NineData 社区版 V4.5.0 正式发布!在数据复制方面,新增 MySQL 至 Greenplum 全链路复制对比,并优化全局 DDL 管控、MySQL/PostgreSQL/MongoDB 同构性能。在数据库 DevOps 方面,新增支持 AWS RDS 全系列及阿里云 PolarDB(兼容 Oracle/PostgreSQL),扩展多场景数据操作能力。在基础服务方面,运维中心新增细粒度任务权限管理,镜像部署适配 cgroup v2 环境。通过本次升级,为开发者带来更高效的体验。

1. NineData 社区版是什么?
NineData 是面向 AI 时代的智能数据管理平台,提供数据库 DevOps、数据复制对比等功能。
-
数据库 DevOps 支持企业级数据库 IDE、安全管控、变更发布等能力,比 Navicat、Bytebase、Flyway、Archery 功能更强大,更易用,可以帮助企业数据库管理更安全更高效。
-
数据复制与对比支持 60 种主流数据库之间的数据迁移、实时同步、数据对比,可以完全替代 Canal、FlinkCDC、DataX、DTS 等产品,用于数据库信创迁移、ETL、容灾、跨云数据同步等场景。
NineData 提供云服务、本地企业版、社区版多种模式。
社区版是面向广大开发者的免费版本,包括了 NineData 的基础功能,可以在本地通过 docker 一键安装部署,5~10 分钟快速体验。
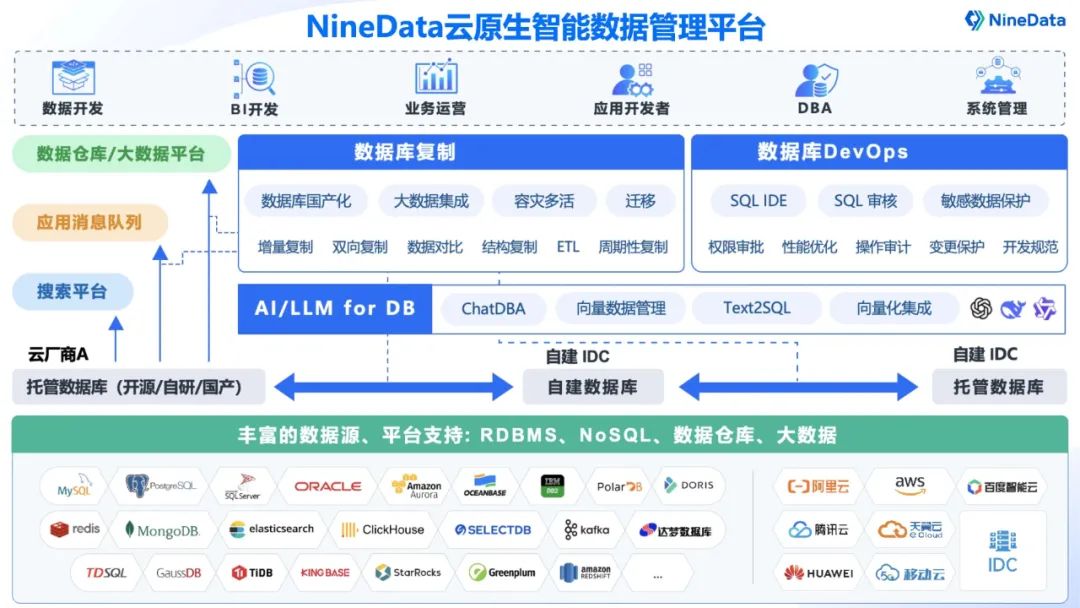
2. 社区版 V4.5.0 核心功能全面升级
2.1 数据复制与对比:提升异构数据库同步能力
-
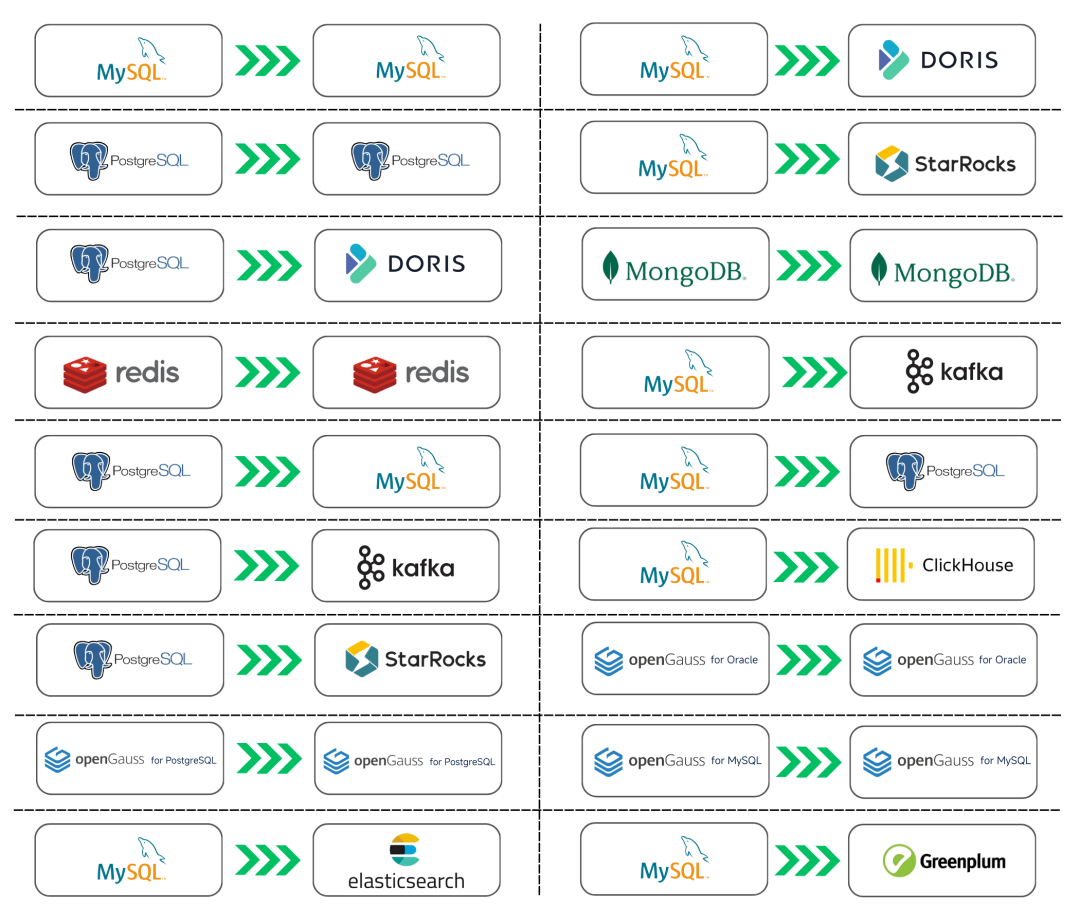
MySQL > Greenplum
支持结构复制、全量复制、增量复制及全量/快速/周期/不一致复检对比。
目前,NineData 社区版 V4.5.0 已支持 18 条数据库迁移链路,如下:
-
支持全局开启或关闭 DDL 复制
在数据复制功能方面,V4.5.0 版本新增全局 DDL 复制控制功能,允许用户根据业务需求灵活控制 DDL 语句的复制行为。
-
多种数据库同构复制优化
NineData 社区版 V4.5.0 版本对多种数据库的同构复制进行了全面优化,包括性能提升、兼容性增强和功能扩展等方面,主要涉及数据库如下:
2.1.1 PostgreSQL 同构复制
-
-
性能提升:加入表相关 DML 语句的批量复制逻辑,提升复制性能。
-
兼容性提升:在数据复制过程中,已支持处理 timestamp 字段取值为 +infinity 或 -infinity 的情况。
-
2.1.2 MySQL 同构复制
-
-
Binlog 读取限流:增量复制过程中,可以通过增量复制页签下的限流设置功能,限制 NineData 对源库 Binlog 的读取速率,以降低对源库的读取压力。
-
Binlog 表对象过滤:如果复制对象不是整个库,NineData 将自动过滤掉复制对象以外的表,大大提升日志解析的速度。
-
latin1 编码 enum/set 修复:支持正确处理以 latin1 编码存储的 enum/set 类型值。
-
2.1.3 MongoDB 同构复制
-
-
新增支持 drop index 语法复制。
-
2.2 数据库 DevOps:全面增强多云数据库管理
-
新增多种数据源类型
NineData 社区版 V4.5.0 版本支持 AWS RDS SQLServer、AWS RDS PostgreSQL、AWS RDS Oracle、AWS RDS MariaDB、AWS Aurora PostgreSQL、PolarDB(兼容 Oracle)、PolarDB PostgreSQL,可在 SQL 窗口、任务、敏感数据管理等功能中使用。
-
敏感数据保护增强(PostgreSQL 增强)
NineData 社区版 V4.5.0 版本进一步增强了敏感数据保护功能,新增支持 PostgreSQL 数据源的自动识别、分类分级功能,支持配置周期任务定时执行。
-
存储过程调试(PostgreSQL)
SQL 窗口的存储过程调试功能新增支持 PostgreSQL 数据源,支持存储过程和函数设置断点、逐步执行、查看与修改变量等操作。
-
数据导入导出(MongoDB)
数据导入导出功能新增支持 MongoDB 数据源,支持 JSON 格式文件的导入与导出。
2.3 服务部署:运行环境适配增强
-
增加对系统 cgroup v2 检测
NineData 社区版 V4.5.0 版本新增对系统 cgroup v2 的检测,增强运行环境适配能力,显著提升了容器化部署的环境适应性和兼容性。
2.4 基础服务:细粒度权限管控升级
-
任务管理权限
运维中心模块支持基于数据源级别的细粒度权限管控,授权用户才可对数据源关联任务进行管理操作。
-
运维中心模块权限
支持在权限管理 > 模块权限中,授予用户运维中心模块的访问权限。授权用户才可访问运维中心管理 NineData 任务。
3. NineData 社区版与主流工具对比
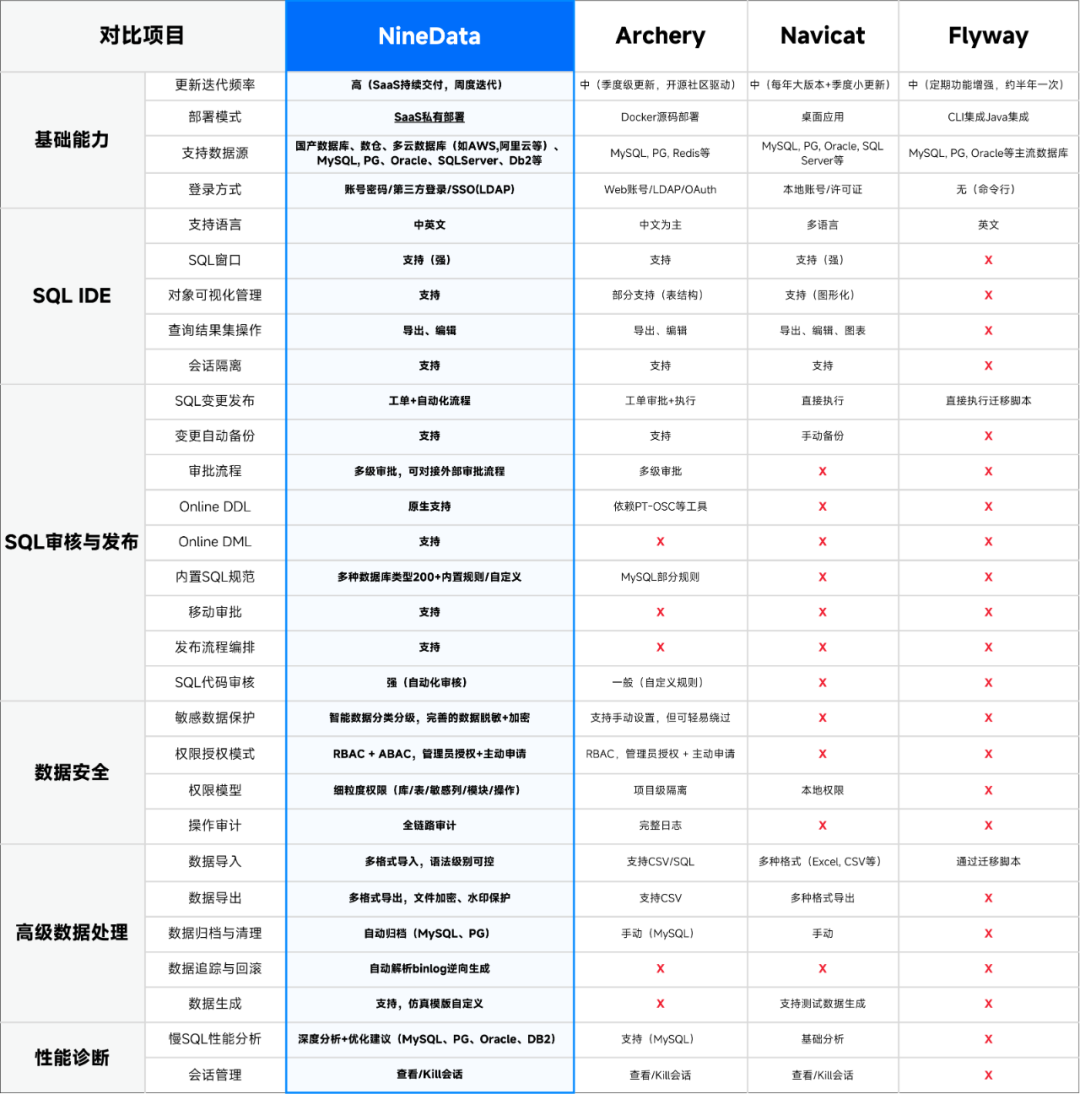
3.1 数据库DevOps
数据库 DevOps 具有数据源管理、数据查询、SQL 规范、SQL 审核、审批流程等强大功能,帮助用户快速完成多种环境的数据管理任务,助力企业数字化转型。
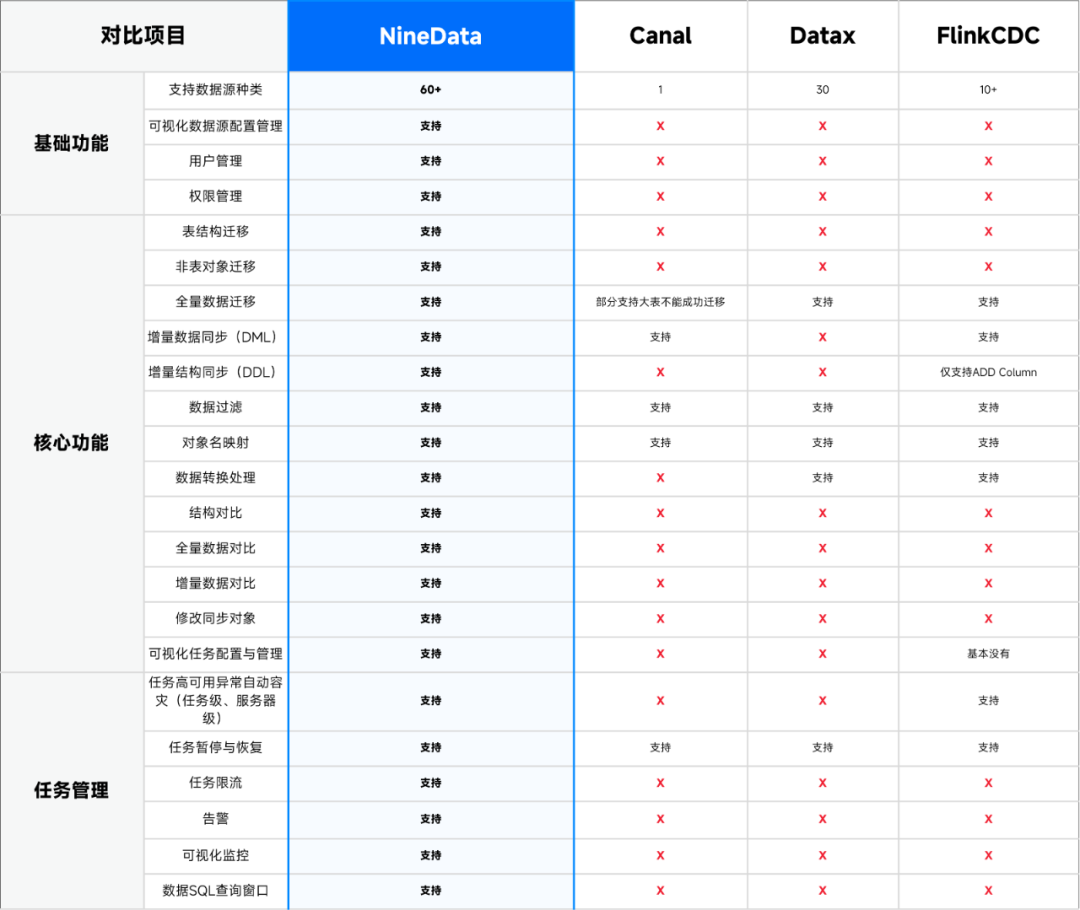
3.2 数据复制
NineData 数据复制支持多种同异构数据源之间的离线、实时数据复制。适合数据迁移、数据库扩缩容、数据库版本升级、异地容灾、异地多活、数据仓库及数据湖数据集成等多种业务场景。
4. 社区版核心优势
-
免费使用:社区版完全开放使用,用户可以随时使用,无订阅费用。
-
快速部署:基于 Docker技术部署,快速完成本地或云环境安装。
-
高性能数据同步:基于自研 CDC 技术,支持每秒数万 TPS 实时复制,适用于大规模数据同步和迁移。
-
安全合规:支持私有化部署部署,确保数据安全性,特别适合敏感数据管理。
-
专业功能覆盖:提供 SQL 审核、结构设计、敏感数据保护等企业级能力。
5. NineData 社区版安装部署
在部署方面,基于Docker技术,用户通过简单命令即可在本地电脑完成安装,仅需需要 5 ~ 10 分钟就可以快速完成安装部署,方法步骤如下:
NineData 社区版安装部署
在服务器中已安装 Docker后,登录服务器的命令行窗口,执行如下命令,待容器启动完成后,即可登录 NineData 控制台直接使用。
docker run -p 9999:9999 --privileged -v /opt/ninedata:/u01 --name ninedata -d swr.cn-east-3.myhuaweicloud.com/ninedata/ninedata:latest
6. 总结
本次 NineData 社区版 V4.5.0 版本升级聚焦于多云数据库管理能力的全面提升,在数据库 DevOps、数据复制与对比、基础服务等方面进行了重大功能增强,并优化了服务部署体验。通过这些更新,NineData 社区版为开发者带来更高效、更安全、更智能的数据库管理体验,帮助企业应对多云、多源数据管理挑战,降低数据管理复杂性。





)






![[deepseek]LNK2001错误即单独编译汇编并链接](http://pic.xiahunao.cn/[deepseek]LNK2001错误即单独编译汇编并链接)
)
)

)


