大纲
1.并发类容器
2.volatile关键字与内存分析
3.Atomic系列类与UnSafe类
4.JUC常用工具类
5.AQS各种锁与架构核心
6.线程池的最佳使用指南
1.并发类容器
(1)ConcurrentMap
(2)CopyOnWrite容器
(3)ArrayBlockingQueue
(4)LinkedBlockingQueue
(5)SynchronousQueue
(6)PriorityBlockingQueue
(7)DelayQueue
(1)ConcurrentMap
ConcurrentMap是Map的子接口,是高并发下线程安全的Map集合。ConcurrentMap有两个实现类:
ConcurrentHashMap
ConcurrentSkipListMapConcurrentHashMap采取了分段锁的技术来细化锁的粒度,把整个Map划分为一系列Segment的组成单元,一个Segment相当于一个小的HashTable。
ConcurrentSkipListMap的底层是通过跳表来实现的,跳表是一个链表,其插入、读取数据的复杂度为O(logn)。
(2)CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。当我们往一个容器中添加元素时,不直接往容器中添加,而是将当前容器进行copy,复制出来一个新的容器。然后向新容器中添加需要的元素,最后将原容器的引用指向新容器。这样做的好处是:可在并发场景下对容器进行读操作而无需加锁,从而实现读写分离。
Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,分别是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器适用于读多写少 + 元素不会特别多的场景。
(3)ArrayBlockingQueue
ArrayBlockingQueue是最典型的有界阻塞队列,其内部是用数组存储元素的,初始化时需要指定容量大小,利用ReentrantLock实现线程安全。
(4)LinkedBlockingQueue
LinkedBlockingQueue是一个基于链表实现的阻塞队列。默认情况下,该阻塞队列的大小为Integer.MAX_VALUE。由于这个数值特别大,所以LinkedBlockingQueue也被称作无界队列,代表它几乎没有界限,队列可以随着元素的添加而动态增长。但是如果没有剩余内存,则队列将抛出OOM错误。所以为了避免队列过大造成机器负载或者内存爆满的情况出现,在使用LinkedBlockingQueue时建议手动传一个队列的大小。
LinkedBlockingQueue内部由单链表实现,只能从head取元素,从tail添加元素。并且采用两把锁的锁分离技术实现入队出队互不阻塞,添加元素和获取元素都有独立的锁。也就是说LinkedBlockingQueue是读写分离的,读写操作可以并行执行。
(5)SynchronousQueue
SynchronousQueue是无缓冲阻塞队列,用来在两个线程之间移交元素。它并不是真正的队列,不维护存储空间,而维护一组线程,这些线程在等待放入或移出元素。
SynchronousQueue是一种极为特殊的阻塞队列,它没有实际的容量。任意线程都会等待获取到数据或者交付完数据才会返回,这里任意线程指的是生产者线程或者消费者线程。生产类型的操作比如put、offer,消费类型的操作比如poll、take。一个生产者线程的使命是将线程中的数据交付给另一个消费者线程,而一个消费者线程则是等待一个生产者线程中的数据。
(6)PriorityBlockingQueue
PriorityBlockingQueue是带优先级的无界阻塞队列,每次出队都返回优先级最好或最低的元素,内部是平衡二叉树的实现。
(7)DelayQueue
DelayQueue是一个无界阻塞队列,用于放置实现了Delayed接口的对象,其中的对象只能在其到期时才能从队列中取走。这种队列是有序的,即队头对象的延迟到期时间最长,注意不能将null元素放置到这种队列中。
2.volatile关键字与内存分析
(1)volatile关键字的作用
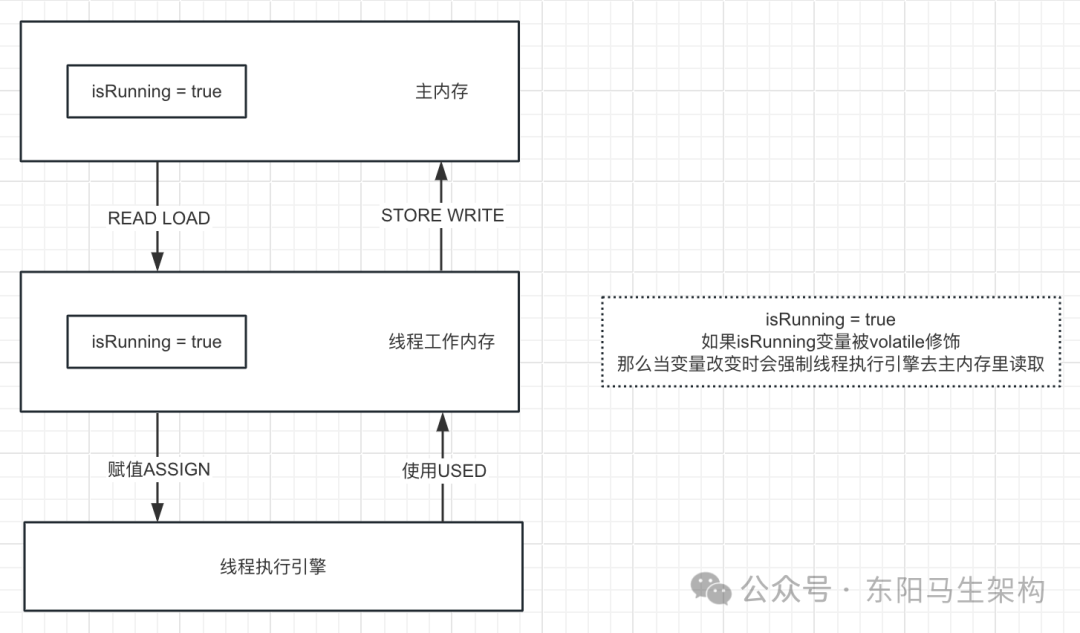
(2)volatile的内存分析
(1)volatile关键字的作用
作用一:多线程间的可见性
作用二:阻止指令重排序
那些支持热部署、支持动态更新的框架会大量使用volatile关键字。此外,ZooKeeper的Watcher机制也可以支持对配置的动态感知。
(2)volatile的内存分析
3.Atomic系列类与UnSafe类
(1)Atomic与UnSafe类的关系
(2)UnSafe类的四大作用
(1)Atomic与UnSafe类的关系
Atomic系列类提供了原子性操作,保证了多线程下的并发安全,Atomic底层是通过调用UnSafe类的CAS方法来实现原子性操作的。
由于UnSafe类可以直接访问操作系统底层硬件,而Java没办法直接访问操作系统底层,所以需借助UnSafe类来实现CAS。
(2)UnSafe类的四大作用
作用一:进行内存操作,比如UnSafe类的allocateMemory()和freeMemory()方法等。
作用二:字段的定位与修改,比如UnSafe类的getInt()和putInt()方法等。
作用三:挂起与恢复线程,比如JDK的LockSupport类,会通过UnSafe类的park()和unpark()方法实现挂起和恢复线程。
作用四:CAS操作(乐观锁),比如UnSafe类的compareAndSwapObject()系列方法就实现了CAS操作。
4.JUC常用工具类
(1)CountDownLatch和CyclieBarrier
(2)Future模式与Callable接口
(3)Exchanger线程数据交换器
(4)ForkJoin并行计算
(5)Semaphore信号量
(1)CountDownLatch和CyclieBarrier
CountDownLatch主要是阻塞一个线程,即阻塞当前的线程,然后调用countdown()方法减到0时就会唤醒阻塞的当前线程。
CountDownLatch和CyclicBarrier的区别:CountDownLatch是一次的阻塞、一个线程的阻塞。比如new一个CountDownLatch时设置为3,当前线程调用await()方法被阻塞,那么必须有线程总共调用3次countdown()方法,当前线程才能继续往下执行。
CyclieBarrier也可以设置一个阈值,比如这个阈值设置为5。有5个线程都调用await()方法,当这5个线程全部准备就绪后才一起往下。
(2)Future模式与Callable接口
Future模式用于让当前线程异步去提交工作,然后进行等待,等到负责异步回调的线程真正执行完之后,当前线程通过调用get()方法就能获取到数据。
(3)Exchanger线程数据交换器
Exchanger可以实现两个线程间的数据的交换,Exchanger通常用于一些对账场景。比如线程A和线程B同时接收同样的数据,进行磁盘IO读写等操作。线程A和线程B执行完都有一个结果,可通过Exchanger对比结果是否一致。
(4)ForkJoin并行计算
ForkJoin的核心就是通过递归拆分将一个大任务拆分成若干的小任务,然后对这些拆分的小任务进行并行计算,接着通过join()整合计算结果,最后计算出统计的结果。
(5)Semaphore信号量
Semaphore可以控制能够同时进行并发访问的线程数量,比如设置了Semaphore最多允许5个线程可以并发进行访问。如果出现20个线程,那么会有15个线程进入Semaphore的AQS对列。
5.AQS各种锁与架构核心
(1)ReentrantLock重入锁
(2)ReentrantReadWriteLock读写锁
(3)Condition条件判断
(4)LookSupport基于线程的锁
(5)AQS架构简介
(6)ReentrantLock底层原理简介
(7)CountDownLatch底层原理简介
(1)ReentrantLock重入锁
ReentrantLock是基于AQS的,AQS的两大核心:一是共享变量state,二是CLH等待队列。重入指的是同一个线程可以反复获得这个ReentrantLock。
Object锁要配合Synchronized + wait() + notify()来实现线程间的阻塞唤醒,而且需要注意的是:wait()方法会释放锁,notify()方法不会释放锁。
ReentrantLock可以通过Condition来实现线程间的阻塞和唤醒,比如使用Condition的await()方法和signal()方法,而且需要注意的是:await()方法会释放锁,signal()方法不会释放锁。
(2)ReentrantReadWriteLock读写锁
ReentrantReadWriteLock也是基于AQS的,可以实现读写分离。
(3)Condition条件判断
Condition条件判断是配合ReentrantLock或者ReentrantReadWriteLock使用的,可以使用类似于Synchronized锁下的wait()方法和notify()方法进行线程阻塞与唤醒。
(4)LookSupport基于线程的锁
LookSupport有两个关键的方法:park()和unpark()。LookSupport的这两个方法会调用UnSafe类中的park()和unpark()方法,分别用来挂起指定线程和唤醒指定线程。
注意:LookSupport唤醒和挂起线程的顺序并没有先后关系,也就是对于同一个线程,先执行unpark()再执行park()也不会影响。
(5)AQS架构简介
一.AQS维护了一个state和一个线程等待队列
其中volatile int state代表着共享资源,多线程争用资源被阻塞时会进入一个FIFO线程等待队列。
二.AQS定义了独占和共享两种资源处理方式
比如ReentrantLock使用的是Exclusive独占的方式,Semaphore使用的是Share共享的方式。
三.AQS的核心方法
isHeldExclusively()方法:
判断线程是否正在独占资源。
tryAcquire()和tryRelease()方法:
表示以独占的方式尝试获取和释放资源。
tryAcquireShared()和tryReleaseShared()方法:
表示以共享的方式尝试获取和释放资源。
(6)ReentrantLock底层原理简介
首先state会初始化为0,表示未锁定状态。当线程A调用ReentrantLock的lock()方法时,会触发调用tryAcquire()方法以独占方式获取锁并将state + 1。此后其他线程调用tryAcquire()方法时就会失败,直到线程A调用ReentrantLock的unlock()方法释放锁(将state减为0)为止。线程A在释放锁之前,可以重复获取锁,重复获取锁时,state会累加,这就是可重入的原理。但获取锁多少次(重入锁多少次/state累加了多少次),就要释放锁多少次,这样才能保证state能回到初始值为0的时候。
(7)CountDownLatch底层原理简介
如果任务分为N个子线程去执行,那么state会初始化为N。这N个子线程是并行执行的,每个子线程执行完就会countdown()一次。每countdown()一次,state就会通过CAS减1。等所有子线程都执行完后(即state=0),会调用unpark()方法唤醒线程,然后主线程从await()方法中返回,继续后面的处理。
public class TestSynchronized {public static void main(String[] args) throws Exception {Object lock = new Object();Thread threadA = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("线程A开始计算");int sum = 0;for (int i = 0; i < 10; i++) {sum += i;}synchronized (lock) {try {System.out.println("线程A先进行阻塞,等待被唤醒");//wait()会阻塞线程A,并且释放synchronized锁lock.wait();} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("线程A计算出的结果sum: " + sum);}});System.out.println("主线程启动线程A");threadA.start();Thread.sleep(2000);synchronized (lock) {System.out.println("主线程唤醒线程A");//唤醒阻塞的线程Alock.notify();}}
}
//执行程序输出的结果如下:
//主线程启动线程A
//线程A开始计算
//线程A先进行阻塞,等待被唤醒
//主线程唤醒线程A
//线程A计算出的结果sum: 45public class ConditionTest {public static void main(String[] args) throws Exception {ReentrantLock lock = new ReentrantLock();Condition condition = lock.newCondition();new Thread() {@Overridepublic void run() {lock.lock();System.out.println("第一个线程加锁");int sum = 0;for (int i = 0; i < 10; i++) {sum += i;}try {System.out.println("第一个线程释放锁以及阻塞等待");condition.await();System.out.println("第一个线程被唤醒重新获取锁");} catch (Exception e) {e.printStackTrace();}System.out.println("第一个线程计算出的结果sum: " + sum);lock.unlock();System.out.println("第一个线程释放锁");}}.start();Thread.sleep(3000);new Thread() {public void run() {lock.lock();System.out.println("第二个线程加锁");System.out.println("第二个线程唤醒第一个线程");condition.signal();lock.unlock();System.out.println("第二个线程释放锁");}}.start();}
}
//执行程序输出的结果如下:
//第一个线程加锁
//第一个线程释放锁以及阻塞等待
//第二个线程加锁
//第二个线程唤醒第一个线程
//第二个线程释放锁
//第一个线程被唤醒重新获取锁
//第一个线程计算出的结果sum: 45
//第一个线程释放锁public class LockSupportTest {public static void main(String[] args) throws Exception {Thread threadA = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("线程A开始运行");int sum = 0;for (int i = 0; i < 10; i++) {sum += i;}System.out.println("挂起线程A");LockSupport.park();System.out.println("线程A被唤醒,输出计算出结果sum: " + sum);}});threadA.start();Thread.sleep(2000);System.out.println("唤醒线程A");LockSupport.unpark(threadA);}
}
//执行程序输出的结果如下:
//线程A开始运行
//挂起线程A
//唤醒线程A
//线程A被唤醒,输出计算出结果sum: 45public class Review {public static void main(String[] args) throws Exception {Thread threadA = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("线程A开始运行");int sum = 0;for (int i = 0; i < 10; i++) {sum += i;}try {Thread.sleep(4000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程A然后再被挂起");LockSupport.park();System.out.println("线程A还是会被唤醒,输出计算出结果sum: " + sum);}}); threadA.start();Thread.sleep(2000);System.out.println("主线程先唤醒线程A");LockSupport.unpark(threadA);}
}
//执行程序输出的结果如下:
//线程A开始运行
//主线程唤醒线程A
//挂起线程A
//线程A被唤醒,输出计算出结果sum: 456.线程池的最佳使用指南
(1)Excutors工厂类
(2)ThreadPoolExecutor自定义线程池
(3)如何确定线程池的线程数量
(4)如何正确使用线程池
(1)Excutors工厂类
Excutors提供了很多方法,比如newFixedThreadPool()等。但是不建议使用Excutors工厂类里的创建线程池方法,因为这些创建线程池的方法里很多都没有界限限制的,存在安全隐患。比如使用newFixedThreadPool()方法创建线程池时,没有限制阻塞队列长度。比如使用newCachedThreadPool()方法创建线程池时,没有限制线程数量。
(2)ThreadPoolExecutor自定义线程池
public class ThreadPoolExecutor extends AbstractExecutorService {...//@param corePoolSize://the number of threads to keep in the pool, even if they are idle, //unless allowCoreThreadTimeOut is set//@param maximumPoolSize://the maximum number of threads to allow in the pool//@param keepAliveTime://when the number of threads is greater than the core, //this is the maximum time that excess idle threads will wait for new tasks before terminating.//@param unit://the time unit for the keepAliveTime argument//@param workQueue://the queue to use for holding tasks before they are executed.//This queue will hold only the Runnable tasks submitted by the execute method.//@param threadFactory://the factory to use when the executor creates a new thread//@param handler//the handler to use when execution is blocked because the thread bounds and queue capacities are reachedpublic ThreadPoolExecutor(//核心线程数int corePoolSize,//最大线程数int maximumPoolSize,//空闲线程的回收时间long keepAliveTime,TimeUnit unit,//存放任务的队列BlockingQueue<Runnable> workQueue,//线程工厂ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) {throw new IllegalArgumentException();}if (workQueue == null || threadFactory == null || handler == null) {throw new NullPointerException();}this.acc = System.getSecurityManager() == null ? null : AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;//拒绝策略}...
}(3)如何确定线程池的线程数量
一.计算密集型
一般来说,计算密集型的一个线程执行比较快,线程数 = CPU核数 + 1 或 CPU核数 * 2。
二.IO密集型
一般来说,IO密集型的一个线程执行比较慢,线程数 = CPU核数 / (1 - 阻塞系数),其中阻塞系数一般是0.8或0.9。
一个应用服务的线程池一定要统一起来进行管理,创建新的线程池的时候,需要知道当前应用系统运行时究竟会使用多少线程。
(4)如何正确使用线程池
一.注意线程池的相关配置
二.利用hook嵌入线程的行为
三.需要优雅关闭线程池
一.注意线程池的相关配置
比如线程数量、阻塞队列的大小等。注意:newFixedThreadPool()方法创建线程池时不会限制阻塞队列长度,newCachedThreadPool()方法创建线程池时不会限制线程数量。
二.利用hook嵌入线程的行为
ThreadPoolExecutor中有beforeExecute()方法和afterExecute()方法,因此可以在某一个线程执行前和执行后输出一些关键的日志。这样在线程运行失败时,便可以进行更加详细的分析。
三.需要优雅关闭线程池
一般为了避免线程池没有合理关闭,都推荐使用Spring创建线程池,然后直接在执行destroy()方法进行销毁时调用shutdown()方法即可。从而确保服务关闭时,线程池也被关闭掉。

)
“ 报 errCode: 10008 的解决方案)




)









)
)
