
文章目录
- 一、顺序表——ArrayList
- 1. 实现自己MyArrayList
- 1. 实现add基础方法
- 2. 实现指定位置加元素add方法
- 3. 完善数组打印方法display
- 4. 完善根据下标找元素get
- 5. 完善判断数字是否在数组中contains
- 6. 根据数字找下标indexOf
- 7. 更新指定下标元素set
- 8. 获取数组有效长度size
- 9. 清空数组clear
- 10. 指定数字删除
- 2. 使用ArrayList
- 3. 遍历ArrayList
- 4. 练练手
- 1. 杨辉三角
- 2. 简易牌组游戏
- 3. 小结
- 二、链表LinkList
- 1. 单向不带头非循环
- 1. 创造链表creatList
- 2. 遍历链表display
- 3. 获取链表长度sieze
- 4. 遍历链表寻找数字是否存在contains
- 5. 头插法插入数字addFirst
- 6. 尾插法插入数字addLast
- 7. 任意位置插入
- 前置知识:线性表表示的是有前驱和后继的表,除了首尾
- 前驱和后继:都有前一个数和后一个数
一、顺序表——ArrayList
指的是从逻辑上和物理上都是连续的表,因其特性(连着的嘛),根据数组的性质,我们可以把顺序表看成数组
我们知道ArrayList中有很多方法,但是有些方法不妨我们先自己实现下,理解其原理
1. 实现自己MyArrayList
//我们先定义一个接口,来放我们要实现的方法
public interface IArrayList {// 新增元素,默认在数组最后新增void add(int data);// 在 pos 位置新增元素void add(int pos, int data);// 判定是否包含某个元素boolean contains(int toFind);// 查找某个元素对应的位置int indexOf(int toFind);// 获取 pos 位置的元素int get(int pos);// 给 pos 位置的元素设为 valuevoid set(int pos, int value);//删除第⼀次出现的关键字keyvoid remove(int toRemove);// 获取顺序表⻓度int size();// 清空顺序表void clear();// 打印顺序表,注意:该⽅法并不是顺序表中的⽅法,为了⽅便看测试结果给出的void display();
}//我们在定义自己的MyArrayList类
public class MyArrayList implements IArrayList{private int [] array;private int usedSize;public static final int SIZE = 10;//默认大小//默认构造⽅法MyArrayList(){array = new int[SIZE];}// 将顺序表容量设置为capacityMyArrayList(int capacity){array = new int[capacity];}@Overridepublic void add(int data) {}@Overridepublic void add(int pos, int data) {}@Overridepublic boolean contains(int toFind) {return false;}@Overridepublic int indexOf(int toFind) {return 0;}@Overridepublic int get(int pos) {return 0;}@Overridepublic void set(int pos, int value) {}@Overridepublic void remove(int toRemove) {}@Overridepublic int size() {return 0;}@Overridepublic void clear() {}@Overridepublic void display() {}
}
构造方法我提供类两种,如果你指定了大小就按照你的大小来,否则就使用默认大小为10的数组
1. 实现add基础方法
我们要求我们指定一个数字data,把它存在顺序表的末尾
我们直接让有效数字的下标的元素等于我们的data就好了,为什么?
因为加入你的有效数字是4个,根据数组0下标起始,此时你的4下标还没有元素,我们直接存就好了 ,再让有效数字++一下
@Overridepublic void add(int data) {array[usedSize] = data;usedSize++;}
但是,这个代码就没有问题了吗,那我问你,如果你数组满了能存吗,嗯?
因此我们还要写一个判断数组是否满了的方法isFull()
private boolean isFull(){return usedSize == array.length;}
那我们满了是不是需要扩容啊,那我们在判断满了后还要写一个扩容方法growTo()
private void growTo(){//扩容两倍array = Arrays.copyOf(array,2*array.length);}
当然,我们还可以指定扩容几倍,因此我重载了下方法
private void growTo(int size){//扩容任意倍array = Arrays.copyOf(array,size*array.length);}
因此此时add()方法最终是
//将data存在末尾@Overridepublic void add(int data) {if(isFull()){//判断是否是空//我们要进行扩容操作growTo();}array[usedSize] = data;usedSize++;}
2. 实现指定位置加元素add方法
我们先想下要怎么去加,是不是要让你指定位置的元素数字往后移,你才有位置去加啊
但是你移动是从前面的数字往后移吗,这样会导致数据丢失
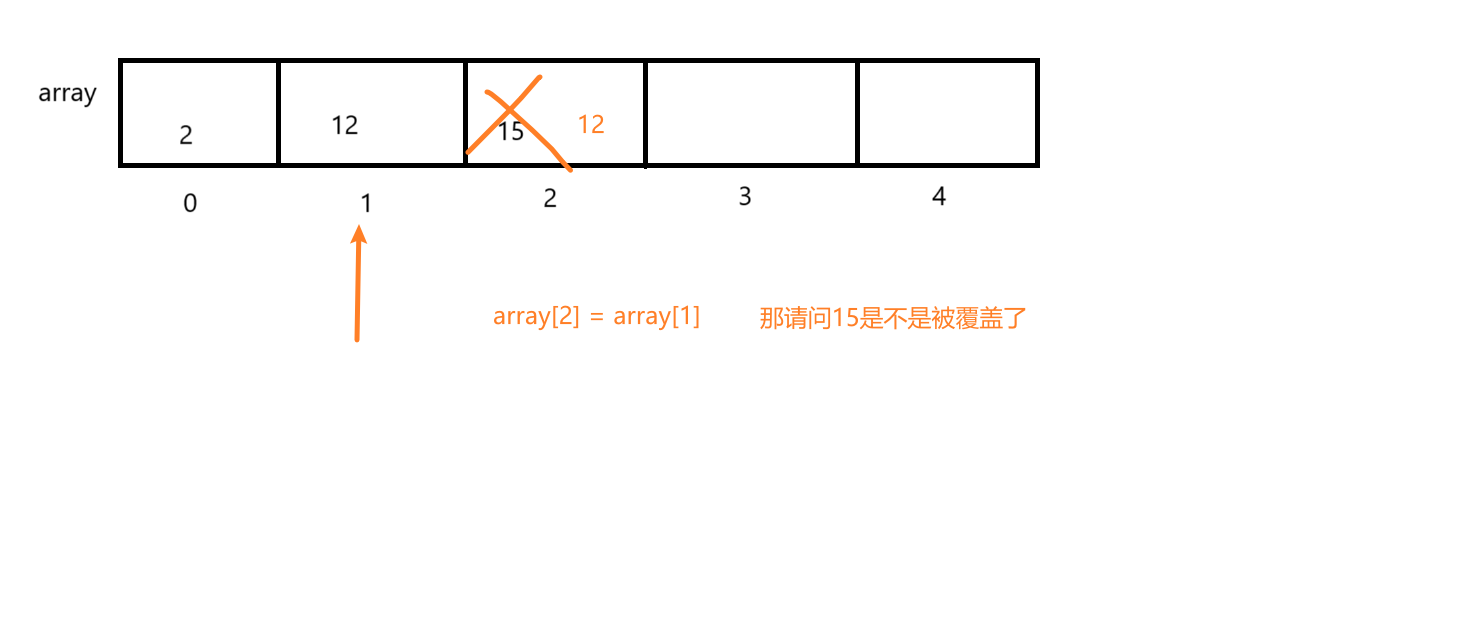
就跟我图里面的一样,这样是不是会导致后面的数据丢失了,因此我们需要从后面开始往前面循环
但是你又要注意了,你的有效数字现在是3个,那你能从下标为3开始吗,不可以,显然越界了
那你想循环的结束条件是什么,是不是走到你指定位置得位置就好了,此时原始数组中你的数字也完成了移动,就变成了这样
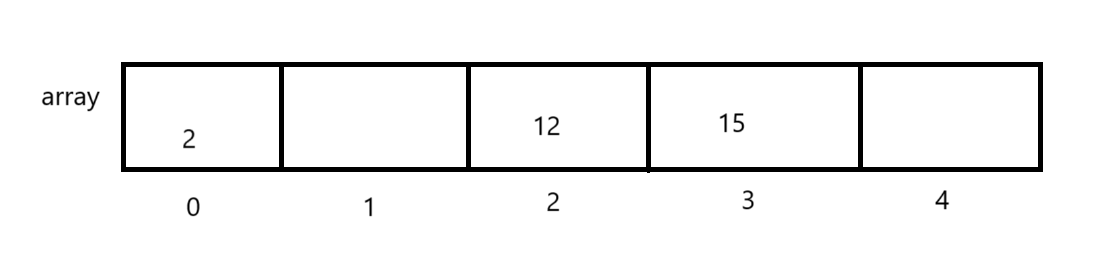
此时你直接插入元素就好了
但是你在想想,数组满了能插入吗,是不是要扩容
还有,你的插入位置能是负数吗,下标有负的吗
还有,你插入的位置能超过有效数字边界吗,那这样就没有意义了
因此我们再写个方法验证pos合法性
private void posIsNormal(int pos) throws PosException {if(pos < 0 || pos > usedSize){throw new PosException("下标非法");}}
对于下标非法,我自定义了一个异常类PosException,继承了RuntimeException类
public class PosException extends RuntimeException{public PosException() {}public PosException(String message) {super(message);}
}
最终在指定位置添加元素的方法如下
@Overridepublic void add(int pos, int data) {try {posIsNormal(pos);} catch (PosException e) {throw new RuntimeException(e);}if(isFull()){growTo();}for (int i = usedSize-1; i >= pos ; i--) {array[i+1] = array[i];}//此时我们放入元素array[pos] = data;//记得有效元素个数++一下usedSize++;}
3. 完善数组打印方法display
请注意打印的终止条件是有效元素个数,不能是数组长度,否则越界(超过有效数字范围就没有数字了啊)
@Overridepublic void display() {for (int i = 0; i < usedSize; i++) {System.out.println(array[i]);}}
4. 完善根据下标找元素get
那我们按照之前思路,是不是先要检查下标的合法性,你想想我们刚刚写的方法,如果下标和有效元素个数一样,它不会抛出异常
但是你想想,我有效元素个数对应的下标应该是我有效元素个数-1才对呀
那如果下标是我的有效元素个数,是不是就会越界,因此我们重新定义一个判断下标是否合法的方法
private void posIsNormalPlus(int pos) throws PosException{if(pos < 0 || pos >= usedSize){throw new PosException("寻找元素下标非法");}}
但是你又想,空的数组能获取到指定下标的元素吗,不行,因此我们还要写一个方法来判断是否是空数组
public boolean isEmpty(){return usedSize == 0;}
那我们是不是可以在定义一个空数组异常CapacityException,,继承了RuntimeException类
public class CapacityException extends RuntimeException{public CapacityException() {}public CapacityException(String message) {super(message);}
}
因此完整的根据下标找元素代码如下所示
@Overridepublic int get(int pos) throws CapacityException{try {posIsNormalPlus(pos);}catch (PosException e){throw new RuntimeException(e);}if(isEmpty()){throw new CapacityException("空数组非法");}return array[pos];}
但是有个小问题,当你的指定的下标是0并且usedSize也是0的时候会抛出异常,但是这也是一种异常情况,不影响
5. 完善判断数字是否在数组中contains
@Overridepublic boolean contains(int toFind) {for (int i = 0; i < usedSize; i++) {if(toFind == array[i]){return true;}}return false;}
不用担心空数组的问题,空数组循环根本进不来
6. 根据数字找下标indexOf
@Overridepublic int indexOf(int toFind) {for (int i = 0; i < usedSize; i++) {if(array[i] == toFind){return i;}}return -1;}
为什么可以return-1呢,因为你下标根本不存在-1嘛,返回了这个值就代表找不到
7. 更新指定下标元素set
老样子,想判断下标合法性,再更新
@Overridepublic void set(int pos, int value) {posIsNormalPlus(pos);array [pos] = value;}
8. 获取数组有效长度size
@Overridepublic int size() {return usedSize;}
9. 清空数组clear
@Overridepublic void clear() {usedSize = 0;}
为什么直接把usedSize置为0就好了,你这么想,我把有效元素个数变成了0,那我不就相当于数组消失了吗,后续我再添加元素的时候我直接覆盖就好了
10. 指定数字删除
那我们要删除数字是不是得先知道数字的下标呀,因此我们先调用indexOf()方法得到下标
如果找不到就说找不到
如果找得到,我们再使用循环让后一个元素盖住前一个元素就好了
@Overridepublic void remove(int toRemove) {int index = indexOf(toRemove);if(index == -1){System.out.println("找不到");return;}for (int i = index; i < usedSize-1; i++) {array[i] = array[i+1];}//如果是引用类型,最后一个多余的元素要置为nullusedSize--;//不要忘了有效数字个数要减少}
为什么循环结束是usedSize-1呢,因为会产生越界,这个之前解释过了
2. 使用ArrayList
- 因为
ArrayList是以泛型实现,因此我们要明确包装类 - 因为其实现了
RandomAccess接口,因此其可以随机访问 - 因为其实现了
Cloneable接口,因此其可以被克隆 - 因为其实现了
Serializasle接口,因此其可被序列化 ArrayList可以被动态扩容- 其在单线程中可用,在多线程可用可用
Vector或者是CopeOnWriteArray
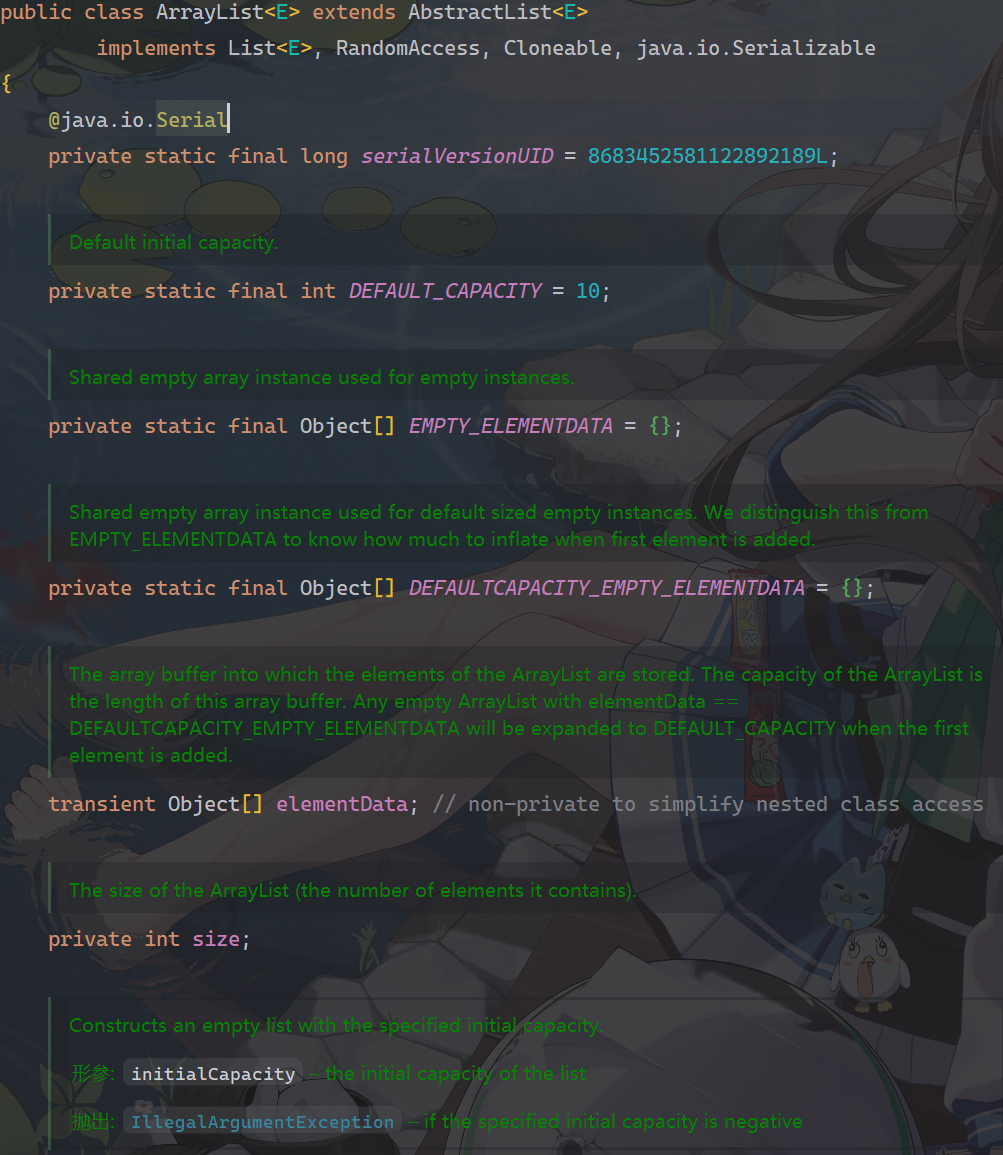
我们打开源码,这些是成员变量
我们看其构造方法
其中有一个带参的构造方法如下
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}
你看如果你给的值为0,就调用我们的空数组,否则就new一个新数组
但同时还有个不带参的构造方法,空数组等于空数组,它怎么放元素呢?
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
这个问题我们先按下不表,带回来解释
还有一个带参的构造方法
public ArrayList(Collection<? extends E> c) {Object[] a = c.toArray();if ((size = a.length) != 0) {if (c.getClass() == ArrayList.class) {elementData = a;} else {elementData = Arrays.copyOf(a, size, Object[].class);}} else {// replace with empty array.elementData = EMPTY_ELEMENTDATA;}}
这个构造方法意思就是你传入的类型只能是Collection类及其子类,其子类范围很广的
因此我们new对象可以这么来做
public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(1);arrayList.add(4);ArrayList<Integer> arrayLists = new ArrayList<>(arrayList);arrayLists.add(8);System.out.println(arrayLists);}
诶,可以使用另一个集合类去实例化当前的集合类
然后你打印的内容包括了之前集合类的内容:[1, 4, 8]
ArrayList内部也有很多方法
对于remove()方法,如果你直接写想要删除的数字,默认删除的是下标,因此如果你写的很大,比如remove(9999)会产生越界
因此如果你想删除对应数字,应该remove(new Integer(9999))
但是我们重点来看subList方法
这个方法可以截取顺序表中的一部分,范围是左闭右开List<Integer> list = arrayList.subList(0,2);,此时list对象中就存的是我们刚刚截取的顺序表
但是,如果你把list中元素改了,神奇的是原来arrayList中数字也发生了改变
打印结果:[1, 4]---->[10, 4]
为什么呢?因为subList方法在截取的时候里面存的是地址,你把地址指向的数字改了,那远顺序表对应元素不就改了吗
小问题:List和ArrayList区别是什么呢?
List <Integer> list = new ArrayList<>();和ArrayList <Integer。 arrayList = new ArrayList<>();
首先是其内部拓展性,ArrayList能够调用的方法比List更多,但是可读性List更胜一筹
因为你ArrayList你看不出来其实现了List接口
我们来解答之前的疑惑:“但同时还有个不带参的构造方法,空数组等于空数组,它怎么放元素呢?”
我们可以点开add方法看下
public boolean add(E e) {modCount++;add(e, elementData, size);return true;}
可以看到又调用了一个add方法,点开
private void add(E e, Object[] elementData, int s) {if (s == elementData.length)elementData = grow();elementData[s] = e;size = s + 1;}
我们看到了,即使是空数组,里面也调用了grow()方法,默认大小是10,我们点开grow()看看
private Object[] grow(int minCapacity) {int oldCapacity = elementData.length;if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity >> 1 /* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);} else {return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];}}
可以看到进行的是1.5被的扩容,然后你看到了newLength,想着我能不能自己定义扩容几倍,想重写,但是grow()被private修饰了,无法重写
3. 遍历ArrayList
有几种方法,第一个就是耳熟能详的遍历数组
//普通遍历for (int i = 0; i < arrayList.size(); i++) {System.out.print(arrayList.get(i)+" ");}
第二个是强遍历
//强遍历
for(Integer x:arrayList){System.out.print(x+" ");第三个就是使用迭代器,我们点开ArrayList的迭代器iterator,发现其父类List也有迭代器,发现其父类的父类Collcetion还是有迭代器,最终再其共同父类发现了最开始的迭代器方法
现在你可能有个问题,为什么这么多父类都有迭代器方法呢?
这是为了在不断的继承中扩展能力,职责分离,也是为了支持多态,每一次继承接口的能力扩展
//Iterator接口中
Iterator<T> iterator();
//Collection接口中
Iterator<E> iterator();
//List接口中
Iterator<E> iterator();
//ArrayList类中
public Iterator<E> iterator() {return new Itr();}/*** An optimized version of AbstractList.Itr*/private class Itr implements Iterator<E> {int cursor; // index of next element to returnint lastRet = -1; // index of last element returned; -1 if no suchint expectedModCount = modCount;// prevent creating a synthetic constructorItr() {}
因此我们就可以使用迭代器,其返回类型是Iterator即最原始的接口类,这也是为了多态
//使用迭代器
Iterator <Integer> it = arrayList.iterator();
while(it.hasNext()){System.out.print(it.next()+" ");
}
这段代码意思就是检测it对象位置下一个是否存在数字,存在就打印,it往下走一个位置,直到其之后不存在数据为止
但是我们用Iterator只能单向遍历,即从前往后
但是我们使用ListIterator可以反着遍历,只不过为了保持代码简洁性平时少用
当然其也可以正向或者反向打印,原理都差不多
ListIterator <Integer> lit = arrayList.listIterator();
//正向打印
while(lit.hasNext()){System.out.print(lit.next()+" ");
}
System.out.println();
//反向打印
while(lit.hasPrevious()){System.out.print(lit.previous()+" ");
}
4. 练练手
1. 杨辉三角
题目链接
我们刚刚已经学了顺序表,我们就想想如何使用顺序表实现它
给出提示:二维数组(顺序表)
List<List<Integer>>
我们先思考下,杨辉三角每一行都和上一行有关系,那是不是我可以把每一行看成一个一维数组,在二维数组中每个元素即是一维数组
那我通过二维顺序表中第i个元素(即第i行)获取上一个元素(即第i-1)行中的上方元素和左上方元素就好了
然后第一列和最后一列永远都是1不变,画个图给大家看下
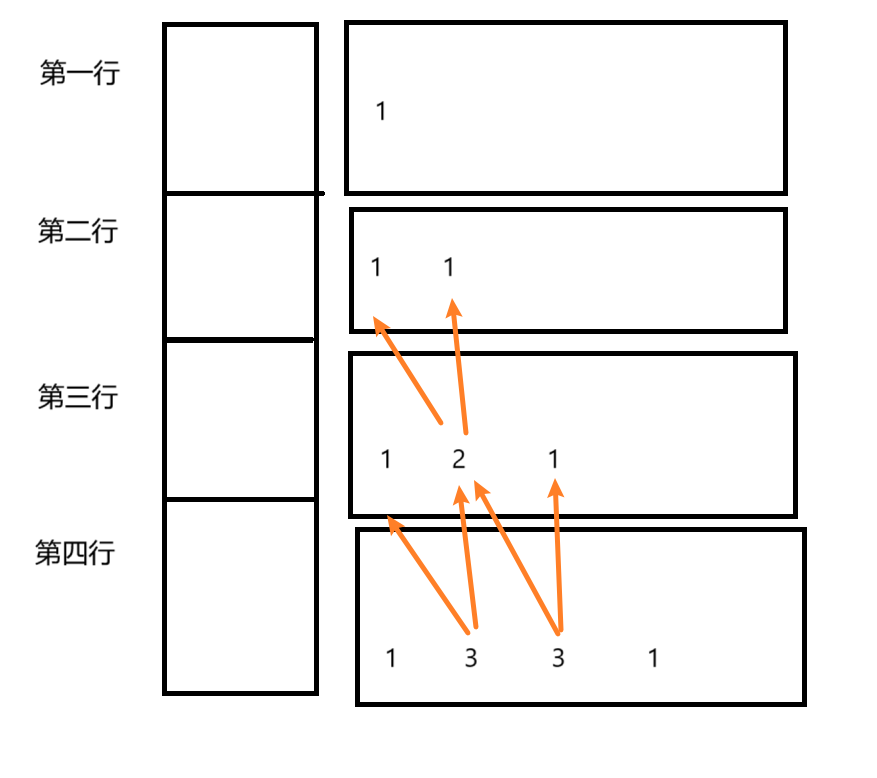
因此我们就来实现下
//杨辉三角public static void main(String[] args) {Scanner sc = new Scanner(System.in);int row = sc.nextInt();//求第几行List <List<Integer>> ret = new ArrayList<>();//二维数组List <Integer> list = new ArrayList<>();//第一行的一维数组list.add(1);//给第一行第一个数组加上数字1ret.add(list);//第一行的元素添加到二维数组的第一个元素即第一行for (int i = 1; i < row; i++) {//先处理每一行第一个元素都是1List <Integer> currentRow = new ArrayList<>();//当前行currentRow.add(1);//当前行第一个元素是1//此时我们需要获取到上一行的信息List<Integer> previousRow = ret.get(i-1);//定义一个临时二维数组获取上一行信息for (int j = 1; j < i; j++) {//列数不能超过行数//存储上一行的同一列和左边一列的数字int value = previousRow.get(j)+previousRow.get(j-1);//循环在一直往后走,因此只要满足条件就行currentRow.add(value);}//此时就剩下最后一个数字1currentRow.add(1);//再把每一行添加到二维数组中ret.add(currentRow);}}
你是不是想说第二行的时候上一行只有一个数,这样会不会越界,其实第二行的时候第二层循环根本进不来,自然就不会越界
2. 简易牌组游戏
我们先定义一个卡片类,存放每一个卡片信息
public class Card {private int value;//牌值private String pattern;//牌的图案public Card(int value, String pattern) {this.value = value;this.pattern = pattern;}@Overridepublic String toString() {return "Card{" +"value=" + value +", pattern='" + pattern + '\'' +'}';}
}
同时我们再定义一个卡组,来初始化和洗刷我们的牌,每一个方法都在注释中有讲解
public class CardGame {public static final String[] cardType = {"▲", "⬛", "○", "◆", "☆"};//返回值是List一维数组,即对象数组public List<Card> cardBuy() {//五组牌,每中图案十张牌List<Card> cardList = new ArrayList<>(10);for (int i = 0; i < 5; i++) {//对每种图案的牌进行初始化for (int j = 1; j <= 10; j++) {//每种图案对应10张牌,每种图案生成十张牌String suit = cardType[i];//当前循环对应的是第几种图案int rank = j;//牌值Card card = new Card(rank, suit);//每张牌就是一个对象cardList.add(card);//要把每张牌添加到牌组中}}return cardList;}public void shuffle(List<Card> cardList) {//洗牌Random random = new Random();//按顺序倒着换牌,就避免了前面换过了一次又换//你看假如我第41个牌和第4个牌换了//那么我下一次的随机数生成范围就只有0~40//而若如果正着来,加入我第4行和第45行换了//那我下一次随机数生成范围要保证不重复,还得要+5,才能保证不在原本范围内for (int i = cardList.size() - 1; i > 0; i--) {//为什么i不能等于0,因为Radom类中不允许为0不然就异常int index = random.nextInt(i);//我们还要写一个交换方法swap(cardList, i, index);}}private void swap(List<Card> cardList, int i, int j) {//交换牌//定义一个中间类,不能直接使用中间变量交换Card temp = cardList.get(i);cardList.set(i, cardList.get(j));cardList.set(j, temp);}
}
好,接下来我们就要写怎么抓牌了,我们采用三个人轮流抓五张牌,即一个人最多抓五次
我们思考下如何确定这个牌属于谁呢,我们想到了,可以使用顺序表
定义一个二维顺序表以每个元素存放每个人牌组
public static void main(String[] args) {CardGame cardGame = new CardGame();List<Card> cardList = cardGame.cardBuy();cardGame.shuffle(cardList);//先定义三个人的牌组List <Card> arrayList1 = new ArrayList<>();List <Card> arrayList2 = new ArrayList<>();List <Card> arrayList3 = new ArrayList<>();//定义二维顺序表存放每个人牌组信息List<List<Card>> arrayList = new ArrayList<>();arrayList.add(arrayList1);arrayList.add(arrayList2);arrayList.add(arrayList3);for (int i = 0; i < 5; i++) {for (int j = 0; j < 3; j++) {//每次摸牌删除0下标的牌,删除后后面的牌会往前补齐Card card = cardList.remove(0);//获取每个人牌组,让每个人牌组中拿一张牌arrayList.get(j).add(card);}}}
3. 小结
对于顺序表,每次空间不够就扩容1.5倍,势必会导致空间的浪费
并且每次插入数据的时候都需要去移动原有数据,如果我们要频繁更新数据,这时间复杂度必然大
因此顺序表适用于静态数据类型或者是数据查找等不频繁更新数据的场景

二、链表LinkList
链表和我们顺序表的接口类似,只不过它们在物理上不连续,但是在逻辑上内部是有联系的
它们是由一个个节点(结点)组成的
分为很多种:单向和双向、带头和不带头、循环和非循环
平常我们用到的大多数都是单向不带头非循环和单向带头非循环
我们先来看图,对于链表,每个节点是由值域和地址域组成的
值域里存放数值,值域里存放下一个节点的地址
我们先来看单向不带头非循环节点示意图
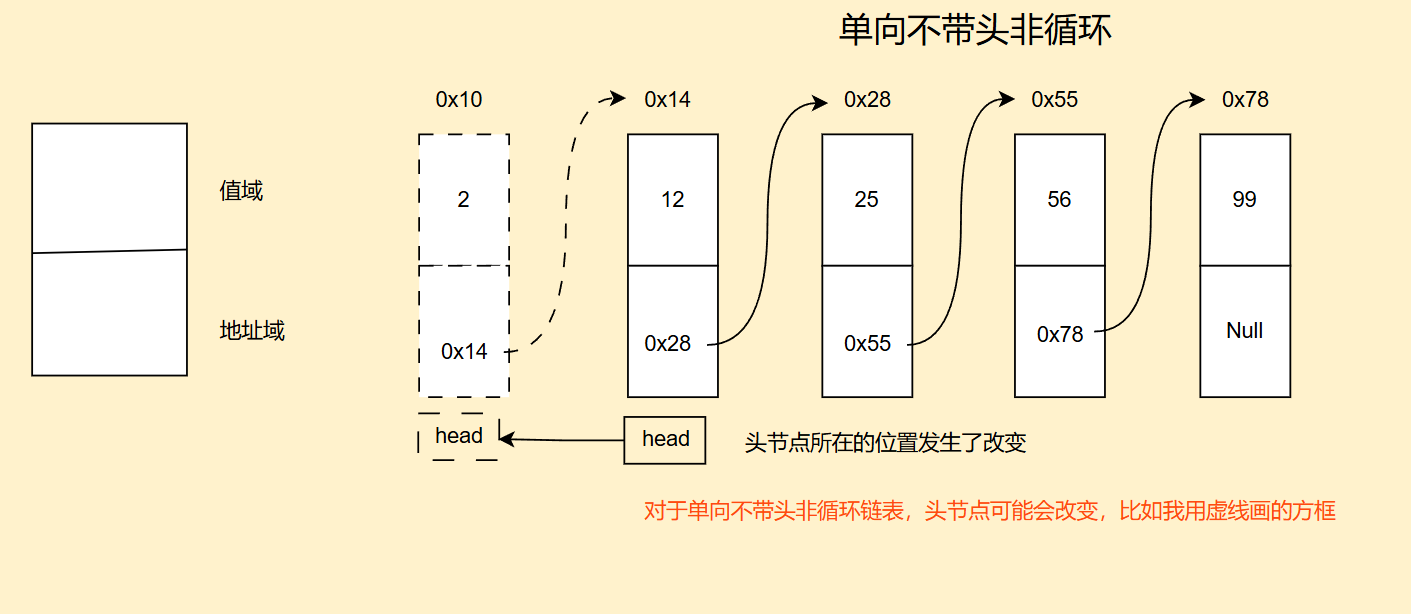
我们可以知道,其头节点并不稳定,会改变位置
我们再来看下单向带头非循环节点示意图
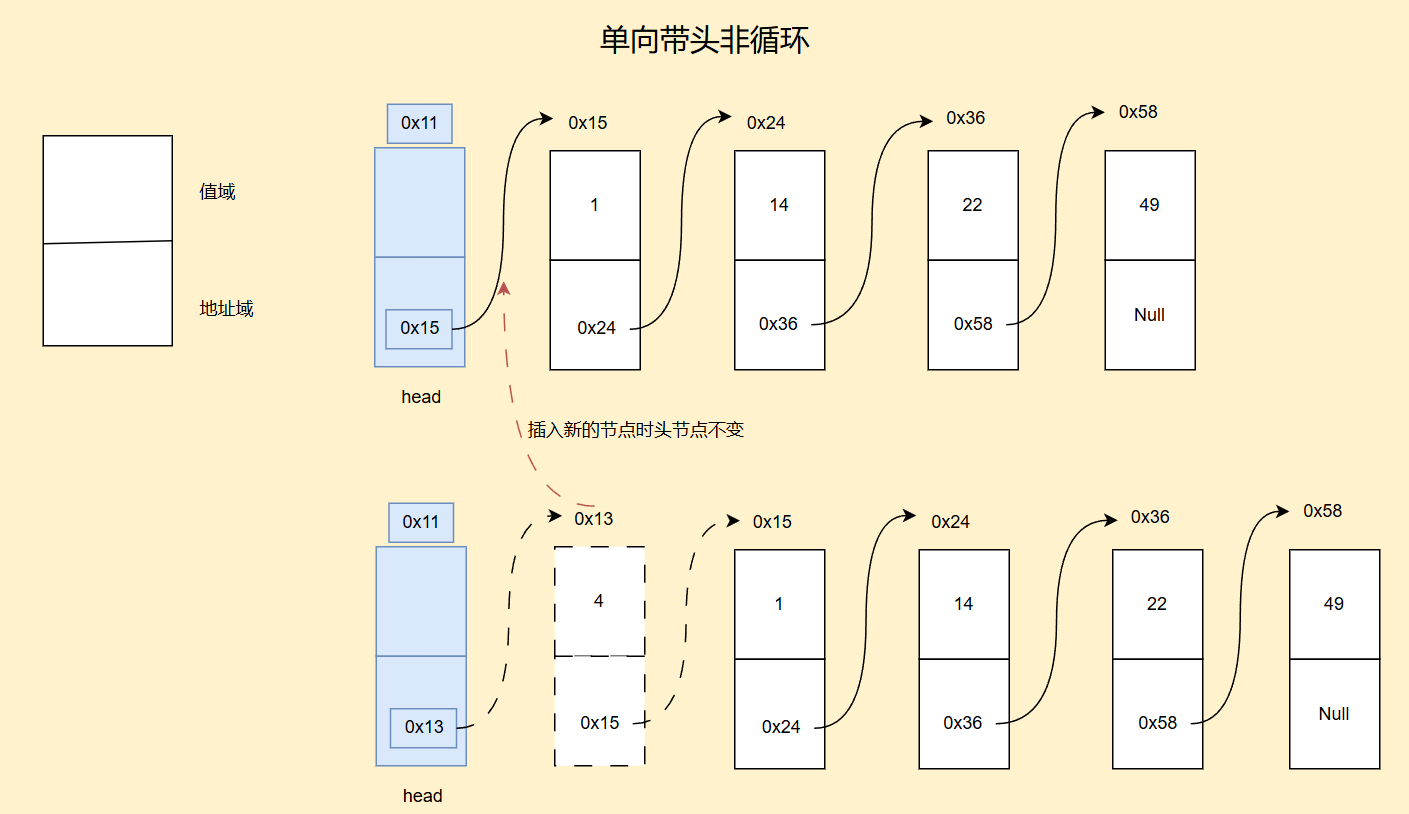
我们可以知道插入新的节点的时候头节点并不会改变,还是在原来位置
再来解释下什么是双向:我们刚刚的两个图都是只存了下一个节点的地址,只能从前往后遍历,反而双向就是存了下一个节点和上一个节点的地址,也就是说可以从后往前遍历
接着看什么是循环:就是说遍历到最后一个节点的时候,里面存的是第一个节点的地址,又可以倒回去
1. 单向不带头非循环
要使得节点有值和地址,数组肯定不行,那只能是类了,但是你不可能定义那么多类,那最后只能是定义内部类了
我们先定义一个链表类MyLinkList,然后在定义一个内部类LinkNode,这个内部类表示每个节点的信息
再在外部类MyLinkList中定义一个成员变量headAdress用来表示头节点地址
再定义一个接口用来拓展当前链表类MyLinkList功能
//ILink接口
public interface ILink {//头插法void addFirst(int data);//尾插法void addLast(int data);//任意位置插⼊,第⼀个数据节点为0号下标void addIndex(int index,int data);//查找是否包含关键字key是否在单链表当中boolean contains(int key);//删除第⼀次出现关键字为key的节点void remove(int key);//删除所有值为key的节点void removeAllKey(int key);//得到单链表的⻓度int size();//清空链表void clear();//展示链表void display();
}//自定义链表类MyLinkList
public class MyLinkList implements ILink{static class LinkNode {public int value;public LinkNode nextAdress;//用类名表示下一个节点地址//节点不用构造函数,待会需要让其指向下一个节点地址public LinkNode(int value) {this.value = value;}}//存的是链表首节点的地址public LinkNode headAdress;@Overridepublic void addFirst(int data) {}@Overridepublic void addLast(int data) {}@Overridepublic void addIndex(int index, int data) {}@Overridepublic boolean contains(int key) {return false;}@Overridepublic void remove(int key) {}@Overridepublic void removeAllKey(int key) {}@Overridepublic int size() {return 0;}@Overridepublic void clear() {}@Overridepublic void display() {}
}
我们现在要开始创建链表了,发现没有创建链表的方法,那不妨我们自己定义一个creatList()
1. 创造链表creatList
我们首先new几个节点对象,然后传值
此时我们思考下,nexxtAdress如何存下一个节点地址呢?
我们想到了,因为引用存的是地址,因此我们可以利用引用去引用下一个节点对象
最后不要忘了头节点的引用
@Overridepublic void creatListSimple() {LinkNode l1 = new LinkNode(10);LinkNode l2 = new LinkNode(13);LinkNode l3 = new LinkNode(19);LinkNode l4 = new LinkNode(22);l1.nextAdress = l2;l2.nextAdress = l3;l3.nextAdress = l4;this.headAdress = l1;}
2. 遍历链表display
你想,我们遍历是不是可以使用头节点进行遍历,打印当前节点的值,然后头节点地址就变成下一个节点地址,到最后一个节点发现这个节点中地址是null,那就说明到头了
但是此时有个问题,你是用的头节点地址进行遍历,那你遍历完之后头节点岂不是不是原来的地方了
因此我们还要定义一个临时地址来帮助我们遍历链表
@Overridepublic void display() {//定义一个临时地址代替head往后遍历LinkNode currentAdress = headAdress;while(currentAdress != null){System.out.println();currentAdress = currentAdress.nextAdress;}}
3. 获取链表长度sieze
这个也是跟刚刚逻辑一样,为了防止头节点丢失,定义一个临时节点代替头节点行动
@Overridepublic int size() {int count = 0;LinkNode currentAdress = headAdress;while(currentAdress != null){count++;currentAdress = currentAdress.nextAdress;}return count;}
4. 遍历链表寻找数字是否存在contains
也是一样的定义中间节点代替头节点行动
@Overridepublic boolean contains(int key) {LinkNode currentAdress = headAdress;while(currentAdress != null){if(currentAdress.value == key){return true;}currentAdress = currentAdress.nextAdress;}return false;}
5. 头插法插入数字addFirst
头插法指的就是把数字放入第一个节点位置,此时你插入的数字即变成了新的头节点
你想想,你插入节点后是不是要和后面的节点绑定,因此你需要绑定原来的头节点的地址
然后新的头节点指向就是你新插入的节点的地址了
@Overridepublic void addFirst(int data) {LinkNode currentAdress = new LinkNode(data);currentAdress.nextAdress = headAdress;headAdress = currentAdress;}
Q:为什么不先让head往前走,指向我们新插入的节点再让新插入的节点的
nextAdress再和原来头节点的地址进行绑定呢?
A:因为这样会导致原本的头节点地址丢失
为什么不用判断原本的头节点为空的情况?
如果你第一个节点是空的,根据我们刚刚的代码currentAdress.nextAdress = null,headAdress = null,本身就是第一个节点了,不用判断是不是空的了
使用链表我们无需移动元素,时间复杂度仅为O(1)
6. 尾插法插入数字addLast
我们先判断链表中有没有节点,没有的话我们直接让新插入的节点充当第一个节点
如果链表中本身存在节点,我们就要去寻找尾节点在哪里(即找到地址)
我们先定义一个临时节点替代头节点去遍历整个链表,找到尾节点后,让尾节点中的nextAdress地址赋予我们新插入节点的地址就可以了
@Overridepublic void addLast(int data) {LinkNode news = new LinkNode(data);if(headAdress == null){headAdress = news;}//找尾节点LinkNode currentAdress = headAdress;while(currentAdress.nextAdress != null){currentAdress = currentAdress.nextAdress;}currentAdress.nextAdress = news;}
7. 任意位置插入
首先我们得先判断你插入的下标是不是合法的
因此我们定义一个数组下标异常类IndexOutOfBoundException
public class IndexOutOfBoundException extends RuntimeException {public IndexOutOfBoundException() {}public IndexOutOfBoundException(String message) {super(message);}
}
还有处理头插和尾插的情况
接着我们再来想,之前我不是说过了单向链表我们不知道前一个节点的地址
因此我们还要写个方法searchIndex获取我们插入下标的前一个节点的地址
//可能还要其他方法来调用这个方法private LinkNode searchIndex(int index){int length = size();if(index <0 || index > length){throw new IndexOutOfBoundException("下标异常");}LinkNode currentAdress = headAdress;int count = 0;while (count != index -1){currentAdress = currentAdress.nextAdress;count++;}return currentAdress;}
在while循环中为什么是减1为终止条件
因为你要赋予下一个节点的地址,相当于新插入节点的前一个节点了
你看,比如我想插入下标为4的地方,那我的循环到下标为2的地方就停住了,然后currentAdress = currentAdress.nextAdress;,此时我currentAdress中存的就是下标为3的地址,不就是我们正要找的吗
我们回到任意位置插入的方法中,找到前一个节点地址后,我们还要判断有没有找到,如果没找到直接返回,如果找到了我们就插入
但是问题是怎么插入呢(我们采用插在我们指定下标的前面)?
我们先定义一个新的节点,接收我们给的数值,然后让我们新的这个节点的nextAdress赋予下一个节点的地址,让新入的节点先和后面节点建立联系
然后通过我们刚刚的找到新入的节点的上一个节点的地址,让上一个节点的,nextAdress赋予我们新插入节点的地址
此时我们新插入的节点就和前面与后面建立了联系,成功插入
@Overridepublic void addIndex(int index, int data) {if(index < 0 || index > size()){throw new IndexOutOfBoundException("数组下标异常");}if(index == 0){//头插法addFirst(data);}if(index == size()){//尾插法addLast(data);}//正式的任意位置插入数字LinkNode currentAdress = searchIndex(index);if(currentAdress == null){return;}LinkNode node = new LinkNode(data);node.nextAdress = currentAdress.nextAdress;currentAdress.nextAdress = node;}
最后我们来测试下目前各个功能是否正常
public static void main(String[] args) {MyLinkList myLinkList = new MyLinkList();myLinkList.creatListSimple();System.out.print("原本链表:");myLinkList.display();System.out.print("求链表个数:");System.out.print(myLinkList.size());System.out.print("头插:");myLinkList.addFirst(999);myLinkList.display();System.out.print("尾插:");myLinkList.addLast(666);myLinkList.display();System.out.print("任意位置插:");myLinkList.addIndex(2,888);myLinkList.display();System.out.print("验证数字存在性:888是否存在:");System.out.print(myLinkList.contains(888));System.out.println();System.out.print("最终链表展示:");myLinkList.display();}
打印结果是正常的





的带状细胞对NLP中的深层语义分析有什么积极的影响和启示)














实践)