背景意义
研究背景与意义
随着现代物流和仓储管理的快速发展,物品分类与检测技术在提高仓库运营效率、降低人工成本方面发挥着越来越重要的作用。传统的物品管理方式往往依赖人工识别和分类,效率低下且容易出错。为了解决这一问题,基于计算机视觉的自动化物品分类检测系统应运而生。近年来,深度学习技术的进步,尤其是目标检测算法的不断优化,使得这一领域的研究取得了显著的进展。
YOLO(You Only Look Once)系列算法作为目标检测领域的佼佼者,以其高效的实时检测能力和良好的准确性,成为了许多应用场景的首选。YOLOv11作为该系列的最新版本,结合了更先进的网络结构和优化策略,能够在复杂环境中实现更高效的物品检测和分类。然而,现有的YOLOv11模型在特定应用场景中的表现仍有提升空间,尤其是在仓库物品的细粒度分类和图像分割任务中。
本研究旨在基于改进的YOLOv11算法,构建一个针对仓库物品的分类检测与图像分割系统。我们将使用包含2000张图像的5S数据集,该数据集涵盖了12种不同类别的物品,包括箱子、手推车、托盘等。这些类别的多样性为模型的训练和评估提供了丰富的样本,能够有效提升模型的泛化能力和实际应用效果。
通过对YOLOv11的改进,我们希望能够在物品检测的准确性和速度上实现突破,进而为仓库管理提供更为智能化的解决方案。该系统的成功实施将为物流行业的数字化转型提供有力支持,推动智能仓储技术的发展,并为相关领域的研究提供新的思路和方法。
图片效果
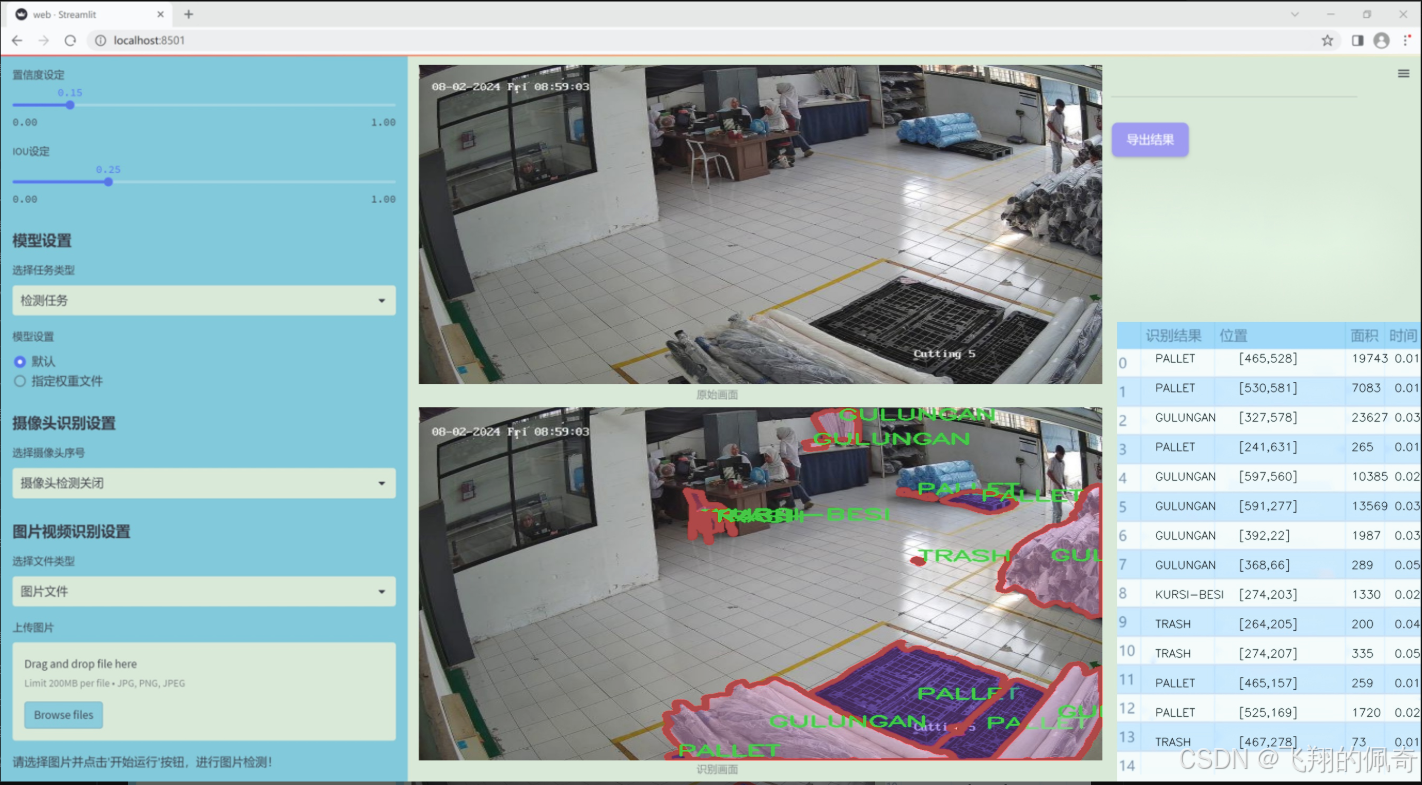
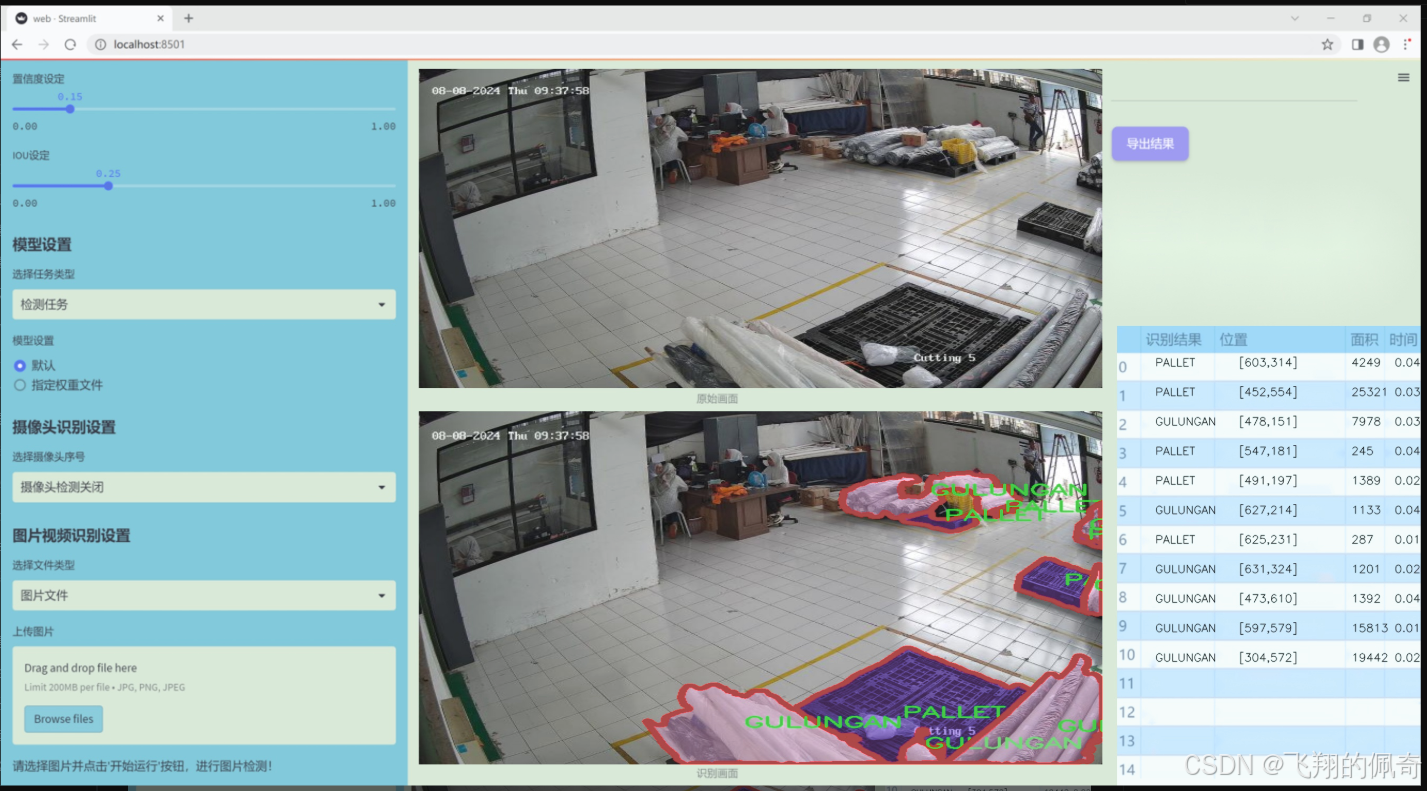
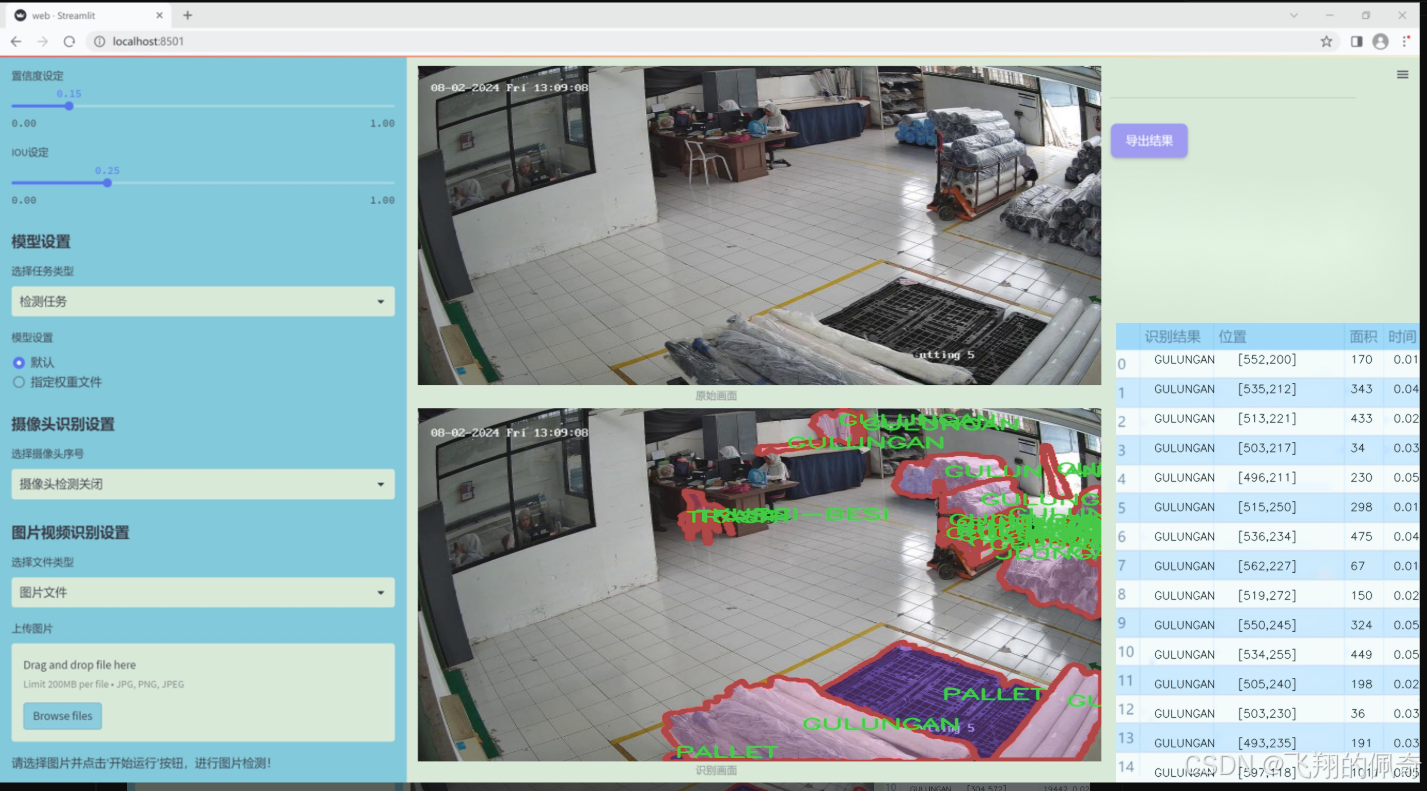
数据集信息
本项目数据集信息介绍
本项目旨在通过改进YOLOv11模型,构建一个高效的仓库物品分类检测图像分割系统,以提升仓库管理的智能化水平。为实现这一目标,我们构建了一个专门的数据集,主题围绕“5S”管理理念展开,强调在仓库环境中物品的整理、整顿、清扫、清洁和素养的重要性。该数据集包含11个类别,涵盖了仓库中常见的物品类型,具体包括:BOX(箱子)、BUNDLING(捆绑物)、GULUNGAN(卷筒)、HAND-PALLET(手动托盘)、KONTAINER(集装箱)、KURSI-BESI(铁椅)、OTHER(其他物品)、PALLET(托盘)、PENGKI(铲子)、SAPU(扫帚)和TRASH(垃圾)。这些类别的选择不仅反映了仓库管理的实际需求,也为物品的分类和检测提供了多样化的视角。
数据集中的图像经过精心挑选和标注,确保每个类别的样本数量均衡,且涵盖了不同的拍摄角度、光照条件和背景环境。这种多样性使得模型在训练过程中能够学习到更为丰富的特征,从而提高其在实际应用中的鲁棒性和准确性。此外,数据集还考虑到了不同物品之间的相似性和差异性,确保模型能够有效地区分相近类别,减少误检和漏检的情况。
通过对该数据集的深入分析和应用,我们期望能够显著提升YOLOv11在仓库物品分类检测中的性能,进而推动“5S”管理理念在仓库环境中的落地实施。最终,我们希望该系统不仅能提高物品管理的效率,还能为仓库的整体运营提供数据支持和决策依据。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class KANConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, spline_order, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, grid_size=5, base_activation=nn.GELU, grid_range=[-1, 1], dropout=0.0):
super(KANConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.spline_order = spline_order # 样条的阶数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.ndim = ndim # 数据的维度(1D, 2D, 3D)self.grid_size = grid_size # 网格大小self.base_activation = base_activation() # 基础激活函数self.grid_range = grid_range # 网格范围# 如果设置了dropout,则根据维度选择相应的Dropout层self.dropout = Noneif dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查分组参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 初始化基础卷积层和样条卷积层self.base_conv = nn.ModuleList([conv_class(input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])self.spline_conv = nn.ModuleList([conv_class((grid_size + spline_order) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 初始化归一化层和激活层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])self.prelus = nn.ModuleList([nn.PReLU() for _ in range(groups)])# 创建样条网格h = (self.grid_range[1] - self.grid_range[0]) / grid_sizeself.grid = torch.linspace(self.grid_range[0] - h * spline_order,self.grid_range[1] + h * spline_order,grid_size + 2 * spline_order + 1,dtype=torch.float32)# 使用Kaiming均匀分布初始化卷积层的权重for conv_layer in self.base_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')for conv_layer in self.spline_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')def forward_kan(self, x, group_index):# 对输入应用基础激活函数,并进行线性变换base_output = self.base_conv[group_index](self.base_activation(x))x_uns = x.unsqueeze(-1) # 扩展维度以进行样条操作target = x.shape[1:] + self.grid.shape # 计算目标形状grid = self.grid.view(*list([1 for _ in range(self.ndim + 1)] + [-1, ])).expand(target).contiguous().to(x.device)# 计算样条基bases = ((x_uns >= grid[..., :-1]) & (x_uns < grid[..., 1:])).to(x.dtype)# 计算多个阶数的样条基for k in range(1, self.spline_order + 1):left_intervals = grid[..., :-(k + 1)]right_intervals = grid[..., k:-1]delta = torch.where(right_intervals == left_intervals, torch.ones_like(right_intervals),right_intervals - left_intervals)bases = ((x_uns - left_intervals) / delta * bases[..., :-1]) + \((grid[..., k + 1:] - x_uns) / (grid[..., k + 1:] - grid[..., 1:(-k)]) * bases[..., 1:])bases = bases.contiguous()bases = bases.moveaxis(-1, 2).flatten(1, 2) # 重新排列和展平基# 通过样条卷积层进行输出spline_output = self.spline_conv[group_index](bases)x = self.prelus[group_index](self.layer_norm[group_index](base_output + spline_output))# 如果设置了dropout,则应用dropoutif self.dropout is not None:x = self.dropout(x)return xdef forward(self, x):# 将输入按组分割split_x = torch.split(x, self.inputdim // self.groups, dim=1)output = []for group_ind, _x in enumerate(split_x):y = self.forward_kan(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone())y = torch.cat(output, dim=1) # 合并输出return y
代码核心部分说明:
KANConvNDLayer类:这是一个自定义的多维卷积层,支持1D、2D和3D卷积。它结合了基础卷积和样条卷积的特性。
初始化方法:初始化卷积层、归一化层、激活函数和样条网格,并进行必要的参数检查。
forward_kan方法:实现了对输入数据的前向传播,计算基础卷积和样条卷积的输出,并应用激活函数和归一化。
forward方法:将输入数据按组分割,并对每个组调用forward_kan进行处理,最后合并输出。
这个程序文件定义了一个名为 KANConv 的卷积层,主要用于深度学习中的卷积神经网络(CNN)。它是一个可扩展的多维卷积层,支持1D、2D和3D卷积,具有自定义的样条基函数(spline basis)和归一化层。程序中包含了一个基类 KANConvNDLayer 和三个子类 KANConv1DLayer、KANConv2DLayer 和 KANConv3DLayer,分别用于处理一维、二维和三维数据。
在 KANConvNDLayer 类的构造函数中,首先初始化了一些参数,包括输入和输出维度、卷积核大小、样条阶数、分组数、填充、步幅、扩张、网格大小、激活函数、网格范围和丢弃率。然后,程序检查分组数是否为正整数,并确保输入和输出维度可以被分组数整除。
接下来,基于传入的卷积类(如 nn.Conv1d、nn.Conv2d 或 nn.Conv3d),程序创建了基础卷积层和样条卷积层的模块列表。每个组都有独立的卷积层和归一化层,以及 PReLU 激活函数。程序还生成了一个网格,用于计算样条基函数。
在 forward_kan 方法中,首先对输入进行基础激活,然后通过基础卷积层进行线性变换。接着,程序计算样条基函数,并将其传递给样条卷积层。最后,输出经过归一化和激活函数处理的结果,并在需要时应用丢弃层。
forward 方法将输入张量按组分割,并对每个组调用 forward_kan 方法进行处理,最后将所有组的输出拼接在一起。
子类 KANConv1DLayer、KANConv2DLayer 和 KANConv3DLayer 继承自 KANConvNDLayer,分别指定了适用于一维、二维和三维卷积的卷积类和归一化类。
总体来说,这个程序实现了一个灵活的卷积层,结合了基础卷积和样条卷积的优点,适用于多种类型的输入数据,并提供了多种可调参数以适应不同的应用场景。
10.4 repvit.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch.nn as nn
import torch
def _make_divisible(v, divisor, min_value=None):
“”"
确保所有层的通道数是8的倍数
:param v: 输入的通道数
:param divisor: 需要被整除的数
:param min_value: 最小值,默认为divisor
:return: 调整后的通道数
“”"
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# 确保向下取整不会减少超过10%
if new_v < 0.9 * v:
new_v += divisor
return new_v
class Conv2d_BN(torch.nn.Sequential):
“”"
包含卷积层和批归一化层的组合
“”"
def init(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1):
super().init()
# 添加卷积层
self.add_module(‘c’, torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
# 添加批归一化层
self.add_module(‘bn’, torch.nn.BatchNorm2d(b))
# 初始化批归一化层的权重
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse_self(self):"""融合卷积层和批归一化层为一个卷积层"""c, bn = self._modules.values()# 计算融合后的权重和偏置w = bn.weight / (bn.running_var + bn.eps)**0.5w = c.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / \(bn.running_var + bn.eps)**0.5# 创建新的卷积层m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups,device=c.weight.device)m.weight.data.copy_(w)m.bias.data.copy_(b)return m
class RepViTBlock(nn.Module):
“”"
RepViT的基本模块,包含通道混合和标记混合
“”"
def init(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
super(RepViTBlock, self).init()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
assert(hidden_dim == 2 * inp)
if stride == 2:# 当步幅为2时,使用卷积和SqueezeExciteself.token_mixer = nn.Sequential(Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),nn.Identity() if not use_se else SqueezeExcite(inp, 0.25),Conv2d_BN(inp, oup, ks=1, stride=1, pad=0))self.channel_mixer = nn.Sequential(Conv2d_BN(oup, 2 * oup, 1, 1, 0),nn.GELU() if use_hs else nn.Identity(),Conv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),)else:assert(self.identity)# 当步幅为1时,使用RepVGGDW模块self.token_mixer = nn.Sequential(RepVGGDW(inp),nn.Identity() if not use_se else SqueezeExcite(inp, 0.25),)self.channel_mixer = nn.Sequential(Conv2d_BN(inp, hidden_dim, 1, 1, 0),nn.GELU() if use_hs else nn.Identity(),Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),)def forward(self, x):# 前向传播return self.channel_mixer(self.token_mixer(x))
class RepViT(nn.Module):
“”"
RepViT模型的主类
“”"
def init(self, cfgs):
super(RepViT, self).init()
self.cfgs = cfgs
input_channel = self.cfgs[0][2]
# 构建初始层
patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),
Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))
layers = [patch_embed]
# 构建反向残差块
for k, t, c, use_se, use_hs, s in self.cfgs:
output_channel = _make_divisible(c, 8)
exp_size = _make_divisible(input_channel * t, 8)
layers.append(RepViTBlock(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
input_channel = output_channel
self.features = nn.ModuleList(layers)
def forward(self, x):# 前向传播,返回特征图features = []for f in self.features:x = f(x)features.append(x)return features
def repvit_m0_9(weights=‘’):
“”"
构建RepViT模型的特定配置
“”"
cfgs = [
# k, t, c, SE, HS, s
[3, 2, 48, 1, 0, 1],
# 其他配置…
]
model = RepViT(cfgs)
if weights:
model.load_state_dict(torch.load(weights)[‘model’])
return model
代码核心部分解释:
_make_divisible: 确保通道数是8的倍数,适用于模型结构的要求。
Conv2d_BN: 封装了卷积层和批归一化层,提供了权重初始化和融合方法。
RepViTBlock: 定义了RepViT的基本构建块,负责通道和标记的混合。
RepViT: 主模型类,负责根据配置构建整个网络结构。
repvit_m0_9: 提供了一个特定配置的RepViT模型构建函数。
以上是代码的核心部分及其详细注释,帮助理解模型的结构和功能。
这个程序文件 repvit.py 实现了一个基于深度学习的模型,主要是 RepViT(Residual Vision Transformer)架构的实现。该模型结合了卷积神经网络(CNN)和视觉变换器(ViT)的优点,适用于图像分类等任务。
首先,程序导入了必要的库,包括 PyTorch 的神经网络模块、NumPy 和一些特定的层(如 SqueezeExcite)。接着,定义了一些全局变量,表示不同版本的 RepViT 模型。
replace_batchnorm 函数用于遍历网络中的所有子模块,将 BatchNorm2d 层替换为 Identity 层。这通常用于模型推理阶段,以减少计算开销。
_make_divisible 函数确保所有层的通道数都是 8 的倍数,这在一些模型架构中是一个常见的要求,以提高计算效率。
Conv2d_BN 类定义了一个包含卷积层和批归一化层的复合模块,并在初始化时对批归一化的权重进行初始化。fuse_self 方法用于将卷积层和批归一化层融合为一个卷积层,以提高推理速度。
Residual 类实现了残差连接的功能,允许在训练时添加随机噪声以提高模型的鲁棒性。它也包含了一个 fuse_self 方法,用于在推理时融合卷积层。
RepVGGDW 类定义了一个深度可分离卷积模块,结合了卷积和批归一化,输出经过激活函数处理的结果。
RepViTBlock 类实现了 RepViT 的基本构建块,包含了通道混合和标记混合的功能,使用了前面定义的模块。
RepViT 类是整个模型的核心,负责构建模型的不同层次。它接受一个配置列表,构建相应的卷积层和 RepViT 块,并在前向传播中返回特征图。
switch_to_deploy 方法用于将模型切换到推理模式,替换掉所有的 BatchNorm 层。
update_weight 函数用于更新模型的权重,将预训练模型的权重加载到当前模型中。
接下来,定义了多个函数(如 repvit_m0_9, repvit_m1_0, 等),这些函数用于构建不同配置的 RepViT 模型,并可以选择性地加载预训练权重。
最后,在 main 部分,程序实例化了一个 RepViT 模型,并对随机生成的输入数据进行前向传播,输出各层的特征图尺寸。
总体而言,这个程序实现了一个灵活且高效的深度学习模型,适用于各种计算机视觉任务,尤其是在图像分类领域。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻



)


)





)

安卓端部署Yolov8-v8.2.99实例分割项目全流程记录)



)
