书写这篇博客的目的在于实践并记录《人工智能导论》(Pyhton版)微课视频版这本书的内容,便于对人工智能有更深层次的理解。
参考文献:姜春茂.人工智能导论(Python版)微课视频版[M]. 北京:清华大学出版社,2021.

目录
2.1 Python的安装--省略
2.2 编程基础
2.2.1 数据类型与变量
1.数据类型
1)数值
2)字符串
3)布尔值
4)列表
5)转义字符
2.变量
2.2.2 字符串和编码
1.Python的字符串
1)字符串的创建
2)字符串的截取
3)字符串的拼接
4)字符串的统计
5)字符串的切割
6)查找字符串下标
1.Python的编码与转换
1)ASCII
2.2.3 列表、元组及字典
1.列表
1)创建列表
2)访问列表中的值
3)列表的切片
4)列表的相加
5)列表的扩展
6)列表的更新
7)列表的删除
2.元组
3.字典
1)创建字典
2)访问字典中的值
3)字典的修改
2.1 Python的安装--省略
2.2 编程基础
2.2.1 数据类型与变量
1.数据类型
Python一共有5种数据类型,分别是:数值、字符串、布尔值、列表和转义字符。(该书只列举了这5种类型,可能是因为面对初学者)
1)数值
只能存放一个值,定义之后不可更改,可以直接访问。
Python的数值类型又分为整型(int)、长整型(long)、浮点型(float)、复数(complex)。
整型:整数,包括正整数与负整数,也可以用十六进制、十进制、八进制表示整数。
print(10)
print(oct(10)) # Octal:八进制
print(hex(10)) # Hexadecimal:十六进制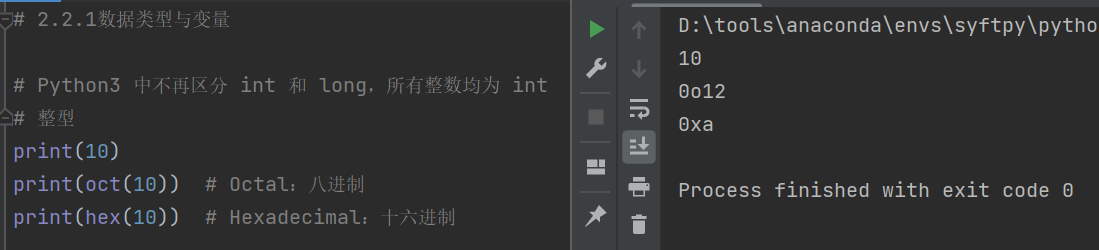
其中,八进制中的个位数表示8的0次方,也就是1;八进制中的十位数表示8的1次方也就是8。10是由1个8的1次方和2个8的0次方组成,因为其结果为0o12,其中“0o”这一前缀表示12是一个八进制的数字。
浮点型:小数,对于很大和很小的浮点数可以用科学计数法表示
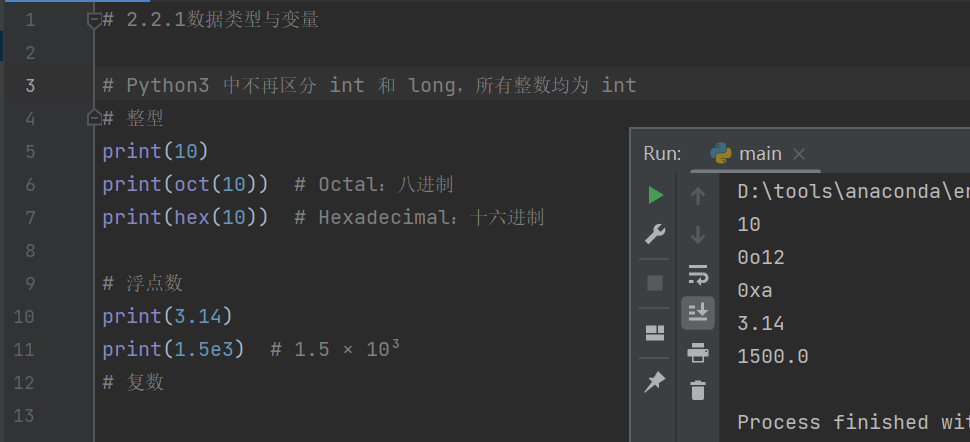
例如,1.5e3是科学计数法表示1.5×10的三次方,既是1.5e3也是1500.0(浮点保留一位小数)
复数:数学中的复数,由实数和虚数两部分组成。与数学复数不同的是:虚数部分用j表示,一般形式为x+yj,其中x是复数的实部,y是复数的虚部,x和y都是实数。
# 复数
c1 = 3 + 4j
print(c1) # 输出: (3+4j)
print(c1.real) # 输出实部: 3.0
print(c1.imag) # 输出虚部: 4.0# 复数运算
c2 = 1 - 2j
print(c1 + c2) # 输出: (4+2j)
print(c1 * c2) # 输出: (11-2j)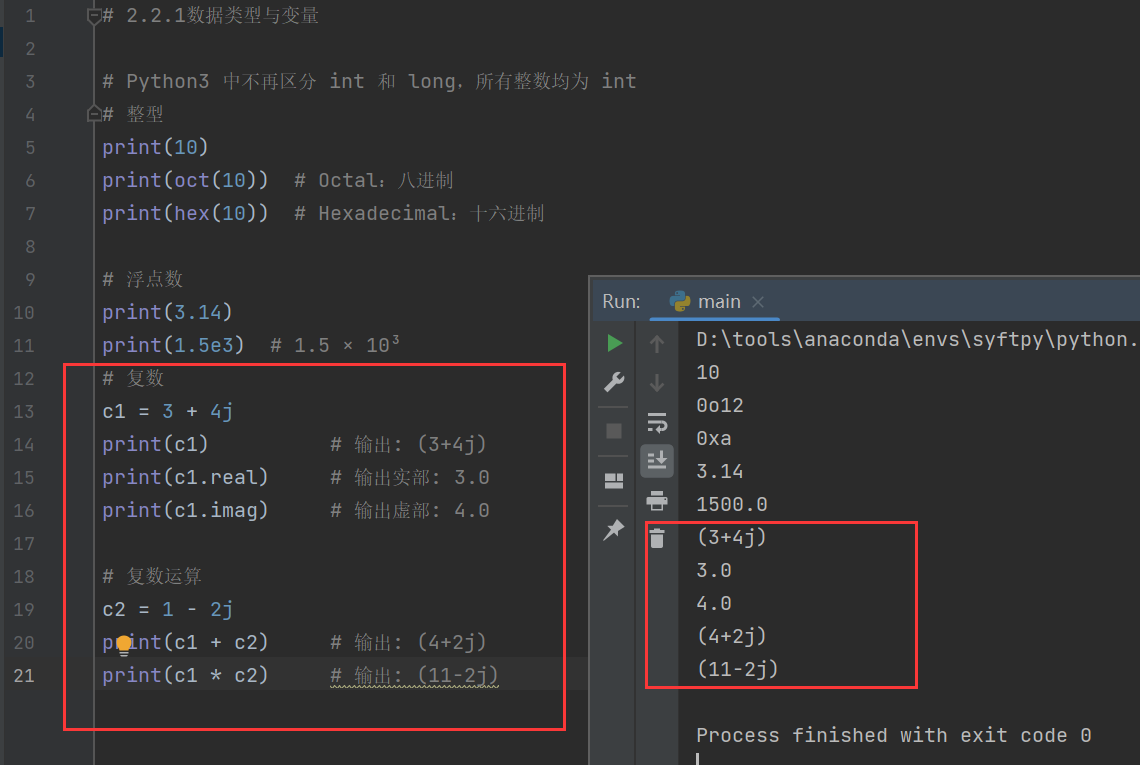
其中c1*c2的过程为:(3+4j)*(1-2j)=3*1+3*(-2j)+4j*1+4j*(-2j)=3-6j+4j-8(j*j)=8+3-2j=11-2j
备注:j*j=-1
2)字符串
一个有序的字符的集合,用于存储和表示基本的文本信息,指的是单引号或双引号括起来的文本部分。
s1 = 'Hello Python!'
s2 = '人工智能'
print(s1+s2)
print(s1[0])
print(s2[1])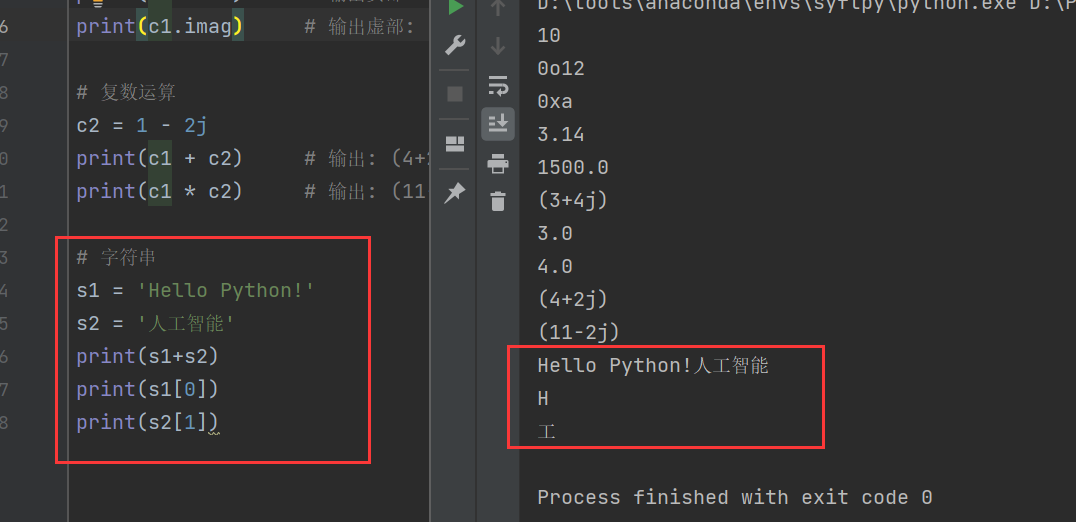
3)布尔值
布尔值只为True或False(首字母大写),也就是对或错。一些公式的计算结果也是布尔值
# 布尔值
print(True)
print(False)
print(3 > 1)
print(3 > 9)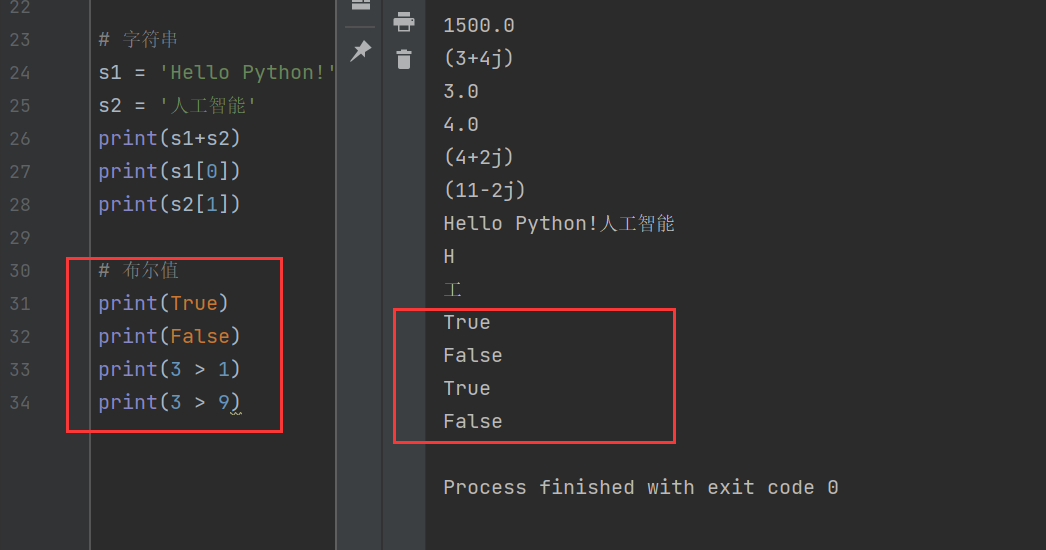
例如第34行代码中,显然3小于9,所以返回结果就是False。
同时,布尔值也可以使用与运算(and)、或运算(or)和非运算(not)进行运算,相当于逻辑运算。
print(True and True)
print(True and True and False)
print(False or True)
print(False or False)
print(not False)
print(not True)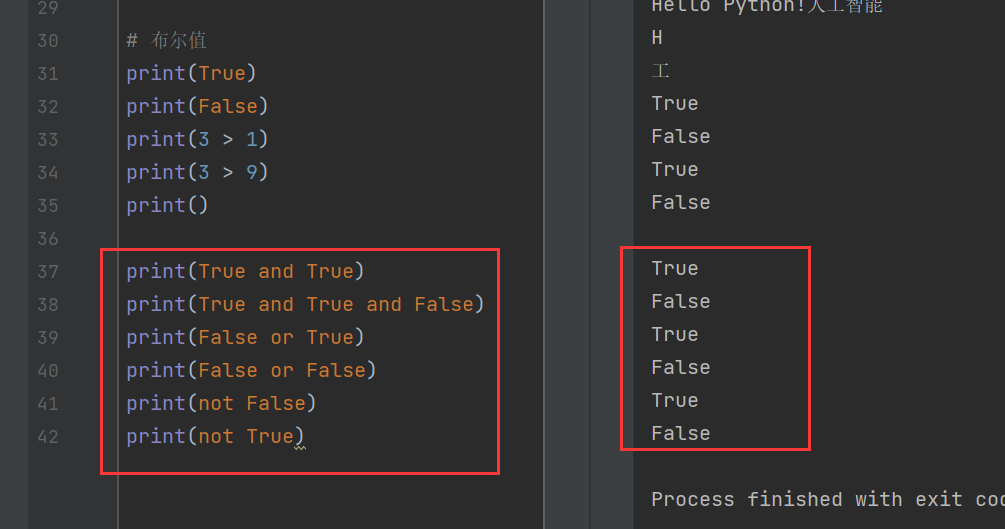
其中,and表示左右两个公式都为真时才为真。那么真 and 假(True and False)有一个为假,所以返回值为假(False);
or表示或者,也就是左右两个公式一个为真即为真。例如,假或真(False or True)只要有一个为真,其返回值就为真(True)。
4)列表
列表是Python中内置有序、可变的序列,可以存储大多数集合类的数据结构,支持字符、数字、字符串,甚至可以包括列表。用[ ]标识,所有元素均放在方括号内部。
通过下面的代码演示列表的有序性和可变性。
list = ["苹果", "香蕉", "橙子"]
print(list)
list[1] = "蓝莓"
print(list)
list.append("葡萄")
print(list)
list.remove("橙子")
print(list)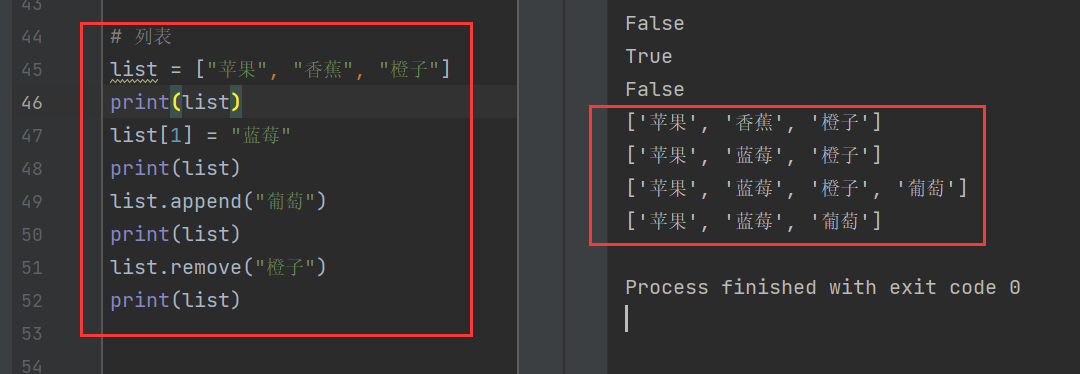
5)转义字符
转义字符是帮助机器理解一些存在歧义内容的字符。
例如,字符串s的内容为let's go!
s = 'let's go!'
在Python中会将s = 'let's go!' 标红和加粗的单引号看作一对,这显然发生了歧义,因此可以用s = 'let\'s go!' 来表示,“\”表示后面的引号只是一个普通字符。
| 转义字符 | 描述 | 转义字符 | 描述 |
| \ | 续行符 | \000 | 空 |
| \\ | 反斜杠符号 | \f | 换页 |
| \' | 单引号 | \v | 纵向制表符 |
| \" | 双引号 | \t | 横向制表符 |
| \a | 响铃 | \r | 回车 |
| \b | 退格 | \e | 转义 |
| \n | 换行 |
接下来举例说明不加转义字符和加了转义字符的代码结果:
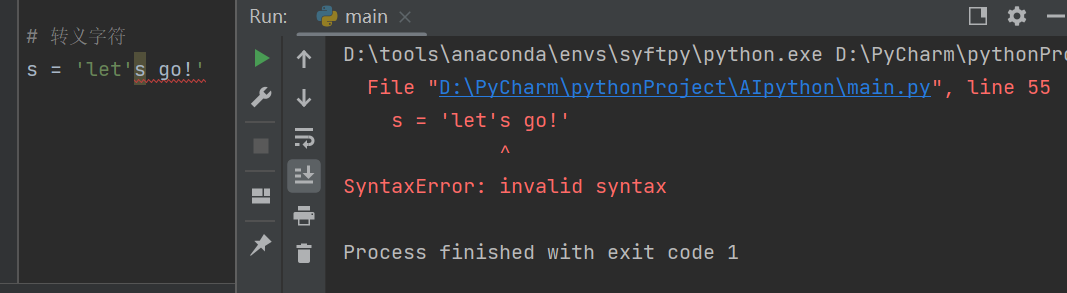
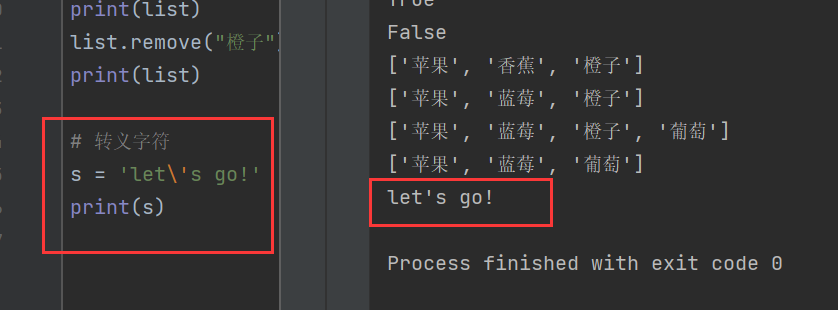
显然,不加转义字符就会出现错误。
2.变量
变量是存储在内存中的值,创建变量时会在内存中开辟一个空间。
变量不仅可以是数字,还可以是任意数据类型。
变量名必须为大小写英文字母、数字、下划线的组合,且不能由数字开头。
Python中的变量赋值不需要类型声明(这一点与c语言不一样),在变量使用前必须赋值,赋值后变量才会被创建。使用“=”给变量赋值,Python中可以同时对多个变量赋值。
变量中的赋值:
number = 125
distance = 123.4
city = "Beijing"
print(number)
print(distance)
print(city)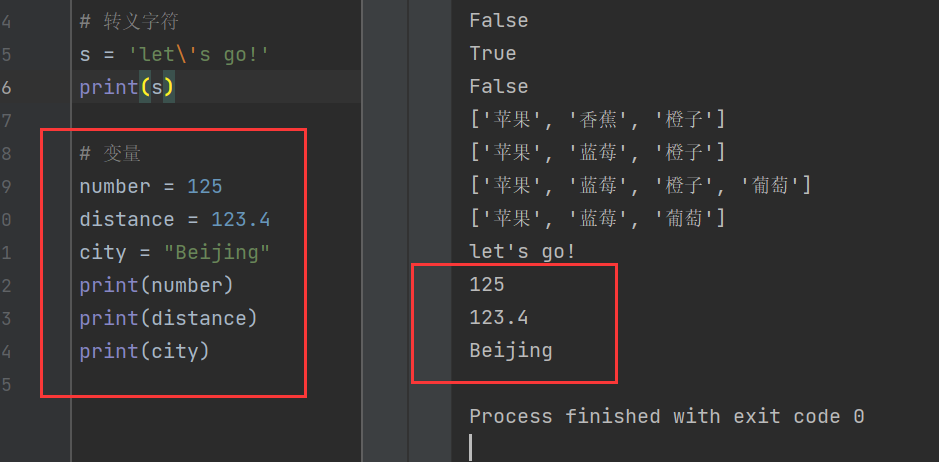
多个变量赋值:
a = b = c = 1
print(a,b,c)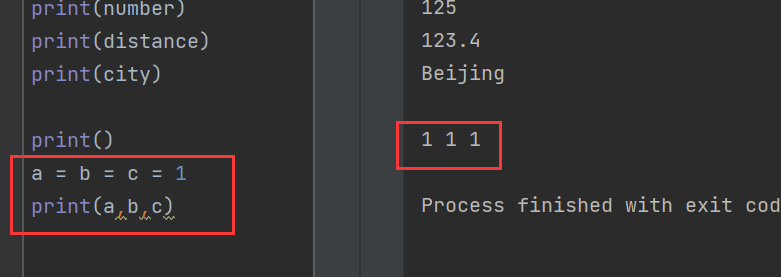
2.2.2 字符串和编码
1.Python的字符串
1)字符串的创建
在2.2.1中已经简单介绍了字符串,使用单引号(‘’)或双引号(“”)创建字符串,字符串的创建只要为变量分配一个值即可
str1 = 'Where are you from?'
str2 = "你来自哪里?"
print(str1)
print(str2)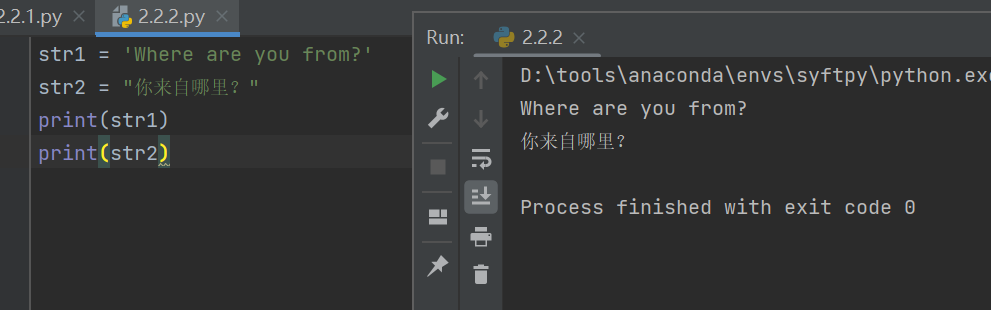
可以看到字符串是由引号所包裹而成的,那么如果存在多个引号,就需要特殊处理,其中错误例子已经在5)转义字符中提到了。
有以下两个解决方法,分别是使用不同引号和使用转义字符。
使用不同引号:
str_name1 = "I'm Joy"
print(str_name1)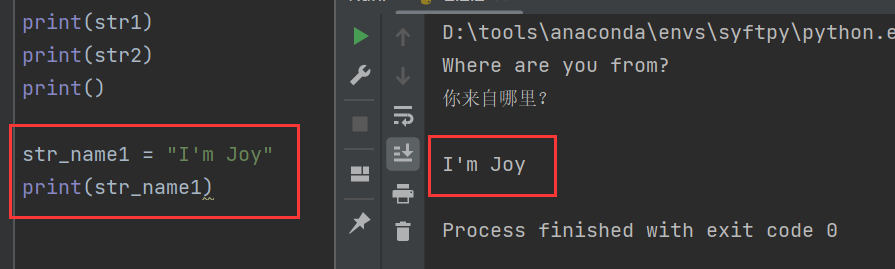
使用转义字符:
PS:这里感觉教材写错了,教材中写的是str3 = 'he said:" I\\'m Joy"'
str3 = 'he said:" I\'m Joy"'
print(str3)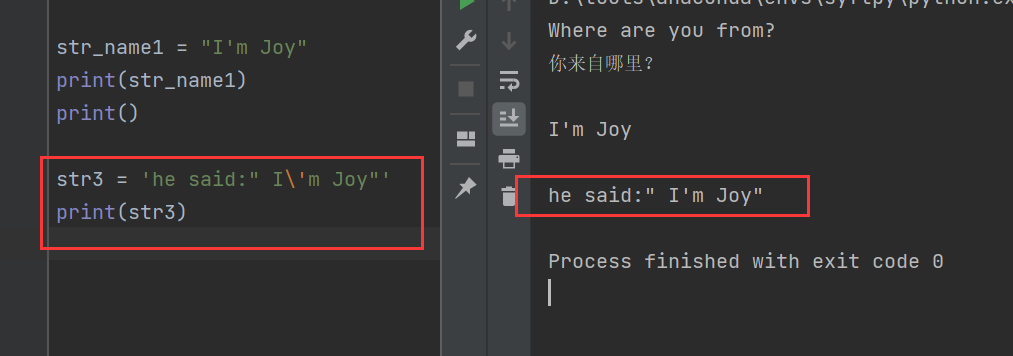
其中"\'"表示就是一个单引号,而不是创建一个字符串的意思。
2)字符串的截取
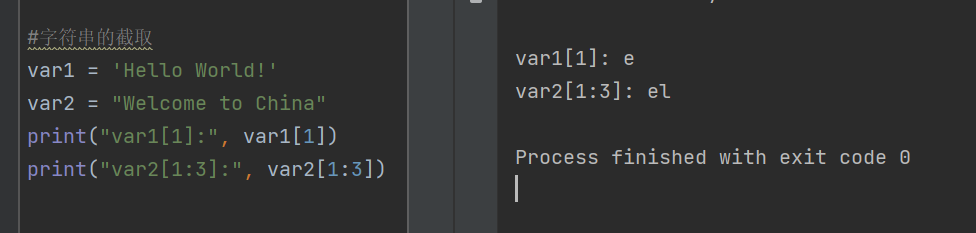
在Python中,使用方括号来截取字符串,遵循左闭右开的原则,字符串的索引值从0开始。
例如:var = "Python!",那么var[0]就是P,var[6]就是!,var[1,3]就是yt
var1 = 'Hello World!'
var2 = "Welcome to China"
print("var1[1]:", var1[1])
print("var2[1:3]:", var2[1:3])
指定元素截取方式:
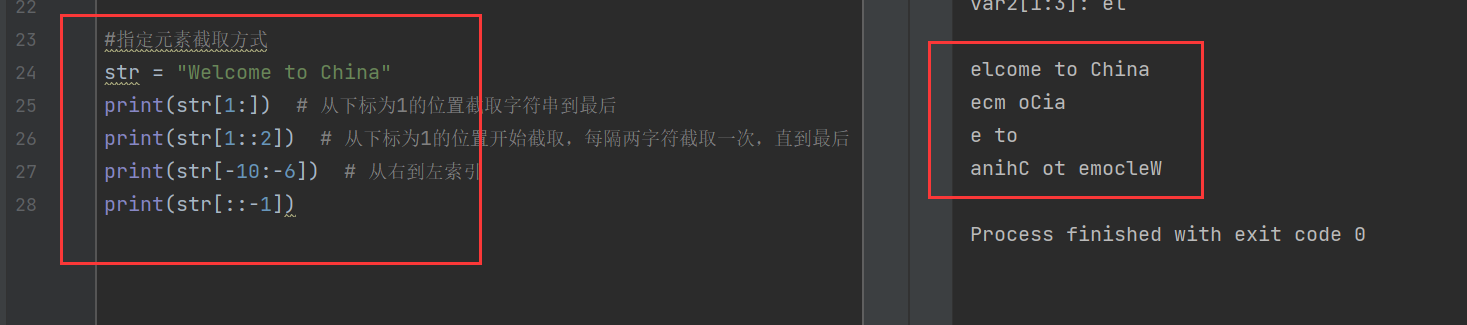
其中,str[1:]是从下标为1开始(e),一直到最后一个字符
str[1::2]是指从下标为1开始(e),每隔两个字符(算开始字符)截取一次,一直到最后一个字符
带负号的索引是指从右到左的索引,最右边的字符的索引是-1,那么-6就是“C”前面的空格,-10就是“welcome”的最后一个“e”,所以从-10到-6应该是“e to”(左闭右开,不包括str[-6])
而str[::-1]则是翻转,也就是前后置换,也就是翻转
3)字符串的拼接
字符串有3种拼接方式,分别是:乘法重叠、加法拼接和使用join拼接
join()用于连接字符串数组,将序列中的元素以指定字符连接成新的字符串
str1 = "Hello" * 3
str2 = 'Hello' + 'World'
a = 'world'
str3 = ' '.join(a)
print(str1)
print(str2)
print(str3)
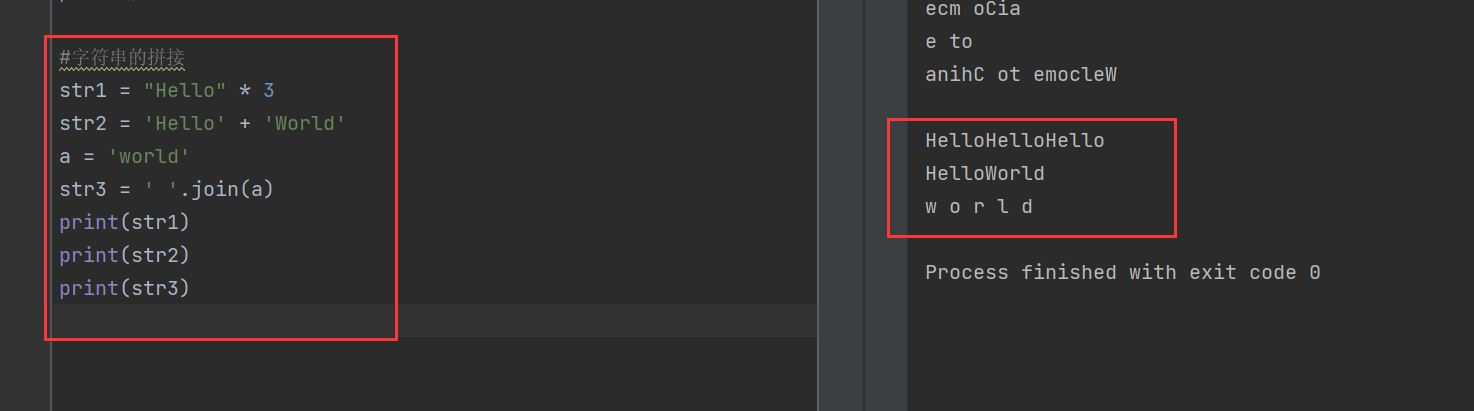
可以看到str1和str2都好理解,而str3使用了join函数,也就是让字符串a中每两个字符之间都用空格隔开
4)字符串的统计
在Python中,使用len()函数计算字符串的长度,空格也会被计算在内
str = "Hello World"
print(len(str))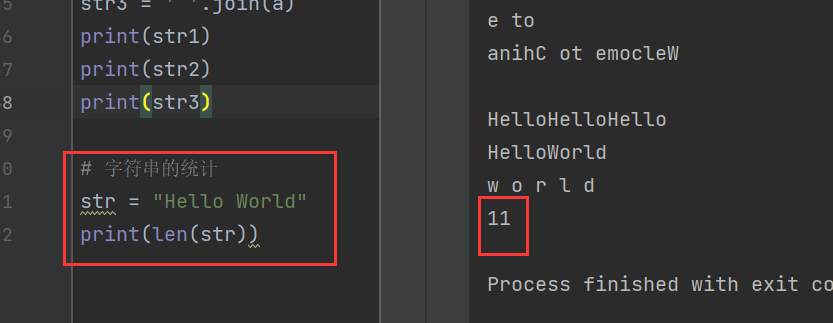
其中,Hello有5个字符,World也有5个,算上一个空格一共就是11个
5)字符串的切割
使用split()对字符串进行分割,有多种分割方式
str = "Aspring people have become a success"
print(str.split(" "))
print(str.split("e"))
print(str.split(" ", 2))
第一行是遇到空格就分割,显然字符串中有5个空格,因此会分割成6个字符串
第二行是遇到e就分割,字符串中一共有6个e,因此会分割成7个字符串
Aspring people have become a success
第三行则是遇到空格就分割,最大分割次数为2(前两行没有写分割次数的参数,因此就是无限次分割),因此会分割成3个字符串
6)查找字符串下标
使用find()函数查找字符串的下标位置,如果找不到则返回-1
find_str = "Aspiring people have become a success"
s1 = "become a success"
print(find_str.find(s1))
print(find_str.find("people"))
print(find_str.find('e', 11))
print(find_str.find('k'))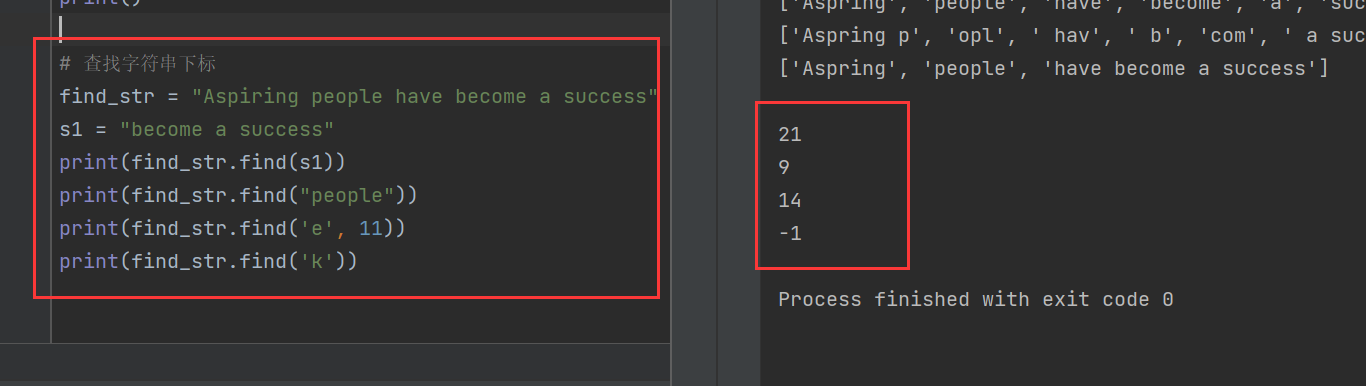
其中,Aspiring一共有7个字符,加上空格就是8个,之后就是people,因为索引从0开始计数,所以people的起始索引位置就是9,其他问题同理
第三个print不是很好理解,这里给出find()函数的说明
str.find(sub[, start[, end]])
- str:待搜索的原字符串。
- sub:必选参数,需要查找的子串。
- start/end:可选参数,限定搜索范围的起始和结束位置索引(左闭右开区间)
因此,print(find_str.find('e', 11))的意思是,从索引为11的位置开始找“e”字符,索引为11的字符是people的o,那么下一个“e”就是people的最后一个“e”,其索引为14.
1.Python的编码与转换
常见的编码方式有以下5种
| 编码 | 制定时间 | 作用 | 所占字符数 |
| ASCII | 1967年 | 表示英语及西欧语言 | 8/1B |
| GB 2312 | 1980年 | 国家简体中文字符集,兼容ASCII | 2B |
| GBK | 1995年 | GB 2312的扩展字符集,支持繁体字,兼容GB 2312 | 2B |
| Unicode | 1991年 | 国际标准组织统一标准字符集 | 2B |
| UTF-8 | 1992年 | 不定长编码 | 1~3B |
在7年计算机的求学过程中,个人认为ASCII码的应用范围更广,因此只说明ASCII。
1)ASCII
ASCII的常见规则:
- 数字比字母小,如'9'<'A';
- 数字按从大到小顺序递增,如'8'<'9'
- 字母按从A到Z的大小顺序递增,如'B'<'H'
- 同一个字母的小写字母比大写字母大,如'e'>'E'
2.2.3 列表、元组及字典
1.列表
1)创建列表
使用[]创建列表, 用逗号分割不同数据项,列表的索引从0开始
list1 = ['KangKang', 18, 'Boy', 'Music']
list2 = [8, 9, 0, 2, 3, 1]
list3 = ['a', 1, 2, 3, 'b']
print(list1)
print(list2)
print(list3)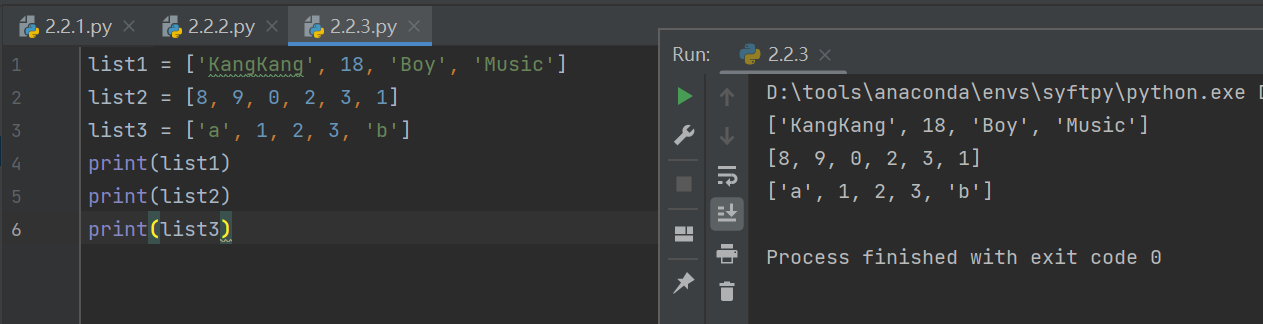
可以看到,数值类型的数据项不需要用引号,但是字符串需要
2)访问列表中的值
可以把列表看成字符串,每一个数据项就相当于字符串中的一个字符。
list1 = ['KangKang', 18, 'Boy', 'Music']
print(list1[2])
print(list1[-1])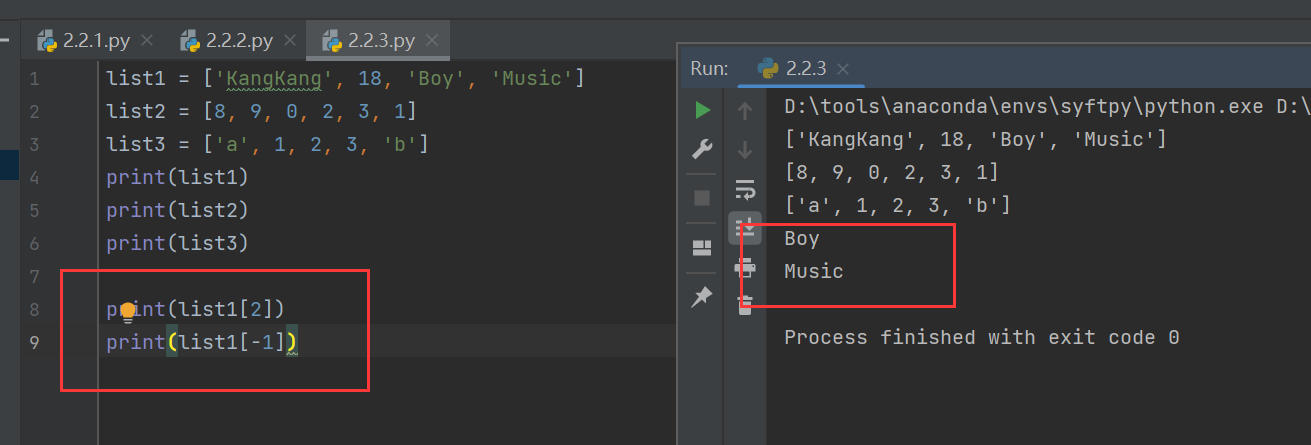 其中,-1代表从右到左的索引,因为最右边的数据项是Music,就是-1对应着Music
其中,-1代表从右到左的索引,因为最右边的数据项是Music,就是-1对应着Music
当索引超出位置时,程序就会报错,例如:

3)列表的切片
切片可以实现一次性获取多个元素,与字符串切割类似,但是列表不需要split()函数。操作规则为:[开始位置:结束位置:间隔],其中,间隔可以不写,默认为1.同样遵循左闭右开的原则
list1 = ['KangKang', 18, 'Boy', 'Music']
print(list1[:2])
print(list1[-2:])
print(list1[::2])
print(list1[:])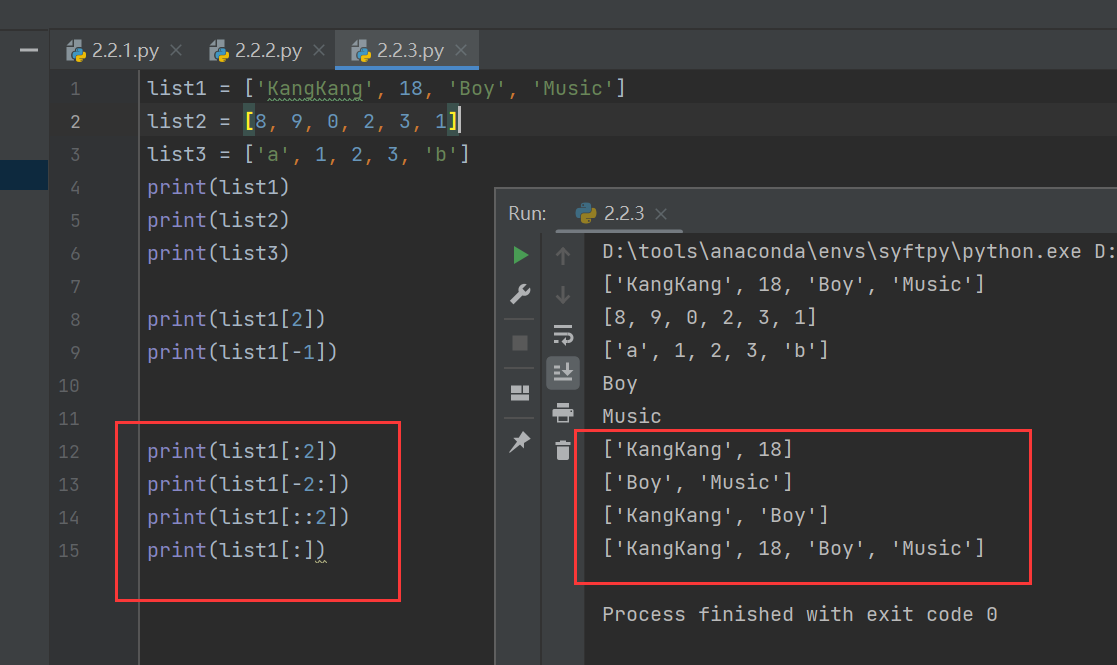
其中第12行的“2”表示结束位置,也就是只输出索引为0和1的数据项
第13行的“-2”表示从右到左的索引位置,-2代表的数据项就是‘Boy’,也就是取出最后两个元素,所以应该输出'Boy', 'Music'
第14行的“2”代表间隔,每两个数据项输出一个数据项
第15行什么参数都没有写,也就是取出全部元素
4)列表的相加
用“+”即可实现列表的相加,其中,列表的相加并没有改变原有列表的元素,两个列表仍为最开始定义的值
# 列表的相加
list1 = ['KangKang', 18, 'Boy', 'Music']
list2 = ["186cm", "70kg"]
list3 = list1 + list2
print(list1)
print(list2)
print(list3)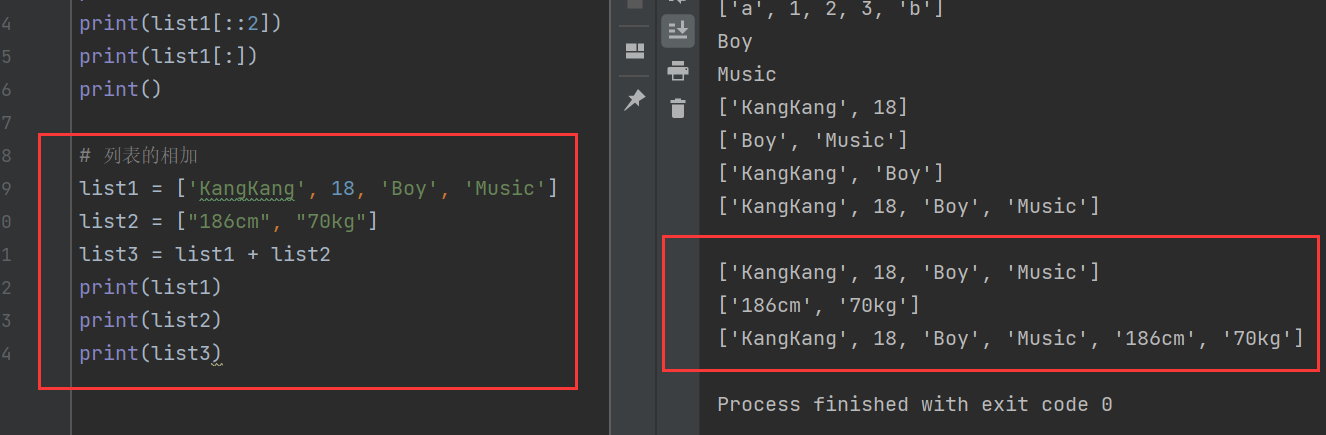
5)列表的扩展
使用extend()函数对列表进行扩展
list1 = ['KangKang', 18, 'Boy', 'Music']
list2 = ["186cm", "70kg"]
list1.extend(list2)
print(list1)
print(list2)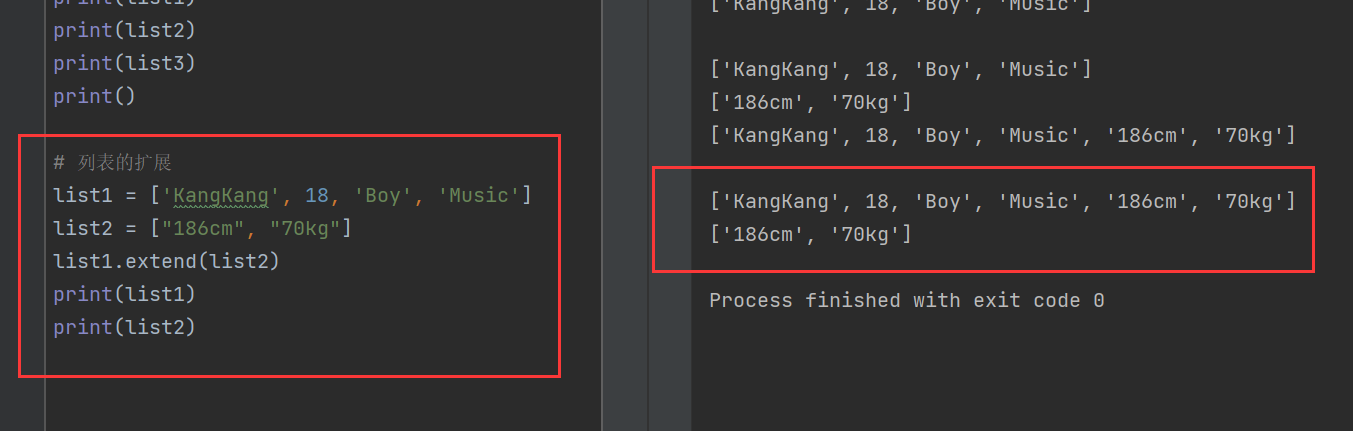 可以看到,extend()使list2的两个数据项成为了list1中的第五个和第六个数据项。
可以看到,extend()使list2的两个数据项成为了list1中的第五个和第六个数据项。
但是为什么不会让列表成为第五个数据项呢?也就是['KangKang', 18, 'Boy', 'Music', ['186cm', '70kg']]
来看看extend()函数的定义:extend() 方法用于将一个可迭代对象(如列表、元组、字符串等)中的元素逐个添加到列表的末尾。添加后,列表的长度会增加可迭代对象中元素的数量。
也就是说,会把list2中的每个数据项而非列表添加在末尾。那么,怎么将列表添加在末尾呢,那就需要append()函数。
以下是append()函数的定义:append() 方法用于在列表的末尾添加一个元素。这个元素可以是任意类型的对象,如数字、字符串、列表等。添加后,列表的长度会增加1。
也就是说,append()会把加入的内容认为是一个整体,而不是像extend()那样将元素进行分解。接下来,将append替换extend来看一下结果吧。
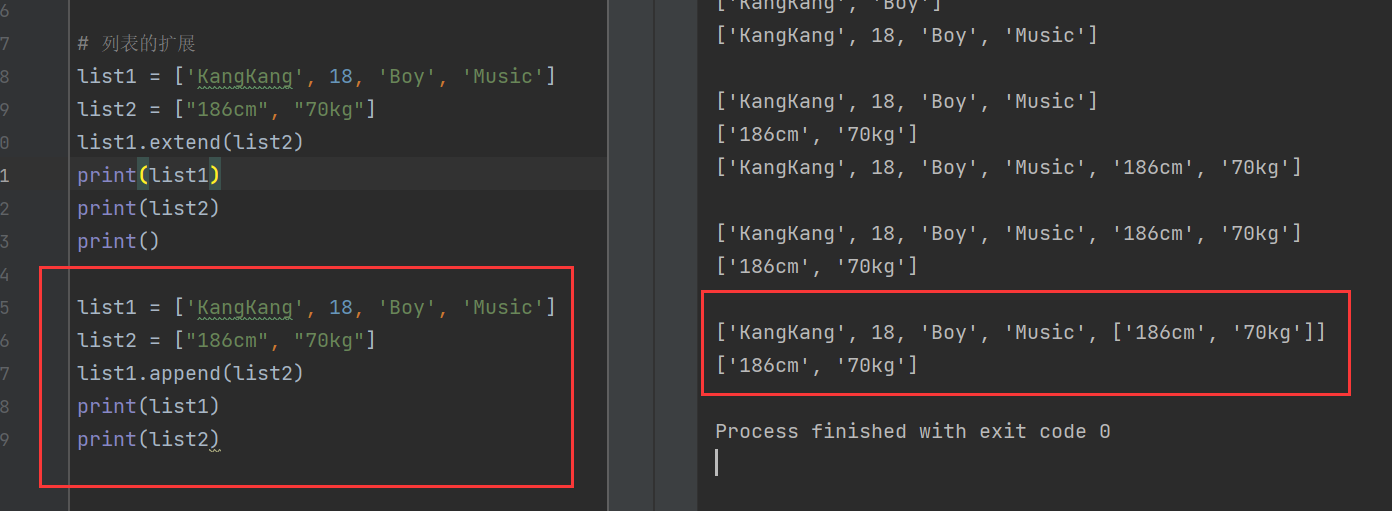
显然,append()函数直接把列表["186cm", "70kg"]加在了尾端。
6)列表的更新
如果直接修改列表中对应索引的数据项,列表中原数据项的内容就会被替换掉
list1 = ['KangKang', 18, 'Boy', 'Music']
list1[0] = "186cm"
list1[1] = "70kg"
print(list1)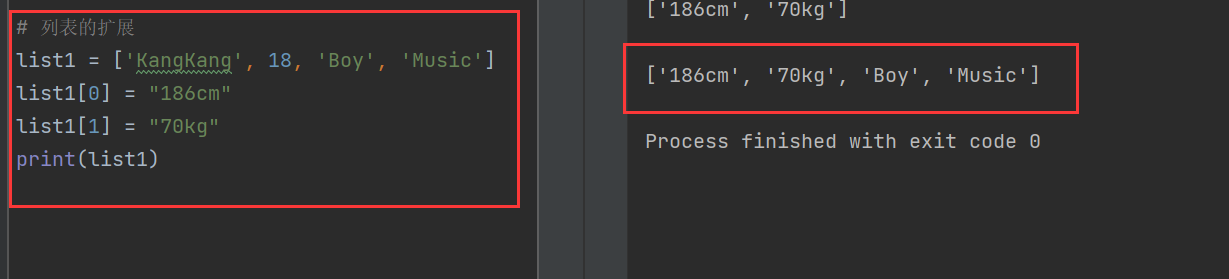
如果不想替换掉原有元素,可以用append()、insert()来添加新元素
list1 = ['KangKang', 18, 'Boy', 'Music']
list1.append("186cm")
print(list1)
list1.insert(1, "70kg")
print(list1)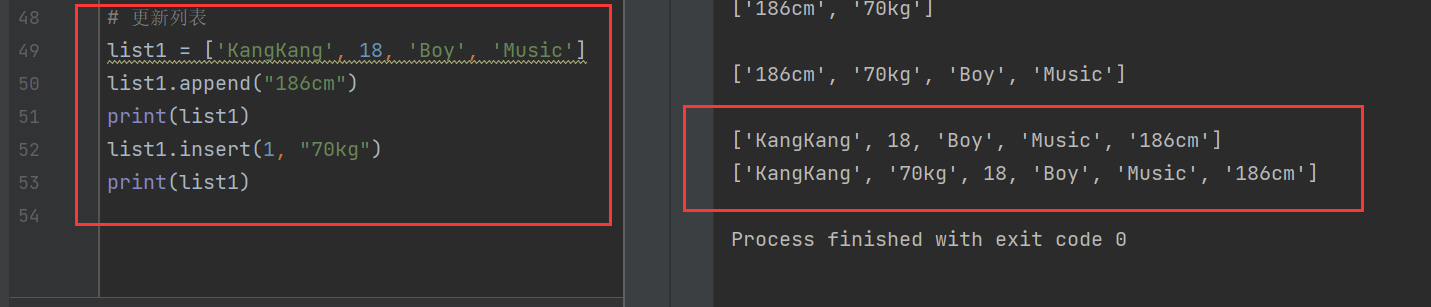
append()函数是将元素加在末尾,insert是将元素插入对应的索引位置
7)列表的删除
有四种方法可以对列表进行删除,分别是:
- 使用
pop()方法:需要删除特定索引处的元素,并且需要在删除后使用该元素的值时。 - 使用
del语句:需要删除特定索引的元素,或者完全清空列表时。 - 使用
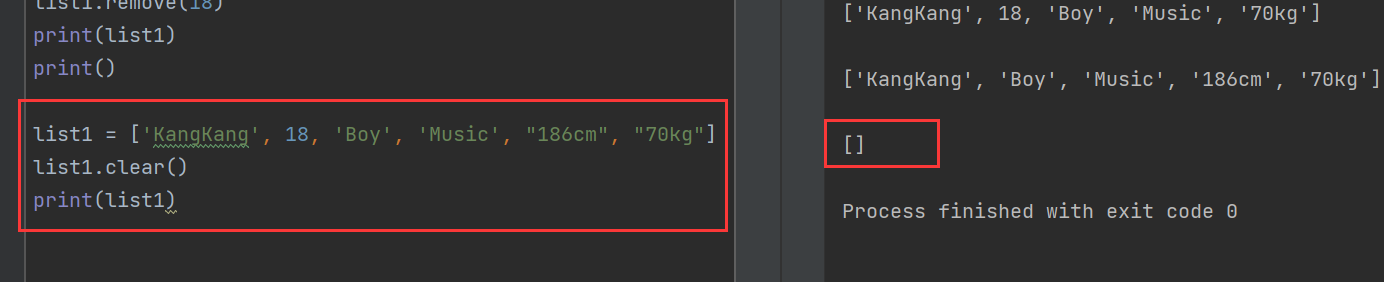
remove()方法:需要删除列表中的特定元素名称而非索引值。 - 使用clear()方法清空列表,将所有元素都删除,但是仍存在空列表
pop():
list1 = ['KangKang', 18, 'Boy', 'Music', "186cm", "70kg"]
pop_item = list1.pop(2)
print(list1)
print(pop_item)
list1.pop()
print(list1)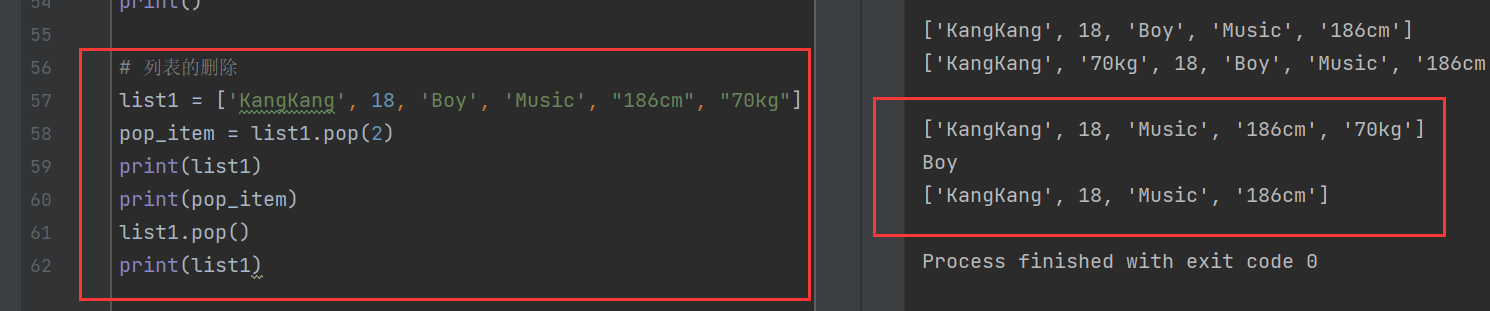
del():

remove():

clear():
2.元组
元组和列表类似,但是元组一旦初始化就不能修改,并且元组用小括号()表示,列表使用方括号[]表示
首先,先介绍一下列表、元组和字典的区别
- 列表(List):可变类型,支持增删改元素
- 元组(Tuple):不可变类型,创建后无法修改元素
- 字典(Dict):可变类型,可增删改键值对,但键必须为不可变类型
tup1 = ('KangKang', 18, 'Boy', 'Music')
print(tup1)
tup2 = ("186cm", "70kg")
print(tup2)
tup3 = tup1 + tup2
print(tup3)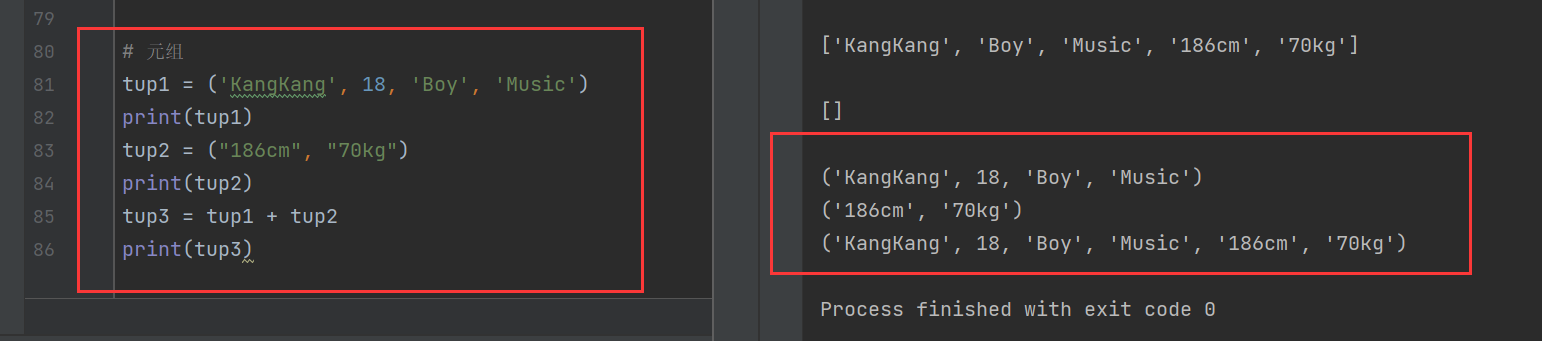
3.字典
字典包括两部分,一部分是键(key),另一部分是值(value)。其中,键是唯一的属性,如果重复了多个同样的键,最后出现的键会替换掉前边的,但是值是不唯一的。
1)创建字典
有两种创建字典的方法:1.使用花括号{};2.使用dict()函数创建,字典的键与值使用冒号:分隔开,键与键使用逗号,分隔开。
除了上述方法初始化字典,还可以用fromkeys()对字典初始化,并用第二个参数作为字典的值
dict1 = {'a':'an', 'b':'be', 'c':'can'}
dict2 = dict()
dict3 = dict(d='defind')
dict4 = dict().fromkeys(['name1', 'name2'], 'KangKang')
print(dict1)
print(dict2)
print(dict3)
print(dict4)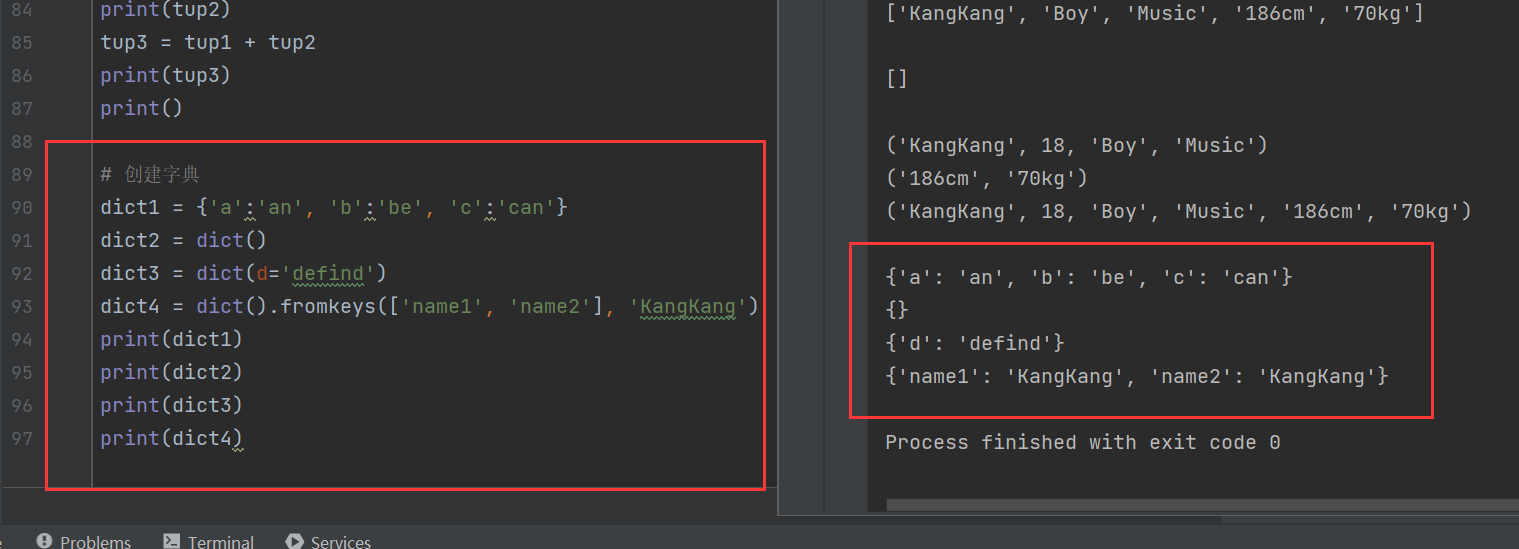
2)访问字典中的值
字典中通过键来寻找值,可以用[]和get()函数的方法来获取对应的值
在这里博主发现,材料中将年龄18也加上了单引号,但是之前的学习中数值类型的字符串可以不加引号,因此这个代码中没有加引号
dict1 = {'Name':'KangKang', 'Age':18, 'height':"186cm", 'weight':'70kg'}
print(dict1)
print(dict1['Age'])
print(dict1.get('Name'))
print(dict1.get('gender'))
3)字典的修改
可以直接通过键来修改值,也可以用update在字典尾端加入键值
dict1 = {'Name':'KangKang', 'Age':18, 'height':"186cm", 'weight':'70kg'}
dict1['Age'] = 20
print(dict1)
dict1.update({'gender': 'male', 'jobs': 'programmer'})
print(dict1)
del dict1['height']
print(dict1)
dict1.pop('Name')
print(dict1)
字典的其他使用方法如下所示:
| 方法 | 说明 | 方法 | 说明 |
| cmp(dict1, dict2) | 比较两个字典元素 | len(dict) | 计算字典元素个数,即键的总数 |
| dict.clear() | 删除字典内所有元素 | dict.copy() | 返回一个字典的浅复制 |
| dict.items() | 以列表返回可遍历的(键,值)元组数组 | dict.keys() | 以列表返回一个字典所有的键 |
| dict.values() | 以列表返回字典中的所有值 | popitem() | 随机返回并删除字典中的一对键和值 |
| dict.has_key(key) | 如果键在字典dict中则返回True,否则返回False | dict.setdefault(key,default=None) | 和get()方法类似,但如果键不存在于字典中,将会添加键并将值设为默认值 |

)






)

)








)