你是否有过这样的经历?
精心配置了 Kubernetes 的 Pod,设置了“刚刚好”的 CPU 和内存(至少你当时是这么想的),结果应用不是资源紧张喘不过气,就是像“双十一”抢购一样疯狂抢占资源。
过去,唯一的解决办法就是重启整个 Pod ——这种破坏性的做法就像用黄油刀做开胸手术,而 SRE 团队正透过手术室的窗户盯着看,紧张但无能为力。
不过,近期发布的 Kubernetes 1.33 版本带来了我们梦寐以求的功能:原地 Pod 垂直伸缩(In-place Pod Vertical Scaling)。
在 Kubernetes 1.33 中该功能已升级为 Beta 版,并且默认启用。你不再需要手动启用特性,这使得它在生产环境中更加易用
(可查阅 Kubernetes 官方文档:https://kubernetes.io/docs/tasks/configure-pod-container/resize-container-resources/)。
这意味着你可以调整正在运行的 Pod 的 CPU 和内存配置,而无需重启。
如果你一直在琢磨垂直自动伸缩(VPA)的细节,那么这次更新会令人格外兴奋——虽然 VPA 的“重新创建”模式在理论上很美好,但实操过程中常常状况百出。
原地 Pod 垂直伸缩提供了一种更加优雅的资源调整方式,或许能让 VPA 的体验更加顺滑。
01/为什么这项更新如此重要?
对 Kubernetes 用户来说,这是一项革新式的重要更新。
假设当应用突然遇到流量激增的高峰期时,过去的做法是要么预留大量资源,但成本很高;要么触发 VPA 更新,导致 Pod 重启。而现在,通过这项更新可以直接实时增加 CPU 和内存配置,不会造成应用卡顿,用户侧几乎无感。
尤其对于那些有状态应用、数据库,或要求持续可用性的服务而言,原地扩缩容能大幅降低宕机时间,提供更加无缝的弹性伸缩体验。
为什么这项特性能实现这一效果?让我们来简单分析一下:
- 告别 Pod重启 : 过去每次调整资源,服务是否宕机全看运气。VPA 会像一个过于热情的保安一样把 Pod 赶下线。现在呢?扩容丝滑得像咖啡师拉花。
- 成本优化魔法 : 不再需要为了“以防万一”的情况,而过度配置资源。正如 Sysdig 团队指出的,这实现了真正的按需付费云经济。
- 拯救有状态工作负载 : 数据库不再需要在“性能”与“可用性”之间做选择了。这就像在行驶的汽车上换轮胎 ——虽然有风险,但现在已经可行!
02/实际应用场景
以下是一些具体的应用场景,从中可以窥见这一功能的实用性:
- 数据库工作负载 当你的 PostgreSQL 实例突然需要更多 RAM 来处理营销部门的数据分析的请求时,你可以在不中断正在进行的交易或清空连接池的情况下扩展资源。用户再也不会看到“请稍后再试”的消息了!
- Node.js API 服务 Node.js 应用可以在无需重启的情况下动态使用新增的 CPU 和内存。因此非常适合使用原地扩缩容来应对流量激增。
- 机器学习推理服务 TensorFlow Serving 等服务在处理更大批量或更复杂模型时,可以实时扩容,无需中断正在进行的推理请求。
- 服务网格 Sidecar 在 Istio 之类的服务网格中, Envoy 代理现在可以根据流量模式动态调整资源,而不会干扰主应用容器的运行。
关于 Java 应用的提醒:
对于基于 JVM 的应用,仅仅调整 Pod 的内存配置并不会自动改变 JVM 的堆(heap)大小,后者通常是在启动时通过-Xmx等参数设置的。虽然原地 Pod 调整可以优化非堆内存和 CPU 资源的使用,但如果想要充分利用扩容后的内存限制,Java应用通常需要调整配置并重启。因此,对于不希望重启的场景来说,Java 应用并不适合进行内存扩容。
03/技术揭秘:Kubernetes 如何灵活调整资源
接下来,让我们深入探讨技术细节,下图展示了 K8s 资源调整的工作流程:
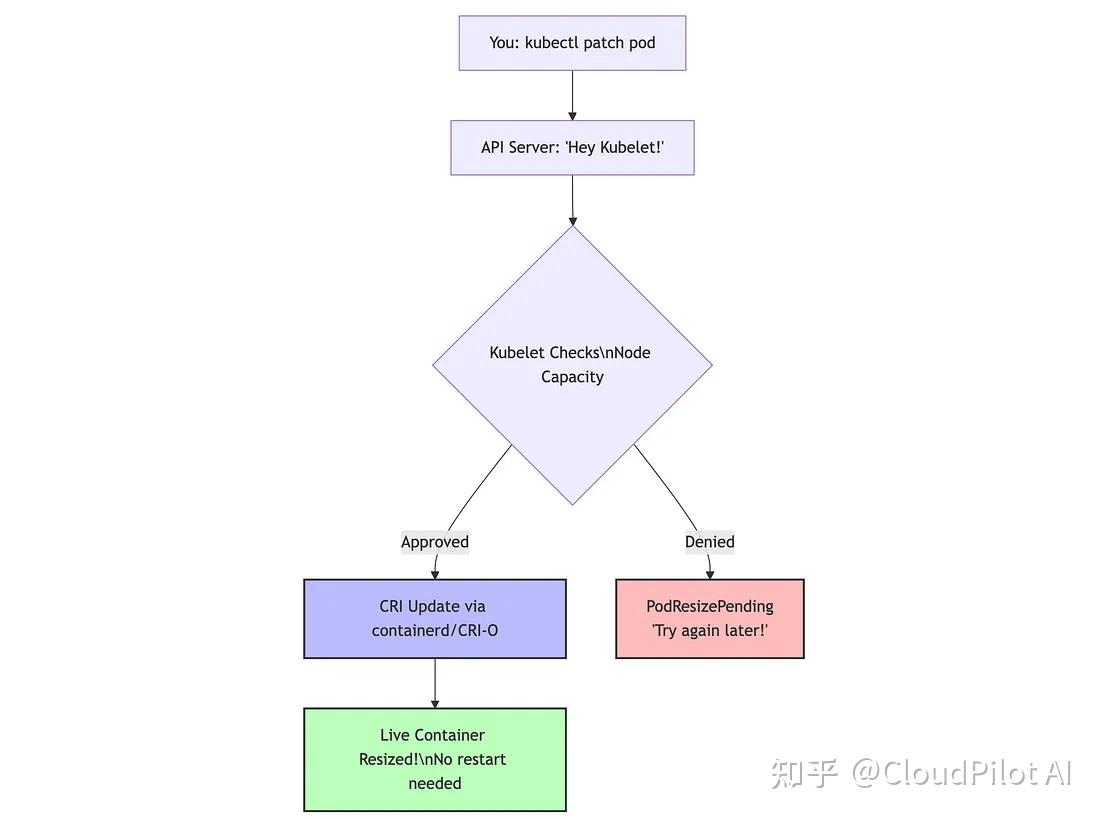
实际发生了什么
- 可变资源字段已支持动态更新 得益于这个 issue (https://github.com/kubernetes/enhancements/issues/1287),Pod 规范中的
resources.requests和resources.limits字段现在支持动态修改,无需再为 Spec 是否不可变而争论了。 - Kubelet 的评估机制 当你提交 patch 时,kubelet 会评估:(
节点可用资源总量) - (当前所有容器资源分配总和) ≥ (新请求资源)?满足条件就允许变更,否则就返回PodResizePending。 - CRI 协议握手 kubelet 会通过容器运行时接口 (CRI) 与 containerd 或 CRI-O 通信:“给这个容器加点资源”。运行时随后会调整对应的 cgroup,无需重启,轻松搞定。这是异步、非阻塞的流程,Kubelet 可以在处理资源调整的同时继续执行其他重要任务。
- 状态更新提示 在执行
kubectl describe pod时,你会看到两个新状态: - PodResizePending —— “节点当前资源不足,稍后再试。”
- PodResizeInProgress —— “正在处理,资源调整中。”
容器运行时兼容性
这一功能在不同的容器运行时中均可使用,但支持程度有差异,情况如下:
- containerd(v1.6+):完全支持,可以平滑调整 CPU 和内存的 cgroup
- CRI-O(v1.24+):完全支持原地扩缩容
- Docker:支持有限,因为它正在逐步退出 Kubernetes
注意:cgroup v2 在内存回收方面比 cgroup v1 更强大,特别是对于内存限制减少的情况下。
04/上手实践:安全地搞点事情
让我们通过一个简单的演示来展示原地 Pod 调整的实际效果,你可以从 Kubernetes API 和 Pod 内部同时查看资源变更。
整个演示运行在 GKE 的 Kubernetes 1.33 上。
- 创建一个资源监控 Pod
首先创建一个持续监控自身资源分配的Pod:
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:name: resize-demo
spec:containers:- name: resource-watcherimage: ubuntu:22.04command:- "/bin/bash"- "-c"- |apt-get update && apt-get install -y procps bcecho "=== Pod Started: $(date) ==="# Functions to read container resource limitsget_cpu_limit() {if [ -f /sys/fs/cgroup/cpu.max ]; then# cgroup v2local cpu_data=$(cat /sys/fs/cgroup/cpu.max)local quota=$(echo $cpu_data | awk '{print $1}')local period=$(echo $cpu_data | awk '{print $2}')if [ "$quota" = "max" ]; thenecho "unlimited"elseecho "$(echo "scale=3; $quota / $period" | bc) cores"fielse# cgroup v1local quota=$(cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us)local period=$(cat /sys/fs/cgroup/cpu/cpu.cfs_period_us)if [ "$quota" = "-1" ]; thenecho "unlimited"elseecho "$(echo "scale=3; $quota / $period" | bc) cores"fifi}get_memory_limit() {if [ -f /sys/fs/cgroup/memory.max ]; then# cgroup v2local mem=$(cat /sys/fs/cgroup/memory.max)if [ "$mem" = "max" ]; thenecho "unlimited"elseecho "$((mem / 1048576)) MiB"fielse# cgroup v1local mem=$(cat /sys/fs/cgroup/memory/memory.limit_in_bytes)echo "$((mem / 1048576)) MiB"fi}# Print resource info every 5 secondswhile true; doecho "---------- Resource Check: $(date) ----------"echo "CPU limit: $(get_cpu_limit)"echo "Memory limit: $(get_memory_limit)"echo "Available memory: $(free -h | grep Mem | awk '{print $7}')"sleep 5doneresizePolicy:- resourceName: cpurestartPolicy: NotRequired- resourceName: memoryrestartPolicy: NotRequiredresources:requests:memory: "128Mi"cpu: "100m"limits:memory: "128Mi"cpu: "100m"
EOF2. 查看 Pod 的初始状态
从 Kubernetes API 的角度查看 Pod 的资源:
kubectl describe pod resize-demo | grep -A8 Limits:你会看到类似以下输出:
Limits:cpu: 100mmemory: 128MiRequests:cpu: 100mmemory: 128Mi现在,看看 Pod 自身如何看待它的资源:
kubectl logs resize-demo --tail=8输出中会包含容器视角的 CPU 和内存限制。
3. 无缝调整 CPU
让我们在不重启的情况下将 CPU 加倍:
kubectl patch pod resize-demo --subresource resize --patch \'{"spec":{"containers":[{"name":"resource-watcher", "resources":{"requests":{"cpu":"200m"}, "limits":{"cpu":"200m"}}}]}}'检查调整状态:
kubectl get pod resize-demo -o jsonpath='{.status.conditions[?(@.type=="PodResizeInProgress")]}'注意:在 GKE 的 Kubernetes 1.33 上,你可能看不到PodResizeInProgress状态,即使调整操作已经成功。如果kubectl get pod resize-demo -o jsonpath='{.status.conditions}'没有显示调整信息,请直接检查实际资源。
调整完成后,从 Kubernetes API 查看更新后的资源:
kubectl describe pod resize-demo | grep -A8 Limits:并验证 Pod 现在看到的 CPU 限制:
kubectl logs resize-demo --tail=8你会注意到 CPU 限制从100m翻倍到200m,而 Pod 没有重启!Pod 的日志会显示 cgroup 的 CPU 限制从大约10000/100000变为20000/100000(表示从 100m 到 200m 的 CPU)。
4. 无痛调整内存
现在,让我们将内存分配加倍:
kubectl patch pod resize-demo --subresource resize --patch \'{"spec":{"containers":[{"name":"resource-watcher", "resources":{"requests":{"memory":"256Mi"}, "limits":{"memory":"256Mi"}}}]}}'稍等片刻后,从 API 验证:
kubectl describe pod resize-demo | grep -A8 Limits:从 Pod 内部查看:
kubectl logs resize-demo --tail=8你会看到内存限制从 128Mi 变为 256Mi,而容器没有重启!
5. 验证是否重启
确认在调整过程中容器从未重启:
kubectl get pod resize-demo -o jsonpath='{.status.containerStatuses[0].restartCount}'输出应该是0——证明我们实现了无需服务中断就能调整资源需求。
6. 清理资源
检验完成后:
kubectl delete pod resize-demo搞定!你已经成功地在不重启 Pod 的情况下原地调整了 CPU 和内存资源。
这种模式适用于任何容器化应用,除了设置适当的resizePolicy外,不需要任何特殊配置。
05/云厂商支持情况
在进行生产环境的尝试之前,先看看各大 Kubernetes 服务商的支持情况:
- Google Kubernetes Engine (GKE):在 GKE 的 Rapid 渠道中提供支持
- Amazon EKS:Kubernetes 1.33 版本预计将于 2025 年 5 月发布。
- Azure AKS:Kubernetes 1.33 版本现已提供预览
- 自建集群:只要运行 Kubernetes 1.33+ 并使用 containerd 或 CRI-O 运行时,完全支持
06/局限性:功能虽然强大,但也有边界
尽管这个功能很酷,但请记住以下几点:
平台和运行时限制
- Windows用户暂不支持:目前仅限Linux
- 某些节点级 Pod 不支持:如果节点启用了静态 CPU 或内存管理器(如 CPU 静态管理器策略),则该节点上的 Pod 将不支持原地扩缩容
- 容器运行时要求:需要 containerd v1.6+ 或 CRI-O v1.24+ 才能提供完整支持
资源管理限制
1. QoS 类别不可更改:
Pod的原始服务质量等级(Guaranteed/Burstable/BestEffort)保持不变。无法通过调整将BestEffort升级为Guaranteed。
2. 目前只支持 CPU 和内存:
想动态调整 GPU 或临时存储?暂时还做不到。目前仅支持 CPU 和内存的原地调整。
3. 内存缩容需谨慎:
- 在不重启容器的情况下降低内存限制,就像炸弹——理论上可行,实际上极危险。
- 建议你设置
restartPolicy: RestartContainer以免场面失控。这在使用 cgroup v1 的系统中尤其关键。
4. Swap 使用限制:
如果 Pod 开启了 Swap 功能,那你就无法动态调整内存,除非将内存的 resizePolicy 设置为 RestartContainer。
5. 资源无法移除:
一旦设置了资源 request 或 limit,就不能通过原地调整将其删除,只能修改数值。
配置和集成限制
1. 并非所有容器都适用
-
- ❎初始化容器和临时容器不支持,这些一次性启动的容器无法使用此功能,因为他们本身就无法重启。
- ✅支持 Sidecar 容器:如果你喜欢用 Sidecar 模式,Sidecar 容器和主容器一样,支持原地进行资源调整,互不打扰。
2. resizePolicy不可更改:
一旦 Pod 创建,就无法更改其resizePolicy。所以请慎重选择,这是资源配置关系里的“从一而终”。
3. 特定应用限制:
如前所述,基于 JVM 的应用在不进行配置修改的情况下,无法自动使用扩容后的内存,通常还需要重启。这类限制适用于所有自行管理内存池的应用。
4. 缩容的风险:
如果你尝试把内存限制调低到低于当前使用量(即使设置了restartPolicy)也可能导致内存溢出(OOM)。
性能注意事项
1. 节点预留资源很关键:
节点需要有足够的可用容量才能成功调度资源。在资源紧张的集群中,Pod 可能会长时间处于 PodResizePending 状态,迟迟不能完成调整。
2.资源调整并非实时完成:
kubelet 是异步处理调整请求的。复杂的 cgroup 更新可能需要几秒钟才能完全生效。
3.调度器不感知扩缩容状态:
Kubernetes 调度器在进行 Pod 调度时不会感知有 Pod 正在调整资源,这可能导致资源压力误判,甚至调度冲突。
记住这些注意事项,你就能避免最糟糕的情况。
07/VPA:很努力但还差点意思
正如我最近在 LinkedIn 上感叹的,垂直 Pod 自动扩缩容(VPA)就像弹性伸缩家族聚会里那个总被忽视的尴尬亲戚。
但好消息是,它的“逆袭”正在进行中。
当前状态(截至 Kubernetes 1.33):
- VPA 尚不支持原地调整——它在调整资源时仍然会直接删除然后再重建 Pod,这在很多场景下显得非常粗暴。
- Kubernetes文档明确指出这一限制:“截至Kubernetes 1.33,VPA 不支持原地调整 Pod,但相关集成正在开发中。”
在 kubernetes/autoscaler PR #7673 中(https://github.com/kubernetes/autoscaler/pull/7673),社区已着手将 VPA 与原地扩缩容机制集成。这意味着未来我们有望看到 VPA 真正实现资源动态调整,而无需重启应用。
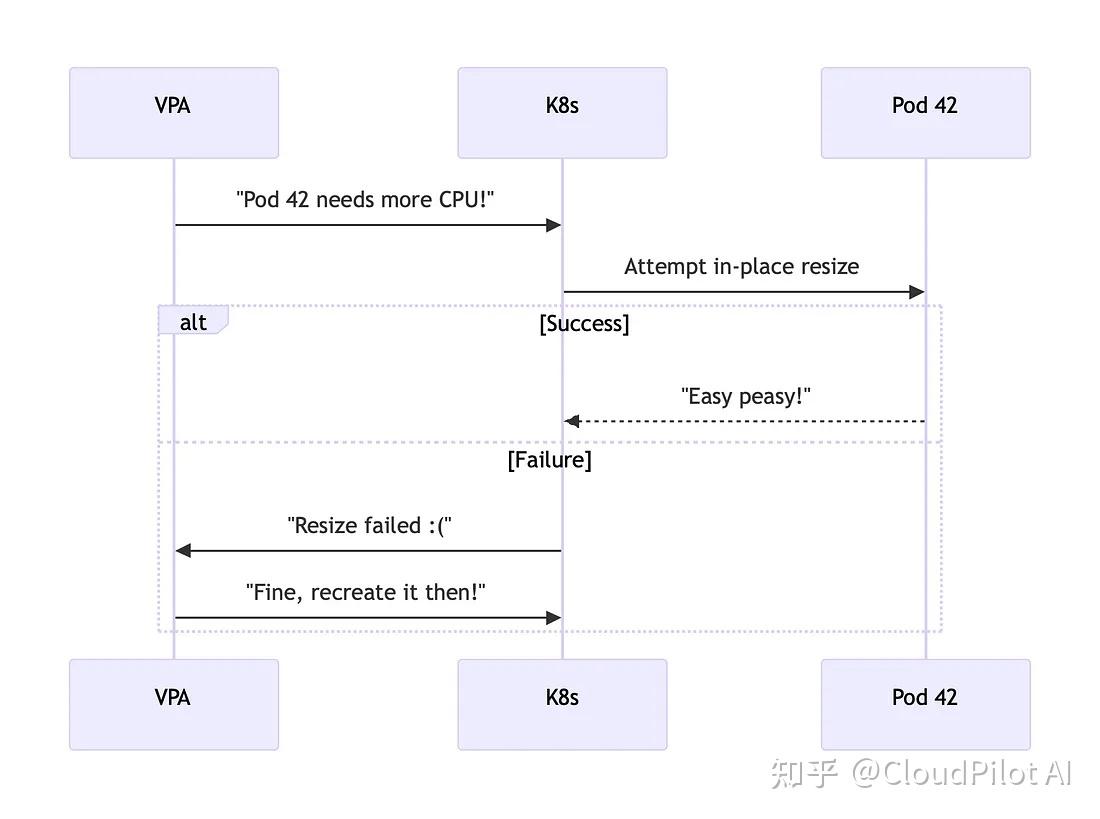
这种混合方案有望让 VPA 真正能具备在生产环境中支持有状态工作负载的能力。在此之前,我们只能继续手动和 Pod 玩资源叠叠乐,谨慎地调整资源。
当前结合 VPA 和手动调整的方法
虽然 VPA 尚未原生支持原地扩缩容,但你仍然可以同时受益于两者:
- 使用 VPA 的“Off”模式:只生成资源推荐,不自动调整
- 基于推荐手动执行扩缩容:根据 VPA 的建议手动进行原地调整
- 编写脚本自动化操作流程:通过脚本自动化手动步骤,避免 Pod 重建
# Example of a simple script to apply VPA recommendations via in-place resize
#!/bin/bash
POD_NAME="my-important-db"
CPU_REC=$(kubectl get vpa db-vpa -o jsonpath='{.status.recommendation.containerRecommendations[0].target.cpu}')
MEM_REC=$(kubectl get vpa db-vpa -o jsonpath='{.status.recommendation.containerRecommendations[0].target.memory}')kubectl patch pod $POD_NAME --subresource resize --patch \"{\"spec\":{\"containers\":[{\"name\":\"database\",\"resources\":{\"requests\":{\"cpu\":\"$CPU_REC\",\"memory\":\"$MEM_REC\"}}}]}}"08/与其他解决方案的对比
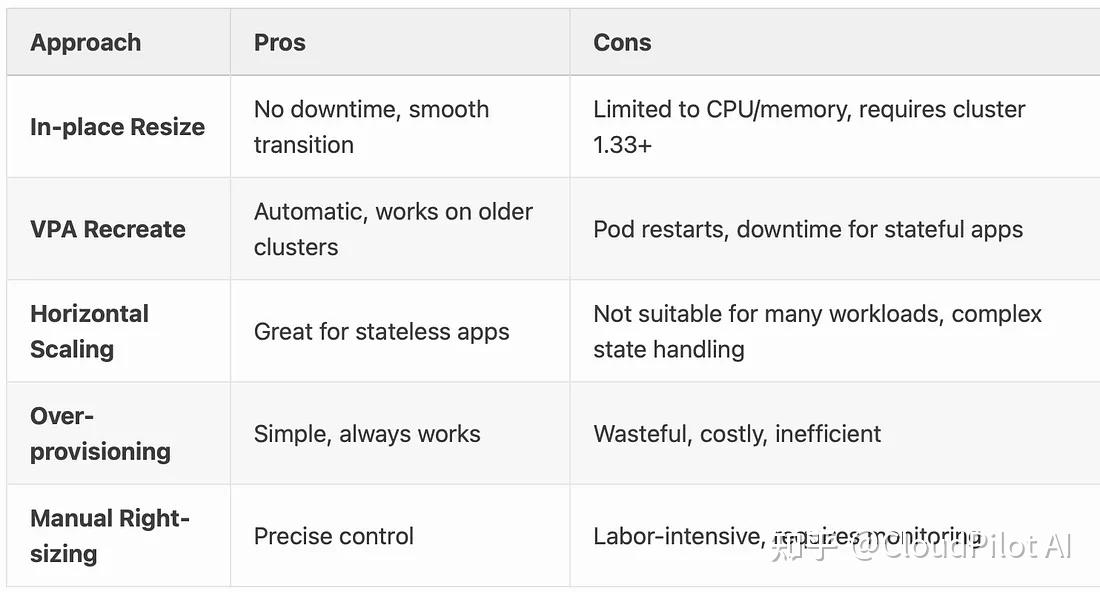
09/展望未来
Kubernetes 1.33 引入的原地 Pod 调整是让垂直扩缩容走向“无感知”的重要一步,但这只是开始。接下来还有更多令人期待的进展:
- VPA 深度集成(开发中) 首先尝试原地调整,仅在绝对必要时才重建 Pod,不再有突发的 Pod 驱逐。
- 支持更多资源类型 不止 CPU 和内存,未来可能连 GPU、临时存储都能动态调整。
- 调度器智能感知 目前调整操作不会通知调度器,Pod 仍可能因节点资源不足被驱逐。后续可能让其具备感知能力,优先保障资源,避免被意外重新调度。
- 和 Cluster Autoscaler / Karpenter 的联动 实现更智能的资源决策,仅在无法原地调整时扩展节点。
- 基于应用指标的自动调整资源 不再只盯着 CPU 和内存,未来可能支持基于“请求延迟”、“队列深度”等应用级指标进行资源动态调整。
这些逐步完善的功能功能共同描绘出一个未来愿景:Kubernetes 正在迈向一个真正智能、高效、不中断的垂直扩缩容时代。
对于开发者和平台团队而言,原地扩缩容(in-place pod resize)功能已经具备实验性使用的条件,非常适合在非生产环境中进行测试和评估。
需要注意的是,尽管该特性功能强大,在引入生产环境前仍需充分验证与测试,以规避潜在的不确定性和兼容性风险。期待这个功能可以帮助你持续提升集群资源管理效率。

)



)






)
)


)


