- 实验目的
1. 掌握特征工程,会进行特征提取与特征选择,会进行缺失值填充。
2. 建立决策树模型,解决实际问题。
3. 会对模型进行调试,能够绘制并保存决策树。
- 实验环境
Python 3.7.0,Sklearn ,PyCharm
- 实验原理
1、特征工程
特征工程、降维与超参数调优是机器学习工程应用中的三个重要问题。在优惠券核销示例中讨论过,输入模型进行训练的一般不是实例的属性,而是从实例的属性数据中提取出的特征。降维技术可以解决因为特征过多而带来的样本稀疏、计算量大等问题。
在训练时,算法参数的设置对算法效果的影响很大,设置合适算法参数的过程称为“超参数调优”。特征工程的目标是从实例的原始数据中提取出供模型训练的合适特征。特征的提取与问题的领域知识密切相关。特征工程在机器学习过程中的位置和作用如下图所示。特征提取是一种创造性的活动,没有固定的规则可循。一般来说,需要先从总体上理解数据,必要时可通过可视化来帮助理解,然后运用领域知识进行分析和联想,然后处理数据提取特征。
首先要数据预处理:
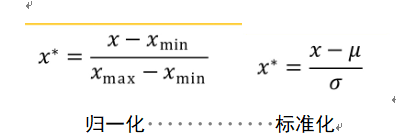

2、决策树算法
决策树,可以理解为:从训练数据中学习得出一个树状结构的模型。决策树属于判别模型,既可以做分类也可以做回归。
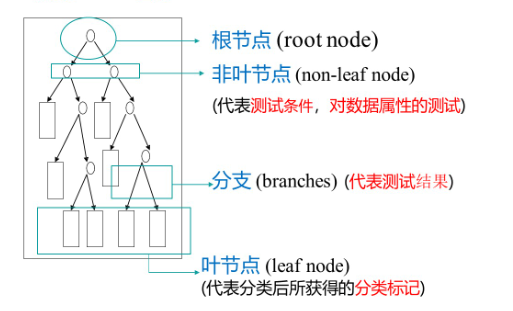
可分为训练阶段和分类阶段:
训练阶段:从给定的训练数据集DB,构造出一棵决策树:class=DecisionTree(DB)
分类阶段:从根开始,按照决策树的分类属性逐层往下划分,直到叶节点,获得决策结果。y= DecisionTree(x)
基尼指数:1.对于样本集D,假设有K个分类,则样本属于第k类的概率为p;,则此概率分布的基尼指数定义为:
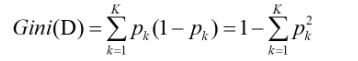
如果样本集D按照某个属性被划分成独立的两个子集D,和Dz,其基尼指数为:
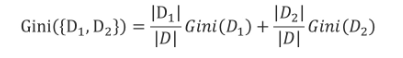
度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为p;(k = 1,2.. . , K),则D的信息嫡定义为:
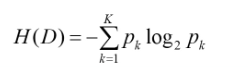
信息增益率:
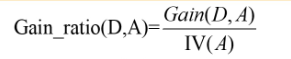
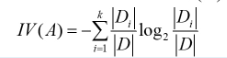
信息增益:
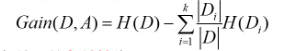
- 实验内容
泰坦尼克号的沉没是历史上最著名的沉船之一。1912年4月15日,在首航期间,泰坦尼克号撞上一座冰山后沉没,2224名乘客和机组人员中有1502人遇难。这一耸人听闻的悲剧震撼了国际社会,并导致了更好的船舶安全条例。
沉船导致生命损失的原因之一是乘客和船员没有足够的救生艇。虽然幸存下来的运气有一些因素,但有些人比其他人更有可能生存,比如妇女,儿童和上层阶级。
在这个挑战中,我们要求你完成对什么样的人可能生存的分析。特别是,我们要求你运用机器学习的工具来预测哪些乘客幸存下来的悲剧。数据描述如下:
特征 | 描述 | 特征描述 |
PassengerId | 序号,乘客编号 | 乘客ID,对结果无影响 |
Survival | 生存,是否获救 | 1是存活,0是未存活 |
Pclass | 票类别-社会地位 | 船舱等级,1 = Upper,2 = Middle,3= Lower |
Name | 乘客姓名 | 乘客姓名,对结果无影响 |
Sex | 性别 | male,female,女士优先,对结果有影响 |
Age | 年龄 | 年龄,对结果有影响 |
SibSp | 兄弟姐妹/配偶的数量 | 对结果有影响 |
Parch | 父母/孩子的数量 | 对结果有影响 |
Ticket | 票号 | 对结果无影响 |
Fare | 乘客票价 | 和船舱等级一样,有影响 |
Cabin | 客舱号码 | 对结果无影响 |
Embarked | 登船港口,上船地点 | C=Cherbourg, Q=Queenstown, S=Southampton 出发地点:S=英国南安普顿Southampton 途径地点1:C=法国 瑟堡市Cherbourg 途径地点2:Q=爱尔兰 昆士敦Queenstown |
数据内容如下:
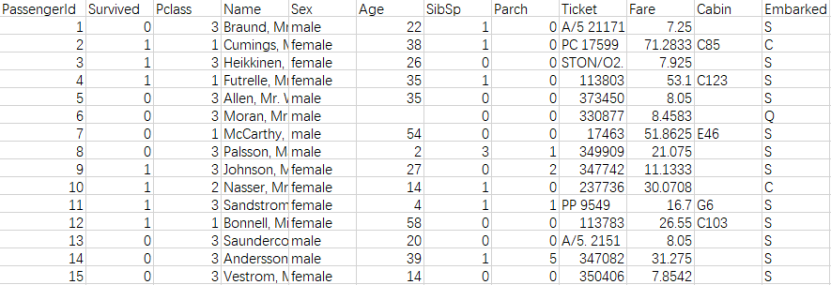
显然,这次事故中没有多少乘客幸免于难。在训练集的891名乘客中,只有342人幸存下来,只有38.4%的机组人员在空难中幸存下来。我们需要从数据中挖掘出更多的信息,看看哪些类别的乘客幸存下来,哪些没有。
数据特征分为:连续值和离散值。
- 离散值:性别(男,女),登船地点(S,Q,C)
- 连续值:年龄,船票价格
任务一、对数据集进行特征处理
1.1源代码
- 导入数据
- 获取数据类型的描述统计信息
print(data.describe())
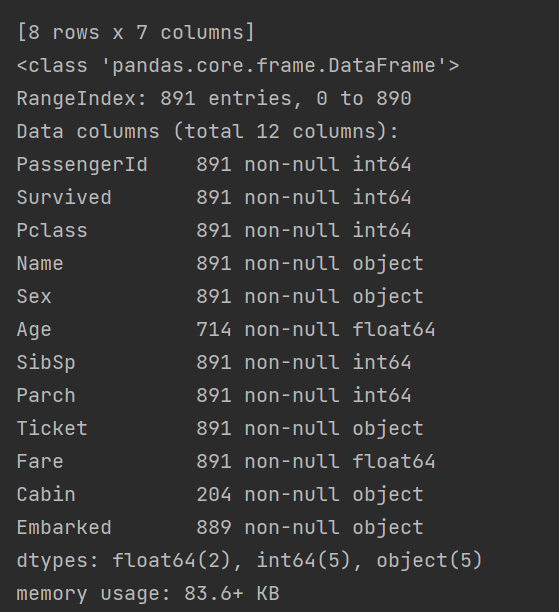
- 查看数据信息:
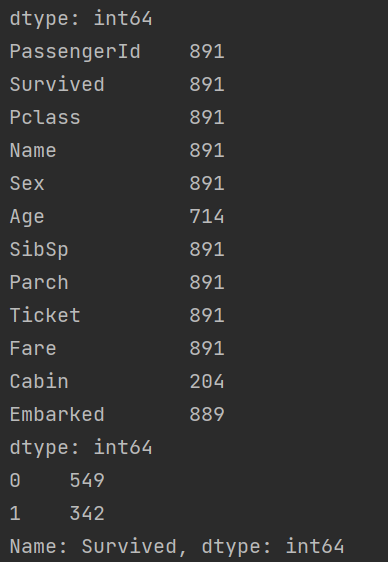
print(data.info())
提取行与列:

提取行列中的数据:

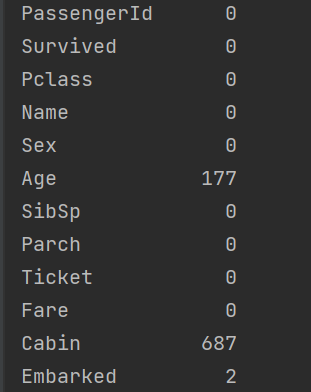
- 查看是否有缺失值:

- 生还情况:
print(data['Survived'].value_counts())
- 正则表达:
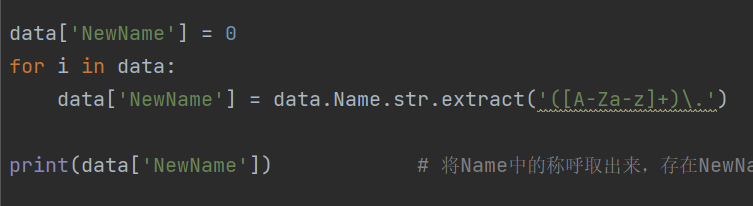
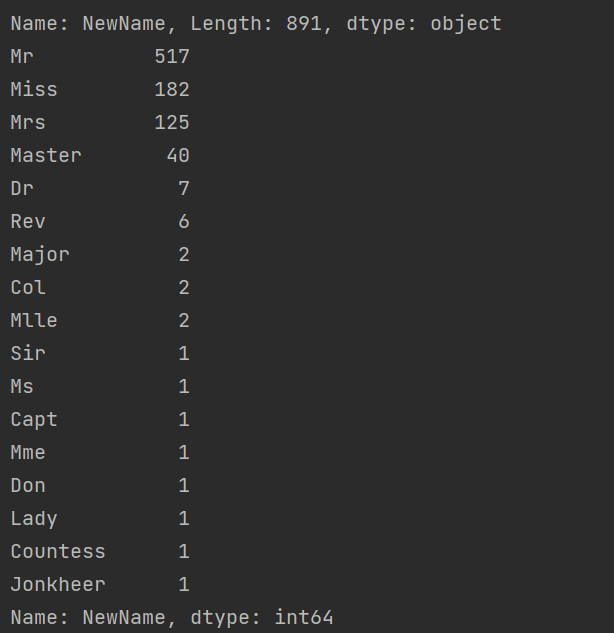
- 对值统计:
print(data['NewName'].value_counts())
- 替换:
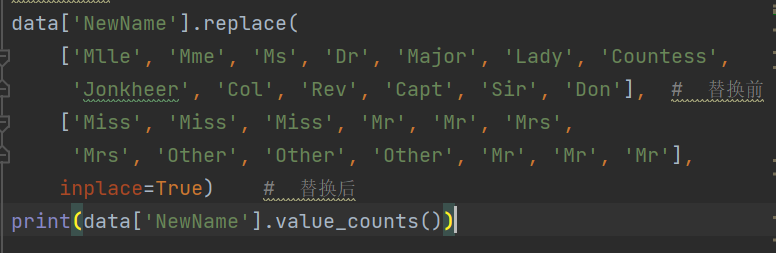
- 求平均年龄:
print(data.groupby('NewName')['Age'].mean())
- 填充缺失值:
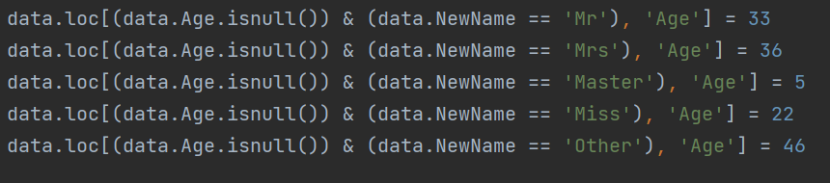
- 再次查看是否有缺失值并进行填充
print(data.Age.isnull().sum()) # 0 表示没有缺失值了。
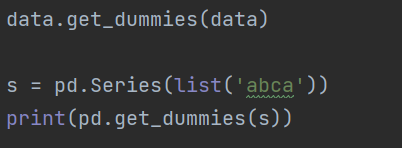
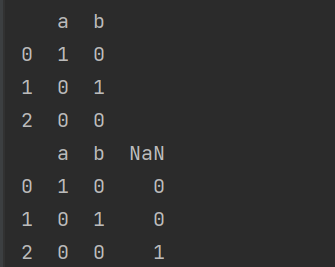
- One-hot编码:
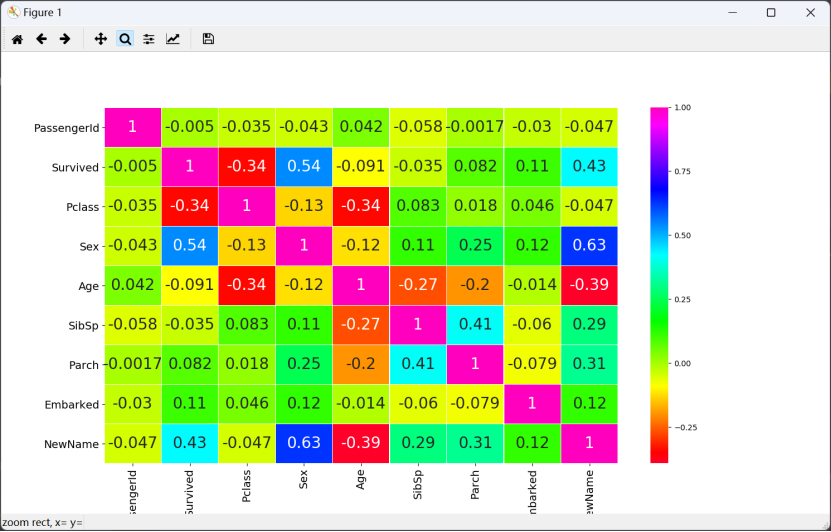
- 特征协方差关系图:
sns.heatmap(data.corr(), annot=True, cmap='gist_rainbow', linewidths=0.2, annot_kws={'size': 20})
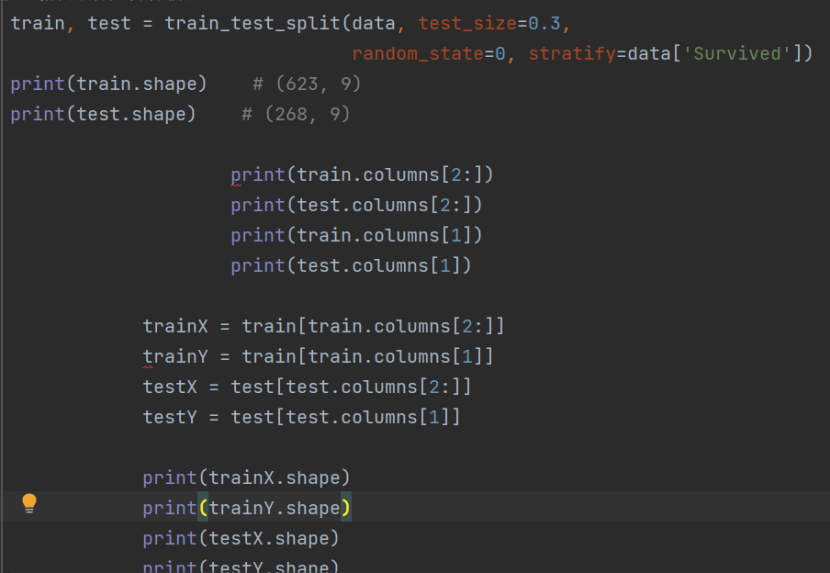
- 构建学习模型:测试集与训练集
- 字符串值转化为数字:

1.2实验结果与分析
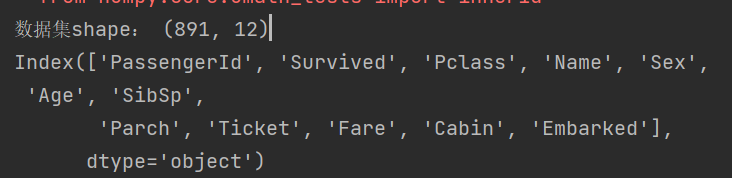
- 数据集详情:
2.获取数据类型的描述统计信息:
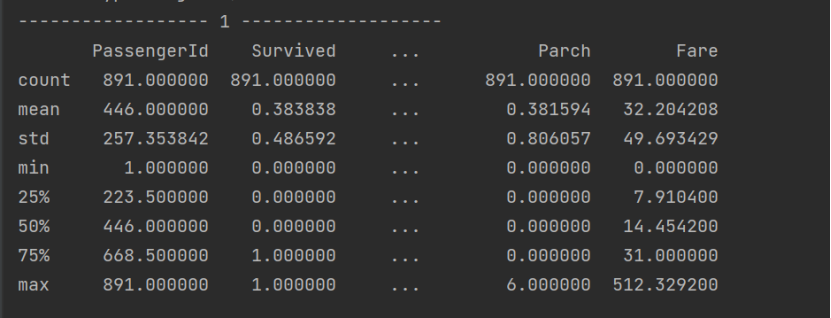
- 数据详细信息:
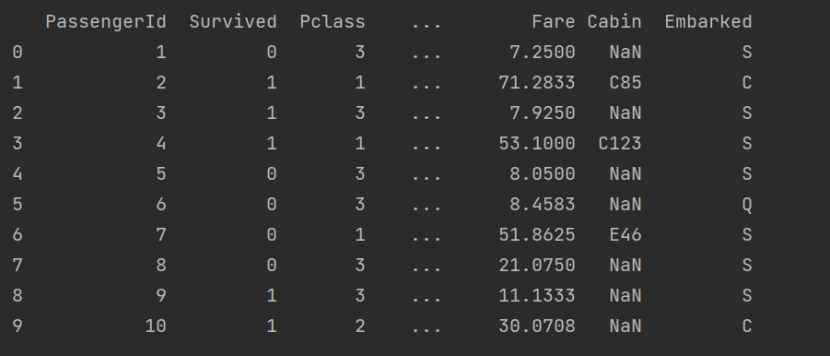
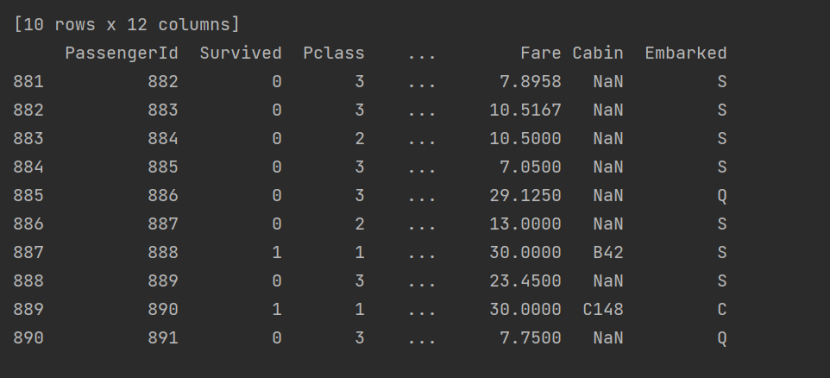
- 前十行数据:
- 第一行第一列:
- 更详细数据:
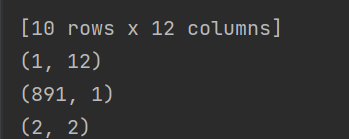
- 缺失值:
- 生还情况:
- 运用正则表达式,对值统计:
- 替换后:
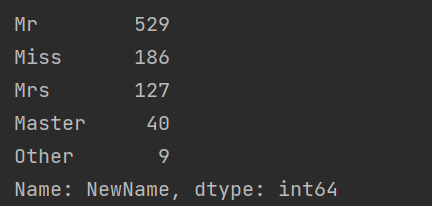
- 平均年龄:
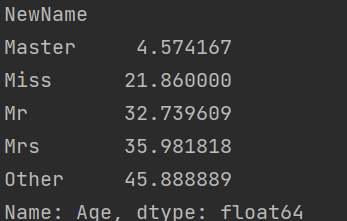
- 填补过程:计算出均值:
 港口确实填充:
港口确实填充: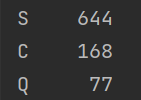
- 编码输出:
- 学习模型:
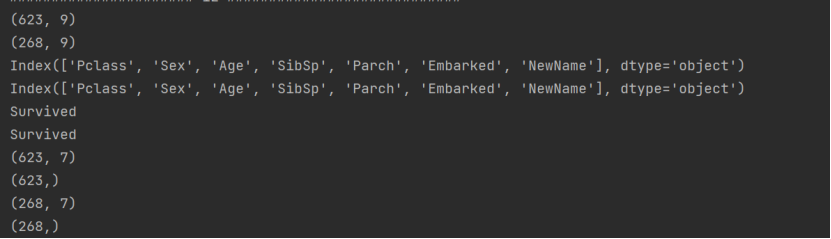
任务二、构建决策模型
2.1源代码
- 构建决策树
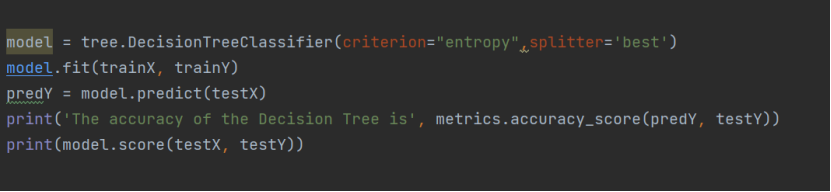
- 实现决策树的可视化
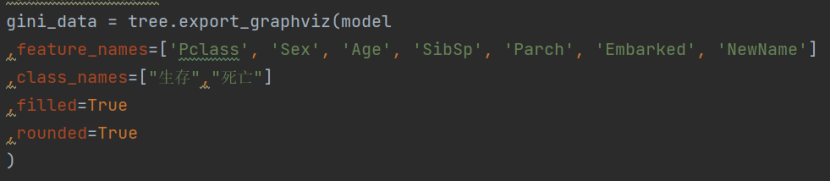

2.2实验结果与分析
决策树可视化结果:
精确的决策树信息

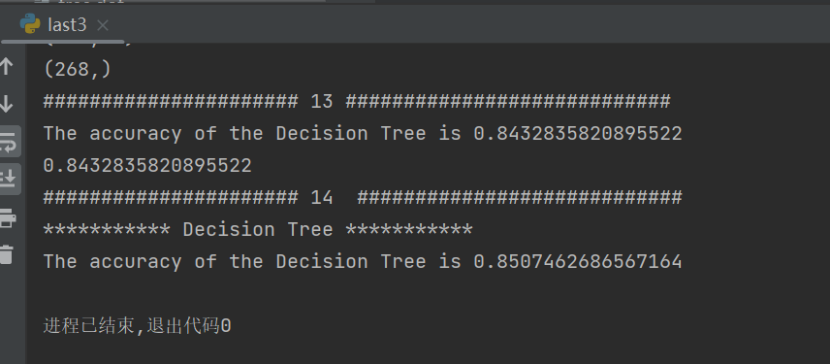
- 实验总结及注意事项
实验总结:特征工程的处理方法有数据预处理、特征提取,特征选择和特征降维,最后构建响应模型;特征提取方面,我们的数值类型可直接使用,时间序列需转成单独的年月日,分类数据可用数值代替类别one-hot编码。本次试验中也可以使用常用的数据挖掘手段对乘客的获救率进行预测。创建决策树时,构建模型中需建立和测试数据集,从而进行达到评估模型的结果。
注意事项:导入数据与训练数据集与前几次实验相通,本次的data明显类型复杂许多,并且在决策树建模过程,我们也可以通过交叉验证的方法有待学习,最后,在这次问题的分析方面,也可以通过后面的学习进行数据分析,使用决策函数进行预测。















,上传文件,后端插入数据,将文件保存到数据库)
)
——pinctrl GPIO)


