Kafka入门4.0.0版本(基于Java、SpringBoot操作)
一、kafka概述
Kafka最初是由LinkedIn公司开发的,是一个高可靠、高吞吐量、低延迟的分布式发布订阅消息系统,它使用Scala语言编写,并于2010年被贡献给了Apache基金会,随后成为Apache的顶级开源项目。主要特点有:
- 为发布和订阅提供高吞吐量
- 消息持久化
- 分布式
- 消费消息采用Pull模式
- 支持在线和离线场景
本次采用最新的kafka版本4.0.0,Kafka 4.0 最引人瞩目的变化之一,当属其默认运行在 KRaft(Kafka Raft)模式下,彻底摆脱了对 Apache ZooKeeper 的依赖。在 Kafka 的发展历程中,ZooKeeper 曾是其核心组件,负责协调分布式系统中的元数据管理、Broker 注册、主题分区分配等关键任务。然而,随着 Kafka 功能的不断丰富与用户规模的持续扩大,ZooKeeper 逐渐成为系统部署和运维中的一个复杂性来源,增加了运营成本与管理难度。
KRaft 模式的引入,标志着 Kafka 在架构上的自我进化达到了一个新高度。通过采用基于 Raft 一致性算法的共识机制,Kafka 将元数据管理内嵌于自身体系,实现了对 ZooKeeper 的无缝替代。这一转变带来了多方面的显著优势:
简化部署与运维:运维人员无需再为维护 ZooKeeper 集群投入额外精力,降低了整体运营开销。新架构减少了系统的复杂性,使得 Kafka 的安装、配置和日常管理变得更加直观和高效。
增强可扩展性:KRaft 模式下,Kafka 集群的扩展性得到了进一步提升。新增 Broker 节点的加入流程更加简便,能够更好地适应大规模数据处理场景下对系统资源动态调整的需求。
提升系统性能与稳定性:去除 ZooKeeper 这一外部依赖后,Kafka 在元数据操作的响应速度和一致性方面表现出色。尤其是在高并发写入和读取场景下,系统的稳定性和可靠性得到了增强,减少了因外部组件故障可能导致的单点问题。
- 之前的架构
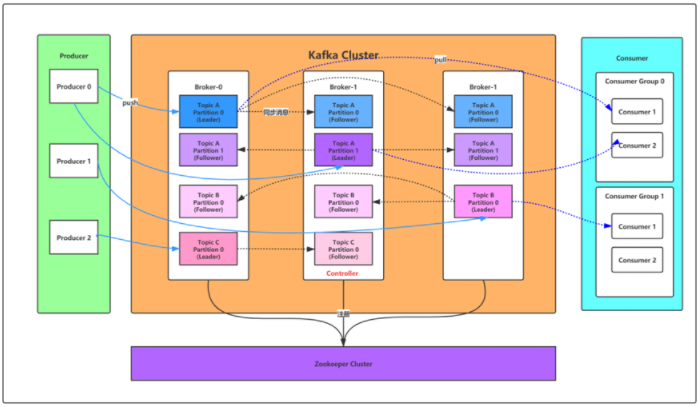
- 现在的架构
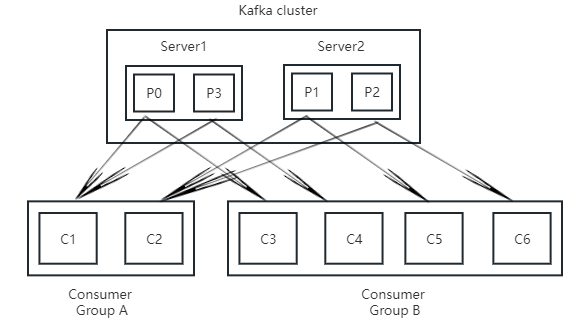
kafka消费模型
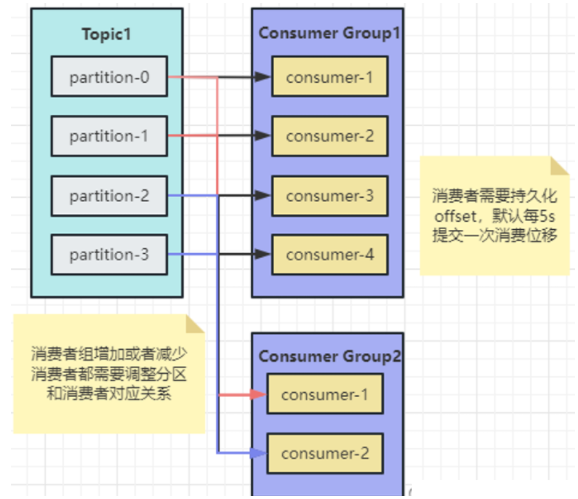
不同消费者组可以消费全量的消息,相同消费者组内的消费者只能消费一部分。
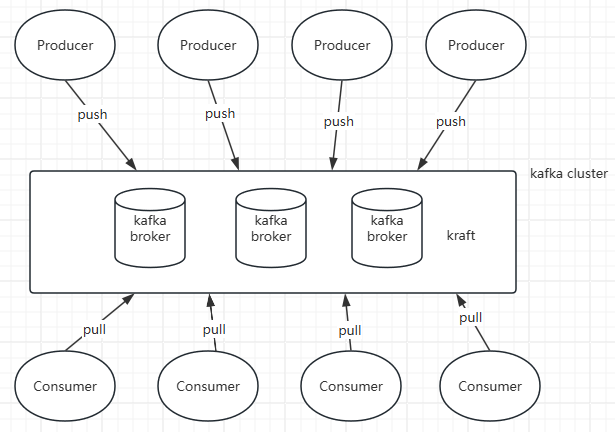
kafka基本概念
Producer(生产者)
消息的生产者,负责将消息发送到Kafka集群中。
Consumer(消费者)
消息的消费者,负责从Kafka集群中读取并处理消息
Broker(服务代理节点)
Kafka集群中的一个或多个服务器,负责存储和转发消息。
Topic(主题)
Kafka中的消息以主题为单位进行归类,生产者发送消息到特定主题,消费者订阅并消费这些主题的消息。
Partition(分区)
每个主题可以细分为多个分区,分区是Kafka存储消息的物理单位,每个分区可以看作是一个有序的、不可变的消息序列。
Replica(副本)
Kafka为每个分区引入了多副本机制,以提高数据的安全性和可靠性。副本分为leader和follower,其中leader负责处理读写请求,follower负责从leader同步数据。
Consumer Group(消费者组)
由多个消费者组成,消费者组内的消费者共同消费同一个主题的消息,但每个消费者只负责消费该主题的一个或多个分区,避免消息重复消费。
kraft
通过采用基于 Raft 一致性算法的共识机制,Kafka 将元数据管理内嵌于自身体系,实现了对 ZooKeeper 的无缝替代
kafka发送端采用push模式
kafka消费端采用pull模式订阅并消费消息
Kafka的工作原理
可以概括为以下几个步骤:
-
消息发布: 生产者将消息发送到Kafka集群的特定主题,并可以选择发送到该主题的哪个分区。如果未指定分区,Kafka会根据负载均衡策略自动选择分区。
-
消息存储: Kafka将接收到的消息存储在磁盘上的分区中,每个分区都是一个有序的消息序列。Kafka使用顺序写入和零拷贝技术来提高写入性能,并通过多副本机制确保数据的安全性和可靠性。
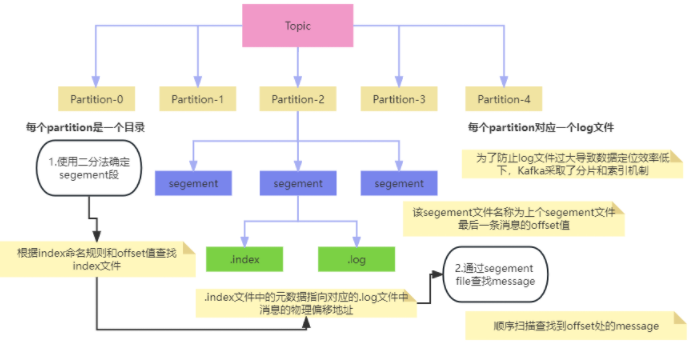
- 消息消费: 消费者组中的消费者从Kafka集群中订阅并消费消息。每个消费者负责消费一个或多个分区中的消息,并确保消息至少被消费一次。消费者可以使用拉(Pull)模式或推(Push)模式从Kafka中拉取消息。
-
负载均衡: Kafka通过ZooKeeper维护集群的元数据信息,包括分区和消费者的对应关系。当消费者数量或分区数量发生变化时,Kafka会重新分配分区给消费者,以实现负载均衡。
-
容错机制: Kafka通过多副本机制实现容错。当leader副本出现故障时,Kafka会从ISR(In-Sync Replicas)集合中选择一个新的leader副本继续对外提供服务。同时,Kafka还提供了多种可靠性级别供用户选择,以满足不同的业务需求。
kafka特点
一、Kafka的持久化机制
Kafka的持久化机制主要涉及消息的存储和复制。Kafka以日志的形式存储消息,每个主题(Topic)被划分为多个分区(Partition),每个分区中的消息按照顺序进行存储。Kafka使用多个副本(Replica)来保证消息的持久性和可靠性,每个分区的消息会被复制到多个副本中,以防止数据丢失。此外,Kafka还允许根据配置的保留策略来保留已消费的消息一段时间,以便在需要时进行检索和恢复。
Kafka的副本机制是其实现高可用性和数据持久性的重要基石。每个主题的每个分区都配置有多个副本,这些副本分散保存在不同的Broker上,从而能够对抗部分Broker宕机带来的数据不可用问题。Kafka的副本机制包括领导者副本(Leader Replica)和追随者副本(Follower Replica):
领导者副本:负责处理所有的读写请求,包括生产者的消息写入和消费者的消息读取。
追随者副本:从领导者副本异步拉取消息,并写入到自己的提交日志中,从而实现与领导者副本的同步。追随者副本不对外提供服务,只作为数据的冗余备份。
Kafka还引入了ISR(In-Sync Replicas)机制,即与领导者副本保持同步的副本集合。只有处于ISR中的副本才能参与到消息的写入和读取过程中,以确保数据的一致性和可靠性。当某个副本与领导者副本的同步延迟超过一定的阈值时,它会被踢出ISR,直到同步恢复正常。
二、Kafka的数据一致性
Kafka通过多个机制来确保数据的一致性,包括副本同步、ISR机制、生产者事务和消费者事务等:
副本同步:确保主副本将数据同步到所有副本的过程,在副本同步完成之前,生产者才会认为消息已经被成功写入。
ISR机制:通过动态调整ISR列表中的副本,确保只有可靠的副本参与到数据的读写操作,从而提高数据的一致性和可靠性。
生产者事务:Kafka的生产者事务机制可以确保消息的Exactly-Once语义,即消息不会被重复写入或丢失。生产者事务将消息的发送和位移提交等操作放在同一个事务中,一旦事务提交成功,就意味着消息已经被成功写入,并且对应的位移也已经提交。
消费者事务:虽然Kafka的消费者通常不直接支持事务但消费者可以通过提交位移(Offset)来确保消息的正确消费。消费者事务将消息的拉取和位移提交等操作放在同一个事务中,以确保消息不会被重复消费或丢失。
二、kafka应用
2.1 win11安装kafka4.0.0
下载地址:https://kafka.apache.org/downloads 下载最后一个kafka-2.13-4.0.0.tgz
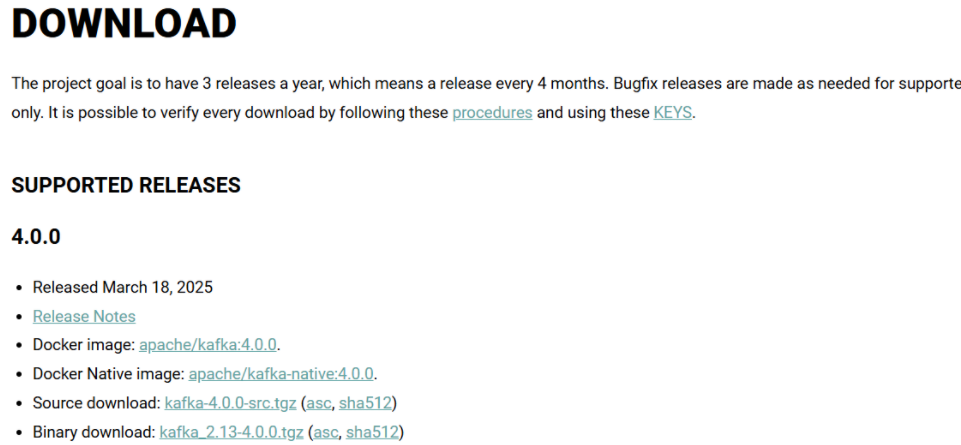
下载好之后,把这个压缩包解压就行了,然后找到config下面的server.properties
找到log.dirs改成自己电脑上的目录
log.dirs=E:\\runSoft\\kafka\\data

先打开命令行,进入到bin下面的windows目录下
命令
kafka-storage.bat random-uuid

先获取uuid,我的uuid为ANVnC_s-QYGJF1C7wu9Aww
命令:
kafka-storage.bat format --standalone -t PPEZ2LW8T8yjZNWnfNHorQ -c ../../config/server.properties

打开命令行,进入到bin下面的windows目录下 启动命令
kafka-server-start.bat ../../config/server.properties
创建topic
kafka-topics.bat --create --topic quickstart-events --bootstrap-server localhost:9092
启动一个消费端
kafka-console-consumer.bat --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
启动一个生产端
kafka-console-consumer.bat --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
问题
1、如果提示如下
命令行 输入行太长。 命令语法不正确。则需要把目录变短,目录太长,win11不让输入。
2,tgz需要解压两次
只解压一次是不行的,tgz是打包之后压缩的。3、如果启动失败,需要重新配置
重新配置时。把log.dirs的路径下面的东西清空
2.2 java开发kafka
第一步,引入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>4.0.0</version>
</dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>2.0.17</version>
</dependency>
第二步,建立生产者
public class Producer {public static void main(String[] args) {Map<String,Object> props = new HashMap<>();// kafka 集群 节点props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");String topic = "test";KafkaProducer<String, String> producer = new KafkaProducer(props);producer.send(new ProducerRecord<String, String>(topic, "key", "value-1"));producer.send(new ProducerRecord<String, String>(topic, "key", "value-2"));producer.send(new ProducerRecord<String, String>(topic, "key", "value-3"));producer.close();}}
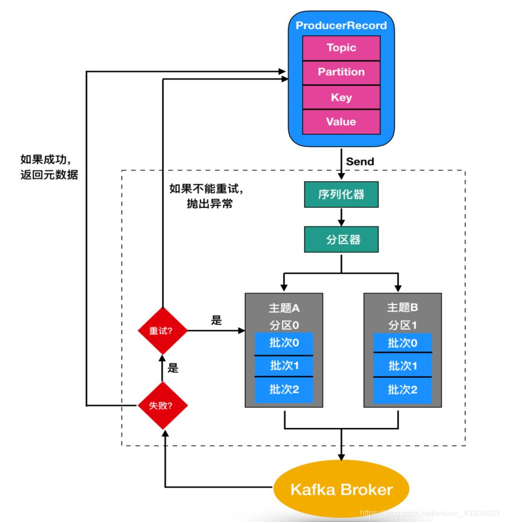
ProducerRecord 是 Kafka 中的一个核心类,它代表了一组 Kafka 需要发送的 key/value 键值对,它由记录要发送到的主题名称(Topic Name),**可选的分区号(Partition Number)**以及可选的键值对构成。
第三步、建立消费者类
public class Consumer {public static void main(String[] args){Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test");props.put("enable.auto.commit", "true");props.put("auto.commit.interval.ms", "1000");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String , String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList("test"));while (true) {ConsumerRecords<String,String> records = consumer.poll(Duration.ofDays(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("partition = %d ,offset = %d, key = %s, value = %s%n",record.partition(), record.offset(), record.key(), record.value());}}}
}
运行效果
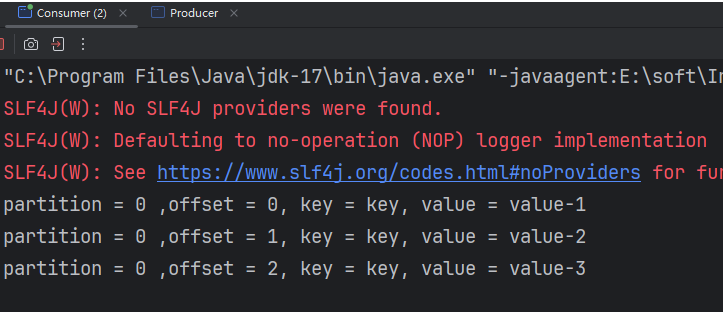
2.3 spring boot整合kafka
第一步,引入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.4.1</version><relativePath/> <!-- lookup parent in repository --></parent><artifactId>spring_boot_kafka_demo</artifactId><packaging>jar</packaging><name>spring_boot_kafka_demo Maven Webapp</name><url>http://maven.apache.org</url><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>4.0.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>第二步,编写配置文件
编写resources下的application.yml
spring:kafka:bootstrap-servers: localhost:9092consumer:auto-offset-reset: earliest
第三步,编写生产者
@Service
public class Producer {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String message) {kafkaTemplate.send("topic1", message);}@PostConstructpublic void init() {sendMessage("Hello, Kafka!");}
}
第四步,编写消费者
@Component
public class Consumer {@KafkaListener(id = "myId", topics = "topic1")public void listen(String in) {System.out.println(in);}
}
第五步,编写启动类
@SpringBootApplication
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}}
运行效果
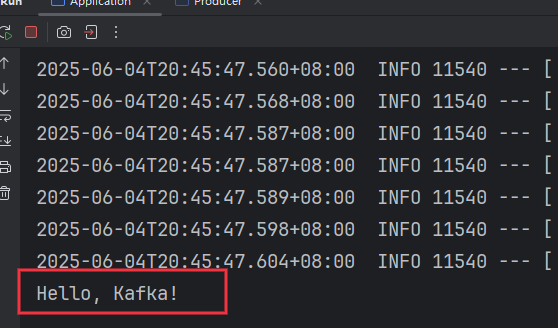
2.4 记录日志到kafka中
第一步,在2.3的基础上,添加依赖
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>2.0.12</version> <!-- Spring Boot 3.x 推荐版本 -->
</dependency>
第二步,添加kafka的日志appender类
public class KafkaLogbackAppender extends UnsynchronizedAppenderBase<ILoggingEvent> {private String topic = "application-logs";private String bootstrapServers = "localhost:9092";private KafkaProducer<String, String> producer;@Overridepublic void start() {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());this.producer = new KafkaProducer<>(props);super.start();}@Overrideprotected void append(ILoggingEvent eventObject) {String msg = eventObject.getFormattedMessage();producer.send(new ProducerRecord<>(topic, msg));}@Overridepublic void stop() {if (producer != null) {producer.close();}super.stop();}// Getter and Setter for XML configpublic void setTopic(String topic) {this.topic = topic;}public void setBootstrapServers(String bootstrapServers) {this.bootstrapServers = bootstrapServers;}
}
第三步,在resources下添加logback-spring.xml文件
<configuration debug="false" scan="true" scanPeriod="30 seconds"><!-- 定义日志格式 --><property name="PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"/><!-- 控制台输出 --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>${PATTERN}</pattern></encoder></appender><!-- Kafka Appender --><appender name="KAFKA" class="com.demo.KafkaLogbackAppender"><bootstrapServers>localhost:9092</bootstrapServers><topic>application-logs</topic></appender><!-- 根日志输出 --><root level="info"><appender-ref ref="STDOUT"/><appender-ref ref="KAFKA"/></root></configuration>
第四步,修改Producer类
@Service
public class Producer {private static final Logger logger = LoggerFactory.getLogger(Producer.class);@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String message) {kafkaTemplate.send("topic1", message);}@PostConstructpublic void init() {sendMessage("Hello, Kafka!");logger.info("Message sent");logger.info("Message sent");logger.info("Message sent");logger.info("Message sent");logger.info("Message sent");}
}
第五步,修改Consumer类
@Component
public class Consumer {@KafkaListener(id = "myId", topics = "topic1")public void listen(String in) {System.out.println(in);}@KafkaListener(id = "myId2", topics = "application-logs")public void listen2(String in) {System.out.println("resinfo:"+in);}
}




详解,附代码。)



问题研究)





加密芯片与MCU协同工作的典型流程)


)

)