VIT与GPT 模型与语言生成:从 GPT-1 到 GPT4
本教程将介绍 GPT 系列模型的发展历程、结构原理、训练方式以及人类反馈强化学习(RLHF)对生成对齐的改进。内容涵盖 GPT-1、GPT-2、GPT-3、GPT-3.5(InstructGPT)、ChatGPT 与 GPT-4,并简要提及 Vision Transformer 的演化。
1. GPT 模型的原理
Transformer 架构中包含 Encoder 与 Decoder 两部分。
- 如果我们只需要处理输入(如 BERT),可以去掉 Decoder;
- 如果我们只生成输出(如 GPT),可以只保留 Decoder。
GPT 是一种只使用 Transformer Decoder 堆叠结构的模型,其训练目标是根据前文预测下一个词,即语言建模任务:
给定前缀 { x 1 , x 2 , . . . , x t } \{x_1, x_2, ..., x_t\} {x1,x2,...,xt},模型预测 x t + 1 x_{t+1} xt+1。
2. GPT 与 ELMo/BERT 的比较
| 模型 | 参数量 | 架构 | 特点 |
|---|---|---|---|
| ELMo | 94M | 双向 RNN | 上下文嵌入 |
| BERT | 340M | Transformer Encoder | 掩码语言模型 + 下一句预测 |
| GPT | 可变(取决于版本) | Transformer Decoder | 自回归语言模型 |
GPT 使用自回归机制,一个词一个词地生成结果,适合生成任务。
3. GPT-1:生成式预训练语言模型
GPT-1 的两大创新:
- 利用海量无标注文本进行预训练(语言建模);
- 对具体任务进行监督微调(分类、情感分析、蕴含等)。
这种预训练 + 微调范式,开启了 NLP 模型训练的新方向。
预训练目标是最大化:
log P ( t 1 , t 2 , . . . , t n ) = ∑ i = 1 n log P ( t i ∣ t 1 , . . . , t i − 1 ) \log P(t_1, t_2, ..., t_n) = \sum_{i=1}^{n} \log P(t_i | t_1, ..., t_{i-1}) logP(t1,t2,...,tn)=i=1∑nlogP(ti∣t1,...,ti−1)
微调目标是最大化:
log P ( y ∣ x 1 , x 2 , . . . , x n ) \log P(y | x_1, x_2, ..., x_n) logP(y∣x1,x2,...,xn)
其中 y y y 是标签。
特定于任务的输入转换:为了在微调期间对模型的体系结构进行最小的更改,将特定下游任务的输入转换为有序序列
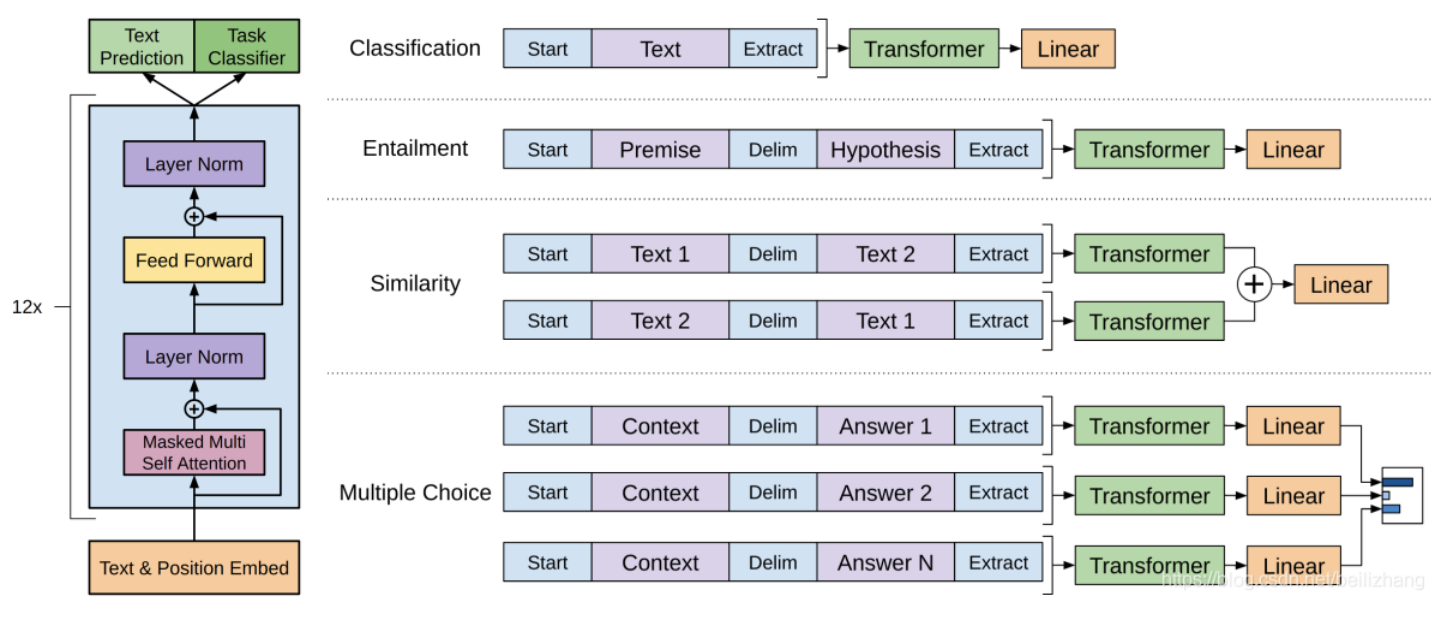
4. GPT-2:无监督多任务学习
GPT-2 扩展了 GPT-1:
- 更大的数据集(从 6GB 增长至 40GB);
- 更多的参数(117M → 1542M);
- 任务无需专门微调结构,只需修改输入格式,即可处理不同任务。
这一版本提出了“语言模型是无监督的多任务学习者”这一重要观点。
5. GPT-3:大规模语言模型与 Few-shot 能力
GPT-3 使用了 1750 亿参数,训练数据量达 45TB,计算资源非常庞大(28.5 万 CPU,1 万 GPU)。
其突破包括:
- 强大的 Few-shot / One-shot / Zero-shot 能力;
- 不再依赖下游微调,输入任务示例即可生成高质量输出。
其架构仍为标准 Transformer Decoder,无重大结构创新。
6. GPT-3.5 / InstructGPT:人类对齐
InstructGPT 引入了 人类反馈强化学习(RLHF),旨在让模型更符合用户意图:
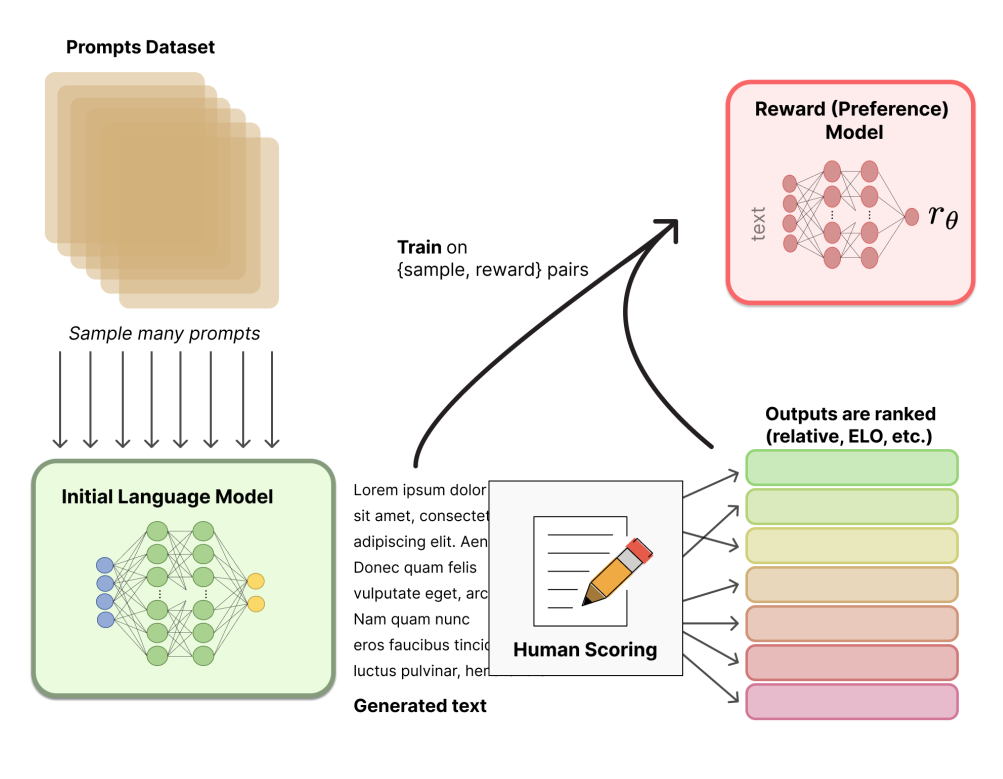
主要流程分为三阶段:
-
语言模型预训练(如 GPT-3);
RLHF一般使用预训练的LMs作为起点(例如,使用GPT-3)
这些预训练的模型可以根据额外的文本或条件进行微调,但这并不总是必要的。(人类增强文本可以用来调整人类的偏好)
-
奖励模型训练(由人工标注生成输出的排序);
Gathering data and training a Reward Model (RM)
- RLHF中的RM:接受文本序列并返回代表人类偏好的标量奖励
- RM的训练集:通过对提示进行采样并将其传递给初始LM以生成新文本,然后由人工注释器对其进行排序。
- 注意:标注对LM的输出进行排序,而不是直接给它们打分。
-
通过强化学习优化模型(使用 PPO 算法)。
-
示例提示
-
通过初始LM和RL策略(初始LM的副本)传递它
-
将策略的输出传递给RM来计算奖励,并使用初始LM和策略的输出来计算移位惩罚
-
采用奖惩结合的方式,通过PPO (Proximal policy)更新
-
结果是模型更加安全、有用且真实。
7. ChatGPT:对话能力与人类协作训练
ChatGPT 是 InstructGPT 的“对话版”,与用户进行多轮交流。
其训练包括:
- 初始监督微调:AI 教练扮演用户和助手角色生成对话;
- 奖励模型训练:对话中多个回复由 AI 教练排序评分;
- 最终强化学习:使用 PPO 方法优化回复。
它与 GPT-3.5 共享核心技术,但训练数据格式专为对话优化。
ChatGPT 的训练概述
ChatGPT 是 InstructGPT 的“兄弟模型”,主要目标是理解提示并生成详细回复。两者使用相同的 RLHF 方法,但 数据构造方式略有不同。
ChatGPT 的训练数据分两部分:
① 初始监督微调数据(Supervised Fine-tuning)
-
训练师(AI Trainers)模拟对话角色:
“The trainers acted as both users and AI assistants…”
即,训练师扮演用户与助手两个角色,人工构造对话数据集。
-
参考模型生成建议(model-written suggestions)**:
帮助训练师撰写回复,提高效率。 -
InstructGPT 数据集也被转换为对话格式并混入**新数据集中。
② 奖励模型数据(Reward Model,比较排序数据)
-
从 AI 训练师与模型的对话中提取**:
“Took conversations that AI trainers had with the chatbot”
-
随机抽取模型生成的回答**,训练师对多个候选答案进行排序打分,构成奖励数据。
总结:ChatGPT 相比 InstructGPT 的不同点
| 阶段 | InstructGPT | ChatGPT |
|---|---|---|
| 微调数据 | 任务式指令对 | 多轮对话,训练师模拟双方 |
| 奖励数据 | 人类写的参考回复 | 人类对多轮对话排序打分 |
8. GPT-4:多模态与推理能力提升
GPT-4 相较于 GPT-3.5 主要提升:
- 更强的创造力与推理能力;
- 多模态输入(文本+图像);
- 更长的上下文处理能力(约 25,000 字);
- 在专业考试中达到人类水平。
其方法未完全公开,但大体基于 ChatGPT 和 InstructGPT 技术演进。
9. Emergent Ability 与 CoT
Emergent Ability(涌现能力) 是指模型规模达到一定程度后,出现新的、未显式训练出的能力。
突发能力是指模型从原始训练数据中自动学习和发现新的高级特征和模式的能力。
Chain of Thought(CoT) 是一种通过 prompt 引导模型“逐步推理”的技巧,可大幅提升逻辑与数学任务表现。
生成思维链(一系列中间推理步骤)可以显著提高llm执行复杂推理的能力
10. Prompt Engineering 简介
Prompt 工程是通过设计输入提示来提升 LLM 输出质量的方法。
一个好的 Prompt 通常包含:
- 角色设定(如你是老师);
- 场景背景(如我们在深度学习课堂);
- 明确指令(解释 prompt engineering);
- 响应风格(应通俗易懂)。
常见方法包括:
- Chain of Thought;
- Self-consistency;
- Knowledge prompt 等。
11. GPT 系列演化总结
| 模型 | 技术路线 | 特点 |
|---|---|---|
| GPT-1 | 预训练 + 微调 | 引入生成式语言模型思想 |
| GPT-2 | 更大模型 | Few-shot、多任务泛化能力 |
| GPT-3 | 巨量参数 | 零样本/少样本迁移能力 |
| GPT-3.5 | RLHF | 对齐人类意图 |
| ChatGPT | 对话优化 | 多轮对话、任务跟踪 |
| GPT-4 | 多模态 + 长上下文 | 强逻辑推理、创造力 |
12. 未来方向:多模态与通用智能
未来的发展趋势将包括:
- 更强的多模态处理能力(语言 + 图像 + 音频);
- 更长文本记忆;
- 与人类交互更自然的代理;
- 融合强化学习、知识图谱等异构技术;
- 向通用人工智能(AGI)迈进。
GPT 是这一进化路线上的关键步骤。
13. Vision Transformer 的动机与背景
传统 CNN 利用局部感受野和共享权重处理图像,但难以建模全局依赖。
Transformer 本是为 NLP 设计,但其强大的全局建模能力被引入图像领域,催生了 Vision Transformer (ViT)。
核心观点:将图像切成 Patch,类比 NLP 中的 token,再用 Transformer 编码序列。
ViT 不再依赖卷积结构,是一种纯基于 Transformer 的视觉模型。
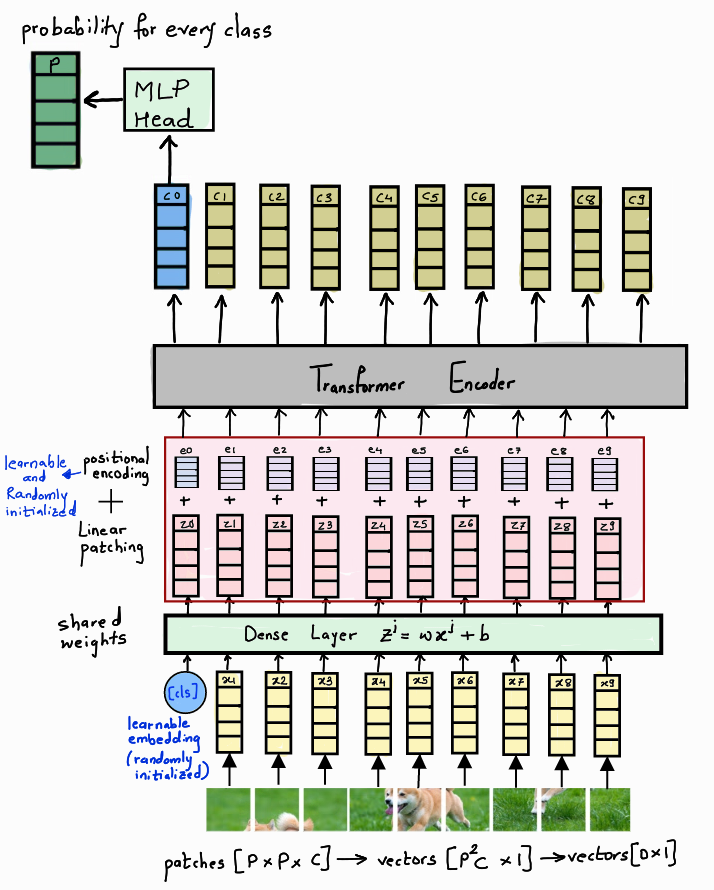
14. Vision Transformer 的核心构成(图像 → patch → 向量序列)
ViT 输入处理流程如下:
- 输入图像大小为 H × W × C H \times W \times C H×W×C;
- 将图像划分为 N N N 个 Patch,每个 Patch 为 P × P P \times P P×P;
- 展平每个 Patch 为长度为 P 2 ⋅ C P^2 \cdot C P2⋅C 的向量;
- 每个 Patch 映射为 D D D 维表示(通过全连接);
- 加入可学习的位置编码;
- 在序列前添加一个
[CLS]token,作为图像的全局表示; - 输入标准 Transformer Encoder。
最终分类结果由 [CLS] token 表示。
15. 多头注意力在 ViT 中的作用
与 NLP 中一样,ViT 中每个 token 都会计算 Query、Key、Value:
Q = X W Q , K = X W K , V = X W V Q = XW_Q,\quad K = XW_K,\quad V = XW_V Q=XWQ,K=XWK,V=XWV
然后进行多头注意力(Multi-Head Attention):
Attention ( Q , K , V ) = softmax ( Q K T d ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d}} \right) V Attention(Q,K,V)=softmax(dQKT)V
多个头并行计算后拼接,再映射到原始维度:
MultiHead ( X ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(X) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W_O MultiHead(X)=Concat(head1,...,headh)WO
注意力机制使模型可以捕捉图像各区域之间的长距离依赖。
16. 位置编码在 ViT 中的关键性
因为 Transformer 本身对输入顺序不敏感,ViT 必须引入 位置编码(Positional Encoding) 以告知 patch 的相对或绝对位置信息。
在 ViT 原始论文中,位置编码是 可学习的向量,维度与 patch 向量一致。
ViT 输入为:
z 0 = [ x class ; x p 1 ; x p 2 ; … ; x p N ] + E pos z_0 = [x_{\text{class}}; x_p^1; x_p^2; \dots; x_p^N] + E_{\text{pos}} z0=[xclass;xp1;xp2;…;xpN]+Epos
其中 x p i x_p^i xpi 表示第 i i i 个 patch 的向量表示, E pos E_{\text{pos}} Epos 是位置嵌入。
17. 类比 NLP 模型:ViT 与 BERT 输入结构对照
ViT 完全借鉴了 BERT 的编码形式:
- 使用
[CLS]token 获取图像全局信息; - patch 类比为 token;
- 添加位置编码。
| 模型 | 输入单位 | [CLS] | 位置编码 | Transformer 层 |
|---|---|---|---|---|
| BERT | token | 是 | 有 | Encoder Stack |
| ViT | patch | 是 | 有 | Encoder Stack |
因此,ViT 可视为一种图像版本的 BERT。
18. ViT 应用于图像分类任务(Encoder-only 模型)
ViT 的应用以图像分类为代表性任务。
其完整流程:
- 图像 → Patch → 向量序列;
- 加入位置编码;
- 输入多层 Transformer Encoder;
- 提取
[CLS]输出向量; - 使用全连接层进行分类预测。
ViT 是 Encoder-only 模型,不包含 Decoder,与 BERT 类似。
19. ViT 模型的训练策略与挑战
训练 ViT 时的挑战:
-
数据依赖性强,若使用小数据集(如 CIFAR-10),效果不如 CNN;
在JFT大数据集上才能略微强过ResNet
-
训练时间长,对正则化要求高;
-
无归纳偏置(不像 CNN 有平移不变性等先验),导致训练初期收敛慢。
解决方法包括:
- 使用 大规模预训练(如 ImageNet-21k);
- 引入 混合训练策略(如 Token Labeling、MixToken);
- 结合 CNN 结构(Hybrid ViT)。
20. 总结:ViT 与 GPT 的共同趋势
ViT 和 GPT 虽应用领域不同,但都体现了 Transformer 的优势:
- 使用统一的序列建模结构;
- 可用于多种下游任务(分类、生成、匹配);
- 都展现出随着模型规模扩大,性能提升的趋势;
- 需要大量数据与计算支持;
- 都引发了通用 AI 架构探索的热潮。
ViT 的出现标志着 Transformer 正式从 NLP 扩展至视觉领域,推动了多模态融合的发展。


)





)

缺省的运行时组件检视器)







)
