目录
前言
一、vector 的框架
二、基础实现
1、无参的构造:
2、析构函数
3、size
4、capacity
5、reserve扩容
6、push_back
7、迭代器
8、 operator[ ]
9、pop_back
10、insert 以及 迭代器失效问题
11、erase 以及 迭代器失效问题
12、resize
13、 拷贝构造
14、赋值运算符重载
15、initializer_list 构造
16、迭代器区间初始化
17、n个val 构造
前言
路漫漫其修远兮,吾将上下而求索;
一、vector 的框架
此处框架的实现,参考 sgi slt3.0 中vector 底层源码;
由于尚未学习空间配置器的相关知识,在模拟实现vector时暂时使用 new 进行替代(注:这种做法虽然不会产生实质性影响,但相比使用空间配置器,new在效率方面会稍逊一筹)。
namespace zjx
{template<class T>class vector{public:typedef T* iterator;private:iterator _start;iterator _finish;iterator _end_of_storage;};
}我们可以将迭代器理解为像指针一样的东西,但其本质可能并不是指针;在 vector 、string 中,用指针实现,但是也不一定其迭代器就是指针(在有些平台下不是,eg. VS库、Linux 中实现);可以利用 typeid 在VS中看一下vector 的迭代器类型,如下:
int main()
{std::vector<int> v;cout << typeid(std::vector<int>::iterator).name() << endl;return 0;
}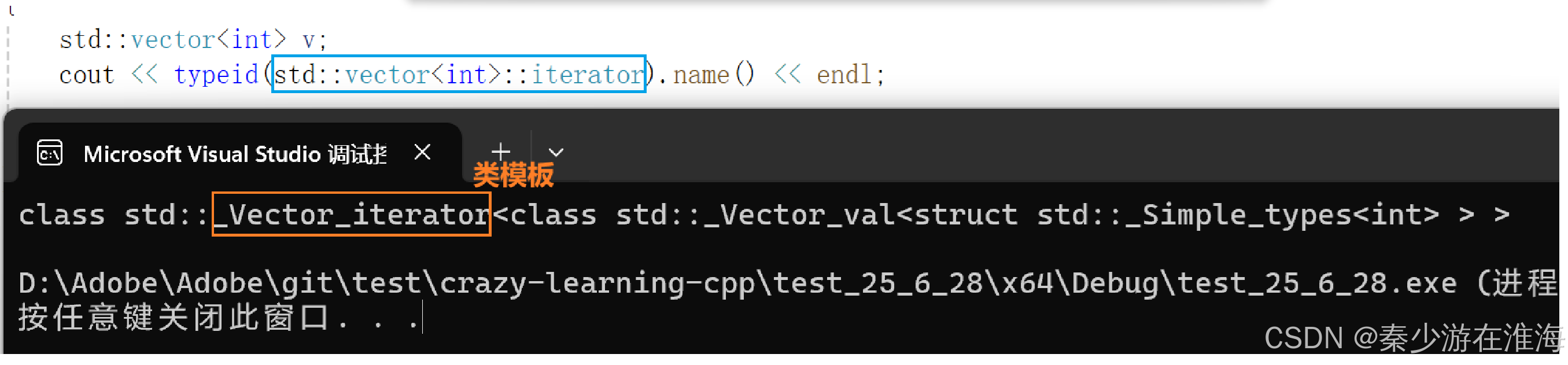
可见,在VS库中vector 的迭代器用一个自定义类型去封装了原始指针;
- 注:在typeid() 中给一个对象或者类型,可通过 typeid 看其真实类型;
还需要注意的是,const迭代器并不是指在 iterator 的基础上前面加 const ,如下:
const zjx::vector<int>::iterator it = v.begin();int* const it = v.begin();//const 修饰了指针本身这两个const表达的含义相同。无论是在原始类型前还是typedef后的类型前添加const,只要是在类型前面添加 const ,修饰的都是迭代器本身。但需要注意的是,const迭代器的作用不是防止迭代器自身被修改,而是限制其所指向内容不可被修改。因此,针对 const迭代器需要专门定义一个新的类型,如下:
typedef const T* const_iterator;修改后 vector的框架:
namespace zjx
{template<class T>class vector{public:typedef T* iterator;typedef const T* const_iterator;private:iterator _start;iterator _finish;iterator _end_of_storage;};
}二、基础实现
1、无参的构造:
vector():_start(nullptr),_finish(nullptr),_end_of_storage(nullptr){}2、析构函数
~vector(){delete[] _start;_start = _finish = _end_of_storage = nullptr;}3、size
需要加上const 来修饰this指针,保证this 指针是否被const修饰均可以调用;
size_t size()const{return _finish - _start;}4、capacity
需要加上const 来修饰this指针,保证this 指针是否被const修饰均可以调用;
size_t capacity() const{return _end_of_storage - _start;}5、reserve扩容
需要注意的是,不能直接使用realloc 进行扩容,必须用new 手动实现realloc异地扩容的逻辑;
这是因为:
- 当 T 为内置类型的时候,reserve 使用realloc 、new 都是没有问题的;即使使用realloc 开辟空间 delete[] 释放空间也是不会报错的;
- 当T 为自定义类型时,开辟的空间就需要调用该自定义类型的构造函数进行初始化(必须进行初始化,eg.T为string 时,如果不初始化,那么string里面的指针、_size、_capacity 均为随机值,没初始化就没有办法正常使用string);同样地,当T为自定义类型,释放此块的空间不能使用free ,而是应该使用 delete[] ,这是因为内置类型可能会涉及资源,需要调用析构函数否则就会造成内存泄漏;
reserve代码:
void reserve(size_t n){if (n > capacity()){T* tmp = new T[n];//开辟新空间memcpy(tmp, _start, sizeof(T) * size());//拷贝数据delete[] _start;//释放旧空间//因为size() 的是通过 _finish-_start 计算的来的_finish = tmp + size();//所以需要先更新_finish ,然后才是 _start_start = tmp;_end_of_storage = _start + n;}}上述代码在处理变量 _start 和 _finish 的时候,必须先处理 _finish ,因为_finish = tmp + size(); 而 size() 通过 _finish - _start 计算得来的;如果先处理 _start 就会影响 size() 的计算;还有一种处理方式,提前通过变量保存扩容之前size() 的值,这样在处理变量的时候就不用顾及处理的先后顺序,更推荐使用这种方式;
reserve 参考代码:
void reserve(size_t n){if (n > capacity()){size_t oldSize = size();T* tmp = new T[n];memcpy(tmp, _start, sizeof(T) * oldSize);delete[] _start;_start = tmp;_finish = _start + oldSize;_end_of_storage = _start + n;}}实际上,此处实现的reserve 还存在一些小 bug , 如果想要快速了解,请跳转到 下文 "14、赋值运算符重载";
6、push_back

和 string 一样,vector 也没有提供push_front、pop_front ;因为对于vector 这种数组结构而言,头插、头删需要挪动数据,其效率很低 , 提供头插、头删没有意义并且完全可以使用insert 、erase 来间接实现头插、头删,所以没有单独实现的必要;
push_back 的参考代码:
void push_back(const T& x){//判断是否需要扩容if (size() + 1 > capacity()){reserve(capacity() == 0 ? 4 : 2 * capacity());}*_finish = x;++_finish;}7、迭代器
Q: 为什么会有迭代器这样的用法?
- 1、下标 + [ ] 这种访问形式不能适用于所有容器;eg.list
- 2、迭代器是STL的六大组件之一;
借助迭代器可以实现算符与容器之间的解耦,用迭代器访问数据的方式在各个容器之中均是相通的;
7.1 begin

iterator begin(){return _start;}const_iterator begin() const{return _start;//权限的缩小}
7.2 end

iterator end(){return _finish;}const_iterator end()const{return _finish;//权限的缩小}8、 operator[ ]
运算符重载的意义:可以通过运算符重载来控制整个运算符的行为;
普通版本的operator[ ]:
T& operator[](size_t i){assert(i < size());return _start[i];}const 版本的operator[ ]:
const T& operator[](size_t i) const{assert(i < size());return _start[i];}9、pop_back
删除尾部的数据不能直接将尾部的空间直接释放掉,在C++中,开辟的空间不能局部释放,只能整体释放;所以pop_back 的实现: --_finish;
void pop_back(){assert(_finish > _start);//确保有数据可以删除--_finish;}10、insert 以及 迭代器失效问题

vector 的insert 并不像 string 中的insert 那样提供下标就可以插入,在vector 中使用insert 需要传迭代器;
insert 实现的思路:1、首先确保pos 合法; 2、判断空间是否足够,是否需要扩容; 3、挪动数据;4、插入数据; 5、维护成员变量;
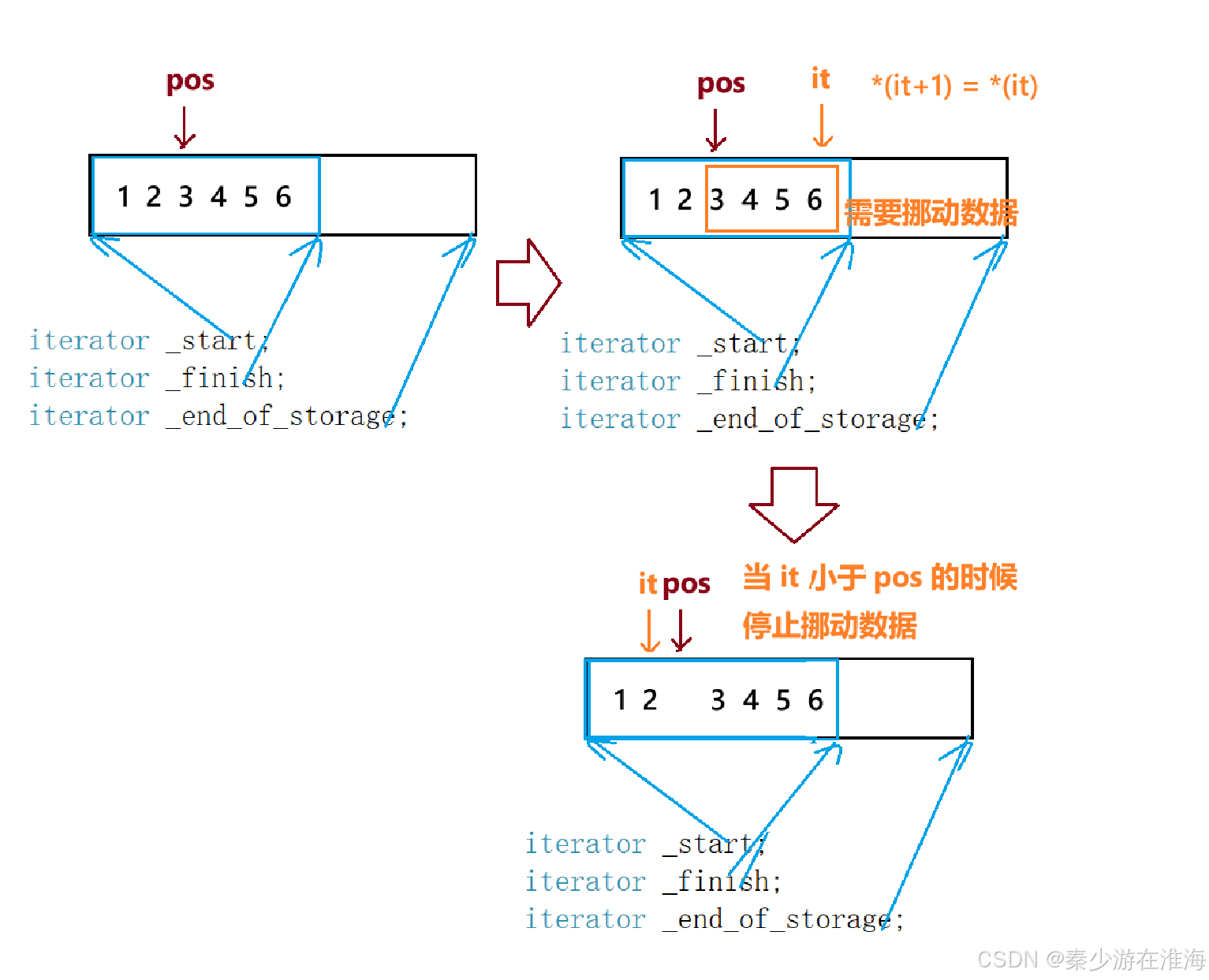
insert 代码:
void insert(iterator pos, const T& x){assert(pos >= _start);assert(pos <= _finish);//判断是否需要扩容if (_finish + 1 > _end_of_storage){reserve(capacity() == 0 ? 4 : 2 * capacity());}//挪动数据iterator it = _finish -1 ;while (it >= pos){*(it + 1) = *it;--it;}*pos = x;//放入数据++_finish;//维护成员变量}测试一下:
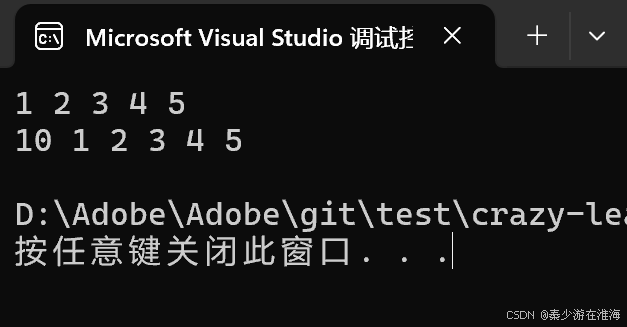
void test3()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;v.insert(v.begin(), 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}
在实现string 的insert的时候,此处的形参pos 不是迭代器而是下标,其类型为size_t ;当pos 为0 的时候,即头插,如果指针end 等于 _size,那么只有当end<0 循环才能停止;而问题就是因为end 的类型为 size_t ,不会小于0而导致了死循环,即便将end 的类型改为 int , 由于pos 的类型为size_t ,在计算的时候发成隐式类型转换同样也会导致死循环;于是乎就有一种十分难受的解决方法:while(end >= (int) pos) .... 而在vector 之中,使用迭代器就没有像在string 中出现的问题,因为迭代器有可能是自定义类型(eg. list) 也有可能是指针,但不可能会有空指针的;
实际上此处还有一个坑:迭代器失效;
第一层的迭代器失效:
Q:什么是迭代器失效?
上述的测试没有出错,但是只需要稍微更改一下:
void test3()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);//v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;v.insert(v.begin(), 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}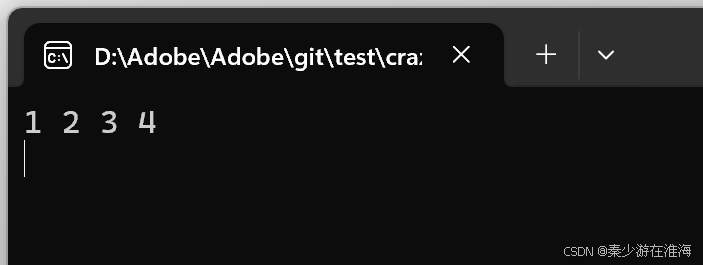
在这个例子之中,insert 第5个数据的时候挂掉了;
Q:为什么在insert 第5个数据的时候程序崩溃了?
- 在第插入第5个数据的时候进行了扩容;
调试看一下:
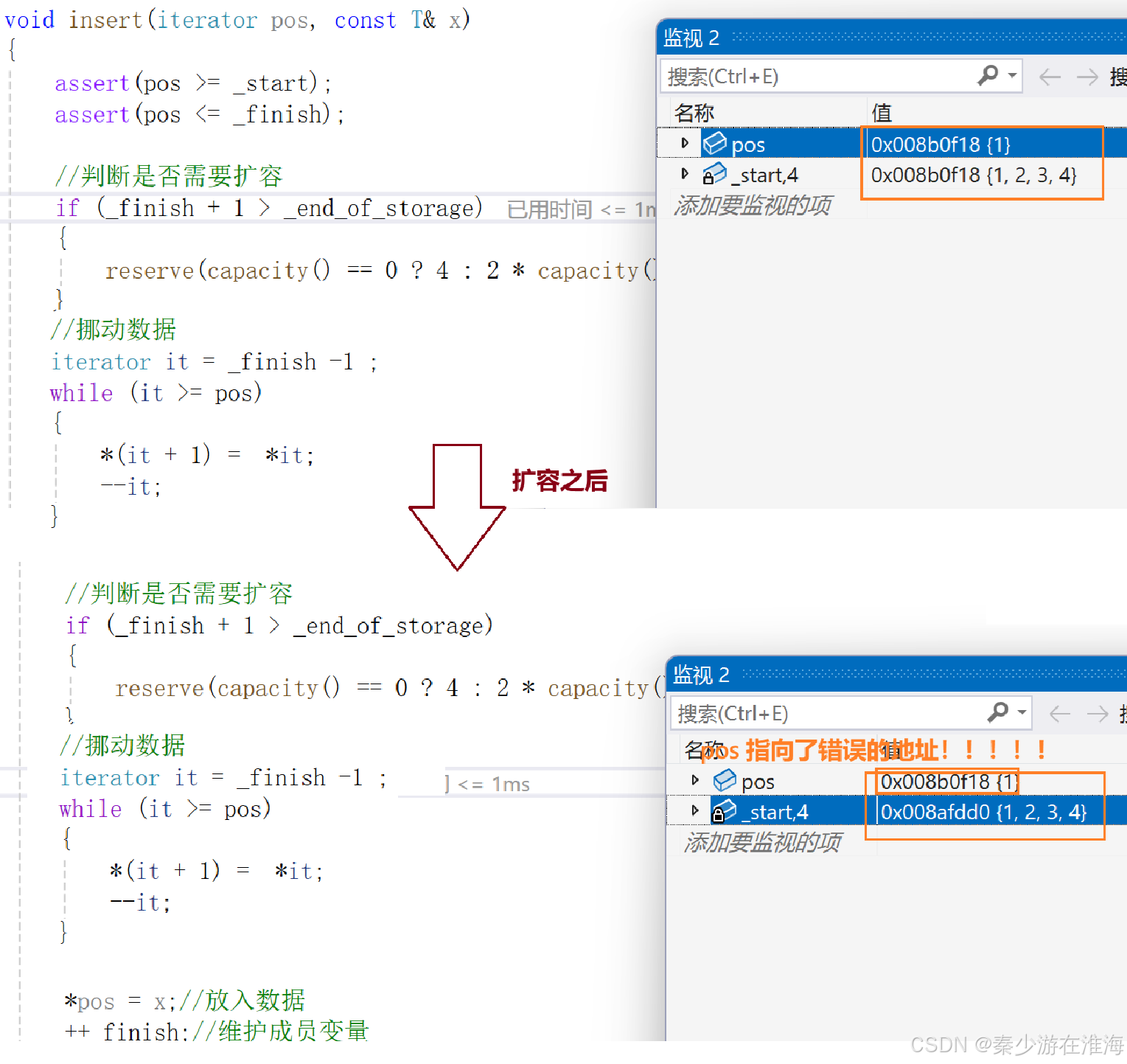
扩容导致pos指向的地址错误;
因为reserve 中实现的扩容逻辑是异地扩容,将旧空间中的数据拷贝放入新空间中,然后释放旧空间,故而 导致 pos 指向的空间不属于当前数组的空间,pos 变为了野指针;
经典的迭代器失效问题:因为扩容而导致的迭代器失效;
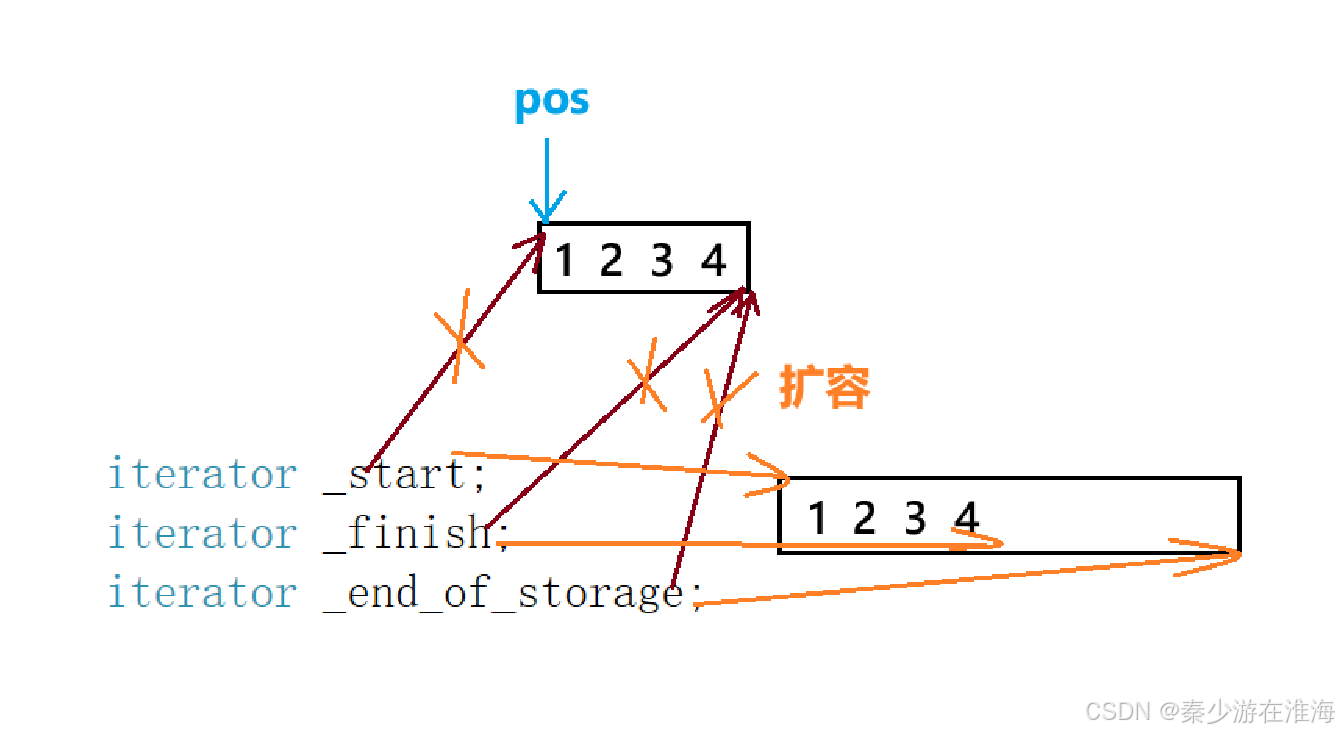
为了解决这个问题,在扩容之后应该更新pos ,那么就需要在扩容之前记录所要插入位置的下标:
insert 修改代码如下:
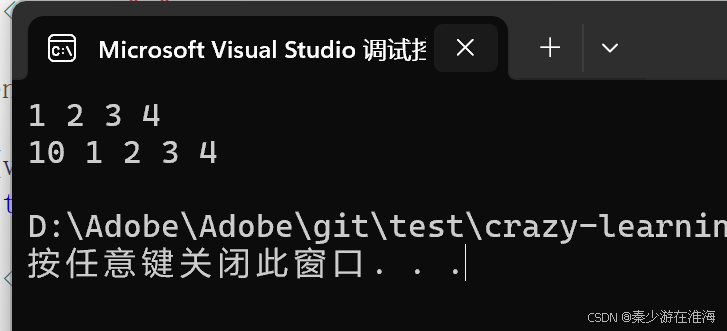
void insert(iterator pos, const T& x){assert(pos >= _start);assert(pos <= _finish);//判断是否需要扩容if (_finish + 1 > _end_of_storage){size_t len = pos - _start;reserve(capacity() == 0 ? 4 : 2 * capacity());pos = _start + len;//扩容之后更新pos}//挪动数据iterator it = _finish - 1;while (it >= pos){*(it + 1) = *it;--it;}*pos = x;//放入数据++_finish;//维护成员变量}此时再测试一下:
void test3()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);//v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;v.insert(v.begin(), 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}
11、erase 以及 迭代器失效问题
erase 的实现逻辑:1、判断pos 是否合法;2、空间中有数据可以删;3、挪动数据;4、维护成员变量
erase代码:
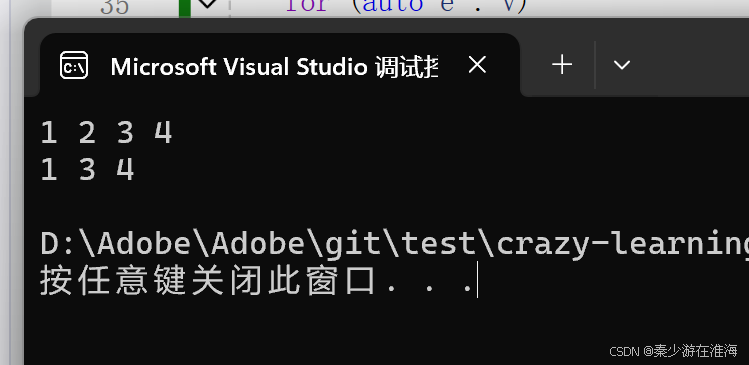
void erase(iterator pos){assert(pos >= _start && pos < _finish);assert(_finish >= _start);//挪动数据iterator it = pos + 1;while (it < _finish){*(it - 1) = *it;++it;}--_finish;//维护成员变量}测试一下:
void test2()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);for (const auto& e : v){cout << e << " ";}cout << endl;//删除v.erase(v.begin() + 1);for (const auto& e : v){cout << e << " ";}cout << endl;
}
第二层迭代器失效:
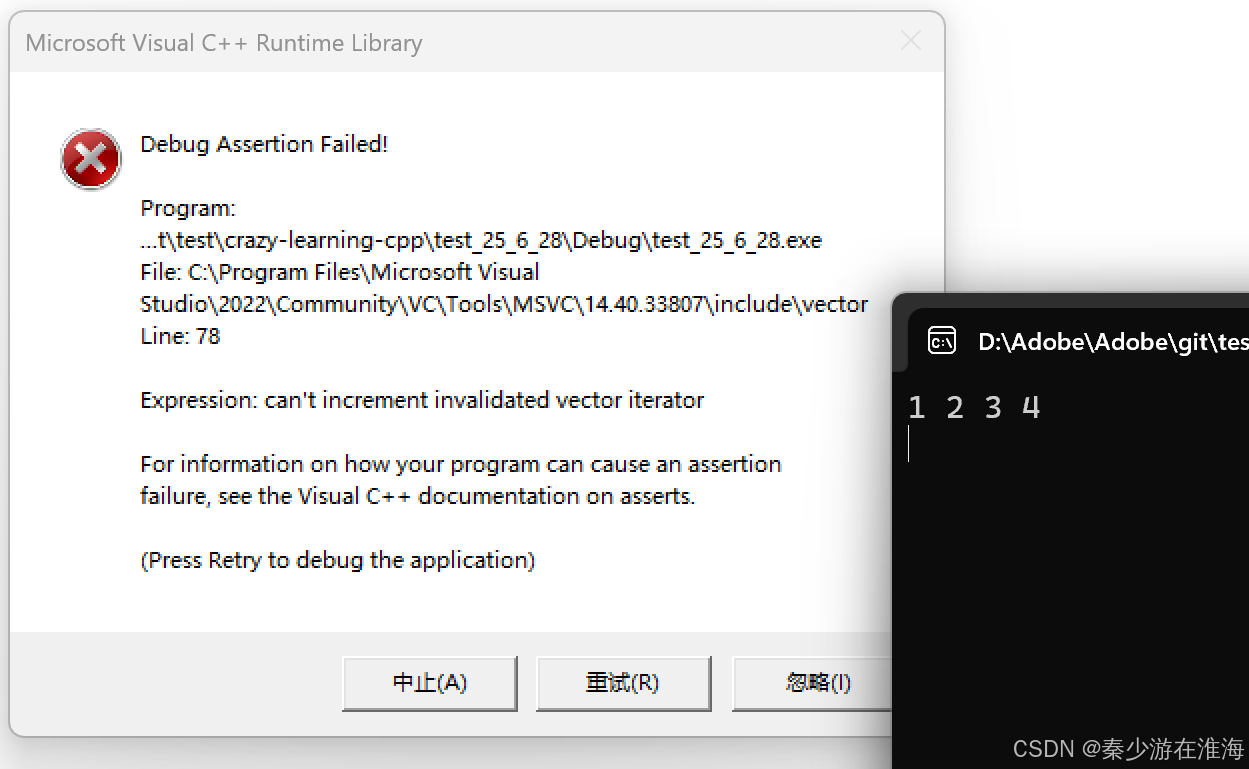
我们先利用库中的vetcor 来演示迭代器失效,eg.有一堆数据,要求将这些数据中所有的偶数均删除掉:
void test5()
{std::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;//删除所有的偶数auto it = v.begin();while (it != v.end()){if (*it % 2 == 0){v.erase(it);}++it;}for (const auto& e : v){cout << e << " ";}cout << endl;
}
在Linux 下运行呢?

在Linux 中运行没有出现迭代器失效的问题,这是由于在不同的平台中实现的方式不同;
也正是由于不同的平台底层的实现上存在差异的,我们在写代码的时候并不能依靠这些差异,倘若依赖了这些差异就会导致写出来的代码不具有跨平台性;
Q:为什么这两个平台中出现了这么大的差异呢?
代码逻辑:
之所以在VS中会报错,因为VS中有严格的检查机制;而在Linux 中没有;
并没有判断 '3' 这个数据就去判断 “4‘ ,也就意味着如果该数组中全为偶数,即使在Linux 下能跑,但是不能删除所有的偶数:

Q:如果最后一个数据为偶数呢?

在Linux中如果最后一个数据为偶数,会发生越界访问;Linux 中的段错误就是越界访问;
显然,通过上述分析,我们在删除偶数的时候,it 指向的数据是偶数,删除之后 it 就不要再向前走;如果不是偶数, 则++it; 修改如下:
//删除所有的偶数auto it = v.begin();while (it != v.end()){//分情况讨论if (*it % 2 == 0){v.erase(it);}else{++it;}}
在Linux 中测试一下:

成功完成了任务!
在VS中呢?
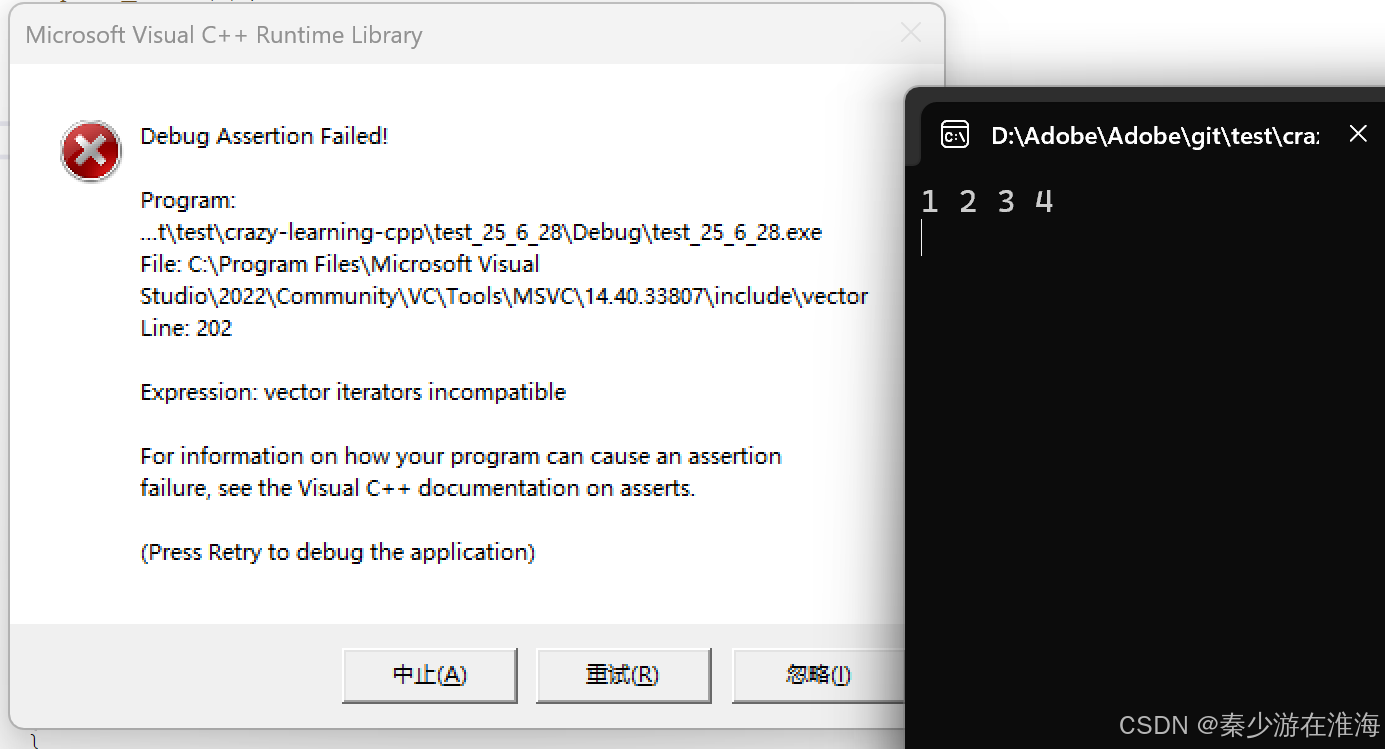
程序还是崩溃的;这是因为在VS中对迭代器的检查非常严酷;
在VS中,insert、erase 之后,均认为其迭代器失效了;而在Linux 中,可以认为erase 之前的迭代器在erase 之后不会失效;
VS并不是单纯地使用了一个指针,而是用了一个复杂的类型(自定义类型)进行封装实现的,在该类中进行了标记,当erase、insert之后,便会认为该迭代器失效,将其标记更改;强制你不能使用该迭代器;
所以erase 之后,不同的平台实现存在差异,但是统一认为 , erase 之前的指针it 在erase 之后失效了:
- 1、erase(it); 在g++ 下没有问题,但是在vs 中有问题;
- 2、erase 还存在潜在的问题;
除了g++ 和 vs 这两个较为常见的C++的两个编译器的平台可能还有其他平台;例如:在军工中的项目,他们使用的编译器是他们自己经过改造过的编译器,也得认为erase 是失效的;并不知道我们所写的代码未来会在哪种平台上跑,而又要保证每个平台上运行都没有问题,就得统一认为erase 前的迭代器在erase 之后就失效了;在有些平台下不排除erase 还有一种实现:缩容;一般的erase 只挪动数据,但缩容的erase 并不会直接释放空间,因为内存申请释放的机制:整个申请整个释放,所以erase 缩容就需要另外开辟一个更小的空间,将旧空间中删除过后的数据放入新空间中,然后释放旧空间,所以erase 也不排除会有野指针的问题,只是我们当前看到的两个主流平的erase 并未进行缩容;
Q:那我们此时该如何修改?

- 在库函数中erase 的返回值为iterator ;

erase返回 刚刚被删除的最后一个数据的下一个位置;
所以erase 的修改如下:
iterator erase(iterator pos){assert(pos >= _start && pos < _finish);assert(_finish >= _start);//挪动数据iterator it = pos + 1;while (it < _finish){*(it - 1) = *it;++it;}--_finish;//维护成员变量return pos;}这样实现的erase ,无论哪个平台怎样实现erase ,均可以更新迭代器以避免迭代器失效的问题;
删除逻辑的代码修改如下:
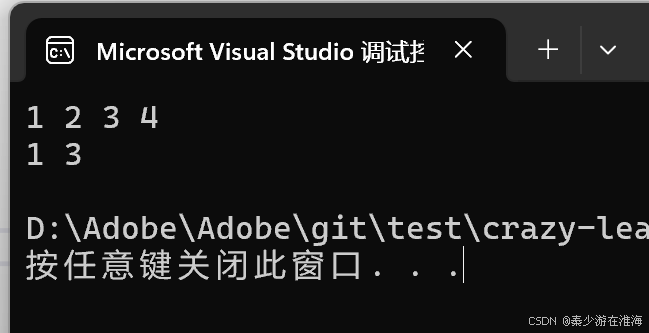
//删除所有的偶数auto it = v.begin();while (it != v.end()){if (*it % 2 == 0){it = v.erase(it);}else{++it;}}再次测试:
在VS下:
在Linux 下:

将erase 修改之后,两个平台均可以跑;
Q:是否还存在其他迭代器失效的情况?
void test4()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);//v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;int i = 0;cin >> i;auto it = v.begin() + i;v.insert(it, 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}
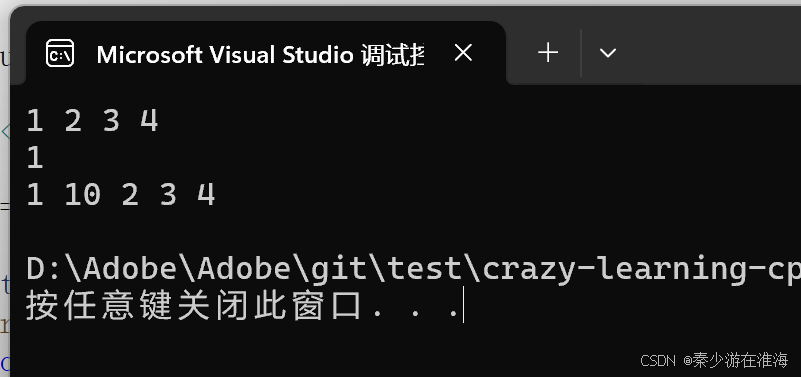
此处的结果看似运行正常,实际上还是存在迭代器失效的问题,当insert 结束之后我们去打印 it 中的值:
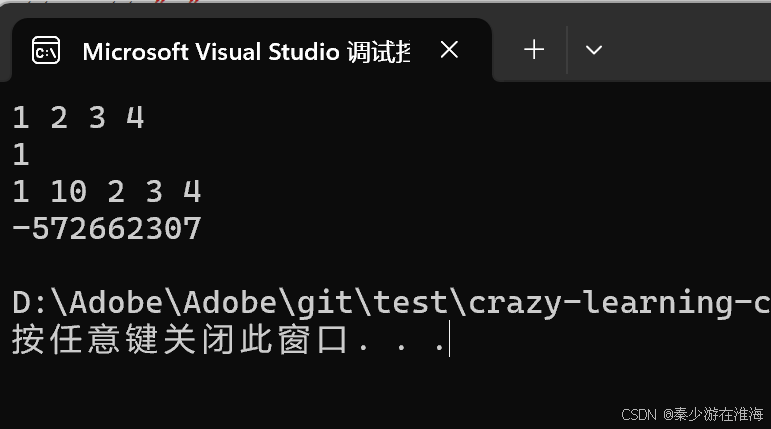
it 指向空间中的数据为随机值,这是因为 it 已经是一个野指针了,只不过是在使用的过程中编译器没有报错;
将it 传值传参给insert 的形参,insert 内部在扩容之后会去维护pos ,但是传值传参,修改形参并不会影响实参;此时你应该就有疑问了,既然传值传参形参的改变不会影响实参,那如果我们使用引用传参呢?insert 的内部维护 pos 的同时也维护了实参it ?可以这样做吗?不能,因为我们在传迭代器的时候有时会传左值(可修改),也有可能会传右值(不可修改,常见的右值有常量、表达式...),而对于右值来说具有常性,不可被修改,也就是说不可以传引用传参;可能你还有疑问,既然对于右值不能被修改,形参能否使用const 引用呢?显然也是不可以的,最然这样做迎合了右值传参,但是对于左值呢?左值是需要修改的;正是因为逻辑的前后矛盾,所以insert 不可以传引用传参,并且库中的insert ,其形参也并未使用引用:
直接认为insert 之后,insert 前的迭代器均失效;
Q:要是没有扩容呢?
- 使用insert 插入数据,其中是否扩容我们是不知道的,并且在不同平台下的扩容规则不同,所以此处我们默认不再使用insert 之前的迭代器;
迭代器失效,即在有些场景下是好的,但由于去做了一些动作,调用了一些接口(eg. insert、erase等)导致迭代器不能再用了;迭代器失效可能是野指针的失效,也有可能是一些强制检查的标记(eg.VS),也有可能是缩容(本质也是野指针问题);原则上,insert、erase 之前的迭代器在insert 、erase 之后要么更新之后再使用,要么就不使用;
12、resize
reserve 是扩容,但是一般不会缩容;
而resize:
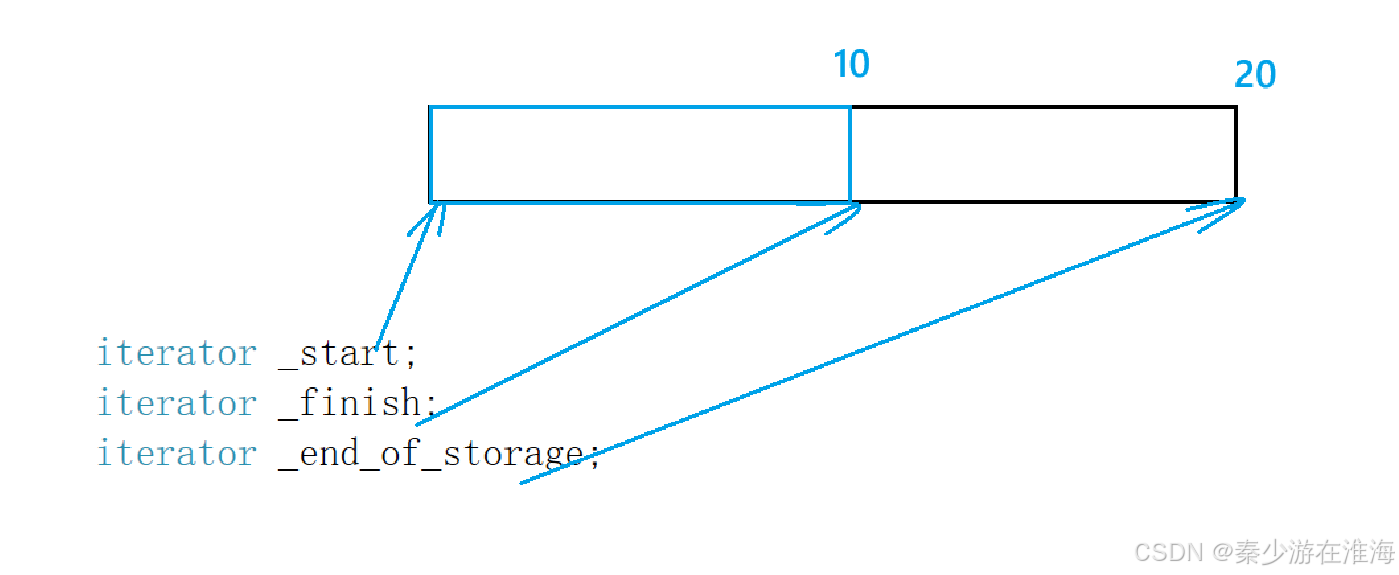
- n > capacity ,扩容;
- size<n<capacity , 进行填充;
- n<size , 删除数据;

其中的 value_type 本质上就是模板参数 T ,一般成员类型有两种,要么在类中经过了typedef,要么就是内部类;
resize 的第二个参数为 T val = T();
为了兼容模板的泛型,内置类型也被迫升级了默认构造这个概念;所以无论T为内置类型还是自定义类型,T() 均会去构造对应的数据;若 T 为 int ,则T() 就是0 , 若T为int* ,则T() 就是空指针……
resize 的常见用法:在创建vector 之后使用resize 开辟空间并进行初始化;
resize 的参考代码:
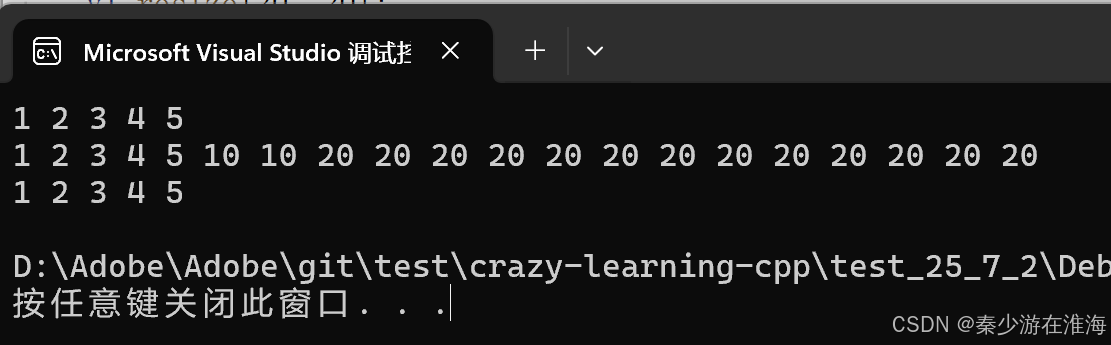
void resize(size_t n, const T& val = T()){if (n < size()){//删除数据_finish = _start + n;}else// n>=size(){reserve(n);//reserve会去判断是否需要扩容//填充数据while (_finish != _start + n){*_finish = val;++_finish;}}}测试一下:
void test3()
{zjx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (const auto& e : v1){cout << e << " ";}cout << endl;v1.resize(7, 10);v1.resize(20, 20);for (const auto& e : v1){cout << e << " ";}cout << endl;v1.resize(5);for (const auto& e : v1){cout << e << " ";}cout << endl;
}int main()
{test3();return 0;
}
13、 拷贝构造

需要注意的是库中拷贝构造中参数类型为 const vector&;在类外,使用模板的类型必须是 vector<T> ,但是在类中,可以直接使用 vector 即模板名当作类型使用;
我们此处实现还是使用 vector<T> ,严谨一些;
若我们没有显式实现拷贝构造,那么编译器自动生成的拷贝构造函数就是浅拷贝,因为vectot 涉及资源,浅拷贝就会导致多次析构而报错;所以拷贝构造函数需要我们显式实现;
//拷贝的两种写法//zjx::vector<int> v2 = v1;zjx::vector<int> v2(v1);v2(v1): --> v2 拷贝构造v1
- 方法一:按照v1 的大小开辟空间,将 v1 的数据拷贝放入新空间中;
- 方法二:复用reserve 与 push_back; 先利用reserve 为v2 开辟空间,再遍历v1 ,将v1 中的数据一个一个地push_back 到 v2 当中;
参考代码:
vector(const vector<T>& v){reserve(v.capacity());for (const auto& e : v){push_back(e);}}但是有一点需要注意的是,拷贝构造也是一种构造,如果vector 的成员变量没有初始化,那么reserve 就会出错;在VS中,内置类型未初始化那么该数据便为随机值,会严重影响reserve 开辟空间;有两种处理方式:
处理方式一:在拷贝构造中使用参数列表为成员变量初始化,如下:
vector(const vector<T>& v):_start(nullptr),_finish(nullptr),_end_of_storage(nullptr){reserve(v.capacity());for (const auto& e : v){push_back(e);}}处理方式二:在成员变量声明处给缺省值,如下:
private:iterator _start = nullptr;iterator _finish = nullptr;iterator _end_of_storage = nullptr;};倘若在成员变量声明处给了缺省值,那么默认构造完全什么都可以不写,如下:
//默认构造函数vector(){}注:当我们在初始化列表中显式地写了的时候,便用你写的值进行初始化,如果啥都没写,就是用缺省值;
还需要注意的是,虽然我们的默认构造函数中可以什么都不写,并不意味着它就可以省略!即使构造函数内部为空,它的存在仍然具有意义,因为我们可以通过初始化列表为成员变量赋初值。如果不定义构造函数,程序就不会执行初始化列表的操作。虽然编译器会在没有显式定义构造函数时自动生成默认构造函数,但需要注意拷贝构造函数也属于构造函数范畴。对于像vector这样涉及资源管理的类,必须显式实现拷贝构造函数,此时编译器就不会再自动生成默认构造函数。因此,即使构造函数内容为空,也必须明确写出这个构造函数!
14、赋值运算符重载
vector 的底层涉及资源,所以其拷贝构造、赋值运算符重载、析构函数均需要我们自己显式实现;
传统写法:释放旧空间、按照赋值对象的空间大小开辟新的空间、拷贝数据;
传统写法代码如下:
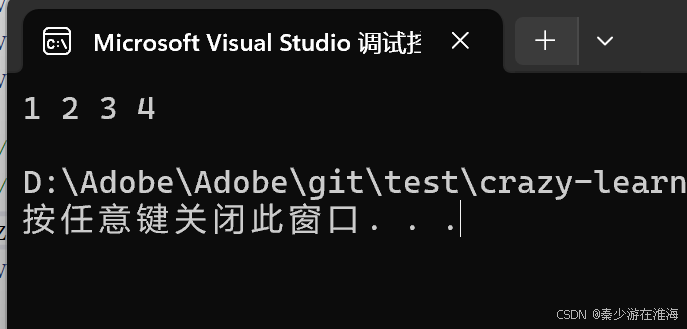
//赋值运算符重载的传统写法vector<T>& operator=(const vector<T>& v){delete[] _start;//释放旧空间_start = _finish = _end_of_storage = nullptr;//置空reserve(v.capacity());//开辟新空间for (auto& e : v)//push_back{push_back(e);}return *this;}测试一下:
void test6()
{zjx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);//拷贝构造两种写法//zjx::vector<int> v2 = v1;zjx::vector<int> v2;v2 = v1;for (const auto& e : v2){cout << e << " ";}cout << endl;
}
现代写法:借助拷贝构造 + swap
在此之前我们先实现swap,代码如下:
void swap(vector<T>& v){std::swap(_start, v._start);std::swap(_finish, v._finish);std::swap(_end_of_storage, v._end_of_storage);}注:我们最好是在vector 中实现一个swap ,如果直接使用算法库中的swap 需要实例化,并且走深拷贝的效率非常低;
现代写法代码如下:
//现代写法vector<T>& operator=(vector<T> v){swap(v);return *this;}现代写法的优势在于:传值传参会调用拷贝构造,而形参v 作为一个局部变量,出了作用域就会被销毁,自动调用其析构函数释放 v 的空间;而 this 就是需要和实参一样的空间,按照传统写法本身也需要释放旧空间,所以不如将 this 指向的空间与 v 中的空间进行交换,让 v 这个局部变量在出函数栈帧的时候自动调用析构函数释放原本 this 指向的空间,而 v 原来的空间给给了 this;现代写法的逻辑非常巧妙~
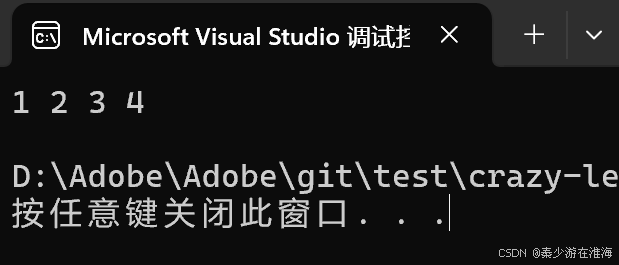
测试一下:
void test6()
{zjx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);//拷贝构造两种写法//zjx::vector<int> v2 = v1;zjx::vector<int> v2;v2 = v1;for (const auto& e : v2){cout << e << " ";}cout << endl;
}
当我们在vector 中放string 的时候:
void test7()
{zjx::vector<string> v1;v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");for (const auto& e : v1){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}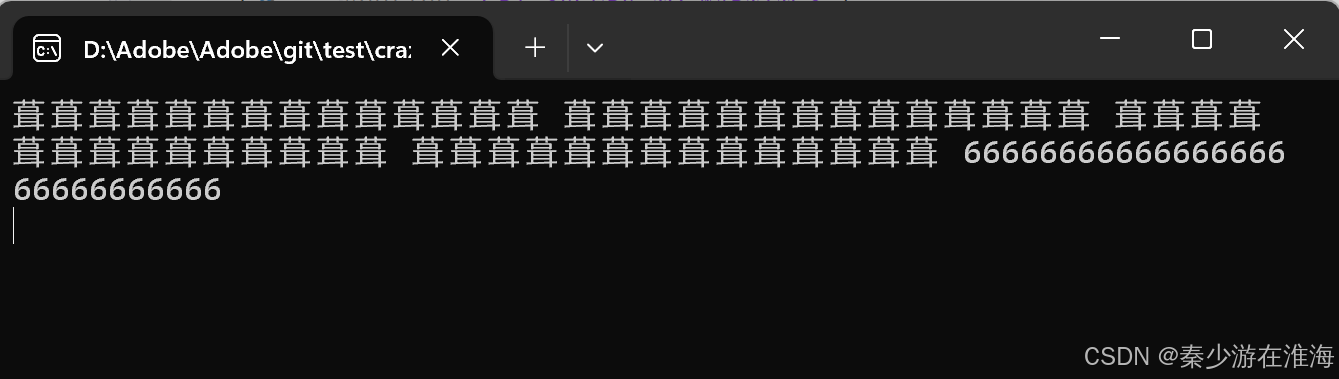
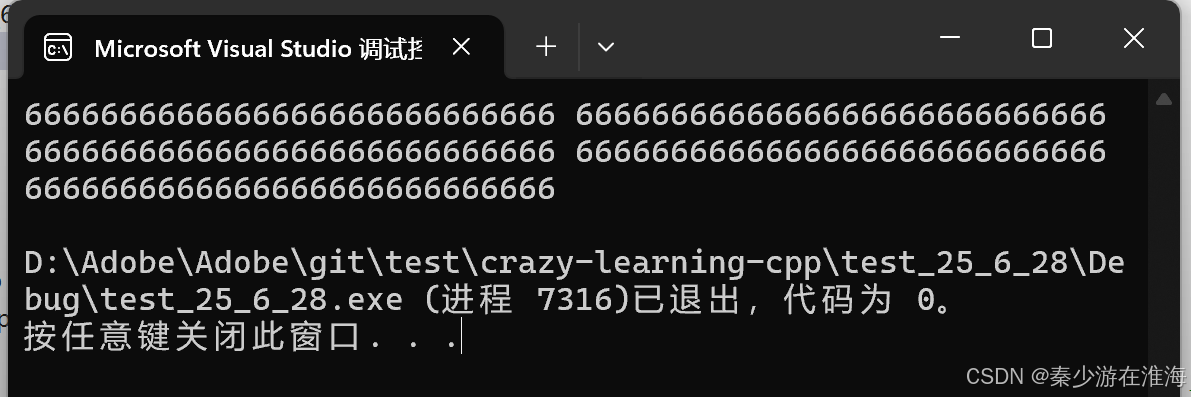
出现了乱码通常就是野指针的问题,随机值所对应的编码正好是“葺”;
刚好是5次push_back , 就导致了野指针的问题,初步怀疑这是扩容带来的问题,但是又不确定,如果少push_back 一个呢?
如上,当我们push_back 4 个数据的时候,程序正常运行,但当push_back 5 个数据的时候却出现了野指针的问题,刚好就卡在扩容这里;我们先调试一下:
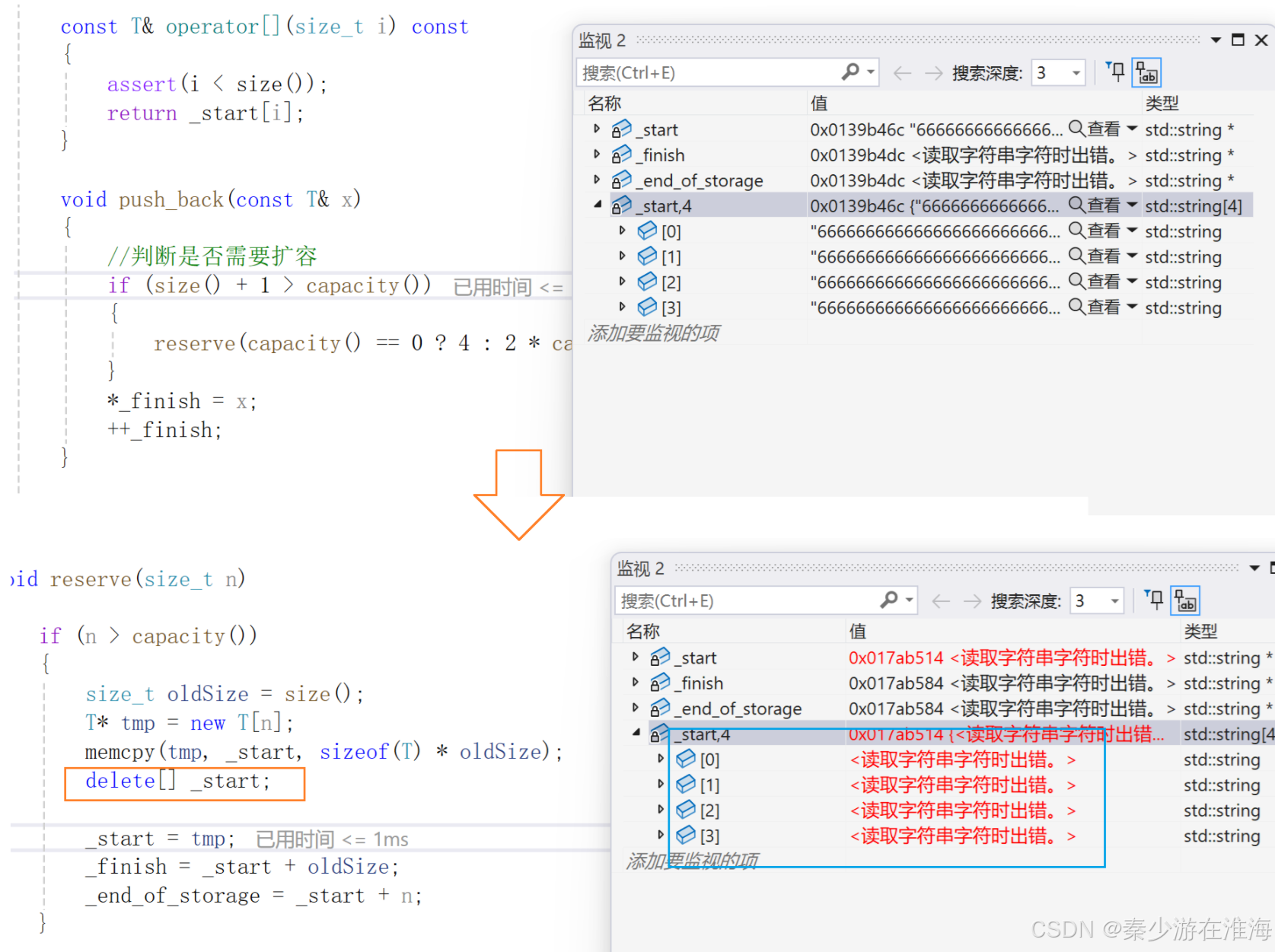
似乎是delete[] _start的时候影响了 tmp 中的数据?需要注意的是,根据调试经验,当前代码出问题不一定是当前位置出错!况且 delete 通常是不会出错的,即使delete 出错也是因为不匹配或者释放的位置不对;此处delete 使用是正确的,错误另有他处;
此处错因源于 memcpy 的浅拷贝,导致同一块空间多次析构故而报错;memcpy 是将 _start 中往后 sizeof(T)*oldSize 字节空间中的数据一个字节一个字节拷贝放入 tmp 中,而vector 中的string 涉及资源,就不能只单纯地进行浅拷贝;
注:在VS中,当字符数组较小的时候会存放在string 的_buffer 之中,比较大的才会存放在堆上,故而我们故意将字符串写得比较长,就是为了让他将数据存放到堆上;
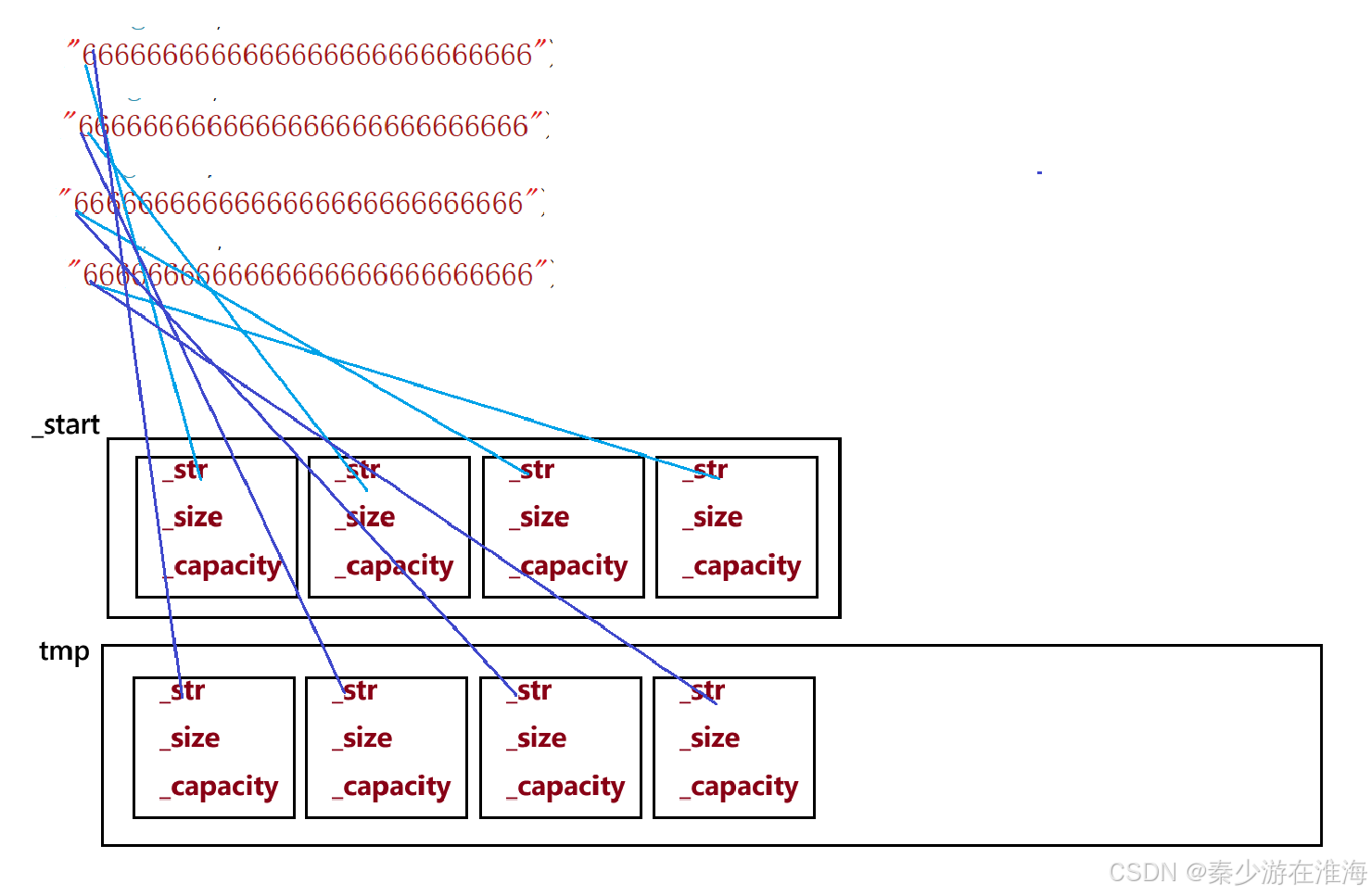
观察调试后 _start 与 tmp 指向的空间:
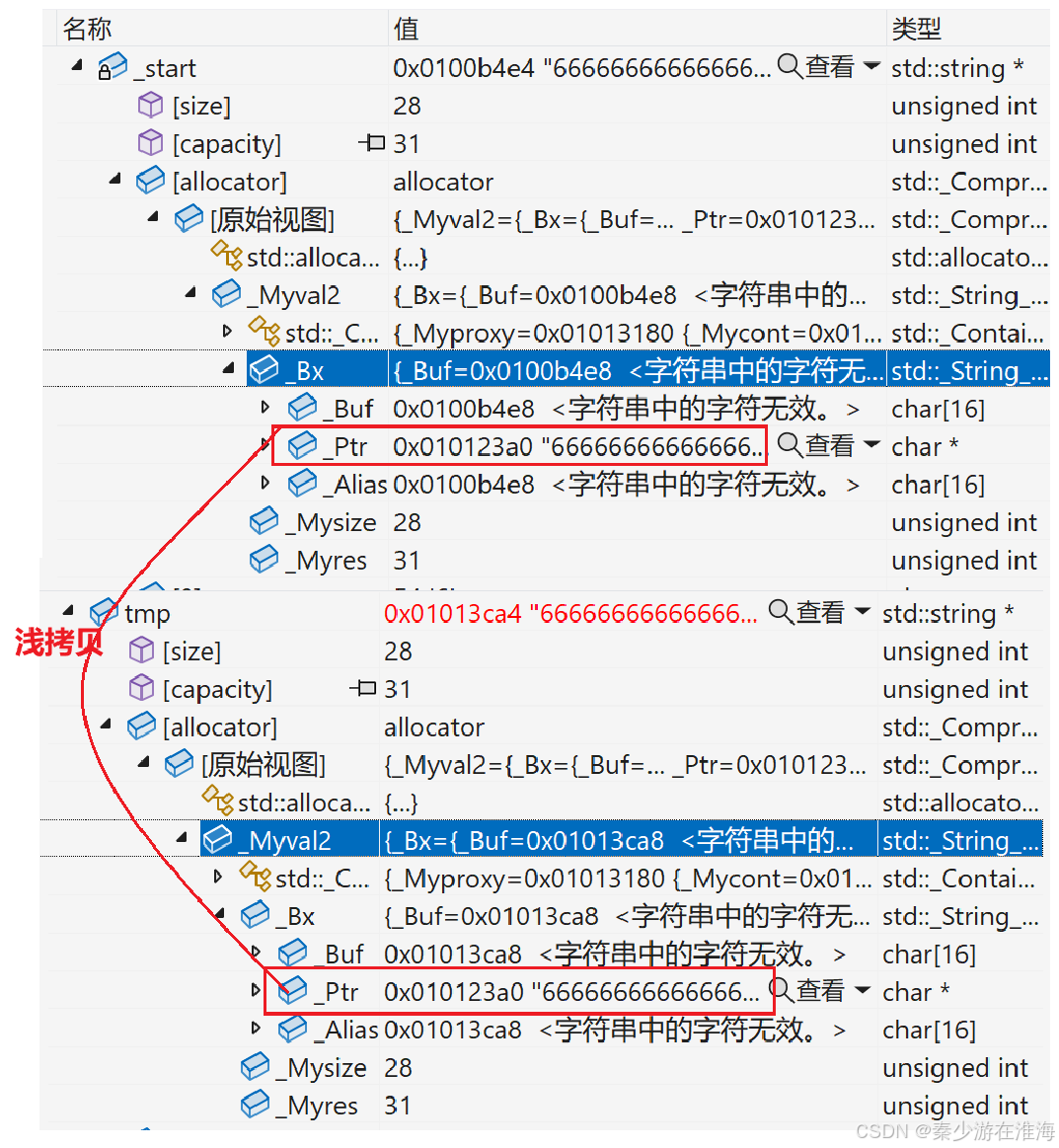
而至于在delete 的时候报错,这是因为delete[] 对于自定义类型的空间会做两件事:
- 1、调用析构函数;
- 2、调用operator delete (本质上就是free)
而此处有两个自定义类型对象指向同一块空间,那么对同一块空间调用两次析构函数,于是乎就报错了;
修改:不使用memcpy ,需要进行深拷贝,让这个 string 走深拷贝,但倘若 T 为内置类型呢?因为模板是泛型,也就是说需要做到面面俱到,是否可以直接访问string 中的 _str ,看其 _size 、_capacity 的大小来决定开辟多大的空间呢?不能,我们不能直接在类外访问一个类的私有成员变量;况且, T也不一定是 string , 实际当中,我们并不知道T究竟为什么类型;
解决:利用赋值,即使T为涉及资源的类,赋值运算符重载一定是深拷贝实现的,倘若T为自定义类型,也没有关系,赋值也可以解决问题;
参考代码如下:
void reserve(size_t n){if (n > capacity()){size_t oldSize = size();T* tmp = new T[n];//memcpy(tmp, _start, sizeof(T) * oldSize);//memcpy 是浅拷贝//我们需要自己实现深拷贝for (size_t i = 0; i < oldSize; i++){//将数据一个一个赋值过去tmp[i] = _start[i];}delete[] _start;_start = tmp;_finish = _start + oldSize;_end_of_storage = _start + n;}}测试一下:
void test7()
{zjx::vector<string> v1;v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");for (const auto& e : v1){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}
15、initializer_list 构造
另外,在vector 之中还可以使用迭代器区间进行初始化:

在C++11 之后,为了更好地去初始化这些容器,就自己创造了一个类型:initializer_list:

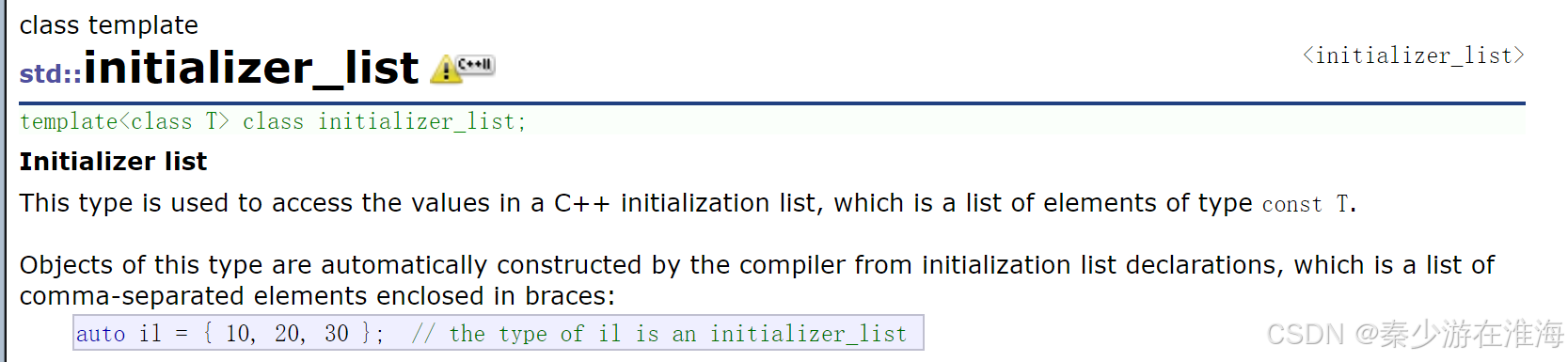
initializer_list 是一个模板,将 {} 括起来地数据传递给一个对象,它会默认将这个对象 il 的类型为 initializer_list<int>;可以认为initializer_list 是系统库中支持的容器;
Q:initializer_list 支持哪些功能?

intializer_list 支持迭代器;
Q: initializre_list 的原理是什么?
简单来说,initializer_list 与 C语言中数组的原理类似;

Q: initializer_list 所开辟的空间在哪里呢?会在常量区吗?还是和数组一样,存放在栈上?
- 打印地址,观察 il 的迭代器所指向的地址离哪一个区域的地址比较近;

从上例中便可以得知 initializer_list 在栈上开辟空间;
对于 initialzer_list ,重点需要理解的是: initializer_list 中有两个指针,一个指向开始,一个指向结束,调试观察如下:
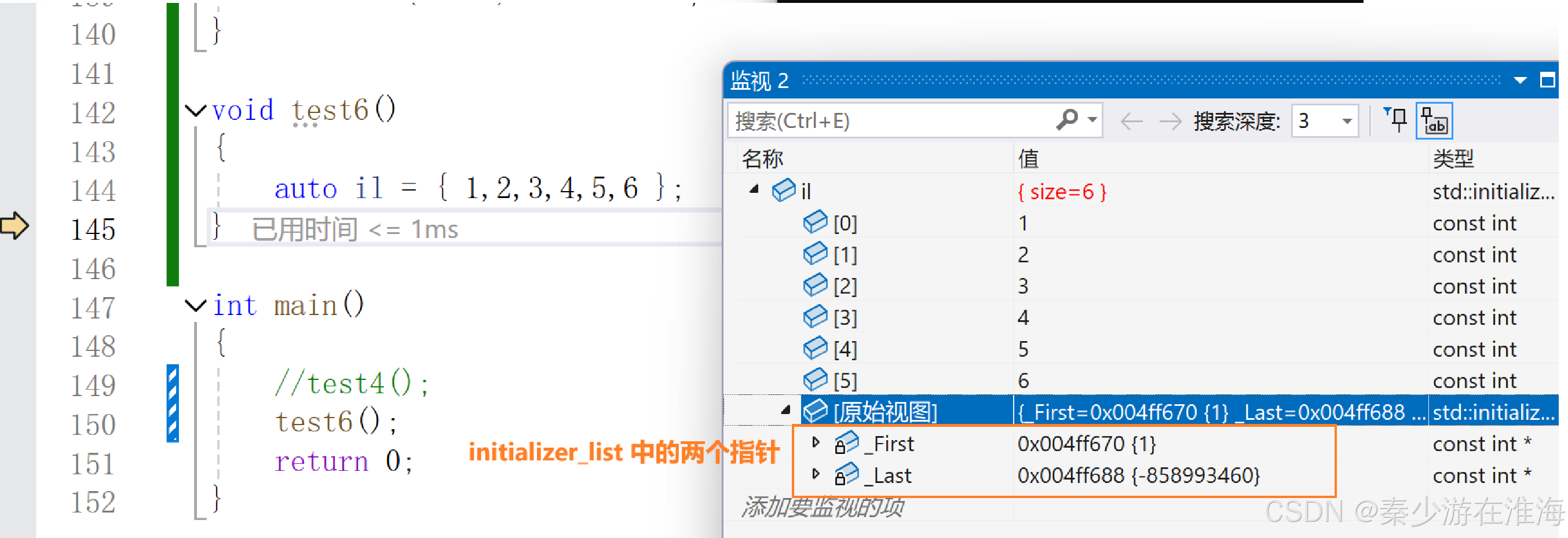
C++11 中增加了这种初始化方式,同时也对编译器进行了处理;当我们想要支持任意一个数据利用 {} 去初始化,那我们就可以去写一个对应版本的构造;
我们还可以使用隐式类型转化,和initializer_list 的效果一样,但是其语法逻辑不同,如下:
vector<int> v1({ 1,2,3,4,5,6 }); //隐式类型转换vector<int> v2 = { 1,2,3,4,5,6 };//initializer_list- 对于 v1 , 单参数的构造函数支持隐式类型转换,语法上来说,要用 {1,2,3,4,5,6} 去构造一个vector的临时对象,再使用该临时对象去拷贝构造v1 ,而编译器在此基础上直接做了优化,即直接构造;
- 对于v2, 是直接调用构造函数;
Q:如何实现 initializer_list 呢?
- 1、initializer_list 作为构造的一种,在构造的时候编译器也会走初始化列表;
- 2、调用 reserve 开辟空间
- 3、initializer_list 有迭代器那么便就支持范围for ,直接依靠范围for 依次去取到 initializer_list<T> il 中所有的数据,然后进行push_back便可;
参考代码:
//initializer_listvector<T>(initializer_list<T> il){reserve(il.size());for (auto& e : il){push_back(e);}}测试:
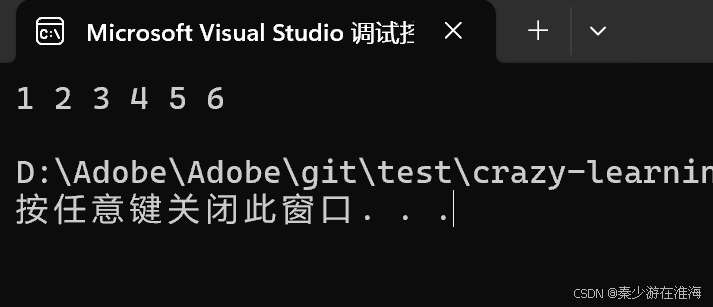
void test6()
{zjx::vector<int> v1 ={ 1,2,3,4,5,6 };for (const auto& e : v1){cout << e << " ";}cout << endl;
}
16、迭代器区间初始化

在库中,迭代器区间的初始化写成了一个模板,在类中成员函数是可以写成模板的 --> 多重模板:
类默认定义的模板参数(eg.T)是给我们整个类使用的,而类中的成员函数模板中也可以用类模板参数T,但是成员函数模板不想用T,并且想实现泛型编程,就可以在类中将此函数实现为函数模板;至于为什么不直接使用 iterator ,是因为 iterator 是属于vector 的,如果直接用vector 中的迭代器那么就只能用vector 的迭代器去初始化,就不支持使用其他类型迭代器区间来进行初始化;
参考代码:
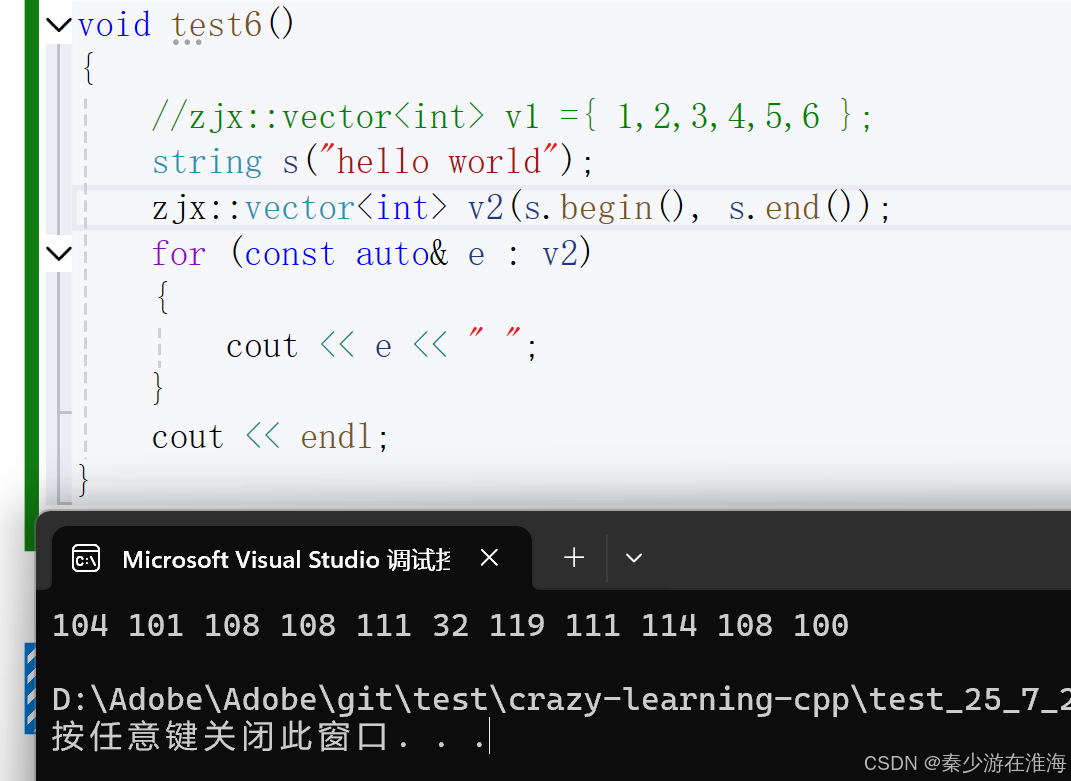
//迭代器区间的构造template<class InputIterator>vector(InputIterator first, InputIterator last){while (first != last){push_back(*first);++first;}}测试:
 可以使用其他类型数据的迭代器进行初始化:
可以使用其他类型数据的迭代器进行初始化:
还可以传原生指针:
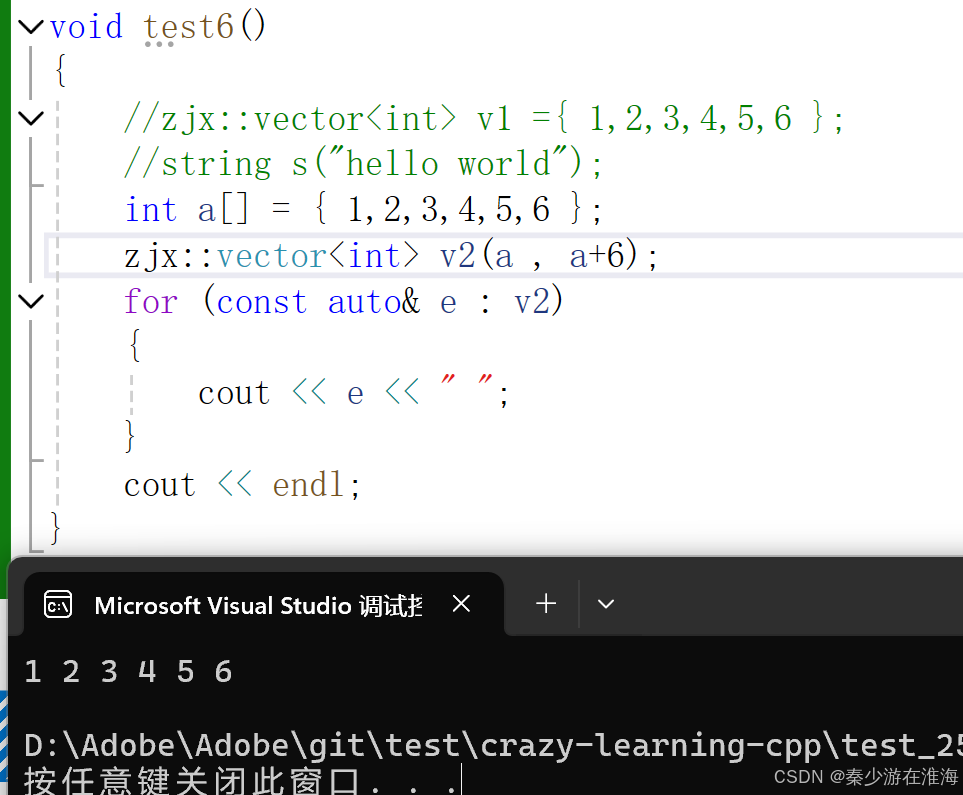
Q: 为什么可以传原生指针?
- 迭代器本身就是在模拟指针的行为,当指针所指向数据的空间是连续的就可以将指针当作迭代器使用;
说到这里,不得不再说一下算法库中的sort , 如下:

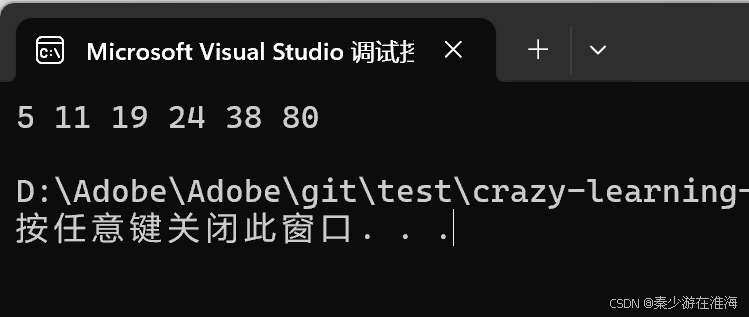
sort 是一个函数模板,也要求参数传递待排序数据的迭代器区间,对于vector 这种空间连续存在的容器进行排序时完全没有问题的,当然也可以对数组进行排序,即可以向sort 传递数组指针,使用如下:
void test7()
{int a[] = { 19,80,11,5,38,24 };sort(a, a + 6);for (auto e : a){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}
17、n个val 构造

其中size_type 就是size_t ,库中的第三个参数时空间配置器,目前不管;
注:空间配置器:STL中的容器为了提高效率,它在申请内存的时候并没有直接向我们的堆调用malloc 、new 去申请,而是直接使用内存池中的空间;此处作为形参,是期望使用者在构造的时候,如果使用者对STL中的内存池(空间配置器)不满意,那么使用者可以自己去实现一个空间配置器,然后作为参数传给vector ,那么此时构造的时候就不再使用vector默认STL中的内存池,而是用你实现的内存池去申请空间;
实现:reserve + 填值,也可以直接去复用resize
//n个val 的构造vector(size_t n, const T& val = T()){//直接复用resizeresize(n, val);}//vector(size_t n, const T& val = T())//{// //reserve + 填值// reserve(n);// for (int i = 0; i < n; i++)// {// *_finish = val;// ++_finish;// }//}测试:
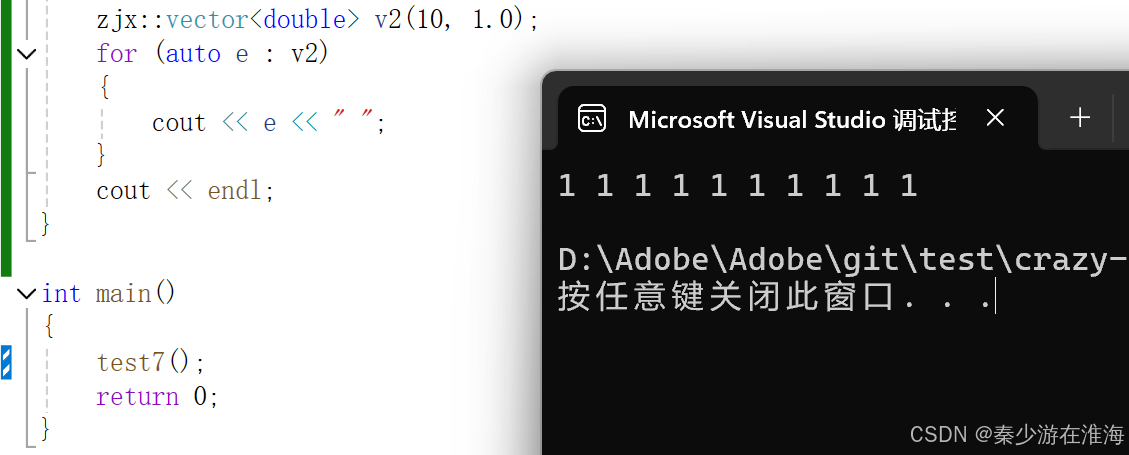
void test7()
{zjx::vector<int> v1(10, 1);for (auto e : v1){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}
再测试一下:
Q:为什么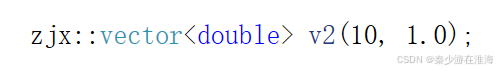 可以正常运行,而
可以正常运行,而 却会报错呢?
却会报错呢?
报错原因:编译器对![]() 去调用了我们实现的迭代器区间构造函数模板;
去调用了我们实现的迭代器区间构造函数模板;
Q:为什么呢?
- C++编译器在进行类型传参(函数模板参数匹配)的原则:匹配更匹配的;即编译器会在有选择的情况下,去“吃”自己更喜欢“吃”的;如果没有自己喜欢“吃”的,也可以“将就”;并且在这两点的基础上,“有现成吃现成”;对于
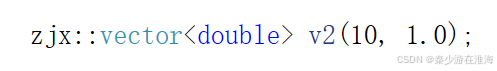 ;来说,编译器没有选择,匹配不上用迭代器区间初始化的构造,就只能去调用 n 个val 的构造;简单从字面量的角度来说就是:给整型的变量编译器就默认它为int 类型,给浮点数字面量编译器默认它的类型为double;当所传参数类型为 int 、double 的时候,就只能“勉强”地去匹配使用 n 个val 完成初始化地函数,因为倘如调用迭代器区间地函数模板,T被实例化为了double ,虽然size_t 与 int 有一点不匹配,但是也可以勉强使用;
;来说,编译器没有选择,匹配不上用迭代器区间初始化的构造,就只能去调用 n 个val 的构造;简单从字面量的角度来说就是:给整型的变量编译器就默认它为int 类型,给浮点数字面量编译器默认它的类型为double;当所传参数类型为 int 、double 的时候,就只能“勉强”地去匹配使用 n 个val 完成初始化地函数,因为倘如调用迭代器区间地函数模板,T被实例化为了double ,虽然size_t 与 int 有一点不匹配,但是也可以勉强使用; - 但是对于
 来说,它是有选择地;相较于用 n 个val 初始化的构造,将 T实例化为int , 但size_t 与int 稍微不太匹配即“能吃但是不太对味口”;对于迭代器区间初始化的构造,它是一个函数模板,v1 的两个实参均为 int 类型的数据,那么InputIterator 就被实例化为了int , 显然相较于用 n 个val 初始化的构造函数,v1 更“喜欢”去调用更适合自己的用迭代器区间初始化的构造函数;
来说,它是有选择地;相较于用 n 个val 初始化的构造,将 T实例化为int , 但size_t 与int 稍微不太匹配即“能吃但是不太对味口”;对于迭代器区间初始化的构造,它是一个函数模板,v1 的两个实参均为 int 类型的数据,那么InputIterator 就被实例化为了int , 显然相较于用 n 个val 初始化的构造函数,v1 更“喜欢”去调用更适合自己的用迭代器区间初始化的构造函数;

而int 类型的数据不可以进行解引用;
Q:如何解决呢?
- 理论上而言,可以将实现n 个val 的构造第一个参数类型size_t 修改为int ,但是库中仍然使用的size_t ,并且即使是修改为int 也还存在其他问题;
首先我们先来看一下库中是如何解决的,如下:
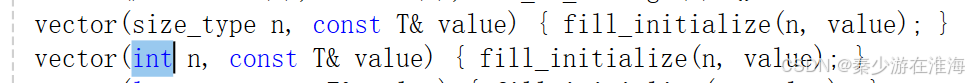
库中实现为了两个函数,按照库中给的进行修改:
参考代码:
//n个val 的构造vector(size_t n, const T& val = T()){//直接复用resizeresize(n, val);}vector(int n, const T& val = T()){//直接复用resizeresize(n, val);}Q:那既然vector 的底层实现中,其第一个参数类型还有用int 实现的,为什么在文件中标明其第一个参数的默认类型为 size_type(size_t) 呢?

- 1、一般在STL的惯例:只要是个数,就不会出现负数的情况,均会给size_t 类型,且用size_t 可以表达的数据会更多一些;
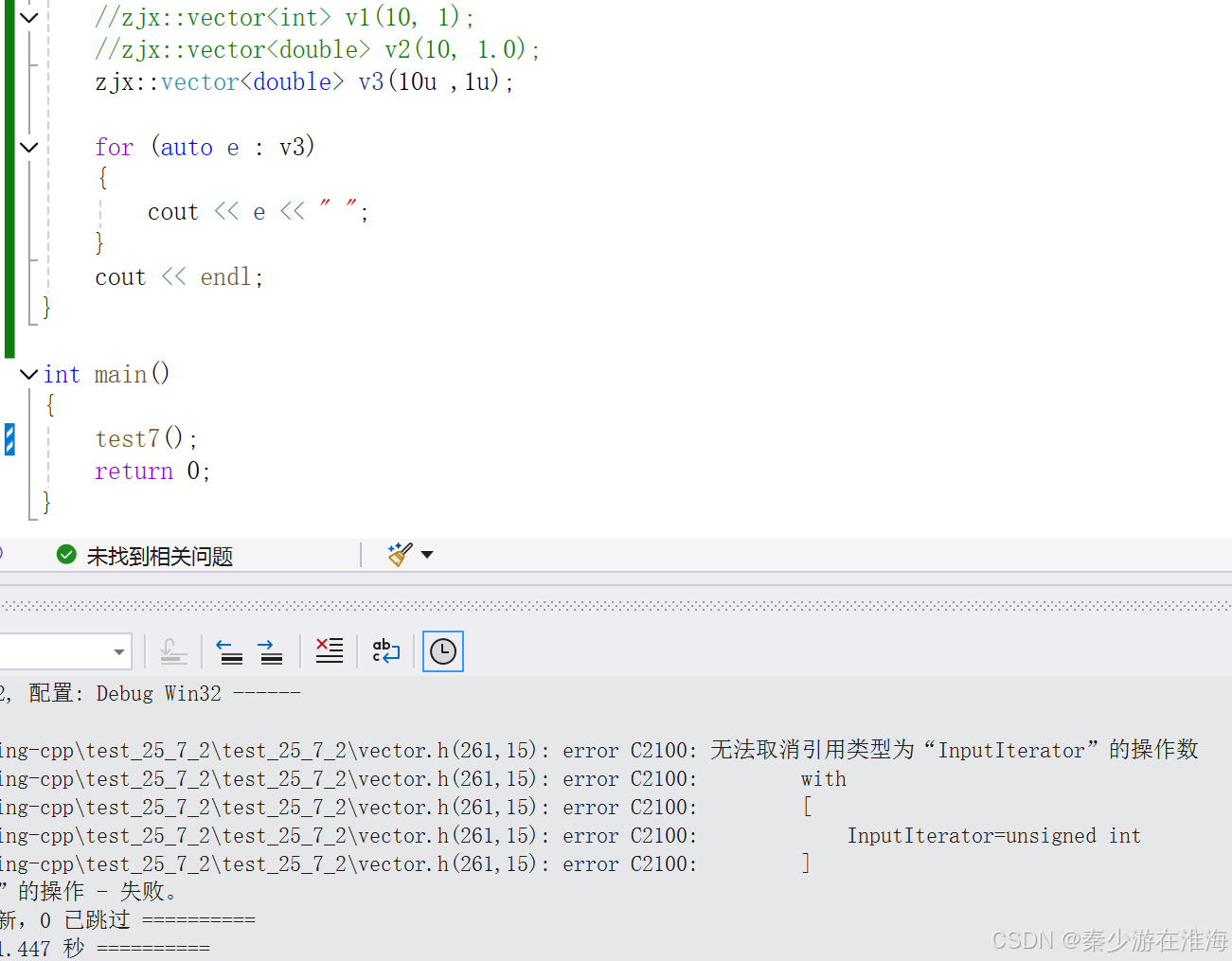
- 2、将size_t 改为 int ,在极端情况下也会出现非法间接寻址的问题;(eg. 传参类型为两个无符号整型,例子如下:还是去调用了用迭代器区间初始化的构造,由于不能对整数进行解引用操作,故而报错)







|如何以实践破解数据挖掘教学痛点)



)
)


)



