1 介绍
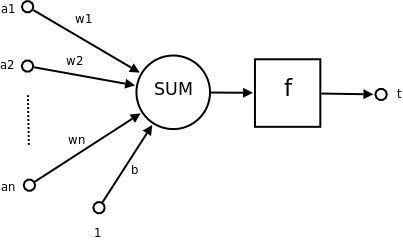
图片来自:https://zh.wikipedia.org/zh-cn/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
神经网络一直感觉挺神奇的,江湖也说可解释性很差,无论如何还是学学吧。借这次学习哈佛的TinyML,也就顺带弄了。
这里没有太多的去看神经网络的细节,主要还是偏重使用层面(对于菜鸟来说,能用大神的库就够了。。。)。
在神经元中,有两个核心变量w(Weight,权重)和b(Bias,偏置)还是要理解。以 y = w*x + b为例,w 控制输入 x 对输出 y 的影响程度,b用于调整模型的输出基准。简单来说,w 负责 “缩放” 输入特征的影响,b 负责 “偏移” 输出结果,两者共同配合使模型能够学习数据中的线性或非线性关系。在训练过程中,模型通过反向传播算法不断更新 w 和 b,以最小化预测误差。
在TinyML课程中,神经网络的练习地址:Course | edX
练习代码地址:https://colab.research.google.com/github/tinyMLx/colabs/blob/master/2-2-5-FirstNeuralNetworkRevisited.ipynb
2 代码
代码整理如下:
import sysimport numpy as np
import tensorflow as tf
from tensorflow import keras# This script requires TensorFlow 2 and Python 3.
if tf.__version__.split('.')[0] != '2':raise Exception((f"The script is developed and tested for tensorflow 2. "f"Current version: {tf.__version__}"))if sys.version_info.major < 3:raise Exception((f"The script is developed and tested for Python 3. "f"Current version: {sys.version_info.major}"))my_layer = keras.layers.Dense(units=1, input_shape=[1])
model = tf.keras.Sequential([my_layer])
model.compile(optimizer='sgd', loss='mean_squared_error')xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)model.fit(xs, ys, epochs=500)print(model.predict(np.array([10.0])))print(my_layer.get_weights())my_layer_1 = keras.layers.Dense(units=2, input_shape=[1])
my_layer_2 = keras.layers.Dense(units=1)
model = tf.keras.Sequential([my_layer_1, my_layer_2])
model.compile(optimizer='sgd', loss='mean_squared_error')xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)model.fit(xs, ys, epochs=500)print(model.predict(np.array([10.0])))print(my_layer_1.get_weights())
print(my_layer_2.get_weights())value_to_predict = 10.0layer1_w1 = (my_layer_1.get_weights()[0][0][0])
layer1_w2 = (my_layer_1.get_weights()[0][0][1])
layer1_b1 = (my_layer_1.get_weights()[1][0])
layer1_b2 = (my_layer_1.get_weights()[1][1])layer2_w1 = (my_layer_2.get_weights()[0][0])
layer2_w2 = (my_layer_2.get_weights()[0][1])
layer2_b = (my_layer_2.get_weights()[1][0])neuron1_output = (layer1_w1 * value_to_predict) + layer1_b1
neuron2_output = (layer1_w2 * value_to_predict) + layer1_b2neuron3_output = (layer2_w1 * neuron1_output) + (layer2_w2 * neuron2_output) + layer2_bprint(neuron3_output)首先导入的keras的库。
Keras 是一个高级神经网络 API(应用程序编程接口),它用 Python 编写,旨在让深度学习模型的构建、训练和部署变得更加简单、直观和高效。
它的主要特点包括:
- 用户友好:提供了简洁易懂的接口,使得开发者能够快速构建复杂的神经网络模型,而无需过多关注底层实现细节。
- 模块化:将神经网络的各个组成部分(如层、激活函数、优化器等)设计为独立的模块,便于组合和复用。
- 可扩展性:支持自定义层、损失函数等,以满足特定的业务需求。
- 多后端支持:最初可以在 TensorFlow、CNTK、Theano 等深度学习框架上运行,后来成为了 TensorFlow 的官方高级 API(即 tf.keras)。
Keras 广泛应用于学术研究、工业界开发等领域,特别适合快速原型设计、教学和解决实际的深度学习问题。无论是简单的全连接神经网络,还是复杂的卷积神经网络(CNN)、循环神经网络(RNN)等,都可以通过 Keras 便捷地实现。
之后检查TensorFlow和Python的版本。
之后使用了1层神经网络和2层神经网络。最后使用同样的数据集对模型进行了验证。
3 代码细节
1层神经网络
通过数据可以看出,关系是y = 2x - 1。
核心代码是:
my_layer = keras.layers.Dense(units=1, input_shape=[1])
model = tf.keras.Sequential([my_layer])
model.compile(optimizer='sgd', loss='mean_squared_error')xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)model.fit(xs, ys, epochs=500)训练 500 次,优化器是随机梯度下降(SGD),损失函数是均方误差(MSE)。units=1表示使用了1个神经元。
上一篇说的梯度下降,就封装在model.fit中。
之后预测输入值10,按照关系,应该值是19。
一开始的训练情况:
Epoch 1/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 482ms/step - loss: 1.8166
Epoch 2/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 87ms/step - loss: 1.5706
Epoch 3/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 136ms/step - loss: 1.3741
最后是训练情况:
Epoch 498/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 64ms/step - loss: 2.4299e-05
Epoch 499/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step - loss: 2.3800e-05
Epoch 500/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 139ms/step - loss: 2.3311e-05
此时的预测结果是[[18.985914]]
最后计算出来的参数:
[array([[1.9979583]], dtype=float32), array([-0.99367034], dtype=float32)]
感觉神经网络计算的参数,只能无限逼近真实值,而且有一定的上限范围。
2层神经网络
代码如下:
my_layer_1 = keras.layers.Dense(units=2, input_shape=[1])
my_layer_2 = keras.layers.Dense(units=1)
model = tf.keras.Sequential([my_layer_1, my_layer_2])
model.compile(optimizer='sgd', loss='mean_squared_error')xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)model.fit(xs, ys, epochs=500)可以看到,和上面单层神经网络基本差不多,就只是增加了一层。这里第一层是units=2,使用了两个神经元。第二层是units=1,使用了一个神经元。
用的数据集也是一致。
开始的训练情况:
Epoch 1/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 301ms/step - loss: 37.9950
Epoch 2/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 53ms/step - loss: 19.0502
Epoch 3/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 55ms/step - loss: 11.7038
最后的训练情况:
Epoch 498/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 117ms/step - loss: 3.2211e-13
Epoch 499/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 61ms/step - loss: 3.2211e-13
Epoch 500/500 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step - loss: 3.2211e-13
最后计算出来的参数:
1层:[array([[-0.10459945, -1.3529563 ]], dtype=float32), array([-0.07518195, 0.46336478], dtype=float32)]
2层:[array([[ 0.554448 ], [-1.5211095]], dtype=float32), array([-0.2534862], dtype=float32)]
可以看到,此时的参数和原始参数2和-1相去甚远。
可以使用print(model.predict(np.array([10.0])))查看输出。
预测结果是[[18.999998]]
也可以手算,过程是:
neuron1_output = (layer1_w1 * value_to_predict) + layer1_b1
neuron2_output = (layer1_w2 * value_to_predict) + layer1_b2
neuron3_output = (layer2_w1 * neuron1_output) + (layer2_w2 * neuron2_output) + layer2_b
预测结果也是[[18.999998]]
可以看出,2层神经网络的效果比1层好出了一个数量级。上限也更高一些。。
4 课后问题
4.1 怎么判断层数和神经元?
层数:
输入是低维数值(比如温度、房价预测):隐藏层很少(1~3层)就行。
输入是高维结构化数据(比如图像 224×224×3):通常会用很多层(10层甚至100层)。
神经元:
输入层神经元数 = 输入特征数(这个是固定的)。
输出层神经元数 = 任务要求(分类数、回归目标数)。
隐藏层神经元数:常见初始值,介于输入层和输出层之间。
例子:
房价预测(10个特征):
输入层:10
隐藏层1:16
输出层:1(回归)
层数:2 隐藏层足够。
手写数字识别(28×28=784特征):
输入层:784
隐藏层:128 → 64
输出层:10(分类)
层数:2~3 隐藏层。
图像分类(224×224×3):
通常直接用 CNN 多层(几十层以上),每层的卷积核数逐渐增多。
调试技巧:
欠拟合 → 增加层数或神经元
过拟合 → 减少层数或神经元,或加正则化(Dropout、L2)
训练慢 → 先简化模型找方向,再加复杂度
这些就是所谓调参侠核心技能吧?
4.2 调参侠速查
调参侠速查表:
🛠 调参侠速查表
现象 / 问题 可能原因 调整方向(超参数 & 结构) 训练集和验证集都准确率低 / loss 高(欠拟合) 模型容量不足 / 学习率太低 / 数据特征不足 1️⃣ 增加层数或神经元数量2️⃣ 换更复杂模型(CNN, LSTM, Transformer)3️⃣ 提高学习率或用自适应优化器(Adam, RMSProp)4️⃣ 增加特征工程或用更丰富的输入数据 训练集准确率高,验证集准确率低(过拟合) 模型太复杂 / 训练时间太长 / 数据不足 1️⃣ 减少层数或神经元2️⃣ 增加正则化(L1/L2、Dropout)3️⃣ 数据增强(图像翻转、噪声等)4️⃣ 提前停止(Early Stopping) loss 不下降 / 降得很慢 学习率太低 / 梯度消失 / 数据归一化问题 1️⃣ 提高学习率或用学习率调度器2️⃣ 换激活函数(ReLU、LeakyReLU)3️⃣ 数据标准化(StandardScaler / BatchNorm) loss 一开始就很大且不变 学习率太高 / 参数初始化不当 1️⃣ 降低学习率2️⃣ 换权重初始化方法(He、Xavier) 结果震荡 学习率太高 / 批大小太小 1️⃣ 降低学习率2️⃣ 增大 batch size 训练速度太慢 模型过大 / I/O 瓶颈 / 硬件不足 1️⃣ 减少模型规模2️⃣ 用 GPU/TPU3️⃣ 数据缓存(prefetch, cache)
📏 推荐初始架构 & 神经元数量参考
输入特征 ≤ 20:12 隐藏层,每层 1664 神经元
输入特征 20200:24 隐藏层,每层 64~256 神经元
高维数据(图像/音频):用 CNN/RNN,通道数随层数增加
输出层:分类数(分类任务)或 1(回归任务)
🔄 调参流程建议
小模型快速验证可行性(先证明能学到东西)
逐步增加复杂度(层数、神经元)
观察验证集(避免过拟合)
优化训练策略(学习率、正则化)
自动调参(Optuna、Ray Tune、Keras Tuner)
4.3 LLM大语言模型和神经网络的关系
神经网络 → 是通用技术框架。
Transformer → 是一种特定神经网络架构,擅长处理序列。
LLM → 是基于 Transformer 的、专门用大规模文本训练的神经网络。
LLM(如 GPT-4、Claude、LLaMA、GLM)本质是 超大规模的 Transformer 神经网络,层数可能几十层甚至上百层,参数量可以到 百亿 ~ 万亿级。仅此而已。。。
)




、随机搜索)


)

)








