【Java高频面试问题】高并发篇
- Kafka原理
- 核心组件
- 高吞吐核心机制
- 高可用设计
- Kafka 如何保证消息不丢失
- 如何解决Kafka重复消费
- 一、生产者端:根源防重
- 二、消费者端:精准控制
- 三、业务层:幂等性设计(核心方案)
- 如何解决Kafka消息积压
- 一、紧急止血:快速降低积压
- 二、消费端优化:提升吞吐能力
- 三、生产端控流:源头限速
- 四、集群与架构改造
- 💎 决策树:按场景选择方案
Kafka原理
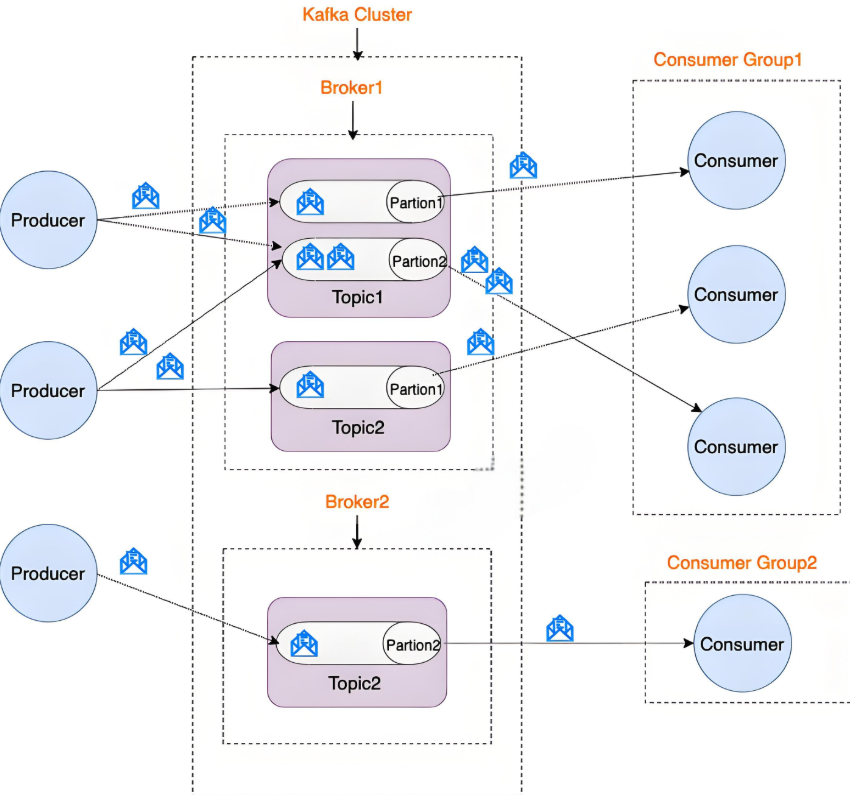
核心组件
| 组件 | 作用 |
|---|---|
| Producer | 生产者,将消息发布到指定Topic(可指定分区策略) |
| Broker | Kafka服务节点,组成集群存储消息(默认端口9092) |
| Topic | 逻辑消息分类(如订单流、日志流) |
| Partition | Topic的分区,每个分区是有序不可变的消息队列(实现水平扩展与并行处理) |
| Consumer | 消费者,通过Consumer Group订阅Topic(组内消费者竞争分区消费权) |
| ZooKeeper | 管理集群元数据、Broker注册、Leader选举(Kafka 2.8+开始支持KRaft模式替代ZK) |
高吞吐核心机制
-
分区与并行化
- Topic划分为多个Partition,分布在不同Broker,提升吞吐能力。
- Producer/Consumer可并行读写不同分区。
-
存储优化
- 顺序写入磁盘:避免随机I/O,速度提升百倍。
- **零拷贝(Zero-Copy)**:
sendfile()减少内核态数据拷贝。 - 页缓存:利用OS缓存加速读写,而非直接写盘。
-
批量处理
- Producer累积消息批量发送(
batch.size+linger.ms)。 - Consumer批量拉取消息(
max.poll.records)。
- Producer累积消息批量发送(
高可用设计
-
副本机制(Replica)
- 每个分区配置N个副本(如
replication.factor=3)。 - Leader处理读写,Follower同步数据,Leader故障时自动选举新Leader。
- 每个分区配置N个副本(如
-
ISR(In-Sync Replicas)
- 动态维护与Leader数据同步的副本集合。
- 仅ISR中的副本可参与Leader选举,确保数据一致性。
Kafka 如何保证消息不丢失
- 生产者设置
**acks=all**:所有ISR副本写入成功才返回确认。 - 生产者(Producer) 调用
send方法发送消息之后,为其添加回调函数。
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
- 消费者手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset (
enable.auto.commit=false+commitSync())。结合分布式锁可以防止消费者重复消费
如何解决Kafka重复消费
一、生产者端:根源防重
-
启用幂等生产者
- 设置
enable.idempotence=true,为每条消息附加唯一序列号(PID + Sequence Number),Broker 自动过滤重复提交的消息 。 - 适用场景:消息发送阶段的网络重试导致重复。
- 设置
-
事务消息机制
- 跨生产者与消费者的分布式事务(
transactional.id),确保消息发送与 Offset 提交原子性。
- 跨生产者与消费者的分布式事务(
producer.initTransactions(); // 初始化事务
producer.beginTransaction();
producer.send(record);
producer.commitTransaction(); // 提交事务
二、消费者端:精准控制
-
手动提交 Offset
- 关闭自动提交(
enable.auto.commit=false),在业务逻辑完成后再提交 Offset 。
- 关闭自动提交(
-
避免 Rebalance 导致重复
- 优化会话超时时间(
session.timeout.ms),防止误判消费者下线触发不必要的分区重分配 。
- 优化会话超时时间(
三、业务层:幂等性设计(核心方案)
-
唯一标识去重
- 生产者为消息注入全局唯一 ID(如 UUID),消费者通过 DB/Redis 判重 。
-
数据库唯一约束
- 利用数据库主键/唯一索引拦截重复数据插入(如订单ID)。
-
状态机驱动
- 基于业务状态流转(如订单“已支付”状态),拒绝重复操作 。
生产者防重复是第一道防线,消费者幂等设计是终极保障
如何解决Kafka消息积压
一、紧急止血:快速降低积压
-
扩容消费者组
- 增加消费者实例:确保消费者数量 ≤ 分区数,避免资源闲置(例如:4 分区主题至少配 4 个消费者)。
# 查看积压情况
kafka-consumer-groups.sh --bootstrap-server <broker> --group <group> --describe
-
跳过非关键消息
- 按时间戳跳过:
--to-datetime "2025-06-18T00:00:00.000"。 - 允许丢失部分数据时,重置 Offset 到最新位置:
- 按时间戳跳过:
kafka-consumer-groups.sh --bootstrap-server <broker> --group <group> --reset-offsets --to-latest --execute
二、消费端优化:提升吞吐能力
-
提升单消费者效率
- 多线程消费:单分区内使用线程池并行处理消息(需确保消息无序或分区内有序)。
- 批量拉取:增大
max.poll.records(默认 500)和fetch.max.bytes,减少网络交互次数。
-
异步化处理
- 将耗时操作(如 DB 写入、计算)移交线程池,消费者仅提交 Offset。
- 使用内存队列解耦:消费者快速拉取 → 队列缓冲 → 工作线程处理。
-
避免阻塞操作
- 优化慢 SQL、减少同步 RPC 调用,用缓存预加载数据。
三、生产端控流:源头限速
-
动态限流
- 令牌桶算法:控制生产者写入速率,匹配消费能力。
- 降级策略:业务高峰时关闭非核心消息生产者。
-
优化生产者参数
linger.ms=50 # 适当增大批量发送延迟
batch.size=16384 # 增大批次大小(默认 16KB)
compression.type=lz4 # 启用压缩减少网络负载
四、集群与架构改造
-
扩容分区与集群
- 增加主题分区数(需重启或新建主题),突破并行消费瓶颈。
- 扩展 Broker 节点和磁盘,提升集群整体吞吐。
-
分流与降级
- 新建临时 Topic:将积压消息转发到更多分区的新 Topic,消费者并行处理。
- 离线补偿:消费者直接消费最新消息,积压数据由离线任务补处理。
-
监控体系
- 实时监控
Consumer Lag,设置阈值告警(如 Lag >10,000 触发)。 - 跟踪 CPU、磁盘 IO、网络流量,定位集群瓶颈。
- 实时监控
💎 决策树:按场景选择方案
| 积压原因 | 优先级方案 |
|---|---|
| 消费能力不足 | 增加消费者 + 消费端多线程优化 |
| 生产流量瞬时飙升 | 生产者限流 + 消息跳过 |
| 分区数不足 | 扩容分区 + Broker 节点 |
| 消费逻辑阻塞(如慢 SQL) | 异步化改造 + 查杀异常进程 |
| 持续产能失衡 | 架构拆分 + 离线补偿 |
关键原则:
- 优先 扩容消费者 和 消费并行化 提升吞吐。
- 生产端限流是 预防性手段,避免系统雪崩。
- 分区数决定 并行上限,需提前规划弹性。
持续更新中…
)



:基于RAG的法律助手项目(上):总体流程简易实现)






)
Aerotech.A3200名空间)






