无需多言,大家应该都用过了,如今都更新到GPT-5了。
1. GPT-1
回到2018年的NLP,神仙打架,BERT与GPT不分先后。
GPT是“Generative Pre-Training”的简称,生成式的预训练。BERT和GPT肯定是GPT难训练,引用量也是BERT更多。
BERT是结合上下文,进行完形填空,相对来说比较简单。但GPT只给上文,让预测下文,能参考的东西只有 一部分。
GPT网络结构跟BERT类似,BERT是Transformer的编码器,GPT是Transformer的解码器,因为它不能用后文的信息,只能用前文特征。
decoder 模块的核心是 因果 self-attention(只能看到前文),这正是自回归生成所需要的。encoder 模块则允许双向(全局)self-attention,用于一次性编码整个序列,适合理解任务。
目标函数: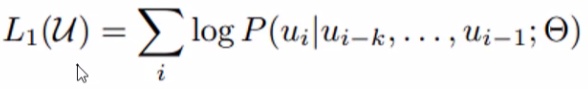
θ 是模型参数,u_{i-1} 到 u_{i-k} 都是上文,预测下文 u_i。
训练好这个GPT-1模型之后,要想进行使用,所有下游任务都需要微调。
2. GPT-2
能不能不微调,直接训出一个zero-shot的,开箱即用的模型。
下游任务有很多很多,不训练怎么能让模型知道要做什么呢?通过一些提示告诉模型需要完成什么任务。
大模型在规模、数据和训练目标的共同作用下,能通过提示(prompt)在很多下游任务上“零次/少次学习(zero-/few-shot)地表现很好”,但在可靠性、效率和特定任务精度上,微调(或参数高效微调)仍然常常必要。
总结来说就是模型更大了(1.17亿→15亿),而且下游任务不需要微调。还是一个decoder-only 的 Transformer 自回归语言模型。
自回归模型要进行预测,但是会不会陷入一个死循环呢?所以我们希望模型预测多样化一些,这就涉及到了采样策略,不能一直选概率最大的,也要选一些其他的。
2.1 这就涉及到了 Temperature
温度就是说对预测结果进行概率重新设计。温度为1就还相当于走softmax,谁得分高谁就概率最大
当温度除以一个小于1的值,会让原本预测的值之间的差异变大,再经过softmax,谁得分高谁概率更大了,所以温度降低就会抑制多样性,最终结果就是概率最大的结果。

当除上大一点的数,就会缩小值之间的差距,所以概率就会趋向平均,所以升温多样性会大一些,但是可能会胡说八道,就是他输出了很多小概率的词。
这时模型在采样时不能让他采样到贼离谱的结果,就是概率很小,但不为0,也是有可能被采样的,这就不合适了,所以引入top-k
2.2 Top k 与 Top p
TOPK和TOPP都是要剔除那些概率特别小的结果,概率排序后TOPK选前10个,那之后的值就全都为0了。
Top-K:只把概率最高的 K 个 token 放进候选池,从中采样。
Top-P(nucleus):把概率最高的前若干个 token(最小集合)取出,使它们的累计概率 ≥ P,然后在这个集合里采样。
这俩不冲突,都能设置,谁先到上限谁以谁为准。
3. GPT-3
GPT-3 不是把架构换了,而是把 尺度(参数、训练数据与 compute)和工程实践 放大到一个新的量级,从而出现了明显的 in-context / few-shot 能力 和若干“突现”行为,这使得模型在很多任务上能在不微调的情况下通过 prompt 就表现得很好。
GPT-2:最大约 1.5B 参数(还有更小的 117M/345M/762M 等变体)。
GPT-3:最大 ~175B 参数(大约是 GPT-2 最大版的 ~100×),这个尺度跃升是核心因素之一。
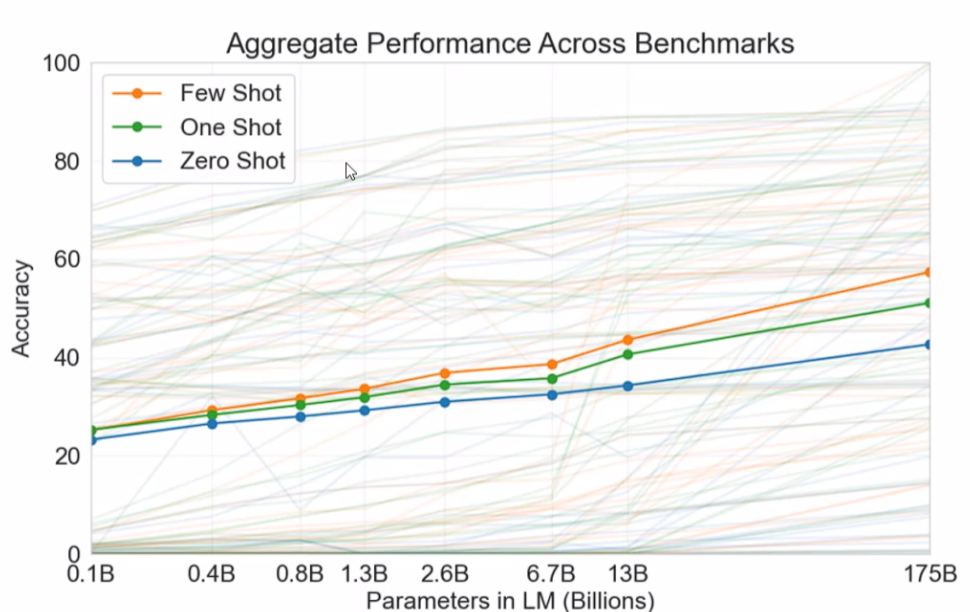
不用做微调,没有再训练的过程。
4. DeBug GPT2
GPT-2是开源的,所以可以来运行学习一下。
4.1 预处理
if __name__ == '__main__':preprocess()
def preprocess():"""对故事数据集进行预处理"""# 设置参数parser = argparse.ArgumentParser()parser.add_argument('--vocab_file', default='vocab/chinese_vocab.model', type=str, required=False,help='词表路径')parser.add_argument('--log_path', default='log/preprocess.log', type=str, required=False, help='日志存放位置')parser.add_argument('--data_path', default='data/novel', type=str, required=False, help='数据集存放位置')parser.add_argument('--save_path', default='data/train.pkl', type=str, required=False, help='对训练数据集进行tokenize之后的数据存放位置')parser.add_argument('--win_size', default=200, type=int, required=False, help='滑动窗口的大小,相当于每条数据的最大长度')parser.add_argument('--step', default=200, type=int, required=False, help='滑动窗口的滑动步幅')args = parser.parse_args()
# 初始化日志对象logger = set_logger(args.log_path)# 初始化tokenizertokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")#pip install jiebaeod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符
# 读取小说数据集目录下的所有文件train_list = []logger.info("start tokenizing data")for file in tqdm(os.listdir(args.data_path)):file = os.path.join(args.data_path, file)
novel中有15本小说,所以0/15,然后拿到第一本

with open(file, "r", encoding="utf8")as reader: # 打开这个数据lines = reader.readlines() # 读取所有行for i in range(len(lines)): # 遍历每一行if lines[i].isspace() != True and lines[i] != '\n': # 如果非空且不是结束# 那就编码这行,然后加上终止符token_ids = tokenizer.encode(lines[i].strip(), add_special_tokens=False) + [eod_id] 一句话里都有些什么,然后加了个终止符
一句话里都有些什么,然后加了个终止符
if i%1000 == 0:# 打印当前步和数据print('cur_step', i, lines[i].strip())else: # 如果是空或\n就跳过continue![]()
# 对于每条数据,使用滑动窗口对其进行截断win_size = args.win_size # 200step = args.step # 200start_index = 0end_index = win_sizedata = token_ids[start_index:end_index] # 取数据截断train_list.append(data) # 添加到训练list中start_index += step # 首尾滑动end_index += step# 这条剩下的数据长度,如果大于或等于50,才加入训练数据集# 其实就是在对长的进行拆分while end_index+50 < len(token_ids): data = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += step# 如果小于50,则这条数据集结束,去下一条短的本身就是一个数据,长的会切分成多个。
执行完这个预处理之后会产生一个.pkl文件
4.2 traing
if __name__ == '__main__':main()
def main():# 初始化参数args = set_args()# ---
def set_args():parser = argparse.ArgumentParser()parser.add_argument('--device', default='0,1', type=str, required=False, help='设置使用哪些显卡')parser.add_argument('--no_cuda', action='store_true', help='不使用GPU进行训练')parser.add_argument('--vocab_path', default='vocab/chinese_vocab.model', type=str, required=False,help='sp模型路径')parser.add_argument('--model_config', default='config/cpm-small.json', type=str, required=False,help='需要从头训练一个模型时,模型参数的配置文件')parser.add_argument('--train_path', default='data/train.pkl', type=str, required=False, help='经过预处理之后的数据存放路径')parser.add_argument('--max_len', default=200, type=int, required=False, help='训练时,输入数据的最大长度')parser.add_argument('--log_path', default='log/train.log', type=str, required=False, help='训练日志存放位置')parser.add_argument('--ignore_index', default=-100, type=int, required=False, help='对于ignore_index的label token不计算梯度')parser.add_argument('--epochs', default=100, type=int, required=False, help='训练的最大轮次')parser.add_argument('--batch_size', default=16, type=int, required=False, help='训练的batch size')parser.add_argument('--gpu0_bsz', default=6, type=int, required=False, help='0号卡的batch size')parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='学习率')parser.add_argument('--eps', default=1.0e-09, type=float, required=False, help='AdamW优化器的衰减率')parser.add_argument('--log_step', default=10, type=int, required=False, help='多少步汇报一次loss')parser.add_argument('--gradient_accumulation_steps', default=6, type=int, required=False, help='梯度积累的步数')parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False)parser.add_argument('--save_model_path', default='model', type=str, required=False,help='模型输出路径')parser.add_argument('--pretrained_model', default='model/zuowen_epoch40', type=str, required=False,help='预训练的模型的路径')parser.add_argument('--seed', type=int, default=1234, help='设置随机种子')parser.add_argument('--num_workers', type=int, default=0, help="dataloader加载数据时使用的线程数量")# parser.add_argument('--patience', type=int, default=0, help="用于early stopping,设为0时,不进行early stopping.early stop得到的模型的生成效果不一定会更好。")parser.add_argument('--warmup_steps', type=int, default=4000, help='warm up步数')# parser.add_argument('--label_smoothing', default=True, action='store_true', help='是否进行标签平滑')args = parser.parse_args()return args
# ---# 设置使用哪些显卡进行训练os.environ["CUDA_VISIBLE_DEVICES"] = args.deviceargs.cuda = not args.no_cuda# if args.batch_size < 2048 and args.warmup_steps <= 4000:# print('[Warning] The warmup steps may be not enough.\n' \# '(sz_b, warmup) = (2048, 4000) is the official setting.\n' \# 'Using smaller batch w/o longer warmup may cause ' \# 'the warmup stage ends with only little data trained.')# 创建日志对象logger = set_logger(args.log_path)# 当用户使用GPU,并且GPU可用时args.cuda = torch.cuda.is_available() and not args.no_cudadevice = 'cuda:0' if args.cuda else 'cpu'args.device = devicelogger.info('using device:{}'.format(device))# 设置随机种子set_random_seed(args.seed, args.cuda)# 初始化tokenizer https://www.sciencedirect.com/science/article/pii/S266665102100019Xtokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")args.eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符args.pad_id = tokenizer.pad_token_id# 创建模型的输出目录if not os.path.exists(args.save_model_path):os.mkdir(args.save_model_path)# 创建模型if args.pretrained_model: # 加载预训练模型model = GPT2LMHeadModel.from_pretrained(args.pretrained_model)else: # 初始化模型model_config = GPT2Config.from_json_file(args.model_config)model = GPT2LMHeadModel(config=model_config)model = model.to(device)logger.info('model config:\n{}'.format(model.config.to_json_string()))assert model.config.vocab_size == tokenizer.vocab_size# 多卡并行训练模型if args.cuda and torch.cuda.device_count() > 1:# model = DataParallel(model).cuda()model = BalancedDataParallel(args.gpu0_bsz, model, dim=0).cuda()logger.info("use GPU {} to train".format(args.device))# 计算模型参数数量num_parameters = 0parameters = model.parameters()for parameter in parameters:num_parameters += parameter.numel()# 这参数量不大logger.info('number of model parameters: {}'.format(num_parameters))# 记录参数设置logger.info("args:{}".format(args))# 加载训练集和验证集# ========= Loading Dataset ========= #train_dataset = load_dataset(logger, args)train(model, logger, train_dataset, args)
def load_dataset(logger, args):"""加载训练集"""logger.info("loading training dataset")train_path = args.train_path # .pkl文件with open(train_path, "rb") as f:train_list = pickle.load(f)# test# train_list = train_list[:24]train_dataset = CPMDataset(train_list, args.max_len)return train_dataset
def train(model, logger, train_dataset, args):train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=collate_fn,drop_last=True)# 打印总共会遍历多少个 batch# len(train_dataloader):每个 epoch 的 batch 数logger.info("total_steps:{}".format(len(train_dataloader)* args.epochs))# 计算训练过程中的 optimizer 步数总数。# // args.gradient_accumulation_steps:整除梯度累积步数,表示每进行 gradient_accumulation_steps 个 mini-batch 才执行一次 optimizer.step()# 每 epoch 的 optimizer 步数大约是len(train_dataloader) / gradient_accumulation_stepst_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochs# 创建优化器optimizer = transformers.AdamW(model.parameters(), lr=args.lr, eps=args.eps)#设置warmup,创建一个线性学习率调度器scheduler = transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)logger.info('start training')train_losses = [] # 记录每个epoch的平均loss# ========== start training ========== ## 遍历每个epochfor epoch in range(args.epochs):# 每个epochtrain_loss = train_epoch(model=model, train_dataloader=train_dataloader,optimizer=optimizer, scheduler=scheduler,logger=logger, epoch=epoch, args=args)train_losses.append(round(train_loss, 4))logger.info("train loss list:{}".format(train_losses))# ---
def train_epoch(model, train_dataloader, optimizer, scheduler, logger,epoch, args):# 训练模式model.train()device = args.device# 忽略的索引ignore_index = args.ignore_indexepoch_start_time = datetime.now()total_loss = 0 # 记录下整个epoch的loss的总和epoch_correct_num = 0 # 每个epoch中,预测正确的word的数量epoch_total_num = 0 # 每个epoch中,预测的word的总数量# 遍历dataloaderfor batch_idx, (input_ids, labels) in enumerate(train_dataloader):# ------DataLoader 会先用 sampler 选索引、调用 dataset.__getitem__ 取到样本列表,然后立刻调用 collate_fn(batch) 将这批样本打包对齐成张量。也就是每个 batch 调一次,在进入训练循环、送入模型之前。
# DataLoader 在组装一个 batch 时对变长序列进行对齐(padding)。
def collate_fn(batch):# 将一个 batch 中不同长度的样本(token 序列)按最长序列补齐为同一长度,返回可直接喂给模型的 input_ids 和 labels 张量。input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=5)labels = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=-100)return input_ids, labels一个batch里的数据长度得相同,标签也同理,5号对应的标签就是-100,就是我们不考虑的
![]() 这4个样本中最大长度应该就是151的,label也是这么大
这4个样本中最大长度应该就是151的,label也是这么大
接下来把数据都放到gpu中:
# ------ # 捕获cuda out of memory exceptiontry:input_ids = input_ids.to(device)labels = labels.to(device)# 对网络模型forwardoutputs = model.forward(input_ids, labels=labels)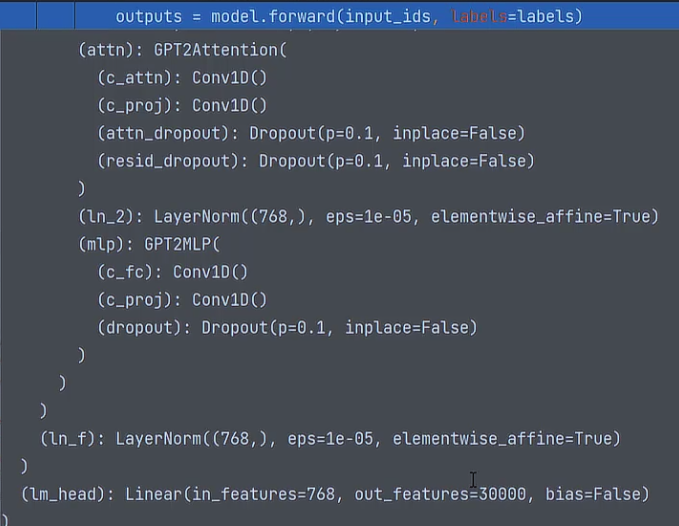
这个网络模型最后输出特征是30000,也就是说我们的语料库中有3w个词,最终就是要预测这个词是3w当中的哪一个。
forward后就会得到预测的词属于3w个类别的概率。
然后计算当前的损失,求个平均
logits = outputs.logitsloss = outputs.lossloss = loss.mean()
# 统计该batch的预测token的正确数与总数batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)# ------
def calculate_acc(logit, labels, ignore_index=-100):# 把预测值展开,拿到所有预测结果logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1))# 把标签也展开labels = labels[..., 1:].contiguous().view(-1)# 对于每条数据,返回最大的值和其index,也就是得到该位置预测的 token id_, logit = logit.max(dim=-1) # 进行非运算,返回一个tensor,若labels的第i个位置为pad_id,则置为0,否则为1# 也就是说如果是要忽略的就不管了non_pad_mask = labels.ne(ignore_index)n_correct = logit.eq(labels).masked_select(non_pad_mask).sum().item()n_word = non_pad_mask.sum().item()return n_correct, n_wordGPT-2 在时间步 t 输出的是对 下一个 token(t+1) 的预测分布(logits 的第 t 列对应标签的第 t+1 个 token)。
举个非常直观的数字例子(batch=1,seq_len=4):
原 labels(token id 序列): labels = [L0, L1, L2, L3]
模型在每个时刻输出 logits(每个时刻是对 vocab 的打分):logits(按时间步看)产生的是对下一个 token 的预测:
logits at t=0 -> 预测 L1
logits at t=1 -> 预测 L2
logits at t=2 -> 预测 L3
logits at t=3 -> 预测 L4(
logits的最后一帧通常没有对应的标签,因此在这个对齐里被丢弃)
所以做:
logits[..., :-1, :]对应 logits for t = 0,1,2labels[..., 1:]对应 labels L1, L2, L3
这里仅作演示,实际中比较的是token id
logit:晚上 吃 大面
label:今天 晚上 吃 大肉真实标签 labels 向右切一格去一一对应,然后逐项比较,n_correct = 2,n_word = 3。
labels[0] = "今天" 没有被比较,因为模型在 t=-1(没有这个时刻)没法去预测它;同理模型在最后一个时刻也是少于labels一位的。相当于logit本身就向左移了一位。
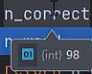 这就是对了98个。
这就是对了98个。
# 统计该epoch的预测token的正确数与总数epoch_correct_num += batch_correct_numepoch_total_num += batch_total_num# 计算该batch的accuracybatch_acc = batch_correct_num / batch_total_numtotal_loss += loss.item()# 如果梯度积累的步数大于1,我们默认是6if args.gradient_accumulation_steps > 1:# 求累积出来的损失到每一步上的均值loss = loss / args.gradient_accumulation_stepsloss.backward()# 梯度裁剪--当梯度很大时,optimizer.step() 会做出巨大的参数更新,导致训练不稳定、loss 振荡甚至 NaN。torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)# “在时间维度上把多个小 batch 的梯度合并”,从而在效果上等同于一次用更大 batch 做反向传播,所以这样可以间接增加batch# 进行一定step的梯度累计之后,更新参数,达到6次累积才更新,否则就攒着if (batch_idx + 1) % args.gradient_accumulation_steps == 0:# 更新参数optimizer.step()# 更新学习率scheduler.step()# 清空梯度信息optimizer.zero_grad()if (batch_idx + 1) % args.log_step == 0:logger.info("batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))del input_ids, outputsexcept RuntimeError as exception:if "out of memory" in str(exception):logger.info("WARNING: ran out of memory")if hasattr(torch.cuda, 'empty_cache'):torch.cuda.empty_cache()else:logger.info(str(exception))raise exception# 记录当前epoch的平均loss与accuracyepoch_mean_loss = total_loss / len(train_dataloader)epoch_mean_acc = epoch_correct_num / epoch_total_numlogger.info("epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))# save modellogger.info('saving model for epoch {}'.format(epoch + 1))model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))if not os.path.exists(model_path):os.mkdir(model_path)model_to_save = model.module if hasattr(model, 'module') else modelmodel_to_save.save_pretrained(model_path)logger.info('epoch {} finished'.format(epoch + 1))epoch_finish_time = datetime.now()logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))return epoch_mean_loss4.3 部署与网页预测展示
# 这个前端在加上cache之后会先走这个函数
@st.cache(allow_output_mutation=True)
def get_model(device, model_path):tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符sep_id = tokenizer.sep_token_idunk_id = tokenizer.unk_token_idmodel = GPT2LMHeadModel.from_pretrained(model_path)model.to(device)model.eval()return tokenizer, model, eod_id, sep_id, unk_id这个模型加载之后是一直存在的。
if __name__ == '__main__':writer()
def writer():st.markdown("""## GPT生成模型""")st.sidebar.subheader("配置参数")generate_max_len = st.sidebar.number_input("generate_max_len", min_value=0, max_value=512, value=32, step=1)top_k = st.sidebar.slider("top_k", min_value=0, max_value=10, value=3, step=1)top_p = st.sidebar.number_input("top_p", min_value=0.0, max_value=1.0, value=0.95, step=0.01)temperature = st.sidebar.number_input("temperature", min_value=0.0, max_value=100.0, value=1.0, step=0.1)parser = argparse.ArgumentParser()parser.add_argument('--generate_max_len', default=generate_max_len, type=int, help='生成标题的最大长度')parser.add_argument('--top_k', default=top_k, type=float, help='解码时保留概率最高的多少个标记')parser.add_argument('--top_p', default=top_p, type=float, help='解码时保留概率累加大于多少的标记')parser.add_argument('--max_len', type=int, default=512, help='输入模型的最大长度,要比config中n_ctx小')parser.add_argument('--temperature', type=float, default=temperature, help='输入模型的最大长度,要比config中n_ctx小')args = parser.parse_args()context = st.text_area("请输入标题", max_chars=512)title = st.text_area("请输入正文", max_chars=512)if st.button("点我生成结果"):start_message = st.empty()start_message.write("自毁程序启动中请稍等 10.9.8.7 ...")start_time = time.time()result = predict_one_sample(model, tokenizer, device, args, title, context)end_time = time.time()start_message.write("生成完成,耗时{}s".format(end_time - start_time))st.text_area("生成结果", value=result, key=None)else:st.stop()
关键的就是这一步:
result = predict_one_sample(model, tokenizer, device, args, title, context)
title 和 context 是原始的中文字符串,然后用分词器编码成 token id 序列再送入模型。
def predict_one_sample(model, tokenizer, device, args, title, context):title_ids = tokenizer.encode(title, add_special_tokens=False)context_ids = tokenizer.encode(context, add_special_tokens=False)input_ids = title_ids + [sep_id] + context_idscur_len = len(input_ids)last_token_id = input_ids[-1] # 初始输入序列的“最后一个 token 的 id”input_ids = torch.tensor([input_ids], dtype=torch.long, device=device)while True:next_token_id = generate_next_token(input_ids,args)# ------其中,generate_next_token(input_ids,args):
def generate_next_token(input_ids,args):"""对于给定的上文,生成下一个单词"""# 只根据当前位置的前context_len个token进行生成,只保留最近 200 个 tokeninput_ids = input_ids[:, -200:]# 模型做预测outputs = model(input_ids=input_ids)# 所有的结果logits = outputs.logits# next_token_logits表示由最后一个时间步的的hidden_state对应的所有prediction_scores# 越靠后看到的前文越多,预测条件越丰富,所以取最后时间步下的的概率结果next_token_logits = logits[0, -1, :]next_token_logits = next_token_logits / args.temperature# 对于<unk>的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个tokennext_token_logits[unk_id] = -float('Inf')filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=args.top_k, top_p=args.top_p)# torch.multinomial表示从候选集合中选出无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标next_token_id = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)return next_token_id这就通过上文预测到下一个位置的词了,然后回到循环中:
# ------# 把原来的input和预测出的词进行拼接input_ids = torch.cat((input_ids, next_token_id.unsqueeze(0)), dim=1)cur_len += 1# 由预测的 token id 还原到 token,也就是词表里的一个符号/子词/字符。用于后面的判断word = tokenizer.convert_ids_to_tokens(next_token_id.item())# 超过最大长度,并且换行if cur_len >= args.generate_max_len and last_token_id == 8 and next_token_id == 3:break# 超过最大长度,并且生成标点符号if cur_len >= args.generate_max_len and word in [".", "。", "!", "!", "?", "?", ",", ","]:break# 生成结束符if next_token_id == eod_id:break# 持续循环,把预测出的词不断加到input后面,然后通过input取预测新词# input_ids 在那句代码里确实是初始上文 + 模型生成出来的所有 token id 的拼接# tokenizer.decode(...) 会把这些 id 按 tokenizer 的规则拼回可读的字符串。 result = tokenizer.decode(input_ids.squeeze(0))# title + [sep_id] + context + 生成的预测content = result.split("<sep>")[1] # 生成的最终内容return content
5. GPT-4
## 待更

















--Java版)

