Bert+ P-tuning
Bert+PET、Bert+P-Tuning
Chain of Thought
Few shot Cot
Auto-COT 解决手动编写高质量CoT示例麻烦耗时的问题
Auto COT 自动思维链生成器
1.业务场景: 每天收到很多反馈,之前需要人工整理,找到重点,做判断那些需要立即处理,
那些可以 慢慢处理,那些不是问题,希望生成报告
2反馈聚类:
根据这个反馈,看一看提出了哪些方面的问题
3代表性采样:
从历史的业务数据中找到每个类别,代表性问题
4.Zero shot Cot 生成分析范例:
把代表性问题丢给大模型,让他生成思考过程
添加大模型作为裁判
5. 构建最终提示:
将前面的内容拼接 成一个few shot
把拼接好的结果丢给大模型。
比较适合的业务场景:
问题多样性 要处理的问题是不是高度多样化,需要考虑不同的维度
是否需要多步复杂推理
示例构建难度 (自己手动写高质量的COT是不是很耗时间)
是不是总有扩展需求
质量需求(当前任务对结果需求是否很高)
上面几个问题,有一半以上都跟场景能对得上,就是适合的场景,如果不是,自己写COT的提示词模板
速度慢,比较浪费TOKEN
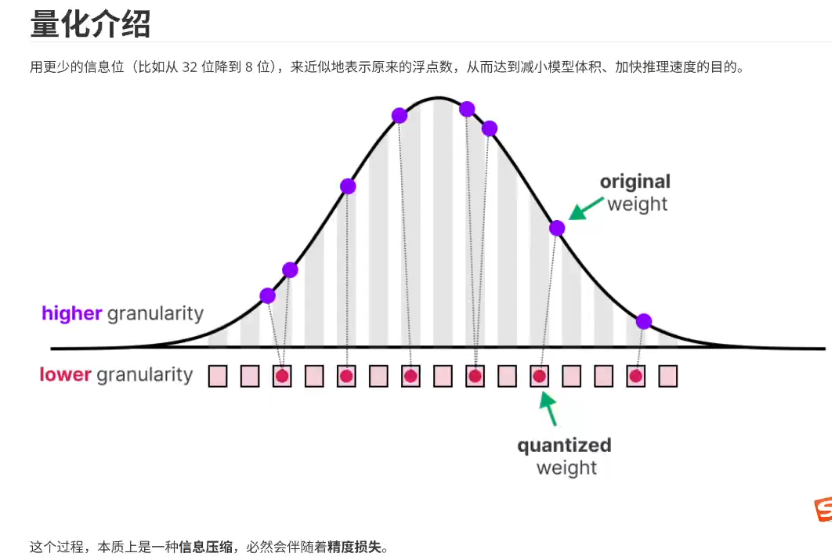
大模型的量化:
H20 8卡 96G 141G
DeepSeek R1 671B FP8训练的 1B字节对应1G 输入KV-cache
4090 24G 5090 32G 量化+offload 卸载一部分参数加载到内存中
KTransformer 存内存的方式 GPU+内存
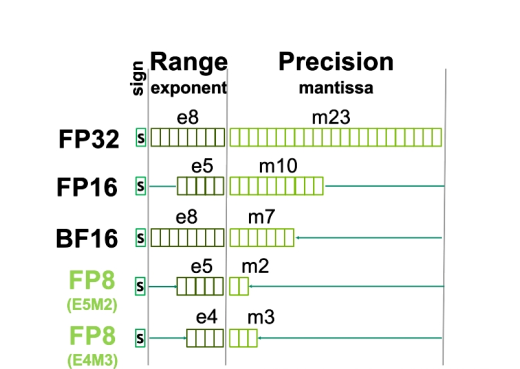
FP64
FP32
FP16、BF16
FP8 FP6 FP4
int8 int4
GGUF
qwen3 8B模型 参数装进显卡 FP8 需要多少显存

FP16, BF16 int8 在各种卡上都能跑的量化方式。
v100 相对便宜一点 32G 5000元
H20 150W
消费级显卡: 3090 4090 5090 游戏卡
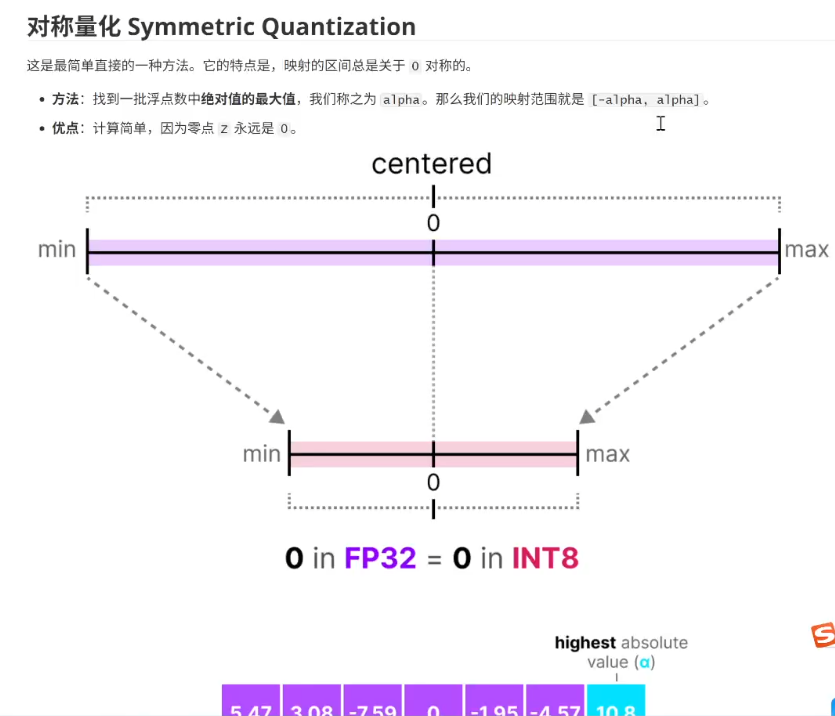
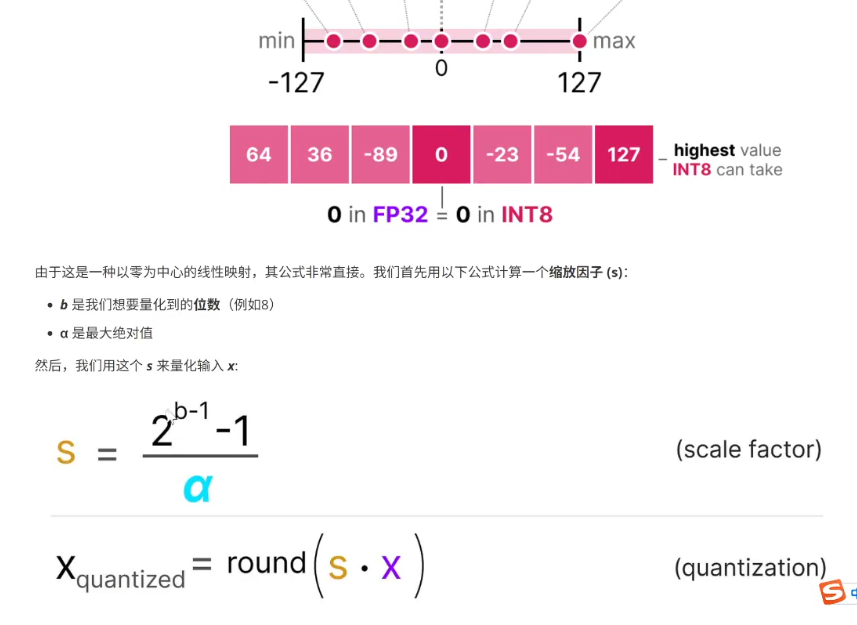
对称量化
非对称量化
范围映射与裁剪 Clipping
训练后量化 Post-Training Quantization

然后,这个激活值的分布被用来计算量化输出所需要的零点(z)和 缩放因子(s)
Dynamic Quantization 动态
Static Quantization 静态

量化计算方式:
对称量化
非对称量化
量化的时机:
训练后量化:
静态量化, 激活值通过一组校准数据集,走一遍模型,计算出数据经过每一层的 s 和 z,
把每层的s 和 z都存起来
动态量化:一边 推理一边计算
训练时量化:


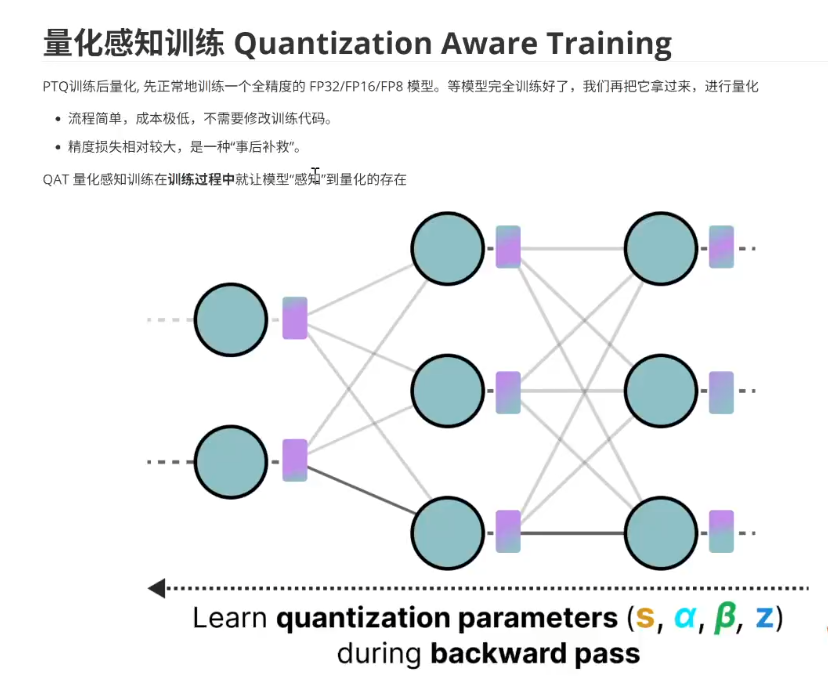
量化感知训练:
显卡:
本地化部署:
2016年 Pascal Tesla P100 Tesla P40 24G显存 几百块钱
FP32 int8
FP16/BF16 不支持
Volta 2017 V100 32G/ 16G
FP16 Tensor Core BF16不支持
int8
Turing 架构 2018 年
Tesla T4 2080Ti 22G显存(2500-3000) 11G显存
FP16 int8 int4 硬件加速
BF16不支持
Ampere 2020年
A100 80G、40G显存
L20 L40 48G显存
原生支持BF16 上限与下限比较大 对比FP16容易出现值溢出
Hopper H100 H200(国内有限制了)
FP8 好多大模型都是在FP8精度上进行训练的
H20 对中国大陆的阉割版 算力,带宽都有限制
2024 blackwell B100 B200
FP4 原生支持
云 阿里云 V100
消费机显卡 , 工业级显卡
消费级显卡: 算力带宽比同时期的工业级显卡 要小
工业级显卡: 支持nylink 带宽比较高,传输效率比较高
多卡
单机单卡:
671B FP8
多机多卡:每台机器之间网络连接
量化重点:
FP16,BF16
int8 int4
FP8 现在大多数的新的模型都是在FP8精度下训练的。
int8 int4 低于8的低比特量化主要用于推理阶段
量化的计算方式:
对称: 量化前是 0 和 量化后 还是0
非对称:
量化的时机:
训练后量化:
动态量化
静态量化
训练量化感知(训练时就考虑量化)
低比特量化:
GGUF
)










)


优化算法简介)
)

)
)
![数学建模算法-day[14]](http://pic.xiahunao.cn/数学建模算法-day[14])