CCAFusion:用于红外与可见光图像融合的跨模态坐标注意力网络
CCAFusion: Cross-Modal Coordinate Attention Network for Infrared and Visible Image Fusion
摘要
红外与可见光图像融合旨在生成一幅包含全面信息的图像,该图像既能保留丰富的纹理特征,又能保留热信息。然而,在现有的图像融合方法中,融合后的图像要么会损失热目标的显著性与纹理的丰富性,要么会引入伪影等无用信息的干扰。为缓解这些问题,本文提出一种用于红外与可见光图像融合的高效跨模态坐标注意力网络,命名为CCAFusion。为充分融合互补特征,本文设计了基于坐标注意力的跨模态图像融合策略,该策略包含特征感知融合模块与特征增强融合模块。此外,本文采用基于多尺度跳跃连接的网络来获取红外图像与可见光图像中的多尺度特征,以便在融合过程中充分利用多层次信息。为减小融合图像与输入图像之间的差异,本文构建了包含基础损失与辅助损失的多约束损失函数,用于调整灰度分布,确保融合图像中结构与强度和谐共存,进而避免伪影等无用信息的干扰。在广泛使用的数据集上进行的大量实验表明,无论是在定性评价还是定量测量方面,所提CCAFusion网络的性能均优于当前主流的图像融合方法。此外,将该网络应用于显著目标检测的结果表明,CCAFusion在高级视觉任务中具有应用潜力,能够有效提升检测性能。
关键词:红外与可见光图像融合;注意力机制;跨模态融合策略;坐标注意力;多约束损失函数
1 引言
红外与可见光图像融合旨在生成一幅包含全面信息的图像。该技术能够保留可见光图像中丰富的纹理特征以及红外图像中的热信息[1]-[3],从而提升在光照变化、目标遮挡、背景杂乱等复杂场景下的关键信息获取能力。图像融合作为一项重要的预处理技术,可助力众多应用准确识别复杂场景中的潜在目标与现象。尤其在视频监控[4]、语义分割[5]、目标检测[6]-[7]等多模态高级视觉任务中,图像融合技术展现出广泛的应用价值。
早期的图像融合研究主要采用多尺度变换法、稀疏表示法、显著性检测法、子空间法、混合方法等多种传统方法对不同模态图像进行融合[8]-[9]。这些传统融合方法虽对红外与可见光图像融合任务有一定积极作用,但由于其所采用的手工设计特征表达能力有限,导致融合图像易出现空间失真问题,如存在伪影、信息不完整等。
近年来,深度学习凭借其卓越的特征提取能力被引入图像融合领域。现有基于深度学习的融合方法主要基于卷积神经网络(CNN)框架[10]-[11]、生成对抗网络(GAN)框架[12]-[14]以及自编码器(AE)框架[15]-[16]构建。尽管基于深度学习的图像融合方法能生成质量较好的融合结果,但仍存在一些局限性:
-
部分图像融合方法采用简单直接的方式将源图像特征迁移至融合图像中。例如,文献[17]-[18]中预设的融合规则仅通过对特征图取平均来获取融合特征,这种直接的特征处理方式可能导致源图像中提取的特征未被充分利用。
-
由于图像融合任务缺乏理想的真值数据,难以平衡源图像与融合图像之间的差异,甚至可能在融合图像中引入伪影等无用信息干扰。为此,有研究探索了基于GAN框架的图像融合方法[19]-[20]。这类方法虽能保留大部分细节信息,但GAN网络难以充分挖掘多模态图像中的代表性信息。
-
基于AE的融合方法在整合源图像有效信息时,对提取的特征缺乏合理引导便直接进行融合[21]-[23]。近年来,研究人员将注意力机制引入基于AE的融合框架中,以区分不同特征的重要性。例如,有研究提出基于卷积块注意力模块(CBAM)[24]的融合策略,用于表征各空间位置及各通道的重要性[25],该方法能生成较好的融合结果。但该融合方法在特征融合过程中未挖掘跨特征与长距离依赖关系,且采用大尺度池化操作捕捉局部相关性,易造成位置信息丢失。
受近期注意力机制相关研究[28]及Densefuse方法[21]的启发,本文提出一种用于红外与可见光图像融合的高效跨模态坐标注意力网络(CCAFusion),旨在解决上述图像融合方法中存在的问题。与传统基于深度学习的融合方法相比,CCAFusion通过引入通道与位置重要性,构建跨模态坐标注意力以引导特征融合;同时,在特征融合过程中挖掘跨特征与长距离依赖关系,避免大尺度全局池化导致的位置信息丢失。为实现互补特征的有效融合,本文在融合策略中设计了特征感知融合模块(FAF)与特征增强融合模块(FEF)。此外,采用基于多尺度跳跃连接的网络结构,提取红外图像与可见光图像中的多尺度特征。
具体而言,CCAFusion网络由编码器模块、融合模块及解码器模块构成。通过跨模态坐标注意力融合模块,实现各层级的跨模态特征融合;将这些跨模态融合特征输入基于跳跃连接结构的解码器模块,从高层信息到低层信息逐步重构出最终的融合图像。此外,针对图像融合任务中缺乏理想真值数据的问题,本文设计了一种新的损失项用于约束网络训练,即多约束损失函数。

为直观展示CCAFusion的优势,图1给出了红外与可见光图像融合的示意图,结果表明该网络能有效保留热目标与纹理特征,且无伪影产生。
综上,本文的主要贡献如下:
-
提出一种新型红外与可见光图像融合跨模态坐标注意力网络(CCAFusion),该网络在图像融合任务中表现出优异性能。将其扩展应用于显著目标检测任务,结果表明CCAFusion可提升后续高级视觉任务的检测性能。
-
设计一种简洁高效的跨模态图像融合策略,该策略包含特征感知融合模块(FAF)与特征增强融合模块(FEF)。其中,FAF基于单模态注意力权重实现互补特征融合;FEF利用跨模态注意力权重增强互补特征。通过对融合模块的消融实验验证了该融合策略的有效性,结果表明FAF与FEF协同作用,能使融合网络保留丰富的图像信息。
-
构建用于图像融合的多约束损失函数。具体而言,本文提出一种新的基础损失,通过KL散度使融合图像与源图像保持相似的灰度分布,从而保留基础信息;辅助损失则用于保留细节信息与热辐射信息。利用该损失函数训练的CCAFusion网络,可合理调整灰度分布,确保融合图像中结构与强度和谐共存,有效避免伪影干扰。通过对损失函数的消融实验,验证了各损失项的有效性及其不同作用。
本文后续内容安排如下:第2章综述图像融合方法的相关研究;第3章详细介绍CCAFusion网络结构;第4章在公开数据集上开展图像融合实验;第5章总结全文。
2 相关工作
本节首先综述经典图像融合算法,随后介绍近年来基于深度学习的图像融合方法相关研究。
2.1 经典图像融合方法
经典图像融合方法可分为六类:多尺度变换法、稀疏表示法、显著性检测法、子空间法、混合方法及其他方法[8]-[9]。其中,应用最广泛的是多尺度变换法与稀疏表示法。
作为经典图像融合方法的代表性分支,多尺度变换法旨在将源图像分解为不同尺度,随后通过逆变换将不同尺度下的特征融合[29]。传统多尺度变换方法包括拉普拉斯金字塔变换(LAP)[30]、非下采样轮廓波变换(NSCT)[31]及离散小波变换(DWT)[32]。Madheswari与Venkateswaran[33]提出一种基于离散小波变换的图像融合框架,结合粒子群优化技术实现红外热图像与可见光图像的融合,其性能优于大多数多分辨率融合技术。
经典图像融合方法的另一典型分支是稀疏表示法。基于稀疏表示的融合方法核心是利用过完备字典对源图像进行表示,再依据融合规则对过完备字典中的稀疏表示系数进行整合,最终得到融合图像[34]。为在字典构建过程中获取充分的特征表示,Wang等人[35]提出一种结合形态学、随机坐标编码与同步正交匹配追踪的图像融合方法。考虑到稀疏表示的滑动窗口技术易引入伪影,研究人员提出卷积稀疏表示法[36],用于学习对应整幅源图像的系数;Liu等人[37]采用该卷积稀疏表示法,有效改善了图像融合任务中细节保留效果不佳的问题。
2.2 基于深度学习的图像融合方法
近年来,基于深度学习的方法[38]-[40]凭借出色的特征提取能力,在图像融合领域取得显著进展。根据图像融合任务中所采用网络架构的特点,基于深度学习的融合方法可分为基于卷积神经网络(CNN)的融合框架、基于生成对抗网络(GAN)的融合框架以及基于自编码器(AE)的融合框架[41]。
2.2.1 基于CNN的融合方法
此类方法利用卷积算子提取显著特征并生成权重图。Liu等人[11]首次将CNN应用于图像融合任务,但该方法依赖二值图,仅适用于多聚焦图像融合。为实现红外与可见光图像融合,Li等人[42]将源图像分解为基础部分与细节部分,针对细节部分,基于深度学习网络提取的特征生成权重。随后,Zhang与Ma[43]构建了一种用于融合任务的压缩-分解模型,该模型采用自适应决策块优化目标函数,并通过调整权重改变不同输入图像的信息占比。
2.2.2 基于GAN的融合方法
这类方法充分利用概率分布估计能力生成融合图像,其核心是生成器与判别器之间的博弈过程。Ma等人[20]创新性地将GAN框架引入图像融合任务,通过判别器驱动生成器生成融合图像。然而,单一判别器易导致模式崩溃,即融合图像过度偏向可见光图像或红外图像中的某一种;此外,文献[20]中的FusionGAN依赖对抗学习进行特征学习,稳定性较差,导致融合结果缺乏纹理细节。为平衡红外图像与可见光图像的信息,Ma等人[44]提出双判别器条件生成对抗网络;为更好地融合源图像的纹理信息,Yang等人[45]构建了基于纹理条件生成对抗网络的图像融合网络。
2.2.3 基于AE的融合方法
此类方法采用自编码器架构实现特征提取与特征重构。Li与Wu[21]提出一种基于编码器-解码器结构的红外与可见光图像融合方法,命名为Densefuse。但该方法在融合层采用直接相加策略整合显著特征,限制了融合性能。为解决这一问题,Xu等人[46]提出一种基于自编码器的图像融合框架,结合逐像素分类的显著性融合规则,突破了深度学习在融合规则应用中的瓶颈。
近年来,注意力机制被引入图像融合任务。Li等人[25]提出基于卷积块注意力模块(CBAM)的融合策略,该策略考虑了各空间位置与各通道的重要性;类似地,Wang等人[16]也在融合层构建了空间注意力与通道注意力模型。与文献[25]中的Nestfuse方法不同,文献[16]将L1范数、均值运算与注意力模型结合,为显著特征生成权重图。
基于深度学习的融合方法虽展现出具有竞争力的融合性能,但仍存在部分待解决的缺陷:
-
图像融合不仅能整合关键信息,还可助力高级视觉任务。然而,以往的融合方法[22]、[45]、[47]-[49]仅关注融合图像的视觉质量与统计指标,忽视了图像融合在高级视觉任务中的应用。与之不同,本文方法不仅在图像融合任务中表现优异,还能提升后续高级视觉任务的检测性能——这一点已通过在显著目标检测中的扩展应用得到验证。
-
部分融合策略在整合源图像有效信息时,依赖直接的手工设计规则,缺乏合理引导(例如文献[21]、[22]中的加法运算)。相比之下,本文基于注意力机制设计了一种新型跨模态图像融合策略,能在注意力机制的引导下整合源图像的有效信息。尽管文献[45]、[49]中基于注意力机制的方法可引导模型更多关注重要内容,但在特征融合过程中忽略了长距离依赖关系。与这些方法不同,本文方法采用坐标注意力设计特征感知融合模块与特征增强融合模块,可同时捕捉通道与位置重要性及长距离依赖关系。
-
同一场景下的图像往往具有相似的灰度分布,这种分布特性可反映图像融合中的基础信息,但现有方法[48]、[49]忽视了这一点。与之相反,本文基于“同一场景图像灰度分布相似”这一事实,设计了一种新的损失函数,通过KL散度使融合图像与源图像保持相似的灰度分布,从而保留基础信息。
3 所提方法
本节首先阐述所提方法的设计动机,随后介绍CCAFusion网络的整体架构,并详细说明跨模态坐标注意力融合策略;接着,详细介绍所设计的多约束损失函数;最后,阐述用于RGB-红外图像融合的CCAFusion具体框架。
3.1 设计动机
红外与可见光图像融合旨在生成一幅包含全面信息的图像,该图像需保留可见光图像中丰富的纹理特征以及红外图像中的热信息。然而,红外图像与可见光图像由不同成像机制的传感器生成,导致源图像之间存在域差异。这种域差异对红外与可见光图像融合任务构成了巨大挑战,因为难以平衡源图像间关键特征的差异。当源图像的结构与强度无法和谐共存时,融合图像的高对比度边缘区域往往会出现伪影。此外,由于现有红外与可见光图像融合方法在融合过程中存在特征表示能力有限、关键信息丢失等问题,其融合结果也易受不良伪影影响,进而不可避免地降低最终性能。
鉴于上述局限性,本文提出一种新型红外与可见光图像融合网络,旨在实现充分的特征保留、强大的特征表示能力以及关键特征的和谐共存,从而避免向融合图像中引入不良伪影。
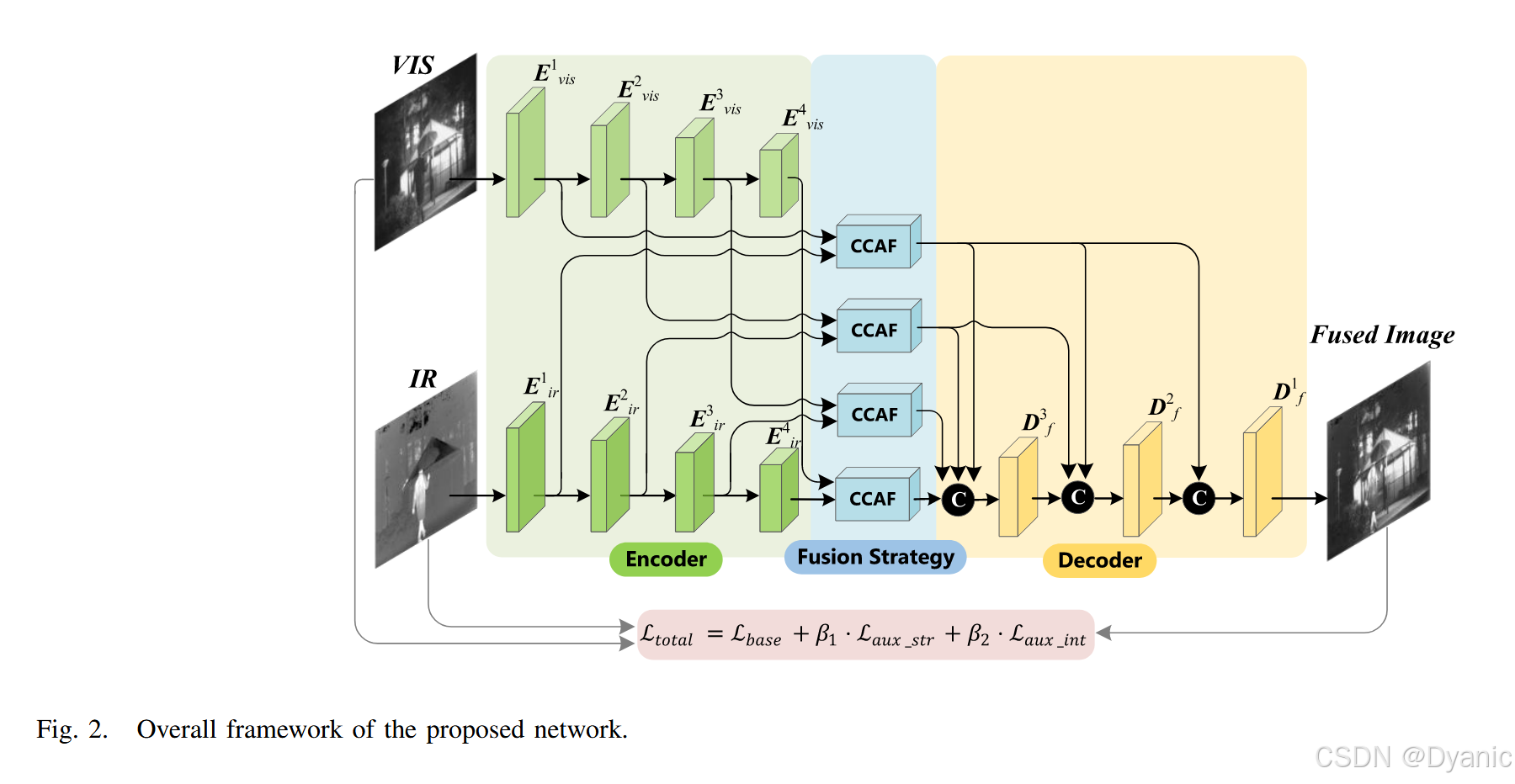
3.2 网络概述
所提网络采用双分支结构,包含4个编码器模块(记为EjiE_j^iEji,其中i∈{1,2,3,4}i \in \{1,2,3,4\}i∈{1,2,3,4},j∈{ir,vis}j \in \{ir,vis\}j∈{ir,vis},iririr代表红外分支,visvisvis代表可见光分支)、4个融合模块以及3个解码器模块(记为DfiD_f^iDfi,其中i∈{1,2,3}i \in \{1,2,3\}i∈{1,2,3})。图2展示了该网络的整体框架。
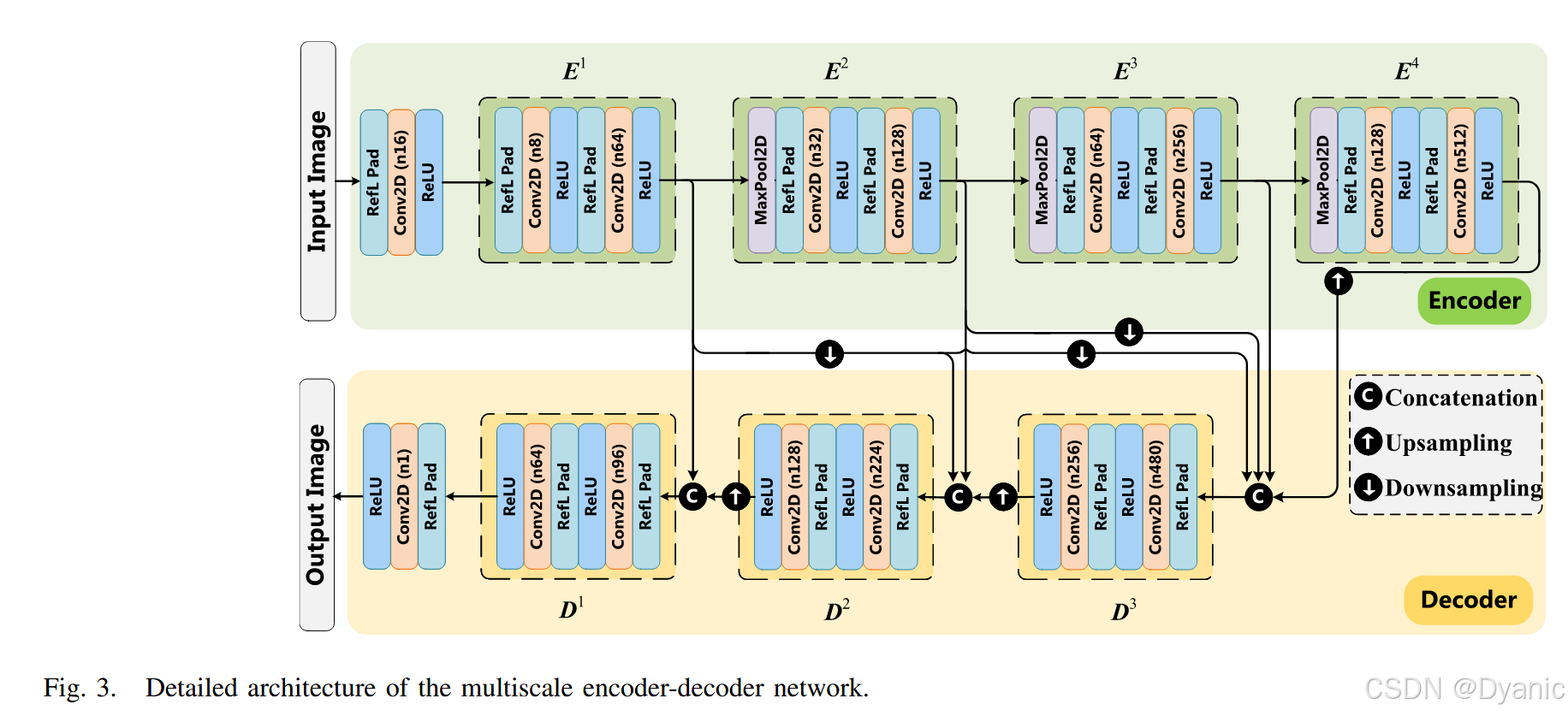
具体而言,首先将红外图像与可见光图像分别输入双分支特征提取网络。每个分支的主干网络为基于多尺度跳跃连接结构的编解码器网络[50],其结构如图3所示。编码器模块的作用是提取各层级的深层特征;随后,将编码器模块的输出传入跨模态坐标注意力融合模块(CCAF),实现各层级的跨模态特征融合;接着,将这些跨模态融合特征输入基于跳跃连接结构的解码器模块,从高层信息到低层信息逐步重构出最终的融合图像。
下文将详细介绍编解码器网络的结构。该编解码器网络的设计灵感来源于Densefuse[21],但与Densefuse通过基于密集连接的网络获取重构图像不同,本文采用基于多尺度跳跃连接的编解码器网络[50],以充分利用红外图像与可见光图像中的多尺度特征,其结构如图3所示。
每个分支的编码器由4个模块构成,每个模块包含2个填充层(Padding层)、2个卷积层(Convolution层)和2个ReLU激活层。其中,第一个卷积层的卷积核大小为3×33 \times 33×3,第二个卷积层的卷积核大小为1×11 \times 11×1。通过多尺度跳跃连接结构与拼接操作(Concatenation)对提取到的不同尺度特征进行整合,再将整合结果分别输入3个解码器模块。与编码器部分类似,每个解码器模块也包含2个填充层、2个卷积层和2个ReLU激活层。各卷积层的通道数如图3所示,最终通过将通道数减少至1,生成输出图像。
3.3 融合策略
可见光图像包含丰富的纹理特征,红外图像则呈现热辐射特征。在背景杂乱、目标遮挡、光照变化等复杂环境下,这两类特征具有互补性。考虑到不同空间信息与通道的作用存在差异,在融合这些互补特征时需重点关注有效信息。因此,本文在融合策略中引入一种新型注意力机制,用于区分特征的重要性。
注意力机制已在多个领域得到广泛研究与应用,能够引导模型更多关注重要内容[51]-[52]。其中,挤压-激励(SE)注意力[53]是最知名且应用最广泛的方法之一,但SE模块仅考虑通道间信息,忽略了位置信息的重要性。卷积块注意力模块(CBAM)同时考虑通道信息与位置信息,文献[25]将其应用于图像融合任务,然而该注意力机制存在长距离依赖关系捕捉不足的问题。
本文的融合策略基于坐标注意力[28]设计,可同时捕捉通道与位置重要性及长距离依赖关系。图4展示了跨模态融合策略的具体结构,该策略包含两个核心部分:特征感知融合模块(FAF)与特征增强融合模块(FEF)。
本文采用FAF实现互补特征(包括可见光图像的纹理特征与红外图像的热辐射特征)的融合。首先,将可见光分支生成的第iii层特征EvisiE^i_{vis}Evisi与红外分支生成的第iii层特征EiriE^i_{ir}Eiri输入跨模态坐标注意力融合模块(CCAF);随后,通过坐标注意力模块(CAM)获取权重矩阵wvisiw^i_{vis}wvisi与wiriw^i_{ir}wiri,分别反映可见光特征与红外特征的重要性。
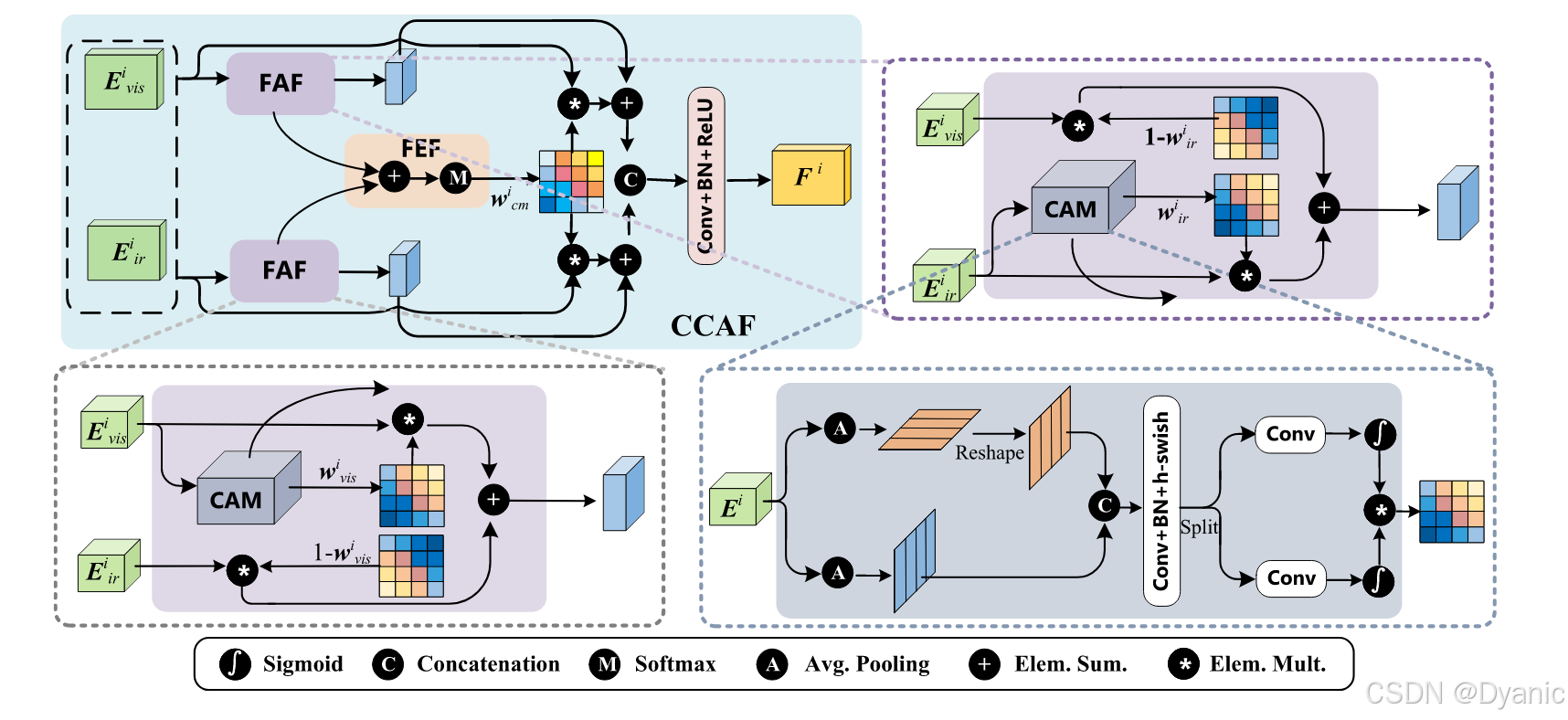
CAM的具体结构如图4右下角所示。给定尺寸为C×H×WC \times H \times WC×H×W的第iii层输入特征EiE_iEi,分别采用尺寸为(H,1)(H,1)(H,1)和(1,W)(1,W)(1,W)的池化核,沿水平坐标与垂直坐标对不同通道的信息进行编码。其中,高度为hhh处第ccc个通道的编码过程定义如下:
yi_ch(h)=1W∑0≤l<WEi_c(h,l)(1)y^h_{i\_c}(h) = \frac{1}{W}\sum_{0 \leq l < W} E^{i\_c}(h,l) \tag{1}yi_ch(h)=W10≤l<W∑Ei_c(h,l)(1)
类似地,宽度为www处第ccc个通道的编码过程定义如下:
yi_cw(w)=1H∑0≤k<HEi_c(k,w)(2)y^w_{i\_c}(w) = \frac{1}{H}\sum_{0 \leq k < H} E^{i\_c}(k,w) \tag{2}yi_cw(w)=H10≤k<H∑Ei_c(k,w)(2)
上述两个过程生成沿两个空间方向的方向感知特征图,使注意力模块能沿一个空间方向捕捉长距离依赖关系,同时沿另一个空间方向保留精确的位置信息,从而帮助网络准确定位感兴趣目标的位置。CAM的直观效果将在4.6.3节详细说明。
为生成经重塑的yi_ch(h)y^h_{i\_c}(h)yi_ch(h)与yi_cw(w)y^w_{i\_c}(w)yi_cw(w)的聚合特征图,先对两者进行拼接,再通过1×11 \times 11×1卷积操作将通道数减少至C/rC/rC/r(其中rrr为通道缩减系数,参考文献[28]设为32),具体公式如下:
f=δ(F1([yi_ch(h),yi_cw(w)]))(3)f = \delta\left(F_1\left([y^h_{i\_c}(h), y^w_{i\_c}(w)]\right)\right) \tag{3}f=δ(F1([yi_ch(h),yi_cw(w)]))(3)
式中,[⋅,⋅][\cdot,\cdot][⋅,⋅]表示拼接操作,F1F_1F1代表1×11 \times 11×1卷积变换函数,δ\deltaδ为h-swish激活函数[54]。随后,将输出特征图f∈RC/r×(H+W)f \in \mathbb{R}^{C/r \times (H+W)}f∈RC/r×(H+W)分解为两个独立张量fh∈RC/r×Hf^h \in \mathbb{R}^{C/r \times H}fh∈RC/r×H与fw∈RC/r×Wf^w \in \mathbb{R}^{C/r \times W}fw∈RC/r×W;通过两个1×11 \times 11×1卷积变换函数F1hF^h_1F1h与F1wF_1^wF1w将通道数恢复至CCC,权重矩阵wiw_iwi为F1hF^h_1F1h与F1wF_1^wF1w的乘积输出,公式如下:
wi=σ(F1h(fh))×σ(F1w(fw))(4)w^i = \sigma\left(F_1^h(f^h)\right) \times \sigma\left(F_1^w(f^w)\right) \tag{4}wi=σ(F1h(fh))×σ(F1w(fw))(4)
式中,σ\sigmaσ为sigmoid函数。将EvisiE^i_{vis}Evisi与EiriE^i_{ir}Eiri输入CAM,可分别得到权重矩阵wvisiw^i_{vis}wvisi与wiriw^i_{ir}wiri。将这两个权重矩阵与输入特征相乘,突出融合任务中的重要特征并抑制无关特征,具体过程如下:
Firi=Eiri∗wiri+Evisi∗(1−wiri)(5)F^i_{ir} = E^i_{ir} * w^i_{ir} + E^i_{vis} * (1 - w^i_{ir}) \tag{5}Firi=Eiri∗wiri+Evisi∗(1−wiri)(5)
Fvisi=Evisi∗wvisi+Eiri∗(1−wvisi)(6)F^i_{vis} = E^i_{vis} * w^i_{vis} + E^i_{ir} * (1 - w^i_{vis}) \tag{6}Fvisi=Evisi∗wvisi+Eiri∗(1−wvisi)(6)
其中,FiriF^i_{ir}Firi与FvisiF^i_{vis}Fvisi为FAF的输出结果。
此外,红外图像中也会体现部分纹理特征,可见光图像中同样存在部分热辐射特征,因此需通过FEF增强这些互补特征。首先对权重矩阵wvisiw^i_{vis}wvisi与wiriw^i_{ir}wiri进行聚合,再将聚合结果输入softmax函数,得到跨模态权重矩阵wcmiw^i_{cm}wcmi,公式如下:
wcmi=softmax(wvisi+wiri)(7)w^i_{cm} = softmax(w^i_{vis} + w^i_{ir}) \tag{7}wcmi=softmax(wvisi+wiri)(7)
基于跨模态权重矩阵wcmiw^i_{cm}wcmi,将FAF输出结果与FEF增强结果相加,得到增强特征FIRiF^i_{IR}FIRi与FVISiF^i_{VIS}FVISi,具体如下:
FIRi=Firi+Eiri∗wcmi(8)F^i_{IR} = F^i_{ir} + E^i_{ir} * w^i_{cm} \tag{8}FIRi=Firi+Eiri∗wcmi(8)
FVISi=Fvisi+Evisi∗wcmi(9)F^i_{VIS} = F^i_{vis} + E^i_{vis} * w^i_{cm} \tag{9}FVISi=Fvisi+Evisi∗wcmi(9)
最后,将可见光分支与红外分支生成的增强特征进行拼接,并输入卷积层,得到跨模态融合特征FiF^iFi,公式如下:
Fi=Conv([FVISi,FIRi])(10)F^i = Conv([F^i_{VIS}, F^i_{IR}]) \tag{10}Fi=Conv([FVISi,FIRi])(10)
3.4 损失函数
针对图像融合任务中缺乏理想真值数据的问题,本文从多维度设计网络训练的损失函数,以在红外与可见光图像融合中保留更多有效信息。
一方面,考虑到同一场景下图像的灰度分布具有相似性,本文结合灰度分布与KL散度损失设计基础损失Lbase\mathcal{L}_{base}Lbase,公式如下:
Lbase=12(KL(S(pf)∥S(qir))2+KL(S(pf)∥S(qvis))2)(11)\mathcal{L}_{base} = \sqrt{\frac{1}{2}\left( \text{KL}(S(p_f) \parallel S(q_{ir}))^2 + \text{KL}(S(p_f) \parallel S(q_{vis}))^2 \right)} \tag{11}Lbase=21(KL(S(pf)∥S(qir))2+KL(S(pf)∥S(qvis))2)(11)
式中,qirq_{ir}qir与qvisq_{vis}qvis分别表示红外图像与可见光图像的灰度分布,pfp_fpf表示融合图像的灰度分布,S(⋅)S(\cdot)S(⋅)为softmax函数,用于对元素进行重缩放。通过KL散度约束融合图像与源图像的灰度分布相似性,从而保留源图像中的基础信息。
另一方面,考虑到融合图像需充分保留细节信息与热辐射信息:融合图像的细节可表示为红外与可见光图像纹理的最大聚合,以保留丰富的细节信息;逐元素最大值选择可使融合图像获得最优强度分布,从而突出热辐射信息。基于此,本文构建辅助结构损失Laux−str\mathcal{L}_{aux-str}Laux−str与辅助强度损失Laux−int\mathcal{L}_{aux-int}Laux−int,公式分别如下:
Laux−str=∥∣∇If∣−max(∣∇Iir∣,∣∇Ivis∣)∥1(12)\mathcal{L}_{aux-str} = \left\| \left| \nabla I_f \right| - \max\left( \left| \nabla I_{ir} \right|, \left| \nabla I_{vis} \right| \right) \right\|_1 \tag{12}Laux−str=∥∣∇If∣−max(∣∇Iir∣,∣∇Ivis∣)∥1(12)
Laux−int=∥If−max(Iir,Ivis)∥1(13)\mathcal{L}_{aux-int} = \left\| I_f - \max\left( I_{ir}, I_{vis} \right) \right\|_1 \tag{13}Laux−int=∥If−max(Iir,Ivis)∥1(13)
式中,IfI_fIf、IirI_{ir}Iir与IvisI_{vis}Ivis分别表示融合图像、红外图像与可见光图像,∇\nabla∇为梯度算子。
最终,CCAFusion的损失函数由基础损失与辅助损失两部分构成,其中辅助损失进一步包含辅助结构损失与辅助强度损失。多约束总损失函数Ltotal\mathcal{L}_{total}Ltotal定义如下:
Ltotal=Lbase+β1⋅Laux−str+β2⋅Laux−int(14)\mathcal{L}_{total} = \mathcal{L}_{base} + \beta_1 \cdot \mathcal{L}_{aux-str} + \beta_2 \cdot \mathcal{L}_{aux-int} \tag{14}Ltotal=Lbase+β1⋅Laux−str+β2⋅Laux−int(14)
式中,β1\beta_1β1与β2\beta_2β2为权重系数,用于平衡各损失项的贡献。β1\beta_1β1与β2\beta_2β2的具体取值调整将在4.2.1节说明。
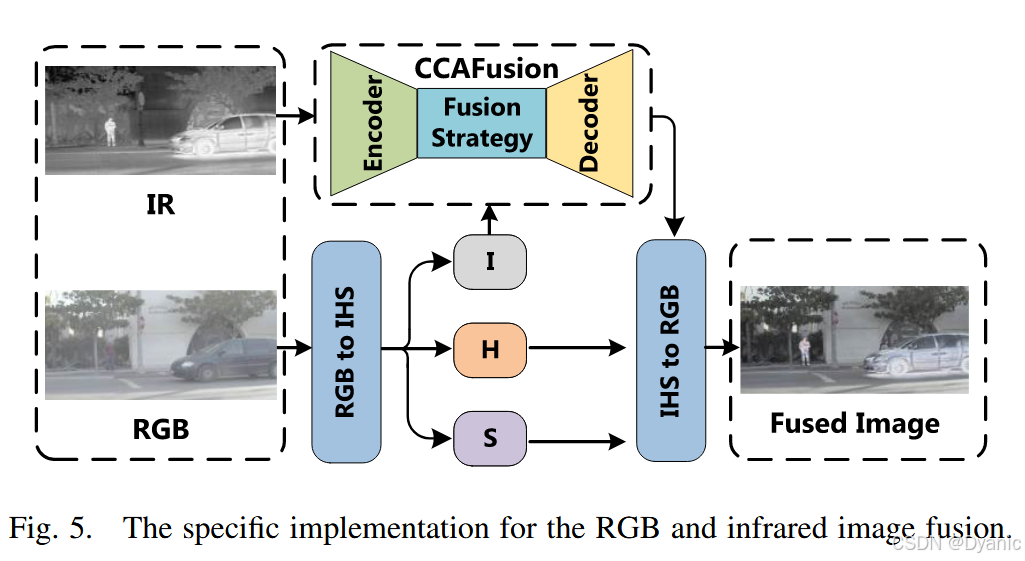
3.5 RGB-红外图像融合
前文所述融合过程针对灰度可见光图像与红外图像。对于RGB-红外图像融合,可先将RGB图像转换至IHS颜色空间(其中III为强度通道,HHH为色调通道,SSS为饱和度通道)。由于主要空间信息集中在III通道,可采用CCAFusion将红外图像与RGB图像生成的III通道进行融合;随后,将融合后的III通道与原RGB图像的HHH、SSS通道结合,再转换回RGB颜色空间,即可得到最终的RGB-红外融合图像。RGB-红外图像融合的对应架构如图5所示。
4 实验与分析
本节首先说明实验设置,包括数据集、评价指标、对比方法及实现细节;随后通过消融实验验证CCAFusion中各组件的有效性,并将所提网络与当前主流图像融合方法进行对比;此外,通过泛化实验验证CCAFusion的泛化能力;最后,将其扩展应用于显著目标检测任务,以证明CCAFusion对高级视觉任务的促进作用。
4.1 实验设置
4.1.1 数据集与评价指标
所提网络在VTUAV数据集[55]上进行训练,该数据集是目前最新的公开可见-热成像多模态数据集,包含两个城市的15个场景(涵盖桥梁、海洋、道路、公园、街道等),且包含雾天、大风天、阴天等不同天气条件下的数据。从VTUAV数据集中随机选取10000对图像作为训练样本,所有训练图像均转换为灰度图并调整尺寸至256×256。
在两个公开数据集上测试所提网络的融合性能:
- TNO数据集[56]:包含21对灰度可见光-红外图像,该数据集通过多波段相机系统预先配准,涵盖不同军事与监控场景的多光谱图像(包括增强可见光、近红外、长波红外/热成像图像)。
- RoadScene数据集[27]:包含61对RGB-红外配准图像,基于FLIR视频[57]构建,场景丰富(涵盖道路、车辆、行人等)。
为全面评估融合质量,从定性评价与定量指标两方面对融合图像进行评估:
- 定性评价:基于人类视觉感知,但主观视觉感知易受人为因素影响。
- 定量指标:采用4种广泛使用的指标,具体如下:
- 互信息(MI)[58]:衡量从输入图像传递到融合图像的信息量,值越大表示融合图像包含的信息越丰富。
- 视觉信息保真度(VIF)[59]:评估融合结果的信息保真度,值越大与人类视觉感知的一致性越好。
- 空间频率(SF)[60]:衡量纹理结构的丰富程度,值越大表示融合结果的纹理越丰富。
- 熵(EN)[61]:评估融合结果中保留的信息量,值越大表示融合结果包含的信息越多。
4.1.2 对比方法与实现细节
为验证CCAFusion的融合性能,将其与当前主流图像融合方法对比,包括传统方法与基于深度学习的方法:
- 传统方法:MDLatLRR[62]。
- 基于深度学习的方法:DenseFuse[21]、SDNet[43]、PIAFusion[26]、U2Fusion[27]。
所有对比方法均采用默认参数设置,实验环境与实现细节如下:
- MDLatLRR:在MATLAB R2020b环境下运行,硬件为AMD R7-4800H 2.9GHz CPU。
- DenseFuse、SDNet、PIAFusion、U2Fusion:基于TensorFlow框架,硬件为1块Nvidia 2080Ti GPU。
- 所提网络(CCAFusion):基于PyTorch框架,硬件为1块Nvidia 2080Ti GPU;优化器采用Adam,学习率设为0.0001,批大小(batch size)设为8,训练轮次(epoch)设为10,训练总时长约9小时。
4.2 消融实验
4.2.1 超参数影响
CCAFusion中的超参数包括多约束损失函数中的β1β₁β1与β2β₂β2:β1β₁β1用于平衡基础损失与辅助结构损失,β2β₂β2用于平衡基础损失与辅助强度损失。设计初衷为:通过基础损失保留源图像中的主要信息,辅助结构损失与辅助强度损失为次要损失,用于进一步确保融合图像中的纹理特征与热辐射信息。
为分析超参数敏感性,将β1β₁β1与β2β₂β2的取值范围设为0~1,实验步骤如下:
- 固定β2β₂β2,测试不同β1β₁β1对网络训练的影响。
- 固定β1β₁β1,测试不同β2β₂β2对网络训练的影响。
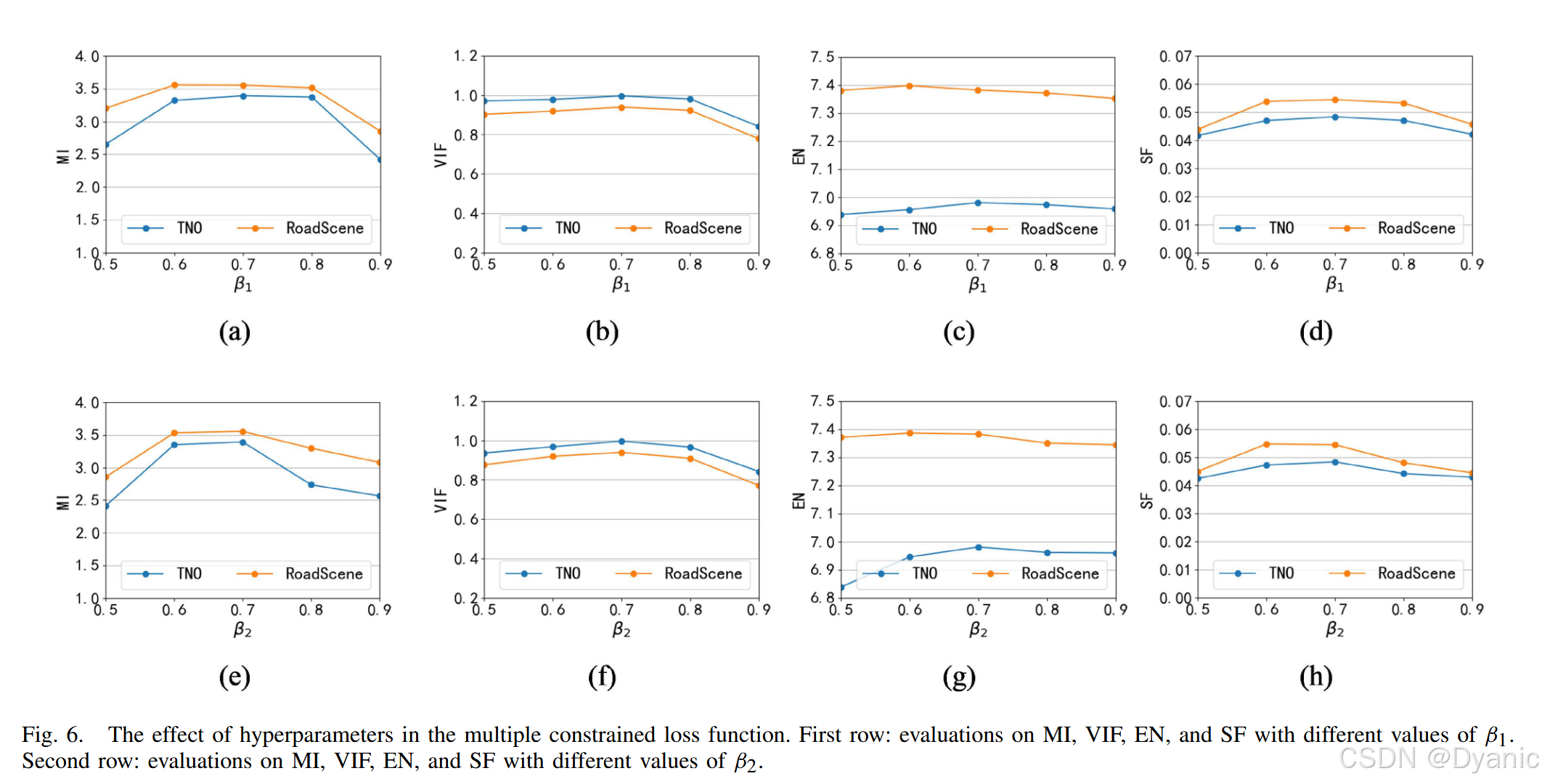
大量实验表明,当β1=0.7β₁=0.7β1=0.7且β2=0.7β₂=0.7β2=0.7时,网络在4项评价指标上均取得最佳性能,结果如图6所示。
4.2.2 损失函数影响
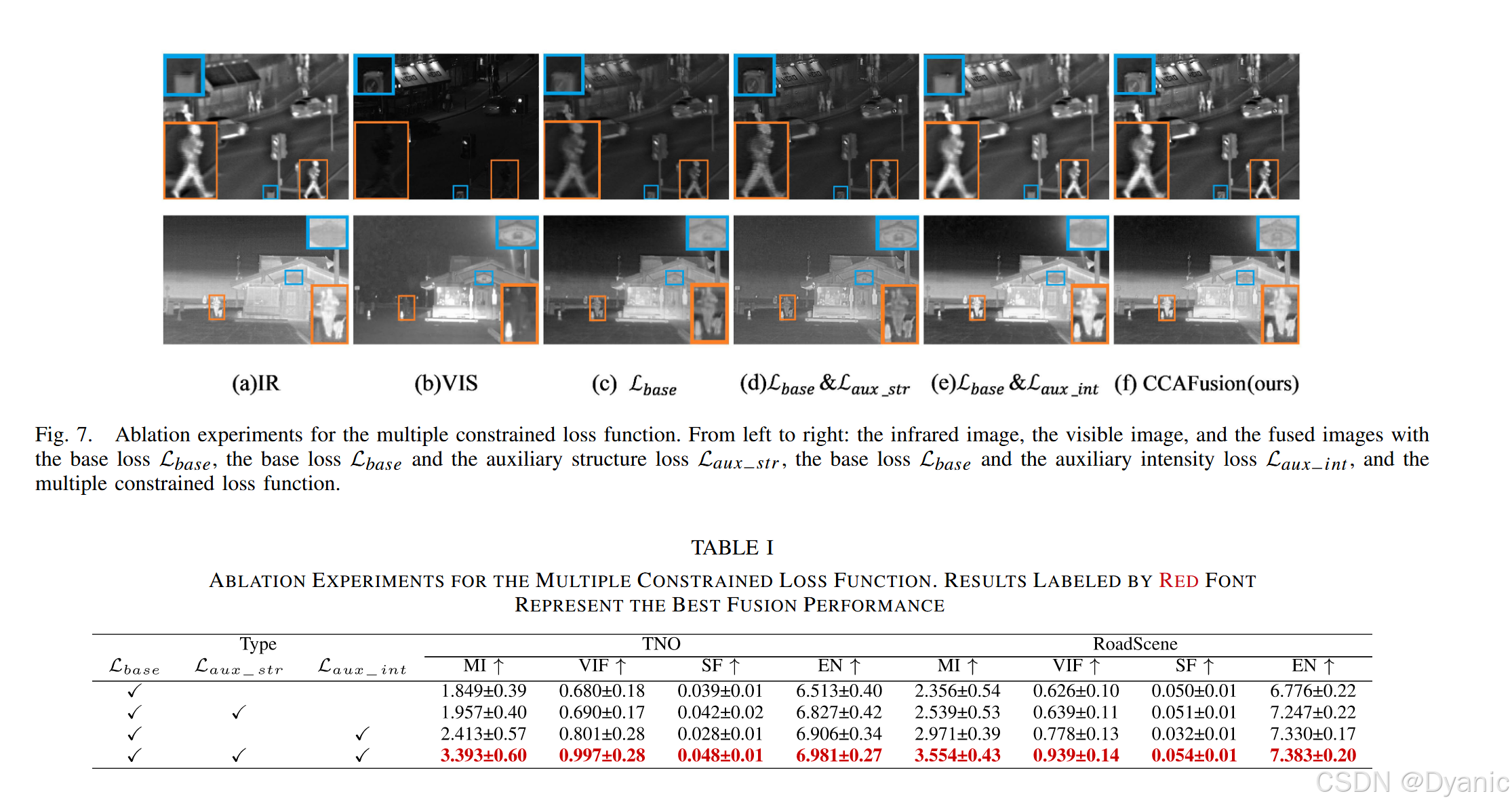
为验证多约束损失函数的有效性,对损失函数的3个组成部分(基础损失Lbase、辅助结构损失Laux-str、辅助强度损失Laux-int)进行消融实验。图7与表1展示了不同损失函数对应的融合结果,分析如下:
- 仅使用基础损失Lbase时:网络仅能保证融合图像的主要灰度分布,但会丢失部分热信息与纹理特征(如图7©所示)。
- 使用基础损失Lbase+辅助结构损失Laux-str时:虽能将源图像的细节传递至融合结果,但热目标显著性不足(如图7(d)所示)。
- 使用基础损失Lbase+辅助强度损失Laux-int时:热信息突出,但细节特征丢失(如图7(e)所示)。
- 使用多约束损失函数时:融合结果同时保留热信息与纹理特征(如图7(f)所示),且在各项定量指标上均取得最高平均值(如表1所示),证明所设计损失函数的有效性。
4.2.3 融合模块影响
为评估融合策略中核心组件的有效性,分别移除CCAFusion的特征感知融合模块(FAF)与特征增强融合模块(FEF),分析其对融合性能的影响:
- 无FEF的融合网络(记为“w/o FEF”)。
- 无FAF的融合网络(记为“w/o FAF”)。
- 完整CCAFusion网络。
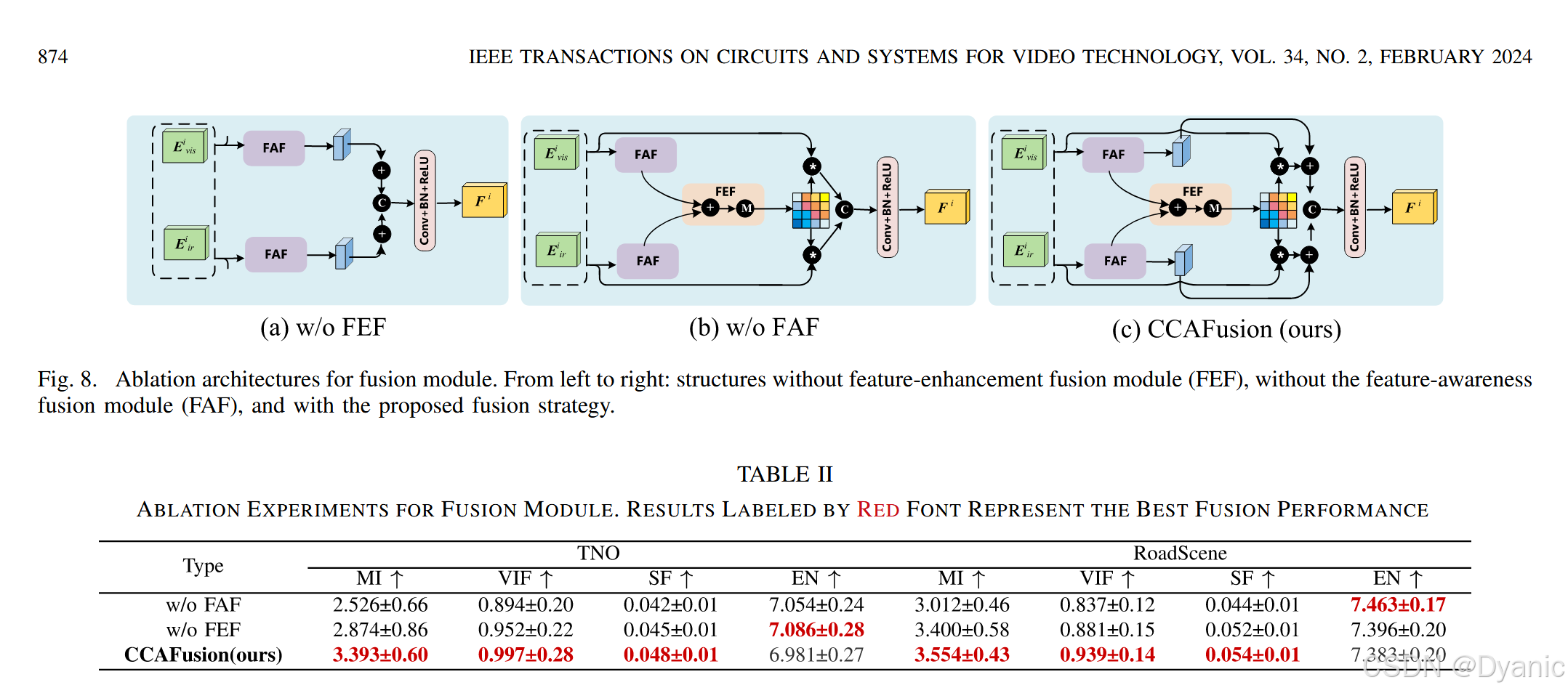
实验结果如图8与表2所示,分析如下:
- CCAFusion在互信息(MI)、视觉信息保真度(VIF)、空间频率(SF)3项指标上均取得最高平均值:
- 互信息(MI)最优:表明CCAFusion能从源图像向融合图像传递更多信息。
- 视觉信息保真度(VIF)最优:表明融合结果与人类视觉感知的一致性更好。
- 空间频率(SF)最优:表明所提方法保留细节信息的能力更优。
- 虽CCAFusion的熵(EN)与“w/o FEF”“w/o FAF”网络差距较小,但结合4.3节与4.4节中与主流方法的对比可知,CCAFusion的融合结果仍包含丰富信息,整体性能更优。
4.2.4 注意力机制影响
为验证坐标注意力(CAM)的有效性,将其与其他常用注意力机制(SE注意力、CBAM)进行对比:将CCAFusion中的CAM替换为SE注意力或CBAM,其他设置保持不变。不同注意力机制的图像融合定量结果如表3所示。
结果表明,得益于CAM对关键通道信息、位置信息及长距离依赖关系的捕捉能力,采用CAM的CCAFusion在互信息(MI)、视觉信息保真度(VIF)、空间频率(SF)3项指标上均取得最优值,熵(EN)与最优值差距较小,证明CAM在CCAFusion中的有效性。
4.3 对比实验
在TNO数据集上,从定性与定量两方面将CCAFusion与当前主流图像融合方法进行对比,以评估其融合性能。
4.3.1 定性对比
为直观展示不同融合方法的性能差异,从TNO数据集中选取3对图像进行定性对比,结果如图9~11所示。每幅图中,图像从左上到右下依次为:红外图像、可见光图像、DenseFuse-add融合图、DenseFuse-L1融合图、MDLatLRR融合图、SDNet融合图、PIAFusion融合图、U2Fusion融合图、CCAFusion融合图。为清晰展示差异,选取每幅融合图中的局部区域(蓝色框与橙色框)放大后置于角落,分析如下:
-
图9:DenseFuse-add、MDLatLRR、SDNet、U2Fusion的融合结果虽在一定程度上保留了热目标,但存在伪影问题。例如,MDLatLRR的融合图中房屋边缘、树枝边缘出现不良光晕或亮边(蓝色框所示),DenseFuse-add、SDNet、U2Fusion也存在类似现象;DenseFuse-L1的融合图无伪影,但显著目标与背景对比度不足,且与可见光图像的天空区域不一致;PIAFusion的融合图保留了背景信息,但丢失了部分树枝纹理;CCAFusion的融合图中树枝纹理与可见光图像最一致,且同时保留了红外图像中的显著目标与可见光图像中的细节,无伪影。
-
图10~11:CCAFusion能有效融合源图像的互补信息。具体而言,图10中,除CCAFusion与PIAFusion外,其他方法的融合图天空区域要么与可见光图像不一致,要么存在伪影污染;而PIAFusion在复杂背景区域的热辐射目标有所弱化。图11中,CCAFusion与SDNet的融合图热辐射目标最显著,但SDNet的融合图背景云层与可见光图像不一致。
综上,CCAFusion既能有效突出红外图像中的显著目标,又在保留可见光图像的细节纹理方面具有优势。
4.3.2 定量对比
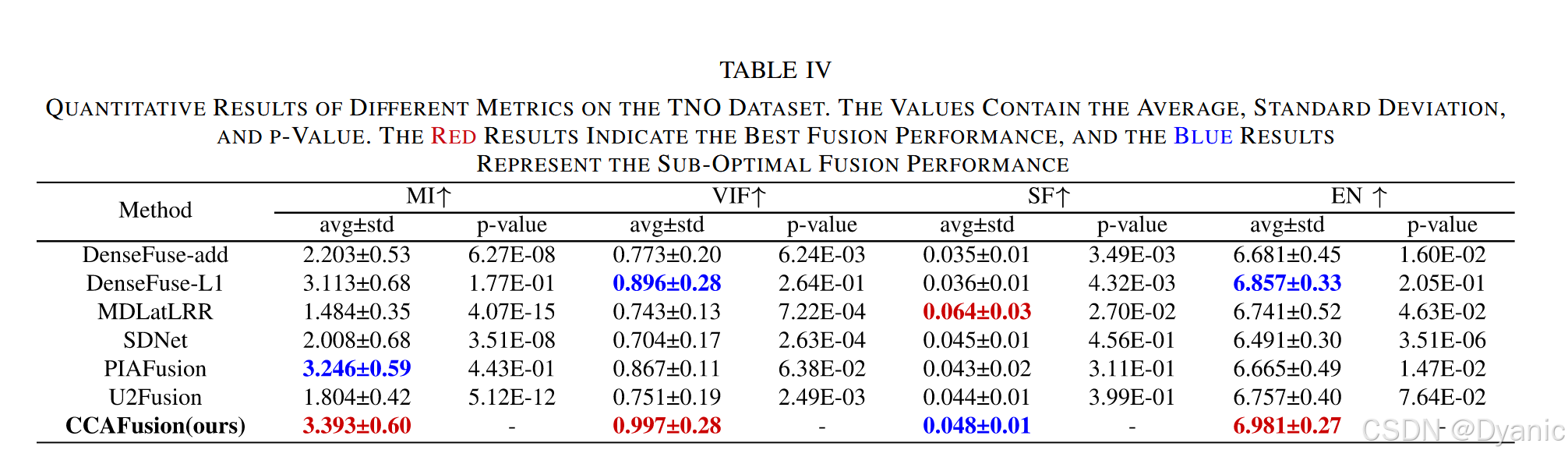
除视觉感知外,通过4种广泛使用的定量指标进一步验证CCAFusion的融合质量。图12与表4展示了TNO数据集21对图像在不同方法下的定量指标对比结果,分析如下:
- 图12:展示了不同融合方法在各定量指标上的直方图分布,数据越靠右偏,表明指标值越大,融合性能越好。
- 表4:列出了各指标的平均值、标准差及p值。由于指标值越大表示融合性能越好,p值基于单侧右尾检验计算(p=Pr(T≥t|H₀),其中T为所提方法的检验统计量,t为对比方法的检验统计量,H₀为原假设,Pr为H₀成立时T至少与t同样极端的概率);红色字体标注最优结果,蓝色字体标注次优结果。
结果表明,在4项指标中,CCAFusion在互信息(MI)、视觉信息保真度(VIF)、熵(EN)3项指标上具有显著优势:
- 互信息(MI)更高:表明CCAFusion的融合图从源图像中获取的信息更多。
- 视觉信息保真度(VIF)更高:表明CCAFusion的融合图信息保真度更好,与人类视觉感知一致性更强。
- 熵(EN)更高:表明CCAFusion的融合图包含的信息更丰富。
在空间频率(SF)上,CCAFusion仅略低于MDLatLRR,原因是MDLatLRR产生的伪影与过度锐化导致其空间频率(SF)偏高。
4.4 泛化实验
为验证CCAFusion的泛化能力,在RoadScene数据集上进行实验。由于RoadScene数据集的可见光图像为RGB图像,采用3.5节所述的RGB-红外融合策略实现融合。
4.4.1 定性对比
图13~15展示了RoadScene数据集中3对图像的融合结果,对比了不同融合算法的性能。为清晰观察视觉差异,用橙色框与蓝色框标记每幅图像的局部区域并放大,分析如下:
DenseFuse-add、MDLatLRR、SDNet、U2Fusion的融合结果存在失真信息,具体表现为:
- 天空颜色失真(如图13、图15所示)。
- 路灯颜色失真(如图14所示)。
DenseFuse-L1与PIAFusion的融合结果中,源图像的纹理信息与显著目标有所弱化(如图13~15所示)。
值得注意的是,CCAFusion有效保留了源图像中的纹理细节与显著目标,无明显失真。
4.4.2 定量对比
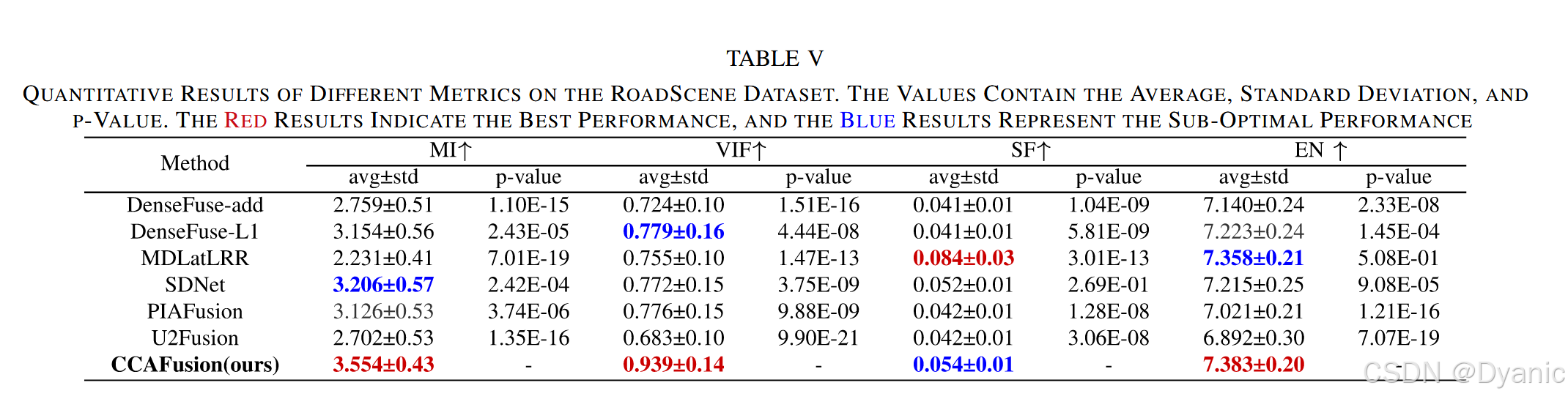
对RoadScene数据集进行定量评估,图16与表5展示了该数据集61对图像在不同方法下的定量指标对比结果:
- 图16:展示了各定量指标的直方图分布,数据越靠右偏,表明指标值越大,融合能力越强。
- 表5:列出了各指标的平均值、标准差及p值,最优结果用红色标注。
结果表明,CCAFusion在RoadScene数据集上仍保持优异性能,进一步验证了其良好的泛化能力。
4.5 效率对比
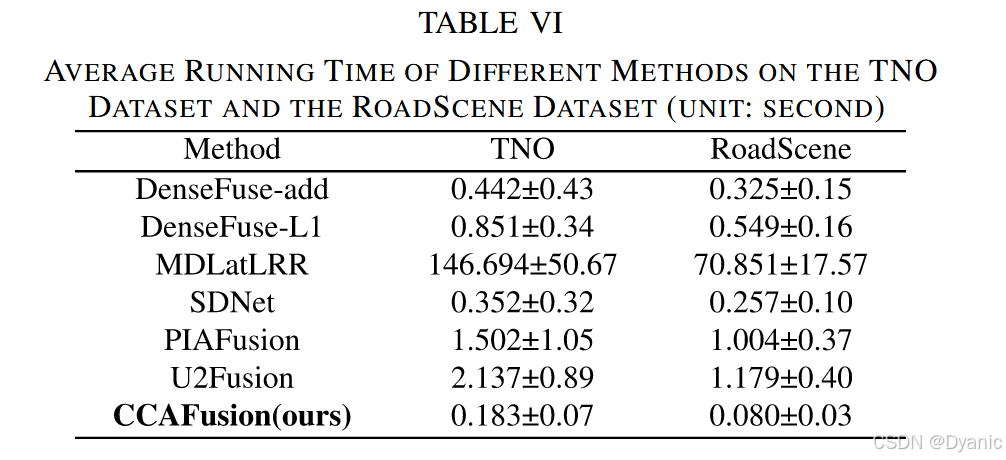
为对比所提方法与其他方法的处理速度,记录不同方法在TNO数据集与RoadScene数据集上的平均运行时间,结果如表6所示。需注意:传统方法(MDLatLRR)在AMD R7-4800H 2.90GHz CPU上运行,其他基于深度学习的方法均在Nvidia 2080Ti GPU上运行。
平均运行时间反映模型的处理速度,运行时间标准差反映模型的稳健性。结果表明:
- 得益于GPU加速,基于深度学习的方法显著快于传统方法。
- 与其他基于深度学习的方法相比,CCAFusion具有竞争力的运算效率与相当的稳健性,可作为高级视觉任务的预处理模块高效部署。
4.6 显著目标检测应用
显著目标检测(SOD)是常见的高级视觉任务之一,旨在识别数字图像中的显著目标或区域。为进一步验证所提融合方法的有效性,将源图像与融合结果分别输入显著目标检测方法[63],并在3个公开的红外-可见光图像对SOD数据集(VT821[64]、VT1000[65]、VT5000[66])上进行测试。
4.6.1 定性对比
图17展示了典型示例,以说明CCAFusion在促进显著目标检测方面的优势,分析如下:
- 可见光图像:受背景限制,无法突出所有显著目标,导致检测结果区域不完整。
- 红外图像:当背景与显著目标混淆时,检测结果与真值(GT)差距较大。
- 融合图像:相较于单模态图像,对显著目标检测具有积极作用;其中,CCAFusion的融合图像因具备强大的热信息与纹理信息整合能力,检测结果与真值最一致。
4.6.2 定量对比
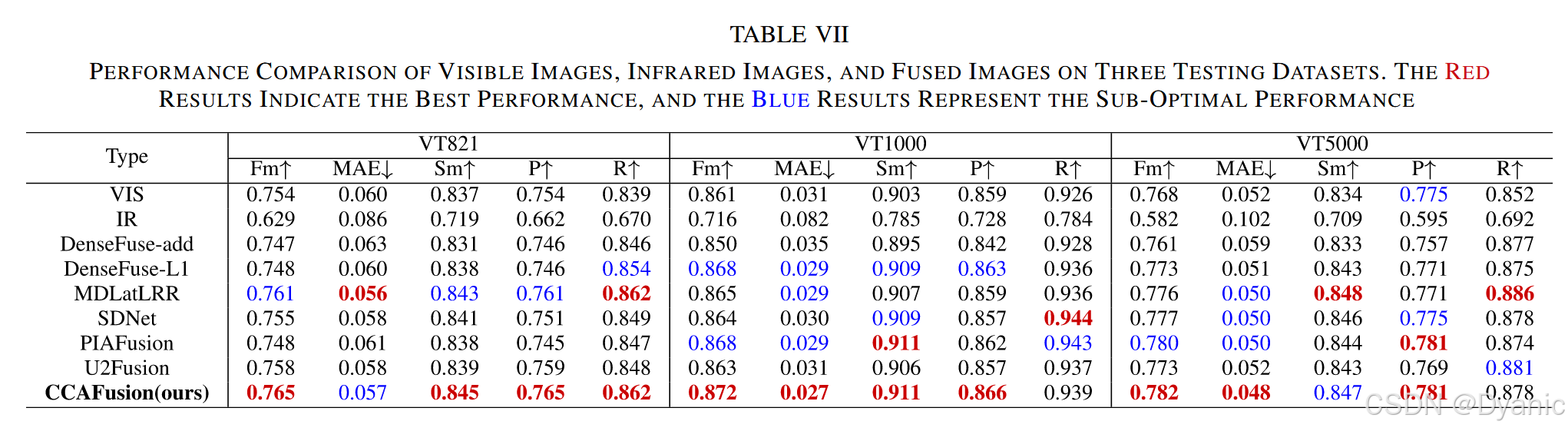
采用定量指标评估显著目标检测性能,结果如表7所示。所用指标定义如下:
- 精度(P)与召回率(R):分别为平均精度与平均召回率。
- F测度(Fm):精度与召回率的加权调和平均数,值越大检测性能越好。
- S测度(Sm):评估预测图与真值图的空间结构相似度,值越大检测性能越好。
- 平均绝对误差(MAE):衡量预测图与真值图在像素级的平均相对误差,值越小检测性能越好。
表7对比了可见光图像、红外图像及不同方法融合图像的检测性能,结果表明:
- 融合图像的检测性能优于单模态图像,证明图像融合对显著目标检测的积极作用。
- DenseFuse-add的融合图像因融合层采用直接相加策略,检测性能较差。
- CCAFusion的融合图像在多数指标上具有明显优势,验证了所提方法的有效性。
综上,CCAFusion的融合图像不仅在红外-可见光图像融合任务中表现优异,还能提升显著目标检测的性能。
4.6.3 注意力机制对比

为进一步对比坐标注意力(CAM)与其他注意力机制在CCAFusion中的性能,将CAM替换为常用的SE注意力与CBAM,其他设置与原CCAFusion一致。不同注意力机制的定性与定量结果分别如图18与表8所示,分析如下:
- 定性结果(图18):采用CAM的CCAFusion在显著目标检测中表现优于SE注意力与CBAM。
- 定量结果(表8):采用CAM的CCAFusion在多数指标上优于其他注意力机制。
优势原因分析:
- SE注意力:仅考虑通道间信息,忽略位置信息的重要性。
- CBAM:虽同时考虑通道信息与位置信息,但缺乏长距离依赖关系捕捉能力。
- CAM:可同时捕捉通道与位置重要性及长距离依赖关系,因此CCAFusion采用CAM能获得更优性能。
5 结论
本文提出一种用于红外与可见光图像融合的高效跨模态坐标注意力网络(CCAFusion),具体工作如下:
- 设计跨模态坐标注意力融合策略,实现互补特征的有效融合;将该融合策略应用于不同尺度,以充分利用多层次信息。
- 定义由基础损失与辅助损失组成的多约束损失函数,用于调整融合图像的灰度分布,确保其结构与强度和谐共存。
大量对比实验表明,无论是定性评价还是定量指标,CCAFusion均优于当前主流图像融合方法;此外,在显著目标检测上的扩展实验证明,CCAFusion能有效促进高级视觉任务的性能。






)


)







】)

