前面的篇章已经详细讲解了线条约束、三维关系与空间深度、人体姿态等几类controlnet的功能与应用,本节内容将对通过controlnet对图像的结构理解及控图效果。
| 序号 | 分类 | Controlnet名称 | 备注 |
| 1 | 线条约束 | Canny(硬边缘) | 约束性强,可以识别详细线条 |
| SoftEdge(软边缘) | 柔和的线条 | ||
| MLSD 直线、最小线段检测 | 主要用于建筑空间 | ||
| Lineart 线稿提取 | 粗细不同的线条 | ||
| Scribble 涂鸦 | 粗略线条、发挥空间大 | ||
| 2 | 三维关系、 空间深度 | Depth 深度 | 空间层次关系 |
| Normal 法线贴图 | 纹理效果常用 | ||
| 3 | 人体姿态、手势与表情 | Openpose 姿态控制 | 姿势、表情、手势控制 |
| 4 | 图像风格转换 | Shuffle 随机 | 打乱图片元素重新组合 |
| IP-Adapter (图像)风格迁移 | 参考图像画风、换脸等 | ||
| T2l-Adapter (文字转图)风格迁移 | 参考原图画风 | ||
| Reference 参考图引导 | 模仿原图绘画 | ||
| Instant-ID 换脸 | 人物换脸 | ||
| 5 | 图片修复与编辑 | Recolor 重上色 | 老照片修复 |
| Inpaint重绘 | 类似于局部重绘,但融合效果更好 | ||
| Tile 分块 | 分块重采样,细节方法 | ||
| 6 | 结构理解 | Seg 语义分割 | 根据色块代表不同含义 |
| 7 | 其它 | InstructP2P 指令式编辑 | 变换场景、特效 |
| Revision 图像修订 |
1 seg(Semantic Segmentation 语义分割)
1.1 seg语义分割概述
seg语义分割对图像预处理的结果不是线条,而是在将画面划分为不同颜色的色块,且不同颜色的色块分别被赋予不同的物体含义,由此可以将图像中物体的内容固定住,在生图期间可以根据色块内容性质画出同类型的物体,不会出现内容结构的偏差。
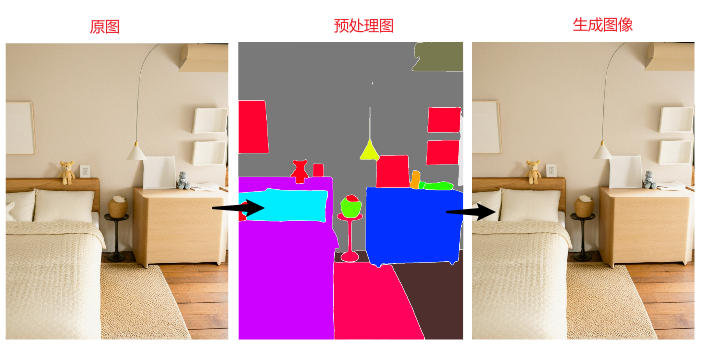
案例图不同区块的物体赋予了不同的颜色,在生成图像时对应色块就会生成特定的对象,从而实现更加准确的内容还原。
1.2 seg的预处理器
seg有4种预处理器:of_ade20k、uf_ade20k和of_coco、以及用于动漫面部识别的anime_face。(mobile_sam用于移动设备)
of代表oneformer算法,uf代表uniformer算法;
ade20k和coco是两种色值数据集;
of_ade20k、uf_ade20k和of_coco是两种算法和两种协议的组合,三款预处理器的识别效果有一定差距,预处理器测试效果对比如下,可以看出oneformer算法优于uniformer算法(uniformer算法中存在色块未识别元素):




原图 of_ade20k of_coco uf_ade20k
anime_face主要用于动漫人物面部的识别,预处理器见本节课课件,下载后安装地址:
根目录\extensions\sd-webui-controlnet\annotator\downloads\anime_face_segment\UNet.pth
下面案例对动漫人物进行识别,采用of_ade20k、uf_ade20k和of_coco三类预处理器仅可以将人物整体识别成一个整体色块,而anime_face则可以更细致地识别动漫人物具体形象。

ade20k和coco是两种色值数据集,不同的色值代表不同的物体,两种数据集所分析的图像和代表的色值数不同,两种色值数据集对应的颜色对照表文件见附件。
1.3 seg应用示例
Seg语义分割在controlnet中常用作以下两种功能:
1.3.1固定色块不改变区域内容,生成不同风格图像
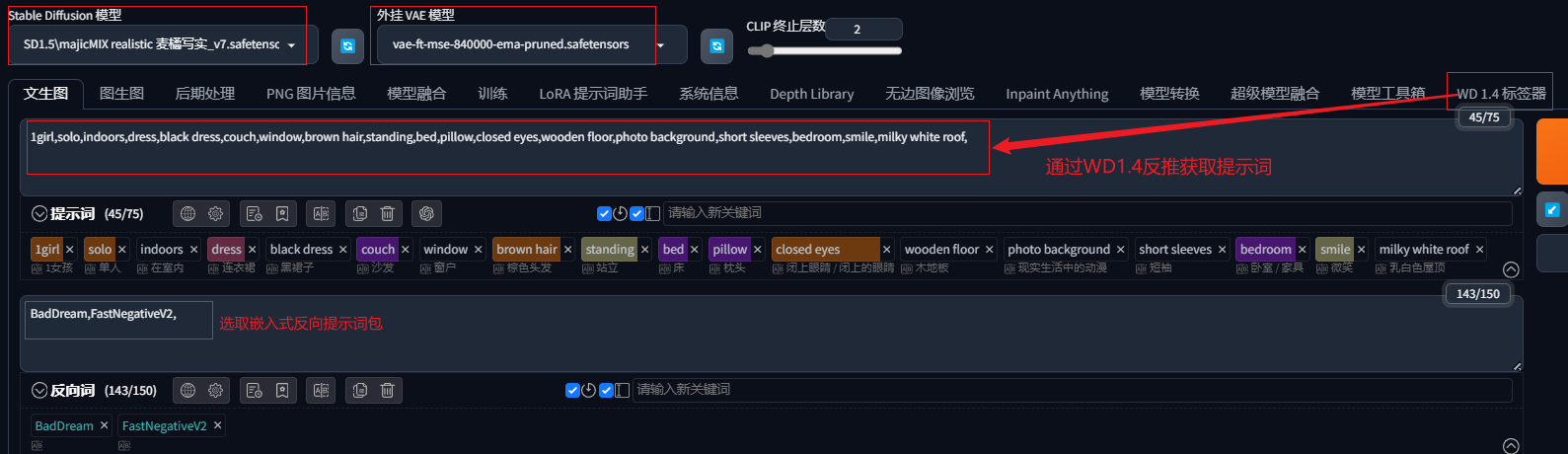
选择一款目标风格的大模型,通过WD1.4反推原图获得提示词,并发送到文生图:
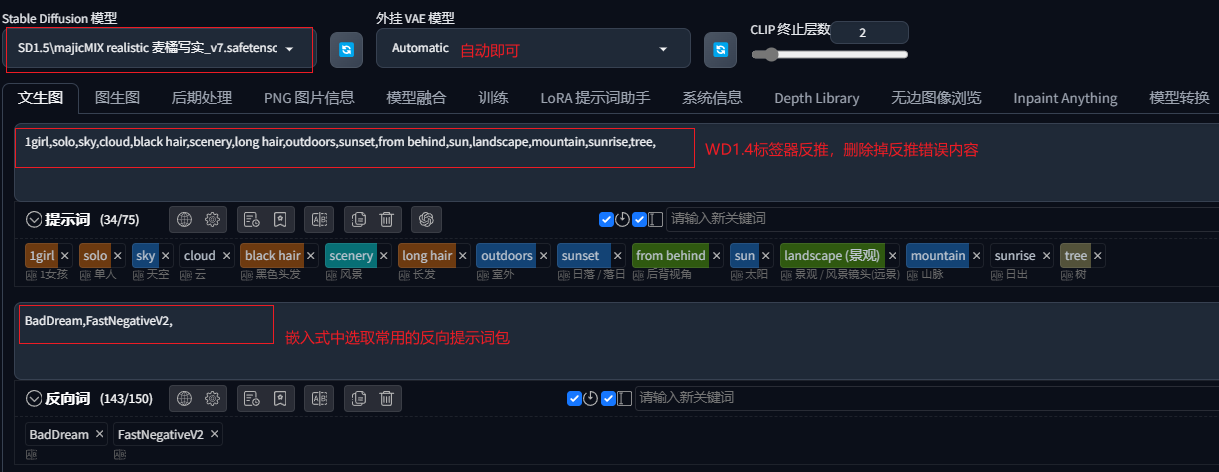
设置出图参数,图片尺寸由controlnet中同步获取。
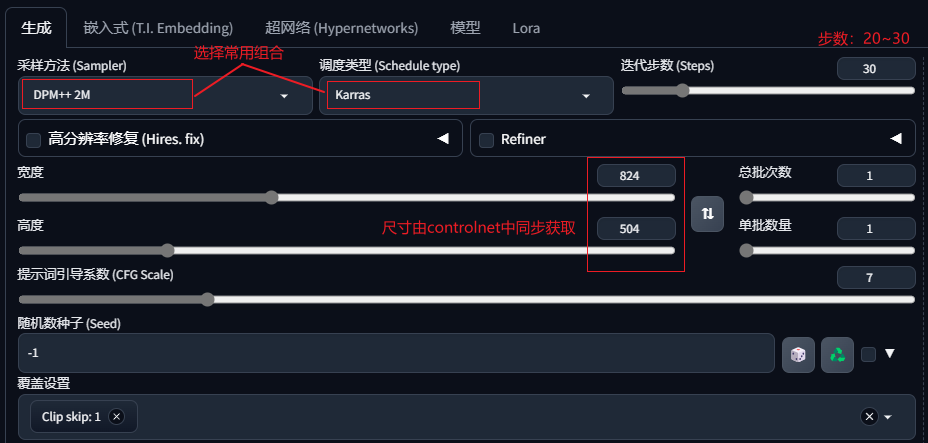
设置controlnet
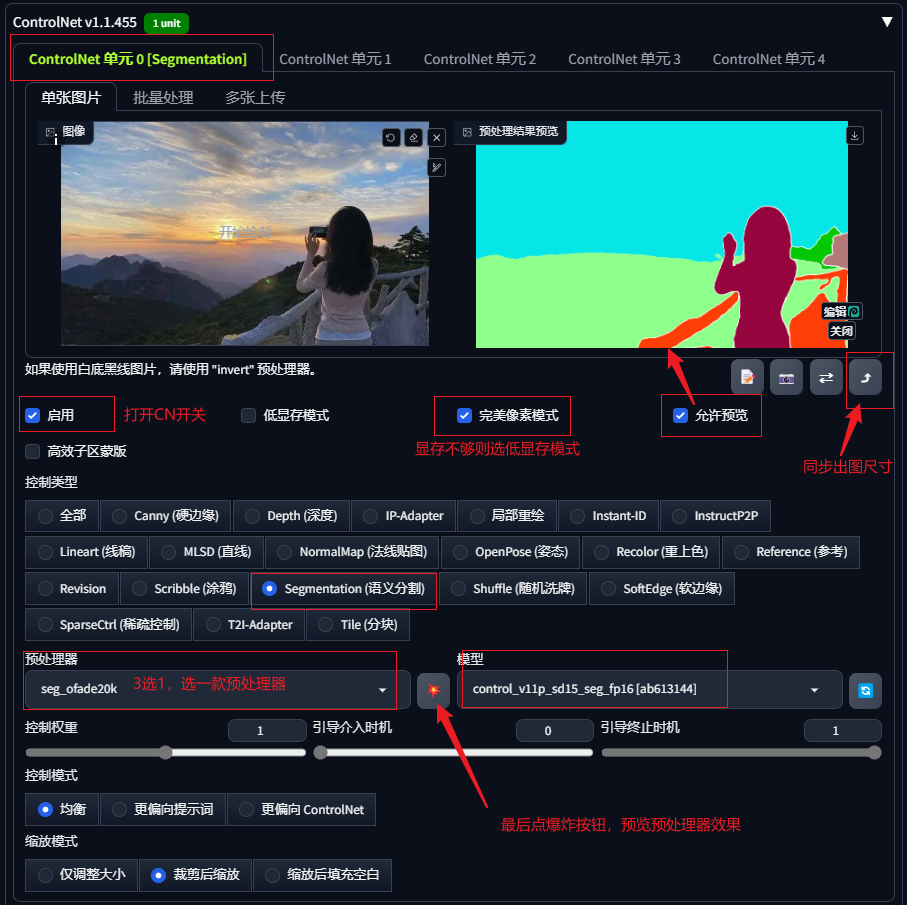

色块在线编辑,点击预处理效果图的右下角处的编辑按钮,进入类似在线PS功能界面对效果图进行在线编辑,可以修改色块的范围边界,进而调整原图的元素结构。
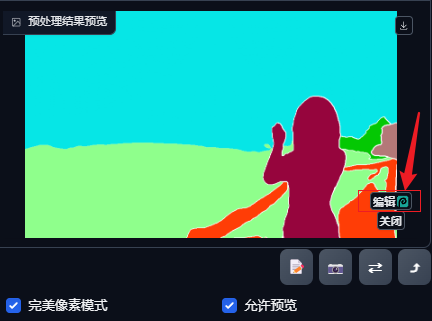
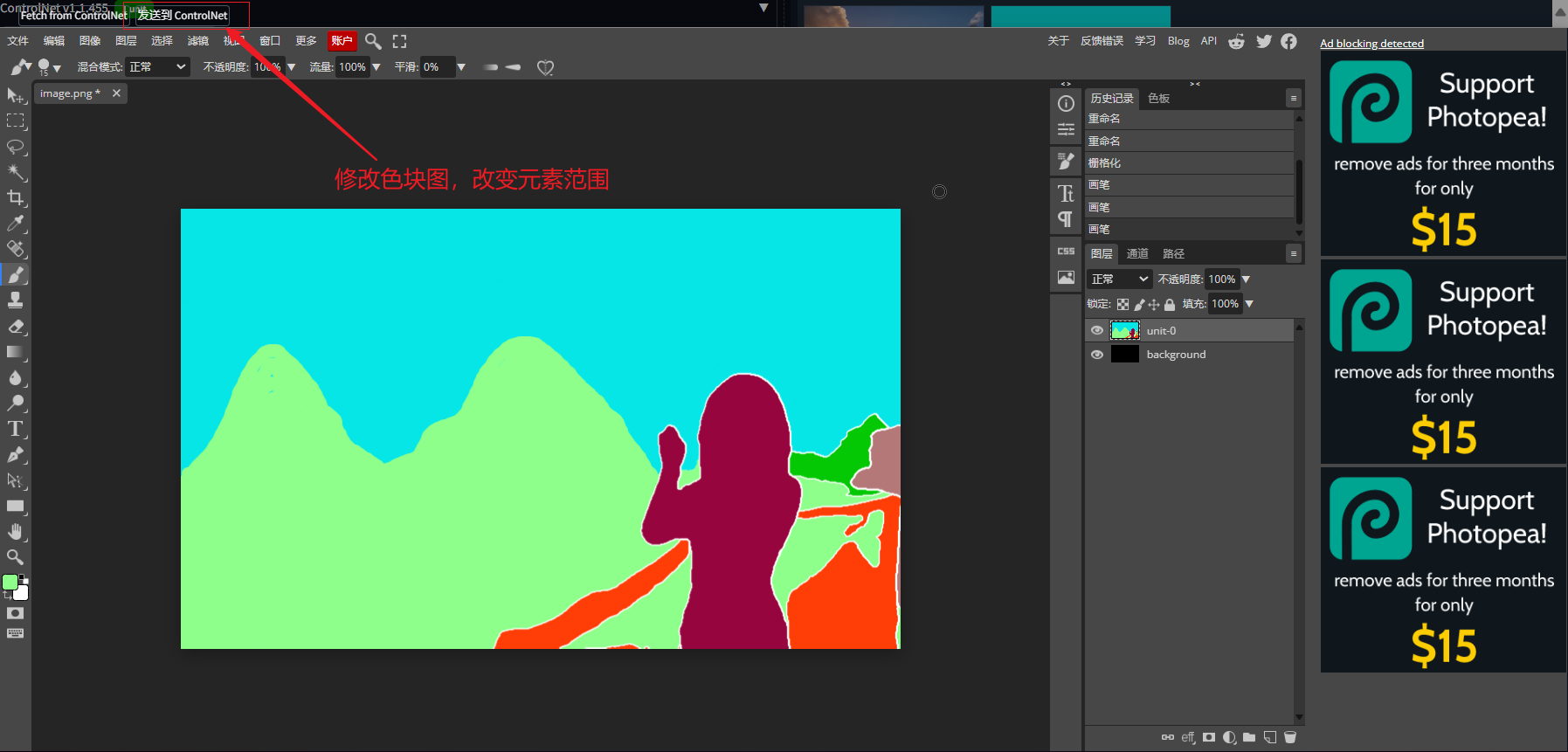
将修改后的色块图直接发送到预处理结果预览处,其余参数均无需调整,直接生图即可;也可以下载修改后的色块图,将色块图上传至controlnet,预处理器选择none,点击爆炸按钮预览,再进行生图;
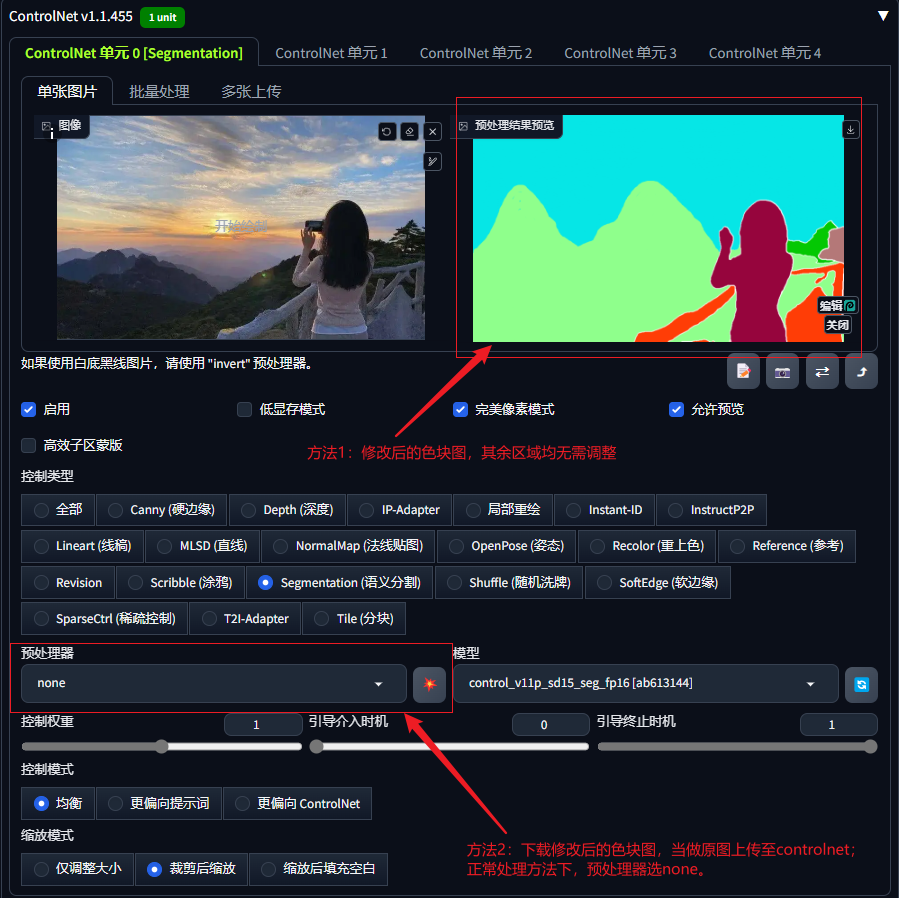


1.3.2通过添加色块,在原图中增加新元素;
可以通过贴图形式将目标物体“贴”到原图中,再进行seg预处理获得色块图;也可以将预处理后的色块图下载下来,通过PS等工具将该区域修改为目标物体的色值,再次生成图像时,该色块即可生成指定的物体;
案例:在卧室中增加人物
先通过贴图方式,将人物图放置到卧室环境图中,获取新的底图。

选择大模型及VAE;通过WD1.4反推修改后的图像获得提示词,发送到文生图,后续操作和上文相同。
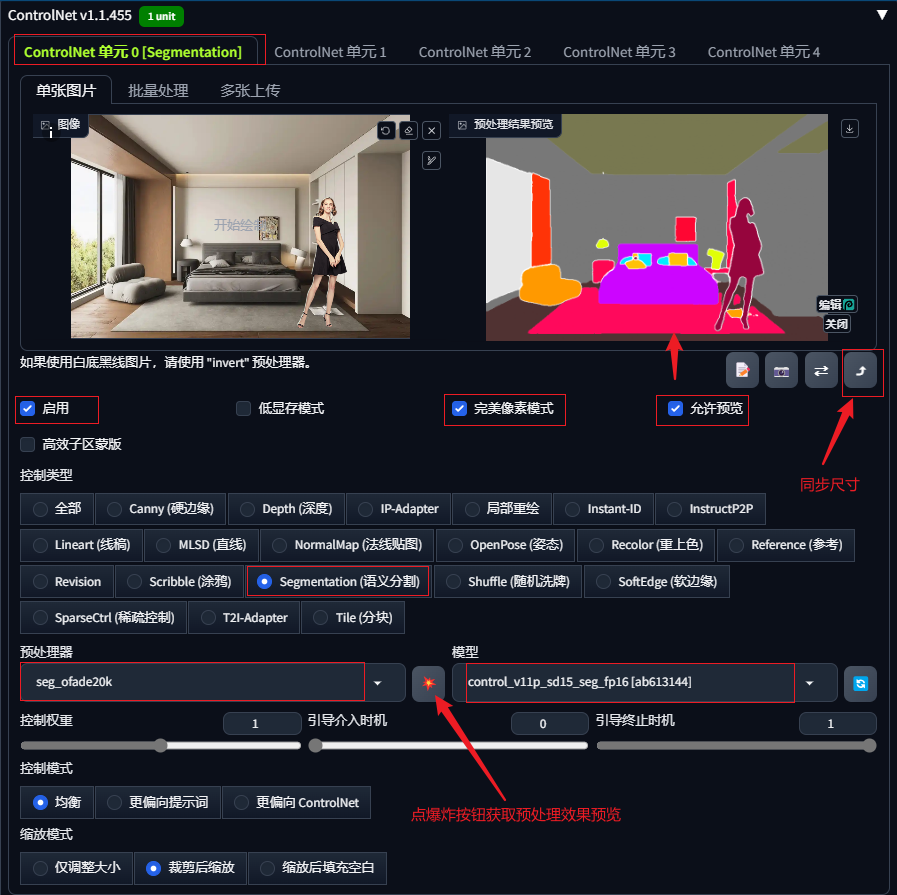

也可以根据色块对照表采用PS画出色块图,再使用文生图+controlnet的seg功能对应生图,即可提前框定图像不同区域内容,使图像更有可控性。
2 InstructP2P 指令式编辑
2.1 InstructP2P概述
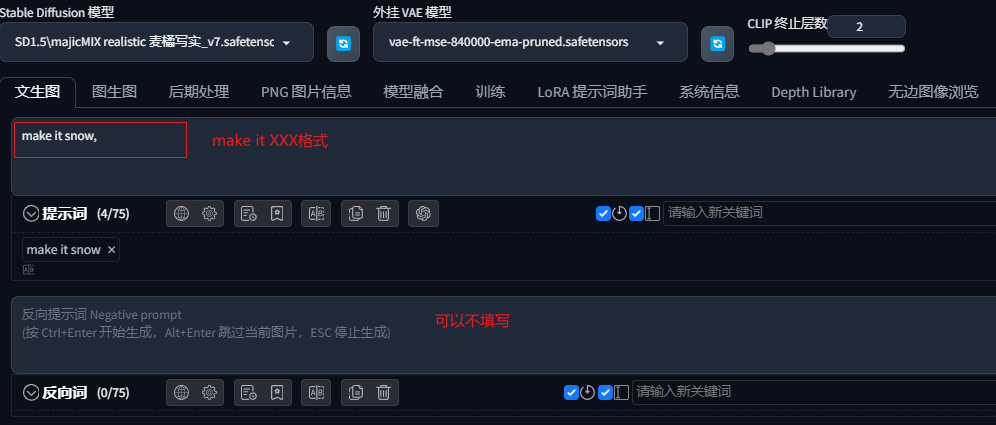
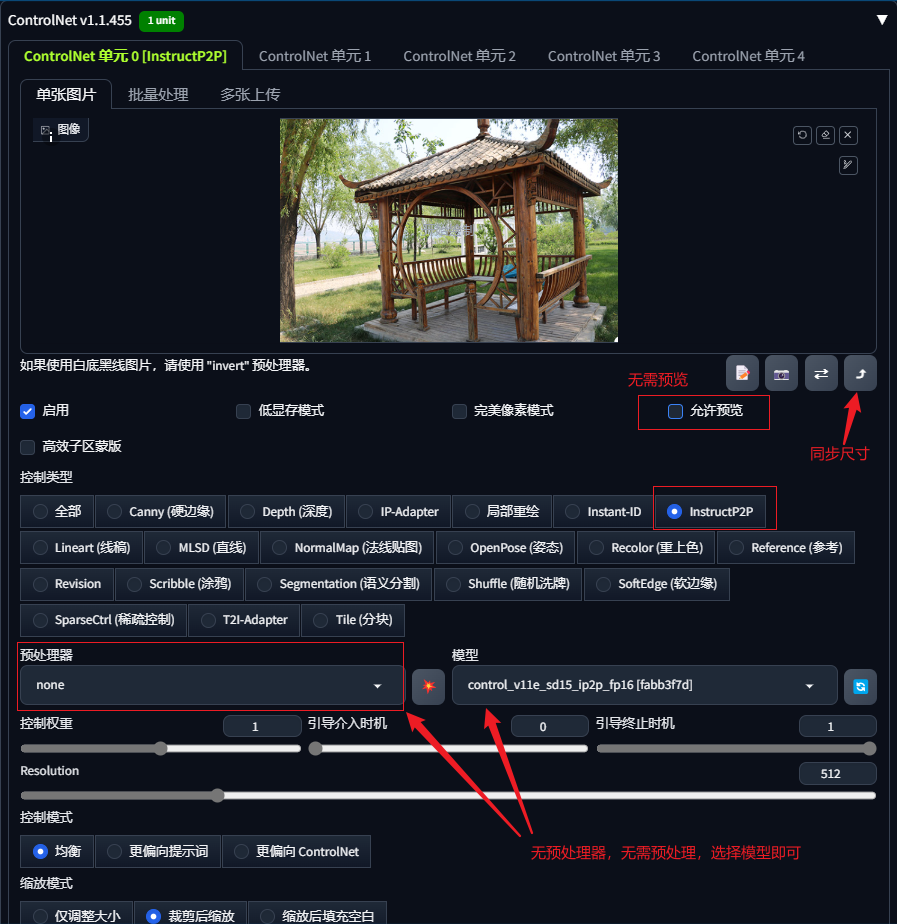
InstructP2P 的全称为 Instruct Pix2Pix 指令式编辑生图,它的原理基本与图生图相同,是直接参考底图内容进行生图,所以使用时无需进行预处理,预处理器选择无即可。
InstructP2P是一种将文字指令转化为图像编辑的功能,它可以识别出底图的内容并根据文字指令对图像进行修改。
control_v11e_sd15_ip2p模型下载后放入:根目录\models\ControlNet文件夹中
huggingface.co/lllyasviel/…
2.2 应用实例
InstructP2P经常被用来给图像增加一些特效、改变环境等,日常使用时用到的频率并不高。提示词中无需描述其它内容,只需要遵守简单的指令格式:
提示词书写格式为:make it XXX
例:让图片中的环境:下雪//变成春天/着火
提示词栏填写:make it XXX


make it snow make it burning
3 Revision 图像修订
3.1 revision概述
Revision是1.1.400及更新版本ControlNet新增的功能,仅适用于SDXL版本的大模型。
Revision主要通过对图像内容进行理解并使用获取到的图片信息进行生图,可以将它看做是一种跳过反推提示词再使用提示词生图步骤,直接使用图片信息进行生图的工具。信息的转译会导致信息流失,比如WD1.4标签器并不能完整概括图片中所有元素,而Revision由图片直接转成embedding,跳过中间文字的转译,可以携带更多的原图信息。
Revision算法可以单独用于图像生成,也可以与提示词Prompt组合使用,对应的也共两款预处理器,revision_clipvision(作为补充)及revision_ignore_prompt(忽略原有提示词)。
3.2应用示例
3.2.1 不填写提示词,仅使用revision:
选择XL版本大模型,正向提示词、反向提示词均不填写,打开controlnet,上传底图,选择revision。
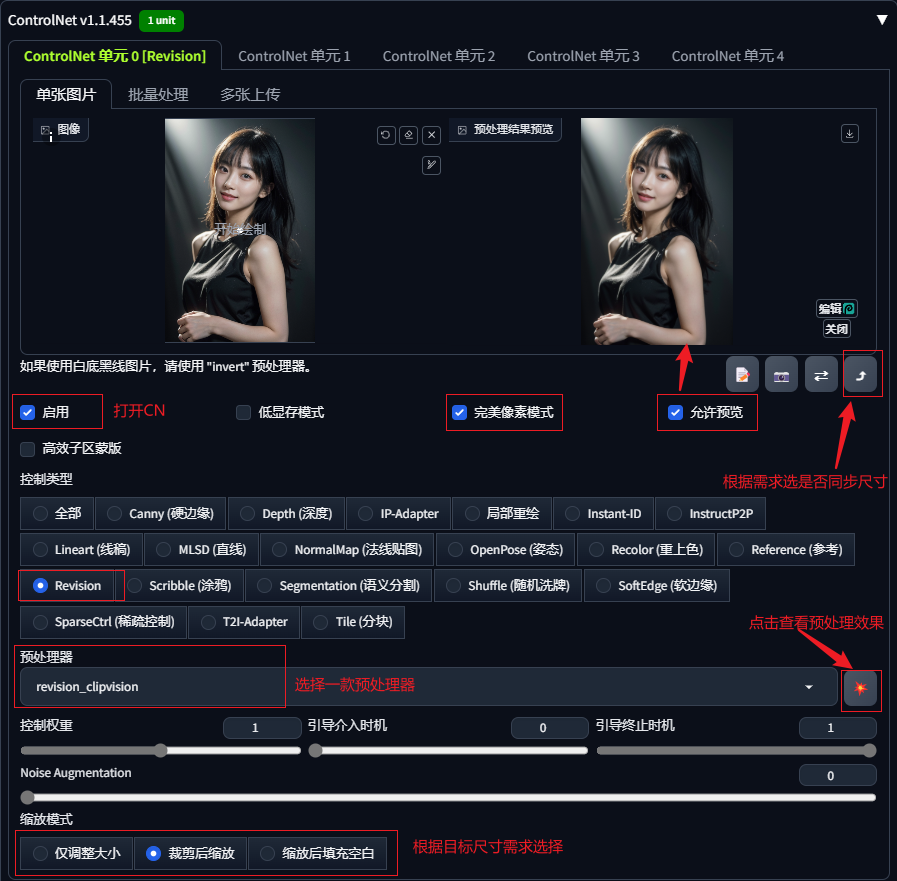
通过出图结果可以看出在不填写提示词的情况下,两款预处理器出图效果几乎没有区别,都可以参考原图中元素进行生图。

3.2.2 有提示词情况下两款预处理器效果对比
我们在正向提示词中填写与原图特征不一致的描述,改变或增加一部分人物关键特征
正向提示词:1 girl,long red hair,blunt bangs,necklace,earrings,
反向提示词:DeepNegative_xl_v1,

clipvision预处理器作为提示词的补充,和提示词一起参与图像生成;
ignore_prompt预处理器则完全忽略提示词的作用,仅使用图片信息进行图片生成;
3.3注意要点
(1)提示词的修改应该基于原参考图基础,变化过大则生成的图像有可能与参考图无关联。
(2)Revision是一种算法,没有额外的训练模型,直接选择预处理器即可使用。
(3)Noise Augmentation噪声增强可以理解为提示词对出图的影响程度,该值越低则controlnet的参考图对出图的影响越大,该值越高则提示词对出图的影响越大,controlnet的参考图影响越小。
4 多个controlnet同时应用
由于图像画面结构和内容复杂,使用单一的controlnet可能无法达到我们预期的效果,此时我们可以同时使用两个或者多个controlnet同时对出图进行控制。
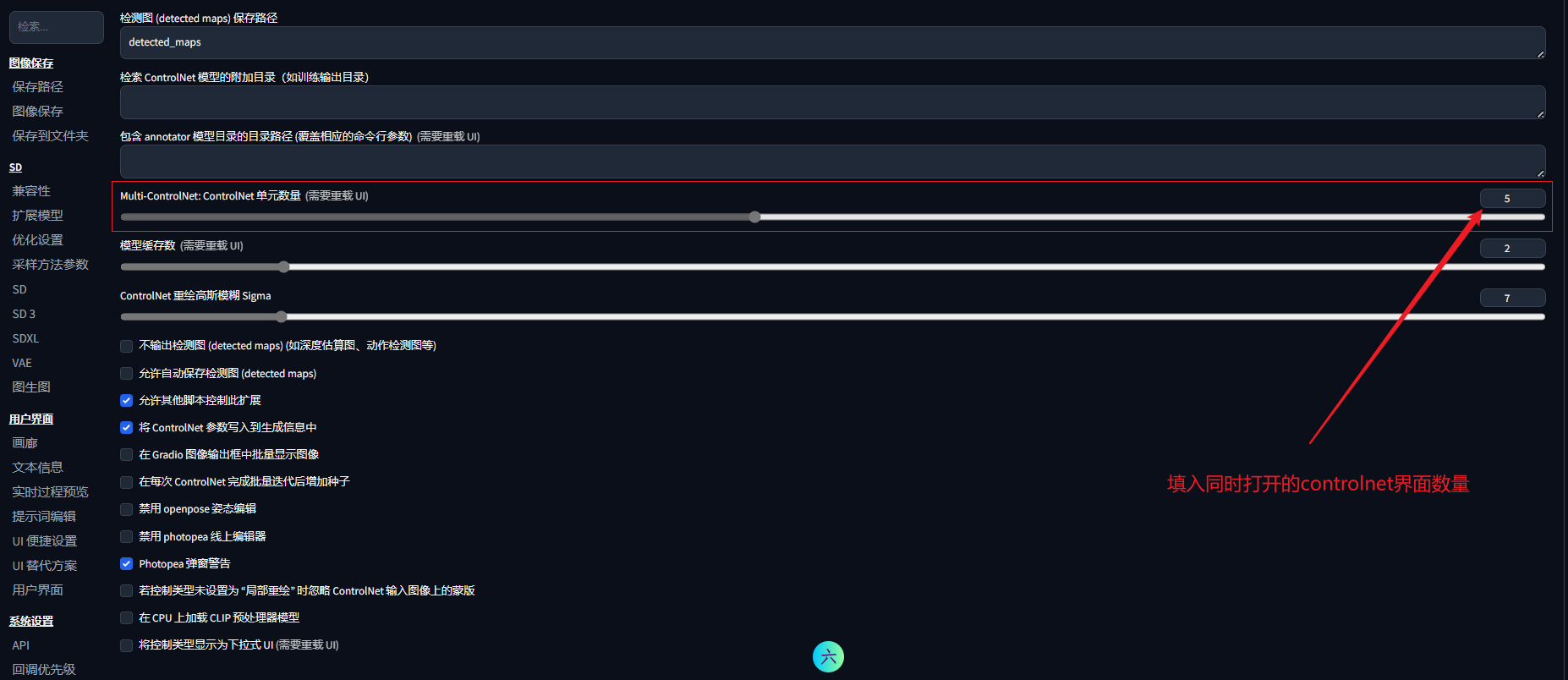
如果你的webUI界面中controlnet功能选项卡中只有1个controlnet,需要先点击“设置”,找到左侧的controlnet,将controlnet单元数量设置为你需要的数量(一般3~4即可),重载webUI即可看到多个controlnet选项。
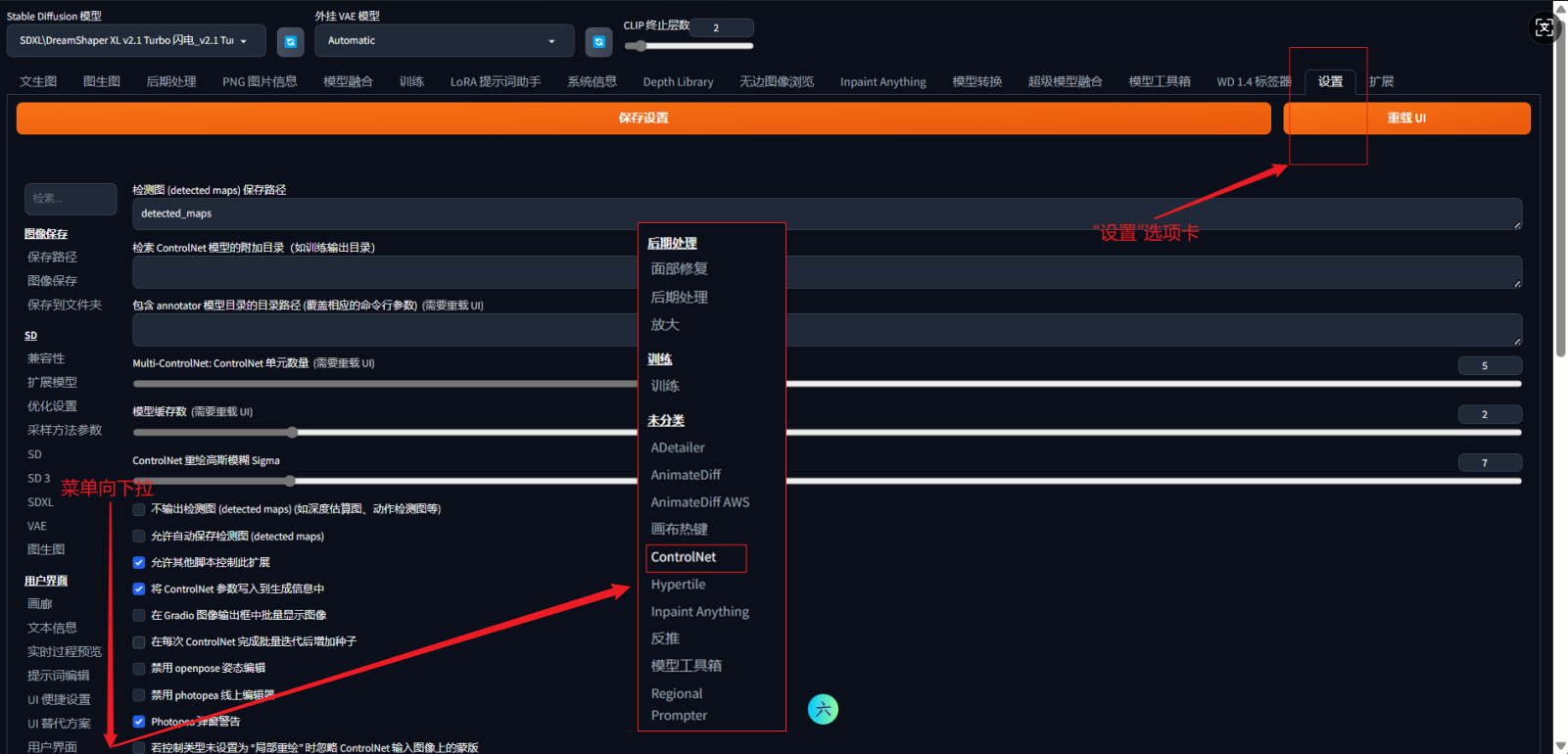
可以通过调整每个controlnet的控制权重及引导介入/终止时机
案例:生成一张图像,参考图1中的人物姿势,参考图2中的绘图色彩


第一步,选择一款大模型,填入简单提示词,调整出图参数
正向提示词:1 girl,
反向提示词:(无)
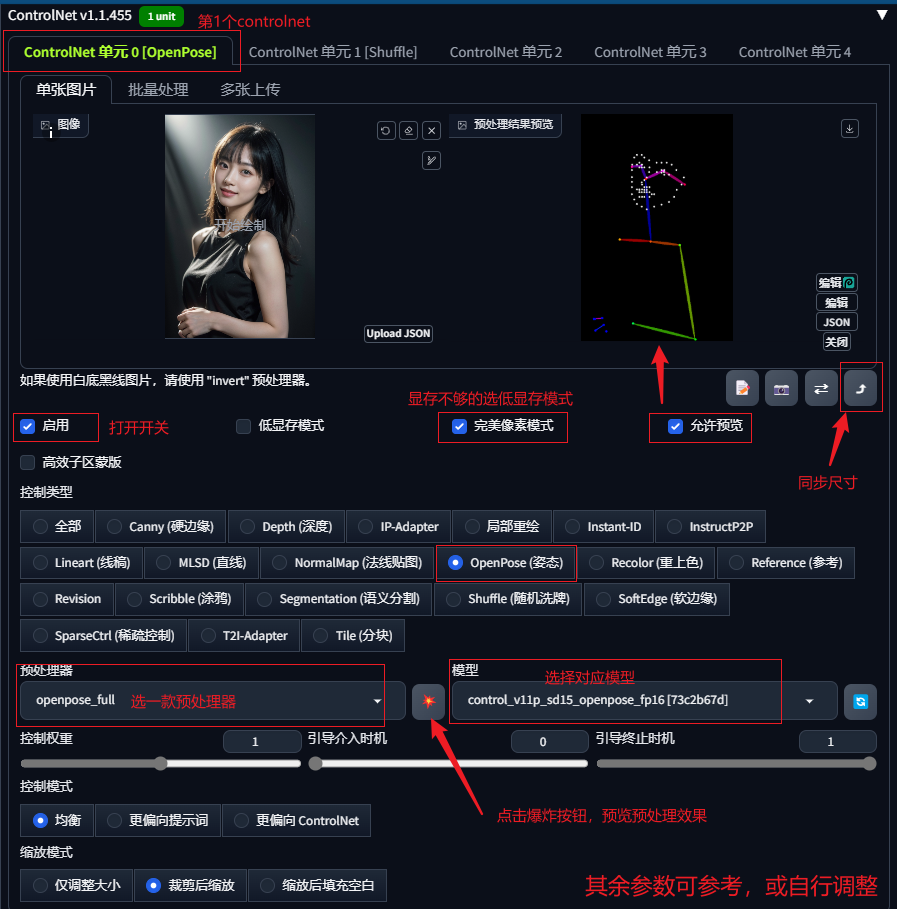
第二步:在controlnet 0中上传人物姿势参考图,选择openpose,通过预处理器获取人物姿态,调整权重等参数。
第三步:在controlnet 2中上传参考的风格图,选择IP-Adapter,预处理,调整权重等参数;
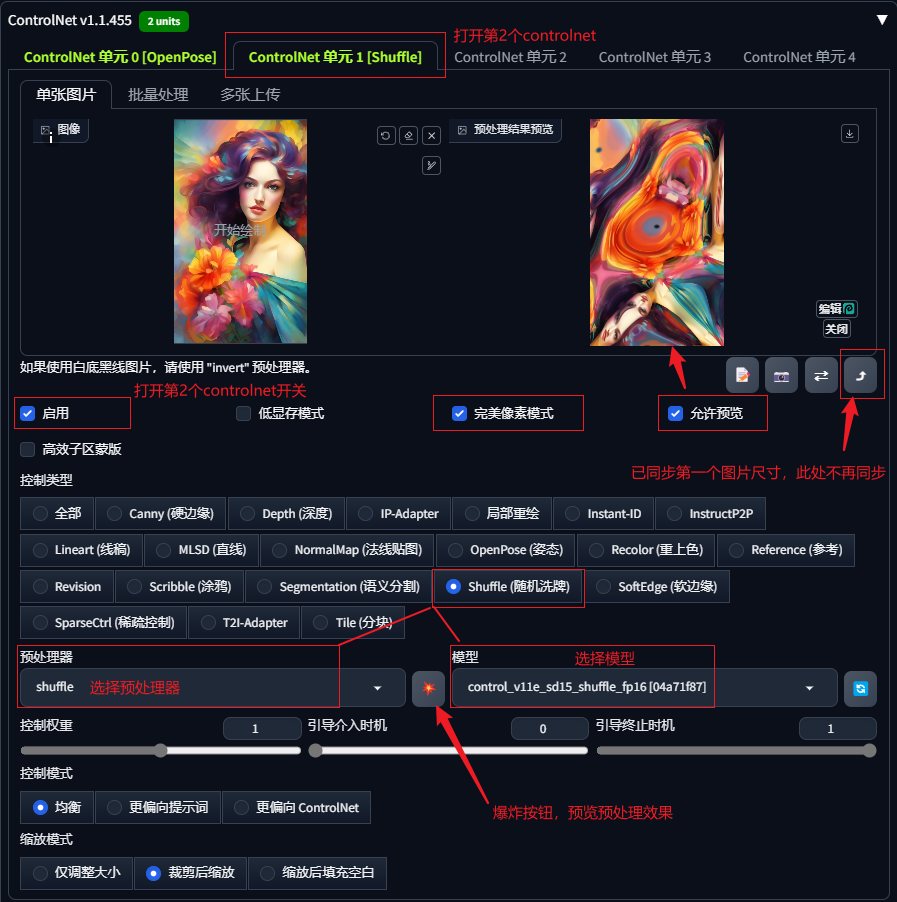
生成图像如下,可以看到在没有额外提示词的情况下,很好地遵循了图像1人物的姿势,图像2的画面色彩元素。

这里分享webUI的本地整合包资源,个人自用的整合包(超全插件及模型,本节课程所有涉及的模型均可在对应文件夹中找到下载)。
整合包形式,无需安装,Windows系统下载打开即用。
「webui全能包(内置超全插件、模型)--100G左右」https://pan.quark.cn/s/3647679a1966
欢迎正在学习comfyui等ai技术的伙伴V加 huaqs123 进入学习小组。在这里大家共同学习comfyui的基础知识、最新模型与工作流、行业前沿信息等,也可以讨论comfyui商业落地的思路与方向。 欢迎感兴趣的小伙伴,群共享资料会分享博主自用的comfyui整合包(已安装超全节点与必备模型)、基础学习资料、高级工作流等资源……
致敬每一位在路上的学习者,你我共勉!Ai技术发展迅速,学习comfyUI是紧跟时代的第一步,促进商业落地并创造价值才是学习的实际目标。

——画青山Ai学习专栏———————————————————————————————
零基础学Webui:
https://blog.csdn.net/vip_zgx888/category_13020854.html
Comfyui基础学习与实操:
https://blog.csdn.net/vip_zgx888/category_13006170.html
comfyui功能精进与探索:
https://blog.csdn.net/vip_zgx888/category_13005478.html
系列专栏持续更新中,欢迎订阅关注,共同学习,共同进步!
—————————————————————————————————————
)





)


详解—单例模式(2))



:小练习)




、编译过程、beep实验)
概念、环境与代码框架)