
我们考虑一个典型的Transformer模型结构,在多层堆叠中,其中包含Attention层和MoE层(FeedForward层被替换为MoE层)。在模型最后是LM Head(语言模型头),通常是一个全连接层,将隐层向量映射到词表大小的输出。
在您描述的配置中,MoE层采用allgatherEP模式,其输出通过Reduce-Scatter操作得到分片输出(每个TP组内,每张卡持有部分隐层维度)。而下一步的LM Head需要完整的隐层向量作为输入。因此,在LM Head之前需要将分片的数据通过All-Gather操作聚合为完整向量。
具体流程如下:
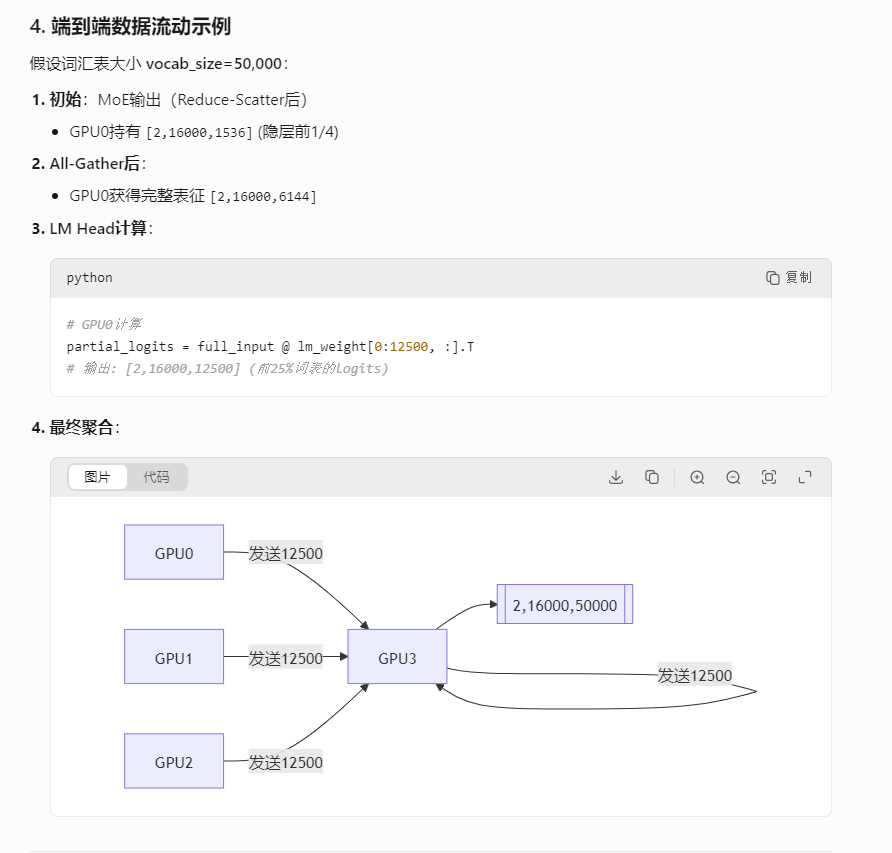
MoE层输出(Reduce-Scatter之后):每张卡持有分片数据,形状为 [batch_size, seq_len, hidden_size/TP_size]
例如:TP=4,hidden_size=6144,则每张卡持有 [batch_size, 16000, 1536]
为了进行LM Head计算(需要完整的隐层向量),在TP组内执行All-Gather操作:
将其他3张卡上的分片数据收集过来,每张卡都得到完整的隐层向量 [batch_size, 16000, 6144]
LM Head计算:
此时每张卡都拥有完整的输出向量,可以独立计算LM Head(一个线性层,权重形状为 [vocab_size, hidden_size])。
但是,由于LM Head的计算量可能很大(特别是词表很大时),通常也会采用张量并行(TP)来切分这个线性层。
LM Head的TP切分:
将LM Head的权重矩阵按列切分(即hidden维度切分),每张卡持有一部分权重:[vocab_size, hidden_size/TP_size]。
这样,每张卡只需要计算自己的部分:logits_local = input_full @ weight_local.T,输出形状为 [batch_size, seq_len, vocab_size/TP_size]
然后,通过All-Gather(在vocab维度)将logits聚合为完整的词表大小(也可以使用Reduce-Scatter,但一般为了后续的损失计算,需要每张卡都有完整的logits,所以用All-Gather):
每张卡收集其他卡计算的logits分片,得到完整的logits:[batch_size, seq_len, vocab_size]
但是,这里有一个效率问题:在LM Head之前做了All-Gather得到完整隐层,而后面又进行了两次通信(第一次是矩阵乘后的All-Gather,第二次是为了得到完整logits)。实际上,我们可以通过Gather操作合并来优化。
另一种常见的做法(如Megatron-LM的做法)是:避免在LM Head之前做All-Gather,而是直接利用分片的隐层和分片的权重计算,然后再进行All-Gather(在词表维度聚合)。这样就只需要一次All-Gather通信。
步骤:
MoE层输出:分片隐层 [batch_size, seq_len, hidden_size/TP_size]
LM Head权重:每张卡持有 [vocab_size, hidden_size] 的列切分(每个分片大小为 [vocab_size, hidden_size/TP_size])
每张卡计算:logits_local = input_local @ weight_local.T 得到 [batch_size, seq_len, vocab_size] 的一部分(实际上是 [batch_size, seq_len, vocab_size] 在vocab维度上的一个分片?注意:矩阵乘法说明:input_local的隐层维度是hidden_size/TP,而weight_local.T的维度是 [hidden_size/TP_size, vocab_size],但这样乘出来的结果是 [batch_size, seq_len, vocab_size],但是注意,这个结果是不完整的,因为输入只是部分隐层。因此需要将各个卡的结果相加(Reduce-Sum)才能得到完整的logits。
因此,正确的做法是:
在计算完本地矩阵乘之后,需要进行一次All-Reduce(Sum)操作,将各个卡上的部分logits相加,得到完整的logits。但这里因为输入本身就是分片的,所以需要All-Reduce。但是,这种做法在Megatron中只适用于无并行的线性层。在LM Head中,如果权重按列切分(即每张卡持有部分权重),那么每个分片权重与输入分片相乘只能得到部分结果,而完整的结果需要将各个部分加起来(即沿着hidden维度拆分,然后结果相加)。
因此,LM Head的计算应该是:
输入:X (每张卡上 [batch_size, seq_len, hidden_size/TP_size])
权重:W (每张卡上 [vocab_size, hidden_size/TP_size])
计算:local_logits = X @ W.T 得到 [batch_size, seq_len, vocab_size],但这个结果只是部分结果(因为是隐层分片和权重分片相乘)
然后,需要All-Reduce(Sum)操作:将各个卡上的local_logits相加,得到完整的logits。
然而,在MoE之后,如果我们不进行All-Gather(还原完整隐层),那么LM Head就要在分片隐层的基础上计算,然后通过All-Reduce来聚合。这样通信量是多少呢?
通信量 = batch_size * seq_len * vocab_size * sizeof(float)
这通常很大,因为vocab_size很大(几万到几十万)。例如,batch_size=1, seq_len=16000, vocab_size=50000, 则通信量=1 * 16000 * 50000 * 4字节=3.2GB,这比之前All-Gather的通信量(1 * 16000 * 6144 * 2字节≈196MB)大得多。
因此,更高效的做法是:
在MoE输出后,使用All-Gather恢复完整隐层(每张卡得到 [batch, seq, hidden],通信量是 (TP_size-1)/TP_size * hidden_size * …,也就是上面提到的377MB左右,对于TP=4,每个分片1536,All-Gather需要发送3个1536的分片,所以输入数据量是 3 * (batch_size * seq_len * 1536),以batch=2, seq=16000为例:3 * 2 * 16000 * 1536 * 2字节(fp16)≈ 2.25GB(注意这是总发送数据量,在NCCL中,All-Gather会将这些数据分发到其他卡,所以每卡接收3块数据,共约2.25GB,但现代GPU卡间带宽高,如NVLink 600GB/s,实际时间很短)
然后,使用TP切分权重计算LM Head(不需要立即做All-Gather)。但注意,由于我们已经All-Gather得到了完整隐层,那么我们可以将LM Head的权重按行切分(即切分vocab维度)。这样每张卡计算一部分词表的logits。
然后,再使用All-Gather将各个卡上分词的logits收集起来,得到完整的logits。
第二步的通信量:All-Gather聚合logits,通信量为:batch_size * seq_len * vocab_size * (TP_size-1)/TP_size * sizeof(float)
例如:batch=2, seq=16000, vocab=50000, TP=4,则通信量 = 2 * 16000 * 50000 * 3/4 * 4字节≈4.8GB(按float32计算,如果用float16则减半)。这依然很大。
所以,为了减少通信量,另一种策略是将LM Head的权重切分到不同的数据并行组(DP)中,只在一个设备上计算整个LM Head(不并行),但这样会引入计算瓶颈。
或者,我们可以不进行第二次All-Gather,而是在后续的损失计算中进行优化。但是,损失计算(交叉熵)通常需要完整的logits。
实际上,我们观察到,在Megatron-LM中,对于LM Head,他们采用了以下两种方式之一:
A. 不切分LM Head(权重复制),在计算之前通过All-Gather得到完整隐层(这样每张卡有完整隐层),然后每张卡独立计算整个LM Head(权重复制,所以输出也是完整的logits)。这样避免了第二步的All-Gather,但每张卡都存储了整个词表(可能很大)且计算了完整的矩阵乘法(计算量大,但并行度高)。
B. 将LM Head用张量并行切分(按hidden维度切分权重),然后通过All-Reduce得到完整的logits(如上所述)。但这种方法在词表大时通信量很大。
由于词表很大(如50k),All-Reduce的通信量甚至比All-Gather隐层还要大,因此实际中更常见的是使用All-Gather隐层的方式(即先将隐层收集完整),然后每张卡独立计算整个LM Head(需要每张卡都存储完整的LM Head权重)。
但是,这需要每张卡都有足够的显存放得下整个LM Head(词表大小×隐层大小×2字节(fp16))。例如50k×6144×2≈600MB,这可以接受。
因此,推荐做法:
MoE层输出后,在TP组内通过All-Gather得到完整隐层(每张卡都有 [batch, seq, hidden])。
然后,LM Head(一个线性层)的权重在每张卡上都是完整的(通过DP组广播,每个DP组内的卡都有相同的权重副本)。
每张卡独立计算:logits = hidden_full @ lm_head_weight.T,得到 [batch, seq, vocab]。
这样避免了LM Head的并行通信,但增加了显存占用(存储完整LM Head权重)和计算量(每张卡都计算整个矩阵乘法)。然而,计算方面实际上通过数据并行分摊了(因为batch切分在数据并行组内,但实际上在TP组内也是完整batch?注意,TP组内的batch是完整的,因为前面All-Gather已经得到完整隐层,而每个TP组计算的是整个batch?)
澄清:我们的并行方式包括DP(数据并行)和TP(张量并行)。在TP组内,每个TP组处理一个数据并行分片(batch的一部分)。所以,在TP组内,All-Gather之后的隐层是该TP组负责的那部分batch(batch_size/DP_size)的完整隐层。然后,在TP组内每张卡计算完整的LM Head(对这部分batch)。
因此,总计算量:每个TP组独立计算batch_size/DP_size个样本的整个LM Head。
这样,LM Head的计算在多个TP组之间是数据并行的(每个组算一部分batch)。
所以,这个方案是可行的,并且没有额外的通信。
总结流程:
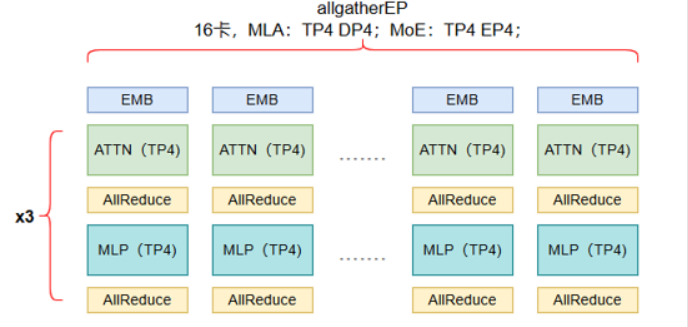
在注意力层:使用TP=4(和DP=4)计算。
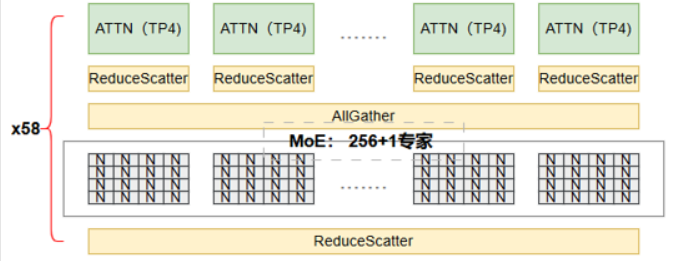
MoE层:使用TP=4和EP=4(allgatherEP模式),输出通过Reduce-Scatter得到分片隐层(每个卡持有部分隐层)。
为了进入后续层(比如下一层可能是Attention层)需要完整隐层?但这里是进入LM Head。
但是,在模型结构上,通常MoE层后面可能还有层(如另一个Attention层),但最后才是LM Head。在您的配置中,可能MoE层是最后一层专家层,然后输出到LM Head。
因此,如果后面是LM Head,那么:
Step1: MoE层输出(Reduce-Scatter后) -> 每张卡有 [batch, seq, hidden/TP]
Step2: 执行All-Gather(在TP组内)得到完整的隐层 [batch, seq, hidden](注意,这个batch是当前DP分片,即batch/DP_size)
Step3: 将完整隐层输入到LM Head(每张卡都有完整的LM Head权重,独立计算)
Step4: 得到logits [batch, seq, vocab],然后计算损失(在数据并行组内需要聚合损失?或者直接在每个设备上计算自己部分batch的损失,然后梯度聚合时自然合并)
注意:损失计算不需要跨设备通信,因为每个设备只计算自己部分batch的损失(标签也是分片的),最后梯度聚合在数据并行组内进行(只对模型参数梯度,损失值本身不需要聚合)。
所以,在MoE层后到LM Head之间,需要一次All-Gather(在TP组内)来恢复完整隐层,然后直接计算LM Head。
这个All-Gather操作是必要的。
如果您不想做这次All-Gather,另一种方法是:将LM Head的TP计算与前面的MoE层的TP输出分片对齐(按隐层维度切分),然后通过All-Reduce(Sum)来聚合logits。但是,如上所述,All-Reduce的通信量很大(因为词表大),所以通常不采用。
结论:在您的配置下,MoE层后进入LM Head之前,需要一次All-Gather(在TP组内)来恢复完整隐层。
这也就是为什么您的问题描述中说“然后进入下一步采用all gather”的原因。




)
---gateway api)
)








)




vue3中的pinia状态管理、组件通信方式及总结、插槽)


)