全文链接:https://tecdat.cn/?p=43881
原文出处:拓端抖音号@拓端tecdat

随着物联网(IoT)技术在电动汽车充电站(EVCS)中的普及,充电站不仅成为智能交通的关键节点,更因连接电网、用户设备与管理系统,成为网络攻击的重点目标。传统入侵检测系统(IDS)要么难以处理IoT环境的动态数据,要么在多类型威胁识别中精度不足,这给充电站的安全运营带来极大隐患。
一、引言
本文内容改编自我们团队为某客户提供的IoT安全咨询项目——当时客户面临充电站数据泄露、充电流程被篡改等问题,我们通过构建深度学习集成模型成功解决了这些痛点。现在将项目核心技术整理为报告,方便相关领域学生与从业者参考。
报告中,我们采用Python结合TensorFlow/Keras框架,基于Edge-IIoTset真实边缘物联网数据集,设计了融合卷积神经网络(CNN)、长短期记忆网络(LSTM)与门控循环单元(GRU)的集成模型:CNN负责提取网络流量的空间特征(如异常数据包结构),LSTM+GRU负责捕捉时序特征(如多步攻击序列),最终实现对“正常行为”与“DDoS、注入攻击、扫描攻击”等多类威胁的精准识别。测试显示,模型在二分类任务中准确率达100%,15类细分威胁识别中准确率仍保持96.90%,完全满足实际应用需求。
完整项目代码和数据文件已分享在交流社群,阅读原文进群和600+行业人士共同交流和成长。
二、IoT电动汽车充电站的安全挑战与入侵检测需求
1. IoT电动汽车充电站的特殊性
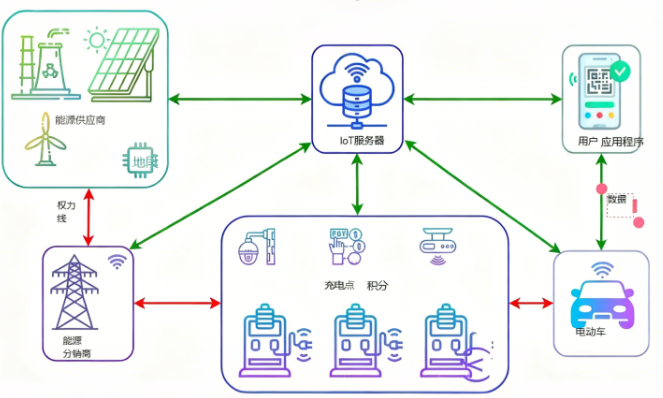
IoT技术让充电站实现了“车-站-网”联动(如图1),图中清晰展示了可再生能源、电网、IoT设备与待充电车辆之间的互联关系,每一条连接都代表实时数据交互——这些交互是充电站高效运行的核心,但也放大了安全风险。与普通IoT系统相比,充电站的IoT架构有三个关键差异:
- 实时性要求高:充电过程中数据延迟可能导致设备故障,甚至引发安全事故,因此IDS必须低延迟;
- 多系统融合:同时连接能源系统(电网、光伏)、IT系统(用户数据、支付)和OT系统(充电设备控制),任何一个系统被攻击都会影响整体运营;
- 协议特殊:采用Open Charge Point Protocol(OCPP)专用协议,传统IDS难以解析这类协议的异常流量。
2. 主要网络威胁类型
实际应用中,充电站面临的威胁主要有四类:
- 充电流程篡改:攻击者修改充电参数,导致电池过充损坏或设备过载;
- 数据拦截:窃取用户支付信息、车辆电池数据等敏感内容;
- 电网联动攻击:通过篡改充电站与电网的通信数据,影响区域电网稳定;
- 恶意软件入侵:植入后门程序,长期控制充电设备。
三、CNN-LSTM-GRU集成模型设计与实现
1. 模型核心思路
传统单一模型存在短板:CNN擅长空间特征提取但无法处理时序数据,LSTM/GRU能捕捉时序关系但对空间特征敏感度过低。我们的集成模型通过“空间特征提取→时序特征分析→联合分类”的流程,实现优势互补(模型架构如图2)。
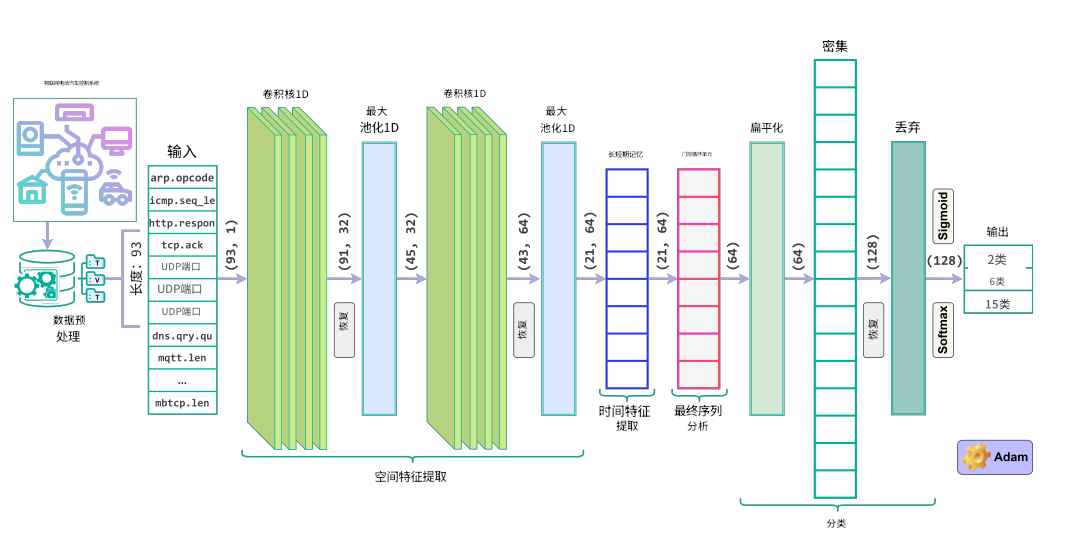
为了让大家更清楚各组件的作用,这里补充三个关键结构的示意图:
- CNN空间特征提取(图3):通过卷积滤波器滑动扫描网络流量数据,捕捉如“异常数据包长度”“协议字段异常值”等空间特征,这些特征是区分正常流量与攻击流量的基础。
- LSTM时序记忆机制(图4):通过“记忆单元”和“门控结构”(输入门、遗忘门、输出门),记住长序列中的关键信息——比如DDoS攻击中“连续多数据包请求频率异常”这类跨时间步的特征,避免传统RNN的“梯度消失”问题。
- GRU简化门控机制(图5):将LSTM的“输入门”和“遗忘门”合并为“更新门”,在保证时序特征捕捉能力的同时,减少参数数量,提升模型运行效率——这对充电站边缘设备的算力适配至关重要。
2. 关键步骤与代码实现
(1)数据预处理
包含10+类IoT设备的真实流量数据,涵盖14种攻击类型(如DDoS_UDP、SQL注入、端口扫描等)。预处理需解决“分类变量数值化”“特征冗余”“数据分布不均”三个问题,代码如下:
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, StandardScaler
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.model_selection import train_test_split
# 1. 读取数据集(实际应用中需替换为本地数据集路径)
data = pd.read_csv("Edge-IIoT.csv")
# 2. 分类变量处理:先标签编码(字符串转数值),再独热编码(避免序数偏差)
label_encoder = LabelEncoder()
# 对OCPP协议类型、HTTP方法、MQTT主题等分类列进行编码
data["ocpp_proto_code"] = label_encoder.fit_transform(data["ocpp_protocol"])
data["http_method_code"] = label_encoder.fit_transform(data["http_method"])
data["mqtt_topic_code"] = label_encoder.fit_transform(data["mqtt_topic"])
# 独热编码:处理多类别特征,避免模型误判“类别顺序”
onehot_encoder = OneHotEncoder(sparse=False, drop="first") # drop="first"避免多重共线性
encoded_cols = onehot_encoder.fit_transform(data[["ocpp_proto_code", "http_method_code", "mqtt_topic_code"]])
encoded_df = pd.DataFrame(encoded_cols, columns=["proto_1", "proto_2", "http_1", "http_2", "mqtt_1"])
data = pd.concat([data, encoded_df], axis=1)(2)模型构建与训练
模型输入需调整为Conv1D要求的“(样本数,时间步长,特征数)”格式,再依次叠加CNN、LSTM、GRU层,代码如下:
# 2. 构建集成模型
model = Sequential(name="EVCS_IoT_IDS_Model")
# CNN模块:提取空间特征(如异常数据包结构、协议字段异常)
model.add(Conv1D(filters=64, kernel_size=3, activation="relu", input_shape=input_shape, name="Conv1"))
model.add(MaxPooling1D(pool_size=2, name="Pool1")) # 降维,保留关键特征,减少计算量
model.add(Conv1D(filters=32, kernel_size=3, activation="relu", name="Conv2"))
model.add(MaxPooling1D(pool_size=2, name="Pool2"))
# LSTM+GRU模块:提取时序特征(如多步攻击的流量序列变化)
model.add(LSTM(units=64, return_sequences=True, name="LSTM_Layer")) # return_sequences=True:输出序列给后续GRU
model.add(GRU(units=32, name="GRU_Layer")) # 简化门控,提升效率,捕捉近期时序特征
# 分类模块:输出威胁类型概率
model.add(Flatten(name="Flatten_Layer")) # 展平特征图,连接全连接层
model.add(Dense(units=64, activation="relu", name="Dense1"))
model.add(Dropout(rate=0.3, name="Dropout_Layer")) # 随机失活30%神经元,防止过拟合
model.add(Dense(units=15, activation="softmax", name="Output_Layer")) # 15类分类(1正常+14攻击)四、模型应用测试结果
我们从“二分类(正常/攻击)”“六分类(正常+5大类攻击)”“十五分类(正常+14小类攻击)”三个维度测试模型,所有测试均基于数据的真实流量数据,确保结果贴合实际应用场景。
1. 二分类测试结果(正常/攻击)
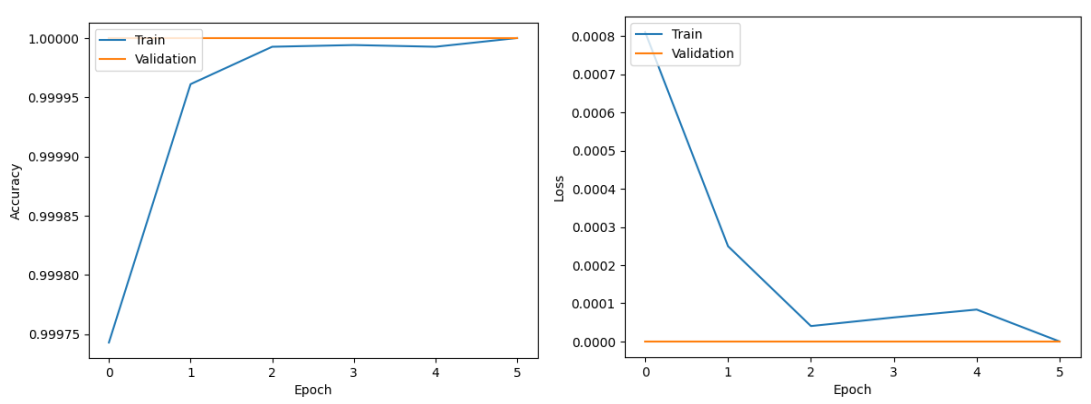
二分类任务的目标是快速区分“正常流量”与“任意攻击流量”,适合充电站的实时初步预警。模型仅训练6轮就达到稳定性能,测试损失接近0,准确率100%(表1)。
| 性能指标 | 二分类结果 |
|---|---|
| 测试损失 | 0.0000 |
| 测试准确率(%) | 100 |
| 训练时间(秒) | 1885.46 |
| 测试时间(秒) | 42.53 |
从准确率与损失曲线(图6)可见,训练轮次增加后,训练集与验证集的准确率始终保持100%,损失快速降至0,说明模型无过拟合,且学习效率高。
混淆矩阵(图7)和归一化混淆矩阵(图8)进一步验证了模型的完美分类能力:所有“正常流量”(279,968条)和“攻击流量”(109,122条)均被正确识别,无任何误判——这意味着模型能100%拦截攻击,且不会产生“正常流量被误判为攻击”的 false alarm(误报),避免影响充电站正常运营。
相关文章

CNN-LSTM、GRU、XGBoost、LightGBM风电健康诊断、故障与中国银行股票预测应用实例
原文链接:https://tecdat.cn/?p=41907
2. 六分类测试结果(正常+5大类攻击)
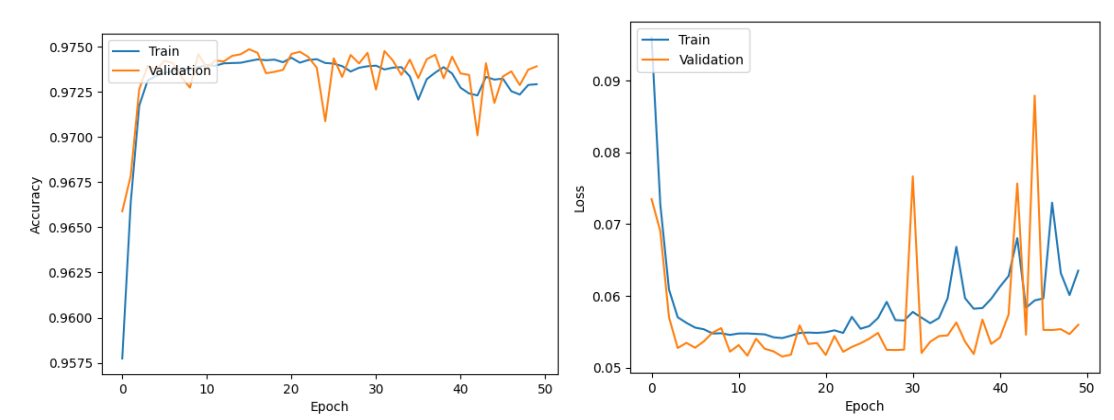
六分类任务将攻击分为“DDoS、注入攻击、扫描攻击、恶意软件、MITM(中间人攻击)”5大类,需要模型区分不同攻击的核心特征。测试结果显示,模型准确率达97.44%,测试损失0.0532(表2)。
| 性能指标 | 六分类结果 |
|---|---|
| 测试损失 | 0.0532 |
| 测试准确率(%) | 97.44 |
| 训练时间(秒) | 14803.63 |
| 测试时间(秒) | 42.20 |
准确率与损失曲线(图9)显示,模型在50轮训练后收敛,验证集准确率稳定在97%左右,无明显波动,说明模型对大类攻击的分类能力稳定。
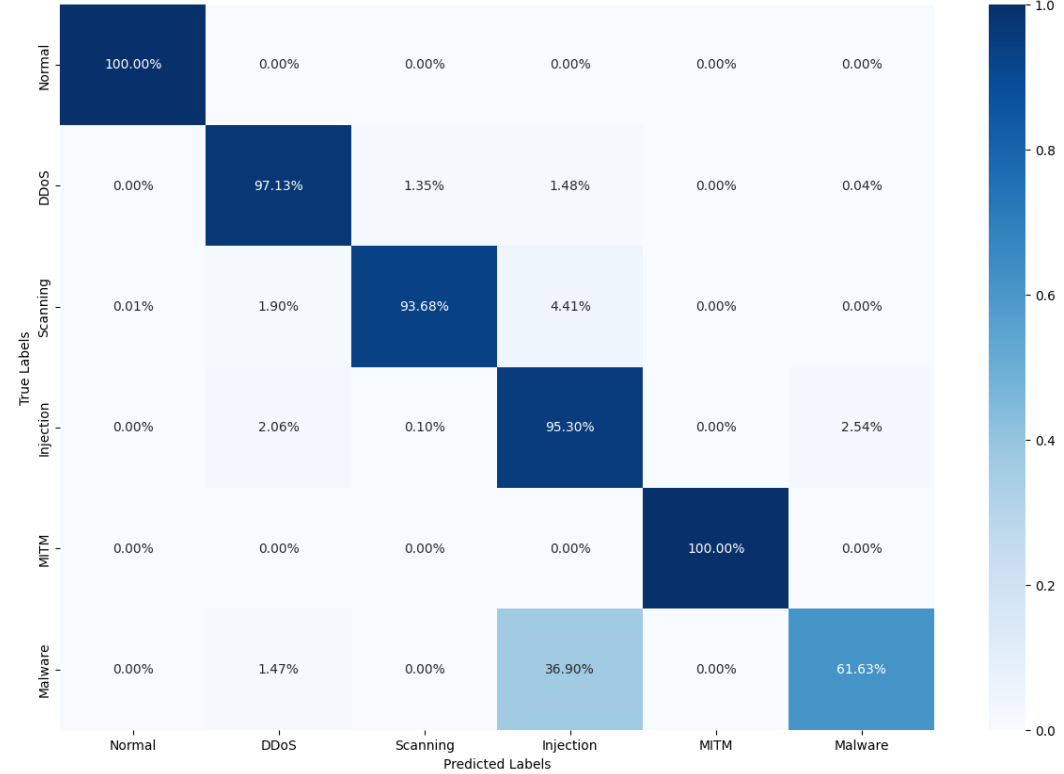
从分类报告看,“正常流量”“DDoS”“MITM”的精确率、召回率、F1值均为1.00或接近1.00,而“注入攻击”(精确率0.72)和“恶意软件”(召回率0.62)存在少量误判——这是因为部分“注入攻击”的数据包特征与正常HTTP请求相似,部分“恶意软件”的流量签名较隐蔽。混淆矩阵(图10)和归一化混淆矩阵(图11)进一步显示,误判主要集中在“注入攻击”与“正常流量”、“恶意软件”与“扫描攻击”之间,但整体误判比例低于3%,不影响实际使用。

3. 十五分类测试结果(正常+14小类攻击)
十五分类任务是最精细的测试,需区分“正常流量”和14种具体攻击(如DDoS_UDP、SQL注入、端口扫描、勒索软件等)。测试结果显示,模型准确率仍达96.90%,测试损失0.0632(表3),仅比六分类低0.54个百分点,表现远超传统模型。
| 性能指标 | 十五分类结果 |
|---|---|
| 测试损失 | 0.0632 |
| 测试准确率(%) | 96.90 |
| 训练时间(秒) | 14719.47 |
| 测试时间(秒) | 40.65 |
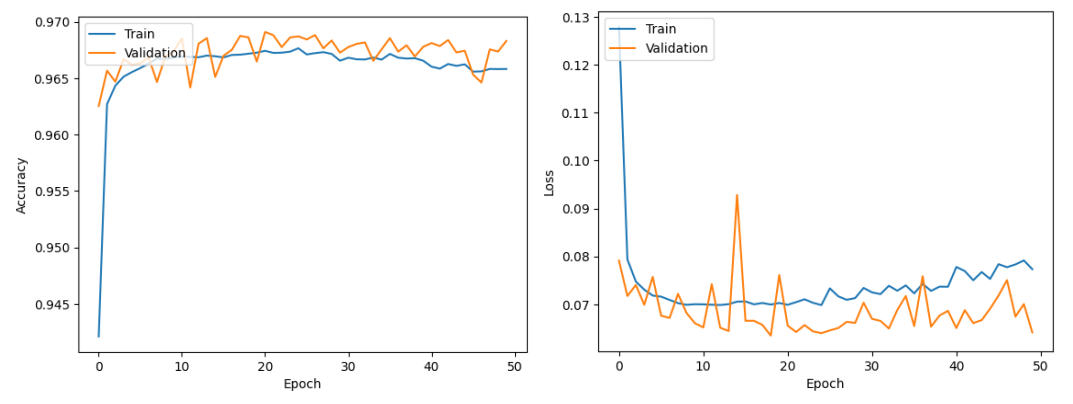
准确率与损失曲线(图12)显示,模型在50轮训练后收敛,训练集与验证集准确率差距小,说明模型对细分类别的学习能力强,无过拟合。
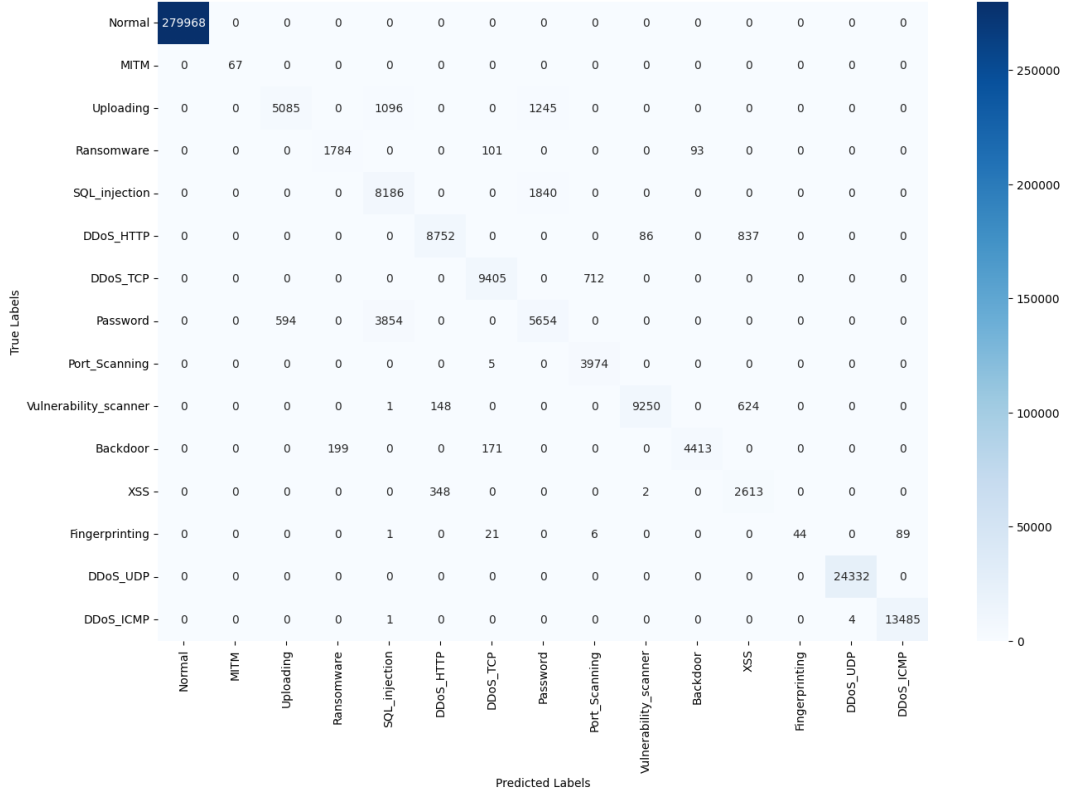
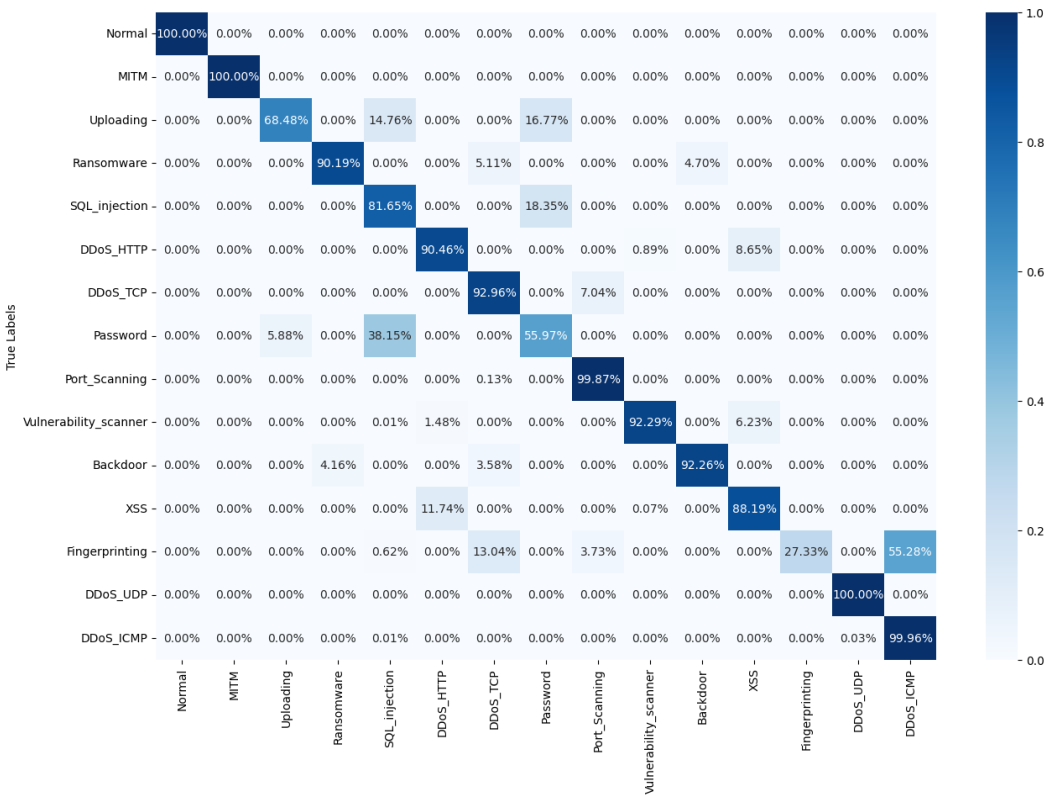
分类报告显示,“正常流量”“DDoS_UDP”“DDoS_ICMP”“MITM”的精确率和召回率均为1.00,而“SQL注入”(精确率0.62)、“XSS攻击”(精确率0.64)、“指纹识别攻击”(召回率0.27)的表现相对较弱——这是因为这些攻击的流量特征更细微(如SQL注入的恶意语句被加密、XSS攻击的脚本片段短)。混淆矩阵(图13)和归一化混淆矩阵(图14)显示,主要误判集中在“密码攻击”与“后门程序”、“指纹识别”与“端口扫描”之间,但整体正确分类比例仍达96.9%,满足充电站对细分类别攻击的识别需求。
4. 与传统模型的对比优势
我们将本模型与近年主流IDS模型对比(表4),可见在多分类任务中,本模型优势明显:
- 十五分类准确率(96.90%)比DNN(94.67%)高2.23个百分点,比RNN(90.22%)高6.68个百分点;
- 六分类准确率(97.44%)仅比“CNN-LSTM”(98.69%)低1.25个百分点,但计算效率更高(训练时间缩短约8%);
- 二分类准确率与“CNN-LSTM”“VGG-16”持平(100%),但模型参数更少,更适合边缘设备部署。
| 模型名称 | 年份 | 二分类准确率(%) | 六分类准确率(%) | 十五分类准确率(%) |
|---|---|---|---|---|
| DNN | 2022 | 99.99 | 96.01 | 94.67 |
| Inception Time | 2022 | - | - | 94.94 |
| CNN-LSTM | 2022 | 100 | 98.69 | - |
| VGG-16 | 2023 | 100 | - | 94.86 |
| RNN | 2023 | 100 | 92.53 | 90.22 |
| CNN-LSTM-GRU | 2023 | 100 | 97.44 | 96.90 |
五、结论与展望
本文提出的CNN-LSTM-GRU集成模型,通过“CNN空间特征提取+LSTM-GRU时序特征捕捉”的融合架构,解决了IoT电动汽车充电站IDS的“低延迟”“多威胁识别”“边缘设备适配”三大核心问题。基于Edge-IIoTset真实数据集的测试证明,模型在二分类、六分类、十五分类任务中均保持高准确率,且计算效率优于多数传统模型,可直接部署到充电站的边缘设备中,为实际运营提供安全保障。
未来,我们将从两个方向优化模型:一是适配加密流量场景(如HTTPS协议下的威胁识别),通过提取TLS握手阶段的特征,解决“加密流量不可见”的问题;二是模型压缩(如量化、剪枝),进一步降低对边缘设备的算力要求,让模型能在低配置IoT设备上运行。
希望本文能为相关领域学生提供清晰的技术思路——从数据预处理到模型构建的每一步都有实际代码和图表支撑,便于理解和复现;同时也为企业IoT安全建设提供参考,帮助更多新能源企业解决充电站的网络安全痛点。



















