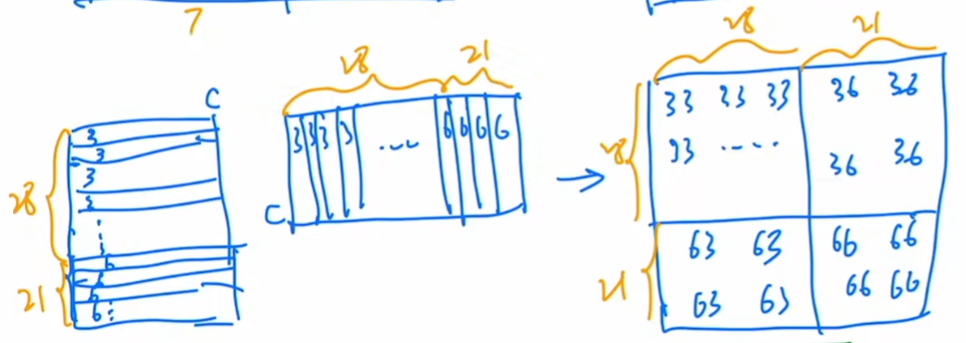
比如说 第一层 56*56*96 切成小块 M*M的 比如取M=7 那么就在这8*8的小块 每个小窗口里算注意力。
原来全局算MSA h*w*c原矩阵 3次乘以c*c的矩阵 得到三个h*w*c 的 q,k,v矩阵,复杂度为3*h*w*c^2
q*k 为 hw*c * c*hw 得到矩阵 A(hw*hw) 复杂度为 (hw)^2*c A*v 复杂度也为 (hw)^2*c
最后 乘以c*c进行投影 复杂度为 h*w*c^2;上面几项总和就为一式。

若窗口大小变成 M*M 把式子1 的所有h=w=M;一共窗口数目为 h*w/m/m
最后得到式子2的结果 关于h*w大小成正比而不是平方。
基于窗口 虽然减小了计算量 但达不到全局算注意力的效果了 于是引入shifted 移动窗口。
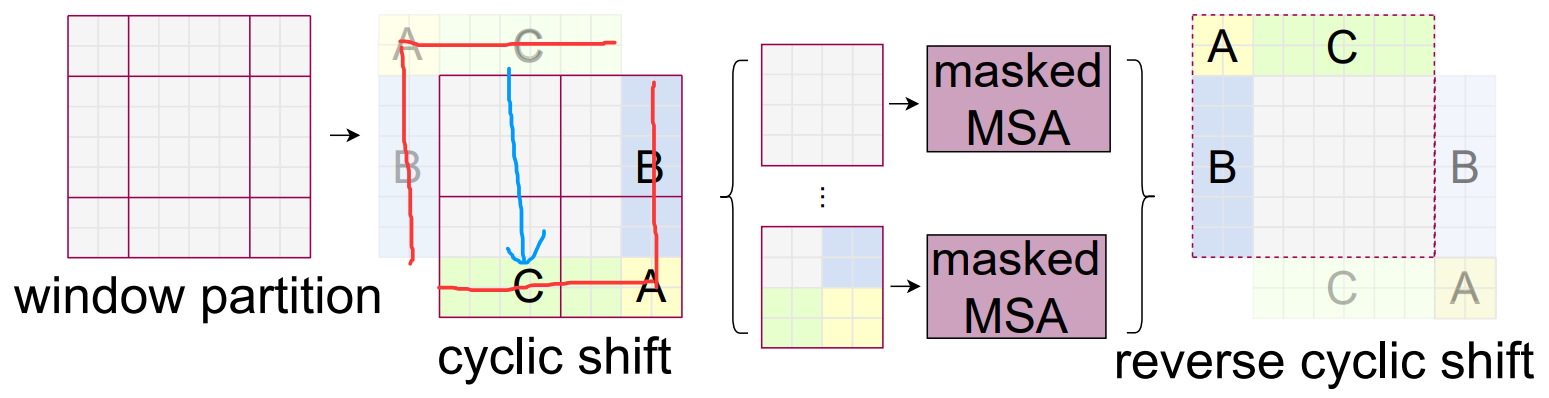
原来是四块的 我平移之后变成了大小不一的九块 不方便算注意力。
于是把左上角的块 移动到右下角 还是拼成了4块。
但不能直接算注意力 比如C之前的位置是在上面(天空)移到下面和(地面)拼在一起了,这两个距离很远的块本来不应该在一起算注意力的,所以还要通过掩码的方式 再进行反向移动还原。
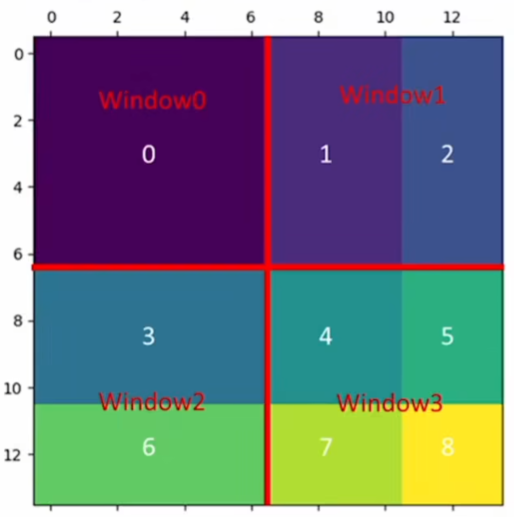
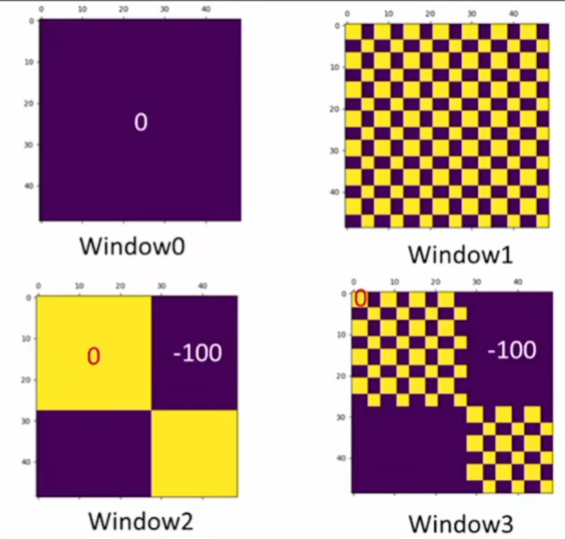
比如 3 6那边应该3、6分别单独算自注意力;把3 6拉直为向量 结果应该是上面一段一些3 下面一段一些6。再转置 算注意力 相当于不要左下和右上的部分 分别减去100,再做softmax。别的部分同理。
3.3 Experiments 实验结果
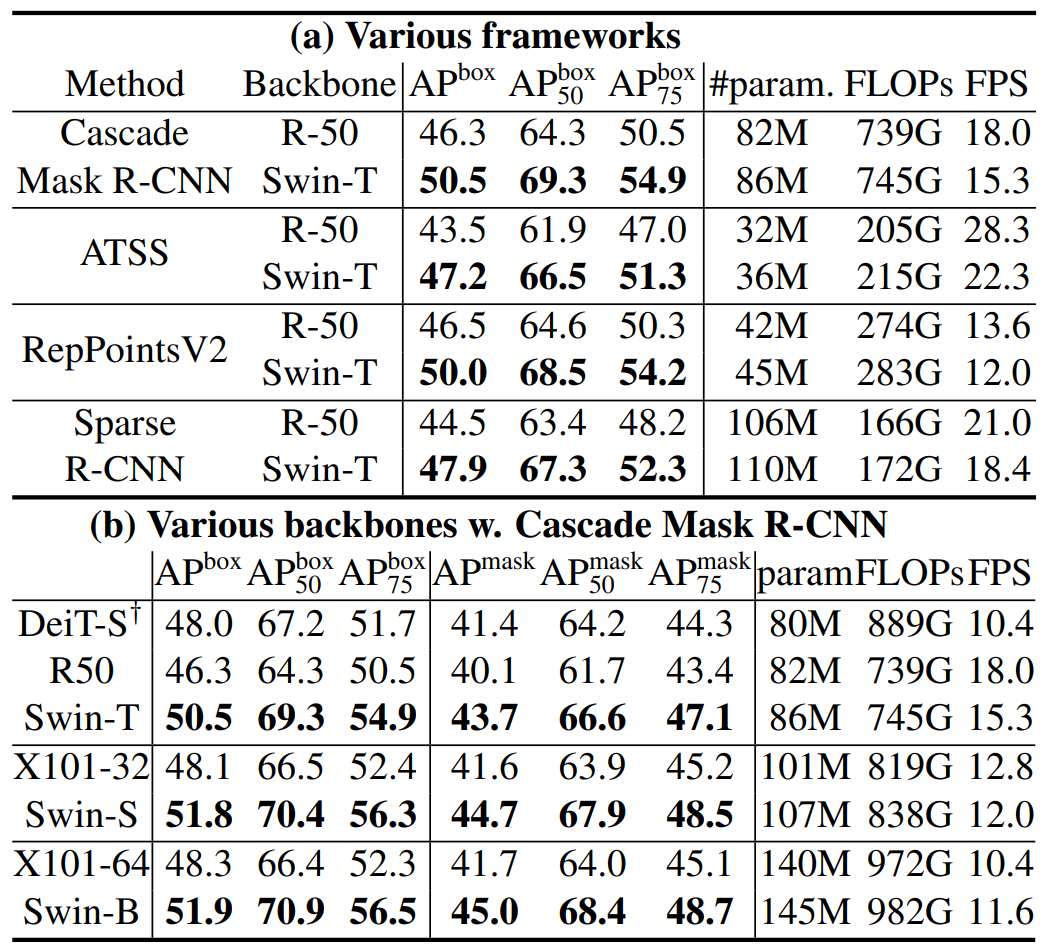
不同大小的架构 Tiny Small Base Large
主要超参数有C的大小和 每个stage中Block的个数,
并且与对应参数量的残差网络进行对比(因为也是四个stage的块)

从 framework架构上 Swin-T全方位碾压R-50;Swin-S全方位碾压X-101-32
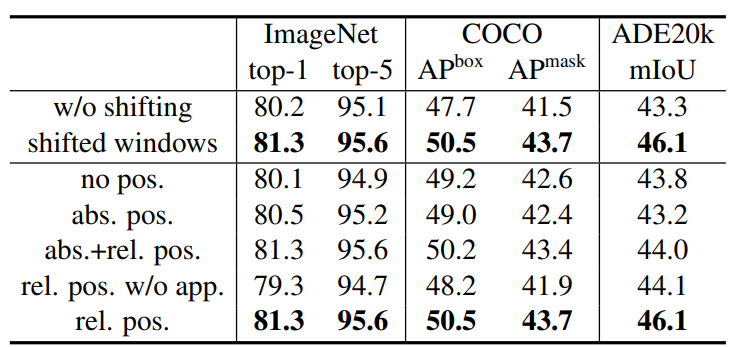
展示移动窗口和相对位置编码的作用;在ImageNet图像分类 COCO目标检测 ADE20k语义分割上




)
![[Maven 基础课程]第一个 Maven 项目](http://pic.xiahunao.cn/[Maven 基础课程]第一个 Maven 项目)




)



——2 环境搭建与入门)


)

