
一、CAP理论在服务注册与发现中的落地实践
1.1 CAP三要素的技术权衡
| 要素 | AP模型实现 | CP模型实现 |
|---|---|---|
| 一致性 | 最终一致性(Eureka通过异步复制实现) | 强一致性(ZooKeeper通过ZAB协议保证) |
| 可用性 | 服务节点可独立响应(支持分区存活) | 分区期间无法保证写操作(需多数节点可用) |
| 分区容错性 | 必须支持(分布式系统基本要求) | 必须支持(通过复制协议实现) |
典型场景对比:
- 电商秒杀(AP):允许部分用户看到旧服务列表,但保证页面可访问。
- 银行转账(CP):必须等待服务状态全局一致,避免资金不一致风险。
二、AP模型深度解析:高可用优先的设计哲学
2.1 核心场景与技术实现
2.1.1 适用场景特征
- 动态伸缩性要求高:
容器化环境中服务实例每分钟上下线超100次(如Kubernetes集群),AP模型的无主节点架构(如Eureka集群)可避免主节点成为瓶颈。 - 读多写少操作:
服务发现请求中查询占比>90%,写入(注册/注销)频率低,允许缓存数据短暂不一致。
2.1.2 关键技术方案
Eureka架构解析:
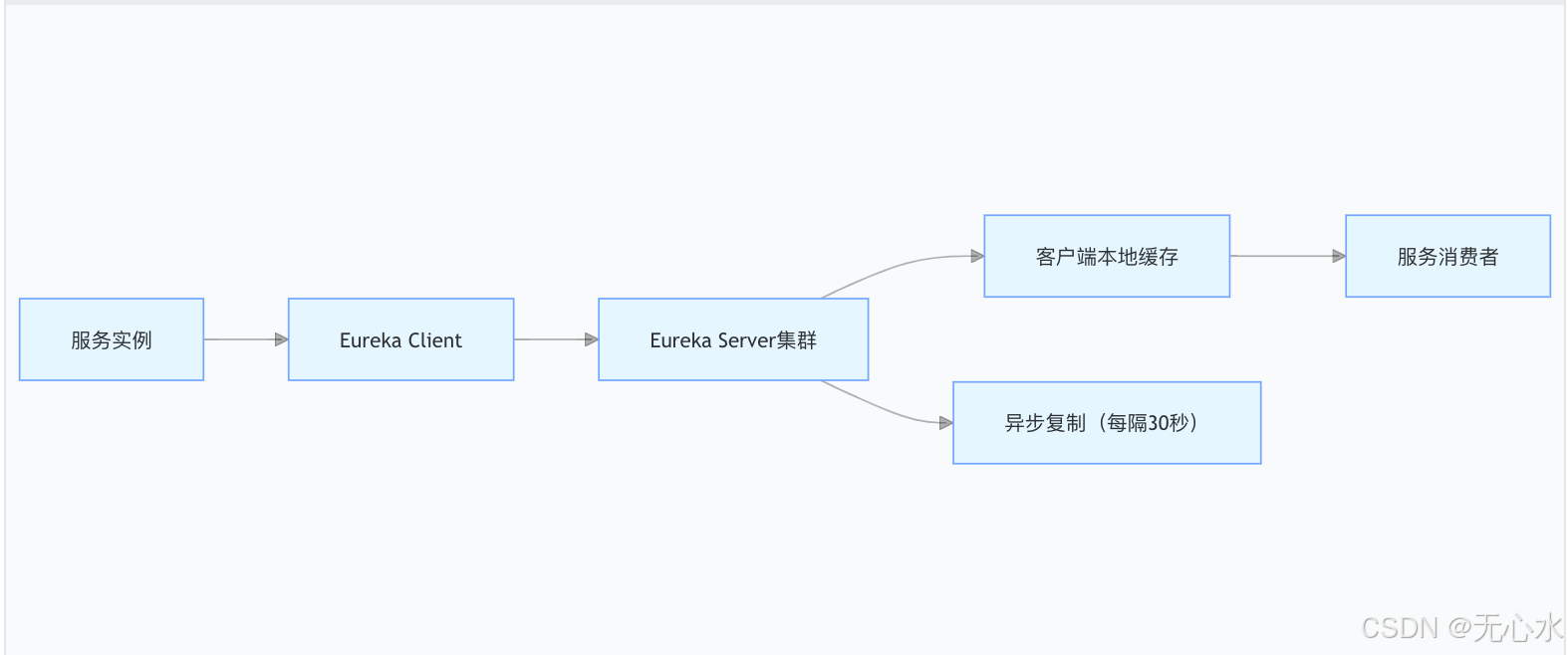
- 心跳机制:服务实例每30秒发送心跳,超时90秒标记为失效。
- 缓存策略:客户端缓存服务列表,默认30秒更新一次,注册中心宕机时仍可调用。
- 自我保护模式:当心跳失败比例>85%,停止剔除服务实例,避免网络分区误判。
Consul AP模式配置:
# consul配置文件
datacenter = "dc1"
server = true
bootstrap_expect = 3
# 开启AP模式(牺牲强一致性换取可用性)
disable_leader = true
disable_gossip = true
三、CP模型深度解析:强一致性优先的设计哲学
3.1 核心场景与技术实现
3.1.1 适用场景特征
- 分布式协调需求:
如Kubernetes的节点注册(需保证Pod列表实时一致)、分布式锁(如Redlock)。 - 配置中心场景:
服务配置变更(如限流规则)需秒级同步到所有节点,避免部分节点使用旧配置导致故障。
3.1.2 关键技术方案
ZooKeeper一致性实现:
- ZAB协议:
写请求由Leader节点处理,通过二阶段提交确保多数节点持久化后才返回成功。 - Watcher机制:
服务消费者监听节点变更事件,配置更新时主动推送通知(延迟<500ms)。
Etcd Raft协议流程:
// Etcd节点状态机
type NodeState int
const (Follower NodeState = iotaCandidateLeader
)// 选举流程
func (n *Node) startElection() {n.currentTerm++n.votedFor = n.idn.resetTimeout()// 向所有节点发送投票请求for _, peer := range n.peers {go n.sendRequestVote(peer, n.currentTerm, n.id)}
}
四、AP与CP的综合对比与选型框架
4.1 核心维度对比表
| 维度 | AP模型(Eureka) | CP模型(ZooKeeper) |
|---|---|---|
| 一致性级别 | 最终一致性(可能返回旧数据) | 强一致性(写操作等待多数节点确认) |
| 可用性 | 高(分区期间仍可读) | 中(分区时无法保证写可用性) |
| 吞吐量 | 高(无锁机制,支持横向扩展) | 中(受限于Leader节点性能) |
| 典型QPS | 10万+/秒(集群规模>10节点) | 1万+/秒(集群规模≤5节点) |
| 节点规模限制 | 无(理论支持无限节点) | ≤7节点(Raft协议最佳实践) |
| 运维复杂度 | 低(无主节点,自动负载均衡) | 高(需维护Leader选举与数据复制) |
4.2 三维度选型框架
4.2.1 业务容忍度维度
- 一致性容忍阈值:
- 允许数据不一致时间<10秒 → 选AP(如商品详情页服务发现)。
- 必须实时一致 → 选CP(如金融交易路由)。
- 可用性SLA:
- 99.99% → AP(通过多活数据中心实现)。
- 99.9% → 可接受CP(如内部管理系统)。
4.2.2 系统规模维度
- 服务实例数:
- >1000个 → AP(Eureka/Consul更适合大规模动态节点)。
- <100个 → CP(ZooKeeper/Etcd管理成本低)。
- 网络分区概率:
- 云原生环境(跨可用区部署)→ AP(分区概率高,需快速 failover)。
- 单数据中心 → CP(分区概率低,优先保证一致性)。
4.2.3 技术生态维度
- Kubernetes场景:
首选CP(Etcd作为默认注册中心,支持K8s强一致性需求)。 - Spring Cloud场景:
可选AP(Eureka已停更,推荐Consul混合模式)。
五、现代架构中的混合策略与优化方案
5.1 分层设计:核心服务与边缘服务分离
graph TBA[业务系统] --> B[核心服务层(CP)]A --> C[边缘服务层(AP)]B --> D[Etcd(强一致性)]C --> E[Consul(AP模式)]D --> F[支付/交易服务]E --> G[推荐/营销服务]
- 核心层:支付、用户中心等使用Etcd,保证交易路由实时一致。
- 边缘层:推荐服务、静态资源服务使用Consul AP模式,提升高并发下的可用性。
5.2 服务网格(Service Mesh)方案
Istio + Etcd架构:
graph LRA[客户端] --> B[Envoy Sidecar]B --> C[Istio Pilot(控制平面)]C --> D[Etcd(CP存储)]B --> E[服务实例]C --> F[定期同步服务列表(AP优化)]
- 数据平面:Envoy Sidecar缓存服务列表,注册中心宕机时仍可路由(AP特性)。
- 控制平面:Istio Pilot从Etcd获取实时数据(CP特性),保证配置变更强一致。
5.3 动态切换方案(Nacos)
# Nacos配置中心动态切换模式
from nacos import NacosConfigClientclient = NacosConfigClient(server_addresses="127.0.0.1:8848")# 切换为CP模式(适用于配置发布)
client.set_mode("CP")
client.publish_config(data_id="service-routing", group="DEFAULT_GROUP", content="strict-consistency")# 切换为AP模式(适用于服务发现)
client.set_mode("AP")
六、高可用设计的三大支柱与最佳实践
6.1 服务端崩溃检测优化
6.1.1 心跳机制调优
| 指标 | AP模型(Eureka) | CP模型(ZooKeeper) |
|---|---|---|
| 心跳间隔 | 30秒(可配置) | 2秒(默认) |
| 超时阈值 | 90秒(3次心跳失败) | 6秒(3次心跳失败) |
| 网络抖动容忍 | 开启自我保护模式 | 无(直接标记为失效) |
6.1.2 故障转移策略
// 客户端重试逻辑(Java示例)
public class ServiceClient {private static final int MAX_RETRIES = 3;private static final long RETRY_INTERVAL = 500; // 500ms间隔public Object invoke(ServiceInstance instance) {for (int i = 0; i < MAX_RETRIES; i++) {try {return doInvoke(instance);} catch (Exception e) {if (i == MAX_RETRIES - 1) {circuitBreaker.open(); // 触发熔断}Thread.sleep(RETRY_INTERVAL);instance = loadBalancer.choose(); // 切换节点}}throw new ServiceUnavailableException();}
}
6.2 客户端容错体系
6.2.1 本地缓存策略
# Python客户端缓存实现(使用Redis)
import redis
import timeclass ServiceRegistryCache:def __init__(self):self.redis = redis.Redis(host='localhost', port=6379)self.ttl = 30 # 缓存有效期30秒def get_instances(self, service_name):instances = self.redis.get(f"sr:{service_name}")if instances:return json.loads(instances)# 缓存失效时查询注册中心instances = self.query_registry(service_name)self.redis.setex(f"sr:{service_name}", self.ttl, json.dumps(instances))return instances
6.2.2 主动健康探测
// Go语言实现客户端主动探测
func healthProbe(instance string) bool {timeout := time.Duration(2) * time.Secondctx, cancel := context.WithTimeout(context.Background(), timeout)defer cancel()req, err := http.NewRequestWithContext(ctx, "GET", instance+"/health", nil)if err != nil {return false}resp, err := http.DefaultClient.Do(req)return err == nil && resp.StatusCode == http.StatusOK
}
6.3 注册中心集群优化
6.3.1 AP集群横向扩展
Eureka集群部署架构:
# 负载均衡配置
upstream eureka_servers {server eureka-node1:8761;server eureka-node2:8762;server eureka-node3:8763;least_conn; # 最小连接数负载均衡
}server {listen 80;location /eureka/ {proxy_pass http://eureka_servers;proxy_http_version 1.1;proxy_set_header Connection "";}
}
6.3.2 CP集群节点规划
Etcd集群最佳实践:
- 节点数:3/5/7(奇数,满足多数派原则)。
- 部署方式:跨可用区(如2AZ部署5节点,3+2分布)。
- 硬件配置:SSD磁盘(保证写入性能),万兆网络(降低复制延迟)。
七、面试高频考点与答题模板
7.1 注册中心崩溃应急处理
问题:当注册中心整体不可用时,微服务系统如何保证可用性?
答题模板:
- 客户端本地缓存:依赖之前缓存的服务列表继续调用(AP模型默认支持,CP模型需手动开启)。
- 静态路由兜底:预先配置关键服务的IP列表(如数据库连接),通过环境变量注入。
- 熔断与降级:关闭服务发现功能,直接访问已知存活节点,非核心业务返回默认值。
- 注册中心恢复策略:优先恢复读接口(AP模型可快速恢复),再逐步恢复写操作(CP模型需重新选举Leader)。
7.2 心跳机制设计权衡
问题:心跳间隔设置为1秒和30秒各有什么优缺点?
答题模板:
- 1秒间隔:
- 优点:故障检测速度快(3秒内发现节点宕机)。
- 缺点:网络负载高(每个节点每秒发送心跳),可能引发流量风暴(如1000个节点每秒产生1000次请求)。
- 30秒间隔:
- 优点:网络开销低(Eureka默认配置),适合大规模集群。
- 缺点:故障恢复延迟长(90秒后才标记为失效),可能导致大量请求失败。
- 优化方案:采用动态心跳机制(如初始30秒,连续3次失败后改为5秒间隔)。
7.3 AP与CP的本质区别
问题:从CAP理论角度,说明AP和CP注册中心的核心差异?
答题模板:
- AP模型:
- 放弃强一致性,保证分区期间服务可读写(如Eureka在网络分区时,各分区独立维护服务列表)。
- 适用于“最终一致性”场景,通过异步复制实现数据收敛。
- CP模型:
- 放弃可用性,保证分区期间只有多数节点存活时才能写(如ZooKeeper在分区时无法响应写请求)。
- 适用于“强一致性”场景,通过共识协议(如ZAB/Raft)保证数据全局一致。
八、行业案例:不同场景下的选型实践
8.1 电商平台(AP优先)
场景:双11大促期间,每秒新增200个容器实例,服务发现QPS峰值达50万次/秒。
方案:
- 注册中心:Consul AP模式(支持动态扩缩容)。
- 优化点:
- 客户端缓存TTL从30秒降至10秒,提升数据新鲜度。
- 开启Consul的Gossip协议优化,减少广播风暴。
- 效果:服务发现成功率>99.9%,故障恢复时间<30秒。
8.2 金融交易系统(CP优先)
场景:跨境支付服务,要求服务路由实时一致,每日交易笔数>100万。
方案:
- 注册中心:Etcd集群(3节点,Raft协议)。
- 优化点:
- 启用预写日志(WAL)持久化,保证数据不丢失。
- 客户端采用长连接监听节点变更(Watch机制),配置更新延迟<1秒。
- 效果:交易路由错误率<0.001%,满足PCI-DSS合规要求。
九、总结:黄金选型法则与行动建议
9.1 黄金选型法则
- 80%原则:80%的互联网应用选择AP模型(如Eureka/Consul),仅20%强一致性场景选CP(如金融/分布式协调)。
- 混合模式优先:优先考虑支持AP/CP切换的中间件(如Nacos),避免技术栈锁定。
- 成本驱动:小规模团队优先AP(运维简单),大型团队可投入CP(满足复杂需求)。
9.2 落地行动建议
- 压力测试:
- 模拟网络分区,测试AP模型的最终一致性时间(如Eureka自我保护模式下的恢复时间)。
- 模拟节点宕机,测试CP模型的Leader选举耗时(如Etcd<200ms)。
- 监控指标:
- AP模型:监控缓存命中率、心跳失败率、自我保护模式触发次数。
- CP模型:监控Leader节点延迟、复制滞后时间、节点投票耗时。
- 应急预案:
- 准备静态路由配置,应对注册中心长时间不可用。
- 定期演练注册中心切换(如从AP切CP),确保灾备流程可行。






)

)




/ 并发 GET解决思路)





