目录
- 第1章:引言
- 第2章:观察与见解
- 2.1 总体观察(Overall Observations)
- 2.2 从EfficientLLM基准中得出的新见解
- 第3章:背景
- 3.1 大语言模型(LLMs)
- 3.2 提升LLMs效率的方法
- 3.2.1 硬件创新
- 3.2.2 软件优化
- 3.2.3 算法改进
- 第4章:提升LLMs效率的技术
- 4.1 LLMs效率的维度(Dimensions of LLM Efficiency)
- 4.2 预算效率:扩展法则(Budget Efficiency: Scaling Laws)
- 4.3 数据效率(Data Efficiency)
- **4.4 架构效率(Architecture Efficiency)**
- 4.5 训练和微调效率(Training and Tuning Efficiency)
- **4.6 推理效率(Inference Efficiency)**
- 第5章:评估
- **5.1 EfficientLLM评估原则(Assessment Principles of EFFICIENTLLM)**
- **5.2 EfficientLLM实验设置(Preliminaries of EFFICIENTLLM)**
- **5.3 架构预训练效率评估(Assessment of Architecture Pretraining Efficiency)**
- **5.4 训练和微调效率评估(Assessment of Training and Tuning Efficiency)**
- 5.5 量化推理效率评估(Assessment of Bit-Width Quantization Inference Efficiency)
- 第6章:EfficientLLM基准的可扩展性
- 6.1 Transformer基础的LVMs架构预训练效率(Efficiency for Transformer Based LVMs Architecture Pretraining)
- 6.2 PEFT在LVMs上的评估(Assessment of PEFT on LVMs)
- 6.3 PEFT在VLMs上的评估(Assessment of PEFT on VLMs)
- 6.4 PEFT在多模态模型上的评估(Assessment of PEFT on Multimodal Models)
- 第7章:相关工作
- 7.1 分布式训练和系统级优化(Distributed Training and System-Level Optimizations)
- 7.2 对齐和强化学习效率(Alignment and RLHF Efficiency)
- 7.3 推理时间加速策略(Inference-Time Acceleration Strategies)
- 7.4 动态路由和模型级联(Dynamic Routing and Model Cascades)
- 7.5 硬件感知训练计划(Hardware-aware Training Schedules)
- 7.6 讨论(Discussion)
- 结论
《EfficientLLM: Efficiency in Large Language Models》由Zhengqing Yuan等人撰写,系统地研究了大语言模型(LLMs)的效率问题,并提出了一个全面的基准框架EfficientLLM,用于评估不同效率优化技术在架构预训练、微调和量化方面的表现。以下是对论文每一章节内容的脉络概览:
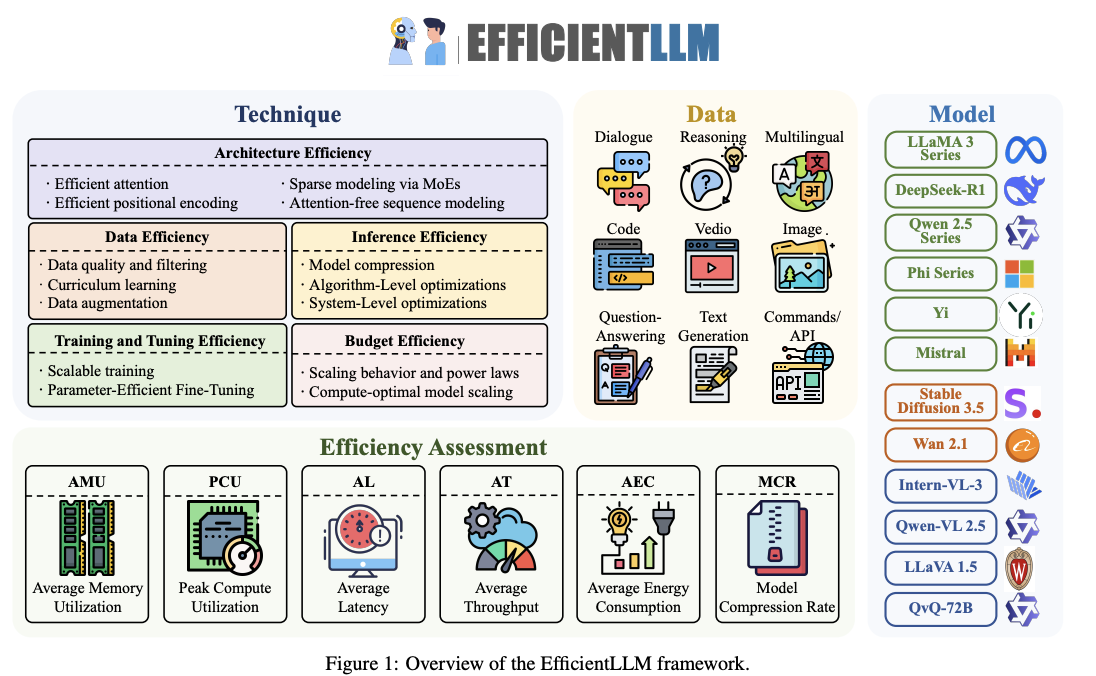
第1章:引言
- 研究背景
LLMs的突破性进展:LLMs如GPT系列和Pathways Language Model(PaLM)在自然语言处理(NLP)领域取得了显著进展。这些模型通过深度学习技术在大规模文本数据上进行训练,能够生成复杂、连贯的语言内容,并在多种任务中表现出色。
模型规模和资源需求:随着模型参数规模的不断增大(如Deepseek R1的671B参数),训练和推理所需的计算资源、内存容量和能源消耗也急剧增加。例如,训练GPT-3(175B参数)需要约3640 Petaflop/s-days的计算量,成本高达数百万美元。
资源需求对应用的影响:这种资源需求的增长限制了LLMs的广泛应用,尤其是在资源受限的环境中。因此,提高LLMs的效率成为了一个关键的研究方向。 - 研究动机
效率挑战:尽管LLMs在性能上取得了巨大进步,但其高昂的计算和能源成本使其在实际部署中面临挑战。例如,GPT-3的训练成本高达数百万美元,推理时的硬件需求和能源消耗也非常可观。
现有研究的局限性:现有的研究通常只关注特定的效率技术,缺乏对多种技术在不同模型规模和任务上的系统性比较。此外,许多研究缺乏对现代硬件(如GPU)能耗的全面评估,或者依赖于理论分析而非大规模实证验证。
EfficientLLM框架的必要性:为了填补这一空白,作者提出了EfficientLLM框架,旨在通过大规模实证研究,系统评估LLMs在架构预训练、微调和量化方面的效率优化技术。 - 研究目标
系统性评估:EfficientLLM框架通过在生产级集群(48×GH200,8×H200 GPUs)上进行大规模实验,系统评估了超过100种模型与技术组合的效率表现。
多维度效率评估:提出了六个细粒度的效率评估指标,包括平均内存利用率(AMU)、峰值计算利用率(PCU)、平均延迟(AL)、平均吞吐量(AT)、平均能耗(AEC)和模型压缩率(MCR),以全面捕捉硬件饱和度、延迟-吞吐量平衡和碳成本。
提供实际指导:通过实验结果,为研究人员和工程师在设计、训练和部署LLMs时提供数据驱动的指导,帮助他们在资源受限的环境中做出更明智的决策。 - EfficientLLM框架的核心概念
架构预训练效率:评估不同架构优化技术(如高效注意力机制、稀疏建模等)在模型预训练阶段的效率表现。这些技术直接影响模型的计算和能源成本。
参数高效微调(PEFT):评估多种参数高效微调方法(如LoRA、RSLoRA等)在适应特定下游任务时的效率和性能。这些方法通过更新模型的一小部分参数来减少微调所需的资源。
量化推理效率:评估不同量化技术(如int4、float16等)在减少模型大小和推理延迟方面的效果。这些技术可以在不重新训练的情况下直接应用于部署。 - 研究贡献
系统性分类和回顾:对LLMs的效率技术进行了系统性分类和回顾,涵盖了架构、训练和推理等多个方面。
新的评估指标:提出了一套新的详细评估指标,用于评估LLMs的多维效率,包括硬件利用率、性能、能耗和模型压缩。
大规模实证基准:通过在大规模GPU集群上进行实验,提供了关于LLMs效率的系统性、大规模实证比较。
实际应用指导:为研究人员和工程师在选择高效模型架构和优化技术时提供了基于实际数据的指导,而不是仅依赖理论分析或启发式选择。
第2章:观察与见解
2.1 总体观察(Overall Observations)
效率优化的多目标权衡:EfficientLLM基准研究发现,没有任何单一方法能够在所有效率维度上实现最优。每种技术在提升某些指标(如内存利用率、延迟、吞吐量、能耗或压缩率)的同时,都会在其他指标上有所妥协。例如,Mixture-of-Experts(MoE)架构虽然通过减少FLOPs和提升准确性来优化计算效率,但会增加显存使用量(约40%),而int4量化虽然显著降低了内存和能耗(最高可达3.9倍),但平均任务分数下降了约3–5%。这些结果验证了“没有免费午餐”(No-Free-Lunch, NFL)定理在LLMs效率优化中的适用性,即不存在一种通用的最优方法。
资源驱动的权衡:在资源受限的环境中,不同的效率技术表现出不同的优势。例如,MQA在内存和延迟方面表现出色,适合内存受限的设备;MLA在困惑度(perplexity)方面表现最佳,适合对质量要求较高的任务;而RSLoRA在14B参数以上的模型中比LoRA更高效,表明效率技术的选择需要根据模型规模和任务需求进行调整。

2.2 从EfficientLLM基准中得出的新见解
架构预训练效率:
注意力机制的多样性:在预训练阶段,不同的高效注意力变体(如MQA、GQA、MLA和NSA)在内存、延迟和质量之间存在不同的权衡。MQA在内存和延迟方面表现最佳,MLA在困惑度方面表现最佳,而NSA在能耗方面表现最佳。
MoE的计算-内存权衡:MoE架构在预训练时可以显著提高性能(如提升3.5个百分点的准确性),同时减少训练FLOPs(约1.8倍),但会增加显存使用量(约40%)。这表明在计算和内存资源之间存在明显的权衡。
注意力自由模型的效率:注意力自由模型(如Mamba)在预训练时表现出较低的内存使用量和能耗,但困惑度有所增加。RWKV在延迟方面表现最佳,而Pythia在生成质量方面表现最佳,尽管其困惑度较高。
深度-宽度比的平坦最优区域:实验结果表明,Chinchilla的深度-宽度比在预训练时存在一个平坦的最优区域,这意味着在该区域内调整模型的深度和宽度对性能的影响较小,为硬件对齐的架构调整提供了灵活性。
训练和微调效率:
PEFT方法的规模依赖性:LoRA及其变体(如LoRA-plus)在1B到3B参数的模型中表现最佳,而RSLoRA在14B参数以上的模型中更有效。参数冻结(只更新特定层或组件)在需要快速微调的场景中表现出最低的延迟,尽管可能会略微降低最终任务的准确性。
全微调的收益递减:对于24B参数以上的模型,全微调的收益递减,损失改进通常小于0.02,而能耗翻倍。这表明在大规模模型适应中应优先采用PEFT方法。
DoRA的延迟权衡:DoRA在微调过程中保持了稳定的损失,但引入了显著的延迟开销,使其更适合于批处理微调管道,而不是实时或延迟敏感的部署场景。
量化推理效率:
量化对性能的影响:int4后训练量化显著提高了资源效率,将内存占用和吞吐量(每秒生成的token数)提高了约3.9倍,但平均任务分数下降了约3–5%。bfloat16在现代Hopper GPU架构上的一致性优于float16,分别在延迟和能耗上分别提高了约6%和9%。
量化精度的选择:bfloat16在延迟和能耗方面表现优于float16,而int4量化在资源受限的环境中表现出色,尤其是在需要降低内存占用和能耗的场景中。这些结果表明,选择合适的量化精度对于平衡推理效率和性能至关重要。
第3章:背景
该章节首先提供了关于大型语言模型(LLMs)的基础知识,以及提升LLMs效率的主要方法。这一章节为后续章节的详细技术评估和实验结果提供了必要的背景信息。
3.1 大语言模型(LLMs)
- LLMs的定义和应用:LLMs是基于Transformer架构的复杂神经网络,通过在大规模文本数据上进行深度学习训练,能够捕捉人类语言的复杂细节。这些模型在自然语言生成、复杂推理和问题解决等任务中表现出色,广泛应用于NLP领域,如机器翻译、文本摘要、问答系统等。
- 模型规模和训练成本:LLMs的参数规模从数十亿到数千亿不等,甚至更大。例如,GPT-3拥有1750亿参数,训练成本高达数百万美元。这些模型的训练需要大量的计算资源和能源,限制了它们的广泛应用。
- 模型架构:LLMs通常基于Transformer架构,采用自注意力机制(Self-Attention)来处理输入序列。这种架构能够并行处理输入序列,有效捕捉长距离依赖关系,但其计算复杂度较高,尤其是随着序列长度的增加。
3.2 提升LLMs效率的方法
3.2.1 硬件创新
- 现代AI加速器:详细介绍了GPU和TPU等现代AI加速器的特点和优势。这些硬件通过大规模并行计算能力显著提高了LLMs的训练和推理效率。
- 新型计算架构:探讨了神经形态计算芯片和光子计算芯片等新型计算架构的潜力。这些架构通过模拟大脑神经元的稀疏脉冲信号或利用光子进行矩阵运算,有望实现更高的能效比。
- 硬件与软件的协同设计:强调了硬件和软件协同设计的重要性,通过定制化的硬件和优化的软件框架,可以进一步提高LLMs的效率。
3.2.2 软件优化
- 分布式训练策略:介绍了数据并行、模型并行和流水线并行等分布式训练技术,这些技术通过将大型模型的训练分布在多个设备上,显著提高了训练效率。
- 混合精度训练:讨论了使用半精度浮点数(如FP16或bfloat16)进行训练的优势,包括减少内存使用量和利用硬件加速提高计算速度。
- 编译器优化:介绍了深度学习编译器(如XLA、TVM)的作用,这些编译器通过操作融合、循环平铺和内存布局优化等技术,生成高效的硬件执行代码。
3.2.3 算法改进
- 高效注意力机制:详细介绍了稀疏注意力机制(Sparse Attention)和多查询注意力机制(Multi-Query Attention, MQA)等高效注意力机制,这些机制通过限制注意力计算的范围,显著降低了计算复杂度。
- 稀疏建模:探讨了Mixture-of-Experts(MoE)架构的优势,这种架构通过增加模型容量,同时在推理时只激活部分参数,显著提高了模型的效率。
- 训练过程优化:介绍了课程学习(Curriculum Learning)和数据增强等技术,这些技术通过逐步增加训练数据的难度或生成更多的训练样本,加速模型的收敛速度。
第4章:提升LLMs效率的技术
4.1 LLMs效率的维度(Dimensions of LLM Efficiency)
- 模型大小与参数数量:模型的参数数量直接影响其内存占用和训练/推理所需的计算资源。
- 计算成本(FLOPs):模型在前向传播和反向传播过程中所需的浮点运算次数。
- 吞吐量(Throughput):模型在单位时间内处理数据的速度,通常以每秒处理的token数或样本数衡量。
- 延迟(Latency):从输入到输出的时间延迟,对于实时应用尤为重要。
- 内存占用(Memory Footprint):模型在训练和推理过程中占用的内存大小。
- 能耗(Energy Consumption):模型在训练和推理过程中消耗的电能,通常以瓦特(W)或千瓦时(kWh)衡量。
这些维度共同决定了LLMs在实际应用中的效率和可行性。
4.2 预算效率:扩展法则(Budget Efficiency: Scaling Laws)
- 扩展行为和幂律关系(Scaling Behavior and Power Laws):Kaplan等人发现,模型性能(如交叉熵损失或困惑度)与模型参数数量和训练数据量之间存在幂律关系。这种关系表明,随着模型规模的增加,性能会逐步提升,但提升的幅度逐渐减小。
- 计算最优模型扩展(Compute-Optimal Model Scaling):Hoffmann等人提出了计算最优模型的概念,即在给定的计算预算下,存在一个最优的模型规模和数据量组合,能够实现最佳性能。例如,Chinchilla模型通过增加训练数据量,显著提升了性能,同时减少了模型参数数量。
- 数据约束和质量(Data Constraints and Quality):在数据受限的情况下,模型规模的增加可能会导致性能提升的收益递减。因此,数据质量的提升和有效的数据利用策略对于提高模型效率至关重要。
- 开放问题(Open Problems in Scaling):尽管扩展法则提供了指导,但在实际应用中仍存在许多问题,例如如何在大规模模型中实现有效的训练、如何处理数据分布的变化等。
4.3 数据效率(Data Efficiency)
数据效率是指如何在有限的数据量下最大化模型的性能。主要方法包括:
- 数据质量与过滤(Importance of Data Quality and Filtering):通过去除重复、低质量或不相关的数据,提高训练数据的质量,从而提高模型的效率。
- 课程学习(Curriculum Learning):按照从简单到复杂的顺序逐步训练模型,类似于人类的学习过程,可以提高模型的收敛速度和最终性能。
- 数据增强和合成数据(Data Augmentation and Synthetic Data):通过生成额外的训练数据或对现有数据进行变换,增加数据的多样性,从而提高模型的泛化能力。
4.4 架构效率(Architecture Efficiency)
架构效率涉及对模型架构的优化,以减少计算和内存需求。主要方法包括:
- 高效注意力机制(Efficient Attention Mechanisms):例如,多查询注意力(MQA)、分组查询注意力(GQA)、多头潜在注意力(MLA)和原生稀疏注意力(NSA)等变体,通过减少计算复杂度或内存占用来提高效率。
- 高效位置编码(Efficient Positional Encoding):改进位置编码方法,如相对位置编码(Relative Positional Encoding)和旋转位置编码(Rotary Positional Encoding),以更好地处理长序列。
- 稀疏建模(Sparse Modeling):通过Mixture-of-Experts(MoE)等技术,实现条件计算,减少每次推理时激活的参数数量。
- 注意力替代方案(Attention-Free Alternatives):探索不依赖自注意力机制的模型架构,如循环神经网络(RNN)和状态空间模型(State Space Models),以进一步降低计算复杂度。
4.5 训练和微调效率(Training and Tuning Efficiency)
这一部分讨论了如何在训练和微调阶段提高LLMs的效率。主要方法包括:
- 可扩展训练策略(Scalable Training Strategies):例如,混合精度训练、数据并行、模型并行和流水线并行等技术,通过充分利用硬件资源,加速大规模模型的训练。
- 参数高效微调(PEFT):通过只更新模型的一小部分参数(如LoRA、RSLoRA、DoRA等),显著减少微调所需的计算资源,同时保持模型性能。
- 训练效率的系统优化:通过优化训练过程中的各种参数(如学习率、批大小等),进一步提高训练效率。
4.6 推理效率(Inference Efficiency)
推理效率涉及在模型部署阶段如何提高效率。主要方法包括:
- 模型压缩技术(Model Compression Techniques):例如,量化(Quantization)、剪枝(Pruning)和知识蒸馏(Knowledge Distillation),通过减少模型大小和计算需求,提高推理速度和能效。
- 算法级推理优化(Algorithm-Level Inference Optimizations):例如,稀疏注意力机制、高效解码算法(如Speculative Decoding)等,通过优化算法实现更高的推理效率。
- 系统级优化和部署(System-Level Optimizations and Deployment):通过优化硬件资源的使用(如内存管理、多任务调度)和部署策略(如模型分片、分布式推理),进一步提高模型在实际应用中的效率。
第5章:评估
第5章“评估”(Assessment)是论文中对EfficientLLM框架进行系统性评估的核心部分。这一章节详细介绍了EfficientLLM框架的评估原则、实验设置、以及针对架构预训练、训练和微调、量化推理等不同维度的具体实验结果。以下是该章节的详细介绍:
5.1 EfficientLLM评估原则(Assessment Principles of EFFICIENTLLM)
在这一部分,作者提出了EfficientLLM框架的评估原则,旨在全面评估LLMs在不同效率优化技术下的表现。评估原则包括以下六个核心指标:
- 平均内存利用率(Average Memory Utilization, AMU):衡量模型在训练和推理过程中内存的使用效率。
- 峰值计算利用率(Peak Compute Utilization, PCU):评估GPU等硬件资源在训练过程中的利用率。
- 平均延迟(Average Latency, AL):衡量模型在推理过程中从输入到输出的平均时间延迟。
- 平均吞吐量(Average Throughput, AT):评估模型在单位时间内处理数据的能力。
- 平均能耗(Average Energy Consumption, AEC):衡量模型在训练和推理过程中消耗的电能。
- 模型压缩率(Model Compression Rate, MCR):评估模型在压缩后的大小与原始大小的比例。
这些指标共同捕捉了硬件资源的饱和度、延迟-吞吐量平衡和碳成本,为全面评估LLMs的效率提供了科学依据。
5.2 EfficientLLM实验设置(Preliminaries of EFFICIENTLLM)
在这一部分,作者详细介绍了EfficientLLM框架的实验设置,包括:
- 模型列表(Curated List of LLMs):实验涵盖了多种LLMs,包括LLaMA 3系列、DeepSeek-R1系列、Qwen 2.5系列、Phi系列、Yi系列等,参数规模从0.5B到72B不等。
- 实验数据集(Experimental Datasets):使用了多个数据集,如FineWeb-Edu(教育领域数据集)、OpenO1-SFT(文本生成数据集)、Medical-o1-reasoning-SFT(医学领域数据集)等,以评估模型在不同任务上的表现。
这些设置确保了实验的全面性和可重复性,为后续的详细评估提供了基础。
5.3 架构预训练效率评估(Assessment of Architecture Pretraining Efficiency)
在这一部分,作者评估了不同架构优化技术在预训练阶段的效率表现,包括:
- 高效注意力机制(Efficient Attention Mechanisms):比较了MQA、GQA、MLA和NSA等不同注意力机制在内存利用率、延迟、吞吐量、能耗和困惑度方面的表现。例如,MQA在内存和延迟方面表现出色,而MLA在困惑度方面表现最佳。
- 稀疏建模(Sparse Modeling via MoE):评估了Mixture-of-Experts(MoE)架构在预训练阶段的效果。MoE通过增加模型容量,同时在推理时只激活部分参数,显著提高了模型的效率。
- 注意力替代方案(Attention-Free Alternatives):探讨了不依赖自注意力机制的模型架构,如Mamba、Pythia和RWKV等,这些架构在内存和能耗方面表现出色,但在困惑度上有所妥协。
这些评估结果为研究人员和工程师在设计和训练LLMs时提供了重要的参考。
5.4 训练和微调效率评估(Assessment of Training and Tuning Efficiency)
在这一部分,作者评估了多种参数高效微调方法(PEFT)在不同模型规模下的效率和性能,包括:
- LoRA及其变体(LoRA, LoRA-plus, RSLoRA):LoRA通过在模型中插入低秩分解矩阵来更新参数,显著减少了微调所需的计算资源。RSLoRA在更大规模模型中表现出更高的效率。
- 参数冻结(Parameter Freezing):通过冻结模型的大部分参数,只更新特定层或组件,显著降低了微调的延迟,但可能会略微降低最终任务的准确性。
- 全微调(Full Fine-Tuning):虽然全微调可以实现最佳性能,但在大规模模型中,其收益递减,能耗显著增加。
这些评估结果为研究人员和工程师在选择合适的微调方法时提供了重要的指导。
5.5 量化推理效率评估(Assessment of Bit-Width Quantization Inference Efficiency)
在这一部分,作者评估了不同量化精度(如bfloat16、float16、int4)对模型推理效率和性能的影响,包括:
- 量化精度的选择:int4量化显著提高了资源利用率,将有效显存容量增加了约4倍,吞吐量提高了约3倍,同时仅导致性能轻微下降(3–5个百分点)。bfloat16在延迟和能耗方面表现优于float16。
- 量化对性能的影响:虽然量化可以显著提高推理效率,但可能会对模型性能产生一定影响。例如,某些任务(如数学推理)对量化精度更为敏感。
这些评估结果为研究人员和工程师在选择合适的量化技术时提供了重要的参考。
第6章:EfficientLLM基准的可扩展性
该章节探讨了EfficientLLM框架在不同模态(语言、视觉、多模态)和不同模型规模下的可扩展性。这一章节通过将EfficientLLM框架应用于大型视觉模型(LVMs)和视觉语言模型(VLMs),验证了这些效率技术在不同领域的适用性和有效性。
6.1 Transformer基础的LVMs架构预训练效率(Efficiency for Transformer Based LVMs Architecture Pretraining)
这一部分将EfficientLLM框架中的效率技术应用于大型视觉模型(LVMs),特别是基于Transformer架构的模型。实验结果表明,这些技术在视觉领域同样有效,能够显著提升模型的预训练效率。具体评估内容包括:
- 高效注意力机制:例如,将MQA、GQA等注意力机制应用于视觉Transformer模型,如DiT(Diffusion Transformer)架构。实验结果表明,这些注意力机制在视觉生成任务中能够显著降低内存占用和计算复杂度,同时保持较高的生成质量。
- 稀疏建模(MoE):将MoE技术应用于视觉Transformer模型,通过条件计算减少每次推理时激活的参数数量。实验结果表明,MoE在视觉生成任务中能够显著提高模型的效率,同时保持生成质量。
- 注意力替代方案:例如,将Mamba(基于状态空间模型的注意力替代方案)应用于视觉生成任务。实验结果表明,Mamba在内存和能耗方面表现出色,但在生成质量上有所妥协。
6.2 PEFT在LVMs上的评估(Assessment of PEFT on LVMs)
这一部分评估了参数高效微调(PEFT)方法在大型视觉模型(LVMs)中的表现。实验结果表明,PEFT方法在视觉领域同样有效,能够显著减少微调所需的计算资源。具体评估内容包括:
- LoRA及其变体:例如,LoRA、LoRA-plus和RSLoRA等方法在视觉Transformer模型中的表现。实验结果表明,这些方法在视觉生成任务中能够显著减少微调所需的计算资源,同时保持较高的生成质量。
- 参数冻结:通过冻结模型的大部分参数,只更新特定层或组件,显著降低了微调的延迟。实验结果表明,参数冻结在视觉生成任务中表现出色,尤其是在需要快速微调的场景中。
6.3 PEFT在VLMs上的评估(Assessment of PEFT on VLMs)
这一部分评估了参数高效微调(PEFT)方法在视觉语言模型(VLMs)中的表现。实验结果表明,PEFT方法在多模态任务中同样有效,能够显著减少微调所需的计算资源。具体评估内容包括:
- LoRA及其变体:例如,LoRA、LoRA-plus和RSLoRA等方法在视觉语言模型中的表现。实验结果表明,这些方法在多模态任务中能够显著减少微调所需的计算资源,同时保持较高的任务性能。
- 参数冻结:通过冻结模型的大部分参数,只更新特定层或组件,显著降低了微调的延迟。实验结果表明,参数冻结在多模态任务中表现出色,尤其是在需要快速微调的场景中。
6.4 PEFT在多模态模型上的评估(Assessment of PEFT on Multimodal Models)
这一部分进一步探讨了PEFT方法在多模态模型中的表现,特别是在处理视觉和语言任务时的效率和性能。实验结果表明,PEFT方法在多模态任务中能够显著减少微调所需的计算资源,同时保持较高的任务性能。具体评估内容包括:
- 多模态任务的挑战:多模态任务需要模型同时处理视觉和语言信息,这增加了模型的复杂性和计算需求。PEFT方法通过只更新模型的一小部分参数,显著减少了微调所需的计算资源。
- 实验结果:通过在多个多模态任务上进行实验,验证了PEFT方法在多模态模型中的有效性。实验结果表明,PEFT方法在多模态任务中能够显著减少微调所需的计算资源,同时保持较高的任务性能。
第7章:相关工作
该章节总结了与EfficientLLM框架相关的现有研究成果,还讨论了这些研究的局限性和未来的研究方向。
7.1 分布式训练和系统级优化(Distributed Training and System-Level Optimizations)
- 分布式训练:介绍了如何通过数据并行、模型并行和流水线并行等技术,将大型模型的训练分布在多个设备上,以提高训练效率。这些技术通过优化数据传输和计算资源的利用,显著减少了训练时间。
- 系统级优化:讨论了如何通过硬件和软件的协同设计,进一步提高训练效率。例如,使用高效的编译器和优化的内存管理策略,可以减少训练过程中的开销。
- 现有工具和框架:介绍了如DeepSpeed、Megatron-LM等工具和框架,这些工具通过提供高效的并行化策略和优化技术,使得训练大型模型成为可能。
7.2 对齐和强化学习效率(Alignment and RLHF Efficiency)
- 对齐技术:讨论了如何通过强化学习从人类反馈(Reinforcement Learning from Human Feedback, RLHF)来对齐大型语言模型的行为,使其更符合人类的偏好和价值观。这种技术通过训练一个奖励模型,并使用策略优化算法(如PPO)来优化模型的行为。
- 效率挑战:虽然RLHF可以显著提高模型的对齐效果,但它本身是一个资源密集型的过程。训练奖励模型和执行策略优化都需要大量的计算资源,这增加了模型训练的复杂性和成本。
- 未来方向:提出了如何通过更高效的采样方法、代理模型或知识蒸馏技术来减少RLHF的计算需求,从而提高对齐过程的效率。
7.3 推理时间加速策略(Inference-Time Acceleration Strategies)
- 动态推理方法:介绍了如动态路由、早停机制和稀疏激活等技术,这些技术通过在推理过程中根据输入的复杂性动态调整计算资源的使用,显著提高了推理速度。
- 现有方法:讨论了如Speculative Decoding、Early Exiting等方法,这些方法通过提前生成或停止计算,减少了不必要的计算开销。
- 未来方向:提出了如何通过进一步优化这些动态推理方法,以及开发新的算法来提高推理效率,特别是在资源受限的环境中。
7.4 动态路由和模型级联(Dynamic Routing and Model Cascades)
- 动态路由:讨论了如何通过动态路由技术,根据输入的复杂性选择合适的模型或模型组件进行推理。这种方法可以显著减少推理过程中的计算资源消耗。
- 模型级联:介绍了模型级联的概念,即通过级联多个模型来处理不同复杂度的任务,从而提高整体的推理效率。
- 未来方向:提出了如何通过开发更智能的路由机制和优化级联策略,进一步提高动态路由和模型级联的效率。
7.5 硬件感知训练计划(Hardware-aware Training Schedules)
- 硬件感知优化:讨论了如何通过自动调度器(Auto-schedulers)来优化训练过程中的并行化策略,以充分利用不同硬件配置的计算能力。
- 现有工具:介绍了如Zeus等工具,这些工具通过动态调整训练过程中的并行化策略,提高了训练效率。
- 未来方向:提出了如何通过进一步开发和优化这些自动调度器,使其能够更好地适应不同的硬件环境和训练任务。
7.6 讨论(Discussion)
- EfficientLLM框架的局限性:讨论了EfficientLLM框架的局限性,包括未涵盖所有效率技术、硬件和基础设施的限制、模型和任务覆盖范围有限、评估指标的静态性以及缺乏经济分析。
- 未来研究方向:提出了未来研究的挑战和方向,如
多目标扩展法则、异构质量语料库的优化、长上下文预训练的课程设计、稀疏路由策略、非Transformer架构的优化、多模态和工具增强LLMs的PEFT、长序列的鲁棒量化等。
结论
- 总结:总结了EfficientLLM框架的主要贡献,强调了通过系统评估效率技术,为LLMs的设计和部署提供了重要的指导。
- 实际意义:指出这些发现为研究人员和从业者提供了明确的行动指南,帮助他们在实际应用中优化LLMs的效率和可持续性。








)





)

)
 recorder-core)

