本文整理自 2025 年 8 月 29 日百度云智大会 —— AI + 算力平台专题论坛,百度智能云 AI 计算首席科学家王雁鹏的同名主题演讲。
大家下午好!昨天在主论坛,我们正式发布了百度百舸 AI 计算平台 5.0,并展示了多项亮眼的性能数据。今天,我将从技术层面,与大家进行一次深度的探讨和解读。
百度百舸 4.0 发布的核心特性是支持十万卡集群的稳定训练,其能力主要围绕大规模训练场景构建。
过去一年,AI 技术的进展与落地速度前所未有,这使得我们的工作负载发生了根本性的变化。
我们正从以预训练为主的单一负载,进入了一个混合负载的新阶段。模型结构上,从传统的稠密 Dense 模型,发展到 MoE 模型、多模态模型为主。业务场景上,用户除了预训练需求,在线推理、SFT、强化学习等需求占比显著提升。
因此,百舸 5.0 进行了全面的升级:
在 AI 基础设施层面和资源管理层面,提供高性能的 AI 计算、AI 网络、AI 存储等产品,支持单一集群内高效的训推混部。
在 AI 工程层面,覆盖从数据准备、模型开发、模型训练和推理部署的 AI 全流程,提供端到端产品能力。
在模型加速层面,对 Dense、MoE 等各类开源热门模型均进行了深度性能加速,并以易用的产品化能力提供给客户,让加速能力可直接落地。
新出现的各类模型的迭代催生了新兴行业的爆发式增长,而大模型能力的持续跃升,进一步加速了 AI 技术在各行业的深度落地进程。
百舸平台精准衔接上层行业工具链,凭借一体化的技术和工程支撑能力,为具身智能、汽车智驾、电商等关键领域及场景赋能,有效降低 AI 应用门槛,助力相关行业加速实现 AI 技术的规模化落地与价值转化。
今天分享的核心,是过去一年最重要的变局 —— MoE 模型的兴起。
某种意义上,MoE 是延续 Scaling Law 的关键创新。如果继续使用 Dense 模型,参数量翻番带来的计算量将无法承受,Scaling Law 将难以为继。而 MoE 的逻辑是:仅激活部分专家层参与计算,在参数量翻倍的同时,计算量基本不变。这使得模型能力得以持续提升。
然而,MoE 架构给基础设施带来了巨大挑战:
参数量剧增:训练和推理从单机/单卡,走向大规模分布式集群。
通信量激增:计算量虽未大增,但通信量大幅提升,计算与通信的比率发生剧变。
系统复杂性提升:整个集群的构建和管理面临全新考验。
因此,要真正发挥 MoE 的优势,必须对基础设施进行一场全面的系统性升级。百舸 5.0 正是围绕这一目标,从芯片、框架到集群,进行全栈协同优化。

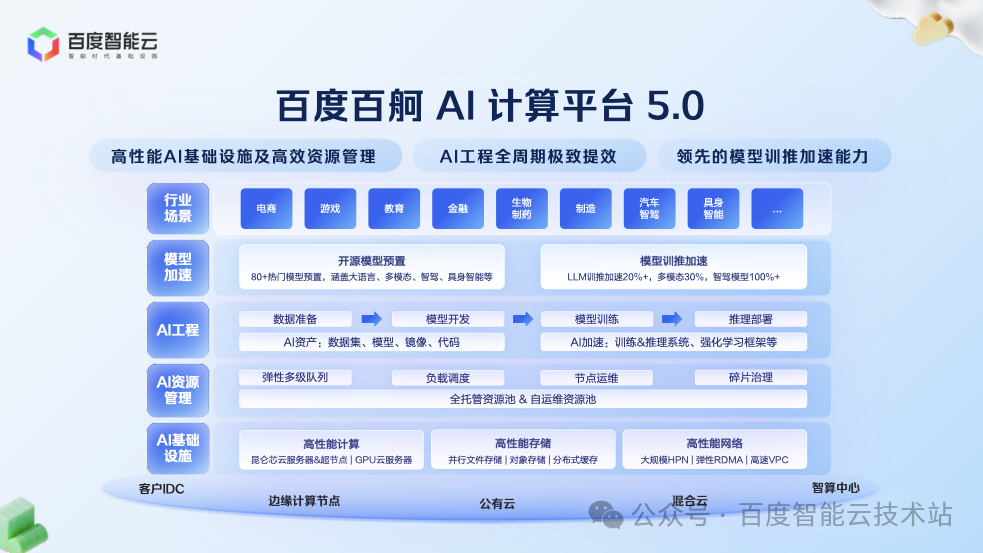
在训练层面,百度百舸推出了「生产可用」的 FP8 混合精度训练方案。
相比 BF16,FP8 能将计算量降低一半,理论性能提升巨大。但实践中,即使接入第三方 NV 官方或者 FP8 算子库,也可能会遇到 Loss 发散、推理陷入循环输出、精度异常等问题。
实践中,成功应用 FP8 进行训练的关键,除了集成 FP8 GEMM Kernel 外,在训练全流程阶段合理应用 FP8 量化 Scale 模式也非常关键。为此,我们需要分阶段考虑如何利用量化策略,具体包括:模型权重转换、权重初始化、优化器初始化、训练运行等。
通过这套全链路的方案,我们确保了在预训练及 SFT 等后训练过程中 FP8 的稳定应用。
在确保精度稳定后,我们进一步追求性能的极致。仅仅 GEMM 计算使用 FP8,对端到端性能提升有限。为此,我们进行了两项关键优化:
算子融合:针对 FP8 引入的额外 Scale 算子,我们进行了更细粒度的融合,将其融入前向或后向计算中,大幅降低了算子开销。
通信优化:通信在训练中占比较大,若通信仍使用 FP16/FP32,将损失 FP8 的性能收益。我们调整并行策略,确保在通信过程中尽可能使用 FP8。
这套组合拳下来,我们实现了端到端训练速度 30% 以上的提升。
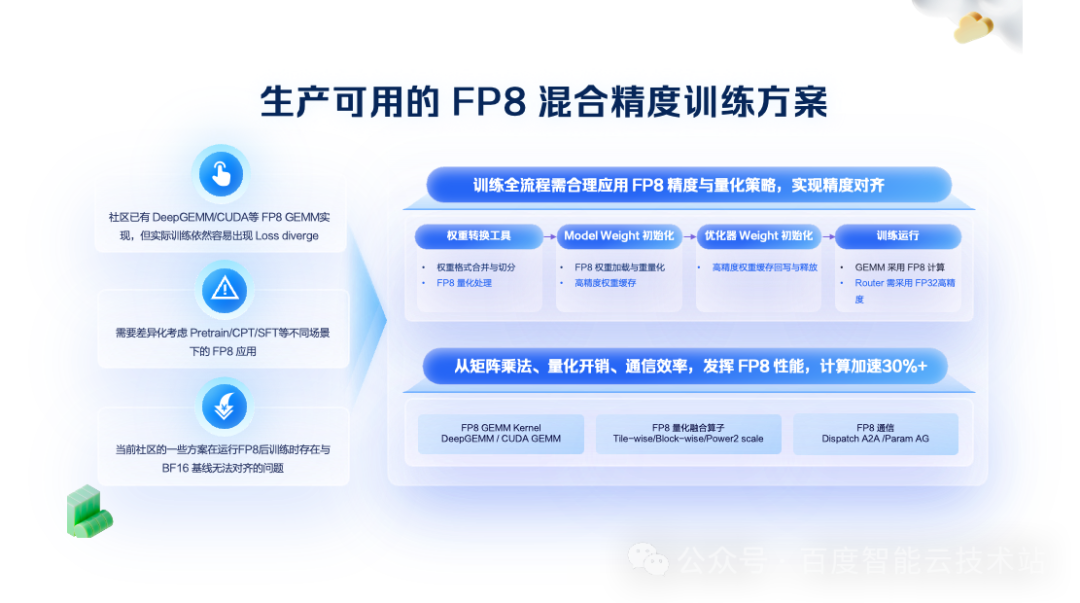
由于 Dense 模型结构规整,可均匀拆分到各显卡并行。但是 MoE 模型兼具「稀疏性」与「计算不均衡性」,需重构分布式并行策略。百舸 5.0 对此进行了深度优化:
异构 TP 切分:针对模型中不同 MLP 大小和 Attention 尺寸的层,采用不同的张量并行(TP)切分逻辑(如 TP4、TP8),实现更高效的计算拆分。
动态 PP 切分:在流水线并行(PP)中,由于 MoE 层与稠密层计算特征差异巨大,我们采用动态均衡策略进行切分,确保各阶段计算负载均衡。
通信隐藏:结合 TP 计算和通信并行、DeepEP 等技术,通过 Batch 间并行机制,将 MoE 模型中暴涨的通信量隐藏在计算过程中,减少 GPU 的等待。
经过这些优化,训练吞吐提升了 50% 以上。
如果说训练的升级是精进,那么推理的升级则是一场彻底的革命。MoE 时代的推理实例,已从单卡单台机器扩展到几十台机器,成为一个庞大的分布式系统。
半年前,我们通过 PD 分离和 EP 并行,打下了业界领先的基础。但这只是一个开始。要构建一个真正高效的系统,需要更深层次的重构。
我们首先将分离式架构进行到底。PD 分离之所以成为业界共识,是因为 Prefill 和 Decode 的计算模式不同,混在一起会冲突。我们发现,分离可以做得更彻底:
VIT 分离:将多模态模型中的视觉编码(VIT)与语言模型计算分离,以适应不同的计算特征。
Attention-MLP 分离:将访存密集型的 Attention 计算与计算密集型的 MLP(专家网络)计算分离,使它们能在最适合的硬件上并行执行。
这种深度分离为性能的极致提升奠定了基础。

作为线上系统,低延迟至关重要。随着上下文长度向 128K 甚至更长发展,计算量呈平方级增长,对响应时间构成巨大挑战(如 16K 输入比 4K 输入计算量高 16 倍)。
针对输入长度跨度范围大的生产场景,为了保证服务质量,我们的解决方案是采用自适应混合并行策略:
对于 16K 以下的输入,我们力求在单机内解决。通过机内 TP 和 SP 并行,并对这些并行策略进行深度优化,最大化减少通信开销,实现接近线性的加速比。
对于 128K 等超长序列,系统可自适应地将请求拆分到多台机器上并行处理,通过机间 TP 和 SP 并行,结合 Attention 分块计算 + 计算通信重叠,突破单机局限。
这一系列技术,使得我们能够将 16K 输入的首 Token 延迟(TTFT)控制在 0.5秒以内,128K 输入的响应时间也仅为 3 秒左右,满足了线上业务对低延迟的严苛要求。

当推理系统从单机扩展到几十台机器的分布式系统时,负载均衡成为决定系统吞吐的核心挑战。
首先,是动态 DP 负载均衡(DPLB)。推理请求的长度是动态变化的,无法像训练任务那样预先分配固定的计算量。如果调度不均,部分计算单元会因任务过重而成为瓶颈,其他单元则可能空闲等待,造成资源浪费。
为此,我们构建了高效的调度系统:
Batch 排队机制优化:在 DP 间实现请求的零排队,将等待时间降至最低。
Token 级精确控制:在 DP 内对请求的输入进行 token 级细粒度切分,确保同一 batch 内的双流任务的负载均匀。
通过这一系列技术,我们实现了整个推理系统无排队、无空等的状态,显著提升了整体吞吐。

其次,是专家负载均衡(EPLB),这是 MoE 模型在 EP 并行下特有的挑战。在每一轮 Batch 处理中,不同专家被激活的 Token 数量是不均衡的。如果某个 GPU 上处理的 Token 数远超平均值,其执行时间,尤其是 AlltoAll 通信时间将成为整个系统的瓶颈,严重影响推理效率。
百舸 5.0 采用了更高效的专家负载均衡策略:
在静态专家冗余策略上,我们使用了更具有统计学意义的百分位权重作为参考。
在动态负载路由策略上,系统在每一轮计算中,都会统计全局的专家激活情况。基于实时数据,动态选择路由目标,实现 GPU 层面的负载均衡。
这从根本上解决了 MoE 模型的内生不均衡问题,保障了推理效率。

最后,是分布式 KV Cache。随着 Agent 应用的普及,大量请求包含重复的System Prompt,这为「用存储换计算」提供了巨大空间。缓存历史计算的 KV 状态,可避免重复计算,直接复用结果。
在构建 KV Cache 中最要的问题是要解决 HBM 容量有限的问题。为此,我们构建了三级缓存的分布式 KV Cache 体系,突破存储容量限制:HBM -> 内存 -> SSD。该体系极大地扩展了缓存容量,支持更长的上下文和更高的复用率。
为解决慢速介质(如 SSD)的延迟问题,我们采用了实时全局索引,系统能全局感知和预测 Cache 需求,提前在后台进行填充,从而大幅提升了缓存命中率。

总结来说,对于一个 PD 分离推理系统而言,它是一项系统性的工程。我们为了算子的计算效率推动了更极致的分离,在引擎层面实施自适应的并行策略,在系统层面实现 DP 和 EP 的负载均衡,在 KV Cache 层面最大化用存储换计算的效益。
通过这一整套组合拳,我们让整体的推理系统吞吐,在之前的版本基础上,再次提升了 50% 以上,同时将首 Token 延迟控制在 0.5 秒。
我们相信,目前这套推理系统是业内领先的、已大规模生产级应用的系统,欢迎大家进行更深入的交流。

AI 计算的极致性能,需「芯片 + 系统」深度协同。
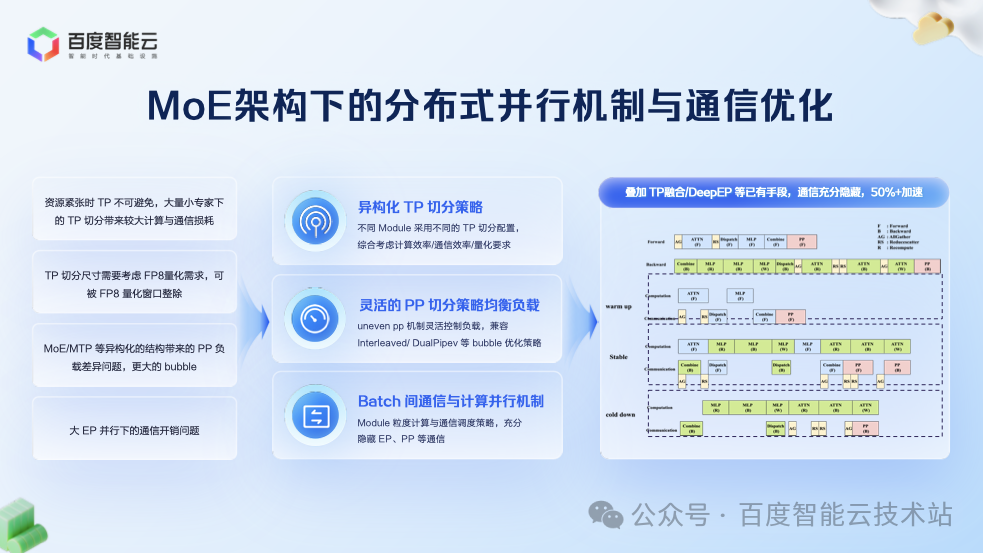
过去,国产芯片多用于推理,训练则面临扩展性、稳定性、精度三大挑战。百度通过 3 万卡昆仑芯集群持续打磨,成功实现了在万卡级别上稳定、高效地训练主流大语言模型、多模态模型和文生视频模型,并保证了与主流芯片对齐的精度。这使得昆仑芯真正成为能训练先进模型的先进国产芯。
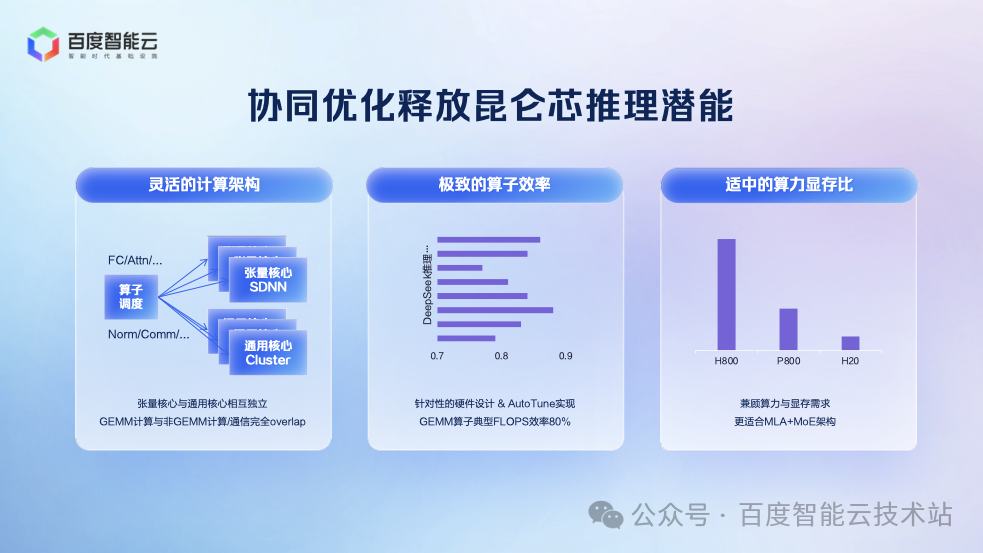
在推理服务上,我们充分利用昆仑芯 P800 的架构特点释放性能优势:
其张量核心与通用核心完全独立,可实现计算与通信的充分并行,特别适合 MoE 架构。
其 Tensor Core 密度更高,使 GEMM、Attention 等核心算子效率均超过 80%,昆仑芯成为最适合 MoE 推理的芯片之一。
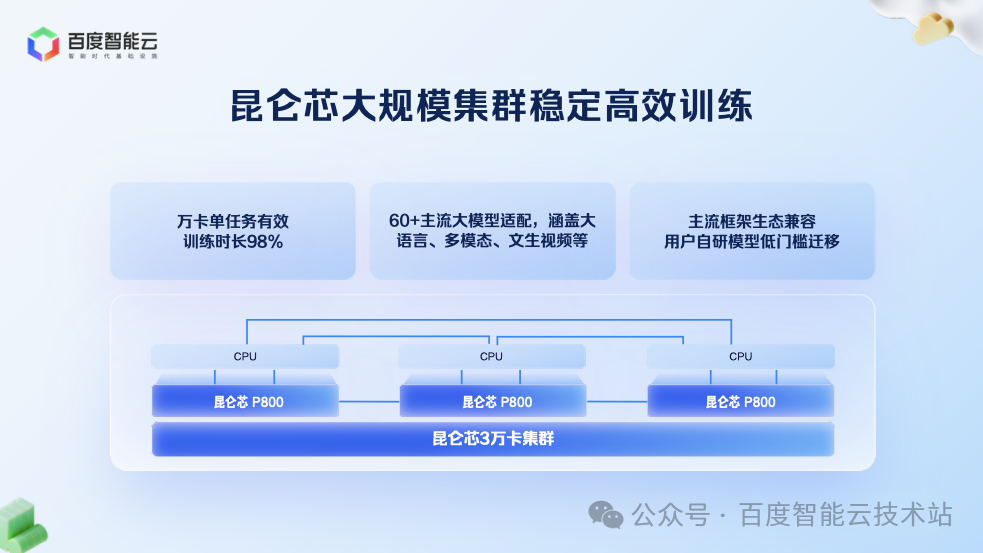
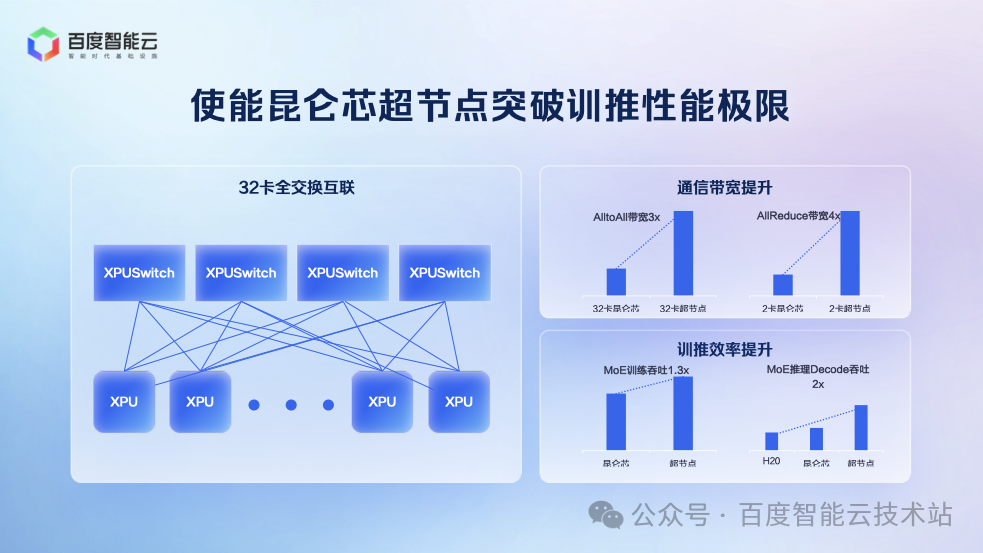
为了满足 MoE 模型的训推需求,百度推出 32 卡昆仑芯超节点,通过全互联架构提升通信效率,兼顾易用性、成本、性能:
易用性:32 卡可部署于标准机柜,背板连接,无需机房改造。
成本:相较于传统 8 卡服务器,成本增加比例极小。
性能:32 卡规模足以支持当前所有主流 MoE 模型的训推需求,且通信效率大幅提升。
经测试,超节点的性能表现如下:
训练性能:MoE 训练吞吐提升 30%,单卡吞吐提升近一倍。
推理性能:推理吞吐提升一倍。
百度百舸平台的这些新能力,已被各个行业客户广泛应用生产业务中。以某教育客户为例,该客户有大量多模态模型需求,如拍照解题、作业批改等,这意味着需要进行海量的 SFT(监督微调)任务,同时也承载着大量的在线推理任务。
百度百舸 5.0 通过硬件适配、资源混部、性能加速等,解决多模态训推的核心痛点:
高效的推理能力:将之前运行在主流 GPU 的业务平滑降低至昆仑芯 P800,显著降低了推理成本。
高效的资源利用率:通过百舸的弹性队列和任务调度能力,实现了训练任务与推理任务在同一集群内的高效混部,避免了资源闲置,大幅提升了整体资源利用率。
无缝的加速体验:客户可以无缝使用百舸提供的各项训练和推理加速组件,无需复杂改造,即可享受性能红利。
这一整套方案,不仅帮助客户大幅降低了资源成本,更重要的是,显著提升了其模型的训练迭代速度,使其能够更快地响应市场变化。

百度百舸 5.0 以 MoE 模型为核心,重构 AI 计算的基础设施 —— 从训练场景的 FP8 量化、分布式并行策略,到推理场景的分离式架构、负载均衡调度,再到硬件端的昆仑芯协同,每一步优化都紧扣混合负载的实际需求。
今天的分享到这里,谢谢大家!






:StandardScaler)




)

)


)
、CommonJS(CJS)和UMD三种格式)
)
:高级实现——平衡源项、边界条件与算法总成)