目录
K最近邻(KNN) - 基于距离的模型
决策边界可视化
查看特定样本的最近邻
随机森林(RF) - 树模型
feature_importances_
SHAP值分析
可视化单棵树
多层感知器(MLP) - 神经网络
部分依赖图
LIME解释器
权重可视化
支持向量回归(SVR) - 核方法
支持向量可视化
部分依赖图
决策边界可视化(对于分类问题)
通用解释方法(适用于所有模型)
Permutation Importance
全局代理模型
Anchor解释法
可视化工具推荐
总结建议
针对不同类型的机器学习模型,我们需要使用不同的可解释性技术。以下是不同模型类型的可解释性分析方法
K最近邻(KNN) - 基于距离的模型
-
决策边界可视化
## KNN-基于距离的模型
# 1. 决策边界可视化import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.inspection import DecisionBoundaryDisplay# 加载数据
iris = load_iris()
X = iris.data[:, :2]
y = iris.target# 训练模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X, y)disp = DecisionBoundaryDisplay.from_estimator(knn, X, response_method="predict",alpha=0.5, grid_resolution=200,xlabel=iris.feature_names[0], ylabel=iris.feature_names[1],
)
disp.ax_.scatter(X[:, 0], X[:, 1], c=y, edgecolor="k")
plt.title("KNN Decision Boundaries")
plt.show()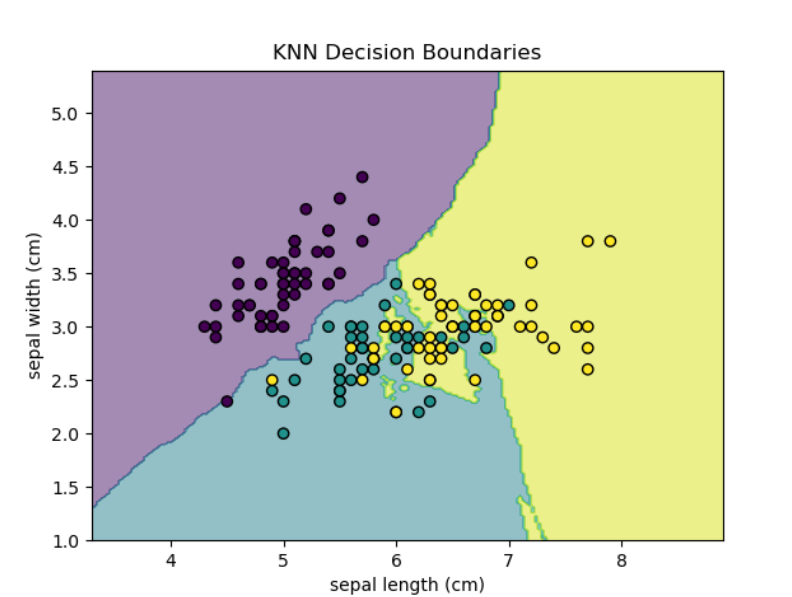
-
查看特定样本的最近邻
# 2. 查看特定样本的最近邻import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.inspection import DecisionBoundaryDisplay# 加载数据
iris = load_iris()
X = iris.data[:, :2]
y = iris.target# 训练模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X, y)sample_idx = 10
distances, indices = knn.kneighbors(X[sample_idx].reshape(1, -1))
print(f"最近邻索引: {indices}")
print(f"距离: {distances}")
# 最近邻索引: [[10 48 5 16 36]]
# 距离: [[0. 0.1 0.2 0.2 0.2236068]]# 可视化最近邻
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.3, label="All points")
plt.scatter(X[sample_idx, 0], X[sample_idx, 1], c='red', s=100, label="Query point")
plt.scatter(X[indices[0], 0], X[indices[0], 1], c='blue', s=50, label="Neighbors")
plt.legend()
plt.title(f"KNN Neighbors (k={knn.n_neighbors})")
plt.show()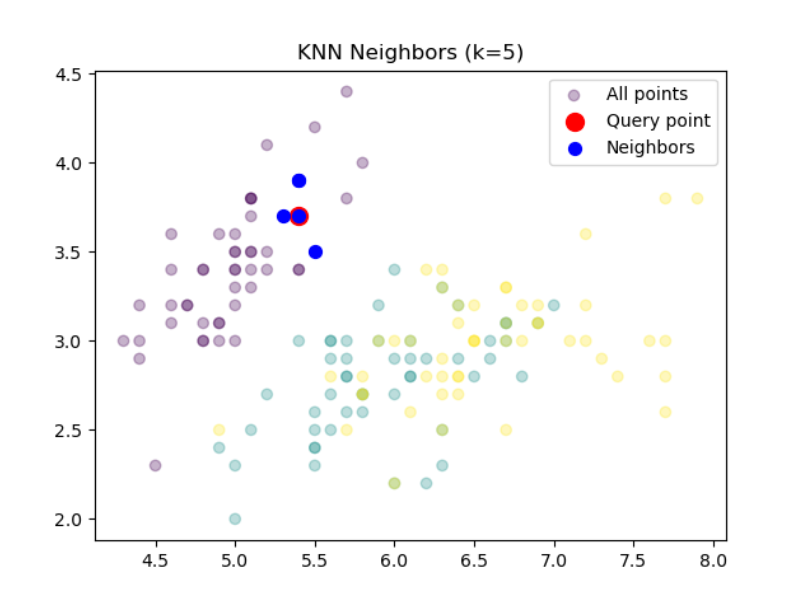 随机森林(RF) - 树模型
随机森林(RF) - 树模型
-
feature_importances_
## RF-树模型
from sklearn.ensemble import RandomForestClassifier
import shap
from sklearn.datasets import load_iris
from sklearn.tree import plot_tree
import matplotlib.pyplot as pltiris = load_iris()
X = iris.data
y = iris.target# 训练模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)# 1. 特征重要性
importances = rf.feature_importances_
plt.barh(iris.feature_names, importances)
plt.title("Random Forest Feature Importance")
plt.tight_layout()
plt.show()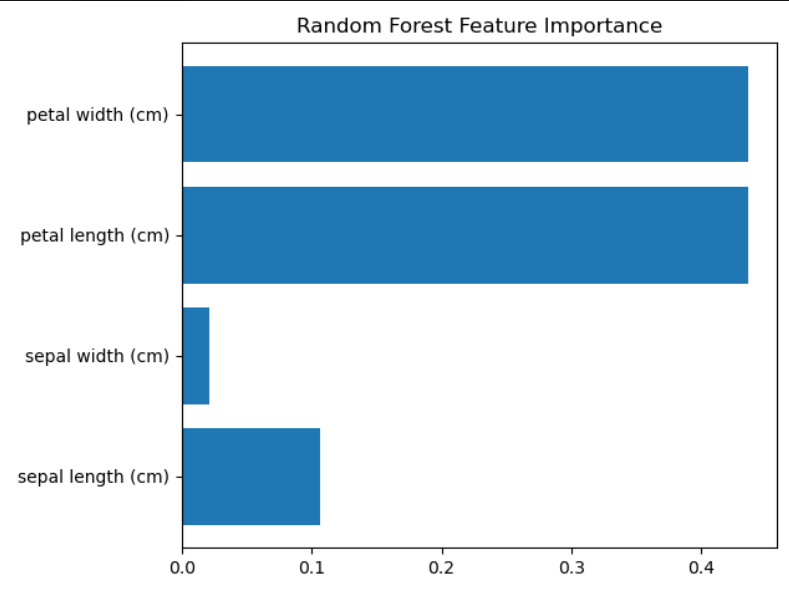
-
SHAP值分析
# 2. SHAP值分析
explainer = shap.TreeExplainer(rf)
shap_values = explainer.shap_values(X[:100]) # 计算前100个样本的SHAP值shap.summary_plot(sh


)







防暴力破解BAT脚本)







