LAS
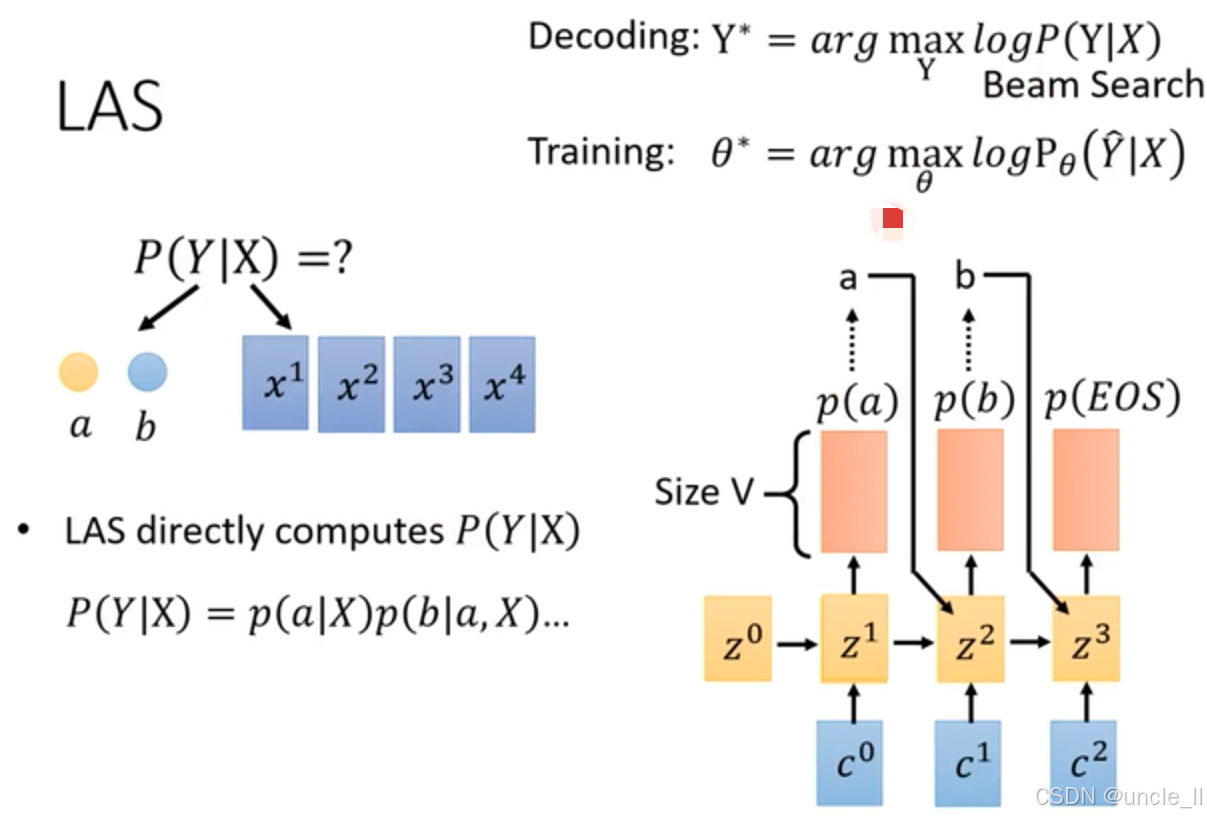
LAS(Listen, Attend and Spell )模型,在语音识别中的解码和训练过程,具体内容如下:
解码(Decoding)
- 公式 Y ∗ = arg max Y log P ( Y ∣ X ) Y^* = \arg\max_Y \log P(Y|X) Y∗=argmaxYlogP(Y∣X) 表示解码阶段的目标是找到使对数条件概率 log P ( Y ∣ X ) \log P(Y|X) logP(Y∣X) 最大的文本序列 Y ∗ Y^* Y∗。这里使用束搜索(Beam Search)算法实现,该算法在每一步保留若干个概率最高的候选路径,以平衡计算量和搜索效果,避免穷举所有可能序列。
训练(Training)
- 公式 θ ∗ = arg max θ log P θ ( Y ^ ∣ X ) \theta^* = \arg\max_{\theta} \log P_{\theta}(\hat{Y}|X) θ∗=argmaxθlogPθ(Y^∣X) 表示训练阶段要找到最优的模型参数 θ ∗ \theta^* θ∗,使模型在给定语音特征 X X X 时,预测文本序列 Y ^ \hat{Y} Y^ 的对数概率最大。通过最大化这个对数似然函数,调整模型参数以提升对语音 - 文本映射关系的学习能力。
模型计算
- 延续前文,再次强调 “LAS directly computes P ( Y ∣ X ) P(Y|X) P(Y∣X)” ,计算方式为 P ( Y ∣ X ) = p ( a ∣ X ) p ( b ∣ a , X ) ⋯ P(Y|X) = p(a|X)p(b|a, X)\cdots P(Y∣X)=p(a∣X)p(b∣a,X)⋯ ,即依次计算每个 token 基于语音特征和已生成 token 的条件概率。
- 右侧展示模型结构,黄色解码器单元 z 0 − z 3 z^0 - z^3 z0−z3结合蓝色上下文向量 c 0 − c 2 c^0 - c^2 c0−c2 输出不同 token 概率(如 p ( a ) p(a) p(a)、 p ( b ) p(b) p(b)、 p ( E O S ) p(EOS) p(EOS)),用于生成文本序列。
CTC, RNN-T
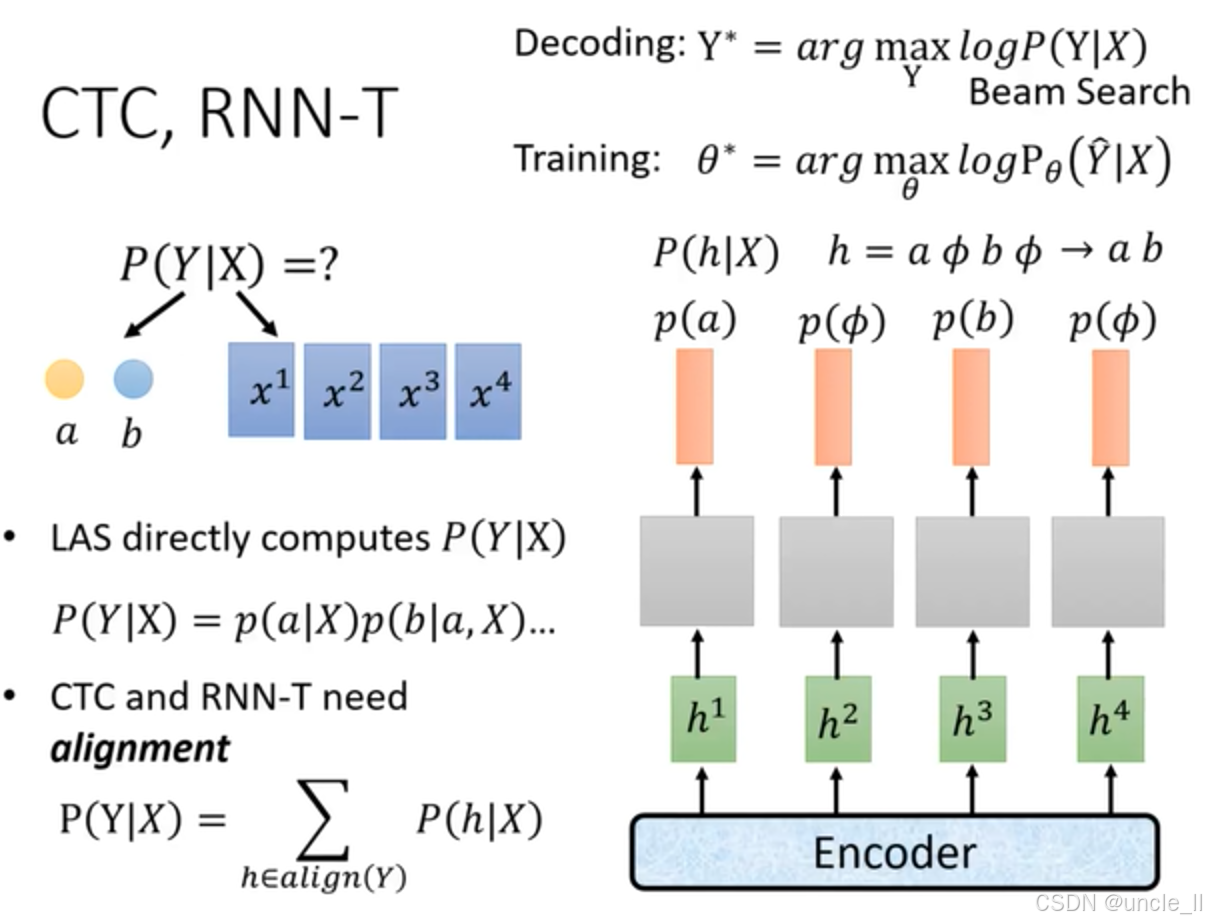
这张图对比了LAS与CTC、RNN - T在语音识别中的原理,重点阐述了CTC和RNN - T的特性:
解码与训练基础
- 解码:公式 Y ∗ = arg max Y log P ( Y ∣ X ) Y^* = \arg\max_Y \log P(Y|X) Y∗=argmaxYlogP(Y∣X) 表示解码目标是找出使对数条件概率 log P ( Y ∣ X ) \log P(Y|X) logP(Y∣X) 最大的文本序列 Y ∗ Y^* Y∗,通过束搜索(Beam Search)实现。
- 训练:公式 θ ∗ = arg max θ log P θ ( Y ^ ∣ X ) \theta^* = \arg\max_{\theta} \log P_{\theta}(\hat{Y}|X) θ∗=argmaxθlogPθ(Y^∣X) 意味着训练时要找到最优参数 θ ∗ \theta^* θ∗,最大化模型预测文本序列 Y ^ \hat{Y} Y^ 基于语音特征 X X X的对数概率。
LAS模型特点
- LAS直接计算 P ( Y ∣ X ) P(Y|X) P(Y∣X) ,计算方式为 P ( Y ∣ X ) = p ( a ∣ X ) p ( b ∣ a , X ) ⋯ P(Y|X) = p(a|X)p(b|a, X)\cdots P(Y∣X)=p(a∣X)p(b∣a,X)⋯,依次计算每个token基于语音特征及已生成token的条件概率。
CTC和RNN - T模型特点
- 对齐需求:与LAS不同,CTC和RNN - T需要进行对齐(alignment)操作。模型通过编码器得到隐藏状态 h 1 − h 4 h^1 - h^4 h1−h4,计算 P ( h ∣ X ) P(h|X) P(h∣X),其中 h h h 序列包含空白符 ϕ \phi ϕ (如 h = a ϕ b ϕ h = a \phi b \phi h=aϕbϕ) 。
- 概率计算:CTC和RNN - T计算 P ( Y ∣ X ) P(Y|X) P(Y∣X) 时,需对所有与目标文本序列 Y Y Y 对齐的路径 h h h求和,即 P ( Y ∣ X ) = ∑ h ∈ a l i g n ( Y ) P ( h ∣ X ) P(Y|X) = \sum_{h \in align(Y)} P(h|X) P(Y∣X)=∑h∈align(Y)P(h∣X)。最终将含空白符的 h h h 序列映射为目标文本序列(如 a ϕ b ϕ → a b a \phi b \phi \to a b aϕbϕ→ab ),解决语音与文本时间不对齐问题。
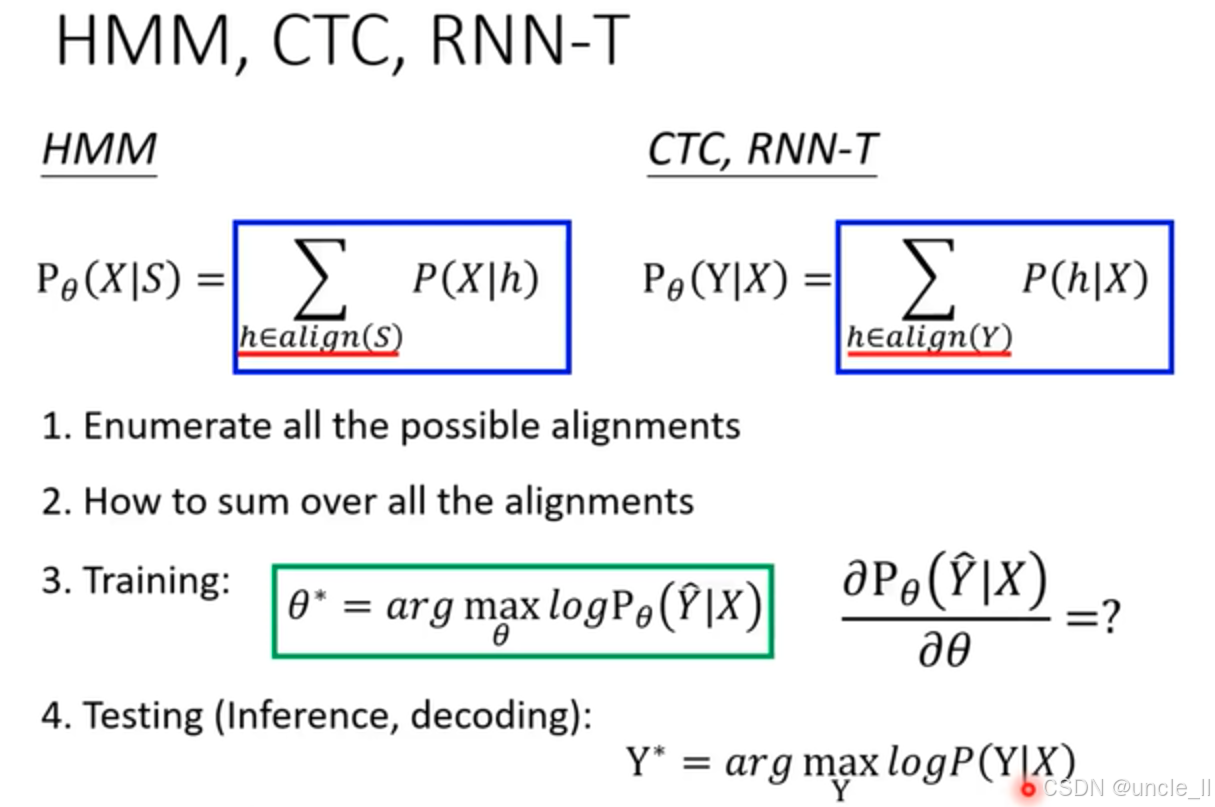
怎么穷举所有的可能组合
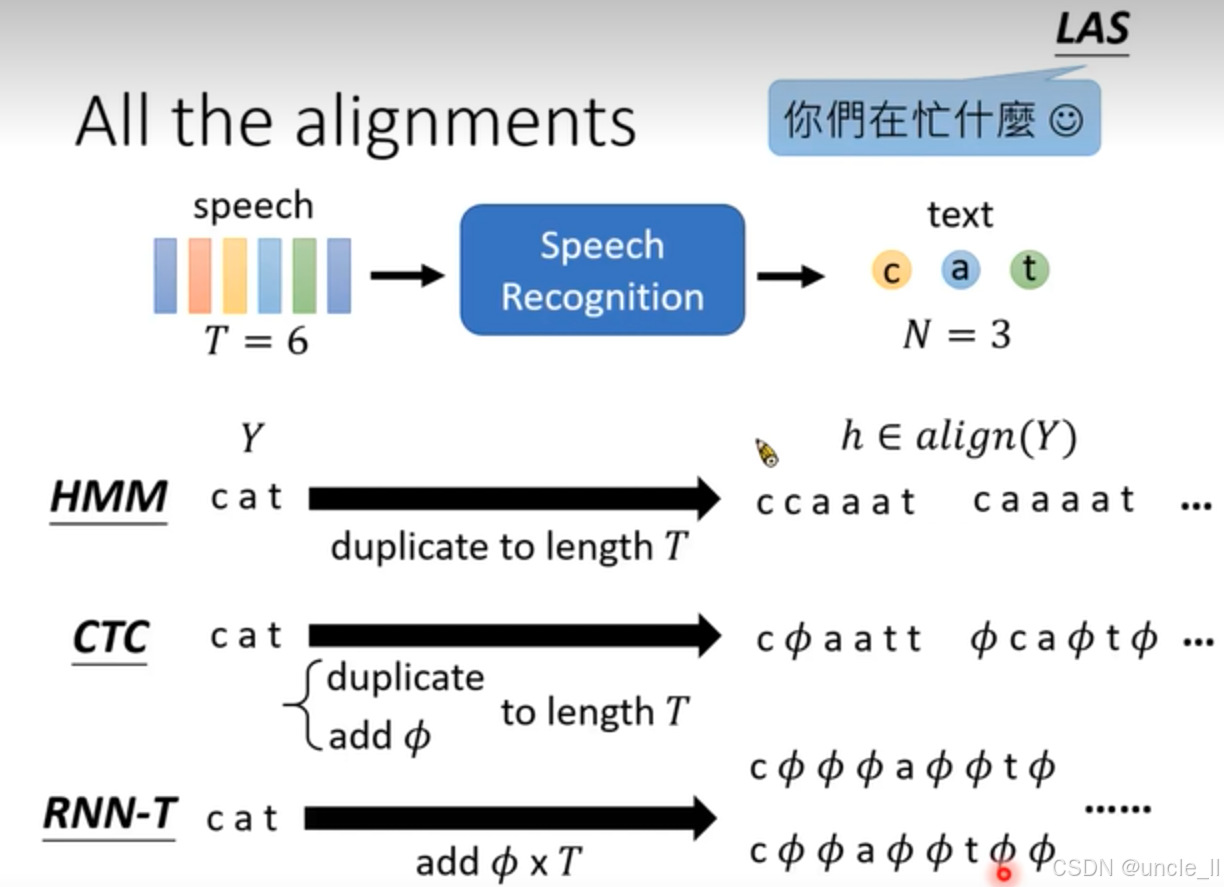
语音识别的对齐方式:
- 图表中部从 “speech”(时长T = 6)到 “text”(字数N = 3)的流程,直观呈现了语音识别从输入语音信号到输出文本的过程。这里时长T和字数N的标注,体现了语音和文本在长度上的对应关系,也是对齐操作需要解决的关键问题,即如何将时长为T的语音准确对应到字数为N的文本上。
不同方法展示
- HMM:HMM(隐马尔可夫模型)在语音识别中通过状态转移和发射概率来建模语音信号。这里展示将 “cat” 扩展到长度T的方式,反映了HMM如何将离散的文本单元对应到连续的语音片段上。其示例结果展示了HMM在对齐过程中的具体实现,可能是通过一系列状态转移来匹配语音的不同时段和文本的每个字符。
- CTC:CTC(Connectionist Temporal Classification)是一种用于解决序列对齐问题的方法。它通过引入空白符,允许模型在不需要预先知道语音和文本精确对齐关系的情况下进行训练。图中展示的将 “cat” 扩展到长度T的示例,体现了CTC在处理语音和文本对齐时的灵活性,它可以自动处理语音和文本之间的时间不对齐问题。
- RNN - T:RNN - T(RNN Transducer)也是一种处理序列到序列任务的模型。它结合了循环神经网络和变换器的特点,能够直接对语音和文本进行联合建模。图中展示的将 “cat” 扩展到长度T的示例,展示了RNN - T在语音识别对齐中的具体操作方式,它可能通过递归计算来逐步生成文本序列,同时考虑语音的上下文信息。
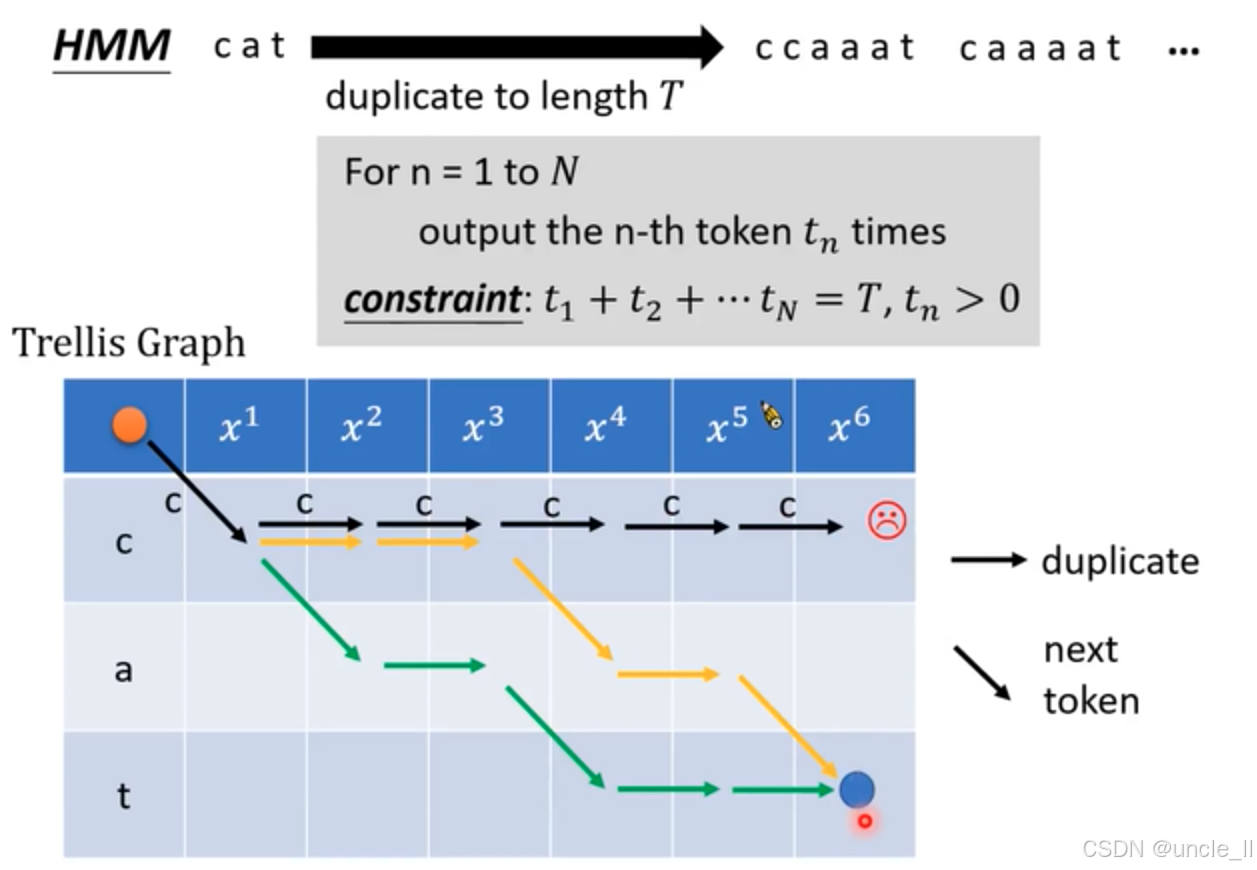
隐马尔可夫模型(HMM)在语音识别中的对齐过程展开,详细展示了将文本 “cat” 扩展到指定长度 T T T 的方法以及对应的网格图表示,以下是详细解释:
文本扩展部分
- 扩展目标与方式:图上方左侧 “HMM” 标识表明这部分内容基于隐马尔可夫模型。“cat” 通过向右的黑色粗箭头指向 “ccaaat caaaat …” ,将 “cat” 中的每个字符重复若干次,以达到总长度为 T T T 的序列。
- 约束条件:灰色文本框内的公式 “For n = 1 to N output the n - th token t n t_n tn times constraint: t 1 + t 2 + ⋯ t N = T , t n > 0 t_1 + t_2+\cdots t_N = T, t_n > 0 t1+t2+⋯tN=T,tn>0” 给出了具体的约束条件。这里 N N N 是文本 “cat” 的字符数量( N = 3 N = 3 N=3), t n t_n tn 表示第 n n n 个字符重复的次数,所有字符重复次数之和要等于 T T T,且每个字符至少重复一次。
- 网格图标识:中间左侧 “Trellis Graph” 表明这是一个网格图,常用于表示序列对齐过程中的状态转移。
- 网格内容:第一行蓝色方格内的 x 1 x^1 x1 到 x 6 x^6 x6 代表语音信号的不同时刻或特征,其中 x 5 x^5 x5 旁的火箭图标和 x 6 x^6 x6旁的红色表情图标可能是用于特殊标记或强调。左侧三行灰色方格内的 c、a、t 对应文本 “cat” 中的字符。
- 箭头含义:黑色箭头 “duplicate” 表示字符重复,即沿着同一行继续选择相同字符;黑色细箭头 “next token” 表示切换到下一个字符。从左上角橙色圆点开始,不同颜色的箭头代表不同的对齐路径,最终都指向右下角蓝色圆点,蓝色圆点下的红色亮点表示最终的结束状态或目标状态。

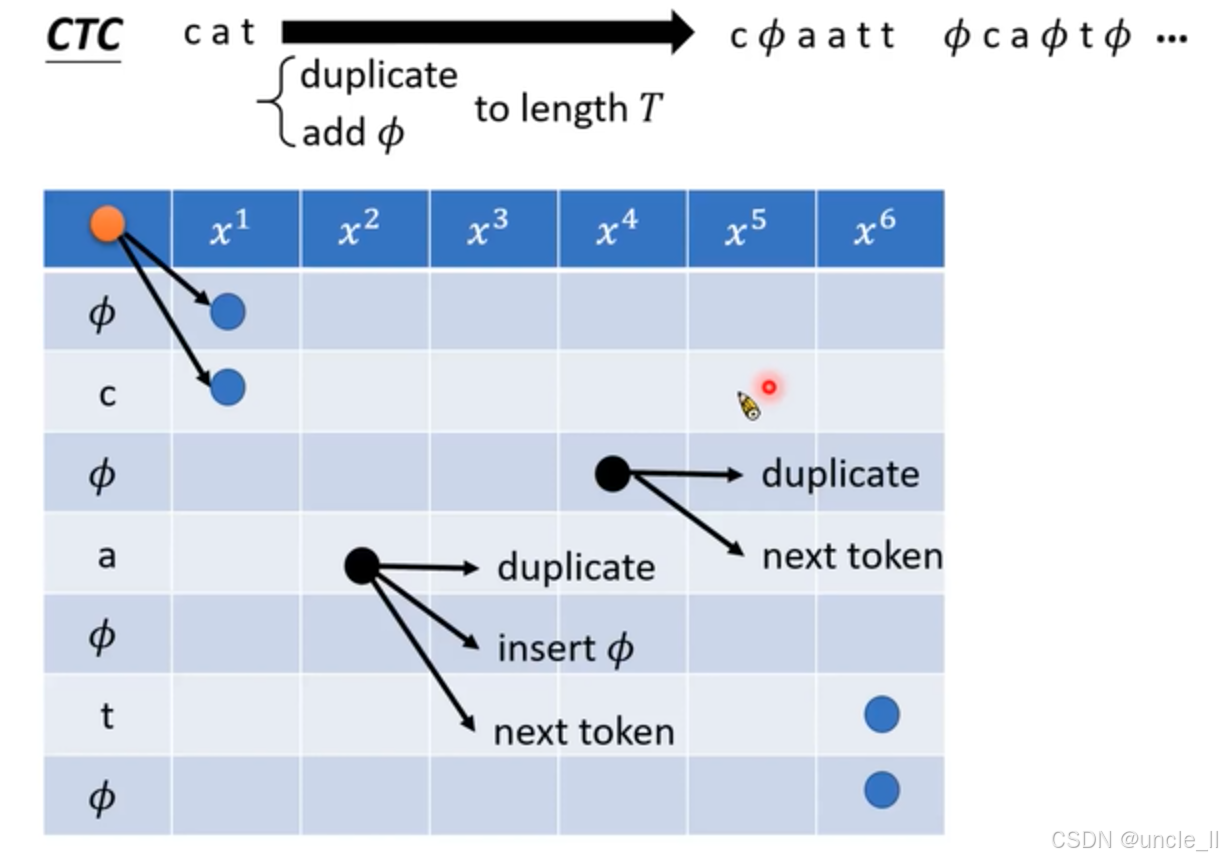
-
操作过程:图中 “CTC” 字样明确了主题。从 “cat” 出发,经过 “duplicate”(重复)和 “add ϕ \phi ϕ”(添加空白符)操作,得到诸如 “ c ϕ a a t t ϕ c a ϕ t ϕ ⋯ c\phi aatt \phi ca\phi t\phi \cdots cϕaattϕcaϕtϕ⋯” 这样的序列。这体现了 CTC 允许在文本中插入空白符,以解决语音和文本在时间上的不对齐问题。
-
规则约束:下方灰色文本框内的代码样式文字给出了详细的输出规则和约束条件。它规定了先输出若干次空白符 ϕ \phi ϕ ,然后依次输出第 n n n个 token 若干次。约束等式和不等式确保了生成序列的长度和字符组合符合要求,如所有字符(包括空白符)出现次数之和要满足一定条件,每个字符重复次数有相应的限制等。
-
文本扩展:“cat” 通过 “duplicate” 和 “add ϕ \phi ϕ” 操作转换为 “ c ϕ a a t t ϕ c a ϕ t ϕ ⋯ c\phi aatt \phi ca\phi t\phi \cdots cϕaattϕcaϕtϕ⋯” 并延长到长度 T T T 。
-
网格图表示:中间的蓝色方格网格是核心部分。方格内标注的 x 1 x^{1} x1 到 $ x^{6}$ 代表语音信号的不同时刻或特征。方格内的不同颜色圆点、符号 ϕ \phi ϕ以及字母 “c”“a”“t” 表示不同的状态。黑色箭头和文字说明 “duplicate”(重复当前字符)、“next token”(切换到下一个字符)、“insert ϕ \phi ϕ”(插入空白符) 展示了状态之间的转移规则。带有爆炸效果的小图标可能是用于特殊标记或强调某个关键状态或操作。
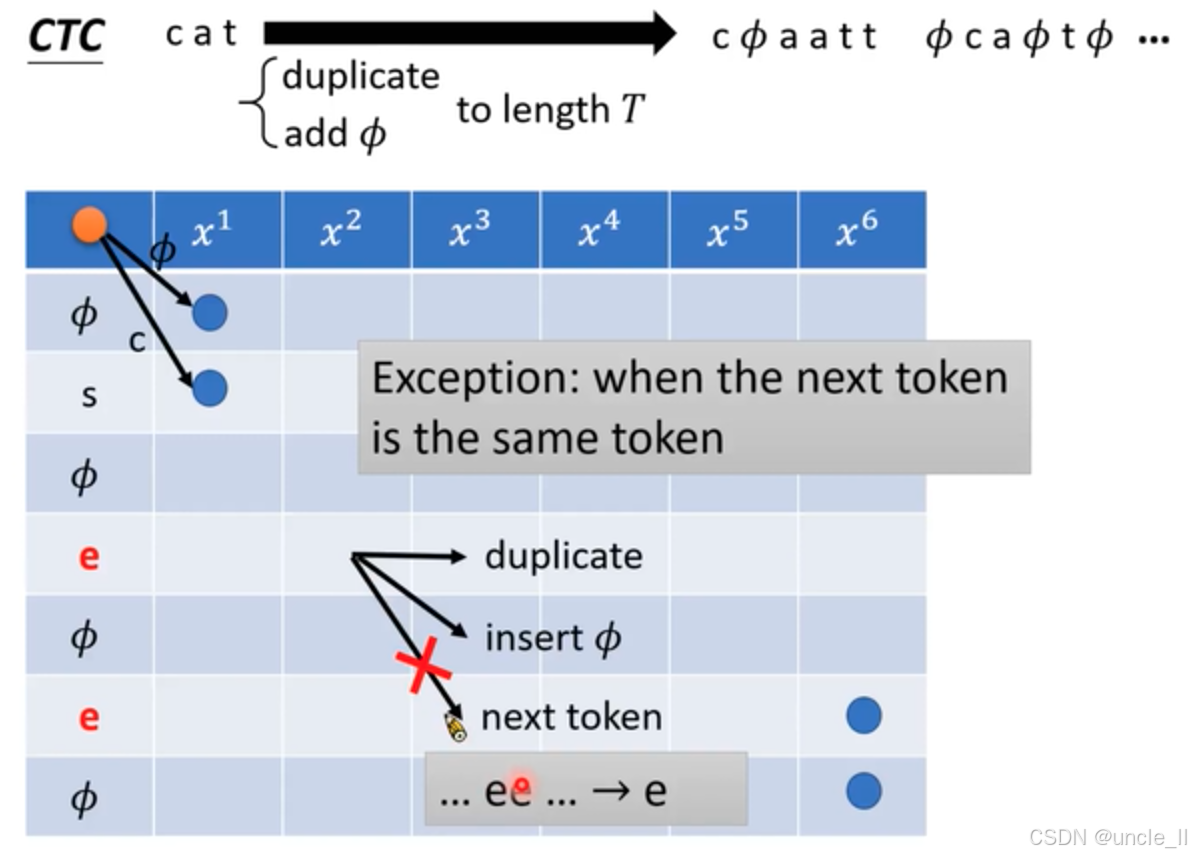
当下一个 token 和当前 token 相同时的处理规则是不能往下走。
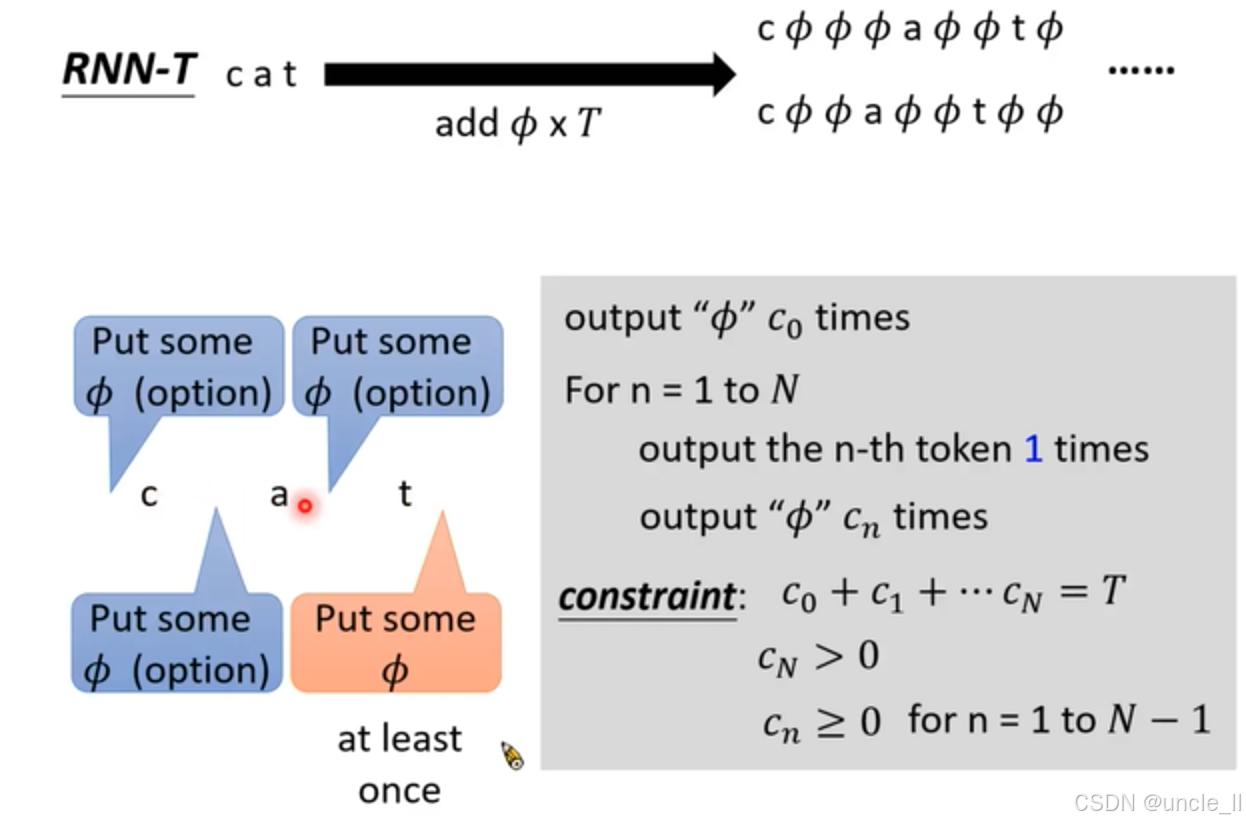
RNN - T(RNN Transducer)在语音识别中的文本处理规则:
文本扩展
- 文本扩展操作:“cat” 通过黑色粗箭头指向右侧形如 “ ϕ a ϕ t ϕ ⋯ \phi a\phi t\phi \cdots ϕaϕtϕ⋯” 的序列,箭头下方 “add ϕ \phi ϕx T” 说明操作是向 “cat” 中添加 ϕ \phi ϕ (空白符),且添加的总次数与参数 T T T 相关。这一操作体现了 RNN - T 在处理语音和文本对齐时,通过引入空白符来增强模型灵活性和处理能力。
- 对话框内容:图片下方左侧的蓝色和橙色对话框包含了重要的规则说明。蓝色对话框 “Put some ϕ \phi ϕ(option)” 表示可以选择添加一些空白符,这给予了模型在处理过程中的一定灵活性。橙色对话框 “Put the n - th token t n t_n tn times” 表示要将第 n n n 个 token 输出 t n t_n tn次,且 “at least once” 强调每个 token 至少要出现一次。
- 规则阐述:右侧灰色方框内的数学相关文字进一步阐述了输出规则和约束条件。它详细说明了输出 ϕ \phi ϕ 的次数规则,例如先输出若干次 ϕ \phi ϕ ,然后依次输出每个 token 若干次。同时,给出了严格的约束等式和不等式,确保生成序列的长度和字符组合符合要求,如所有字符(包括空白符)出现次数之和要满足一定条件,每个 token 重复次数有相应的下限等。
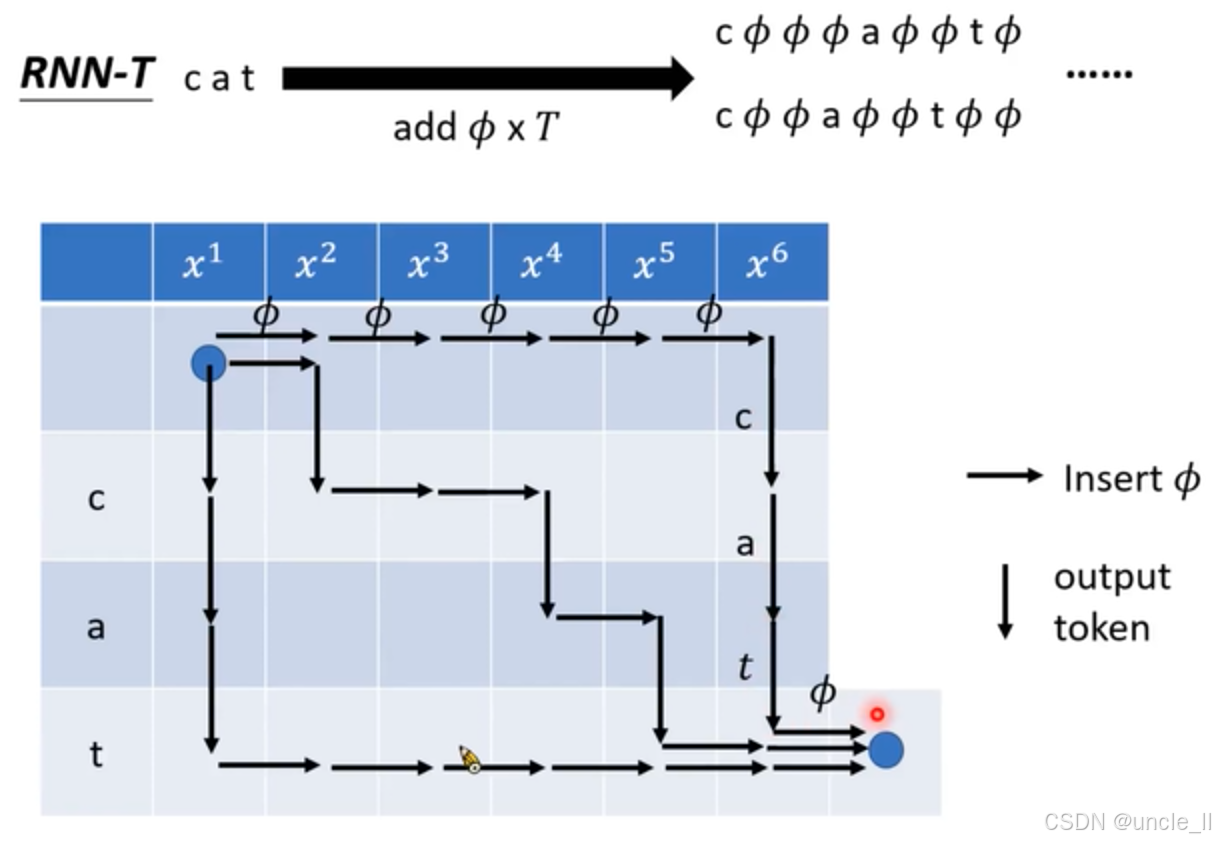
横着走插入的是空,往下走是预测下一个token
- 核心操作:从 “cat” 出发,通过箭头 “add ϕ \phi ϕ x T” 指向添加了多个空白符号 “ ϕ \phi ϕ” 的序列,这表明 RNN - T 在处理文本时,会向原始文本中添加一定数量的空白符,以增强模型在处理语音和文本对齐时的灵活性。
- 网格含义:网格图由上下两部分组成,上方蓝色方格标注的 x 1 x^{1} x1 到 x 6 x^{6} x6 代表语音信号的不同时刻或特征;下方浅蓝色方格中字母 “c”“a”“t” 重复排列,代表文本中的字符。
- 路径规则:黑色箭头表示不同的操作,“Insert ϕ \phi ϕ” 表示插入空白符,“output token” 表示输出当前字符。路径的起始和结束点用蓝色圆点标记,清晰地展示了整个操作流程的开始和结束。
- 特殊标记:路径中的红色圆点标记在 “t” 处,可能是为了突出某个关键步骤或状态;铅笔图标标记可能表示需要进一步处理或注意的节点。
总结
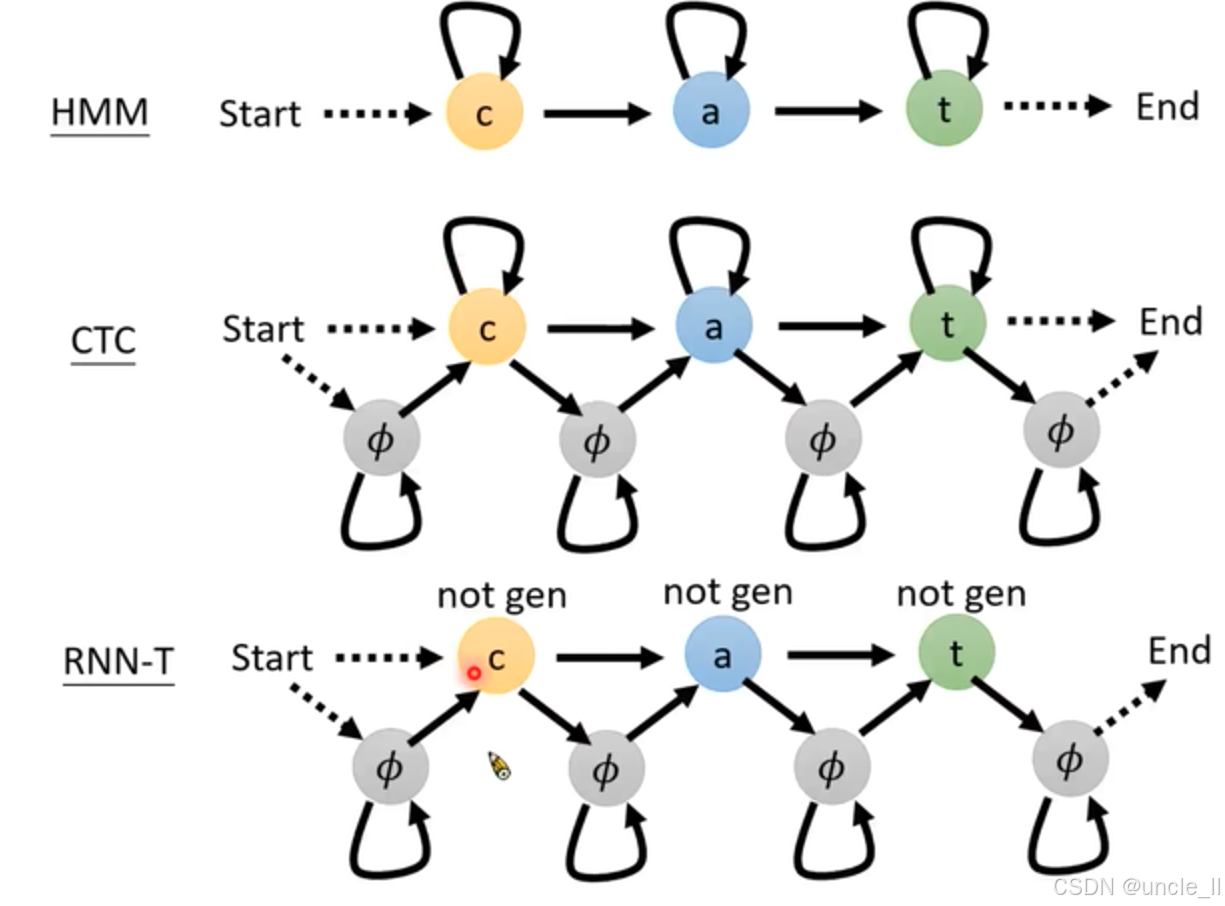
- HMM(隐马尔可夫模型):由一系列带有字母(如 “c”“a”“t”)的圆圈表示状态,圆圈之间的箭头体现了状态转移关系。HMM通过状态转移概率和发射概率来描述序列的生成过程,在语音识别中,这些状态和转移可能对应着语音的不同音素或发音状态的变化。
- CTC(Connectionist Temporal Classification):同样由带字母和符号(如 “c”“a”“t”“( \phi )”)的圆圈和箭头构成状态转移图。CTC引入了空白符 ϕ \phi ϕ,用于处理语音和文本之间的时间不对齐问题。它允许模型在不需要预先知道语音和文本精确对齐关系的情况下进行训练,增强了模型的灵活性。
- RNN - T(RNN Transducer):除了字母和符号的圆圈及箭头外,部分状态上方标注了 “not gen”,可能表示这些状态在特定条件下不进行生成操作。RNN - T结合了循环神经网络和变换器的特点,能够直接对语音和文本进行联合建模,其状态转移反映了模型在处理语音序列时逐步生成文本的过程。





)









)



