ℹ️教程说明
Ollama 是一款轻量级本地大模型部署工具,使用广泛,且容易上手,适合作为AI技术的入门。
🧩教程各部分链接:
- 第一课:ollama运行原理介绍及同类工具对比
- ollama运行原理介绍及同类工具对比,与选择建议
- 第二课:ollama安装(Windows)
- 介绍了两种典型安装模式:普通安装方式和独立 CLI
- 第三课:ollama安装大模型的方式汇总
- ollama安装大模型的五种典型方式的详细汇总
- 第四课:🐑 Ollama 命令汇总
- 本文全面介绍了Ollama的相关命令的语法与示例,包括核心命令、模型管理命令、高级与系统命令
- 第五课:桌面模型管理应用调用ollama大模型
- 本文介绍了如何通过桌面应用调用本地Ollama大模型,对比了11款主流工具,并重点介绍了几个常用工具的具体安装和配置。
- 第六课:Python 调用 Ollama 大模型方式汇总
- 本文系统介绍了Python调用Ollama大模型的多种方式,包括官方SDK、REST API、OpenAI兼容接口、CLI调用及上层框架集成。
开始本课内容。。。
📚第四课:🐑 Ollama 命令汇总
Ollama 的命令行界面(CLI)设计简洁但功能强大,大概分为三类:
- 核心命令
- 模型管理命令
- 高级与系统命令
另外,在命令之后,增加了环境变量配置、故障排除与技巧两个内容。
一、核心命令
这些是你最常用的命令,用于与模型交互。
1. ollama run - 运行模型
功能:拉取(如果不存在)并启动一个与模型的交互式聊天会话。这是最常用的命令。
语法:ollama run [选项] <模型名>:<标签> [提示词]
选项:
-
无特定选项,但支持通用全局选项(如
--verbose)。
示例:
# 1. 进入与 llama3 模型的交互式对话
ollama run llama3# 2. 运行指定版本的模型 (例如 8B 参数的版本)
ollama run llama3:8b# 3. 非交互模式:直接运行一次提示词并退出
ollama run llama3 "请用中文写一首关于秋天的诗"执行界面参考:
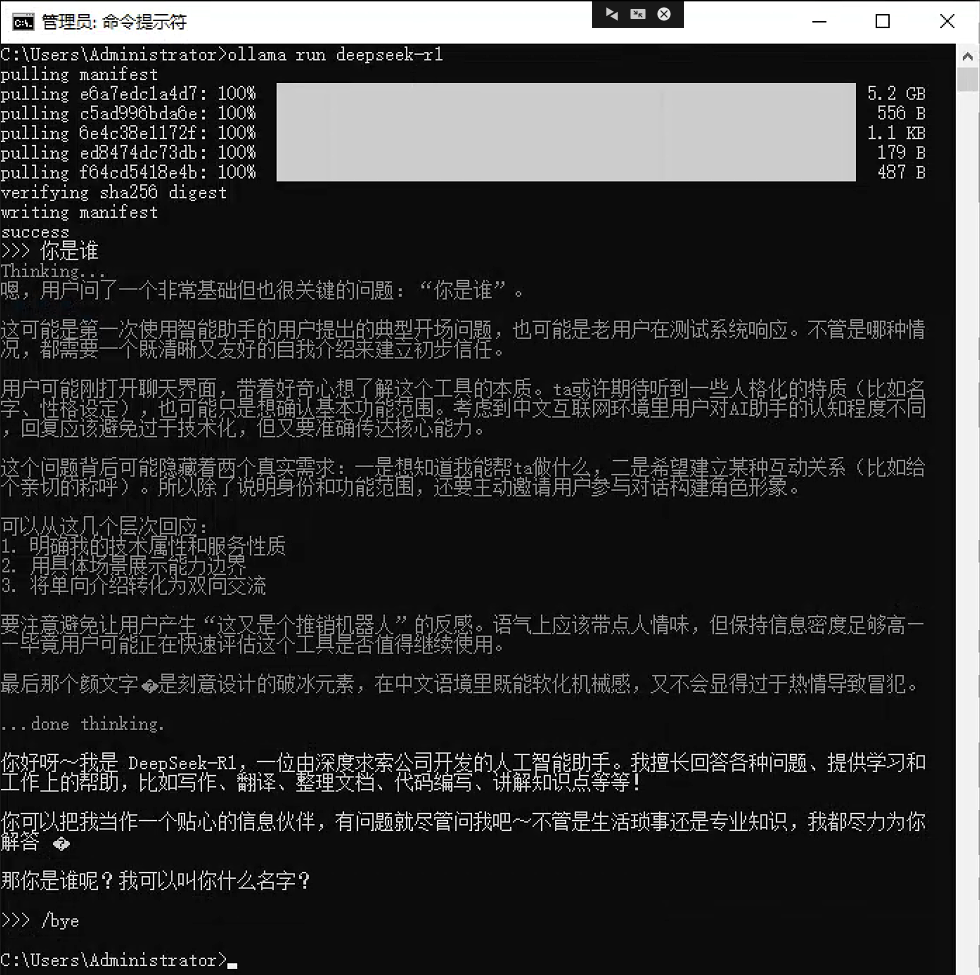
说明:在交互模式中,输入 /bye、/exit 或按下 Ctrl+D 退出。Ollama 会自动维护多轮对话的上下文。
2. ollama pull - 下载模型
功能:从模型库下载模型到本地,但不立即运行,同时具有重新下载模型的作用。
语法:ollama pull <模型名>:<标签>
示例:
# 1. 下载默认标签的 llama3 模型(通常是最新或推荐版本)
ollama pull llama3# 2. 下载指定标签的模型 (例如 70B 参数的 4-bit 量化版本)
ollama pull llama3:70b-text-q4_0# 3. 下载其他模型,如 Mistral
ollama pull mistral# 4. 下载中文优化模型
ollama pull qwen2:7b📜说明:pull 是 run 命令的第一步。使用 run 时如果模型不存在会自动调用 pull。
执行界面参考:
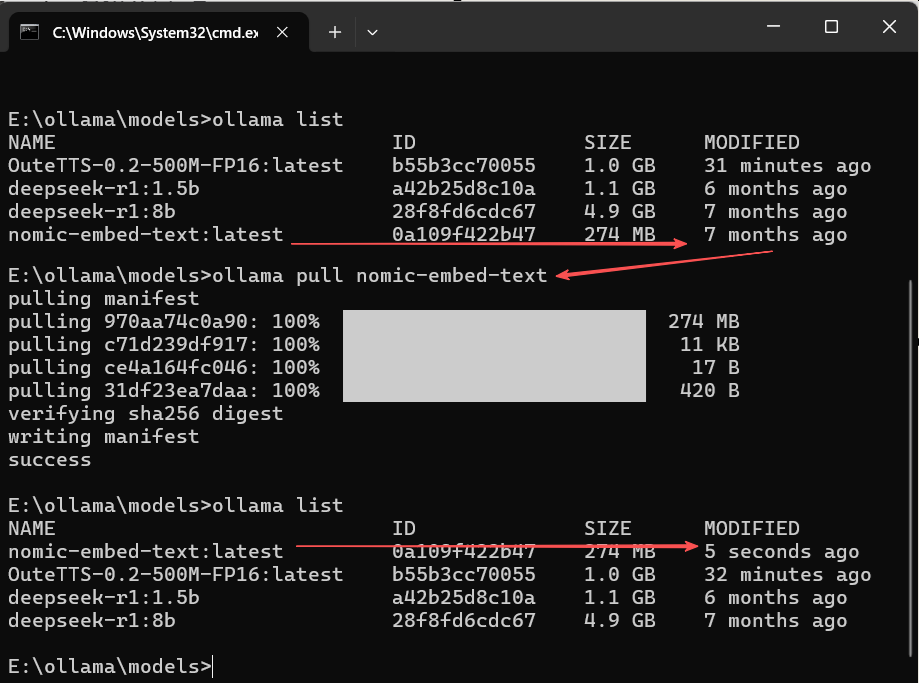
📜说明:pull 可以用于重新下载模型。
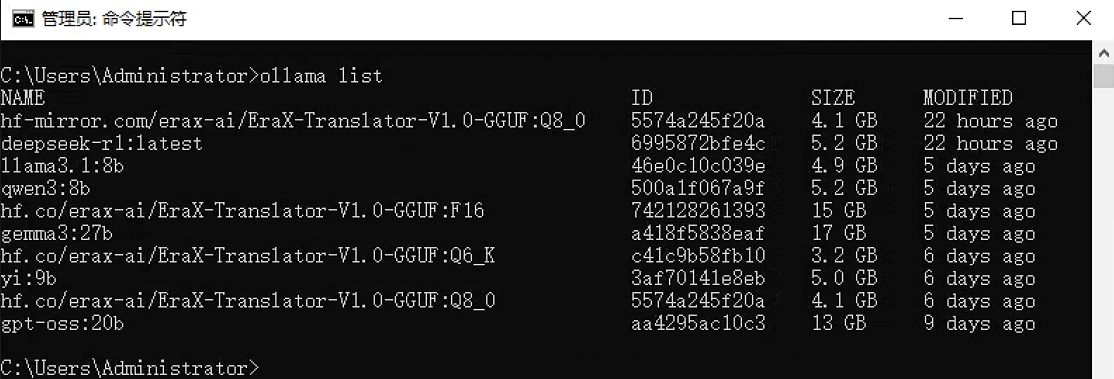
3. ollama list - 列出模型
功能:显示所有已下载到本地的模型及其详细信息。
语法:ollama list
执行界面参考:
4. ollama rm - 删除模型
功能:从本地存储中删除一个模型,释放磁盘空间。
语法:ollama rm <模型名>:<标签>
示例:
# 删除指定版本的模型
ollama rm mistral:7b# 删除默认标签的模型
ollama rm codellama执行界面参考:
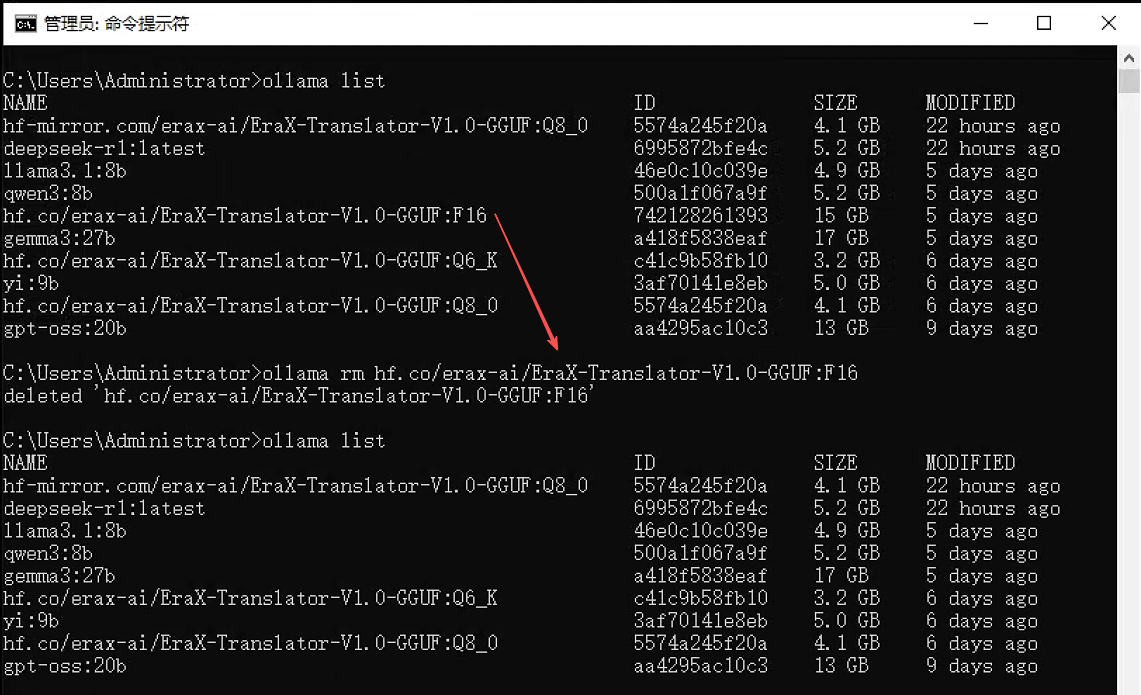
注意:删除操作不可逆,请谨慎执行。
5. ollama cp - 复制模型
功能:创建一个已有模型的副本,并赋予新的名称。
语法:ollama cp <源模型名>:<标签> <目标模型名>
示例:
# 将 llama3 复制为一个名为 my-llama 的新模型
ollama cp llama3 my-llama用途:常用于创建模型的基础副本,以便后续使用 ollama create 进行自定义。
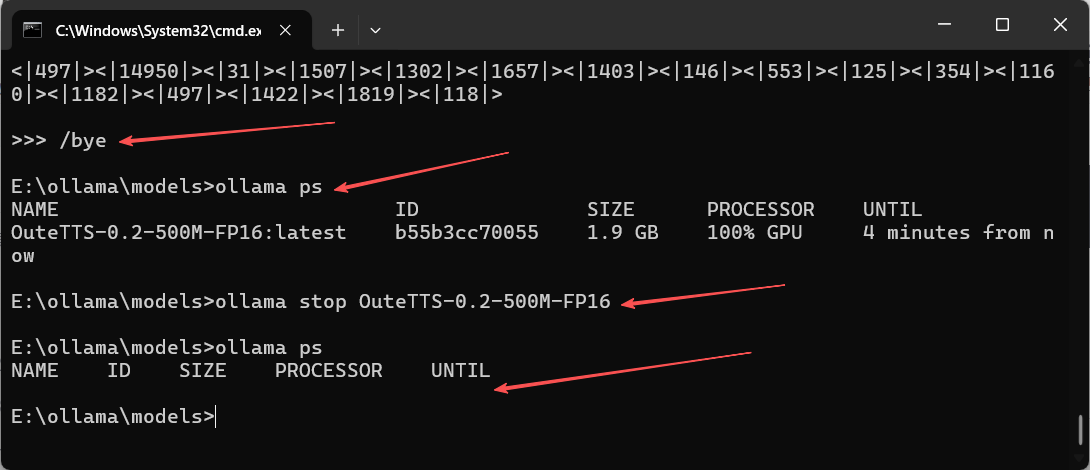
6. ollama stop - 停止特定模型
功能:/bye等,只是退出模型交互,ollama stop可以停止运行的指定模型。
语法:ollama stop [选项] <模型名称或ID>
示例:
# 使用模型名称停止 (最常见)
ollama stop deepseek-r1:1.5b# 使用模型ID停止 (名称可能重复或过长时更精确)
ollama stop a42b25d8c10a📜注:配合 ollama ps 命令,通过ollama ps获取运行的模型名称或模型ID
执行界面参考:
二、模型管理命令
这些命令用于创建和管理自定义模型配置。
7. ollama create - 创建模型
功能:基于一个 Modelfile 创建自定义模型。
语法:ollama create <模型名> -f <Modelfile路径>
示例:
-
1)首先创建一个
Modelfile文件:
# Modelfile 内容示例
FROM llama3
# 设置系统提示词,定义模型角色
PARAMETER temperature 0.8
PARAMETER num_ctx 4096
SYSTEM """
你是一个乐于助人的AI助手,请用中文回答所有问题。
"""📝 Modelfile 核心指令详解
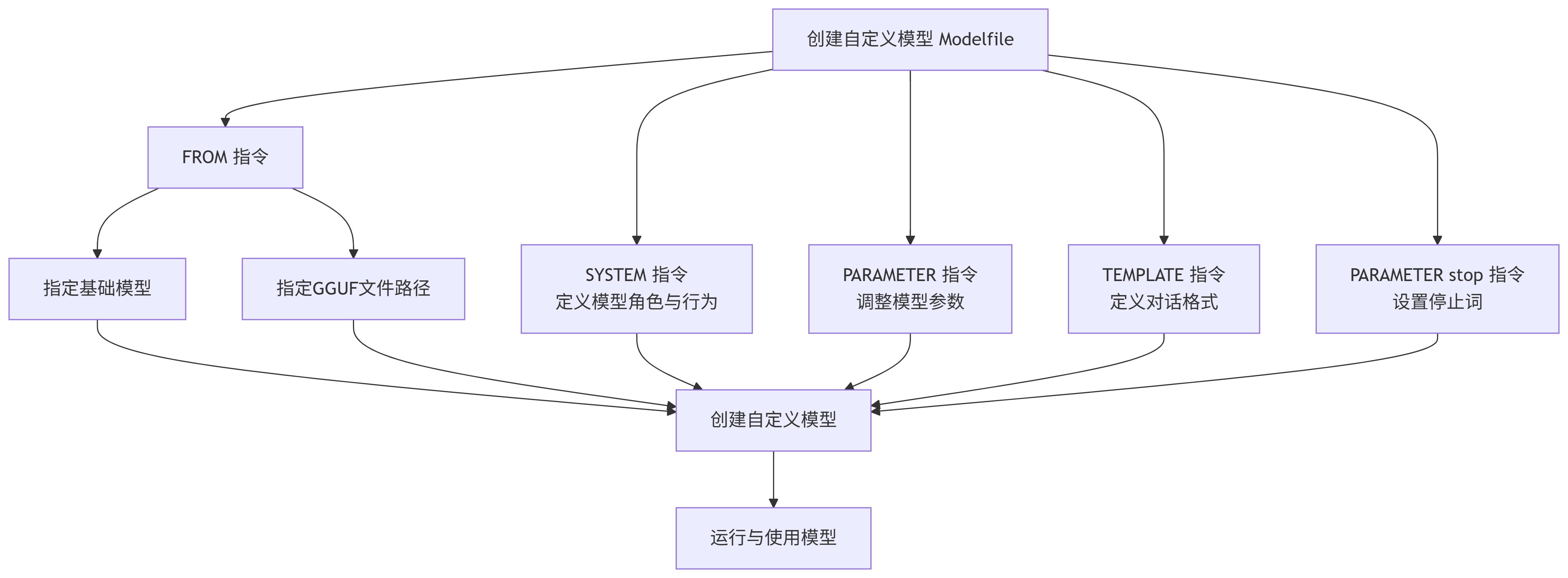
Modelfile 是一个文本文件,它通过一系列的指令来定义模型的行为。以下是其中最常用和最关键的指令:
| 指令 | 是否必需 | 描述与用途 | 示例 |
|---|---|---|---|
| FROM | 是 | 指定基础模型或GGUF模型文件路径 | FROM llama3FROM ./qwen2-7b-q4_k_m.gguf |
| PARAMETER | 否 | 设置模型推理参数,控制生成效果 | PARAMETER temperature 0.7PARAMETER num_ctx 4096 |
| SYSTEM | 否 | 定义系统提示词,设置模型角色、行为准则或上下文 | SYSTEM "你是一个乐于助人的AI助手,请用中文回答所有问题。" |
| TEMPLATE | 否 | 定义模型使用的对话模板,适用于特定模型格式 | TEMPLATE """{{ if .System }}<|im_start|>system\n{{ .System }}<|im_end|>\n{{ end }}""" |
| PARAMETER stop | 否 | 设置停止词,告诉模型生成何时结束 | PARAMETER stop "<|im_end|>"PARAMETER st |
下面是这些指令之间主要关系和流程的示意图:
🔧 关键指令说明
-
FROM指令:这是 Modelfile 中唯一必须的指令。它有两个主要用途:
-
指定基础模型:例如
FROM llama3,这意味着你的自定义模型将基于官方的llama3模型进行构建。你需要确保已经通过ollama pull llama3下载了该基础模型。 -
引用本地GGUF模型文件:例如
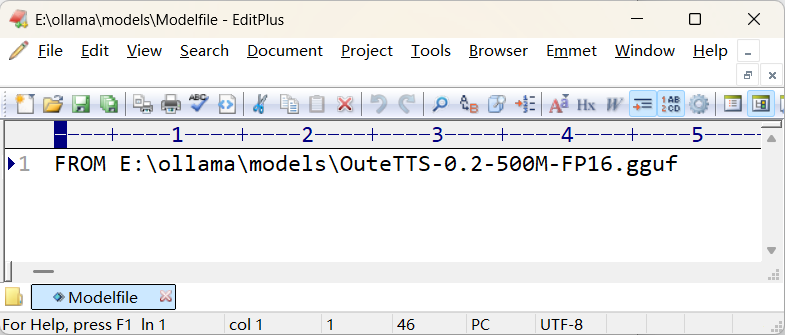
FROM ./vicuna-33b.Q4_0.gguf或FROM ./codeqwen-1_5-7b-chat-q8_0.gguf,或者绝对路径 FROM E:\ollama\models\OuteTTS-0.2-500M-FP16.gguf。这允许你直接使用从 Hugging Face 或其他平台下载的 GGUF 格式模型文件。
-
-
PARAMETER指令:常用的参数包括:
-
temperature:控制生成文本的随机性。值越高(如0.8),输出越随机、创造性越强;值越低(如0.2),输出越确定、保守。 -
num_ctx:设置模型上下文窗口的大小(token 数),例如4096。 -
top_p:一种采样策略,通常与 temperature 一起使用。 -
repeat_penalty:惩罚重复的 token,有助于减少生成内容中的重复。
-
-
SYSTEM指令:你可以在这里定义模型的角色、行为准则或知识背景。例如,你可以设置
SYSTEM "你是一位专业的软件开发工程师,擅长Python和Go语言。",这样模型就会在这个语境下回答你的问题。 -
TEMPLATE指令:这个指令通常需要参考模型本身的文档来正确设置。例如,很多 Chat 模型(如 Llama 3)需要特定的模板格式才能正常工作。
-
PARAMETER stop指令:此指令用于定义停止词(stop words),当模型在生成过程中遇到这些词时,便会停止继续生成。这对于控制模型输出的长度和格式非常有用。
🔢复杂Modelfile 文件示例:
# 从本地GGUF文件创建(假设文件在当前目录)
FROM ./llama3.2-1b-instruct-q4_k_m.gguf
# 或者从已拉取的官方模型创建
# FROM llama3.2:1b-instruct# 设置系统提示词,定义模型角色
SYSTEM """
你是一个幽默的、乐于助人的AI助手,名字叫"小智"。
你总是以有趣的方式和用户交流,并且在回答技术问题时非常准确。
请始终使用中文与用户对话。
"""# 设置模型参数
PARAMETER temperature 0.8 # 创造性较高
PARAMETER num_ctx 4096 # 上下文窗口大小# 定义模板和停止词(以Llama 3为例)
TEMPLATE """
<|begin_of_text|><|start_header_id|>system<|end_header_id|>{{ .System }}<|eot_id|><|start_header_id|>user<|end_header_id|>{{ .Prompt }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>{{ .Response }}<|eot_id|>
"""
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|end_header_id|>"📜Modelfile文档参考: https://ollama.cadn.net.cn/modelfile.html
-
2)然后创建模型:
# 从当前目录的 Modelfile 创建模型
ollama create my-chinese-assistant -f ./Modelfile# 创建后即可像普通模型一样运行
ollama run my-chinese-assistant执行示例及界面参考:
- 在https://huggingface.co/OuteAI/OuteTTS-0.2-500M-GGUF/tree/main下载OuteAI/OuteTTS-0.2-500M-GGUF的文件“OuteTTS-0.2-500M-FP16.gguf”,并放在E:\ollama\models下
- 并在此目录下创建配置文件:
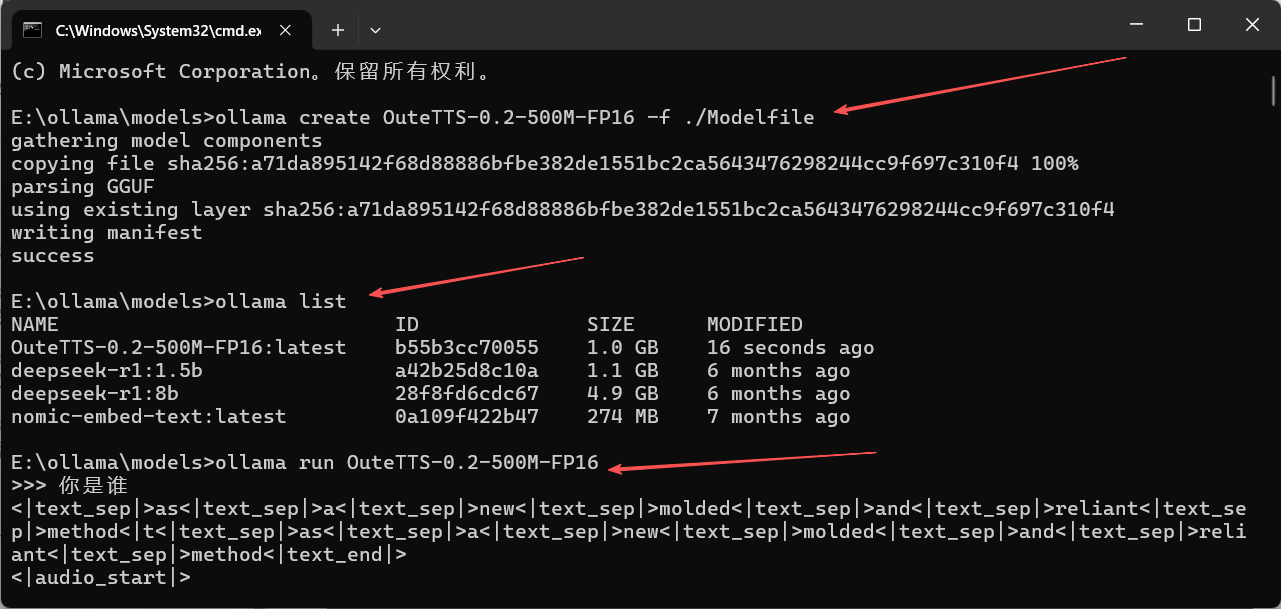
- 执行命令:
ollama create OuteTTS-0.2-500M-FP16 -f ./Modelfile
ollama run OuteTTS-0.2-500M-FP16执行界面如下:
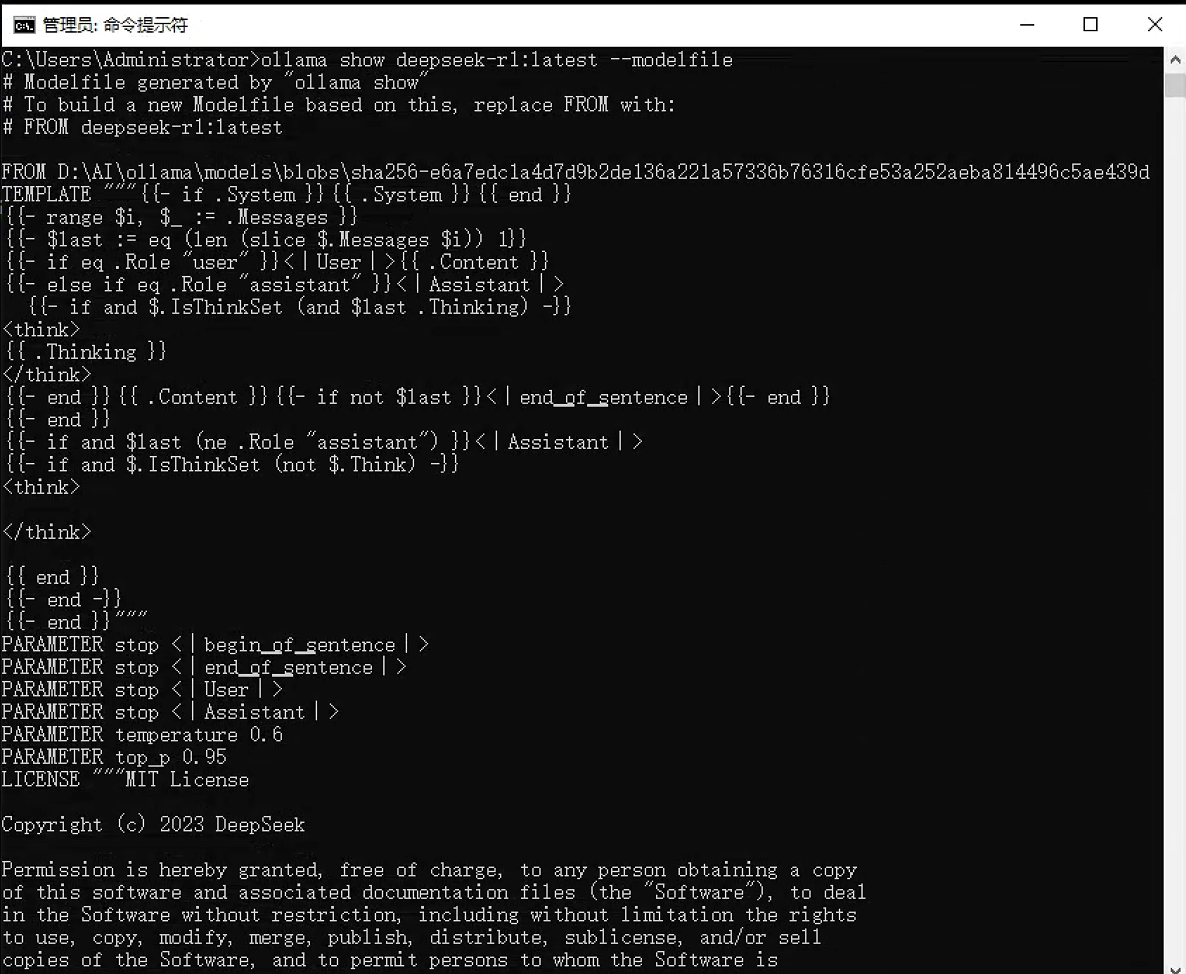
8. ollama show - 显示模型信息
功能:显示模型的详细信息,包括其 Modelfile 内容。
语法:ollama show <模型名> [选项]
选项:
-
--modelfile:显示模型的 Modelfile 内容 -
--parameters:显示模型参数 -
--system:显示系统提示词 -
--template:显示模板 -
--license:显示许可证信息
示例:
# 显示模型的完整信息
ollama show my-chinese-assistant# 仅显示 Modelfile 内容
ollama show my-chinese-assistant --modelfile# 显示模型参数配置
ollama show my-chinese-assistant --parameters执行界面参考:
三、高级与系统命令
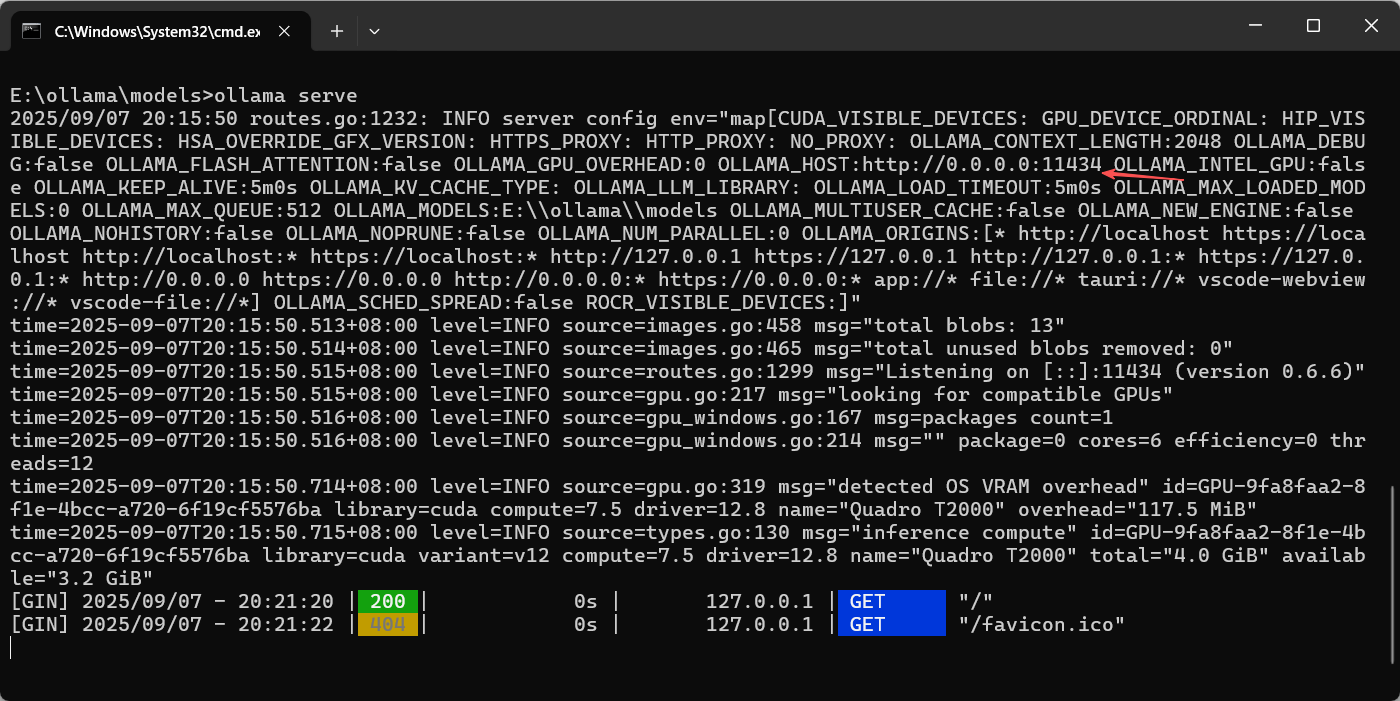
9. ollama serve - 启动API服务
功能:启动 Ollama API 服务器,使模型可通过 REST API 访问。
语法:ollama serve
说明:
-
通常作为后台服务运行,而不是手动启动
-
默认监听在
127.0.0.1:11434 -
可使用环境变量
OLLAMA_HOST更改监听地址
执行界面参考:
⚠️注意:如果ollama桌面程序已经运行,则ollama serve随之启动,再执行ollama serve命令,会提示冲突,如下界面所示,可以退出ollama桌面程序后,再运行ollama serve,这样仅供程序接口调用。

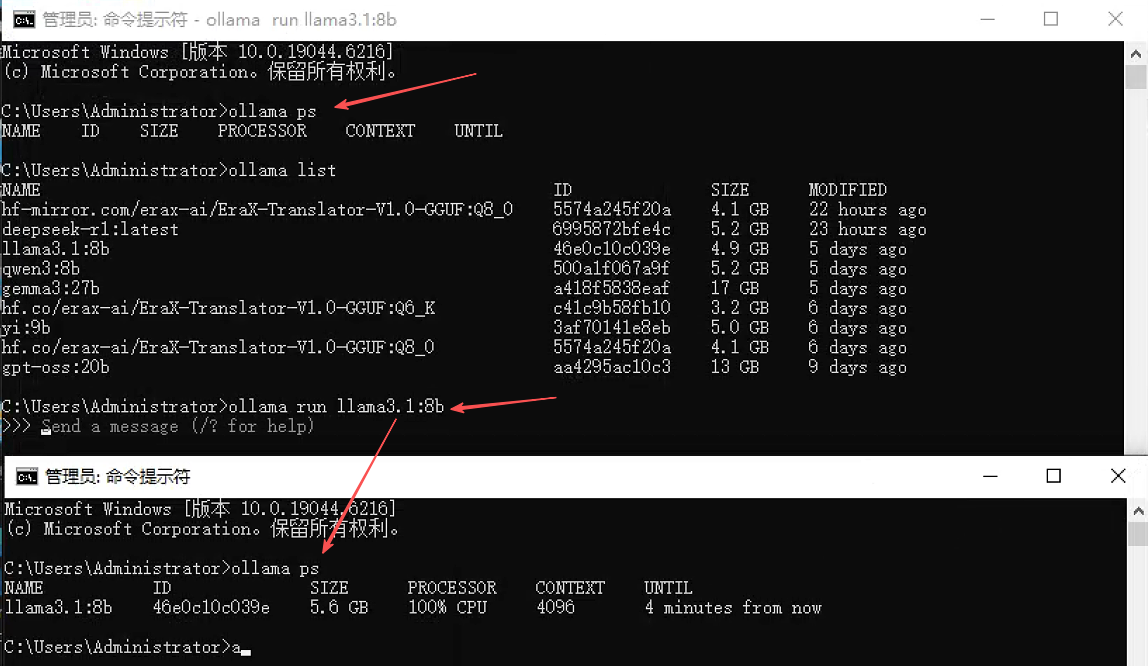
10. ollama ps - 显示运行中的模型
功能:显示当前正在运行的模型及其资源使用情况。
语法:ollama ps
执行界面参考:
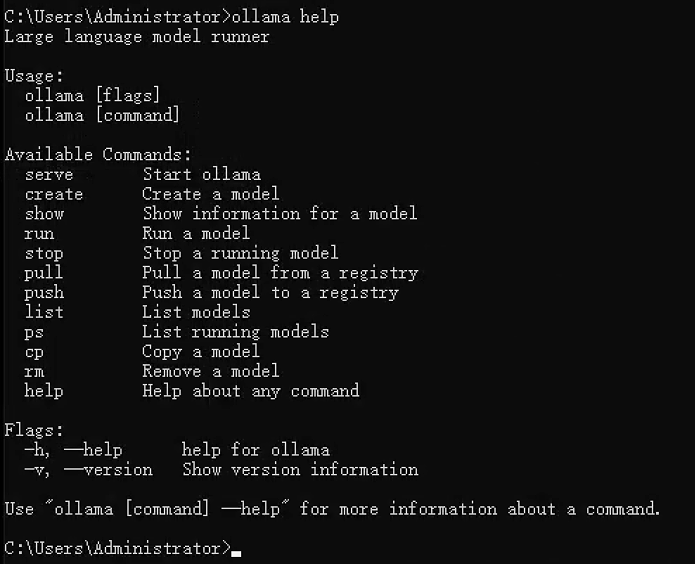
11. ollama help - 获取帮助
功能:显示帮助信息,可查看所有命令或特定命令的用法。
语法:
# 显示所有命令
ollama help# 显示特定命令的帮助
ollama help run
ollama help create执行界面参考:
12. 关闭 ollama
没有直接的关闭命令,通过快捷键 Win+X 打开任务管理器,点击“ 启动”,在进程中结束 Ollama 的任务,如果需要可以禁用 Ollama,不再随机启动。
四、环境变量配置
通过环境变量可以配置 Ollama 的各种行为:
| 环境变量 | 功能 | 示例值 |
|---|---|---|
OLLAMA_HOST | 设置API服务监听地址 | 0.0.0.0:11434 (允许远程访问) |
OLLAMA_MODELS | 设置模型存储路径 | /data/ollama/models |
OLLAMA_KEEP_ALIVE | 控制模型在内存中的保留时间 | 5m、2h、-1 (始终保留) |
OLLAMA_DEBUG | 启用调试日志 | 1 (启用) |
使用示例:
# 临时设置环境变量(Linux/macOS)
export OLLAMA_HOST=0.0.0.0:11434
export OLLAMA_KEEP_ALIVE=2h
ollama serve# Windows (命令行)
set OLLAMA_HOST=0.0.0.0:11434
ollama serve# 或者创建配置文件 ~/.ollama/config.json
{"host": "0.0.0.0:11434","keep_alive": "2h"
}五、故障排除与技巧
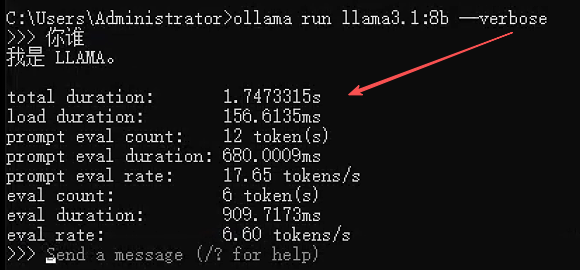
1. 查看详细日志
# 使用 verbose 模式查看详细输出
ollama run llama3 --verbose# 在Linux上查看服务日志
journalctl -u ollama -f执行界面参考:
2. 清理磁盘空间(Linux/macOS)
# 删除不再使用的模型
ollama list
ollama rm old-model-name# 清理临时文件(Linux/macOS)
rm -rf ~/.ollama/models/manifests/*✍️备注:Windows下,删除模型,我观察对应的模型文件也删除了,就不用额外清理了,大家可以通过删除模型前后,模型物理文件列表的变化,进行验证。
3. 模型文件默认位置
-
Linux/macOS:
~/.ollama/models/ -
Windows:
C:\Users\<用户名>\.ollama\models - 模型文件的实际位置
Windows下,在cmd,通过命令
set OLLAMA_MODELS查看有没有设置该变量,如果返回具体位置,则模型在此位置,否则在默认位置。
执行界面参考:

六、命令总结
按照不同的使用思路,在梳理一下各命令。
1. 模型管理命令
| 命令 | 用法 | 示例 |
|---|---|---|
| 创建模型 | ollama create <model_name> -f Modelfile | ollama create my-model -f ./Modelfile(Modelfile 定义模型架构、参数等) |
| 拉取模型 | ollama pull <model_name[:version]> | ollama pull llama3:7b(下载指定版本) |
| 列出模型 | ollama list | 显示本地模型名称、ID、大小、修改时间 |
| 查看详情 | ollama show <model_name> | 输出模型版本、参数、描述等 |
| 复制模型 | ollama cp <源模型> <新模型> | ollama cp llama3 my-llama3 |
| 删除模型 | ollama rm <model_name> | ollama rm llama3:7b(释放磁盘空间) |
2. 服务与运行命令
| 命令 | 用法 | 示例 |
|---|---|---|
| 启动服务 | ollama serve | 默认端口 11434,支持 --port 11435 自定义 |
| 停止服务 | ollama stop 或 pkill -f "ollama serve" | 强制终止可用 systemctl stop ollama(Linux) |
| 运行模型 | ollama run <model_name> [参数] | ollama run llama3 --temp 0.7 --max-tokens 500(调整温度、输出长度) |
| 查看运行模型 | ollama ps | 显示正在运行的模型及其状态 |
| 停止模型 | ollama stop <model_name> 或 Ctrl+D(交互界面) | 优雅终止指定模型 |
3. 会话与交互命令
- 交互命令:
/load <model>:加载模型或会话。/save <model>:保存当前会话状态。/clear:清除上下文历史。/bye:退出会话。/set system "提示词":设置系统提示(如角色、格式)。/set format json:强制输出 JSON 格式。



)





)


,IT营业同步招募)






