一·代码
import torch
print(torch.__version__) # 验证安装的开发环境是否正确'''
MNIST 包含 70,000 张手写数字图像;60,000 张用于训练,10,000 张用于测试。
图像是灰度的,28x28 像素的,并且居中的,以减少预处理和加快运行。
'''import torch
from torch import nn # 导入神经网络模块from torchvision import datasets # 封装了很多与图像相关的模型、及数据集
from torchvision.transforms import ToTensor # 数据转换、张量,将其他类型的数据转换为 tensor 张量,numpy array, dataframe'''下载训练数据集(包含训练图片 + 标签)'''
training_data = datasets.MNIST( # 跳转到函数内部源代码,pycharm 按 Ctrl + 鼠标点击root="data", # 表示下载的手写数字,到哪个路径,.60000train=True, # 表示下载后的数据集,里的,训练集download=True, # 如果你之前已经下载过了,就不用再下载transform=ToTensor() # 张量,图片是不能直接传入神经网络模型
) # 对于 pytorch 来说能够识别的数据一般是 tensor 张量'''下载测试数据集(包含训练图片 + 标签)'''
test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor() # Tensor 是在深度学习中被使用广泛的数据类型,它为深度学习框架(如 PyTorch、TensorFlow)紧密集成,方便进行神经网络的训练和推理。
) # 允许 CPU 和 GPU 运行,Tensor 可以在 GPU 上运行,这在深度学习应用中可以显著提升计算速度。print(len(training_data))# '''展示手写数字图片,把训练数据集中的前 59000 张图片展示一下'''
#
# from matplotlib import pyplot as plt
#
# figure = plt.figure()
# for i in range(9):
# img, label = training_data[i + 59000] # 提取第 59000 张图片
# figure.add_subplot(3, 3, i + 1) # 图像窗口中创建多个小窗口、小窗口用于展示图片
# plt.title(label)
# plt.axis("off") # plt.show() 才显示矢量
# plt.imshow(img.squeeze(), cmap="gray") # plt.imshow() 函数来将数组(data)中的数据显示为图像,并在图形窗口中显示图像
# a = img.squeeze() # img.squeeze() 从张量 img 中去掉维度为 1 的,如果该维度的大小不为 1 则张量不会改变。cmap="gray" 表示使用灰度色彩映射来显示图像,这意味着图像将以灰度模式显示
# plt.show()
# '''创建数据DataLoader(数据加载器)
# batch_size:将数据集分成多份,每一份为batch_size个数据。
# 优点:可以减少内存的使用,提高训练速度。
# '''
from torch.utils.data import DataLoader # 数据管理工具,打包数据
train_dataloader = DataLoader(training_data, batch_size=64)#64张图片为一个包,1、损失函数2、GPU一次性接受的图片个数
test_dataloader = DataLoader(test_data, batch_size=64)
for X, y in test_dataloader:#X是表示打包好的每一个数据包print(f"Shape of X [N, C, H, W]: {X.shape}")#print(f"Shape of y: {y.shape} {y.dtype}")break# 判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU。 '''#返回cuda, mps. CPU m1 , m2 菜显CPU+GPU RTX3060,
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")#字符串的格式化。 CUDA驱动软件的功能: pytorch能够去执行cuda的命令, cuda通过GPU指令集去控制GPU
# #神经网络的模型也需传入到GPU,1个batchsize的数据集也需要传入到GPU,才可以进行训练。''' 定义神经网络 类的继承这种方式'''
class NeuralNetwork(nn.Module):#通过调用类的形式来使用神经网络,神经网络的模型,nn.moduledef __init__(self):#python基础关于类,self类自己本身super().__init__()#继承的父类初始化self.flatten = nn.Flatten()#展开,创建一个展开对象flattenself.hidden1 = nn.Linear(28*28, 128)#第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去前一层神经元的个数,当前本self.hidden2 = nn.Linear(128, 256)#为什么你要用128self.out = nn.Linear(256, 10)#输出必需和标签的类别相同,输入必须是上一层的神经元个数def forward(self, x): #前向传播,你得告诉它 数据的流向。是神经网络层连接起来,函数名称不能改。当你调用forward函数的时候,传入进来的x = self.flatten(x) #图像进行展开x = self.hidden1(x)x = torch.relu(x) #激活函数,torch使用的relu函数 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return xmodel = NeuralNetwork().to(device)
print(model)# 训练函数
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)loss = loss_fn(pred, y)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()if batch_size_num % 100 == 0:print(f"loss: {loss_value}?f [number: {batch_size_num}]")batch_size_num += 1# 测试函数(示例,可补充完整测试指标计算等逻辑)
def test(dataloader, model, loss_fn):passloss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 执行训练
train(train_dataloader, model, loss_fn, optimizer)
class NeuralNetwork(nn.Module):#通过调用类的形式来使用神经网络,神经网络的模型,nn.moduledef __init__(self):#python基础关于类,self类自己本身init初始化代码,
''' 定义神经网络 类的继承这种方式'''
class NeuralNetwork(nn.Module):#通过调用类的形式来使用神经网络,神经网络的模型,nn.moduledef __init__(self):#python基础关于类,self类自己本身super().__init__()#继承的父类初始化self.flatten = nn.Flatten()#展开,创建一个展开对象flattenself.hidden1 = nn.Linear(28*28, 128)#第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去前一层神经元的个数,当前本self.hidden2 = nn.Linear(128, 256)#为什么你要用128self.out = nn.Linear(256, 10)#输出必需和标签的类别相同,输入必须是上一层的神经元个数def forward(self, x): #前向传播,你得告诉它 数据的流向。是神经网络层连接起来,函数名称不能改。当你调用forward函数的时候,传入进来的x = self.flatten(x) #图像进行展开x = self.hidden1(x)x = torch.relu(x) #激活函数,torch使用的relu函数 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x
def __init__(self):#python基础关于类,self类自己本身super().__init__()#继承的父类初始化self.flatten = nn.Flatten()#展开,创建一个展开对象flattenself.hidden1 = nn.Linear(28*28, 128)#第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去前一层神经元的个数,当前本self.hidden2 = nn.Linear(128, 256)#为什么你要用128self.out = nn.Linear(256, 10)#输出必需和标签的类别相同,输入必须是上一层的神经元个数这里是对象层没有开始操作
def forward(self, x): #前向传播,你得告诉它 数据的流向。是神经网络层连接起来,函数名称不能改。当你调用forward函数的时候,传入进来的x = self.flatten(x) #图像进行展开x = self.hidden1(x)x = torch.relu(x) #激活函数,torch使用的relu函数 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x这个是开始操作数据的
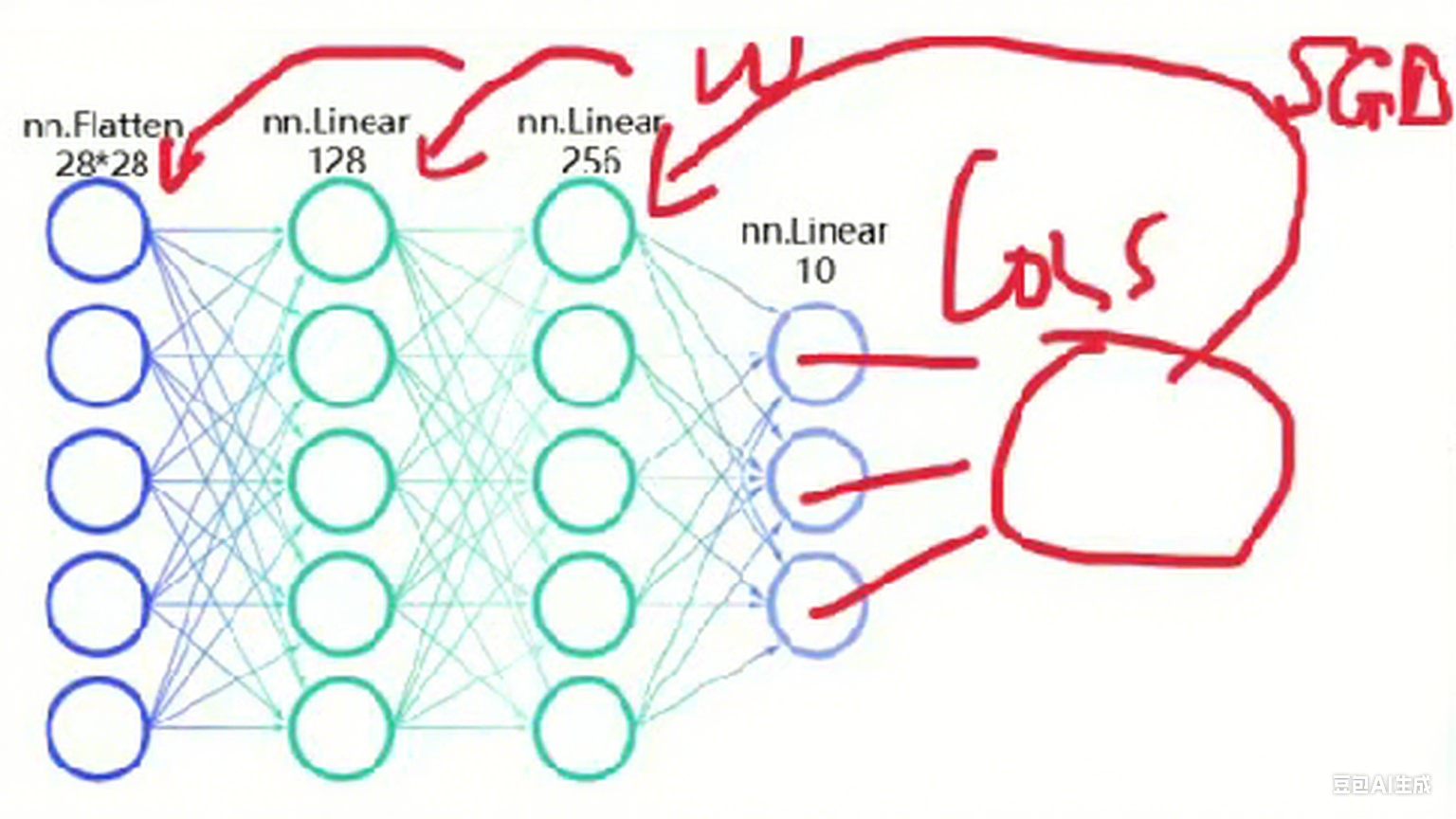
目前为止书接上回网络搭建任务二就完成了
这样的网络搭建就完成了
训练的方法就是构建一个损失函数来方向更新w权重,以及反向更新用什么方法来反向更新
loss_fn = nn.CrossEntropyLoss()
# #L1Loss: L1损失,也称为平均绝对误差(Mean Absolute Error, MAE)。它计算预测值与真实值之间的绝对差值的平均值。
# NLLLoss: 负对数似然损失(Negative Log Likelihood Loss)。它用于多分类问题,通常与LogSoftmax输出层配合使用。
# NLLLoss2d: 这是NLLLoss的一个特殊版本,用于处理2D图像数据。在最新版本的PyTorch中,这个损失函数可能已经被整合到NLL
# PoissonNLLLoss: 泊松负对数似然损失,用于泊松回归问题。
# GaussianNLLLoss: 高斯负对数似然损失,用于高斯分布(正态分布)的回归问题。
# KLDivLoss: Kullback-Leibler散度损失,用于度量两个概率分布之间的差异。
# #MSELoss: 均方误差损失(Mean Squared Error Loss),计算预测值与真实值之间差值的平方的平均值。
# #BCELoss: 二元交叉熵损失(Binary Cross Entropy Loss),用于二分类问题。
# BCEWithLogitsLoss: 结合了Sigmoid激活函数和二元交叉熵损失的损失函数,用于提高数值稳定性。
# HingeEmbeddingLoss: 铰链嵌入损失,用于学习非线性嵌入或半监督学习。
# MultiLabelMarginLoss: 多标签边际损失,用于多标签分类问题。
# SmoothL1Loss: 平滑L1损失,是L1损失和L2损失(MSE)的结合,旨在避免梯度爆炸问题。
# HuberLoss: Huber损失,与SmoothL1Loss类似,但有一个可调的参数来控制L1和L2损失之间的平衡。
# SoftMarginLoss: 软边际损失,用于二分类问题,可以看作是Hinge损失的一种软化版本。
# CrossEntropyLoss: 交叉熵损失,用于多分类问题。它结合了LogSoftmax和NLLLoss的功能。
# MultiLabelSoftMarginLoss: 多标签软边际损失,用于多标签二分类问题。
# CosineEmbeddingLoss: 余弦嵌入损失,用于学习非线性嵌入,通过余弦相似度来度量样本之间的相似性。
# MarginRankingLoss: 边际排序损失,用于排序问题,如学习到排序的嵌入空间。
# MultiMarginLoss: 多边际损失,用于多分类问题,旨在优化分类边界的边际。
# TripletMarginLoss: 三元组边际损失,用于学习嵌入空间中的距离度量,通常用于人脸识别或图像检索等任务。
# TripletMarginWithDistanceLoss: 这是TripletMarginLoss的一个变体,允许使用自定义的距离函数。
# CTCLoss: 连接时序分类损失(Connectionist Temporal Classification Loss),用于序列到序列的学习问题
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)优化算法,这里的model是前面定义的类
model = NeuralNetwork().to(device)
print(model)下面的是优化器的一些函数
from . import swa_utils as swa_utils
from . import lr_scheduler as lr_scheduler
from .adadelta import Adadelta as Adadelta
from .adagrad import Adagrad as Adagrad
from .adam import Adam as Adam
from .adamax import Adamax as Adamax
from .adamw import AdamW as AdamW
from .asgd import ASGD as ASGD
from .lbfgs import LBFGS as LBFGS
from .nadam import NAdam as NAdam
from .optimizer import Optimizer as Optimizer
from .radam import RAdam as RAdam
from .rmsprop import RMSprop as RMSprop
from .rprop import Rprop as Rprop
from .sgd import SGD as SGD
from .sparse_adam import SparseAdam as SparseAdam
这个就是输出的结果进行损失函数反向更新通过SGD的方法来更新权重
train(train_dataloader, model, loss_fn, optimizer)#训练1次完整的数据,多轮训练,
test(test_dataloader, model, loss_fn)这个里开始训练然后就是调取前面的函数
# 训练函数
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)loss = loss_fn(pred, y)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()if batch_size_num % 100 == 0:print(f"loss: {loss_value}?f [number: {batch_size_num}]")batch_size_num += 1pred = model.forward(X)执行上面的代码
def forward(self, x): #前向传播,你得告诉它 数据的流向。是神经网络层连接起来,函数名称不能改。当你调用forward函数的时候,传入进来的x = self.flatten(x) #图像进行展开x = self.hidden1(x)x = torch.relu(x) #激活函数,torch使用的relu函数 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x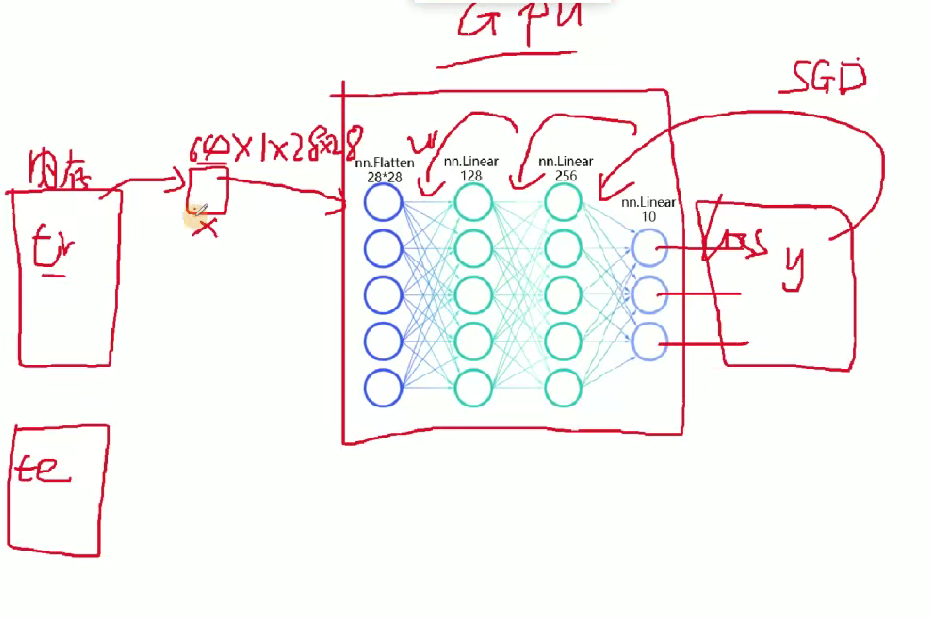
计算机会自动搭建64个这样的网络,然后64张图片分别进行前向传播得到输出预测结果,然后在计算损失值,然后和loss比较求和平均更新w的权重
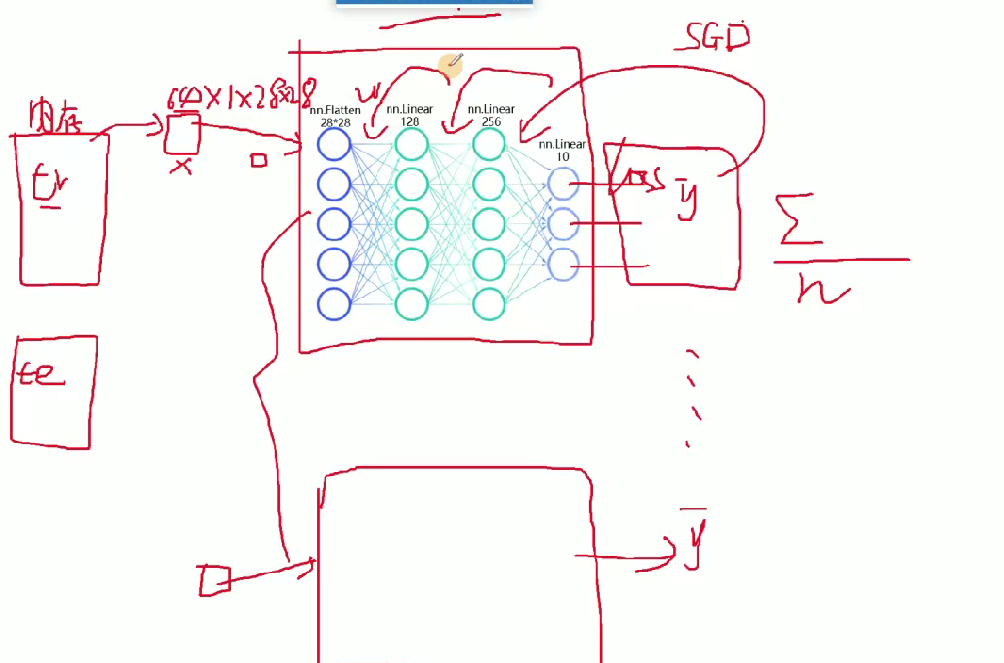
这里使用交叉熵损失函数
loss = loss_fn(pred, y)这里进行权重更新
optimizer.zero_grad() # 梯度值清零
loss.backward() # 反向传播计算得到每个参数的梯度值w
optimizer.step() # 根据梯度更新网络w参数
def test(dataLoader, model, loss_fn): # dataLoader: <torch.utils.data.dataloader.DataLoader object at 0x00000260size = len(dataLoader.dataset)#10000 # 获取数据集的总样本数量,这里标注了数量是10000num_batches = len(dataLoader)#打包的数量 # 获取数据加载器的批次数,即打包后的数量model.eval() #测试,w就不能再更新。 # 将模型设置为评估模式,此时模型参数不会被更新test_loss, correct = 0, 0 # 初始化测试损失和正确预测的数量with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存 # 关闭梯度计算,减少内存使用,因为测试阶段不需要反向传播for X, y in dataLoader: # 遍历数据加载器中的每个批次数据X, y = X.to(device), y.to(device) # 将数据和标签移动到指定设备(CPU或GPU)pred = model.forward(X) # 模型前向传播,得到预测结果test_loss += loss_fn(pred, y).item() #test_loss是会自动累加每一个批次的损失值 # 累加每个批次的损失值,item()将张量转换为Python数值correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累加正确预测的数量,先比较预测和真实标签,转换为浮点型后求和再转换为Python数值a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号 # 记录预测与真实标签是否匹配的布尔值,解释了argmax参数dim=1的含义b = (pred.argmax(1) == y).type(torch.float) # 将上述布尔值转换为浮点型张量test_loss /= num_batches #能来衡量模型测试的好坏。 # 计算平均每个批次的测试损失,用于衡量模型测试表现correct /= size #平均的正确率 # 计算平均正确率,即正确预测数占总样本数的比例
with torch.no_grad(): #一个上下文管理器上下文管理器,能自动检测当前打开的文件,在反向传播计算的过程中会产生大量的临时数据,不要的话就清理掉了
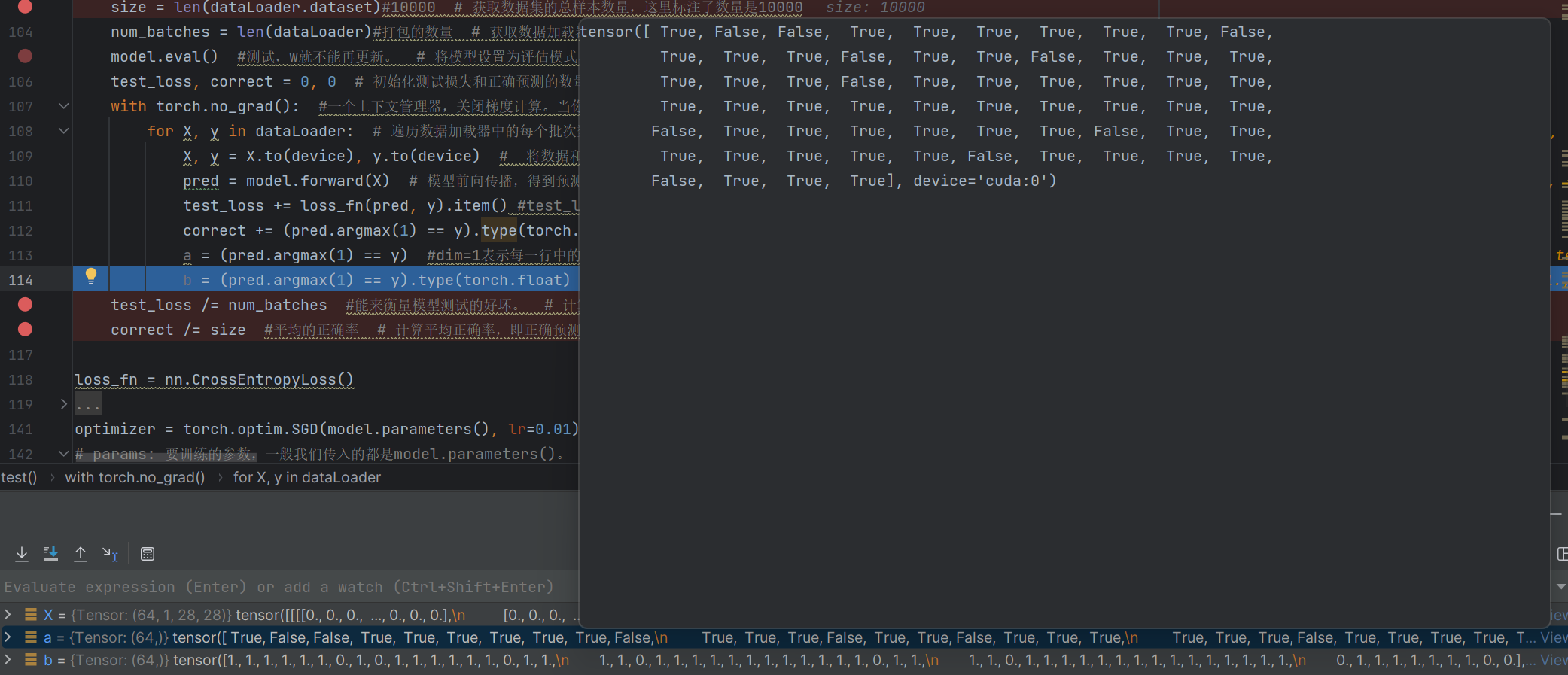
a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号 # 记录预测与真实标签是否匹配的布尔值,解释了argmax参数dim=1的含义
b = (pred.argmax(1) == y).type(torch.float) # 将上述布尔值转换为浮点型张量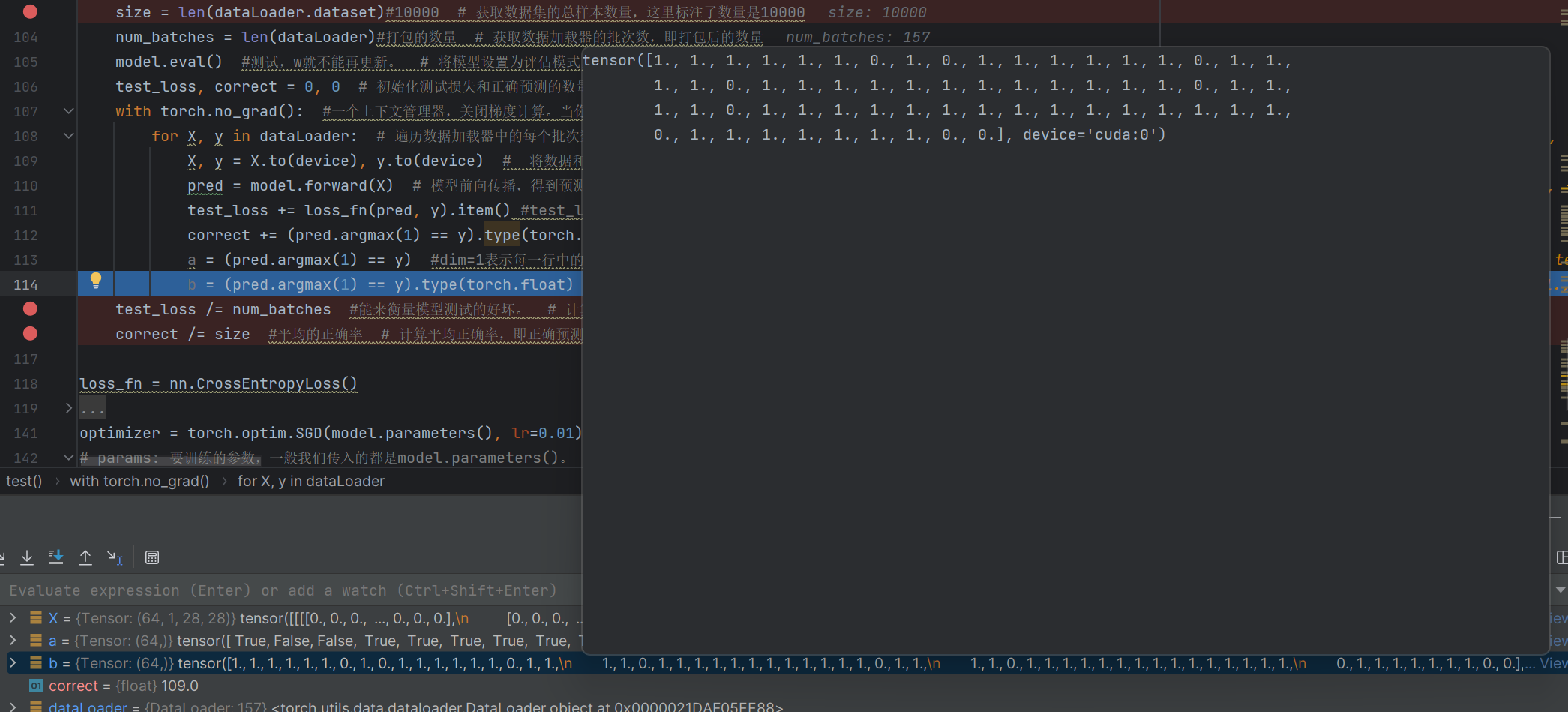
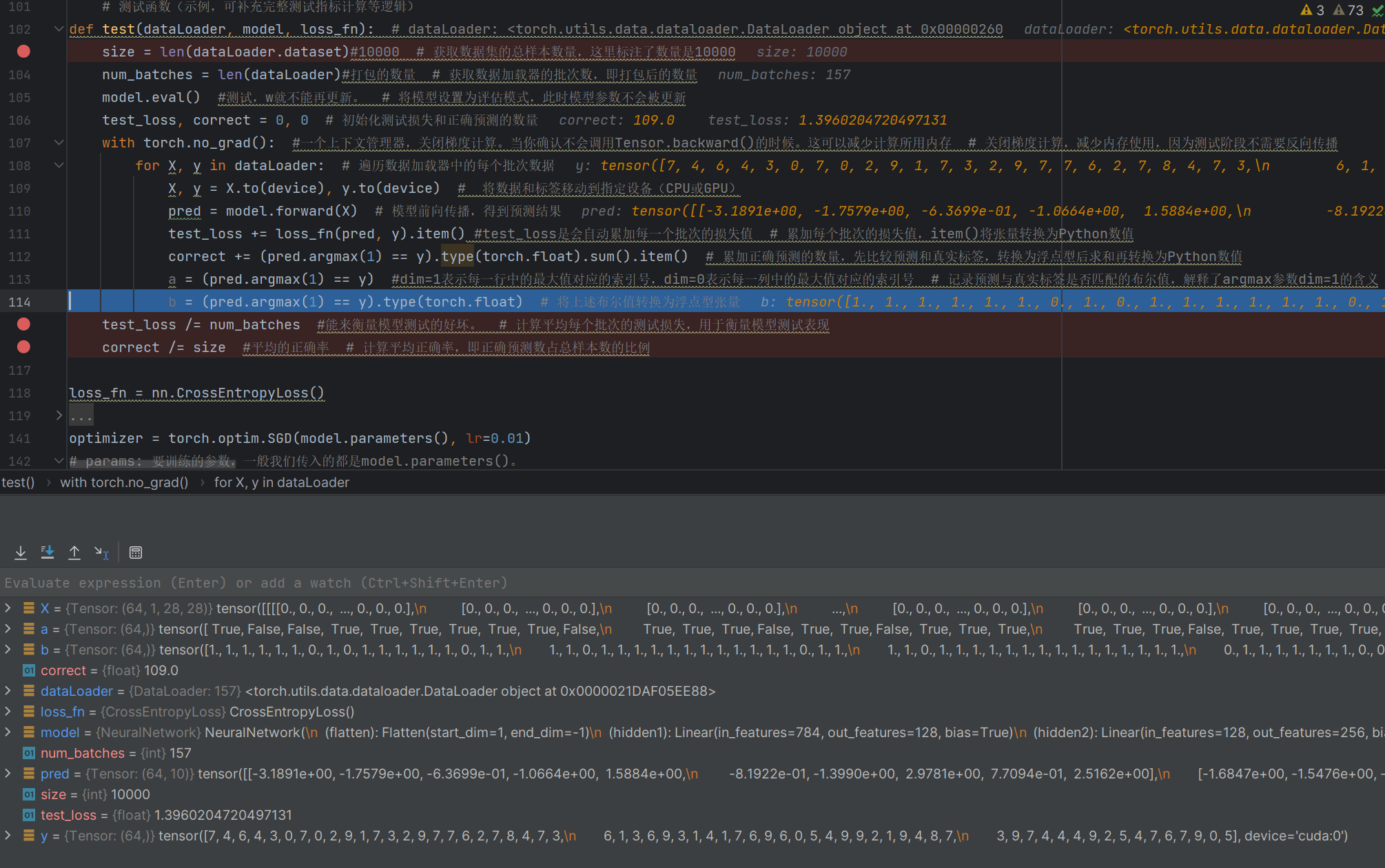
这里的correct是判断出了对了109个
# 定义训练的轮数(epoch),即整个训练数据集会被模型学习多少遍
# 这里设置为 10,注释里也提出了疑问“到底选择多少呢?”,实际需根据数据集、模型等情况调整
epochs = 10 #到底选择多少呢?# 循环执行多轮训练,轮数由上面定义的 epochs 决定
for t in range(epochs):# 打印当前轮次信息,t 从 0 开始,所以用 t+1 展示人类习惯的“第 1 轮、第 2 轮”等print(f"Epoch {t+1}\n-------------------------------")# 调用训练函数,将训练数据加载器、模型、损失函数、优化器传入,执行一轮训练# 注释里说明“10 次训练”,对应 epochs 为 10 时会循环调用训练 10 次train(train_dataloader, model, loss_fn, optimizer)#10次训练# 当所有轮次的训练都完成后,打印 “Done!” 提示训练结束
print("Done!")
# 调用测试函数,传入测试数据加载器、模型、损失函数,对训练好的模型进行测试评估
test(test_dataloader, model, loss_fn)后面
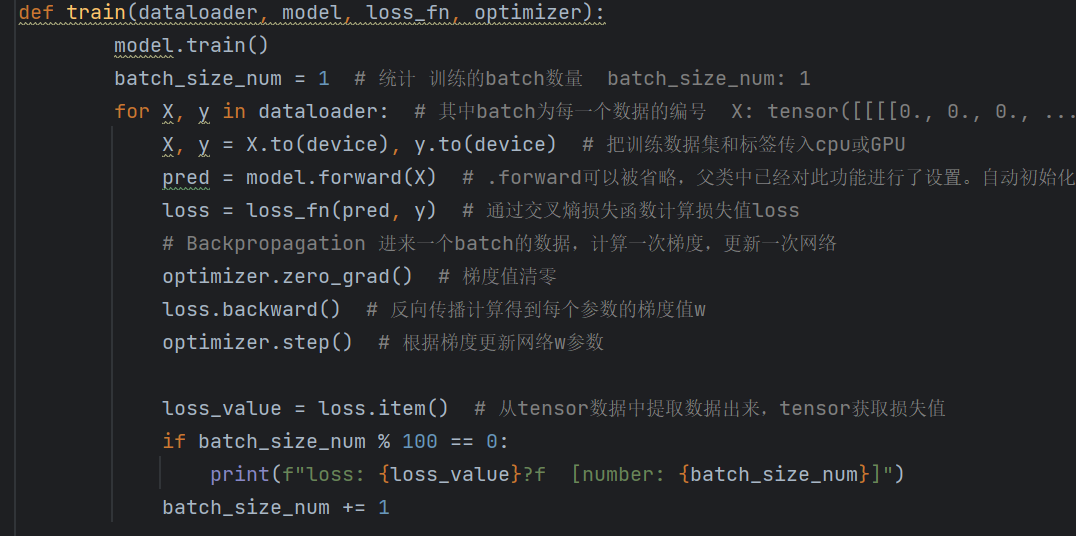
if batch_size_num % 100 == 0:print(f"loss: {loss_value}?f [number: {batch_size_num}]")这里100批次来计算损失函数
二.改进
原本的代码进行的运算太慢了需要改进
# 计划分析 sigmoid 函数和 relu 函数,这里拼写可能有误,正确一般是 sigmoid
###分析sigmiod, relu
# 计划分析随机梯度下降(sgd)优化器和 Adam 优化器
### sgd, Adam 优化器
- 批量梯度下降法(Batch Gradient Descent)BGD
使用全样本数据计算梯度,例如一个 batch_size=64,计算出 64 个梯度值
好处:收敛次数少。坏处:每次迭代需要用到所有数据,占用内存大耗时大。 - 随机梯度下降法(Stochastic Gradient Descent)
从 64 个样本中随机抽出一组,训练后按梯度更新一次
优点:速度快。缺点:可能陷入局部最优,搜索起来比较盲目,并不是每次都朝着最优的方向 - 小批量梯度下降法(Mini-batch Gradient Descent)
将训练数据集分成小批量用于计算模型误差和更新模型参数。是批量梯度下降法和随机梯度下降法的结合。 - 自适应矩估计 (Adaptive Moment Estimation) Adam
- 动量梯度下降(Momentum Gradient Descent)
- AdaGrad
- RMSprop
- AdamW
- Adadelta
下面就是一些优化器函数
from . import swa_utils as swa_utils
from . import lr_scheduler as lr_scheduler
from .adadelta import Adadelta as Adadelta
from .adagrad import Adagrad as Adagrad
from .adam import Adam as Adam
from .adamax import Adamax as Adamax
from .adamw import AdamW as AdamW
from .asgd import ASGD as ASGD
from .lbfgs import LBFGS as LBFGS
from .nadam import NAdam as NAdam
from .optimizer import Optimizer as Optimizer
from .radam import RAdam as RAdam
from .rmsprop import RMSprop as RMSprop
from .rprop import Rprop as Rprop
from .sgd import SGD as SGD
from .sparse_adam import SparseAdam as SparseAdam
但也会有限制这个限制就是步长
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)下一步就是优化激活函数
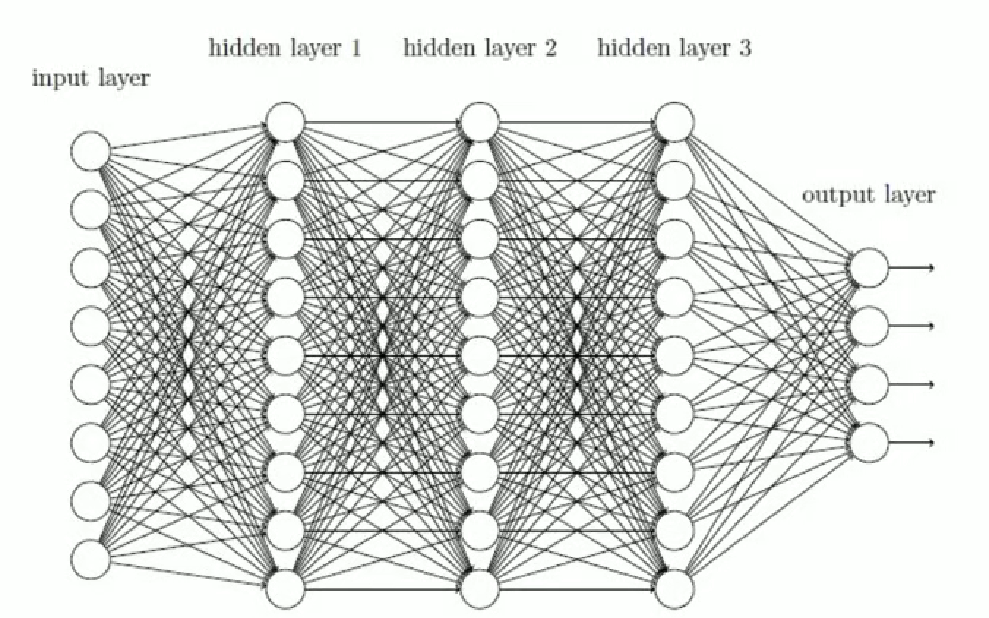

梯度消失
如果连乘的因子大部分小于 1,最后乘积的结果可能趋于 0,也就是梯度消失,后面的网络层的参数不发生变化.
梯度爆炸
如果连乘的因子大部分大于 1,最后乘积可能趋于无穷,这就是梯度爆炸
造成原因:
梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑下方
案解决:
用 ReLU、tanh、P - ReLU、R - ReLU、Maxout 等替代 sigmoid 函数。
ReLU

需要多层隐含层,才会奏效
def forward(self, x): #前向传播,你得告诉它 数据的流向。是神经网络层连接起来,函数名称不能改。当你调用forward函数的时候,传入进来的x = self.flatten(x) #图像进行展开x = self.hidden1(x)x = torch.relu(x) #激活函数,torch使用的relu函数 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x



网络编程:TCP 机制与 HTTP 协议)
![[element-plus] el-table在行单击时获取行的index](http://pic.xiahunao.cn/[element-plus] el-table在行单击时获取行的index)

——查询构建、Text2SQL、查询重构与分发)
)






:plt.imshow() - 绘制矩阵与图像的强大工具)

)

)