前言
从15年开始,在深度学习的重要模型中,AutoEncoder(自编码器)可以说是打开生成模型世界的起点。它不仅是压缩与重建的工具,更是VAE、GAN、DIffusion等复杂生成模型的思想起源。其实AutoEncoder并不复杂,它是以一种无监督的方式教会模型将复杂的数据转换成一种更简单的表现形式。
一、什么是AutoEncoder
AutoEncoder是一种无监督学习模型,其目标是通过编码器将输入压缩成低维的隐藏表示,称为隐空间,再通过解码器将其还原回原始输入。总的来说,就是:编码器压缩,解码器还原。
编码器主要由两部分组成:
- Encoder:把输入
映射到潜在表示
- Decoder:再将
还原为近似输入的
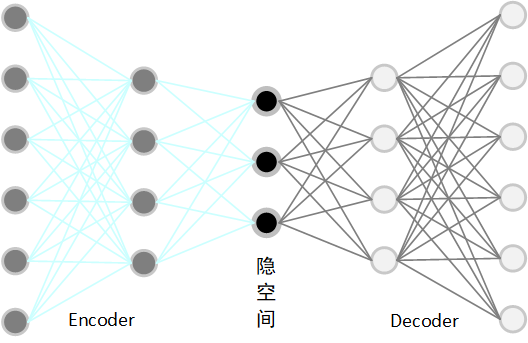
二、AutoEncoder的原理
前面我已经说了,AutoEncoder是一种神经网络,主要是用来学习数据的表示,尝试用尽可能少的特征来描述大量数据,实现数据压缩,例如下图所示: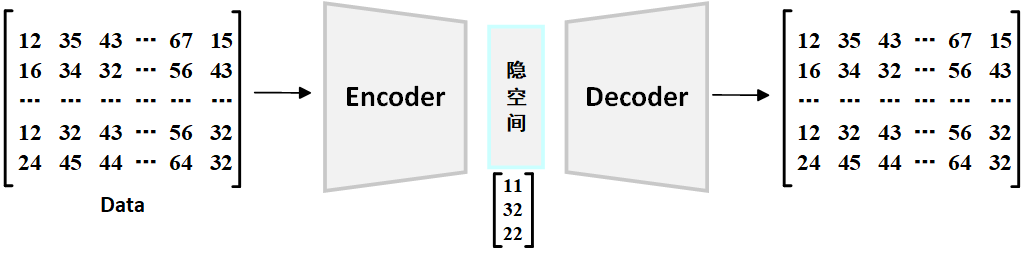
Encoder将输入数据压缩成潜在空间表示,潜在空间是一个低维空间,捕捉了输入数据的核心特征,Decoder则从潜在空间产生的压缩表示中重建原始数据。
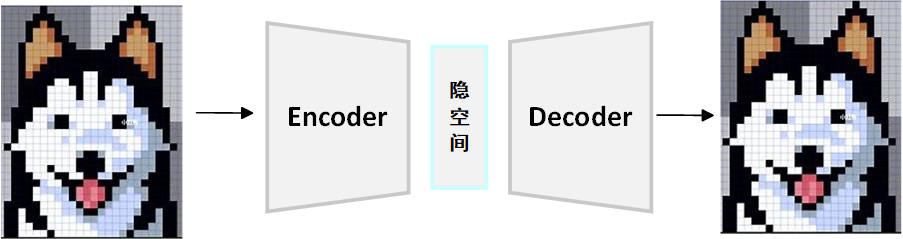
例如编码图像,对于上面的小狗头像,编码其将图像降维到几个关键特征,潜在空间保存这些特征,解码器再从这些低维特征中重建图像。
三、如何训练AutoEncoder
我们已经知道了AutoEncoder工作的原理,那么训练自编码器就是最小化原始数据与重建数据之间的差异,目的是提高解码器根据隐空间表示准确重建原始数据的能力,同时,编码器也以一种更好的方式压缩数据,确保原始数据被有效地重建。
通常,我们使用MSE来表示原始数据与重建数据的差异:
四、隐空间维度的影响
我们已经知道了如何训练AutoEncoder,接下来我们讨论一下隐空间维度对模型的影响。
我们已经知道,AutoEncoder的优势就是它能够进行数据降维,隐空间的维度是由隐空间层的神经元数量决定的,如果隐空间层神经元数量为2,则隐空间就是二维的。接下来我将使用MINST手写数字数据集,训练AutoEncoder,并可视化一下隐空间维度对模型影响。
训练AutoEncoder:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
from torchvision import transformstransform = transforms.ToTensor()
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)class AutoEncoder(nn.Module):def __init__(self):super(AutoEncoder, self).__init__()self.encoder = nn.Sequential(nn.Linear(784, 128),nn.ReLU(),nn.Linear(128, 64))self.decoder = nn.Sequential(nn.Linear(64, 128),nn.ReLU(),nn.Linear(128, 784),nn.Sigmoid())def forward(self, x):x = x.view(x.size(0), -1)z = self.encoder(x)out = self.decoder(z)return outmodel = AutoEncoder()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.MSELoss()for epoch in range(5):for imgs, _ in train_loader:imgs = imgs.view(imgs.size(0), -1)out = model(imgs)loss = loss_fn(out, imgs)optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {epoch}: Loss={loss.item():.4f}")可视化:
import matplotlib.pyplot as plt
# 设置中文字体为黑体(可选字体)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 正确显示负号
plt.rcParams['axes.unicode_minus'] = False model.eval()
with torch.no_grad():for imgs, _ in train_loader:imgs = imgsout = model(imgs)break # 只看一批就够了imgs = imgs.cpu().view(-1, 1, 28, 28)
out = out.cpu().view(-1, 1, 28, 28)# 显示原图与重建图
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):# 原图ax = plt.subplot(2, n, i + 1)plt.imshow(imgs[i].squeeze(), cmap='gray')plt.title("原始图")plt.axis("off")# 重建图ax = plt.subplot(2, n, i + 1 + n)plt.imshow(out[i].squeeze(), cmap='gray')plt.title("重构图")plt.axis("off")
plt.show()
当隐空间层的维度设置为2时,训练好的AutoEncoder的效果为:
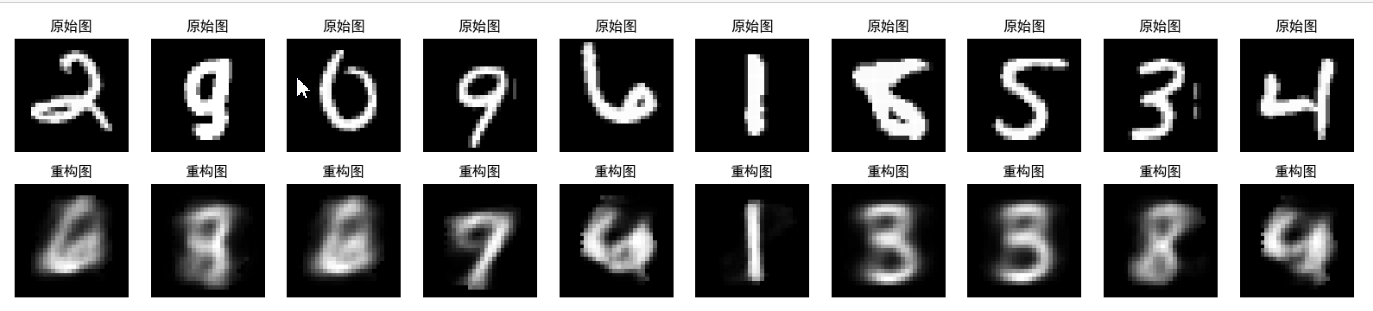
当隐空间层的维度设置为64时,训练好的AutoEncoder的效果为:

通过对比发现,隐空间的维度大小直接重构数据的质量, 为什么或这样呢?
其实这很好解释,因为AutoEncoder的任务就是压缩、重建,较差的重建质量说明隐空间的组织性较差,因为好的隐空间表示能够将每种类型的数字聚类成一簇。但是较低的隐空间维度虽然也能使得一些类型聚类成簇,但是会导致它们相互重叠,很大概率集中在同一区域,而且可能存在系数现象,如下图所示:
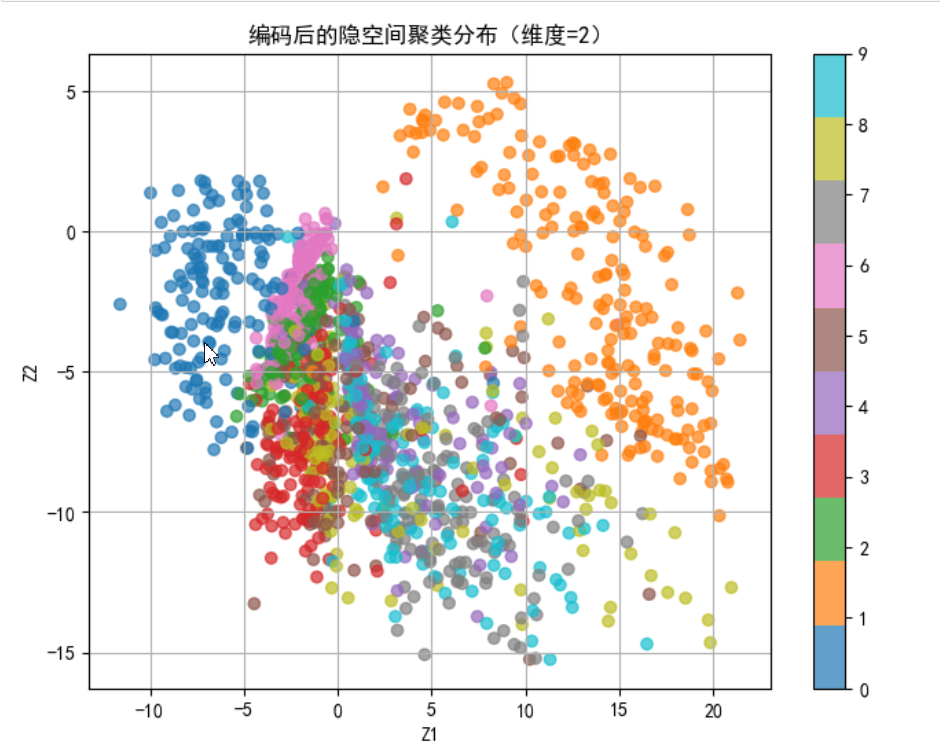
而更高的维度之间的聚类的分隔度更高,但是仍然会有重叠的部分出现。
五、AutoEncoder的局限
AutoEncoder的最大的局限性就是隐空间,因为AutoEncoder只依赖重建损失来组织隐空间,虽然表现良好,但是通过第四部分我们可以知道,聚类的簇并不是特别完美。为此,大多数基于此类的自编码器都会对隐空间进行正则化,而其中最有名的就是变分自编码器(VAE)。当然,之后我会详细的介绍VAE。
总结
以上就是AutoEncoder的全部内容,相信小伙伴们已经对AutoEncoder有了深刻的理解:AutoEncoder是深度学习中一个经典且充满启发的结构,压缩重构的结构,能够学到数据的“核心特征”,为后续的复杂的生成模型奠定了基础。
如果小伙伴们觉得本文对各位有帮助,欢迎:👍点赞 | ⭐ 收藏 | 🔔 关注。我将持续在专栏《人工智能》中更新人工智能知识,帮助各位小伙伴们打好扎实的理论与操作基础,欢迎🔔订阅本专栏,向AI工程师进阶!
: Plugin ‘mysql_native_password‘ is not loaded)

!!!C++语言(嵌入式八股文,嵌入式面经))










的EKF,一维滤波,用于解决观测噪声的异常|附完整代码,订阅专栏后可直接查看)




)
