传统的仓库建模理论(如维度建模)仍然是基石,但大数据的“4V”特性(Volume, Velocity, Variety, Value)要求我们对这些方法进行演进和补充。
以下是结合大数据知识体系对仓库建模方法的总结:
一、核心目标:为何建模?—— 大数据仓库的挑战
在大数据环境下,建模的终极目标依然是降低成本、提高效率、保障质量,但具体表现为:
- 降低计算成本:避免在PB级数据上做低效的
JOIN,节省大量CPU和内存资源。 - 降低存储成本:通过合理的模型设计,结合压缩格式(如Parquet,ORC),减少巨额数据存储费用。
- 提高查询效率:为Ad-Hoc查询、BI报表、数据服务提供快速响应,支持实时/近实时分析。
- 管理数据复杂性:应对结构化、半结构化(JSON,XML)、非结构化(日志,文本)数据的统一处理。
- 保障数据质量与一致性:在复杂、多源的数据流转中,确保“单一事实来源”,建立可靠的数据血缘。
二、核心方法论:经典理论的演进与并存
大数据领域没有推翻经典,而是让其各司其职。
| 建模方法 | 大数据中的定位与演进 |
|---|---|
| 范式建模(3NF) | 主要应用于ODS/操作数据层。在大数据平台中,ODS层常作为贴源数据的存储区,尽可能保留原始细节,用于数据追溯和细节查询。其范式程度可能降低,常采用拉链表等技术处理缓慢变化维。 |
| 维度建模(Kimball) | 仍然是大数据仓库核心DWD/DWS/ADS层的黄金标准。其“事实表-维度表”的星型/雪花型模型理念,与列式存储(Parquet/ORC)和MPP计算引擎(Spark, Presto, Doris)完美契合,能极大提升查询性能。 |
| Data Vault | 在大数据环境中获得新生。其Hub-Link-Satellite的模型设计高度灵活,易于应对源系统变更和历史数据追踪,非常适合作为EDW核心层的模型,用于整合多源、异构的海量数据。 |
为了更直观地展现这些方法论如何在一个现代大数据数据仓库中协同工作,可以参考以下的分层架构图:
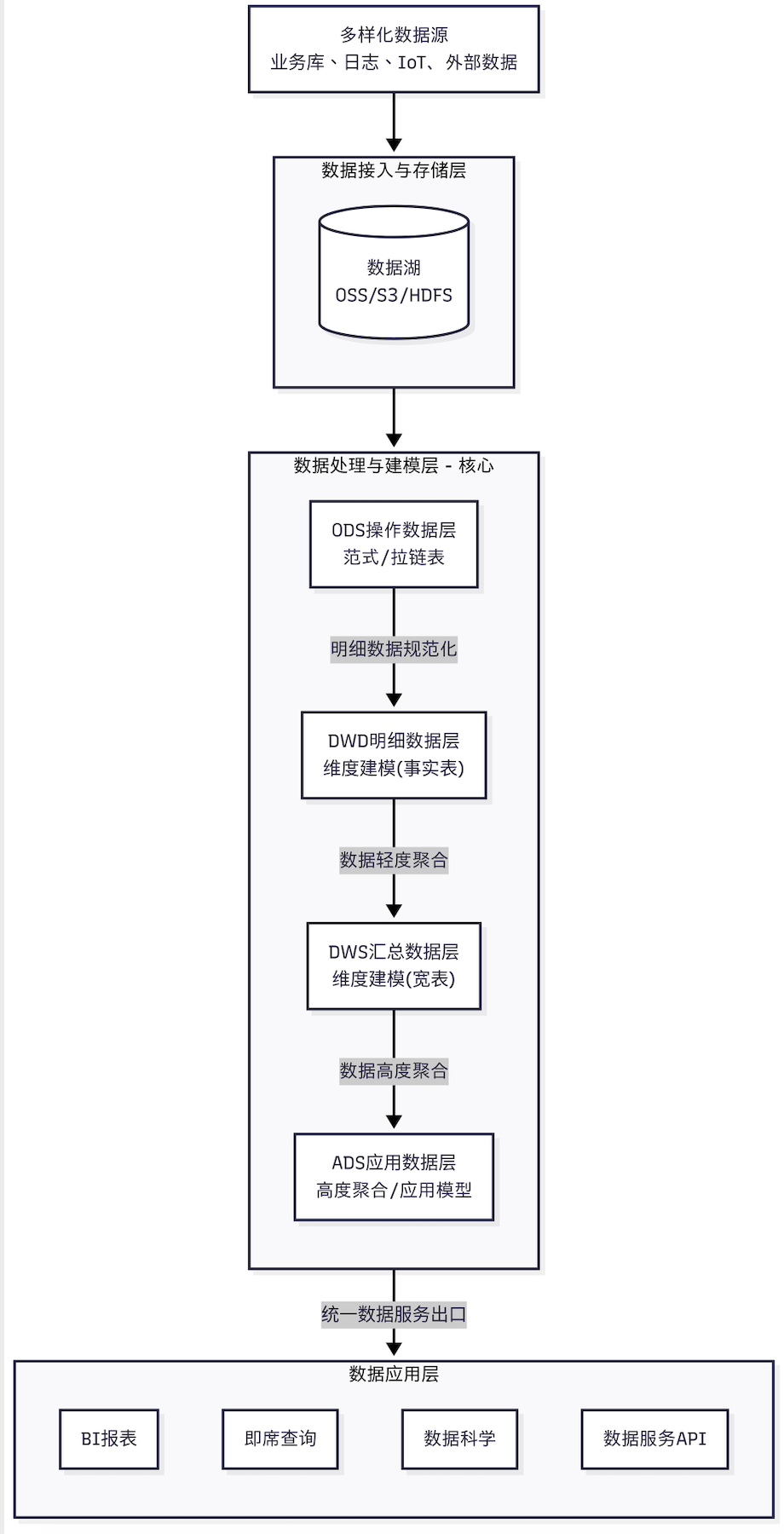
三、关键技术:赋能大数据建模的基石
大数据模型的高效运转,依赖以下关键技术:
-
列式存储 (Parquet, ORC)
- 与维度建模绝配:查询通常只访问少数几列(维度和度量),列存可以极速扫描所需数据,避免读取整行。
- 高效压缩:同一列数据类型一致,压缩比极高,大幅降低存储成本。
- 谓词下推:在扫描时提前过滤数据,进一步减少I/O。
-
分布式计算框架 (Spark, Flink)
- 模型构建的引擎:负责执行海量数据的
ETL/ELT任务,将原始数据加工成规范的模型层(DWD, DWS等)。 - 处理多样性数据:Spark等引擎可以同时处理结构化和半结构化数据,满足复杂的数据整合需求。
- 模型构建的引擎:负责执行海量数据的
-
Lambda/Kappa 架构
- 模型数据的生成方式:
- Lambda:批处理层生成精准、全面的批处理模型(如日粒度的DWD表);速度层生成近实时的增量数据模型。两者合并服务于应用。
- Kappa:完全基于流处理构建模型,简化架构,更适合实时性要求极高的场景。
- 模型数据的生成方式:
-
数据湖与湖仓一体 (Data Lakehouse)
- 模型的存储与载体演进:传统数仓模型扩展到数据湖上。
- 流程:数据湖(Delta Lake, Apache Iceberg, Hudi)存储原始数据和模型各层数据,在其上构建数仓模型,同时支持BI、ML等多种工作负载,实现了低成本存储与高性能分析的统一。
四、实践原则:大数据建模的“ Dos & Don’ts”
- 维度建模优先:对于大多数分析场景,星型模型仍然是性能和易用性的最佳平衡点。
- 深度分层,职责单一:采用分层设计(如ODS -> DWD -> DWS -> ADS),每层职责明确,便于管理和维护。
- ODS:贴源,备份。
- DWD:数据清洗、规范化、维度退化,形成明细事实表。
- DWS:轻度汇总,构建宽表,减少后续重复计算。
- ADS:面向具体应用,高度聚合,无需二次计算。
- “大宽表”策略:在DWS/ADS层,预先将常用维度退化(Denormalize) 到事实表中,形成宽表,用存储换计算,彻底避免查询时的大表
JOIN,这是大数据查询优化的关键手段。 - 分区与分桶:利用时间分区和字段分桶,极大缩小查询数据扫描范围,提升性能。
- 数据治理融入建模:
- 元数据管理:记录模型的表结构、血缘关系、业务含义。
- 数据质量:在模型ETL过程中嵌入稽核规则(如非空检查、枚举值检查、波动检查)。
- 生命周期管理:自动清理过期或无效的模型数据。
总结
在大数据知识体系下,数据仓库建模方法:
- 核心思想未变:维度建模依然是追求查询性能和易用性的核心方法论。
- 技术载体进化:基于数据湖、使用列式存储、通过分布式计算构建。
- 架构模式扩展:采用分层设计和批流一体的方式加工数据。
- 管理要求更高:必须与数据治理紧密结合,才能保障大规模数据模型的有效性。
最终,所有建模工作都是为了将庞大、原始、混乱的数据,有序地组织成易于理解和高效访问的信息,从而释放大数据的价值。



与arm-linux-gcc、ARMGCC、ICCARM(IAR)、C51编译器的兼容性)


》)











![[Wit]CnOCR模型训练全流程简化记录(包括排除BUG)](http://pic.xiahunao.cn/[Wit]CnOCR模型训练全流程简化记录(包括排除BUG))
实战:鸢尾花数据集处理技巧)