【头歌实验】Keras机器翻译实战
第1关:加载原始数据
编程要求
根据提示,在右侧编辑器补充代码,实现load_data函数,该函数需要加载path所代表的文件中的数据,并将文件中所有的内容按\n分割,转换成一个列表后返回。
代码
#coding:utf8
import osdef load_data(path):'''读取原始语料数据:param path: 文件路径:return: 句子列表,如['he is a boy.', 'she is a girl']'''#*********Begin*********#with open (path,'r',encoding='utf-8') as file:content = file.readlines()return [line for line in content]#*********End*********#第2关:Tokenize
相关知识
为了完成本关任务,你需要掌握什么是 Tokenize ,以及怎样实现 Tokenize 。
为什么需要 Tokenize
对于深度学习和机器学习程序来说,除了数字之外,什么都不认识。也就是说假设现在有一个机器翻译的程序,能将英语翻译成法语,然后我们把英语句子作为输入,输入到程序中。此时程序其实会将句子中的单词、符号等信息转换成数字,再丢给模型去计算。所以将单词转换成数字是实现机器翻译的第一步,而 Tokenize 就是最为常用的一种将单词转换成数字的方式。
什么是 Tokenize
Tokenize 看起来高大上,其实就是将每个单词都映射成一个数字而已。例如现在语料库中的句子如下:
[‘The quick brown fox jumps over the lazy dog .’, ‘By Jove , my quick
study of lexicography won a prize .’, ‘This is a short sentence .’]
那么 Tokenize 就是统计所有句子中出现的不同的词,然后将每个单词与一个数字对应起来。如:
{‘the’: 1, ‘quick’: 2, ‘a’: 3, ‘brown’: 4, ‘fox’: 5, ‘jumps’: 6,
‘over’: 7, ‘lazy’: 8, ‘dog’: 9, ‘by’: 10, ‘jove’: 11, ‘my’: 12,
‘study’: 13, ‘of’: 14, ‘lexicography’: 15, ‘won’: 16, ‘prize’: 17,
‘this’: 18, ‘is’: 19, ‘short’: 20, ‘sentence’: 21}
所以经过 Tokenize 后,语料库中的句子变成了只有数字的列表,如下所示:
[[1, 2, 4, 5, 6, 7, 1, 8, 9], [10, 11, 12, 2, 13, 14, 15, 16, 3, 17],
[18, 19, 3, 20, 21]]
怎样实现 Tokenize
keras 为我们已经实现好了 Tokenize 功能,我们只需调用接口即可实现 Tokenize 。示例代码如下:
from keras.preprocessing.text import Tokenizer
# 语料
x = ['The quick brown fox jumps over the lazy dog .', 'By Jove , my quick study of lexicography won a prize .', 'This is a short sentence .']
# 实例化Tokenizer对象,使用单词级别的Tokenize
x_tk = Tokenizer(char_level=False)
# 对语料进行Tokenize
x_tk.fit_on_texts(x)
# 打印Tokenize的语料
print(x_tk.texts_to_sequences(x))
编程要求
根据提示,在右侧编辑器补充代码,实现tokenize函数。
代码
#coding:utf8
from keras.preprocessing.text import Tokenizerdef tokenize(data):'''tokenize:param data: 语料,类型为list:return: tokenize后的语料,类型为list'''#*********Begin*********#x=[]x=data# 实例化Tokenizer对象,使用单词级别的Tokenizex_tk = Tokenizer(char_level=False)# 对语料进行Tokenizex_tk.fit_on_texts(x)# 打印Tokenize的语料#print(x_tk.texts_to_sequences(x))return x_tk.texts_to_sequences(x)#*********End*********#
第3关:padding
相关知识
为了完成本关任务,你需要掌握:什么是 padding 以及怎样实现 padding。
为什么要 padding
通常情况下语料库中的每个句子中的单词数量不可能会是完全一致的。就比如上一关中用来举例的语料中3条句子的单次数量是不同的。
但是在搭建神经网络时,神经网络中每层的神经元的个数其实就已经确定下来了。特别是输入层的神经元数量,每一个神经元代表着一个词。
一边是单次数量不确定,另一边是需要确定好单词数量,怎么办呢?这个时候可以使用 padding 方法。
什么是 padding
padding 其实就是设定一个最大的单词数量,当 tokenize 后的句子中单词数量小于最大单词数量时,就在后面补0。
假设 tokenize 后的句子为:[18 19 3 20 21],最大单词数量为10,那么 padding 后的句子为:[18 19 3 20 21 0 0 0 0 0]。
怎样实现 padding
keras 同样为我们实现好了 padding 功能,省得我们重新造轮子。示例代码如下:
from keras.preprocessing.sequence import pad_sequences
# tokenize后的语料
x = [[[18 19 3 20 21]]]
# 打印padding的结果,最大单词数量为10
print(pad_sequences(x, maxlen=10, padding='post'))
题目
编程要求
根据提示,在右侧编辑器补充代码,实现 padding 函数。注意:最大单次数量为data中所有句子的单次数量的最大值。
代码
#coding:utf8
from keras.preprocessing.sequence import pad_sequencesdef padding(data):'''padding,最大单词数量为data中所有句子的单词数量的最大值:param data: 语料,类型为list:return: padding后的语料,类型为list'''#*********Begin*********## tokenize后的语料x = datamaxlen=(max(len(x) for x in data))# 打印padding的结果,最大单词数量为10return pad_sequences(x, maxlen, padding='post')#*********End*********#
第4关:搭建双向RNN神经网络
相关知识
为了完成本关任务,你需要掌握:
RNN ;
RNN 即循环神经网络,RNN 通常作用于语言处理,目前最为常见的自然语言处理就是通过 RNN 或者 RNN 的变种实现的。由于语言的数据量十分庞大使用普通的全连接网络进行训练需要的参数存在几何倍增加,同时我们每说一句话都是存在一定的时序的,时序的不同表达的意思也不同。对于这种问题来说,全连接网络的处理能力就有点捉襟见肘了。
比如现在有个句子,句子最后面有一处缺失,需要使用神经网络来预测一下这个缺失的词是什么。句子是这样的:“我喜欢阿伦艾弗森,我平常爱和朋友打___。”当我们把这个句子输入到全连接网络中可能会得到其他结果,比如和朋友打架、和朋友打年糕等等。这些结果都忽略了之前文字带来的影响,但是输入到 RNN 中就不一样了, RNN 会“记住”之前的内容,他记下了“阿伦艾弗森”发现他是一个篮球巨星,因此 RNN 会推断输出和朋友打篮球。
那么 RNN 是如何保留这种“记忆”的呢?请观察下图的左边部分, RNN 神经网络结构图, x为输入的数据,同时右侧的圆圈也是 RNN 的输入,这部分输入的就是之前的记忆,由这两种输入共同决定最后的输出。
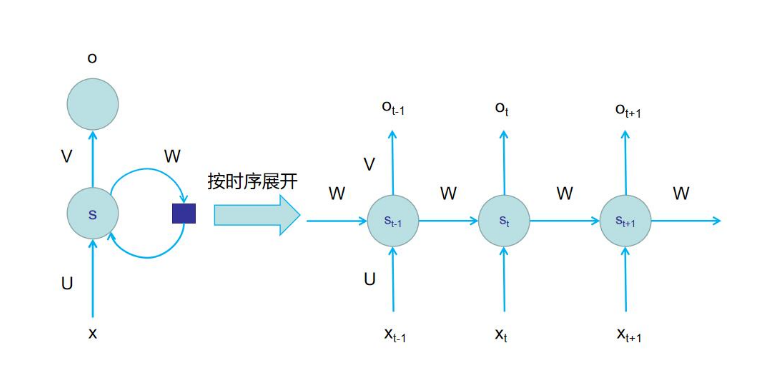
对于上图的左边部分不是特别容易理解,我们将其展开进行进一步解释。看右边部分中位于中间的神经元,该神经元的输入源自两个方面,一个是下方的x ,x代表的是当前时刻输入的外部数据也就是上文举例的句子中的汉字或者词语,另一个来自上一个神经元传递的s,s代表的是内部数据也就是上一个神经元经过计算后保留的记忆。将这两种输入共同作用在当前神经元上,经过计算后输出O。这就是为什么喜欢使用 RNN 处理语言问题的主要原因。
但是这种最普通的 RNN 有一个弊端,就是只能从前往后,这样会导致一个问题,就是当前的输出至于前一时刻的输入和输出有关。那有没有既能从前往后,又能从后往前呢?有!那就是双向 RNN 。
双向 RNN
为什么需要既能从前往后又能从后往前的 RNN 呢,因为如果仅仅是从前往后的方式来理解句子的语义的话,会有可能产生歧义。例如:“He said, Teddy bears are on sale” 和 “He said, Teddy Roosevelt was a great President。在上面的两句话中,当我们看到“Teddy”和前两个词“He said”的时候,我们有可能无法理解这个句子是指President还是Teddy bears。因此,为了解决这种歧义性,我们需要从后往前看。这就是双向 RNN 所能实现的。
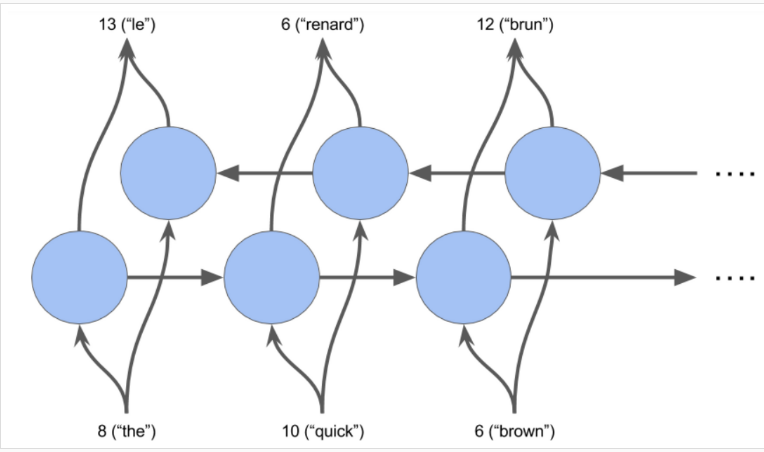
怎样搭建双向 RNN 神经网络
以将英语翻译成法语的功能为例。当我们把英语和法语的语料进行 tokenize 和padding 处理后,就可以将经过处理后的英语语料作为伸进网络的输入,将经过处理后的法语语料作为输出。所以这个网络应该是一个处理分类问题的神经网络。
因此,网络的输出层其实就是一个全连接层,神经元的数量就是法语 tokenize 后词的数量,激活函数是softmax。
确定了输出层后,就要确定处理输入层数据的层了。很明显,就是用双向 RNN ! keras 中有相应的接口来帮助我们实现双向 RNN 。示例代码如下:
# SimpleRNN表示RNN,Bidirectional表示双向的意思。128表示RNN有128个神经元,由于我们需要RNN处理后的序列,所以return_sequences为True,dropout是随机丢弃的概率,能够防止过拟合
Bidirectional(SimpleRNN(128, return_sequences = True, dropout=0.1), input_shape=input_shape)
知道怎样构建双向 RNN 层之后,相信你能够很轻松的构建出整个神经网络了。
编程要求
根据提示,在右侧编辑器补充代码,实现build_model函数,该函数的功能是构建一个含有128个神经元的双向 RNN 层和含有french_vocab_size个神经元的全连接层的神经网络。(怎样将层与层之间连接起来,请查阅 keras 官方文档。)
代码
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN, Bidirectionaldef build_model(input_shape, french_vocab_size):'''tokenize:param input_shape: 英语语料的shape,类型为list:param french_vocab_size: 法语语料词语的数量,类型为int:return: 构建好的模型'''#*********Begin*********## 创建序列模型model = Sequential()# 添加双向RNN层作为第一层,指定input_shapemodel.add(Bidirectional(SimpleRNN(128, return_sequences=True), input_shape=input_shape))# 添加全连接层model.add(Dense(french_vocab_size, activation='softmax'))# 编译模型model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])return model#*********End*********#第5关:实现机器翻译
相关知识
为了完成本关任务,你需要将前面所有的知识融会贯通。
机器翻译流程
1.分别对英语语料和法语语料进行 tokenlize 处理,以及 padding 处理;
2.构建神经网络;
3.编译神经网络,训练;
4.加载训练后的模型并进行翻译。
编程要求
根据提示,在右侧编辑器补充代码,实现机器翻译功能。由于平台无法训练太久,所以这里只训练30个epoch,若想达到比较好的翻译效果,可以在自己电脑上训练久一点。
PS:请不要修改 Begin-End 之外的代码!
代码
#coding:utf8
import os
import warnings
warnings.filterwarnings('ignore')
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
from keras.models import Sequential, Model
from keras.layers import Input, Dense, SimpleRNN, Bidirectional, TimeDistributed
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
from keras.losses import sparse_categorical_crossentropy
from keras.optimizers import Adam
import numpy as npdef load_data(path):'''读取原始语料数据,只读取前3000条文本:param path: 文件路径:return: 句子列表,如['he is a boy.', 'she is a girl']'''with open(path, 'r') as f:return f.readlines()[:3000]def tokenize(data):'''tokenize:param data: 语料,类型为list:return: (tokenize后的语料,tokenizer对象)'''x_tk = Tokenizer(char_level = False)x_tk.fit_on_texts(data)return x_tk.texts_to_sequences(data), x_tkdef padding(data, length=None):'''padding,最大单词数量为dlength:param data: 语料,类型为list:param data: 词数量,类型为int:return: padding后的语料,类型为list'''if length is None:length = max([len(sentence) for sentence in data])return pad_sequences(data, maxlen = length, padding = 'post')def build_model(input_shape, french_vocab_size):'''tokenize:param input_shape: 英语语料的shape,类型为list:param french_vocab_size: 法语语料词语的数量,类型为int:return: 构建好的模型'''model = Sequential()model.add(Bidirectional(SimpleRNN(128, return_sequences=True, dropout=0.1), input_shape=input_shape[1:]))model.add(Dense(french_vocab_size, activation='softmax'))return modeldef logits_to_text(logits, tokenizer):"""将神经网络的输出转换成句子:param logits: 神经网络的输出:param tokenizer: 语料的tokenizer:return: 神经网络的输出所代表的字符串"""index_to_words = {id: word for word, id in tokenizer.word_index.items()}index_to_words[0] = '<PAD>'return ' '.join([index_to_words[prediction] for prediction in np.argmax(logits, 1)])#*********Begin*********#
english_sentences = load_data('small_vocab_en.txt')
french_sentences = load_data('small_vocab_fr.txt')
preproc_english_sentences, english_tokenizer = tokenize(english_sentences)
preproc_french_sentences, french_tokenizer = tokenize(french_sentences)
max_english_sequence_length = max([len(i) for i in preproc_english_sentences])
max_french_sequence_length = max([len(j) for j in preproc_french_sentences])
max_length = max(max_english_sequence_length,max_french_sequence_length)
preproc_english_sentences = padding(preproc_english_sentences, max_length)
preproc_french_sentences = padding(preproc_french_sentences, max_length)
english_vocab_size = len(english_tokenizer.word_index) + 1
french_vocab_size = len(french_tokenizer.word_index) + 1
tmp_x = preproc_english_sentences.reshape((*preproc_english_sentences.shape, 1)
)
preproc_french_sentences = preproc_french_sentences.reshape((*preproc_french_sentences.shape,1)
)
model = build_model(tmp_x.shape, french_vocab_size)
#*********End*********## 编译神经网络
model.compile(loss=sparse_categorical_crossentropy, optimizer = Adam(1e-3))
# 训练(这里只训练30个epoch)
model.fit(tmp_x, preproc_french_sentences, batch_size=512, epochs=30, validation_split=0.2, verbose=0)# 保存翻译结果
with open('result.txt', 'w') as f:for i in range(10):result = english_sentences[i]+' -> ' + logits_to_text(model.predict(np.expand_dims(tmp_x[i], 0))[0], french_tokenizer)f.write(result)

)

)







)







