管道架构概述
RAG 管道由多个处理阶段组成,这些阶段将文本内容转换为适合智能检索的结构化知识表示:
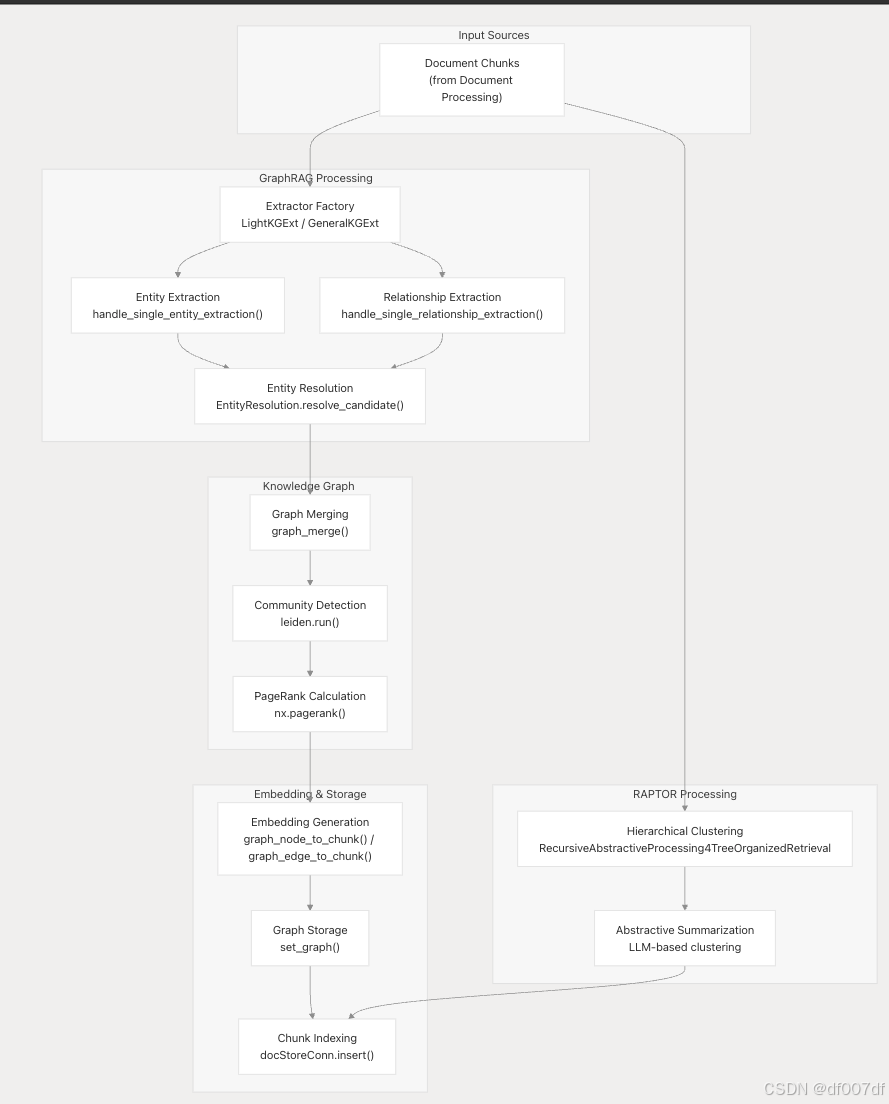
文档到知识图谱工作流程
主要处理工作流程通过 run_graphrag 功能将单个文档块转换为统一的知识图谱:
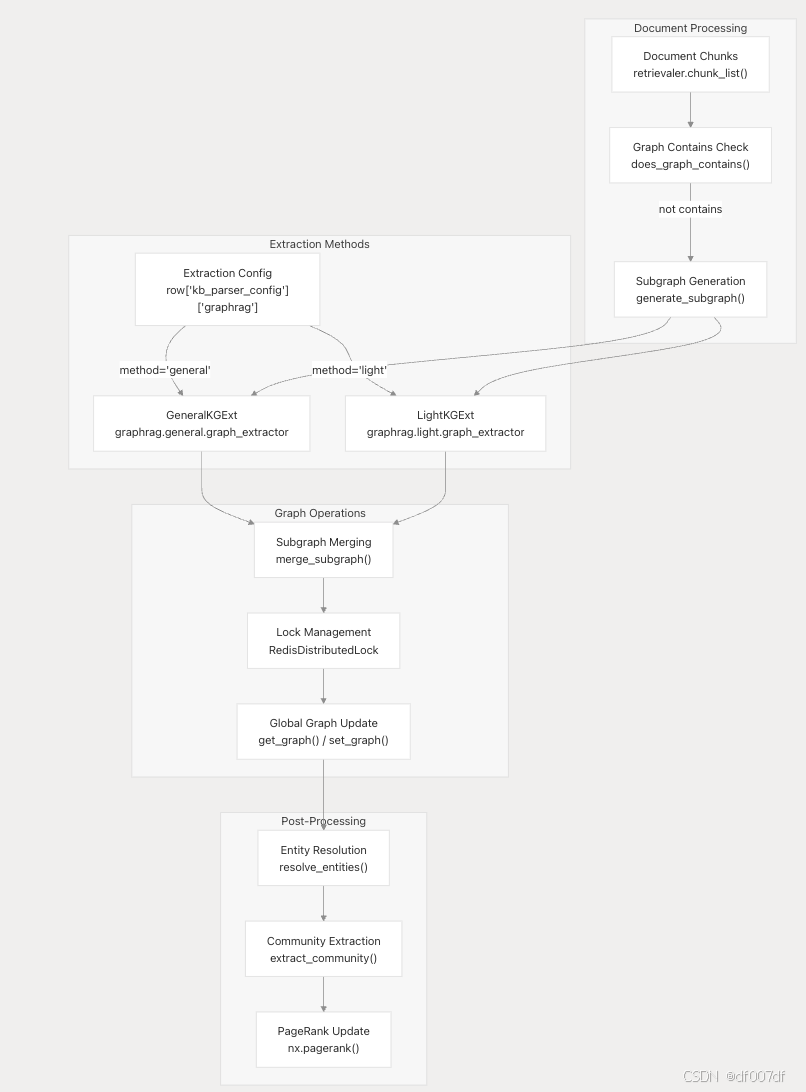
GraphRAG 处理方法
RAGFlow 支持两种不同的 GraphRAG 提取方法,每种方法都针对不同的用例进行了优化:
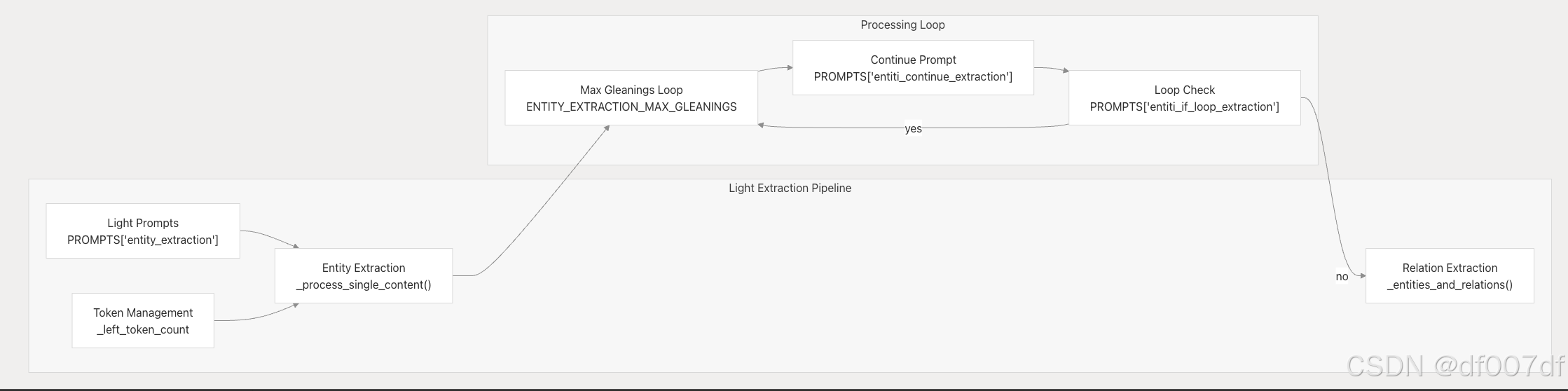
Light GraphRAG 方法
Light 方法使用简化的基于提示的方法来加快处理速度:
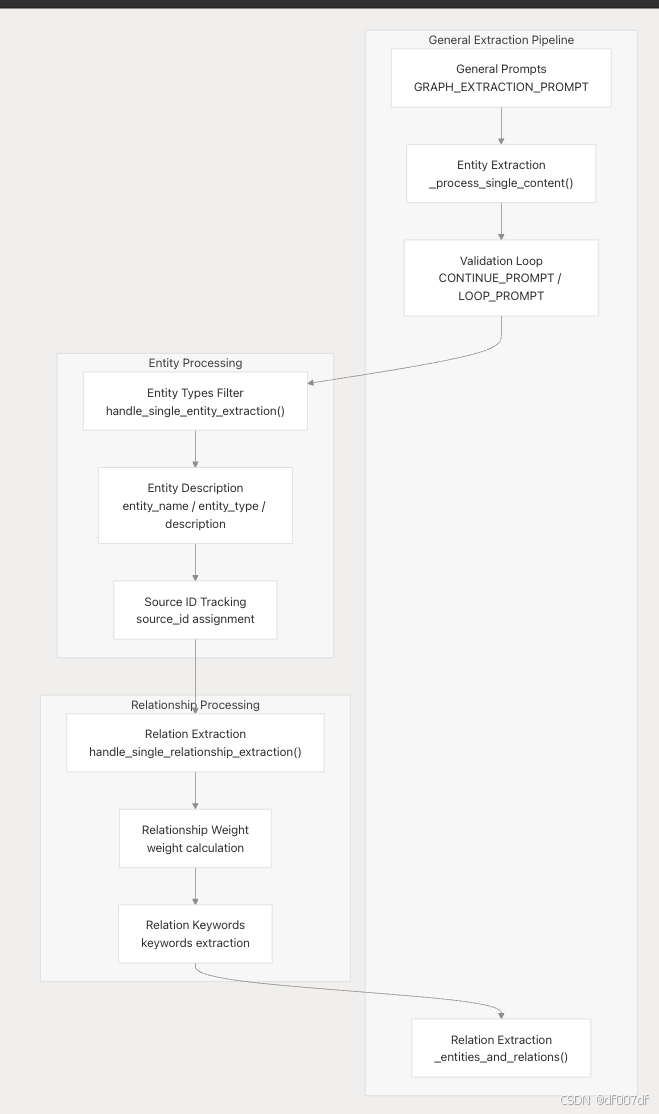
通用 GraphRAG 方法
常规方法通过多个验证步骤提供更全面的提取:
实体解析和图形合并
实体解析过程使用基于 LLM 的相似性分析来识别和合并重复实体:
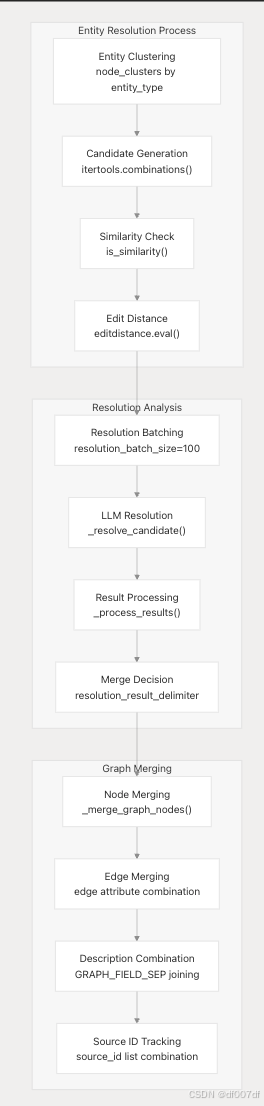
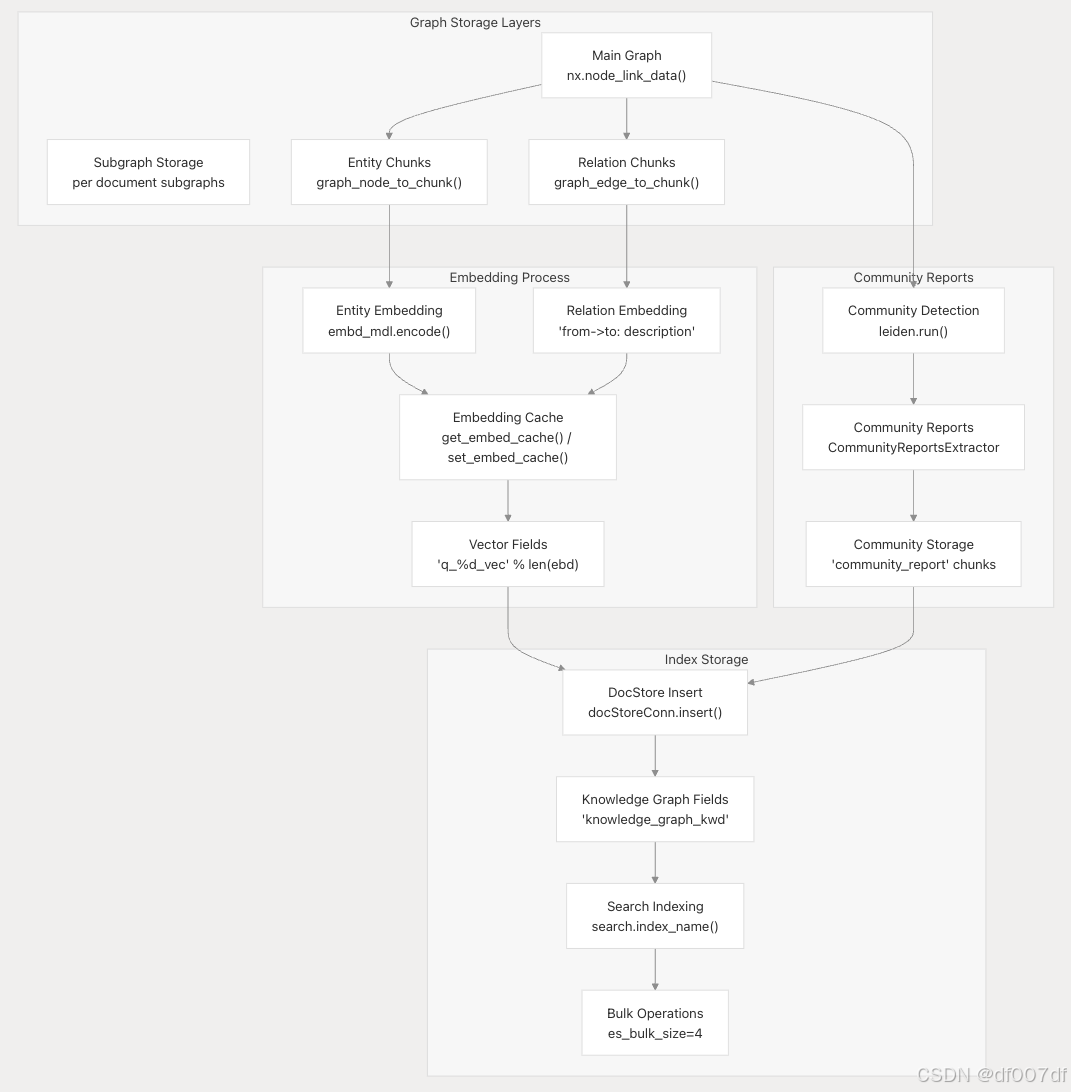
知识图谱存储和索引
处理后的知识图谱以多层格式存储,支持图和向量运算:
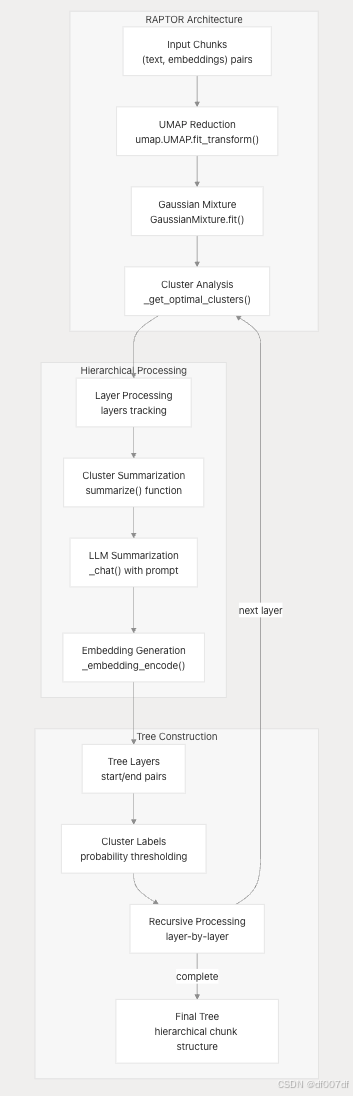
RAPTOR 分层处理
RAPTOR(用于树组织检索的递归抽象处理)提供分层聚类和总结:
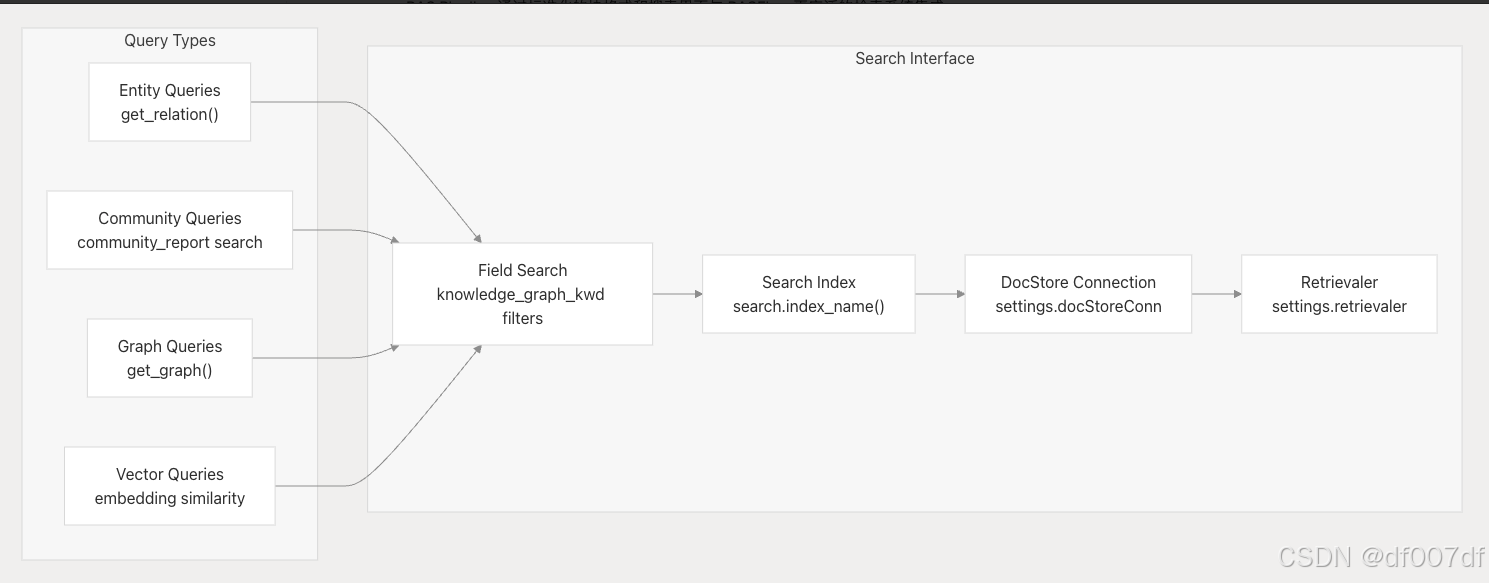
与检索系统集成
RAG Pipeline 通过标准化的块格式和搜索界面与 RAGFlow 更广泛的检索系统集成:
| 元件 | 积分点 | 数据格式 |
|---|---|---|
| 知识图谱实体 | knowledge_graph_kwd: “entity” | entity_kwd、entity_type_kwd、content_with_weight |
| 知识图谱关系 | knowledge_graph_kwd: “relation” | from_entity_kwd、to_entity_kwd、weight_int |
| 社区报告 | knowledge_graph_kwd: “community_report” | entities_kwd、weight_flt、docnm_kwd |
| 图结构 | knowledge_graph_kwd: “graph” | NetworkX 序列化为 JSON |
| 猛禽摘要 | 标准块格式 | 分层嵌入向量 |
管道支持通过多种查询模式进行检索:



:Visual Studio(IDE) VS Visual Studio Code)
)
免安装中文版)





)





)

)