一、逻辑存储结构
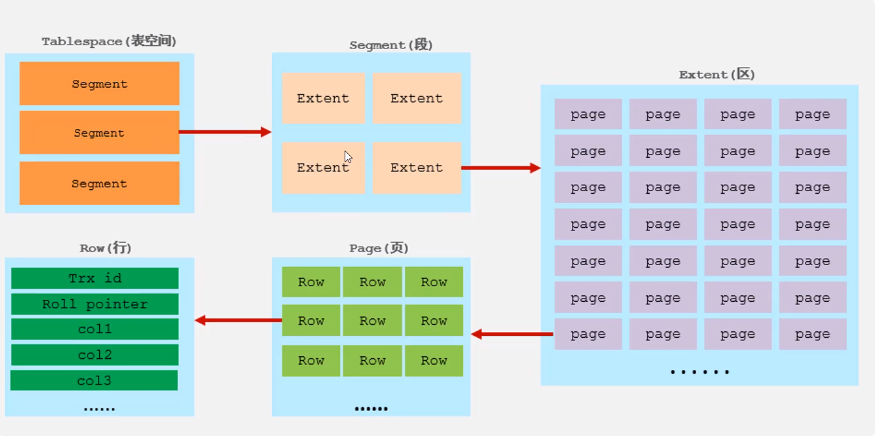
(1)表空间(ibd文件):一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
cd /var/lib/mysql
(2)段,分为数据段(leaf node segment)、索引段(non-leaf node segment)、回滚段(rollback segment),InnoDB是索引组织表,数据段就是B+树的非叶子节点。段用来管理多个extent(区)。
(3)区,表空间的单元结构,每个区的大小为1M,默认情况下,InnoDB存储引擎页大小为16K,即一个区中一共有64个连续的页。
(4)页,是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎每次从磁盘申请4-5个区。
(5)行,InnoDB存储引擎数据是按行进行存放的。

二、架构
1、架构图
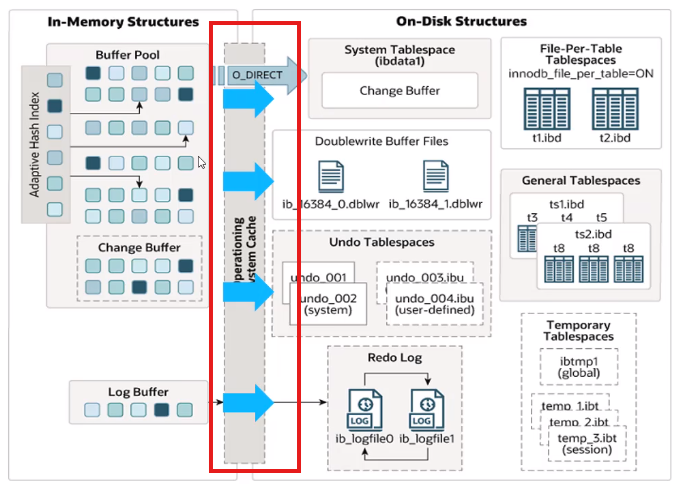
MySQL5.5版本开始,默认使用InnoDB存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发中使用非常广泛。
InnoDB架构图,左侧内存结构,右侧磁盘结构。
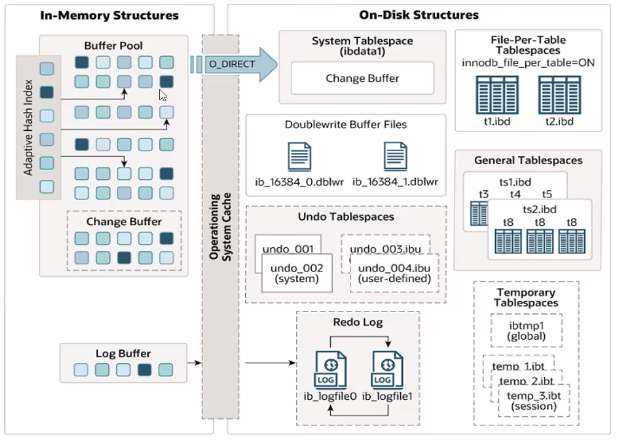
2、内存结构
(1)buffer pool:缓冲池


dirty page:缓冲区的页还没有刷新到磁盘上。
(2)change buffer:更改缓冲区
对唯一索引和主键索引不会操作更改缓冲区。

在执行增删改语句时,不是直接操作到磁盘,而是将数据变更存放在更改缓冲区,再以一定频率将将数据放入缓冲池,再刷新到磁盘中。

(3)log buffer:日志缓冲区


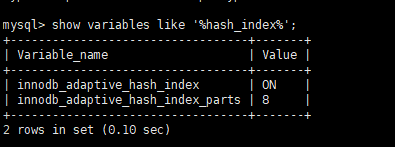
(4)adaptive hash index:自适应哈希索引
InnoDB默认不支持哈希索引,默认B+索引。哈希索引不支持范围查询,支持等值匹配。

3、磁盘结构
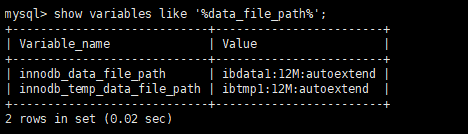
(1)system tablespace:系统表空间

参数:innodb_data_file_path
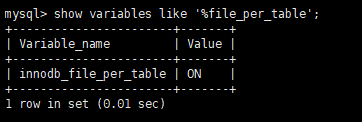
(2)file-per-table tablespaces(每张表独立的表空间)
![]()
参数:innodb_file_per_table
(3)general tablespaces(通用表空间)
需要通过create tablespace语法创建通用表空间,在创建表时,可以指定该表空间。
语法:
create tablespace xxx add datafile ·file_name· engine = engine_name;
create table xxx tablespace ts_name;

cd /var/lib/mysql
(4)undo tablespace:撤销表空间
![]()
![]()
(5)temporary tablespace:临时表空间
![]()
(6)doublewrite buffer files:双写缓冲区

![]()
(7)redo log:重做日志

以循环方式写入重做日志文件,涉及两个文件:
![]()
4、后台线程
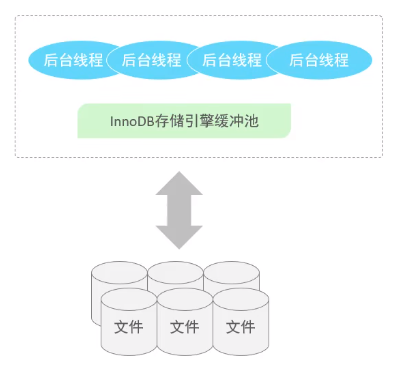
后台线程:在合适的时机,将InnoDB存储引擎缓冲池中的数据刷新到磁盘文件中。
(1)master thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
(2)IO Thread
在InnoDB存储引擎中大量使用了AIO来处理IO请求,可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
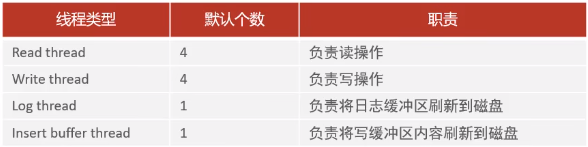
(3)Purge Thread
主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
(4)page cleaner thread
协助master thread刷新脏页到磁盘的现场,它可以减轻master thread的工作压力,减少阻塞。
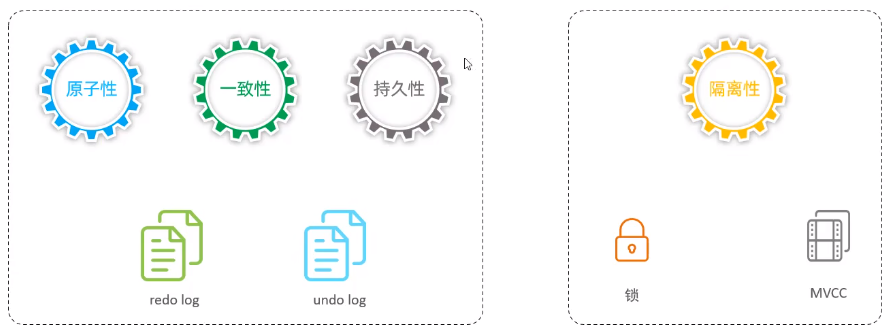
三、事务原理
1、事务原理概述
事务特性:

2、redo log:重做日志
redo log实现持久性

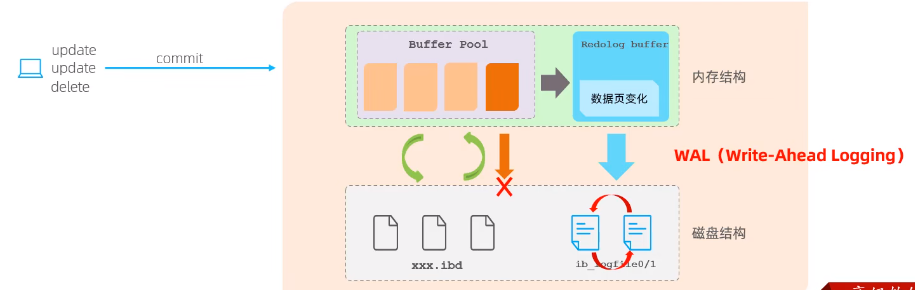
当客户端发起事务操作时,先操作缓冲区,在缓冲区查找是否有我们要操作的数据,没有数据则通过后台线程去磁盘读取该数据,缓存在缓冲区中,进行增删改操作后,将增删改的数据直接写入redo log buffer,记录数据页变化,然后直接将其刷新在磁盘文件redo log file内。过段时间进行脏页刷新时,若程序出错,可通过redo log进行恢复。
为WAL(write-ahead logging)先写日志
每隔一段时间会清理redo log file,因此,这两个文件是循环写的。
3、undo log:回滚日志(Ctrl+Z)
undolog实现原子性

在进行update操作时,undo log记录更新前的数据。
undo log销毁:当我们在进行回滚操作后,undo log就没有用了,会进行销毁,但不会立即删除,因为还有可能用于MVCC(多版本并发控制)。
4、MVCC(多版本并发控制)
(1)基本概念
①当前读:
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:select ... lock in share mode(共享锁),select ... for update、update、insert、delete(排他锁)都是一种当前读。
演示:
开启两个客户端,在第一个客户端执行select * from student;
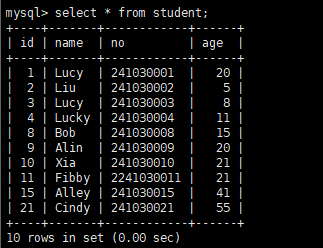
在第二个客户端执行update操作:
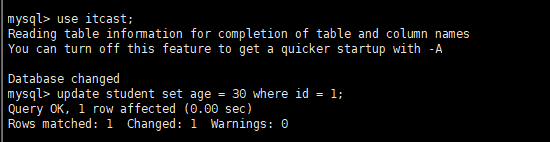
此时在第一个客户端执行select * from student;无法查询到更新后的数据,第二个客户端commit;后也无法查询到更新后的语句,要读取最新的数据,即当前读,要执行select * from student lock in share mode;
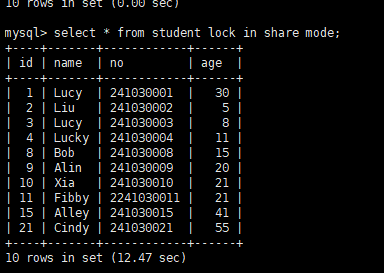
②快照读

前文在第一个客户端执行select * from student;无法查询到更新后的数据,第二个客户端commit;后也无法查询到更新后的语句,即为快照读。
repeatable read:
在一个事务中第一次执行select * from student;为快照读的地方,后面执行的select * from student为读取前面的快照数据。
③MVCC(multi-version concurrency control)

三个隐式字段、undo log、readview
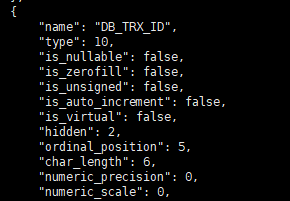
(2)MVCC-隐式字段
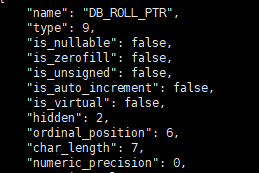
创建了一张表,含三个字段id、age、name,在InnoDB引擎中还会增加三个字段
![]()

使用ibd2sdi student.ibd查询表结构
可以看到两个隐式字段,由于这张表有主键,第三个隐式字段不会被自动创建
(3)MVCC-undo log

有数据如下所示:

要执行下面的事务:
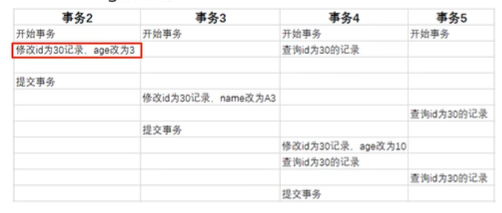
首先要执行事务2,update操作,现在undo log日志中记录更新前的数据:

然后再修改数据;


同理执行事务2:

执行事务3:

undo log版本链:

(4)MVCC-readview
读取记录由readview决定



(5)MVCC-RC级别
每一次执行快照读时生成readview
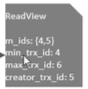
分析事务5:
当第一次执行查询id为30的记录时,readview为如下所示:

由于事务2已经提交了,所以当前活跃事务为3,4,5
事务5要查询数据,快照读为他生成的,creator_trx_id=5

带入db_trc_id=4,都不行,沿着版本链带入db_trc_id=3,失败
带入=2时,满足第二条,查询到这条:
![]()
当第二次查询id为30的记录时,readview为如下所示:
依次带入:

查询到这条数据:
![]()
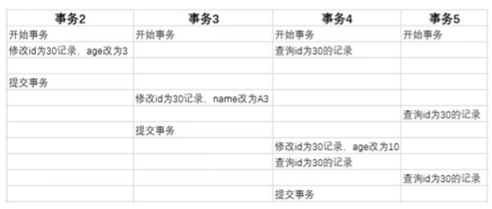
(6)MVCC-RR级别
RR隔离级别下,仅在事务第一次执行快照读时生成readview,后续复用该readview。
事务5中,两次查询id为30的记录,两次readview都如下所示:
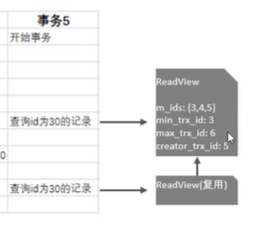
规则和上面一样,两次查询到的为:
![]()
- MTK mtk_drm_plane.c)


)









)
》)




![[Mysql数据库] 知识点总结5](http://pic.xiahunao.cn/[Mysql数据库] 知识点总结5)