阳性(Positive)和阴性(Negative)
阳性(Positive)=正类:通常指的是我们关注的类别或事件;阴性(Negative)=负类: 指的是与阳性相反的类别或事件。
如果对猫类别感兴趣,那么猫就是正类,而其他事物(例如狗,牛,人类)都是负类。
如果目标是检测/识别行人,那么行人就是正类,而其余的则是负类。
阳性和阴性完全是一个相对的概念,取决于任务中关注的对象。
混淆矩阵(Confusion Matrix)
混淆矩阵 = 可能性矩阵 = 错误矩阵,它是一种用于评估机器学习分类模型表现的工具,它将模型的预测结果分为四类,以预测垃圾邮件为例子:
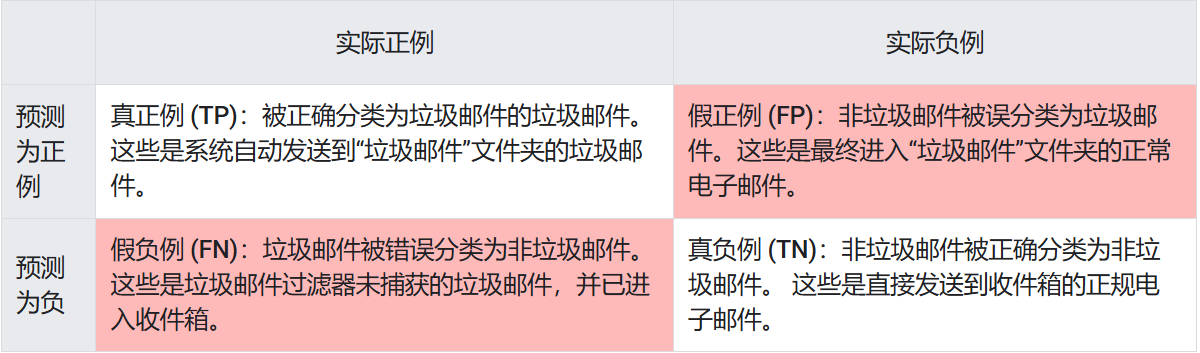
真阳性(True Positive, TP):实际为阳性,预测也为阳性。垃圾邮件,模型分类为垃圾邮件
真阴性(True Negative, TN):实际为阴性,预测也为阴性。普通邮件,模型分类为普通邮件
假阳性(False Positive, FP) = 第一类错误(Type I Error) = 误报 :实际为阴性,预测为阳性。普通邮件,模型分类为垃圾邮件。
假阴性(False Negative, FN) = 第二类错误(Type II Error) = 漏报:实际为阳性,预测为阴性。垃圾邮件,模型分类为普通邮件
阈值 Threshold
通过设置阈值,我们可以直接指示模型以何种置信度(Confident Level)来区分正类和负类
假设有一个用于垃圾邮件检测的逻辑回归模型,该模型预测一个介于 0 到 1 之间的值,表示给定电子邮件是垃圾邮件的概率。预测结果为 0.50 表示电子邮件为垃圾邮件的可能性为 50%,预测为 0.75 表示电子邮件为垃圾邮件的可能性为 75%,依此类推。
您想在电子邮件应用中部署此模型,以将垃圾邮件过滤到单独的邮件文件夹中。不过,为此,您需要转换模型的原始数值输出(例如 0.75)分为“垃圾邮件”或“非垃圾邮件”这两类。
如需进行此转换,您需要选择一个阈值概率,称为分类阈值(Classification Threshold)。然后,概率高于阈值的样本会被分配到正类别(即要测试的类,此处为 spam)。概率较低的样本会被分配到负类别(即备选类别,此处为 not spam)。
虽然 0.5 看起来像是一个直观的阈值,但如果一种错误分类的代价高于另一种类型,例如将非常重要的正常邮件错误归类为垃圾邮件(这就是后面会提到的假阳性/第一类错误/误报 ),应显著提高阈值避免误判。
先给结论
- 降低阈值,会提高真正例、假正例(误报),降低真负例、假负例(漏报);
- 提高阈值,会提高真负例、假负例(漏报),降低真正例、假正例(误报)
- 原因显而易见,阈值更高,模型需要更高的信心才会归类为正例,因此不管实际正负,模型预测为正的样本都会变少,而结果是二元化,不预测为正就会预测为负,因此模型预测为负的样本都会变多。
举个例子,假设在数据集中,实际正例和实际负例分别为 50,合计 100
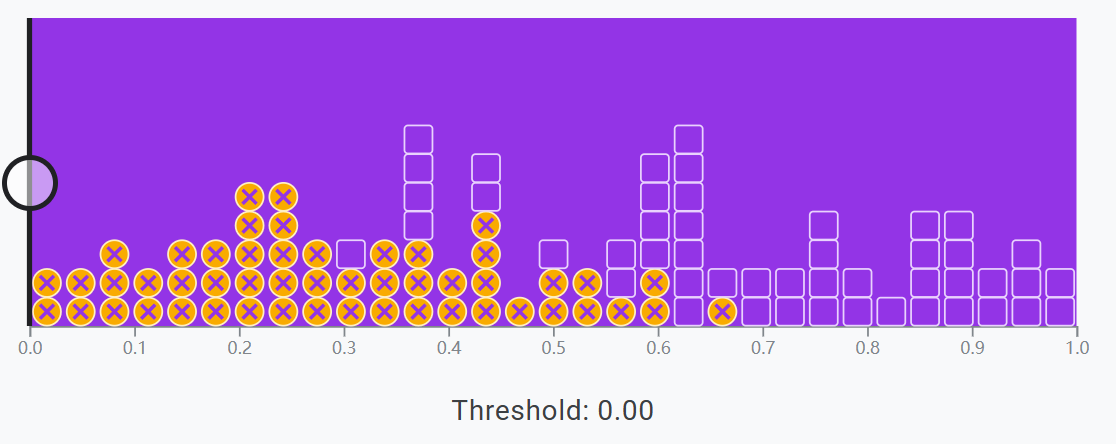

当阈值设为 0 时,代表着指示模型,将可能性大于 0 的例子归类为正例,实质就是将所有例子归类为正例
这样做的优点是能找出所有正例,但相对的,会引入很多误报。
以垃圾邮件为例,即虽然能准确找到所有垃圾邮件,但也会把所有普通邮件都当成垃圾邮件误报。
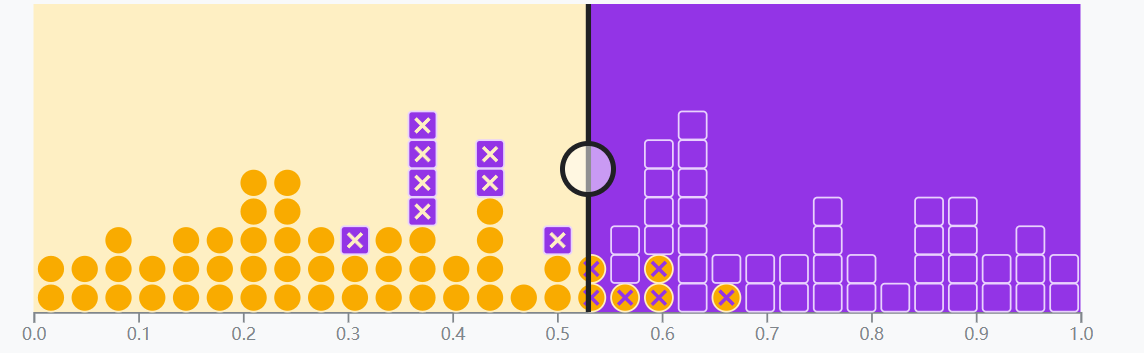

当阈值设为 0.53 时,代表着指示模型,将可能性大于 0.53 的例子归类为正例
这样做,我们可以极大减少误报,但相应地也会引入一些漏报。
以垃圾邮件为例,虽然此时有 8 封垃圾邮件没有被正确分类,但至少,有 47 封普通邮件被正确分类,显然,在邮件分类中,我们多看几封垃圾邮件,也不愿意遗漏任何一封普通邮件,因此可以说,0.53 的阈值比 0 的阈值更合理。


当阈值设为 0.68 时,代表着指示模型,将可能性大于 0.68 的例子归类为正例
这样做,我们可以将误报完全消除,但相应地引入了大量的漏报。
以垃圾邮件为例,虽然此时所有普通邮件都没有被误伤(FP = 0),但相应的,漏网之鱼垃圾邮件大大增加到 22。
在做深度学习预测分类时,有些任务绝对不能出现漏报,为此就算带来了很多误报,也可以接受;有些任务,可以容忍出现一些漏报,只要将漏报和误报控制在一个较低的水平就可以。
- 癌症筛查:漏诊癌症(FN)可能导致患者错过最佳治疗时机,危及生命。此时采取的策略应是召回率优先(将阈值降低),即使将许多良性肿瘤误判为恶性(FP),也需确保尽可能检出所有癌症病例。
- 电商商品推荐:误推不相关商品(FP)降低用户体验;漏推潜在喜欢商品(FN)损失部分转化率。此时采取的策略应是平衡精确率和召回率,即将阈值调整到合理地步,类似上面的 0.52 。
数据集不平衡
作为训练模型的一部分,我们希望提供给模型的数据集中,每个类别包含的实际个例数,应当大致相当。如果实际正例的总数与实际负例的总数不接近,则表示数据集不平衡。以预测垃圾邮件为例,数据集中可能数千条普通邮件,而垃圾邮件只有几例。
评价模型的指标
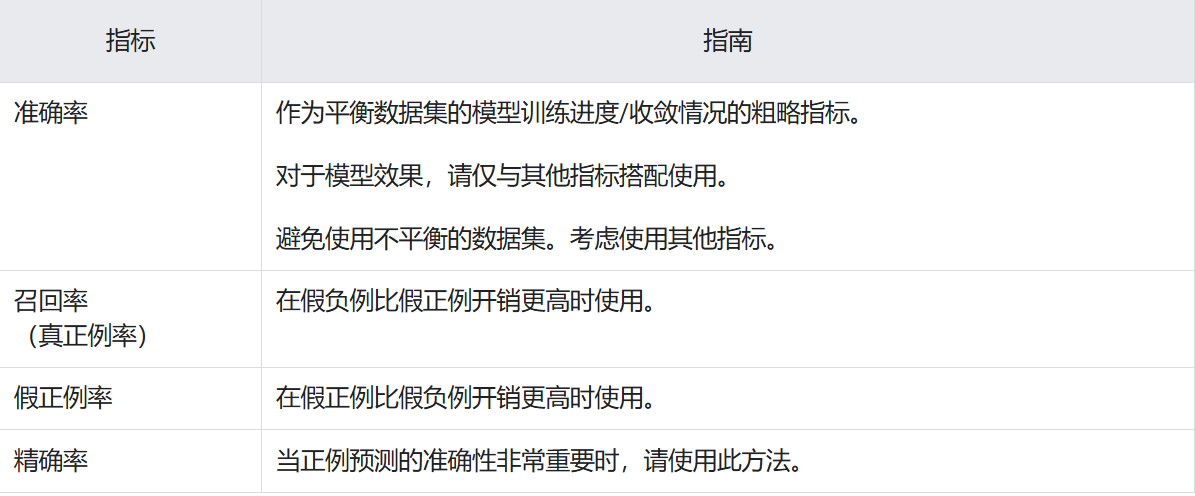
真正例、假正例和假负例是用于计算评估模型的几个实用指标。哪些评估指标最有意义,取决于具体模型和具体任务、不同错误分类的代价,以及数据集是平衡的还是不平衡的。
本部分中的所有指标均基于单个固定阈值计算得出,并且会随阈值的变化而变化。很多时候,用户会调整阈值以优化其中某个指标。
-
准确率(Accuracy):准确率用于衡量一个分类模型的效果。它表示模型预测对的次数占总预测次数的百分比。- 由于精度包含混淆矩阵中的所有四种结果(TP、FP、TN、FN),因此,在执行通用或未指定任务的通用或未指定模型、数据集平衡、两个类别中的示例数量相近的情况下,精度可以用作衡量模型质量的粗略指标。
- 例如,模型测试了 100 张图片,其中有 90 张预测正确(TP + TN = 90),那么准确率就是 90%。
- 对于严重不均衡的数据集(例如普通邮件占比非常低为1%,垃圾邮件占比为 90%),如果我们将阈值调到最高,模型 100% 都预测为负类(普通邮件),则准确率得分为 99%。尽管得分很高,这个模型实质毫无用处
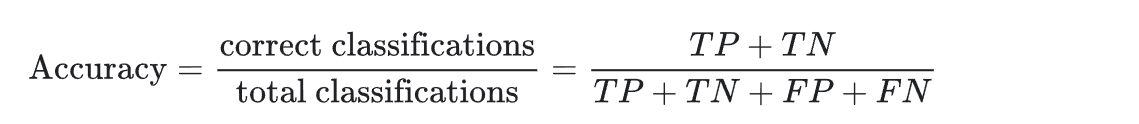
-
精确率(Precision):所有被预测为正类的样本中,实际为正类的比例。

-
召回率(Recall)=灵敏度(Sensitivity)=真正例率(TPR):所有实际为正类的样本中,被预测为正类的比例,衡量模型正确识别正类的能力。召回率。- 在实际正例数量非常少的不均衡数据集中,召回率作为指标的意义不大。

- 在实际正例数量非常少的不均衡数据集中,召回率作为指标的意义不大。
-
准确率会在一个合适的阈值达到最高;但精确率和召回率通常呈反函数关系,其中一个提高会反过另一个,无法同时提高二者。
-
F1 Score:是精确率和召回率的调和平均数(一种平均值)。该指标在精确率和召回率的重要性之间进行了平衡,对于类别不平衡的数据集,该指标优于准确率。更广泛地说,当精确率和召回率的值接近时,F1 也会接近它们的值。当精确率和召回率相差很大时,F1 将与较差的指标相似。
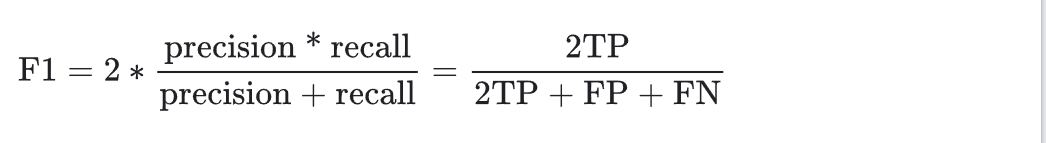
假正例率(False Positive Rate, FPR)=误报概率:所有实际为负类的样本中,(错误地)被预测为正例的比例。
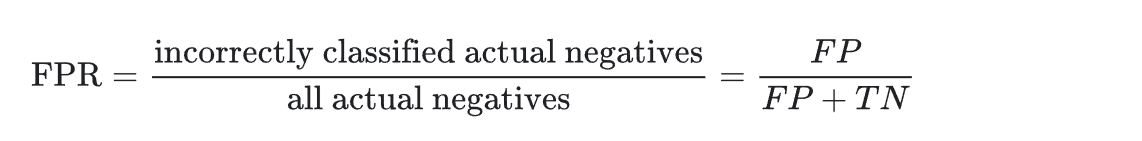
- 特异性(Specificity):所有实际为负类的样本中,(正确地)被预测为负类的比例,衡量模型正确识别负类的能力。特异性 = 真正负类率,

例题:构建一个二元分类器,用于检查昆虫捕获器的照片,以确定是否存在危险的入侵物种。在该系统中,误报(假正例)很容易处理:昆虫学家发现照片被错误分类,并将其标记为误报即可。假设准确率水平在可接受的范围内,此模型应该针对哪个指标进行优化?
误报 (FP) 的成本较低,而假负例的成本非常高,因此,最大限度地提高召回率(即检测概率)是明智之举。
ROC 曲线(ROC, Receiver Operating Characteristic Curve)
上一部分介绍了一组模型指标,这些指标均以固定的阈值来计算,一旦更换阈值,每个指标都会变化。
如果想评估所有可能的阈值下模型的表现,则需要 ROC、AUC。
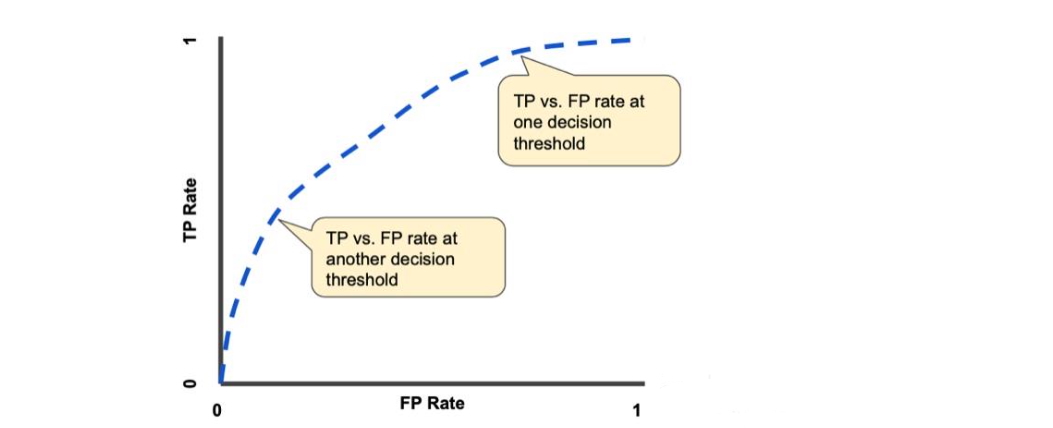
ROC 曲线是模型在所有阈值上的表现的可视化表示。
ROC 曲线的绘制步骤:
- 将 0-1 之间的阈值按照固定间隔分类,例如十等分。
- 对于每个阈值,计算对应的 TPR 和 FPR。
- 绘制 ROC 曲线:将所有阈值对应的 TPR 和 FPR 绘制在图上,FPR 为 x 轴,TPR 为 y 轴。
- 计算 AUC:ROC 曲线下的面积(AUC)表示模型的整体性能。AUC 值越高,模型的分类性能越好。
举个例子,假设有一个医疗检测模型,用于判断患者是否患有某种疾病(正样本)或没有疾病(负样本)。我们将绘制 ROC 曲线来评估模型性能。
- 收集预测概率:预测结果可能是每个患者的概率值,比如 [0.1, 0.4, 0.35, 0.8]。
- 选择不同阈值:选择阈值 0.2, 0.4, 0.6, 0.8 等。
- 计算 TPR 和 FPR:对于阈值 0.2,将所有预测概率大于等于 0.2 的样本标记为正类。计算 TPR 和 FPR。
- 重复上述步骤,计算其他阈值下的 TPR 和 FPR。
- 绘制 ROC 曲线:在图中,x 轴是 FPR,y 轴是 TPR,绘制 ROC 曲线。
- 计算 AUC:计算 ROC 曲线下的面积。AUC 越接近 1,模型性能越好。
曲线下方面积 (Area under the curve,AUC)
曲线下面积的数学意义是,代表模型在随机选择一个正例和一个负例时,将正例的排序高于负例的概率,表示模型在所有可能的阈值下的总体表现。
以垃圾邮件为例子,AUC 为 1.0 的垃圾邮件分类器始终会给随机选取的垃圾邮件赋予比随机选取的正常邮件更高的垃圾邮件概率。
更为人话的说法就是,AUC 越高,表示模型在打分阶段更能准确地区分正例和负例:它通常会给正例更高的得分,给负例更低的得分,从而具备更强的区分能力。
AUC反映了二分类模型对正负样本的区分能力,取值范围从 0 到 1:
- AUC = 1:模型能够完美地区分所有正样本和负样本。
- AUC = 0.5:模型的性能相当于随机猜测,没有实际区分能力。
- AUC < 0.5:模型的预测性能差于随机猜测,通常需要重新训练或调整模型。
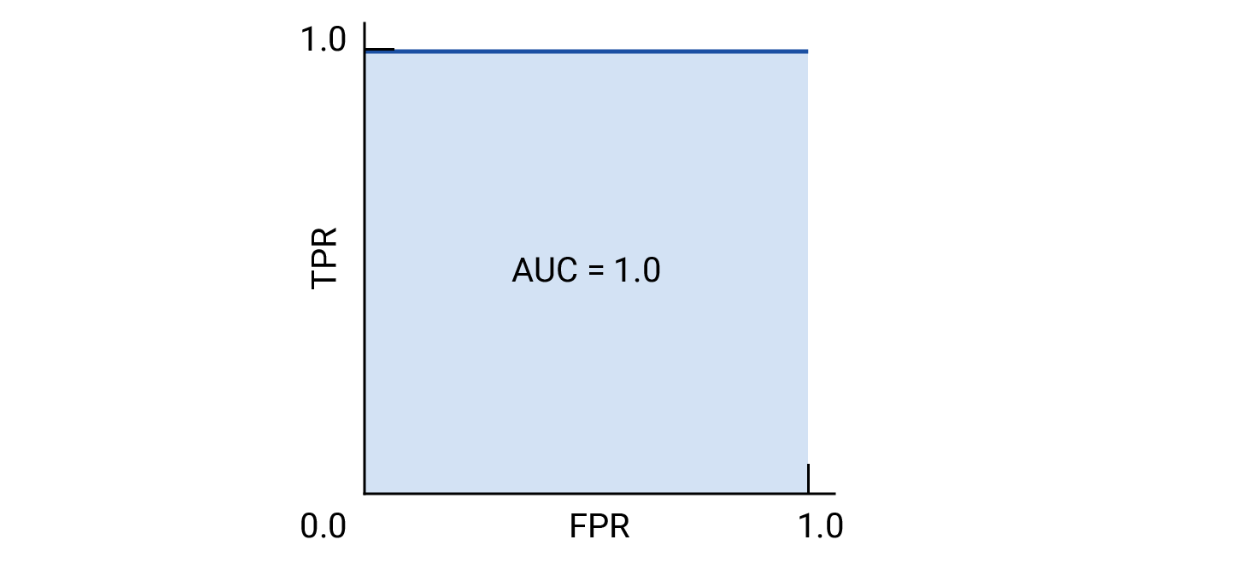
完美模型的 ROC 和 AUC,由于在任何阈值下均不存在误报和漏报,且 TP、TN 均为 1,因此 TPR、FPR 均为恒定常数 1。
随着阈值从1逐步减小到0(或从高到低),模型会“更宽松”地判为正类,导致:
- TPR 上升(找到了更多正类)
- FPR 也上升(错判的负类也变多)
标注(Annotation)
标注就是给数据打标签的过程。在机器学习中,标注数据是为了让模型能够学习如何将输入数据映射到正确的输出。标注的过程通常包括以下几个步骤:
- 选择数据:选择需要标注的数据,例如图片、文本或视频。
- 添加标签:为每个数据样本添加标签。例如,我们有一组图片,我们会给每张图片加上标签,标明这张图片是“狗”还是“猫”。
- 检查和验证:确保标注的准确性,以便模型可以学习到正确的信息。






:健康饮食(附代码))




)


)

的图像生成与编辑:原理、应用与实践)
和backward())

