一、渲染循环核心
while (!glfwWindowShouldClose(window)) {glfwPollEvents();helloTriangleApp.drawFrame(); // 绘制帧}在 Vulkan 中渲染帧包含一组常见的步骤
-
等待前一帧完成(vkWaitForFences)
-
从交换链获取图像(vkAcquireNextImageKHR)
-
录制一个命令缓冲区将场景绘制到图像上(vkBeginCommandBuffer、vkEndCommandBuffer)
-
提交已记录的命令缓冲区(vkQueueSubmit)
-
呈现交换链图像(vkQueuePresentKHR)
这就是一个drawFrame函数要做的主要工作。
二、同步
GPU执行需显式同步。
例如下面这些事件:
-
从交换链获取图像(vkAcquireNextImageKHR)
-
执行在获取的图像上绘制的命令
-
将该图像呈现到屏幕上进行呈现,将其返回到交换链(vkQueuePresentKHR)
信号量
用于控制GPU上的同步操作。
VkCommandBuffer A, B = ... // 录制命令缓冲
VkSemaphore S = ... // 创建一个信号// 当操作 A 完成时,将发出信号量 S 的信号,而操作 B 将不会启动,直到 S 发出信号
vkQueueSubmit(work: A, signal: S, wait: None)// 在操作 B 开始执行后,信号量 S 将自动重置回未发出信号的状态,从而允许再次使用它。
vkQueueSubmit(work: B, signal: None, wait: S)栅栏
它是用于对 CPU(也称为主机)上的执行进行排序的。如果主机需要知道 GPU 何时完成某件事,我们会使用栅栏。
例如:截屏操作
VkCommandBuffer A = ... // 记录包含传输操作的命令缓冲区
VkFence F = ... // 创建围栏对象// 将命令缓冲区A提交到队列,立即开始执行,并在完成时发出围栏F的信号
vkQueueSubmit(work: A, fence: F)vkWaitForFence(F) // 阻塞当前执行线程,直到命令缓冲区A完成执行save_screenshot_to_disk() // 必须等待传输操作完成后才能执行三、绘制过程
创建同步对象
void HelloTriangle::createSyncObjects() {// 为每一帧预分配同步对象的存储imageAvailableSemaphores.resize(MAX_CONCURRENT_FRAMES);renderFinishedSemaphores.resize(MAX_CONCURRENT_FRAMES);inFlightFences.resize(MAX_CONCURRENT_FRAMES);// 设置信号量创建信息结构体VkSemaphoreCreateInfo semaphoreInfo{};semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;// 设置围栏创建信息结构体,初始化为已信号化状态VkFenceCreateInfo fenceInfo{};fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT; // 初始状态设为已信号化,允许第一帧立即执行// 为每一个并发帧创建一组同步对象for (size_t i = 0; i < MAX_CONCURRENT_FRAMES; i++) {if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphores[i]) != VK_SUCCESS|| vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphores[i]) != VK_SUCCESS|| vkCreateFence(device, &fenceInfo, nullptr, &inFlightFences[i]) != VK_SUCCESS) {throw std::runtime_error("Failed to create synchronization objects for a frame!");}}
}录制命令
void HelloTriangle::recordCommandBuffer(VkCommandBuffer commandBuffer, uint32_t imageIndex) {// 1. 开始记录命令缓冲区VkCommandBufferBeginInfo beginInfo{};beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;if (vkBeginCommandBuffer(commandBuffer, &beginInfo) != VK_SUCCESS) {throw std::runtime_error("Failed to begin recording command buffer!");}// 2. 设置渲染通道信息VkRenderPassBeginInfo renderPassInfo{};renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;renderPassInfo.renderPass = renderPass; // 指定使用的渲染通道renderPassInfo.framebuffer = swapChainFramebuffers[imageIndex]; // 指定目标帧缓冲renderPassInfo.renderArea.offset = {0, 0}; // 渲染区域起点renderPassInfo.renderArea.extent = swapChainExtent; // 渲染区域大小// 设置清除颜色 (黑色)VkClearValue clearColor = {{{0.0f, 0.0f, 0.0f, 1.0f}}};renderPassInfo.clearValueCount = 1;renderPassInfo.pClearValues = &clearColor;// 3. 开始渲染通道,使用内联子通道内容vkCmdBeginRenderPass(commandBuffer, &renderPassInfo, VK_SUBPASS_CONTENTS_INLINE);// 4. 绑定图形管线vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, graphicsPipeline);// 5. 设置视口 (Viewport) - 定义裁剪空间坐标到帧缓冲坐标的映射VkViewport viewport{};viewport.x = 0.0f;viewport.y = 0.0f;viewport.width = static_cast<float>(swapChainExtent.width);viewport.height = static_cast<float>(swapChainExtent.height);viewport.minDepth = 0.0f;viewport.maxDepth = 1.0f;vkCmdSetViewport(commandBuffer, 0, 1, &viewport);// 6. 设置剪刀区域 (Scissor) - 定义实际渲染的区域VkRect2D scissor{};scissor.offset = {0, 0};scissor.extent = swapChainExtent;vkCmdSetScissor(commandBuffer, 0, 1, &scissor);// 7. 执行绘制命令 - 绘制3个顶点,组成一个三角形vkCmdDraw(commandBuffer, 3, 1, 0, 0);// 8. 结束渲染通道vkCmdEndRenderPass(commandBuffer);// 9. 结束命令缓冲区记录if (vkEndCommandBuffer(commandBuffer) != VK_SUCCESS) {throw std::runtime_error("Failed to record command buffer!");}
}绘制帧
void HelloTriangle::drawFrame() {// 1. 等待当前帧的围栏被信号化,确保上一帧的渲染操作已完成vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, UINT64_MAX);// 重置围栏状态,为下一帧做准备vkResetFences(device, 1, &inFlightFences[currentFrame]);// 2. 从交换链获取下一可用图像,使用当前帧的"图像可用"信号量uint32_t imageIndex;vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);// 3. 重置并记录当前帧的命令缓冲区vkResetCommandBuffer(commandBuffers[currentFrame], 0);recordCommandBuffer(commandBuffers[currentFrame], imageIndex);// 4. 设置提交信息,定义命令执行的依赖关系VkSubmitInfo submitInfo{};submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;// 等待"图像可用"信号量,确保在图像可用后再开始渲染VkPipelineStageFlags waitStages[] = {VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT};submitInfo.waitSemaphoreCount = 1;submitInfo.pWaitSemaphores = &imageAvailableSemaphores[currentFrame];submitInfo.pWaitDstStageMask = waitStages;// 指定要执行的命令缓冲区submitInfo.commandBufferCount = 1;submitInfo.pCommandBuffers = &commandBuffers[currentFrame];// 当命令执行完成时,信号化"渲染完成"信号量submitInfo.signalSemaphoreCount = 1;submitInfo.pSignalSemaphores = &renderFinishedSemaphores[currentFrame];// 提交命令到图形队列,并关联围栏以跟踪完成状态if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {throw std::runtime_error("Failed to submit draw command buffer!");}// 5. 设置呈现信息,准备将渲染结果呈现到屏幕VkPresentInfoKHR presentInfo{};presentInfo.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;// 等待"渲染完成"信号量,确保渲染完成后再呈现presentInfo.waitSemaphoreCount = 1;presentInfo.pWaitSemaphores = &renderFinishedSemaphores[currentFrame];// 指定要呈现的交换链和图像索引presentInfo.swapchainCount = 1;presentInfo.pSwapchains = &swapChain;presentInfo.pImageIndices = &imageIndex;// 提交呈现请求到呈现队列vkQueuePresentKHR(presentQueue, &presentInfo);// 6. 更新当前帧索引,循环使用预分配的同步对象currentFrame = (currentFrame + 1) % MAX_CONCURRENT_FRAMES;
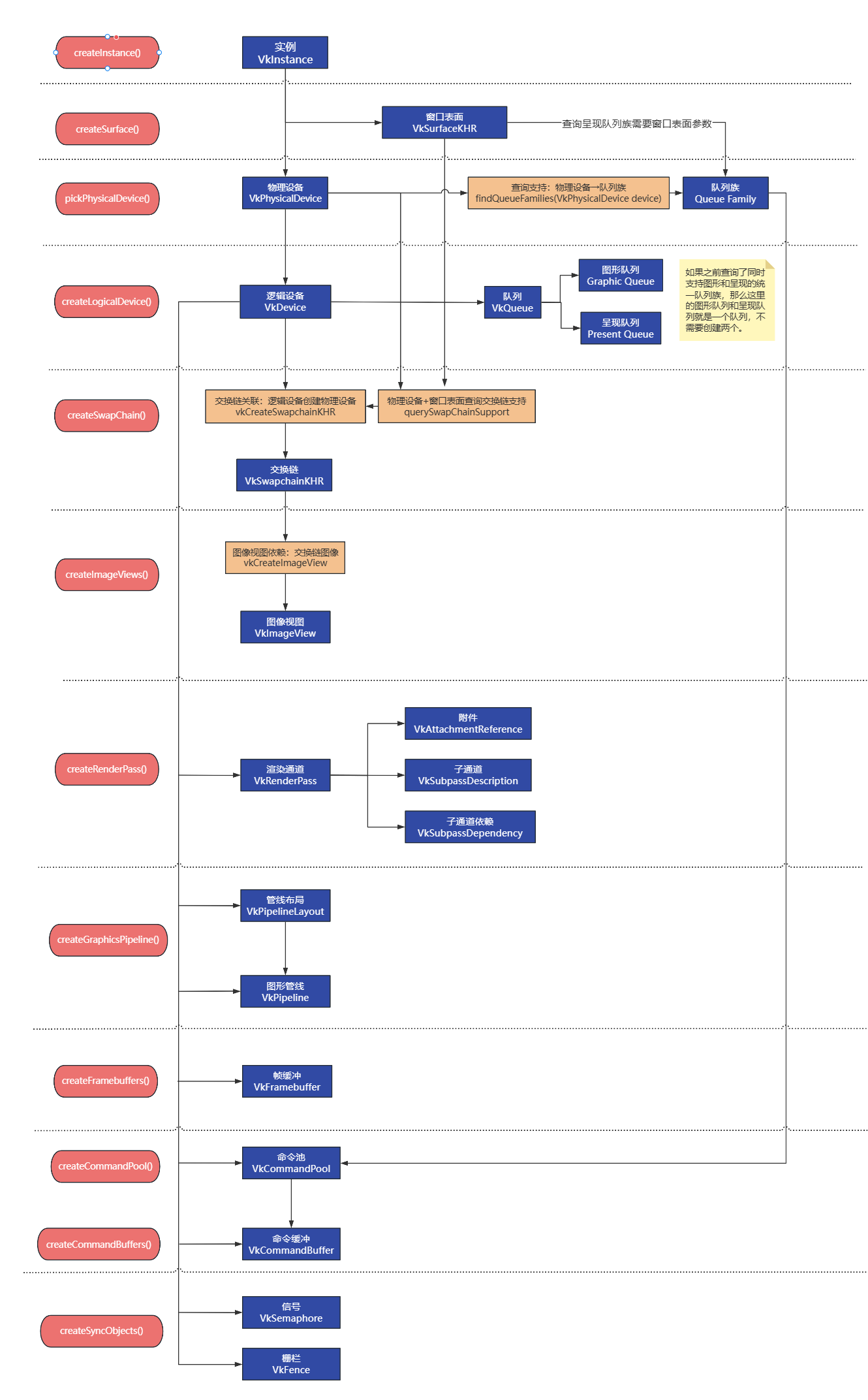
}完整的初始化过程关系图
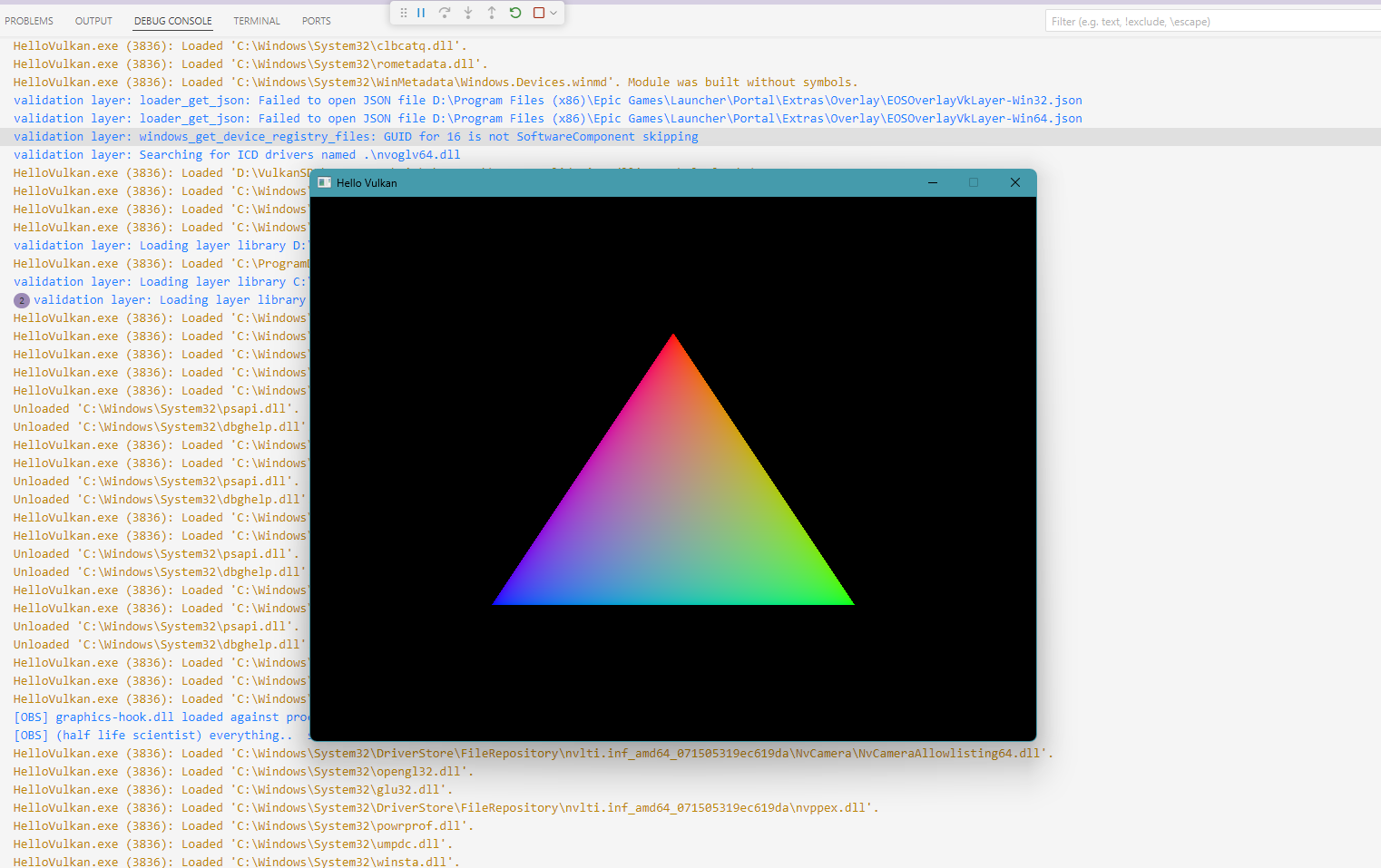
呈现效果:
四、新增成员变量和成员函数
新增/更新的成员变量
// 全局变量
const int MAX_CONCURRENT_FRAMES = 3; // 定义绘制的最大并行帧数// 类成员变量更新
std::vector<VkCommandBuffer> commandBuffers; // 为每一帧创建一个命令缓冲
std::vector<VkSemaphore> imageAvailableSemaphores; // 为每一帧创建一个图片信号量
std::vector<VkSemaphore> renderFinishedSemaphores; // 为每一帧创建渲染器完成信号量
std::vector<VkFence> inFlightFences; // 为每一帧创建一个栅栏新增成员函数
void createCommandBuffers();void recordCommandBuffer(VkCommandBuffer commandBuffer, uint32_t imageIndex);void createSyncObjects();void cleanupSwapChain()void drawFrame();上一节和本节代码保存为分支 04_render_present



![ParaGraphX [特殊字符]](http://pic.xiahunao.cn/ParaGraphX [特殊字符])
)

)





:动态准入控制和Webhook)


)


)
