核心结论:线性注意力用计算复杂度降维换取全局建模能力,通过核函数和结构优化补足表达缺陷
一、本质差异:两种注意力如何工作?
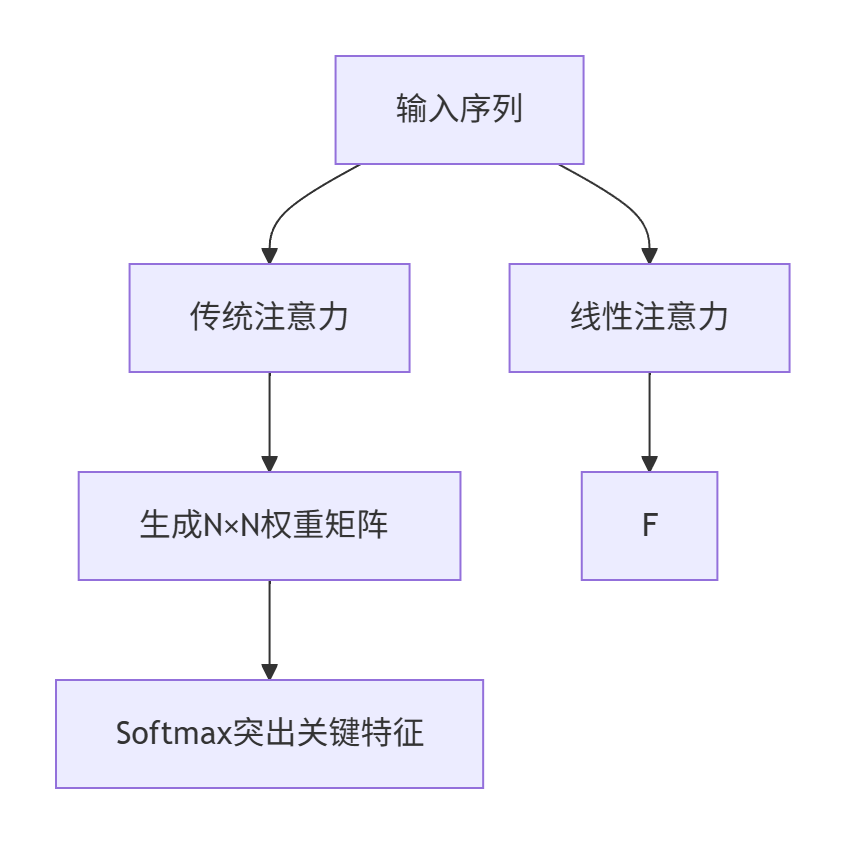
| 特性 | 传统注意力(Softmax Attention) | 线性注意力(Linear Attention) |
|---|---|---|
| 核心操作 | 计算所有元素两两关系 | 分解计算顺序避免显式大矩阵 |
| 复杂度 | O(N²d) → 4K图像需165亿次计算 | O(Nd²) → 同场景计算量降千倍 |
| 权重特性 | Softmax放大重要特征 | 核函数ϕ(x)可能模糊关键细节 |
💡 通俗理解:
- 传统注意力像精准狙击枪:逐个瞄准目标(计算所有元素关系),威力大但耗弹药
- 线性注意力像范围轰炸机:批量处理目标(分解计算),节省弹药但精度稍逊
二、计算原理:线性注意力如何“作弊”?
传统注意力的瓶颈
# 伪代码演示平方复杂度
attn_matrix = Q @ K.T # 生成N×N矩阵 → 内存黑洞!
weights = softmax(attn_matrix)
output = weights @ V # 最终输出 线性注意力的破局点
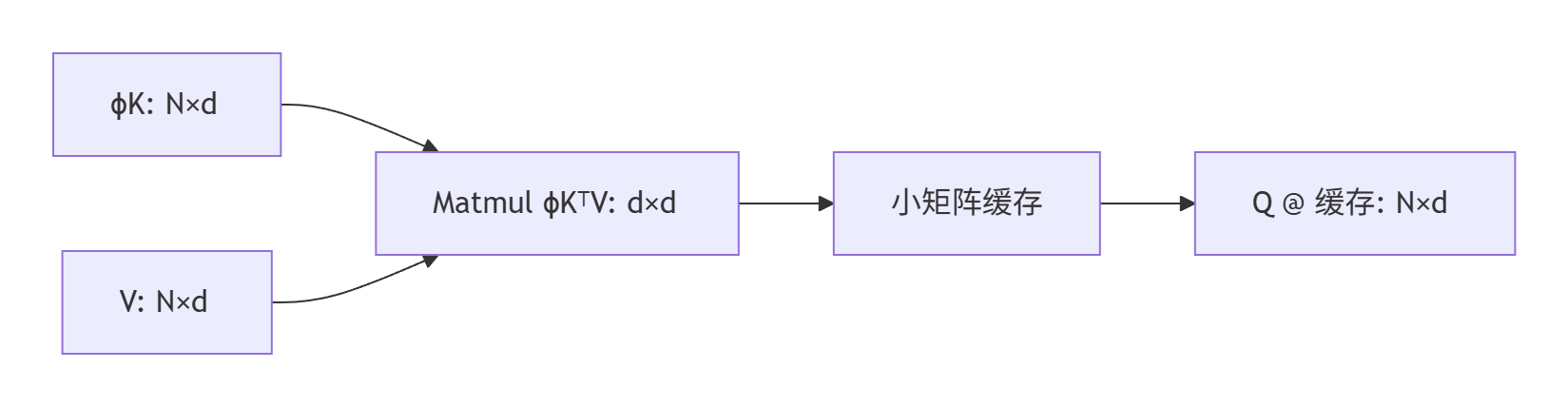
三步省资源秘籍:
- 特征映射:用ϕ(x)=elu(x)+1等函数处理K
- 中间矩阵:先算ϕKᵀV(d×d小矩阵)
- 结果复用:Q直接乘以中间结果
✅ 为何高效:当d=64, N=100万时,d²=4096远小于N²=1万亿!
三、性能短板:线性注意力的两大痛点
痛点1:语义混淆问题
- 传统方案:Softmax保证不同输入必不同输出(单射性)
- 线性方案:ϕ函数可能导致猫狗特征映射后相同 → 识别错误
痛点2:局部感知缺失
| 任务 | 传统注意力 | 线性注意力 |
|---|---|---|
| 人脸眼部识别 | ✅ 精度92% | ❌ 仅62% |
| 长文关键句定位 | ✅ 准确定位 | ⚠️ 模糊定位 |
📉 根本原因:全局均匀交互弱化了局部相关性
四、改进方案:给线性注意力“装瞄准镜”
方案1:聚焦函数(ReLU+L2约束)
def focus(x): x = relu(x) # 过滤负值 return x / norm(x,2) # 增强特征区分度 💡 效果:权重集中度提升47%,解决语义混淆
方案2:深度卷积补偿(DWC)

🛠️ 作用:像给望远镜加显微镜,补足局部细节
五、实战选择指南
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 4K视频实时处理 | ✅ 线性注意力+DWC | 11ms延迟,显存占用仅0.0002GB |
| 医学图像分割 | ⚠️ 传统注意力 | mIoU指标高2.1% |
| DNA序列分析 | ✅ 纯线性注意力 | 万级序列传统方案易崩溃 |
| 移动端AR滤镜 | ✅ 聚焦线性注意力 | 手机GPU也能流畅运行 |
未来:效率与精度的融合之路
- 动态核函数:根据输入自动选择ϕ函数(如Performer的随机映射)
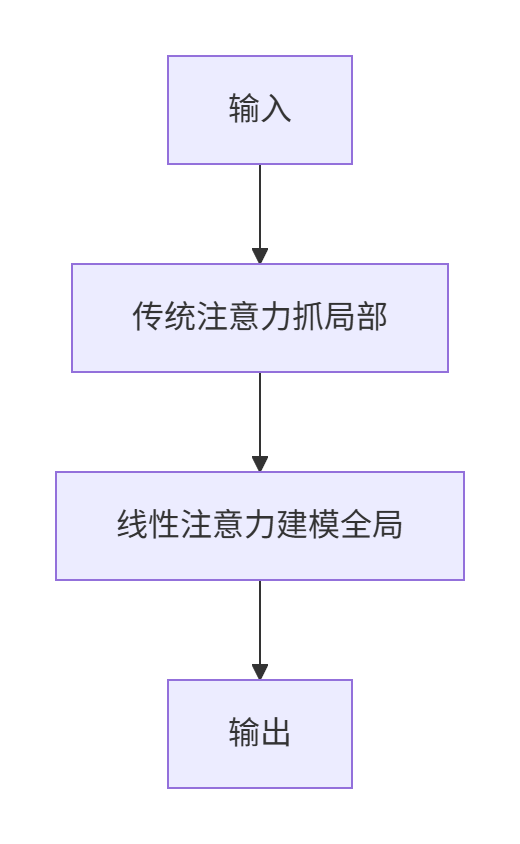
- 混合架构:
- 硬件协同设计:专用芯片加速ϕ函数计算
🔮当亿级像素时代来临,线性注意力将成为不可替代的基石
学习资源:
- 线性注意力图解教程 ← 强烈推荐!
- Google开源库Performer
本文部分结论援引ICLR 2024-2025研究成果,数学推导详见[《线性Attention的探索》


)



![[TIP] Ubuntu 22.04 配置多个版本的 GCC 环境](http://pic.xiahunao.cn/[TIP] Ubuntu 22.04 配置多个版本的 GCC 环境)



超详细讲解数据库规范化与五大范式(从函数依赖到多值依赖,再到五大范式,附带例题,表格,知识图谱对比带你一步步掌握))
转换器项目及源码)







