KNN:
这里要求我们完成一个KNN分类器,实现对图片使用KNN算法进行分类标签
k_nearest_neighbor.py
这里要求我们完成4个接口
# X:测试集
# 使用两个循环
def compute_distances_two_loops(self, X):num_test = X.shape[0]num_train = self.X_train.shape[0]dists = np.zeros((num_test, num_train))for i in range(num_test):for j in range(num_train):# TODO:# 计算测试集中第i张图片与训练集中第j张图片的L2距离,并储存到dists[i,j]# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****dists[i,j]=np.sqrt(np.sum(np.square(X[i,:]-self.X_train[j,:])))# X[i,:]选取测试集第i张图片,self.X_train[j,:]选取测试集第j张图片,相减得到各元素之差# np.square得到各元素平方# np.sum对每列求和# np.sqrt再对和开方# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return dists
# X:测试集
# 使用一个循环
def compute_distances_one_loop(self, X):num_test = X.shape[0]num_train = self.X_train.shape[0]dists = np.zeros((num_test, num_train))for i in range(num_test):# TODO:同上# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****dists[i,:]=np.sqrt(np.sum(np.square(self.X_train-X[i,:]),axis=1))# 由于自动扩展,self.X_train的每行j都减去X[i,:]# np.square对每个元素平方# np.sum(axis=1)对每行元素求和# np.sqrt对每个元素开平方# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return dists
# X:测试集
# 不使用循环
def compute_distances_no_loops(self, X):num_test = X.shape[0]num_train = self.X_train.shape[0]dists = np.zeros((num_test, num_train))# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****dists=np.sqrt(np.sum(np.square(self.X_train-X[:,None,:]),axis=2))# X[:,None,:]将X的形状从(num_test,D)变为(num_test,1,D),# 这样可以实现自动扩展,X_train的每行都减去X,得到结果的size为(num_test,num_train,D)# np.square对每个元素平方# np.sum(axis=2)对D所对应的维度的元素求和# np.sqrt对每个元素开平方# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return dists
# dists:距离矩阵
# k:最近邻个数
# 返回预测标签
def predict_labels(self, dists, k=1):num_test = dists.shape[0]y_pred = np.zeros(num_test)for i in range(num_test):closest_y = []# TODO: 找到k个最近邻的标签# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****knn=np.argsort(dists[i,:])[0:k] # argsort返回从小到大排序的索引# 取前k个索引# dists[i,:]是第i个测试样本到所有训练样本的距离# knn是第i个测试样本的k个最近邻的索引closest_y=self.y_train[knn]# 通过索引knn找到对应的标签# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# TODO: 统计k个最近邻的标签中出现次数最多的标签# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****y_pred[i]=np.argmax(np.bincount(closest_y.astype(int)))# np.bincount统计每个标签出现的次数# closest_y.astype(int)将标签转换为整数类型# np.argmax找到出现次数最多的标签的索引# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return y_pred通过比较,三种计算dists矩阵的方法效率比较如下:
Two loop version took 14.840988 seconds
One loop version took 33.446717 seconds
No loop version took 0.102279 seconds可以发现完全向量化的运算效率很高,所以尽量使用向量化运算
交叉验证及寻找最优k
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]X_train_folds = []
y_train_folds = []
# TODO:将X_train和y_train分为num_folds份# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****X_train_folds=np.array(np.split(X_train,num_folds))
y_train_folds=np.array(np.split(y_train,num_folds))
#np.split将传入数组平均分为nums_folds份# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# 储存k所对应的所有folds作为测试集的acc
k_to_accuracies = {}# TODO: 使用cross-validation计算每个k对应的acc
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# 遍历所有可能的k
for k in k_choices:curr_acc=[]for i in np.arange(num_folds): # i 为测试集下标idx = np.array([j for j in range(num_folds) if j!=i]) # 取出训练集下标X_test_n=X_train_folds[i]y_test_n=y_train_folds[i]X_train_n=np.concatenate(X_train_folds[idx],axis=0) # 将训练集连接y_train_n=np.concatenate(y_train_folds[idx],axis=None) #对应标签连接classifier = KNearestNeighbor()classifier.train(X_train_n, y_train_n)y_test_n_pred = classifier.predict_labels(classifier.compute_distances_no_loops(X_test_n), k) #得到预测标签向量num_correct = np.sum(y_test_n_pred == y_test_n) # 计算正确预测标签向量acc = float(num_correct) / len(y_test_n) # 计算acccurr_acc.append(acc)k_to_accuracies[k]=curr_acc# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# Print out the computed accuracies
for k in sorted(k_to_accuracies):for acc in k_to_accuracies[k]:print('k = %d, accuracy = %f' % (k, acc))结果可视化如下:
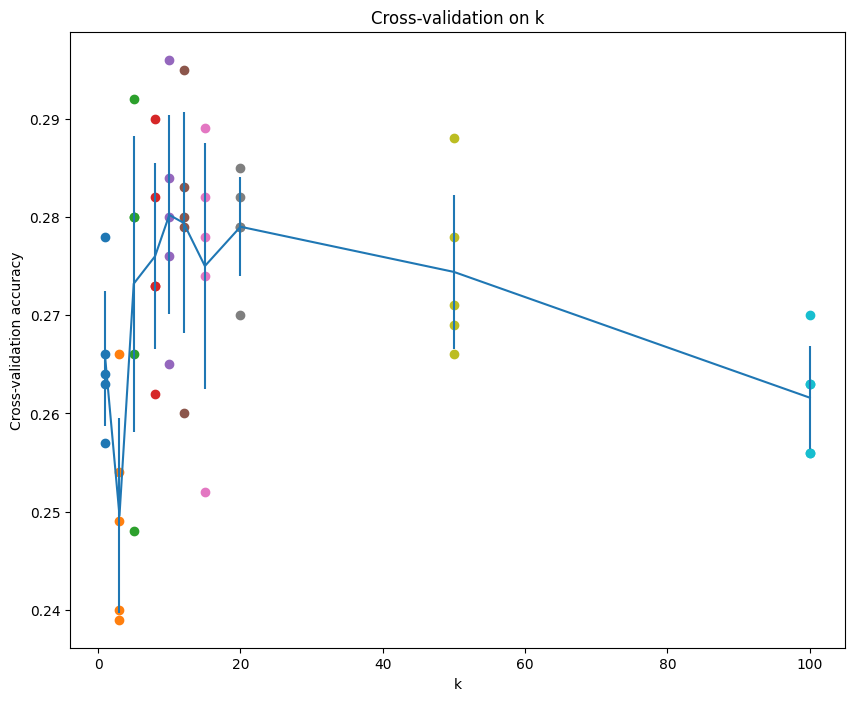
可以发现acc最优的k = 10
SVM:
Loss:
梯度:
linear_svm.py
# W:权重矩阵 (D,C)
# X:测试集 (N,D)
# y:标签 (N,)
# reg:正则化强度
# loss:损失值
# dW:梯度 (D,C)
def svm_loss_naive(W, X, y, reg):dW = np.zeros(W.shape) # 初始化梯度为0num_classes = W.shape[1] # 类别数num_train = X.shape[0] # 训练样本数loss = 0.0for i in range(num_train):f=0scores = X[i].dot(W) # 计算第i个样本的得分correct_class_score = scores[y[i]] # 获取正确类别的得分for j in range(num_classes):if j == y[i]:continuemargin = scores[j] - correct_class_score + 1 # 这里设置的delta为1if margin > 0: # margin大于0才计算损失和梯度,否则损失和梯度都为0loss += margin dW[:,j]+=X[i] # 累加梯度,这里多加了正确标签的梯度f+=1 # 计算多加的次数dW[:,y[i]] += -f*X[i] # 修正正确标签的梯度# 平均损失和梯度loss /= num_traindW/=num_train# 添加正则化损失loss += reg * np.sum(W * W)# TODO: 添加正则化梯度# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****dW+=2*reg*W# 正则化梯度,乘以2是因为我们对W的平方求导# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return loss, dW
def svm_loss_vectorized(W, X, y, reg):loss = 0.0dW = np.zeros(W.shape) # TODO: 向量化计算Loss# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****num_test=len(X) #样本数scores=X.dot(W) # 计算所有样本的得分 (N,C)correct_class_scores=scores[np.arange(num_test),y] # 获取所有样本的正确类别得分 (N,)margin=np.clip(scores-correct_class_scores.reshape([-1,1])+1,0,None) # 计算margin (N,C),并将小于0的值设为0# correct_class_scores.reshape([-1,1]) 将正确类别得分转换为列向量# scores-correct_class_scores.reshape([-1,1]) 计算每个类别的margin# np.clip(...,0,None) 将小于0的margin设为0margin[np.arange(num_test),y]=0 # 将正确类别的margin设为0loss=np.sum(margin)/num_test + reg * np.sum(np.square(W)) # 平均损失加上正则化损失# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# TODO: 向量化计算梯度# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****m = (margin>0).astype(int) # 将margin大于0的部分设为1(表示需要计入这个权重所对应的梯度),其他部分为0 (N,C)f=np.sum(m,axis=1) # 计算每个样本违反margin的类别数 (N,)m[np.arange(num_test),y]=-f # 将正确类别的margin设为负的违反类别数 (N,C),用于特别处理正确类别的梯度dW= X.T.dot(m)/num_test + 2*reg*W # X.T.dot(m) 计算每个类别的梯度 (D,C),dW[i,j]是第i个特征对第j个类别的梯度# 那么其就等于X[i].dot(m[:,j])# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return loss, dWlinear_classifier.py
# X: 训练数据 (N, D)
# y: 标签 (N,)
# learning_rate: 学习率
# reg: 正则化强度
# num_iters: 迭代次数
# batch_size: batch大小
# verbose: 是否打印训练过程
# 输出:每次iteration的loss
def train(self, X, y, learning_rate=1e-3, reg=1e-5, num_iters=100,batch_size=200, verbose=False):num_train, dim = X.shapenum_classes = np.max(y) + 1 # 类别数if self.W is None:self.W = 0.001 * np.random.randn(dim, num_classes) #随机初始化Wloss_history = []for it in range(num_iters):X_batch = Noney_batch = None# TODO: 随机采样一个batch# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****idx=np.random.choice(num_train,batch_size) #从num_train个样本中随机选择batch_size个样本的索引X_batch=X[idx,:]y_batch=y[idx].reshape(1,-1) #重建为(N,)# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****loss, grad = self.loss(X_batch, y_batch, reg)loss_history.append(loss)# TODO: 更新权重W# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****self.W-=learning_rate*grad# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****if verbose and it % 100 == 0:print('iteration %d / %d: loss %f' % (it, num_iters, loss))return loss_history
# X: 测试数据 (N, D)
# 返回预测标签 (N,)
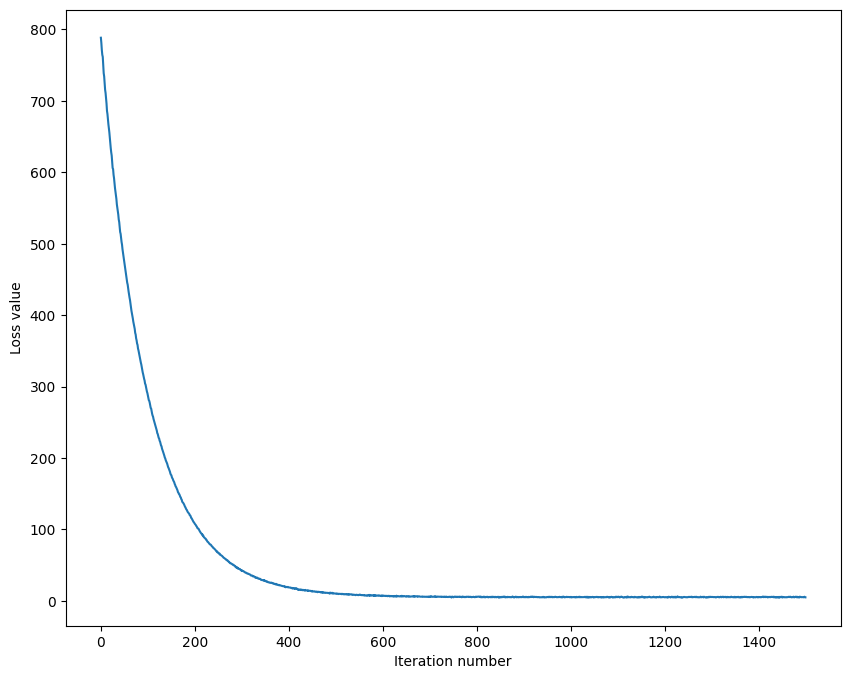
def predict(self, X):y_pred = np.zeros(X.shape[0])# TODO: 计算预测标签# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****y_pred=np.argmax(X.dot(self.W),axis=1).reshape(1,-1)# 找到得分最高的样本对应的索引,并重建为列向量# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return y_predloss曲线如下:
网格化搜索寻找最优超参数:
# 使用验证集来调整超参数(正则化强度和学习率)。
learning_rates = np.linspace(5e-8, 5e-7,num=5)
regularization_strengths = np.linspace(2e4, 3e4,num=5)# 储存键值对{(学习率,正则化强度):(训练acc,验证acc)}
results = {}
best_val = -1 # 记录最优验证acc
best_svm = None # 最优验证acc对应的SVM对象# TODO: 使用验证集来调整超参数(学习率和正则化强度)。
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****for lr in learning_rates:for reg in regularization_strengths:svm = LinearSVM()loss_hist = svm.train(X_train, y_train, learning_rate=lr, reg=reg,num_iters=1500, verbose=True)y_train_pred = svm.predict(X_train)y_val_pred = svm.predict(X_val)train_acc=np.mean(y_train == y_train_pred)val_acc=np.mean(y_val == y_val_pred)results[(lr,reg)]=(train_acc,val_acc)if(val_acc>best_val):best_svm=svmbest_val=val_acc# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****for lr, reg in sorted(results):train_accuracy, val_accuracy = results[(lr, reg)]print('lr %e reg %e train accuracy: %f val accuracy: %f' % (lr, reg, train_accuracy, val_accuracy))print('best validation accuracy achieved during cross-validation: %f' % best_val)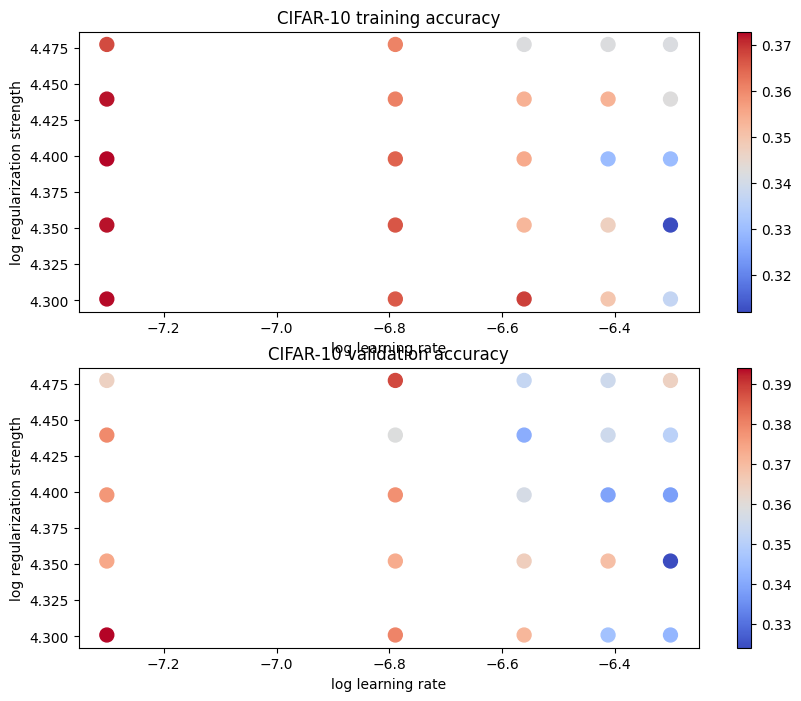
可以看到,在搜索范围内,学习率和正则化强度越小,train_acc和val_acc都是越高,也许还需要扩大一下搜索边界,且换成对数范围搜索会更佳
可视化各个类所对应的权重矩阵:

Softmax:
Loss:
梯度:
softmax.py
def softmax_loss_naive(W, X, y, reg):loss = 0.0dW = np.zeros_like(W)# TODO: 使用显示循环计算loss和梯度# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****num_train = X.shape[0]num_classes = W.shape[1]for i in range(num_train): # 第i个样本scores = X[i].dot(W) # 第i个样本的得分向量 (C,)exp_scores = np.exp(scores - np.max(scores))probs = exp_scores / np.sum(exp_scores) # 类别概率 (C,)loss += -np.log(probs[y[i]]) # 第i个样本的交叉熵损失for j in range(num_classes): # 第j个类别# X[i]与第j个类别 能贡献到的权重梯度就是 dw[:,j]if j == y[i]: # 正确类别的贡献dW[:,j] += (probs[j] - 1) * X[i] # dW[:,j] = (exp_scores[j]/np.sum(exp_scores) - 1) * X[i]else : # 错误类别的贡献 dW[:,j] += probs[j] * X[i] # dW[:,j] = 1/np.sum(exp_scores) * exp_scores[j] * X[i]loss = loss / num_train + reg * np.sum(np.square(W))dW = dW / num_train + 2 * reg * W# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return loss, dW
def softmax_loss_vectorized(W, X, y, reg):loss = 0.0dW = np.zeros_like(W)# TODO: 向量化计算loss和梯度# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****num_train = X.shape[0] # 样本数Nscores = X.dot(W) # (N, C)exp_scores = np.exp(scores - np.max(scores)) # (N, C)total = np.sum(exp_scores, axis=1,keepdims=True) # (N, 1)probs = exp_scores / total # (N, C)loss = -np.sum(np.log(probs[np.arange(num_train), y])) / num_train + reg * np.sum(np.square(W))probs[np.arange(num_train), y] -= 1 # 正确类别减1dW = X.T.dot(probs) / num_train + 2 * reg * W # (D, C)# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return loss, dW搜索超参数
# 使用验证集搜索超参数
from cs231n.classifiers import Softmax
results = {}
best_val = -1
best_softmax = None
learning_rates = np.linspace(8e-8, 2e-7,10)
regularization_strengths = np.linspace(1e4, 5e4,3)# TODO: 和SVM的一样
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****for lr in learning_rates:for reg in regularization_strengths:clf=Softmax()loss_hist = clf.train(X_train, y_train, learning_rate=lr, reg=reg,num_iters=1500, verbose=True)y_train_pred = clf.predict(X_train)y_val_pred = clf.predict(X_val)train_acc=np.mean(y_train == y_train_pred)val_acc=np.mean(y_val == y_val_pred)results[(lr,reg)]=train_acc,val_accif(val_acc>best_val):best_softmax=clfbest_val=val_acc
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# Print out results.
for lr, reg in sorted(results):train_accuracy, val_accuracy = results[(lr, reg)]print('lr %e reg %e train accuracy: %f val accuracy: %f' % (lr, reg, train_accuracy, val_accuracy))print('best validation accuracy achieved during cross-validation: %f' % best_val)权重矩阵可视化:

two_layer_net:
两层神经网络
先经过第一层,再经过ReLU层,再经过第二层,再经过softmax层,最后输出
前向传播:
Loss:
梯度:
其中
其中
其中
neural_net.py
# X: 测试集 (N,D)
# y: 标签 (N,)
# reg: 正则化强度
# 返回值:loss, grads
def loss(self, X, y=None, reg=0.0):# Unpack variables from the params dictionaryW1, b1 = self.params['W1'], self.params['b1']W2, b2 = self.params['W2'], self.params['b2']N, D = X.shape# Compute the forward passscores = None# TODO: 计算前向传播# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****z1=X.dot(W1) + b1 # 计算第一层的线性变换a1=np.maximum(0,z1) # ReLU激活函数scores=a1.dot(W2) + b2 # 计算第二层的线性变换# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# If the targets are not given then jump out, we're doneif y is None:return scores# Compute the lossloss = None# TODO: 计算loss, 包括数据损失和W1,W2的Lw正则化损失, 使用softmax损失函数# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****exp_socres = np.exp(scores - np.max(scores, axis=1, keepdims=True)) # exp得分probs = exp_socres / np.sum(exp_socres, axis=1, keepdims=True) # 概率loss = -np.sum(np.log(probs[np.arange(N), y])) / N + reg * (np.sum(np.square(W1)) + np.sum(np.square(W2))) # 数据损失 + L2正则化损失# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# Backward pass: compute gradientsgrads = {}# TODO: 计算梯度# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****probs[np.arange(N), y] -= 1 # 正确类别的概率减1grads['W2'] = a1.T.dot(probs) / N + 2 * reg * W2grads['b2'] = np.sum(probs, axis=0) / Nda1 = probs.dot(W2.T)da1[z1 <= 0] = 0 # ReLU 反向传播,小于等于0的部分梯度为0grads['W1'] = X.T.dot(da1) / N + 2 * reg * W1grads['b1'] = np.sum(da1, axis=0) / N# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return loss, grads
def train(self, X, y, X_val, y_val,learning_rate=1e-3, learning_rate_decay=0.95,reg=5e-6, num_iters=100,batch_size=200, verbose=False):num_train = X.shape[0]iterations_per_epoch = max(num_train / batch_size, 1)# Use SGD to optimize the parameters in self.modelloss_history = []train_acc_history = []val_acc_history = []for it in range(num_iters):X_batch = Noney_batch = None# TODO: 创建随机batch# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****idx = np.random.choice(num_train, batch_size)X_batch = X[idx,:]y_batch = y[idx] # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# Compute loss and gradients using the current minibatchloss, grads = self.loss(X_batch, y=y_batch, reg=reg)loss_history.append(loss)# TODO: 梯度下降# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****self.params['W1'] -= learning_rate*grads['W1']self.params['b1'] -= learning_rate*grads['b1']self.params['W2'] -= learning_rate*grads['W2']self.params['b2'] -= learning_rate*grads['b2']# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****#if verbose and it % 100 == 0:#print('iteration %d / %d: loss %f' % (it, num_iters, loss))# Every epoch, check train and val accuracy and decay learning rate.if it % iterations_per_epoch == 0:# Check accuracytrain_acc = (self.predict(X_batch) == y_batch).mean()val_acc = (self.predict(X_val) == y_val).mean()train_acc_history.append(train_acc)val_acc_history.append(val_acc)# Decay learning ratelearning_rate *= learning_rate_decayreturn {'loss_history': loss_history,'train_acc_history': train_acc_history,'val_acc_history': val_acc_history,}
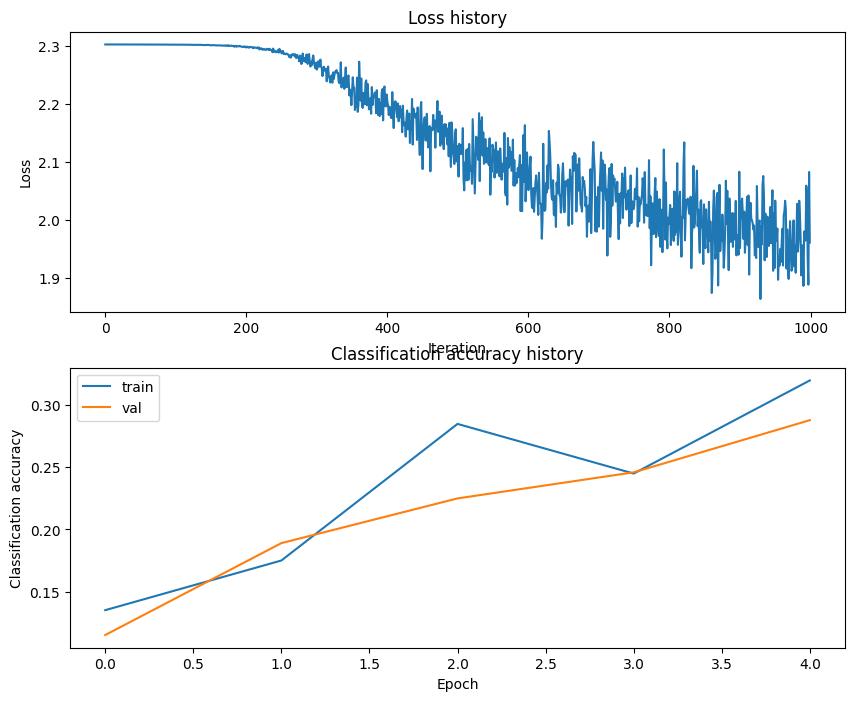
def predict(self, X):y_pred = None# TODO: 预测# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****z1=np.dot(X,self.params['W1'])+self.params['b1']a1=np.maximum(0,z1)scores=np.dot(a1,self.params['W2'])+self.params['b2']y_pred=np.argmax(scores,axis=1)# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return y_pred训练的loss与acc如下
网格化搜索超参数
best_net = None # store the best model into this
best_val = -1
best_hs=None
best_lr=None
best_reg=Noneinput_size = 32 * 32 * 3
hidden_size = [50,100]
num_classes = 10learning_rate = np.linspace(0.75e-3,1.25e-3,5)
reg_ = np.linspace(0.2,0.4,5)# TODO: 网格化搜索超参数
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for hs in hidden_size:for lr in learning_rate:for reg in reg_:net = TwoLayerNet(input_size, hs, num_classes)stats = net.train(X_train, y_train, X_val, y_val,num_iters=1000, batch_size=200,learning_rate=lr, learning_rate_decay=0.95,reg=reg, verbose=True)train_acc = stats['train_acc_history'][-1]val_acc = stats['val_acc_history'][-1]loss = stats['loss_history'][-1]print('hs %d | lr %0.3e | reg %0.3e | loss= %0.3e | train_acc %f | val_acc %f'%(hs, lr, reg, loss, train_acc, val_acc))if(val_acc > best_val):best_val = val_accbest_net = netbest_hs = hsbest_lr = lrbest_reg = regprint('best val_acc = %f for hs %d | lr %e | reg %e' %(best_val,best_hs,best_lr,best_reg))# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****图形特征提取:
HOG特征:
通过统计图像局部区域的梯度方向分布来表征图像,可以捕获图像的形状和边缘信息
Color Histogram HSV特征:
在HSV颜色空间中统计颜色分布的特征描述,来表征图像的颜色信息
使用提取特征数据网格化搜索SVM超参
# Use the validation set to tune the learning rate and regularization strengthfrom cs231n.classifiers.linear_classifier import LinearSVMlearning_rates = [1e-9, 1e-8, 1e-7]
regularization_strengths = [5e4, 5e5, 5e6]results = {}
best_val = -1
best_svm = None# TODO: 使用提取的特征和不同的学习率和正则化强度训练SVM分类器,并在验证集上评估其性能。
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for lr in learning_rates:for reg in regularization_strengths:svm = LinearSVM()loss_hist = svm.train(X_train_feats, y_train, learning_rate=lr, reg=reg,num_iters=1500, verbose=False)# 计算train acc和val accy_train_pred = svm.predict(X_train_feats)train_accuracy = np.mean(y_train == y_train_pred)y_val_pred = svm.predict(X_val_feats)val_accuracy = np.mean(y_val == y_val_pred)results[(lr, reg)] = (train_accuracy, val_accuracy)if val_accuracy > best_val:best_val = val_accuracybest_svm = svm# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****# Print out results.
for lr, reg in sorted(results):train_accuracy, val_accuracy = results[(lr, reg)]print('lr %e reg %e train accuracy: %f val accuracy: %f' % (lr, reg, train_accuracy, val_accuracy))print('best validation accuracy achieved during cross-validation: %f' % best_val)2层神经网络超参数搜索:
一开始我设置了很小的学习率范围和很大的正则化强度,以及训练轮数不够多(1500),val acc一直只能在0.13左右,后来我扩大了学习率的范围,减少了正则化强度,并提升了训练轮数,最后发现在学习率为0.1,正则化强度为0,训练轮数为5000的时候取得0.59 的val acc, 且这个模型在test acc也取得了0.578,说明泛化能力较好
best_net_simple = TwoLayerNet(input_dim=154, hidden_size=500, num_classes=10)stats = best_net_simple.train(X_train_feats, y_train, X_val_feats, y_val,learning_rate=0.1, reg=0,num_iters=5000,batch_size=200,learning_rate_decay=0.95,verbose=True) train_acc = (best_net_simple.predict(X_train_feats) == y_train).mean()
val_acc = (best_net_simple.predict(X_val_feats) == y_val).mean()
test_acc = (best_net_simple.predict(X_test_feats) == y_test).mean()print(f"\n最终结果:")
print(f"训练准确率: {train_acc:.4f}")
print(f"验证准确率: {val_acc:.4f}")
print(f"测试准确率: {test_acc:.4f}")![[python][flask]Flask-Principal 使用详解](http://pic.xiahunao.cn/[python][flask]Flask-Principal 使用详解)


![[Linux入门] Linux 远程访问及控制全解析:从入门到实战](http://pic.xiahunao.cn/[Linux入门] Linux 远程访问及控制全解析:从入门到实战)



之使用教程(3)配置)
——表结构介绍)









)
