一.概述
1.C语言编译优化介绍
C语言编译优化是提升程序性能的核心手段,涉及从源代码到机器码的多层次转换,下面从优化级别、常用技术、内存管理、指令调度等多个维度详细介绍。
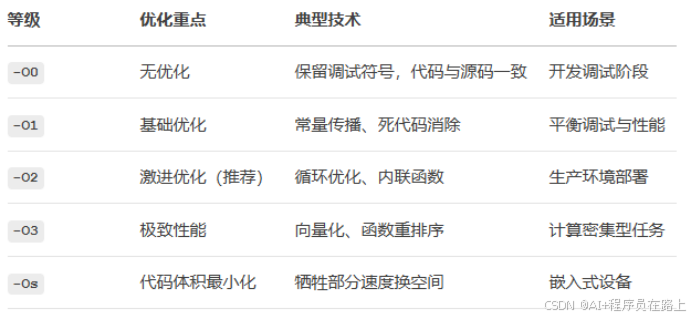
2.编译器优化等级(GCC/Clang)
二.常用优化技术
1.常量传播与折叠
// 编译前
int a = 3 + 5;
int b = a * 2;
// 编译后(常量折叠)
int a = 8;
int b = 16;
2.死代码消除
// 编译前
int func(int x) {
int a = x + 2;
if (0) { // 永远不成立的条件
a = 100;
}
return a;
}
// 编译后
int func(int x) {
return x + 2;
}
3.循环优化
// 编译前(未优化)
for (int i = 0; i < 1000; i++) {
a[i] = i * 2;
}
// 编译后(循环展开示例)
a[0] = 0; a[1] = 2; a[2] = 4; ... a[999] = 1998;
4. 函数内联
// 编译前
static inline int add(int a, int b) {
return a + b;
}
int main() {
int x = add(3, 4); // 调用点
return x;
}
// 编译后(内联展开)
int main() {
int x = 7; // 直接替换为计算结果
return x;
}
5. 窥孔优化(Peephole Optimization)
// 编译前
x = x + 0; // 无意义操作
y = y * 1; // 无意义操作
// 编译后
// 上述两行被删除
三.内存与指针优化
1.内存访问优化
编译器会:
重排序内存访问以减少缓存缺失
合并相邻内存访问(如多次对同一变量的读写)
使用寄存器缓存频繁访问的内存区域
2.指针别名分析
void func(int *a, int *b) {
*a = 10;
*b = 20;
printf("%d\n", *a); // 编译器能否优化为printf("10\n")?
}
如果编译器能确定a和b不指向同一地址(即无别名),则可优化为常量输出
使用restrict关键字可帮助编译器进行更激进的指针别名分析:
void func(int *restrict a, int *restrict b) { ... }
四.指令调度与流水线优化
现代处理器采用指令流水线执行,编译器会:
指令重排序:调整无关指令顺序以填满流水线
延迟分支:在分支指令后插入有效指令以减少流水线停顿
预取指令:提前加载数据到缓存,减少内存访问延迟
例如:
// 原始代码
a = b + c;
d = e * f;
g = h + i; // 与前两行无依赖
// 优化后(指令重排序)
a = b + c;
g = h + i; // 提前执行,减少流水线等待
d = e * f;
五.GCC/Clang 高级优化选项
1.特定优化开关:
-ftree-vectorize # 启用循环向量化
-fomit-frame-pointer # 省略帧指针,减少栈操作
-finline-functions # 激进内联(可能增加代码体积)
2.链接时优化(LTO):
gcc -flto -O3 main.c lib.c -o program # 跨文件全局优化
3.Profile-Guided Optimization(PGO):
# 1. 编译带-profile参数
gcc -O3 -fprofile-generate main.c -o program
# 2. 运行程序收集执行信息
./program input1 input2 ...
# 3. 使用收集的信息重新编译
gcc -O3 -fprofile-use main.c -o program
六.优化案例分析
1.案例:循环优化
// 优化前(未对齐的内存访问)
for (int i = 0; i < N; i++) {
a[i] = b[i] + c[i];
}
// 优化后(手动对齐和向量化)
for (int i = 0; i < N; i += 4) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
a[i+2] = b[i+2] + c[i+2];
a[i+3] = b[i+3] + c[i+3];
}
2.案例:结构体成员排序
// 优化前(内存对齐导致浪费)
struct Data {
char a; // 1字节
int b; // 4字节 → 需对齐到4字节边界,浪费3字节
char c; // 1字节
short d; // 2字节 → 需对齐到2字节边界,浪费1字节
}; // 总大小:12字节
// 优化后(按大小降序排列)
struct Data {
int b; // 4字节
short d; // 2字节
char a; // 1字节
char c; // 1字节
}; // 总大小:8字节
七.优化陷阱与平衡之道
(一)调试与优化的冲突
高优化等级可能导致反汇编代码与源码行号不匹配,调试时需保留符号信息(-g 选项)。
变量被优化消失(如未使用的临时变量)可能引发“代码逻辑正确但运行结果异常”的诡异问题。
(二)过度优化的风险
-Ofast 选项可能违反C标准(如假定浮点运算无NaN),导致数值计算不可靠。
激进内联可能使代码体积暴涨,反而降低指令缓存命中率。
(三)代码可读性与可维护性的权衡
手动展开循环、大量使用宏内联可能使代码逻辑复杂化,需通过注释明确优化意图。
优先依赖编译器自动优化(如 -O2 已涵盖多数通用优化),仅在性能瓶颈处手动调优。
八.总结:让编译器成为你的优化助手
C语言编译优化的核心是“理解工具链,善用默认优化,精准突破瓶颈”:
基础优化先行:合理选择 -O2 等通用选项,利用编译器成熟的优化策略。
聚焦热点代码:通过性能分析工具(如 gprof、perf)定位瓶颈,针对性优化循环、函数调用等高频区域。
平衡技术取舍:在代码效率、调试便利性、可维护性间找到适合项目的平衡点。
掌握这些技巧,不仅能让生成的代码跑得更快,更能深入理解编译器与硬件的协同工作原理,写出“让编译器更好发挥”的高质量C语言代码。







)

)

)







