前言
我们通过提示词工程提升了通用LLM的专业知识水平,并结合Function Calling构建了私有业务能力。为了在实际应用中有效维护私有领域的专有数据,我们进一步采用大模型微调或RAG检索增强技术,使LLM能够充分掌握私有知识库的内容。
一、微调和RAG选择
① 知识静态 vs 动态
如果企业知识库在短期内变化较少,更倾向长期积累,且更关心对话流畅度和风格统一,可优先考虑微调大模型;
如果知识库更新频率很高、内容格式多样、需要保证用户问到最新信息推荐,则RAG更适合。
② 资源与能力
微调:需要有训练基础设施(GPU 服务器或云上 GPU ),有标注能力、MLOps 经验;后续每次版本迭代需额外算力。
RAG:需要有向量数据库(如 Milvus、Faiss、Pinecone 等),并熟悉向量检索与 Prompt 工程;大模型可直接调用 API,无需训练资源投入。
③ 用户体验与业务目标
一致性与口径统一:微调后的模型在同一领域内输出风格更稳定,适合有统一口径要求的内部文档问答、内部知识助手;
最新信息与引用可查:RAG 可以随时引用最新文档,适合外部客服或知识库更新频繁的场景。
④ 区别一览
| 对比维度 | 微调大模型(Fine-Tuning) | 检索增强生成(RAG) |
|---|---|---|
| 响应流程 | 只需模型一次前向推理 | 先检索→再拼接Prompt→大模型推理 |
| 部署与基础设施 | 需要大规模微调训练环境与推理环境(专用 GPU) | 需要向量索引系统 + 通用大模型推理环境 |
| 知识更新成本 | 高——每次新增/修改都需重新微调 | 低——只需更新向量索引,无需再训练大模型 |
| 生成连贯度 | 通常更连贯、更具连贯的领域风格 | 依赖检索质量,可能出现回答片段化或上下文脱节 |
| 可解释性 | 较差——知识藏在模型权重中,难以追踪具体来源 | 较好——可展示检索到的文档片段及来源 |
| 资源与成本 | 高——训练耗时长、显存占用大;需要专门的 MLOps 流程 | 中等——嵌入生成与检索占用资源有限,但需维护索引服务 |
| 维护与迭代 | 复杂——每次迭代都要全流程跑一遍,包括采集、标注、微调、评估 | 灵活——只要索引数据新增/修改即可 |
| 实时性要求 | 对于在线部署模型推理,延迟相对较低;但更新频率低时难以实时应答新知识 | 延迟略高,需要检索阶段;索引规模大时需要做性能优化 |
| 应用场景 | 知识更新频率较低,且对回答一致性、完整性要求高的场景;企业内训库、FAQ 稳定版本 | 知识库内容频繁更新,且需兼容多种文档类型场景;在线文档检索问答、动态资料库 |
二、RAG介绍
RAG 全称为 Retrieval-Augmented Generation(检索增强生成)。简单来说,RAG 是一种将「文档/知识库检索」与「大语言模型(LLM)生成」相结合的技术架构。
大致流程是:当用户提出问题时,先检索相关的知识片段(通常是私有文档库或公开文档库中与问题最相关的片段),然后将这些检索到的片段拼接到提示(prompt)里,交给大语言模型进行生成式回答。
通过“先检索、再生成”的思路,RAG 能将模型回答更加“基于事实”,同时又保留了 LLM 在自然语言生成(NLG)方面的优势。
三、RAG具体实现流程
使用 Sora 文生图 功能获得的基本流程图
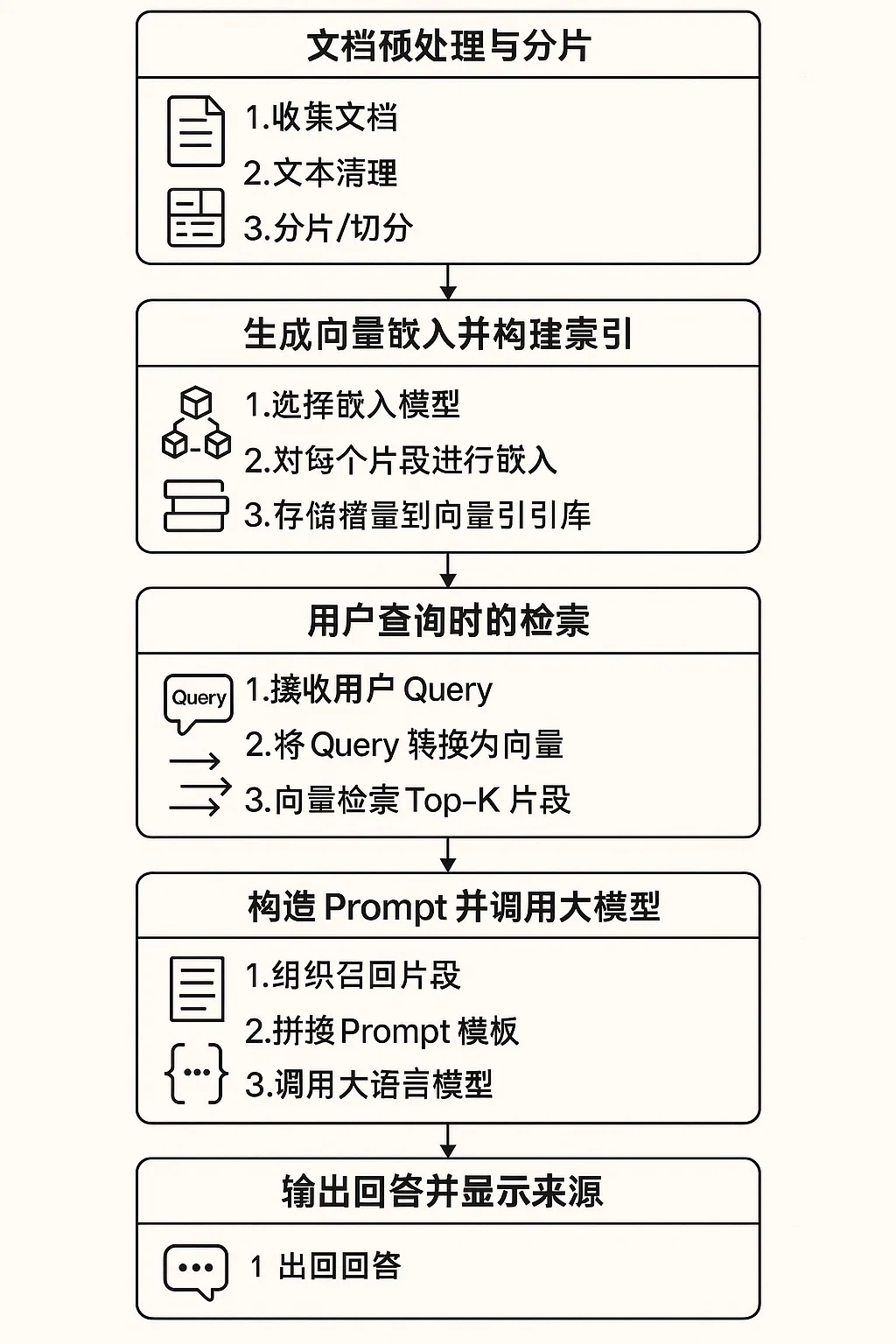
① 文档预处理与分片(Shard/Chunk)
(1) 收集文档
将所有要纳入私有知识库的内容(如内部手册、技术文档、FAQ、报表说明、法律条款等)集中到一个来源。
(2) 文本清理
对不同格式的文档(PDF、Word、HTML)进行 OCR(如果是图片内文字)或直接提取纯文本,去除多余空行、页眉页脚等无关信息。
(3) 分片/切分
将一整篇长文档按“章节”、“段落”,或按固定 Token/字符长度(比如每 500-1,000 字)切分成一个个小单元(“片段”)。
理想情况下,每个片段要保证“语义完整”,既不能太短导致断句,也不能太长让后续检索浪费上下文。
② 生成向量嵌入并构建索引
(1) 选择嵌入模型
常用的文本嵌入模型包括 OpenAI 的 text-embedding-ada-002、Sentence-BERT(SBERT)、MiniLM 、阿里 的 multimodal-embedding-v1等。
(2) 对每个片段进行嵌入
把每个文本片段输入嵌入模型,得到一个定长向量(通常维度在 512~1,536 之间)。
(3) 存储向量到向量索引库
选择一个向量数据库(如 Faiss、Milvus、Pinecone、ChromaDB 等)来存储这些向量,同时保留与原文本片段的映射关系(ID、文档来源、页码/段落号等元信息)。
同时可为每个向量关联额外的元数据,以便后续检索后快速知道“这个片段来自哪个文档、哪个位置”。
③ 用户查询时的检索
(1) 接收用户 Query
用户在对话界面/API 接口中输入一个自然语言问题。
(2) 将 Query 转换为向量
同样使用上面嵌入模型对用户 query 进行编码,得到一个“查询向量”。
(3) 向量检索 Top-K 片段
在向量索引库中,以查询向量为基准,按照余弦相似度(或内积)检索出与之最相近的 Top-K 个文档片段。
通常 K 的值在 3~10 之间,可根据知识库规模与实时性要求做实验调优。
④ 构造 Prompt(提示)并调用大模型
(1) 组织召回片段
根据检索结果,取到的每个片段都会包含原文短句;此时可以将最相关的 3~5 条片段按“重要性”排序。
(2) 拼接 Prompt 模板
类似以下:
你是公司的智能知识问答助手。以下是与用户问题相关的文档片段,请基于这些片段来回答用户问题,并在回答末尾以 “[来源:文档名, 段落编号]” 的方式注明出处。
=== 检索到的文档片段开始 ===
[片段1文字内容]
[片段2文字内容]
…
=== 文档片段结束 ===用户提问:{用户原始问题}
回答要点:
(3) 调用大语言模型
将上述拼接好的完整 Prompt(包括检索到的内容和用户问题)发送给通用大模型(如 GPT-4、LLaMA-2、Claude 2、内部自研大模型等)。模型会“参照”这些真实片段内容,生成一段连贯且有凭据的回答。如果需要极高的可解释性,还可以在 Prompt 中要求“请在回答中引用片段编号”。
⑤ 输出回答并显示来源
返回的文本通常包括完整自然语言回答,有时也会带上“参考来源”或“原文段落编号”。
四、RAG自定义优化方案
① 分片策略
按语义切分:优先按“章节/小节”或“自然段落”分片,保证每个片段内部逻辑连贯。
重叠分片:相邻片段可以有少量上下文重叠(比如前后 50 字重叠),避免切分边界导致信息丢失。
② 检索召回策略
向量 + 关键词混合检索:先用布尔检索或 BM25 做粗召回,再用向量检索做精排,提高召回准确率。
多轮检索:当用户问得非常笼统时,可先做一级检索(广泛召回),再基于用户反馈精选 Top-K 片段做二级检索。
③ Prompt 长度管理
如果 Top-K 片段拼接后超过 LLM 的上下文窗口(如 GPT-4 32K Token 限制),需要先对每个片段做摘要压缩,只截取最关键的句子。或者优先保留与用户 query 余弦相似度最高的那几段,再拼接到 prompt 里。
④ 动态更新
文档新增/变更:需对新增文档切分并生成嵌入,插入向量索引;若某个文档更新,先在索引里删除对应向量,再重新切分生成插入。
索引重建或离线批量更新:对于文档量剧增、检索效果下降时,可定期做一次全量索引重建,或者做分库分片。
⑤ 来源可视化
一般会把“文档名+页码/段落号”作为元信息存入索引里,最终在回答中把它写成 “[来源:XXX 文档,第 12 页,第 3 段]”,让用户确认事实依据。
五、前置准备-开通向量库
① 注册账号
可以免费使用 2G 容量的向量数据库:pinecone
自由选择方式注册即可
选择个人使用
选择使用方式,我们用于AI智能体,文件大小都在1-10m之间即可
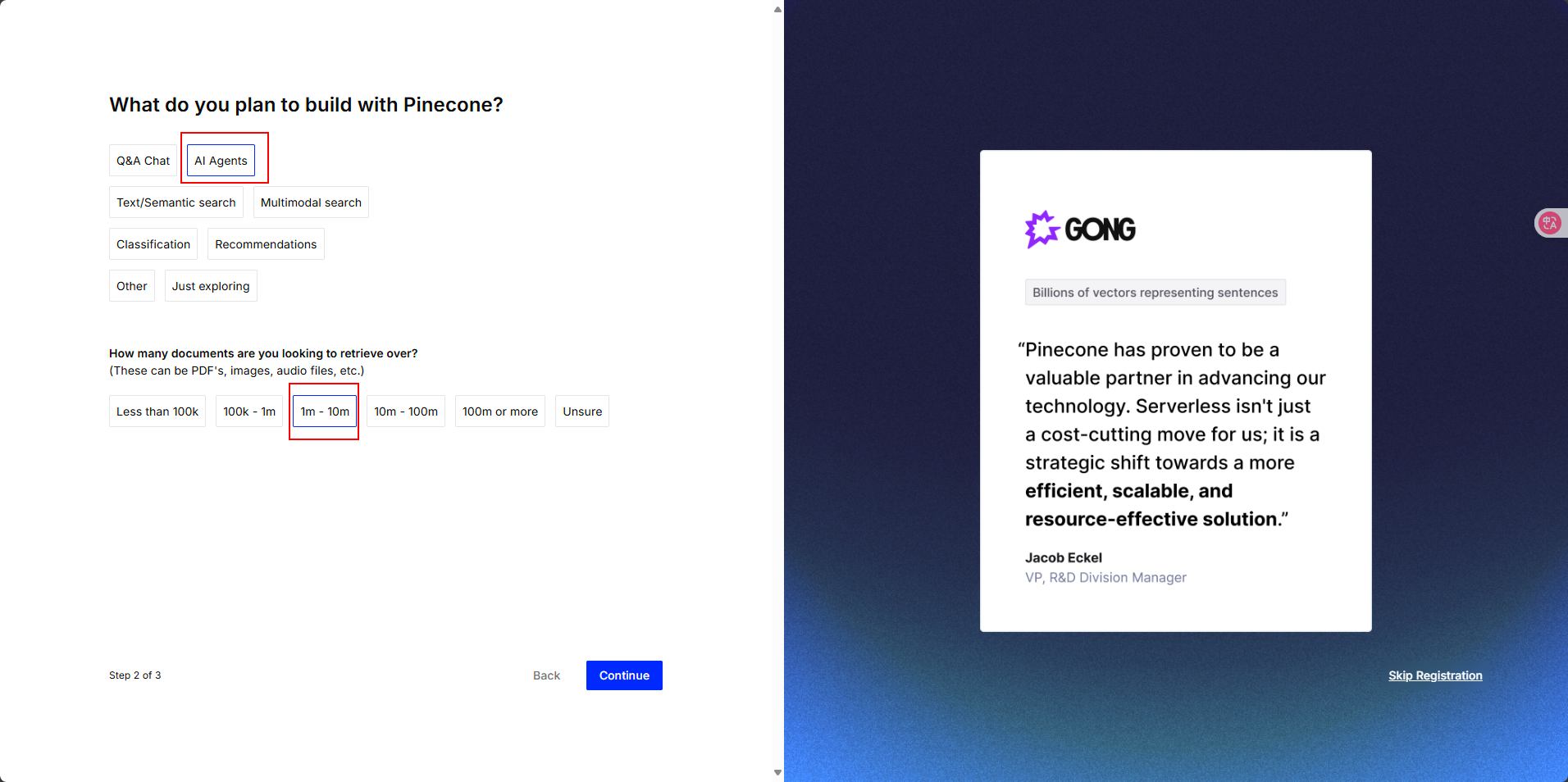
选择初次使用向量数据库
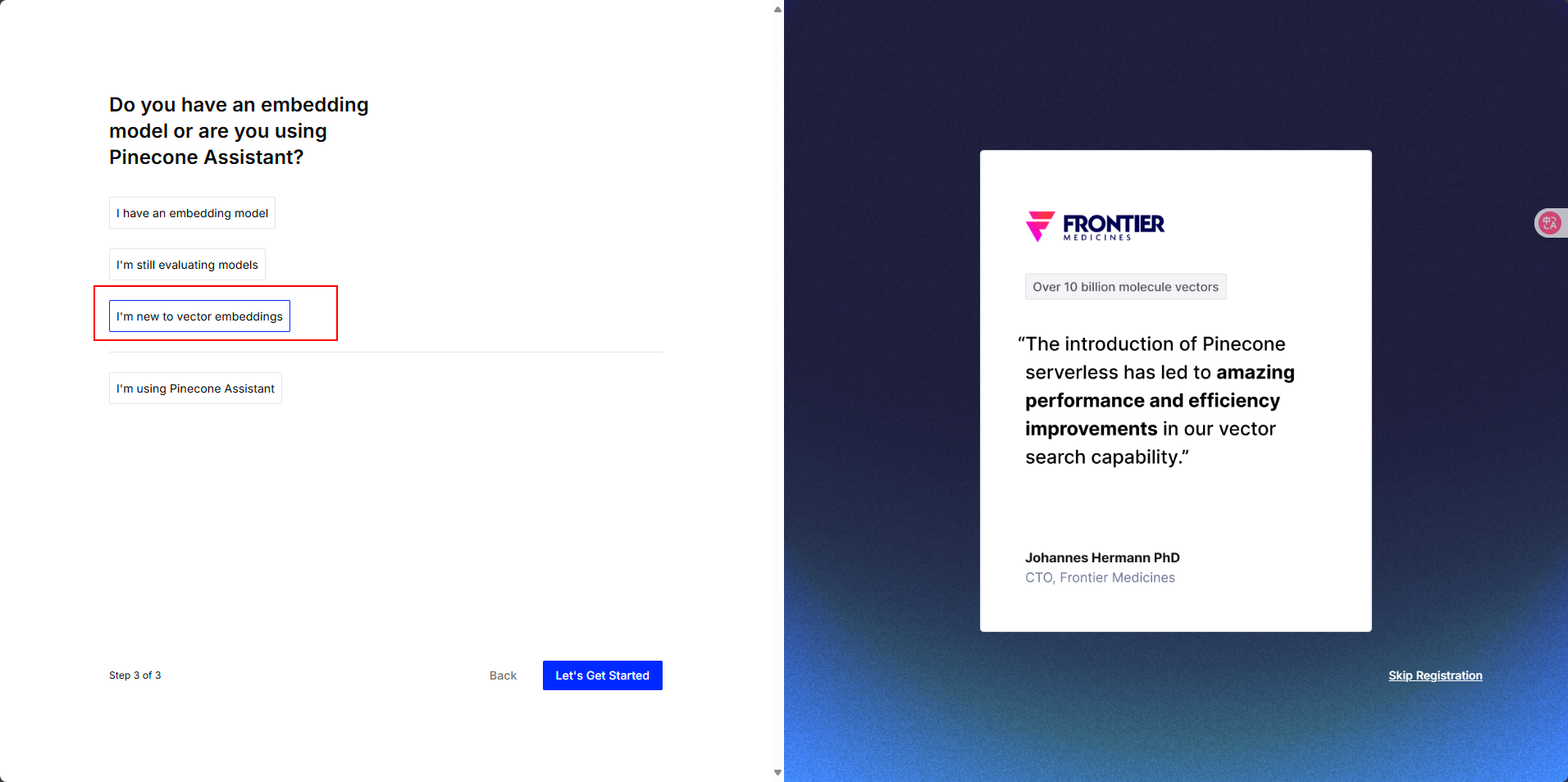
弹出提示自己的key,一定要记下来,保存好
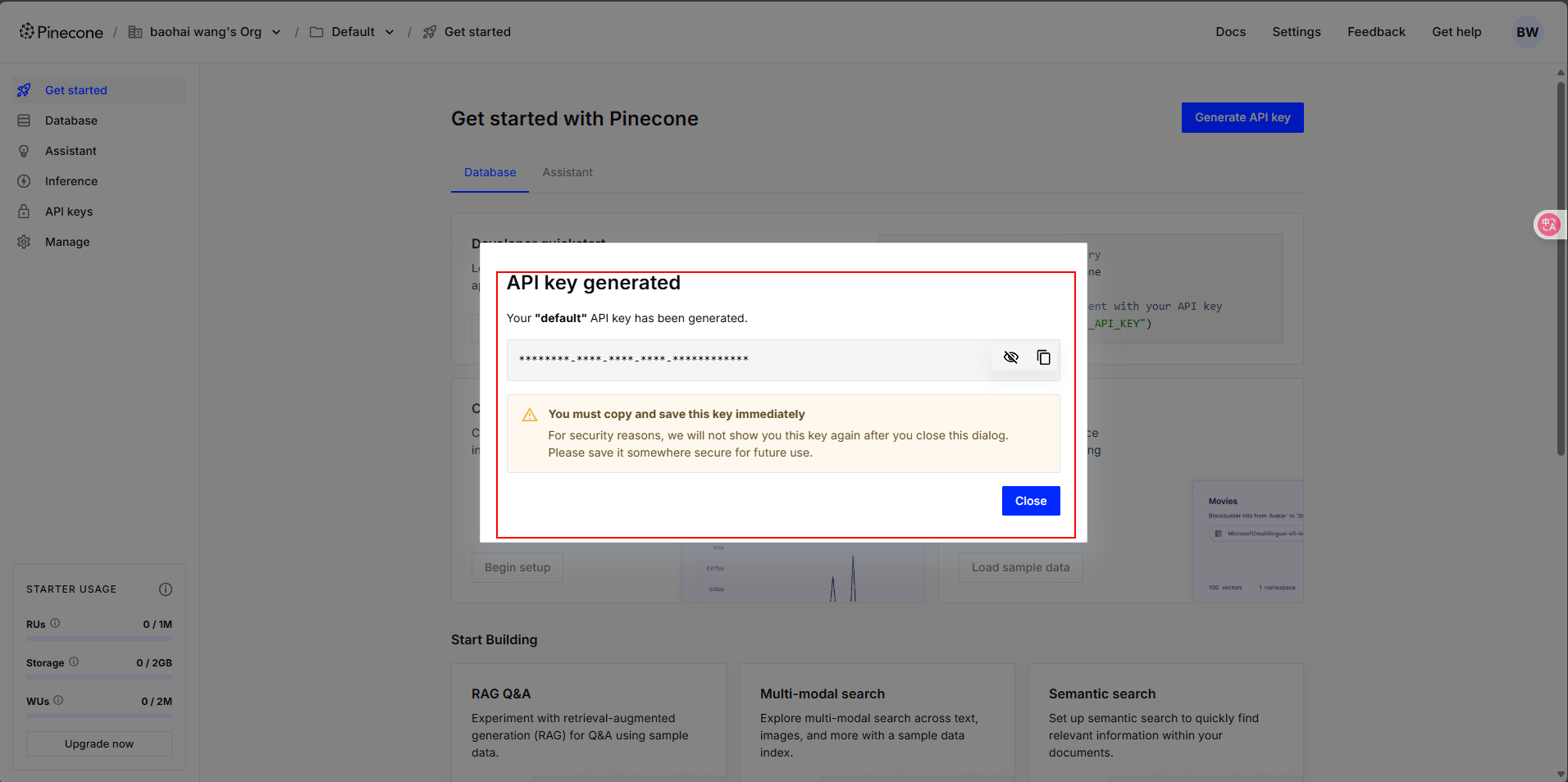
② 创建向量数据库
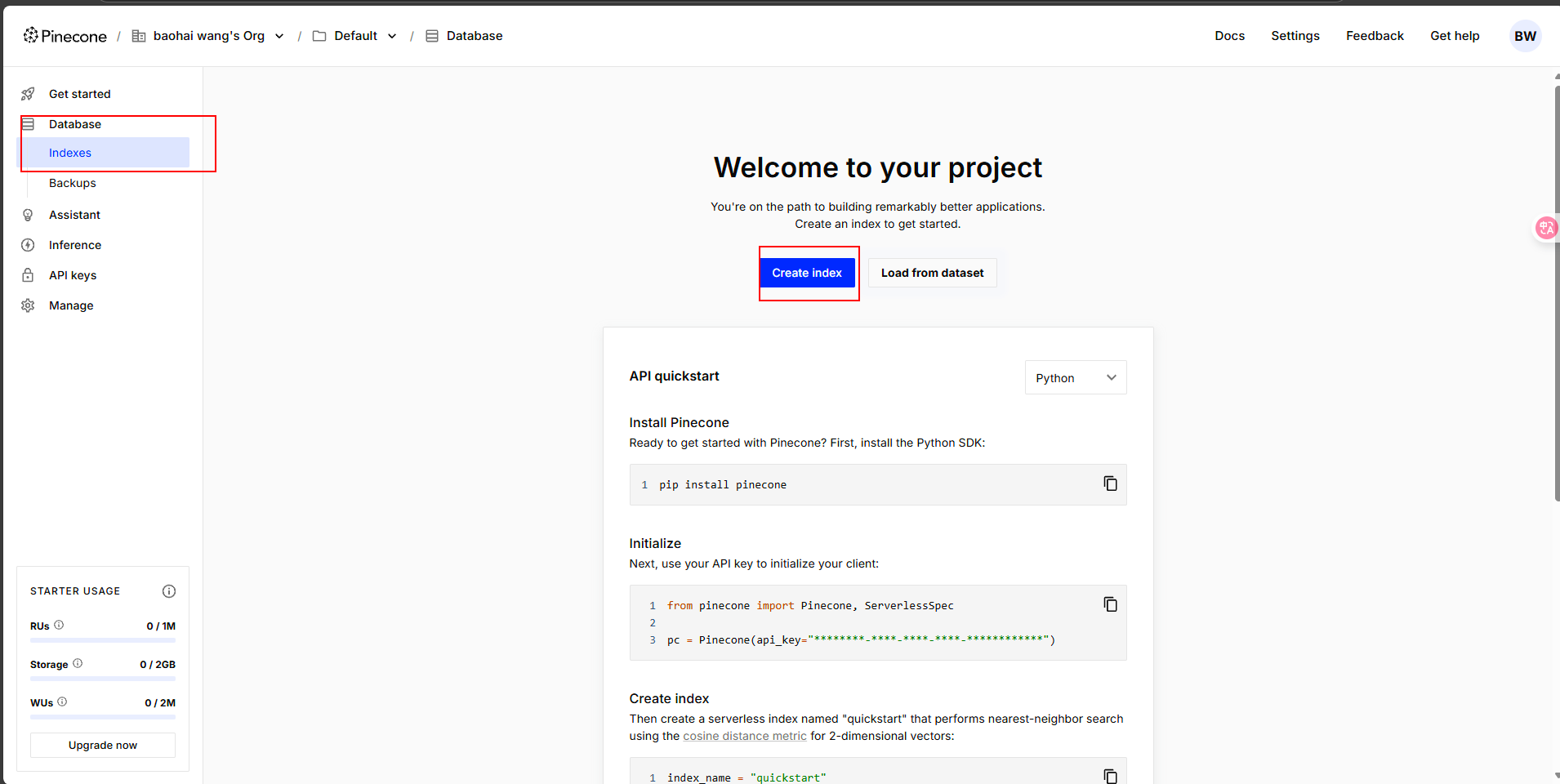
输入数据库名字,其他默认即可
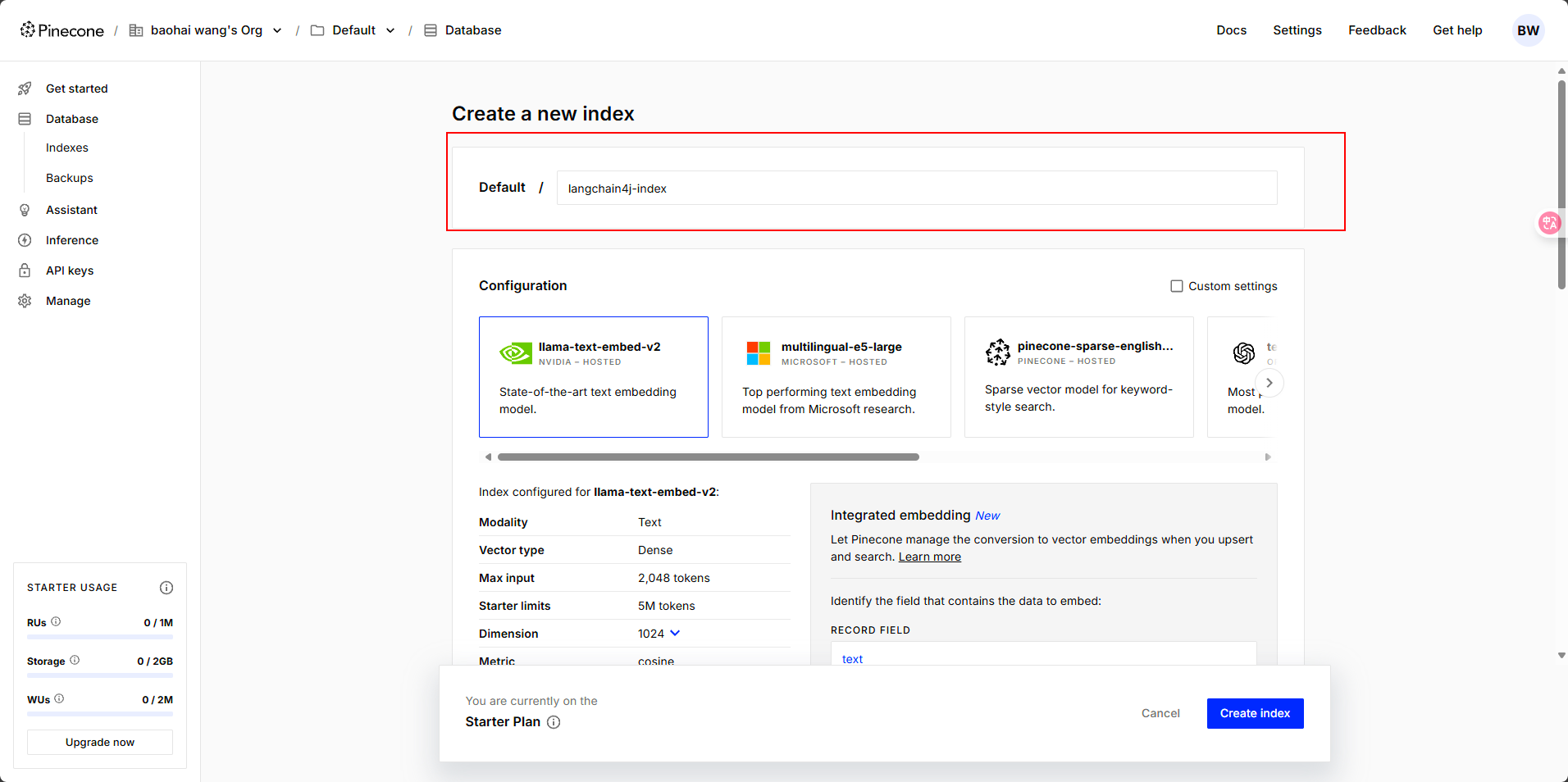
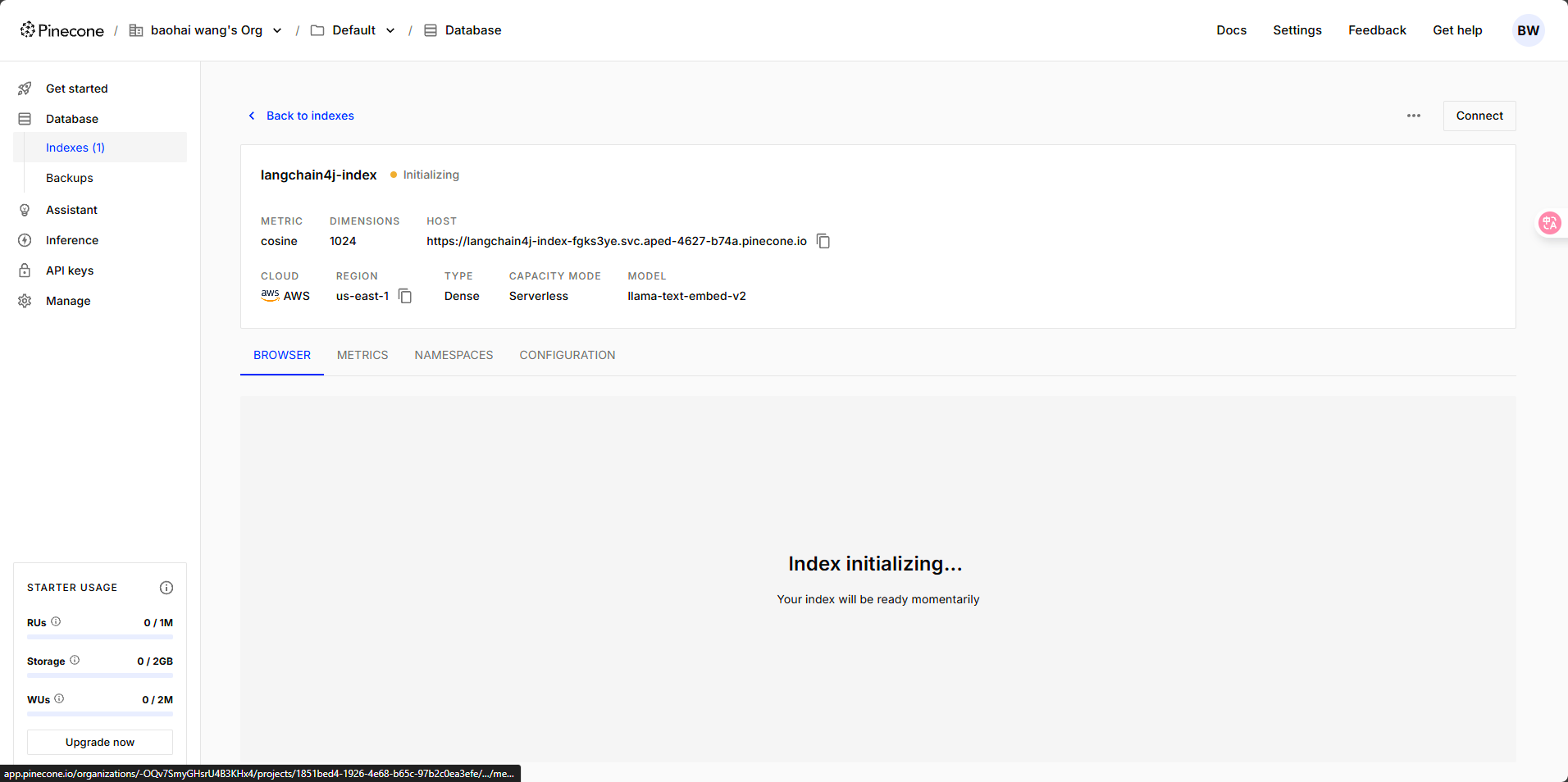
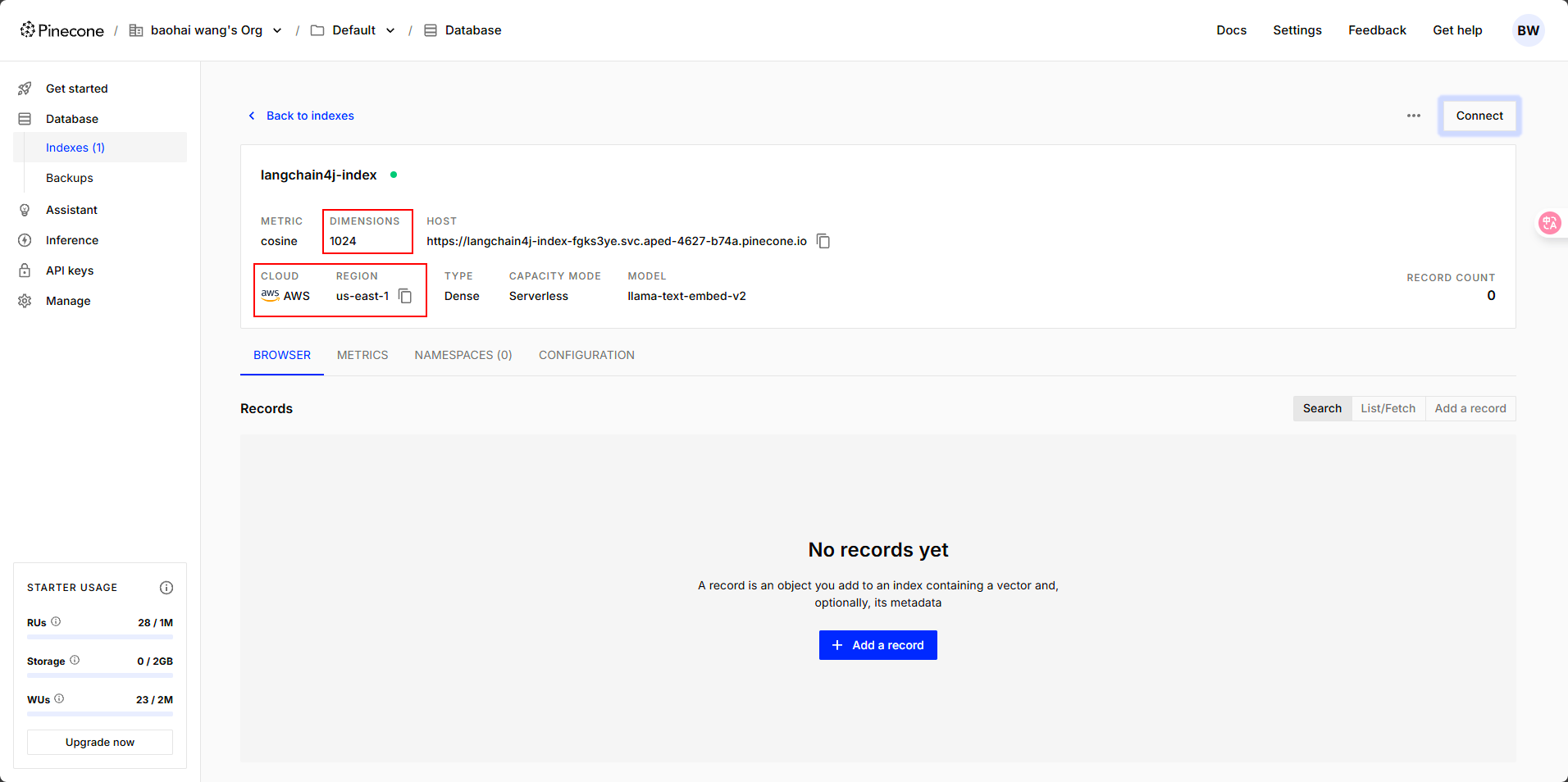
这里有一点需要注意,数据库中的 Dimensions 是向量维度的意思,这里默认的维度是 1024。我们在选择向量模型的时候,维度数值需要保持一致。
六、向量维度解读
① 什么是“向量”?
在二维平面里,一个点的位置可以用 (x, y) 来表示:向右走 x 个单位、向上走 y 个单位,就到达了这个点。这个 (x, y) 就是一个二元向量,或者说“二维向量”。
在数学上,向量(vector)是一个在空间里既有大小(length/长度)又有方向(direction)的量。用数值来表示时,向量就变成了“数字的有序列表”——比如 (3, 4)、(-1, 7, 2) 等。
② 向量维度(dimension)究竟指的是什么?
(1) 在几何空间里的维度
二维向量:如 (x, y),维度为 2,代表在平面上的位置或方向。
三维向量:如 (x, y, z),维度为 3,代表在三维空间里的位置。比如我们在现实中生活的空间就可以用三维向量表示:向右/左、向前/后、向上/下。
一维向量:如 (x),维度为 1,本质上是一个数值。比如在数轴上某一点的位置就可以看作一维。
维度(dimension)在几何里就是“空间的自由度”或“坐标数量”,对应我们给定一个点需要多少个数值来描述。
(2) 在机器学习/嵌入(Embedding)里的维度
当我们把一段文字、一张图片、一个声音等“复杂对象”转成向量时,并不再局限于“2 维”或“3 维”这样直观几何意义上的维度,而是会用“更高维度”的数值列表来表达更丰富的语义或特征。比如一个文本句子可能被编码成一个 512 维、768 维、甚至 1536 维的向量。这里的“维度数(512、768、1536……)”并不是“几何中的坐标长度”,而是“特征空间(feature space)”中“特征维度”的数量。
举个例子:如果我们把一段简单句子看作一个“物品”,然后把它拆分成若干个“语义属性”(比如:情感倾向、有无否定、主题领域、句子长度、关键词出现频次……)这些属性越多,就需要更多的维度去表示。于是就产生了“高维向量”。
在深度学习模型(如 BERT、GPT、Sentence-BERT 等)中,模型会在训练时学习到一个“映射函数”,将任意一句话或文档映射到一个固定长度的向量(例如 768 维)。这个 768 维的向量里,每一维都是一个“抽象的特征值”,它并不代表人眼能直观理解的“‘颜色’、‘长度’”之类的东西,而是“模型通过数千万篇文本学习后抽象出的特征分量”。
(3) 为什么要用高维向量?
信息容量:高维向量能承载更多的“语义信息”或“特征组合”。在 2 维/3 维中我们很难用数字表示复杂的句子含义,但在几百维里,模型可以把“情感”、“主题”“相似度”等不同层面混合编码。
区分度更高:假设我们用 2 维向量去表示所有中文句子,那么很多不同意思的句子就可能挤在非常相近的位置、相互混淆。高维空间更容易把不一样的句子拉开距离,让相似的句子聚在一起,而与它无关的句子距离更远。
线性可分性:在高维空间里,数据往往更容易通过“线性变换”或“简单几何操作”分离开来。许多经典机器学习理论(比如支持向量机的核函数方法)都基于“在高维空间里更容易找到分界面”这一思路。
③ 如何理解“向量维度”在 RAG 中的作用?
(1) 从文本到向量(Embedding)
在 RAG 架构里,我们会把文档或句子“嵌入(Embedding)”为一个定长向量。比如我们选择了 768 维的嵌入模型(常见的 BERT、SBERT、OpenAI 的 text-embedding-ada-002 等),那么每个文档片段就会被编码成一个有 768 个数字组成的列表。
维度越多模型理论上能表达越丰富的特征细节,但计算量、存储量也更大。
维度越少越节省存储、速度越快,但信息可能被压缩得过于粗糙,表示能力下降。
所以选择向量维度时往往需要折中:比如 512、768、1024、1536 这样的常见设置。
(2) 高维空间的“距离”与“相似度”
当我们有了若干个高维向量(比如多个文档片段),要知道用户提问与哪个片段“最相关”,就需要“在高维空间里量距离”。
常见的相似度度量:余弦相似度——衡量两个向量之间的夹角余弦值,范围在 -1 到 +1 之间。值越接近 1 表示两者方向越一致(即语义越相似)。欧氏距离——直观地计算高维空间里的距离长度,距离越短意味着越相似。
在高维空间里,语义相近的句子会在许多维度上的数值都比较接近,形成“高维邻居”——这样用余弦或欧式距离衡量时,就更容易找到真正语义最相近的文档片段。如果维度过低(比如只有 2 维或 3 维),那么许多不同含义的句子就会被挤在“视图”里相互重叠,检索效果会变差。
④ 通俗比喻
以“菜的味道”做比喻:一道菜的“味道特点”可以由“咸度、甜度、酸度、辣度、鲜味”……等多个指标来衡量,每个指标就是一个“维度”。如果只拿“咸度”一个指标(1 维)判断两道菜是否类似,很容易出错。但如果有 5、10 个维度,就能更准确。
六、使用向量数据库
① 添加依赖
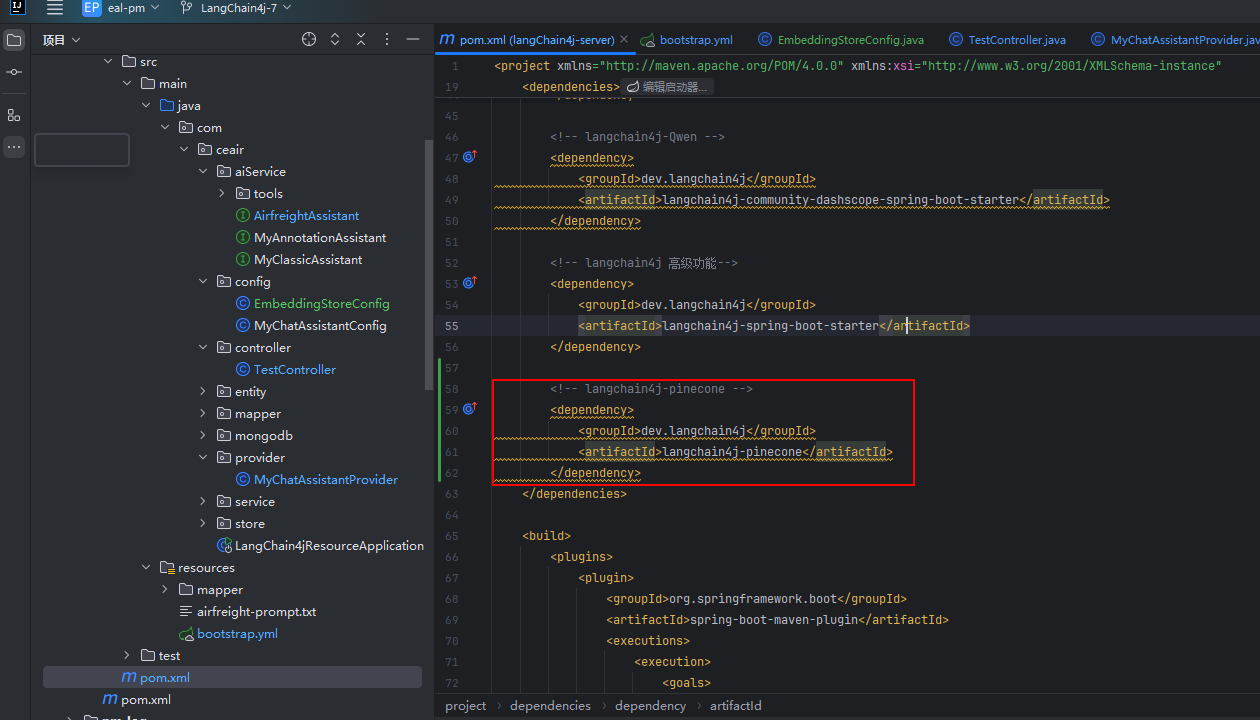
<!-- langchain4j-pinecone -->
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-pinecone</artifactId>
</dependency>② 添加配置文件
我们需要添加通义向量模型的配置,以及向量数据库的配置。
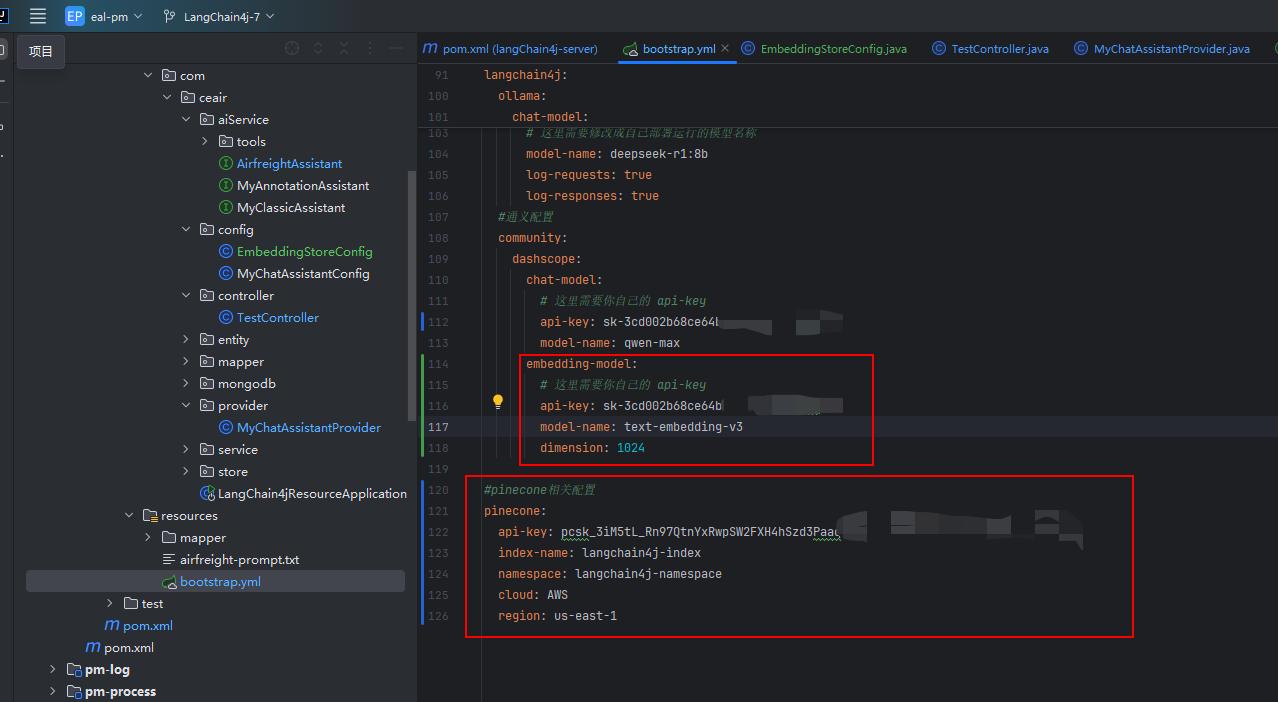
(1) 通义的向量模型配置说明
通义向量模型清单
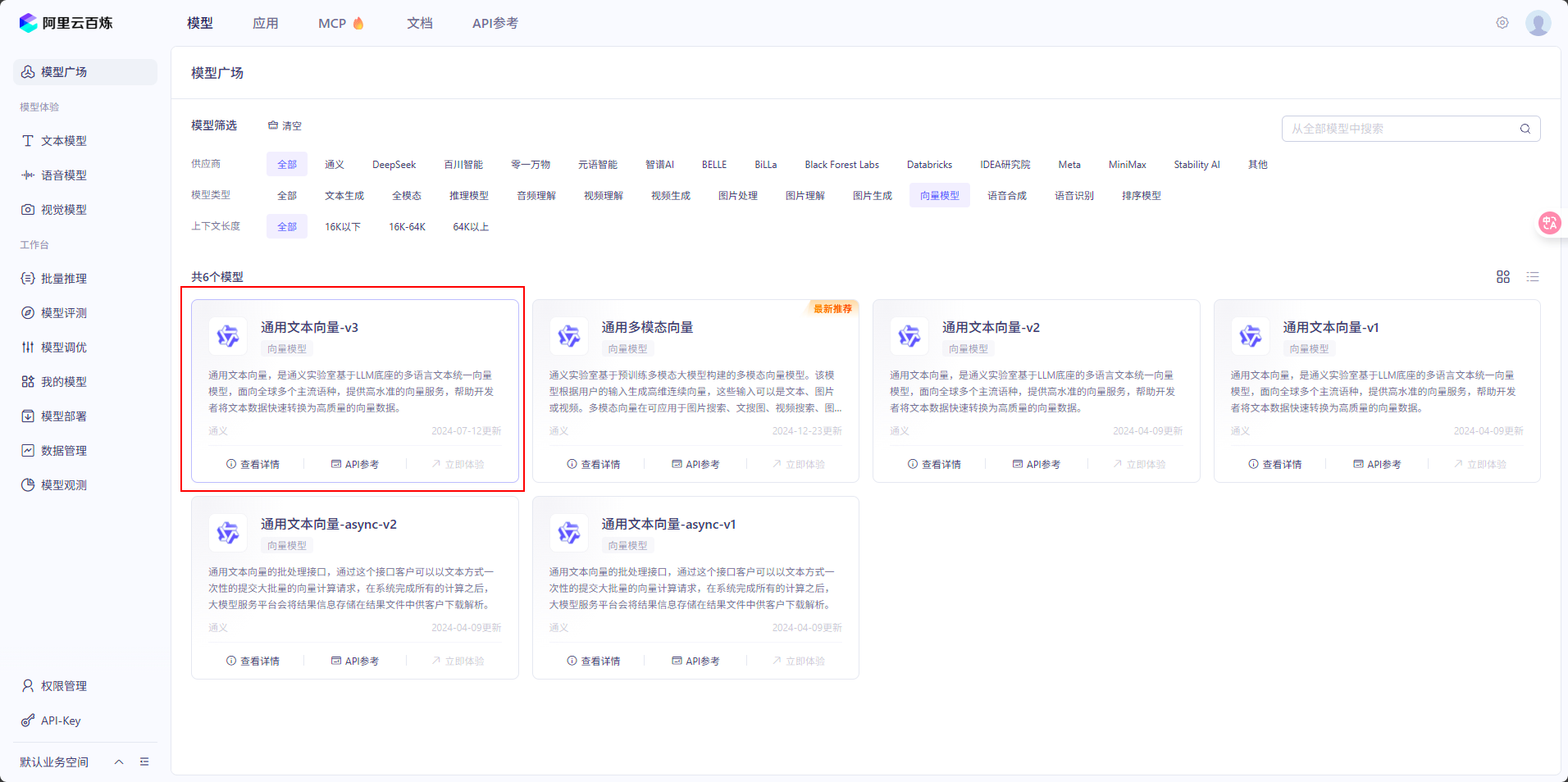
我们选择第一个,进入API参考,可以看到向量维度支持 1024
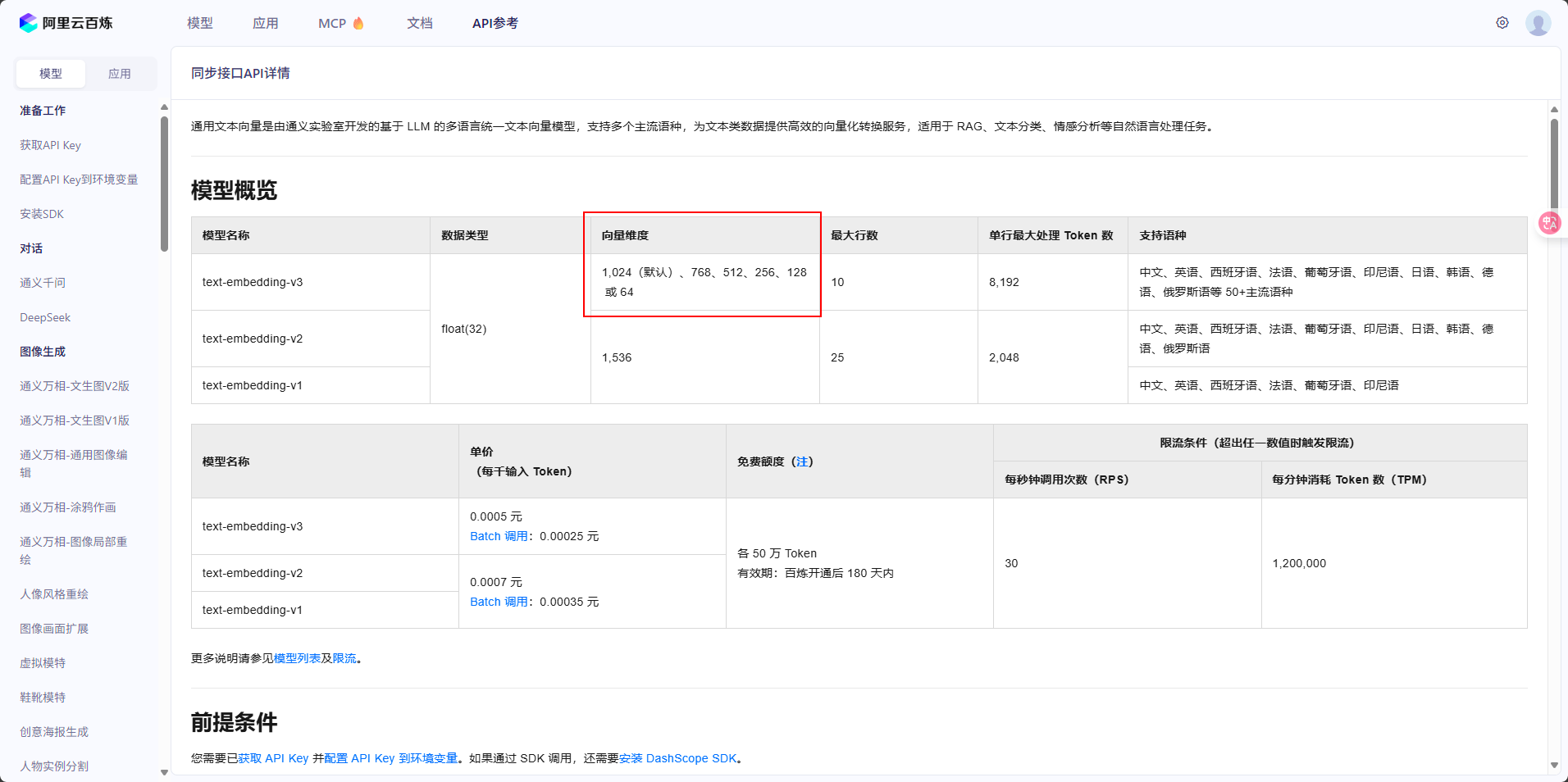
(2) 向量数据库的配置说明
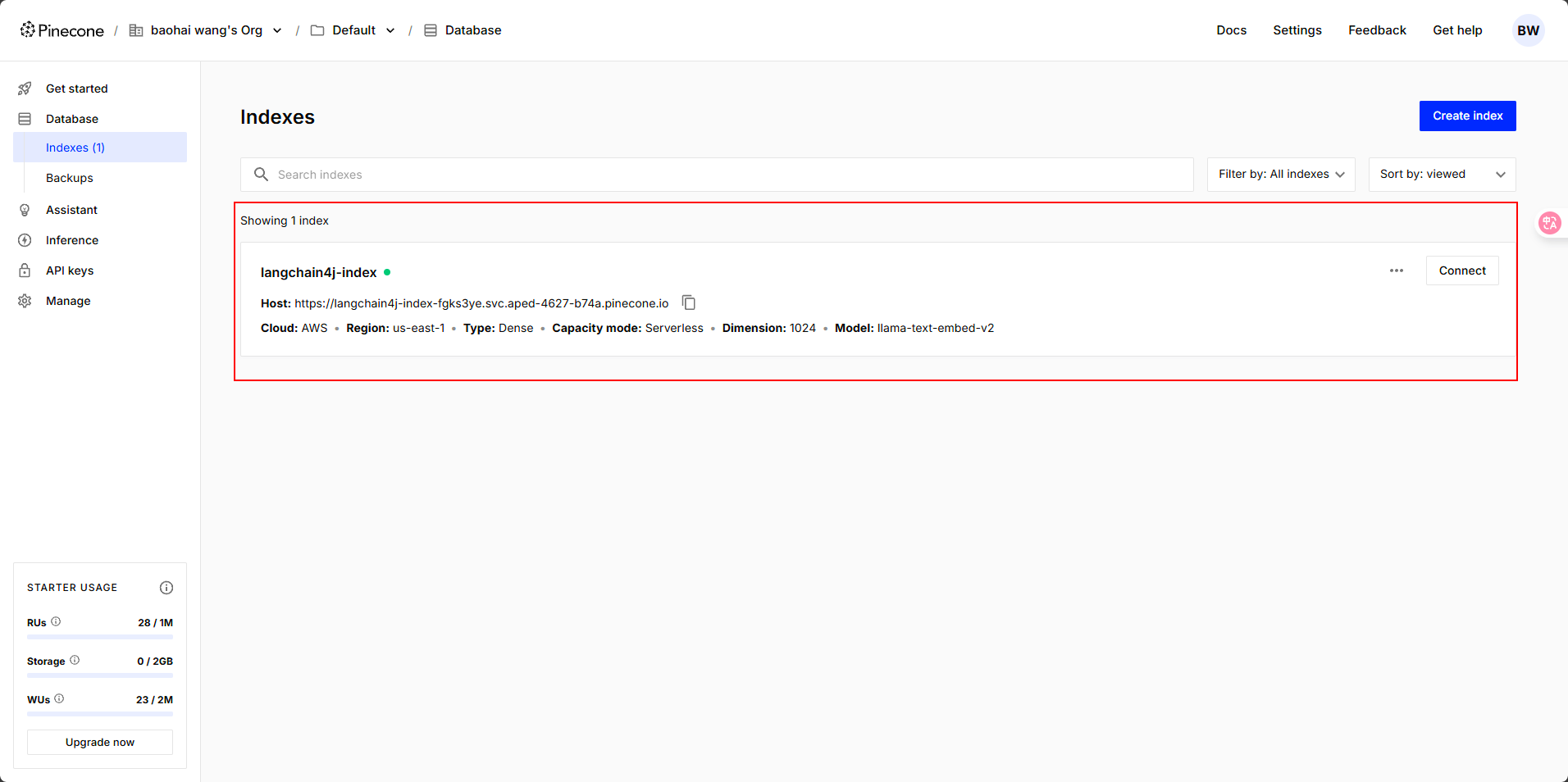
api-key就是我们注册的时候平台发放给我们的,其他信息在我们创建好的向量数据库里可以查看到。
③ 添加配置类
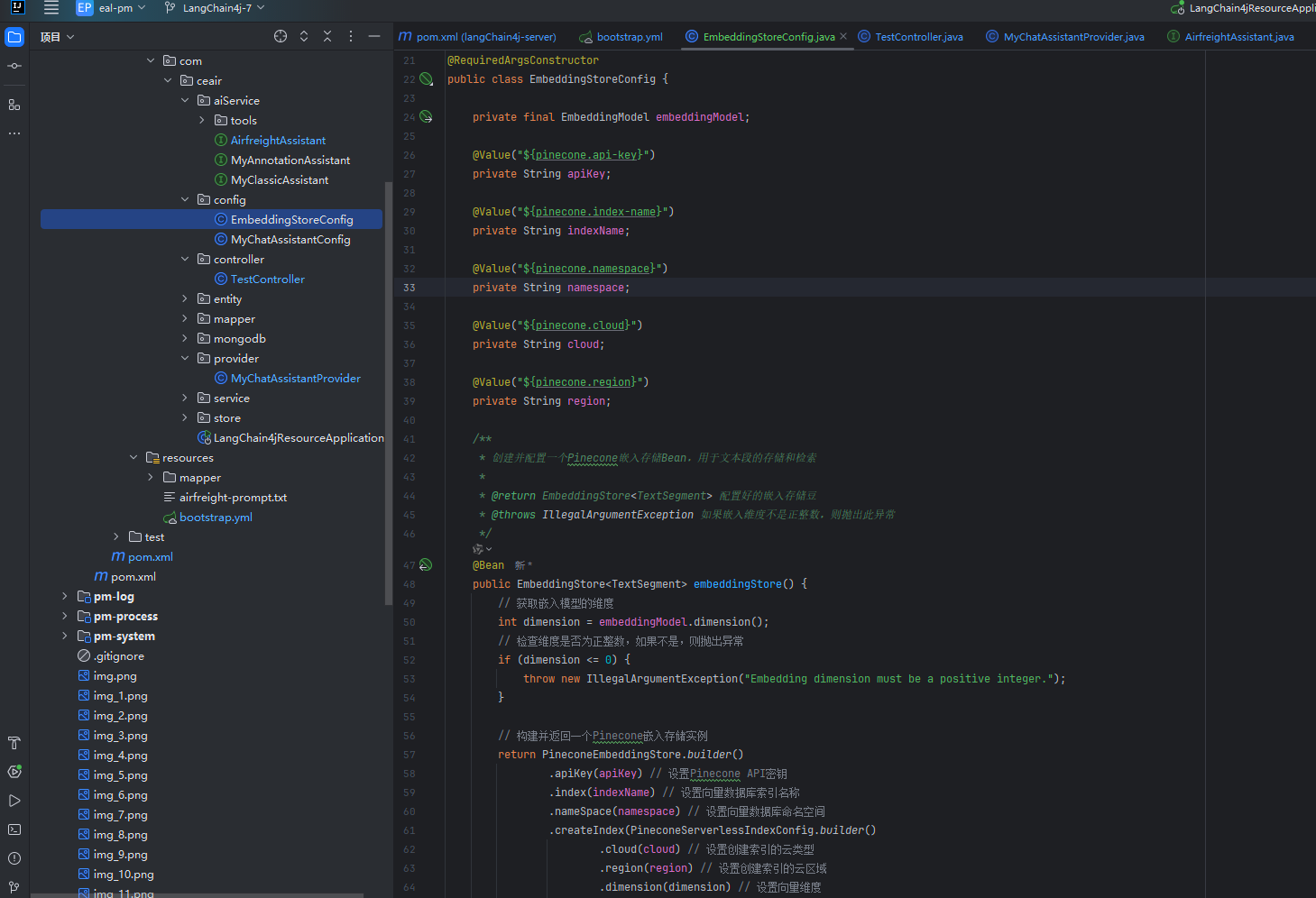
package com.ceair.config;import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeEmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeServerlessIndexConfig;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @author wangbaohai* @ClassName EmbeddingStoreConfig* @description: 向量数据库配置文件* @date 2025年05月23日* @version: 1.0.0*/
@Configuration
@RequiredArgsConstructor
public class EmbeddingStoreConfig {private final EmbeddingModel embeddingModel;@Value("${pinecone.api-key}")private String apiKey;@Value("${pinecone.index-name}")private String indexName;@Value("${pinecone.namespace}")private String namespace;@Value("${pinecone.cloud}")private String cloud;@Value("${pinecone.region}")private String region;/*** 创建并配置一个Pinecone嵌入存储Bean,用于文本段的存储和检索** @return EmbeddingStore<TextSegment> 配置好的嵌入存储豆* @throws IllegalArgumentException 如果嵌入维度不是正整数,则抛出此异常*/@Beanpublic EmbeddingStore<TextSegment> embeddingStore() {// 获取嵌入模型的维度int dimension = embeddingModel.dimension();// 检查维度是否为正整数,如果不是,则抛出异常if (dimension <= 0) {throw new IllegalArgumentException("Embedding dimension must be a positive integer.");}// 构建并返回一个Pinecone嵌入存储实例return PineconeEmbeddingStore.builder().apiKey(apiKey) // 设置Pinecone API密钥.index(indexName) // 设置向量数据库索引名称.nameSpace(namespace) // 设置向量数据库命名空间.createIndex(PineconeServerlessIndexConfig.builder().cloud(cloud) // 设置创建索引的云类型.region(region) // 设置创建索引的云区域.dimension(dimension) // 设置向量维度.build()).build();}}
七、智能体添加RAG能力
① 添加向量检索工具
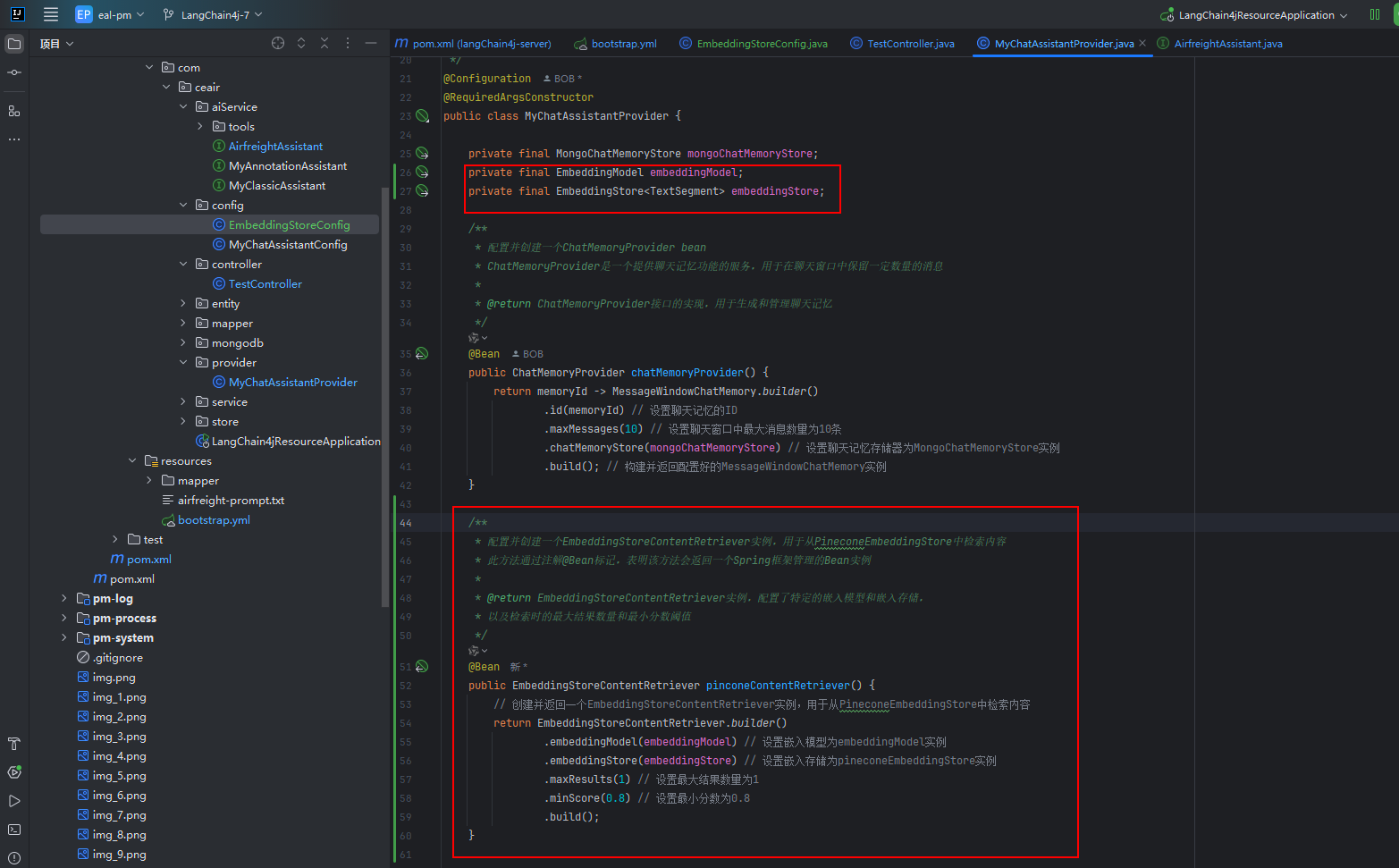
private final EmbeddingModel embeddingModel;
private final EmbeddingStore<TextSegment> embeddingStore;/*** 配置并创建一个EmbeddingStoreContentRetriever实例,用于从PineconeEmbeddingStore中检索内容* 此方法通过注解@Bean标记,表明该方法会返回一个Spring框架管理的Bean实例** @return EmbeddingStoreContentRetriever实例,配置了特定的嵌入模型和嵌入存储,* 以及检索时的最大结果数量和最小分数阈值*/
@Bean
public EmbeddingStoreContentRetriever pinconeContentRetriever() {// 创建并返回一个EmbeddingStoreContentRetriever实例,用于从PineconeEmbeddingStore中检索内容return EmbeddingStoreContentRetriever.builder().embeddingModel(embeddingModel) // 设置嵌入模型为embeddingModel实例.embeddingStore(embeddingStore) // 设置嵌入存储为pineconeEmbeddingStore实例.maxResults(1) // 设置最大结果数量为1.minScore(0.8) // 设置最小分数为0.8.build();
}② 为Aiserver注册检索工具
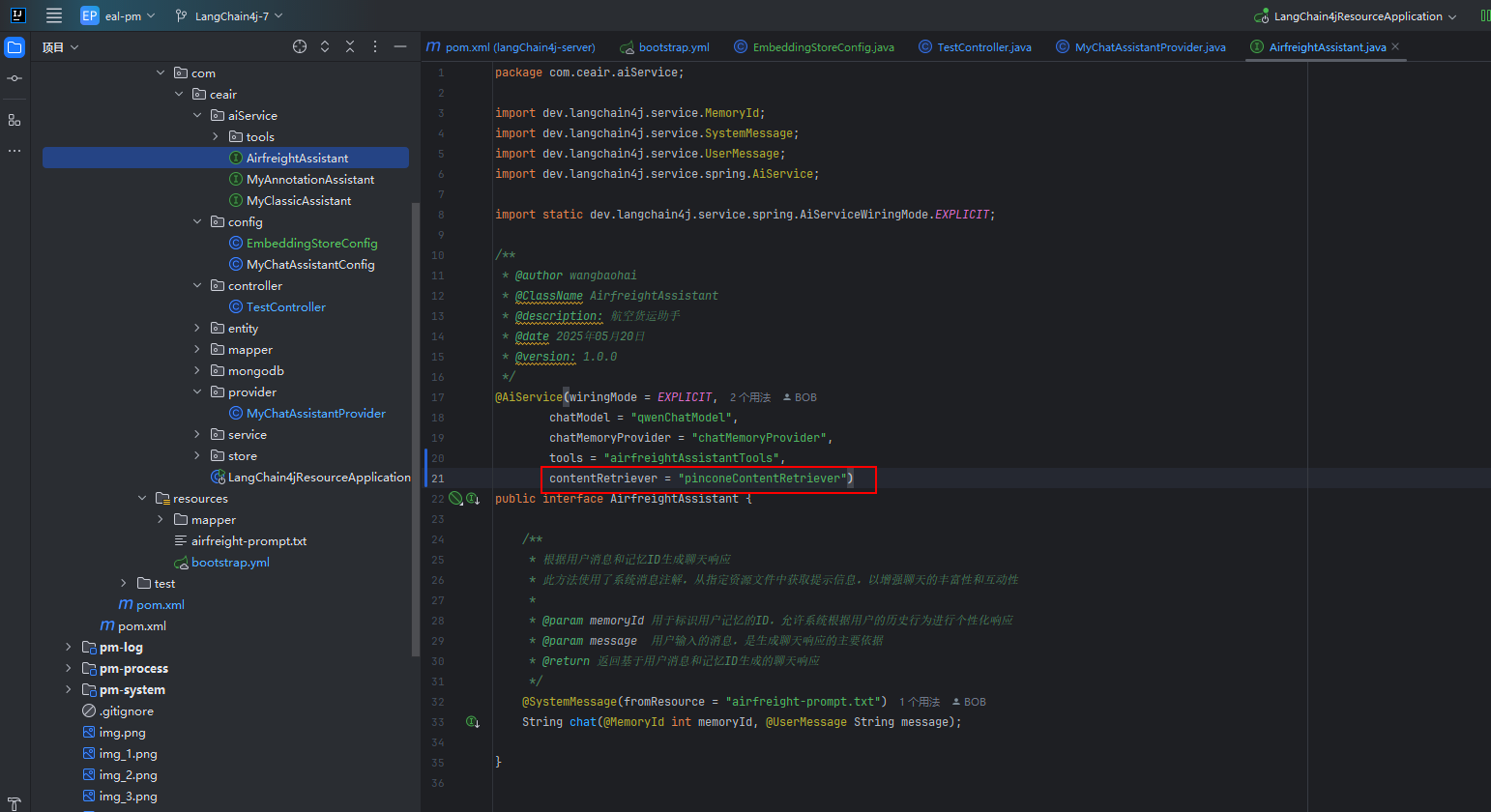
@AiService(wiringMode = EXPLICIT,chatModel = "qwenChatModel",chatMemoryProvider = "chatMemoryProvider",tools = "airfreightAssistantTools",contentRetriever = "pinconeContentRetriever")八、验证功能
① 添加上传知识文档测试工具
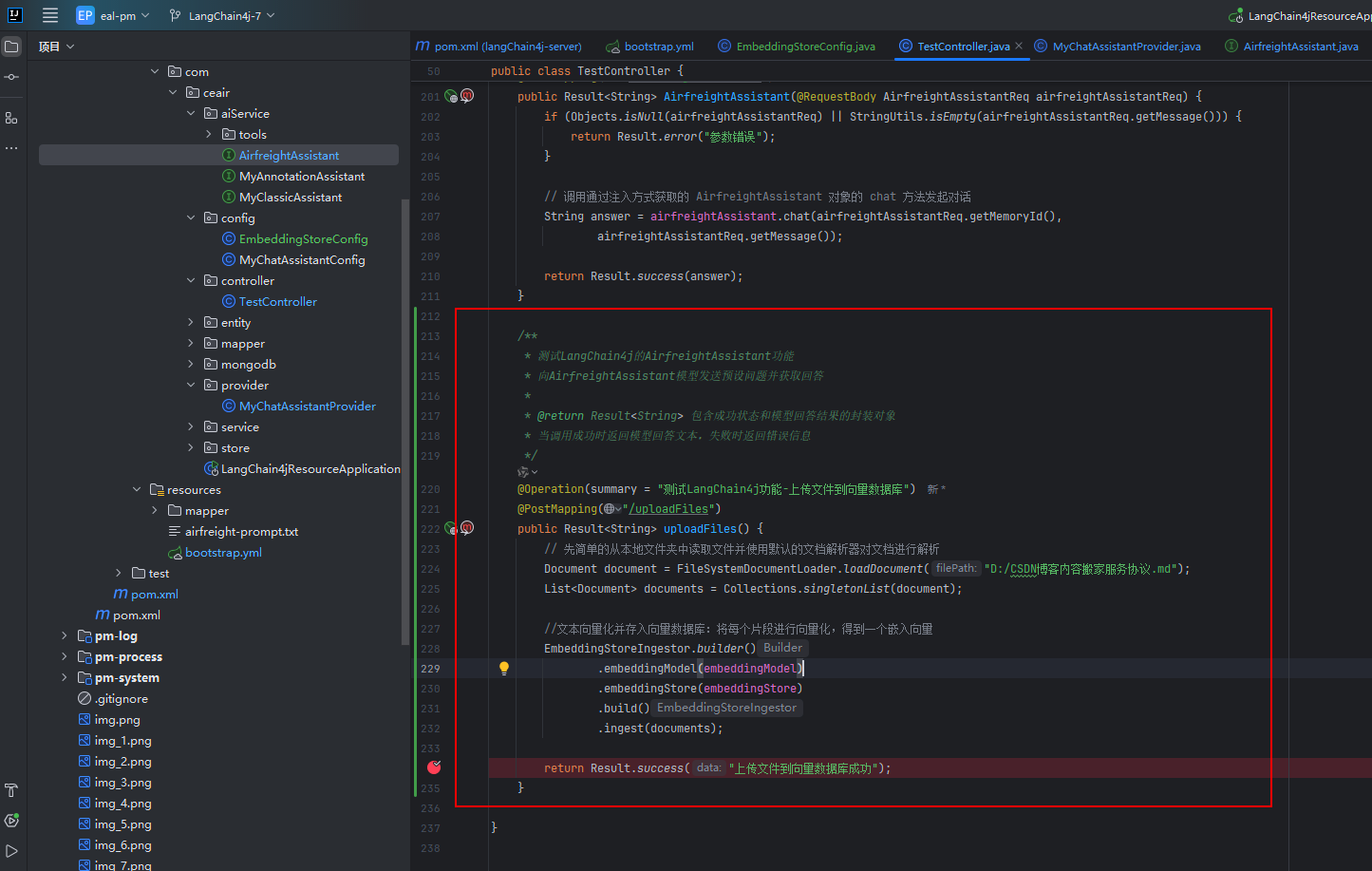
private final EmbeddingModel embeddingModel;
private final EmbeddingStore<TextSegment> embeddingStore;/*** 测试LangChain4j的AirfreightAssistant功能* 向AirfreightAssistant模型发送预设问题并获取回答** @return Result<String> 包含成功状态和模型回答结果的封装对象* 当调用成功时返回模型回答文本,失败时返回错误信息*/
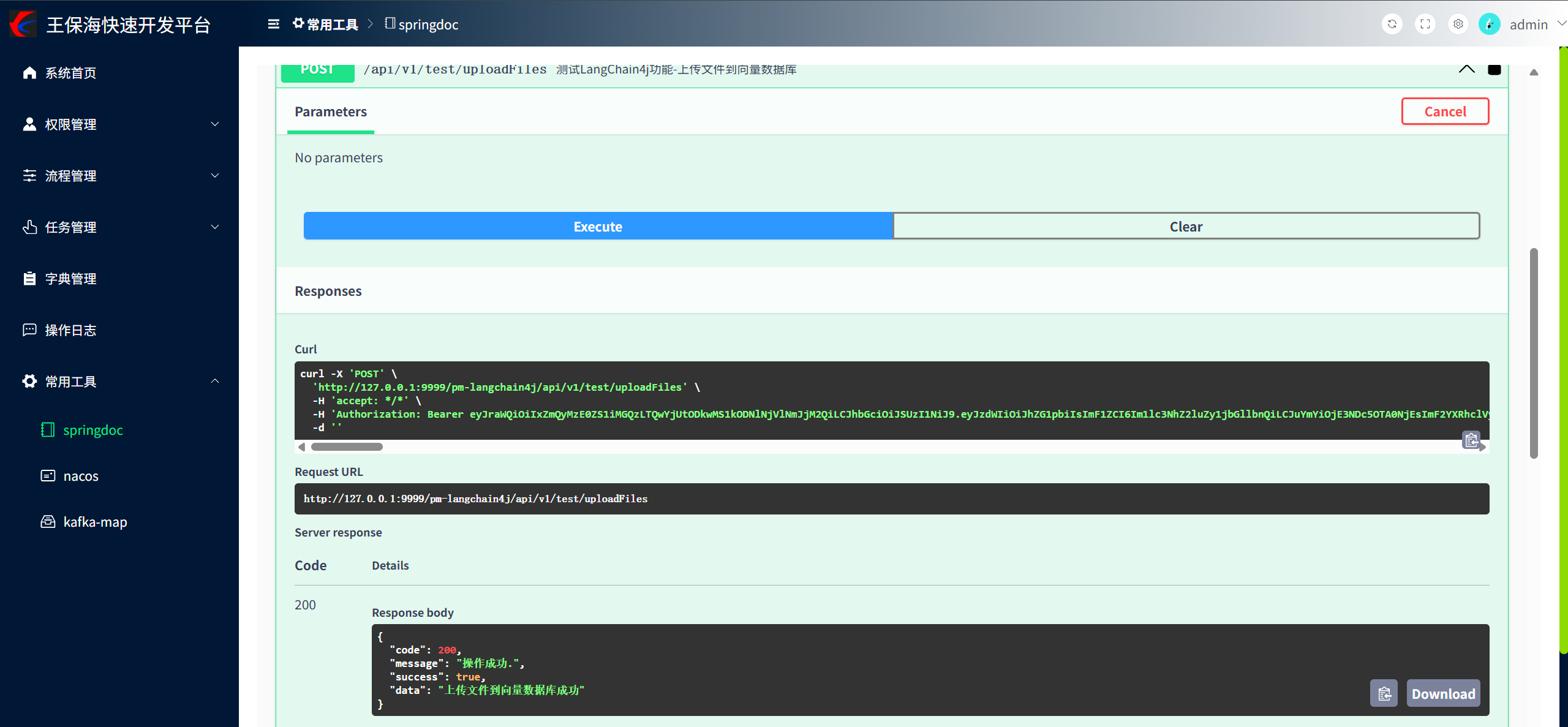
@Operation(summary = "测试LangChain4j功能-上传文件到向量数据库")
@PostMapping("/uploadFiles")
public Result<String> uploadFiles() {// 先简单的从本地文件夹中读取文件并使用默认的文档解析器对文档进行解析Document document = FileSystemDocumentLoader.loadDocument("D:/CSDN博客内容搬家服务协议.md");List<Document> documents = Collections.singletonList(document);//文本向量化并存入向量数据库:将每个片段进行向量化,得到一个嵌入向量EmbeddingStoreIngestor.builder().embeddingModel(embeddingModel).embeddingStore(embeddingStore).build().ingest(documents);return Result.success("上传文件到向量数据库成功");
}② 准备知识文档
知识文档内容,将这个内容保存为md文件,放到D盘的根目录。
③ 调用接口上传向量数据库
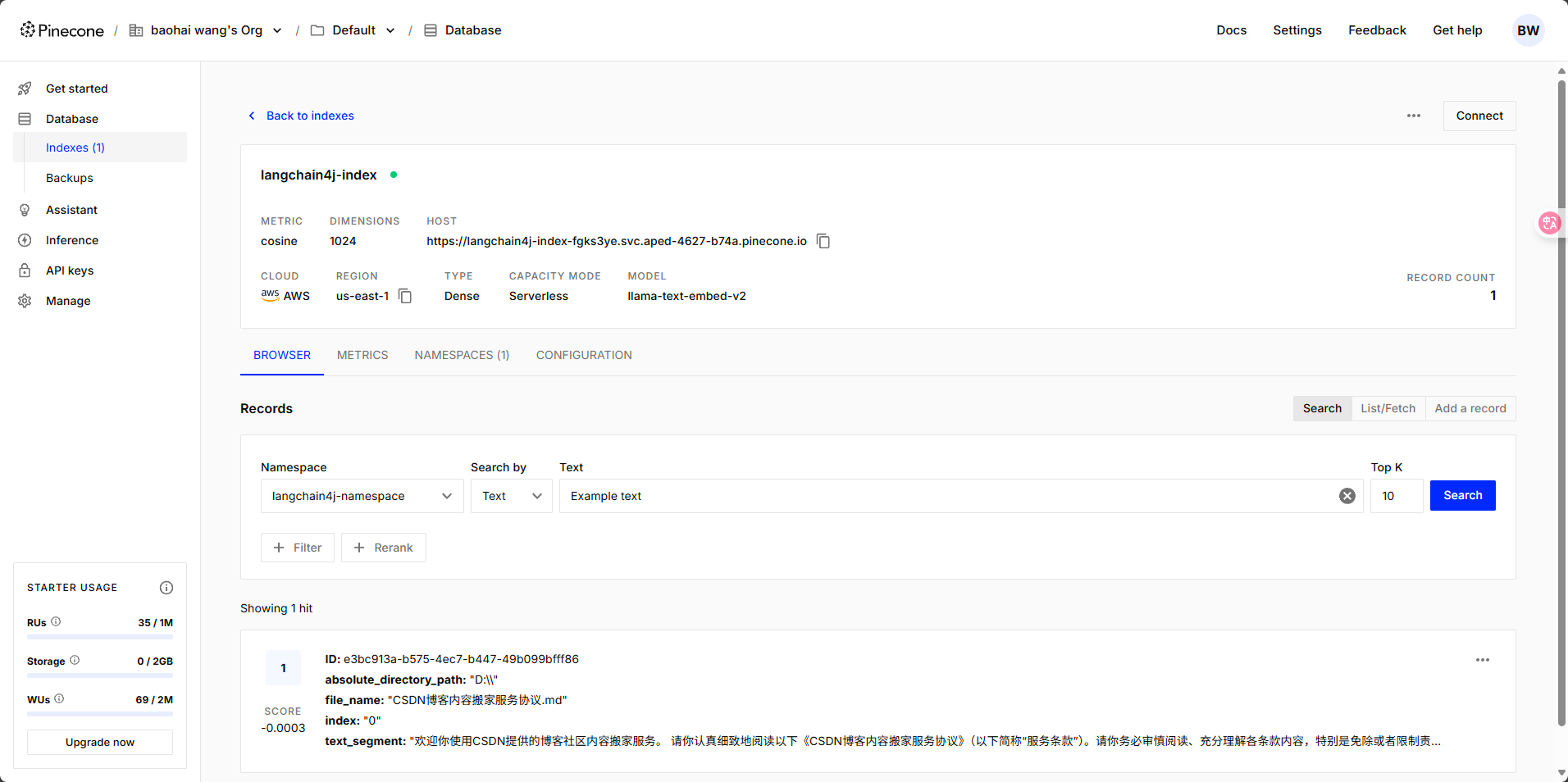
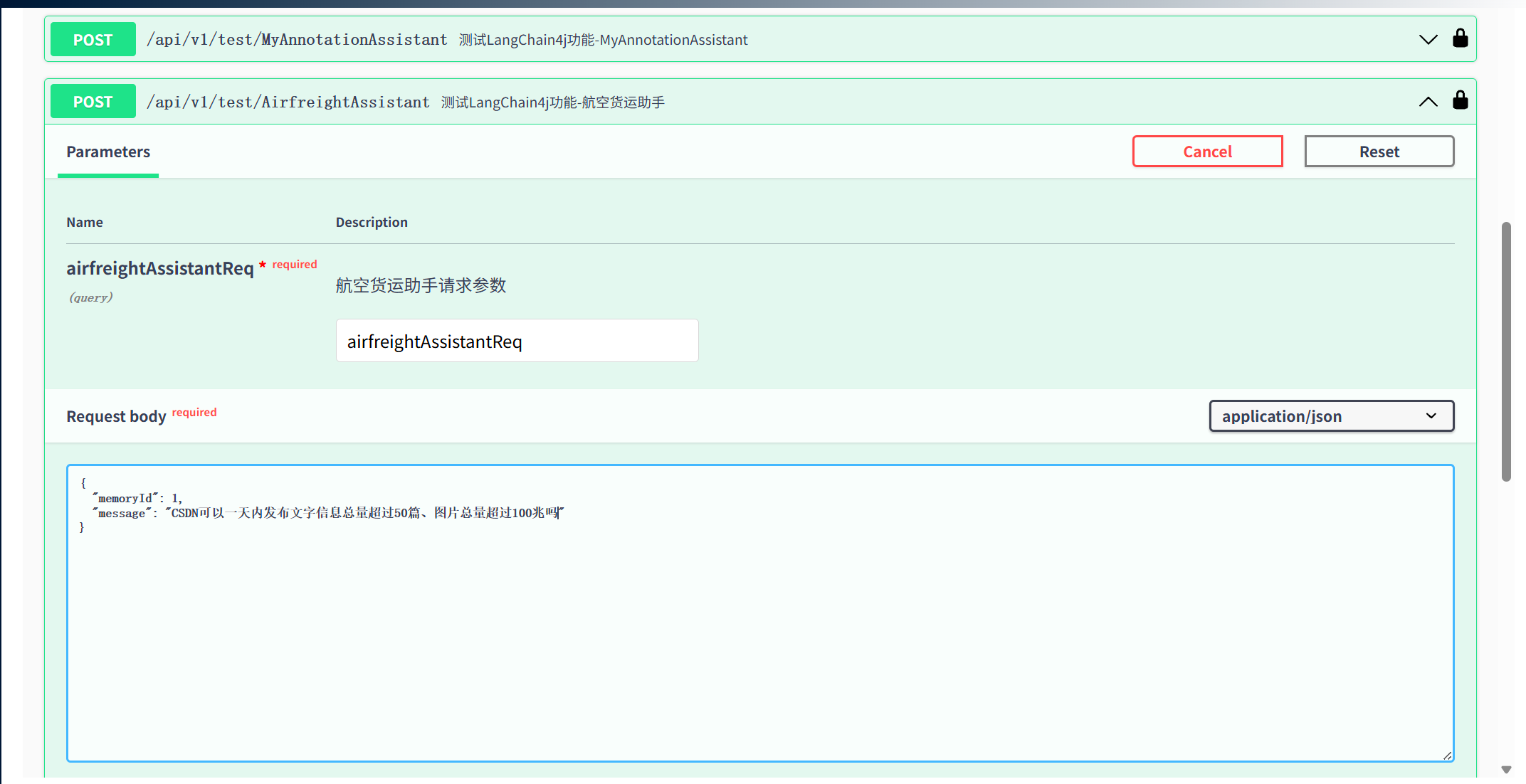
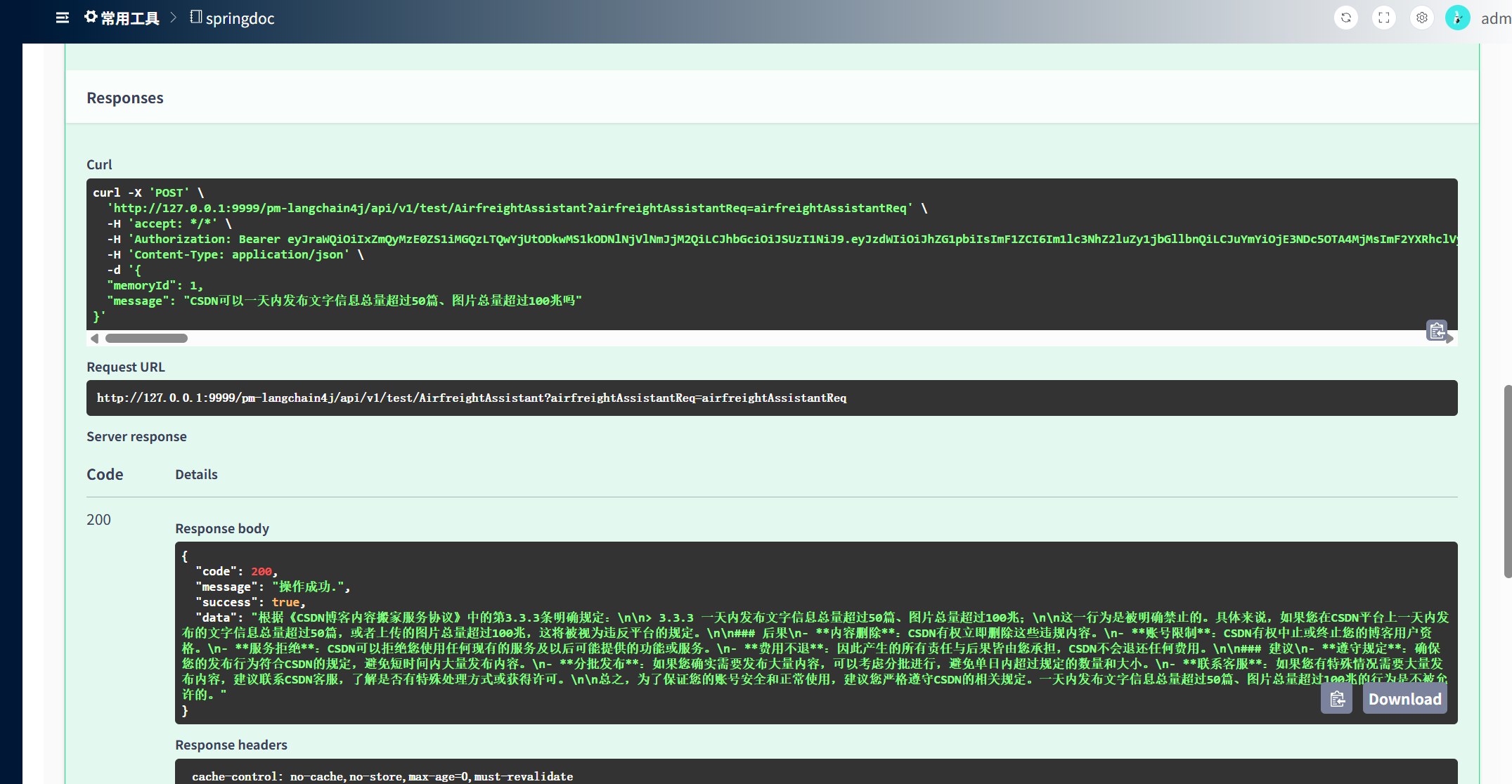
④ 调用AiService验证RAG
提问:CSDN可以一天内发布文字信息总量超过50篇、图片总量超过100兆吗,可以看到回答中已经检索到了私有的知识库。
后记
按照一篇文章一个代码分支,本文的后端工程的分支都是 LangChain4j-7,前端工程的分支是 LangChain4j-1。
后端工程仓库:后端工程
前端工程仓库:前端工程



带论文文档1万字以上,文末可获取,系统界面在最后面。)

作为另一个http接口的请求参数)








)

)


