点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Sentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective
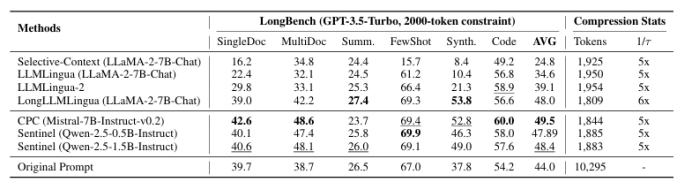
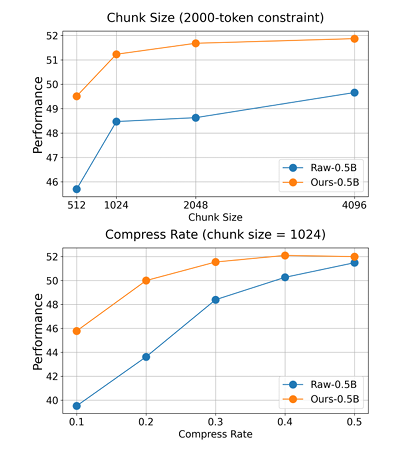
检索增强型生成(RAG)通过外部上下文增强了大型语言模型(LLMs),但检索到的段落通常冗长、嘈杂或超出输入限制。现有的压缩方法通常需要训练专门的压缩模型,这增加了成本并降低了可移植性。本文提出了Sentinel,这是一个轻量级的句子级压缩框架,将上下文过滤重新定义为基于注意力的理解任务。Sentinel不是训练一个压缩模型,而是通过一个轻量级分类器探测一个现成的0.5B代理LLM的解码器注意力,以识别句子的相关性。实证研究表明,查询-上下文相关性估计在不同模型规模之间是一致的,0.5B代理与更大模型的行为非常接近。在LongBench基准测试中,Sentinel实现了高达5倍的压缩,同时匹配了7B规模压缩系统的问答性能。结果表明,探测原生注意力信号可以实现快速、有效的、问题感知的上下文压缩。


文章链接:
https://arxiv.org/pdf/2505.23277
02
R-KV: Redundancy-aware KV Cache Compression for Training-Free Reasoning Models Acceleration
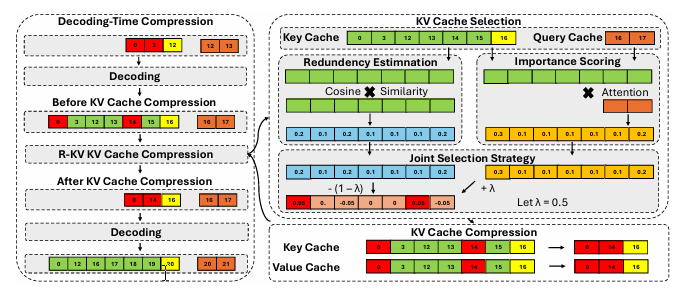
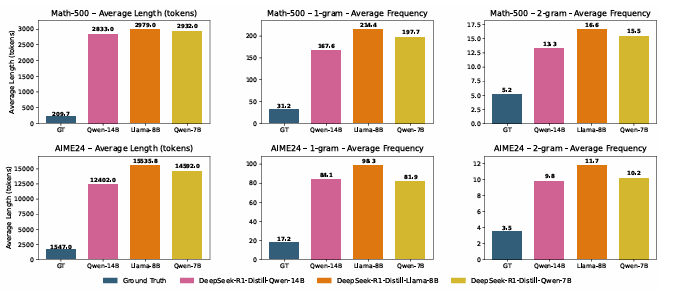
推理模型在自我反思和思维链推理方面表现出令人印象深刻的性能。然而,它们通常会产生过长的输出,导致在推理过程中 key-value(KV)缓存过大。尽管思维链推理显著提高了复杂推理任务的性能,但当使用现有的 KV 缓存压缩方法部署时,也可能导致推理失败。为了解决这一问题,本文提出了针对推理模型的冗余感知 KV 缓存压缩方法(R-KV),这是一种专门针对推理模型中冗余标记的新方法。该方法仅使用 10% 的 KV 缓存就能保留接近 100% 的完整 KV 缓存性能,显著优于现有的 KV 缓存基线,后者仅能达到 60% 的性能。值得注意的是,R-KV 甚至在使用 16% 的 KV 缓存时就能达到完整 KV 缓存性能的 105%。这种 KV 缓存的减少还带来了 90% 的内存节省和比标准思维链推理推理快 6.6 倍的吞吐量。实验结果表明,R-KV 在两个数学推理数据集上始终优于现有的 KV 缓存压缩基线。
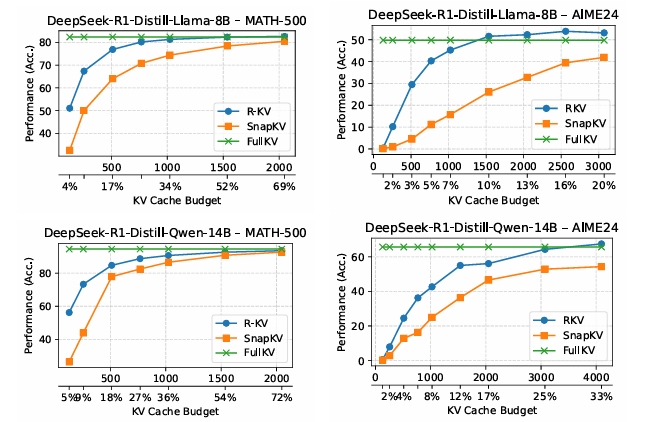
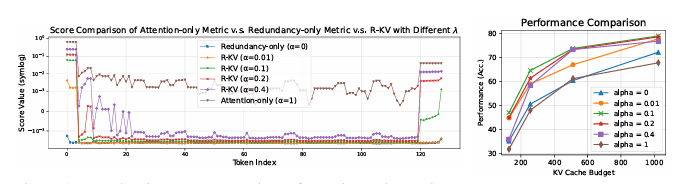
文章链接:
https://arxiv.org/pdf/2505.24133
03
Bounded Rationality for LLMs: Satisficing Alignment at Inference-Time
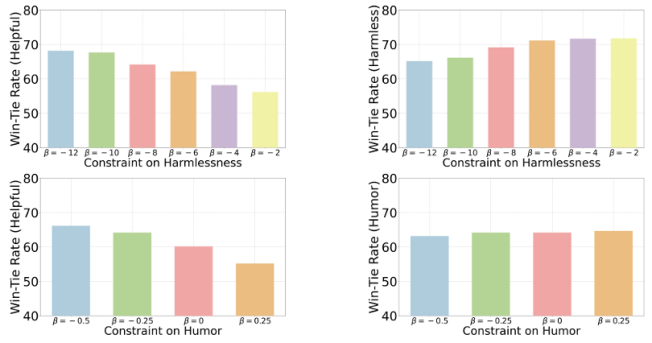
由于偏好反馈固有的多面性,将大型语言模型与人类对齐是一项挑战。虽然现有的方法通常将其视为多目标优化问题,但它们往往忽略了人类实际上是如何做出决策的。对有限理性的研究表明,人类的决策遵循满意策略,即优化主要目标,同时确保其他目标满足可接受的阈值。为了弥合这一差距,并操作化的概念,满意的对齐,我们提出SITALIGN:推理时间框架,解决对齐的多方面性质,最大限度地提高主要目标,同时满足基于阈值的约束二级标准。我们提供了理论上的见解,我们的满意度为基础的推理对齐方法派生的次优界。我们经验验证SITAlign的性能,通过广泛的实验多个基准。例如,在PKU-SafeRLHF数据集上,主要目标是最大化帮助,同时确保无害阈值,SITAlign在GPT-4获胜率方面优于最先进的多目标解码策略22.3%,同时坚持无害阈值。
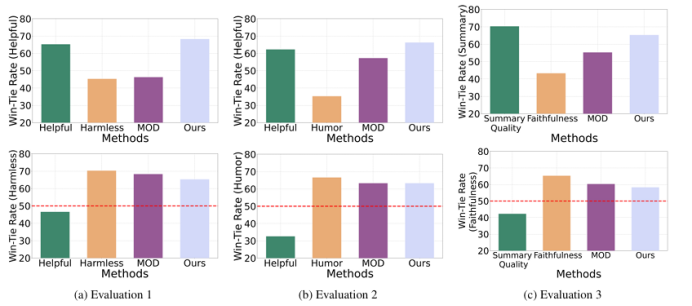
文章链接:
https://arxiv.org/pdf/2505.23729
04
Active Layer-Contrastive Decoding Reduces Hallucination in Large Language Model Generation
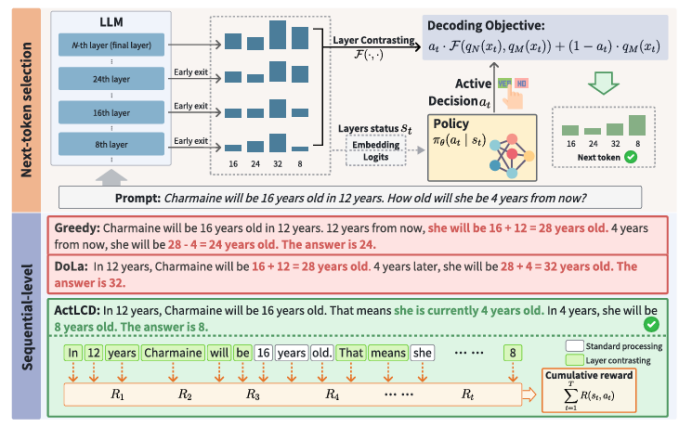
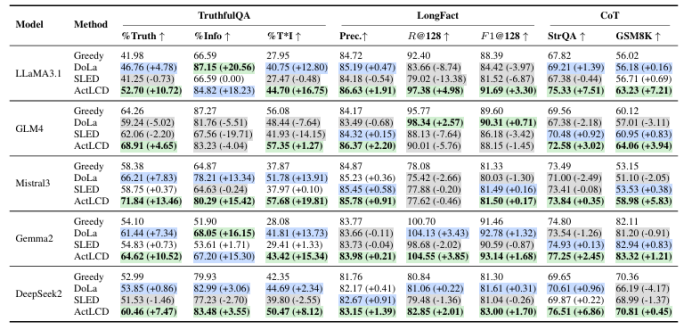
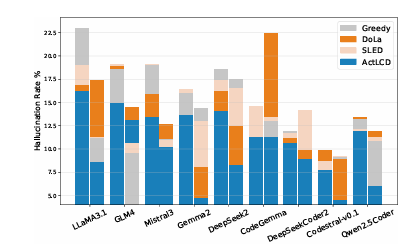
最近的解码方法通过改进在生成过程中选择下一个标记的方式,提高了大型语言模型(LLMs)的事实性。这些方法通常在标记级别操作,利用内部表示来抑制表面模式。然而,LLMs仍然容易出现幻觉,特别是在较长的上下文中。本文提出了一种新颖的解码策略——主动层对比解码(ActLCD),它主动决定在生成过程中何时应用对比层。通过将解码视为一个序贯决策问题,ActLCD采用由奖励感知分类器引导的强化学习策略,优化事实性,超越了标记级别。实验表明,ActLCD在五个基准测试中超越了最先进的方法,展示了其在多种生成场景中减少幻觉的有效性。
文章链接:
https://arxiv.org/pdf/2505.23657
05
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
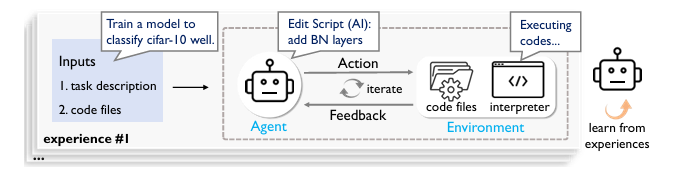
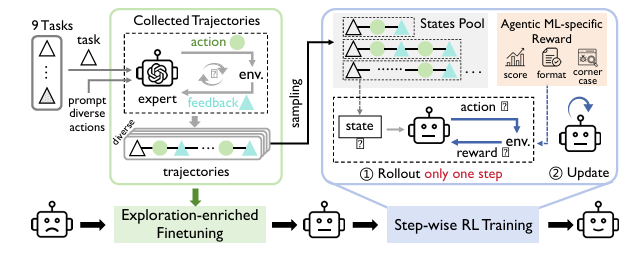
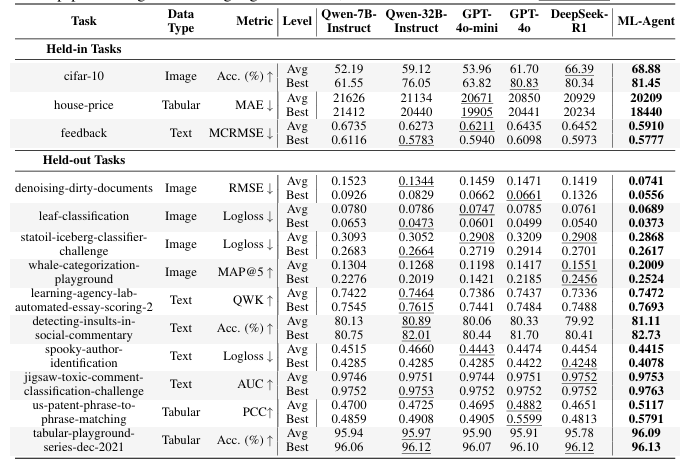
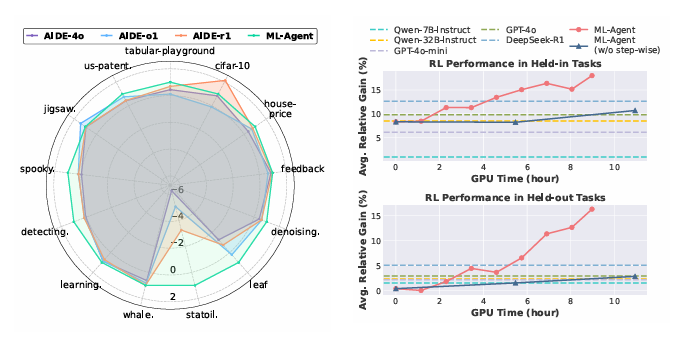
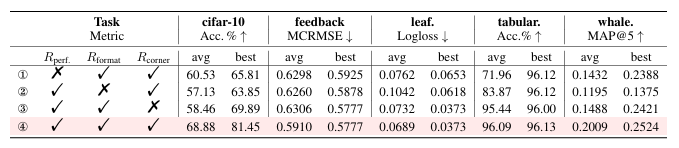
大型语言模型(LLM)基础代理的出现显著推动了自主机器学习(ML)工程的发展。然而,大多数现有方法严重依赖手动提示工程,无法根据多样化的实验经验进行适应和优化。针对这一问题,本文首次探索了基于学习的代理机器学习范式,其中LLM代理通过在线强化学习(RL)在机器学习任务上进行交互式实验以学习。为此,本文提出了一种新颖的代理机器学习训练框架,包含三个关键组件:(1)探索增强的微调,使LLM代理能够生成多样化的动作以增强RL探索;(2)逐步强化学习,使训练能够在单个动作步骤上进行,加速经验收集并提高训练效率;(3)针对代理机器学习的特定奖励模块,将多种机器学习反馈信号统一为一致的奖励以优化RL。利用该框架,我们训练了ML-Agent,这是一个由7B规模的Qwen-2.5 LLM驱动的自主ML代理。值得注意的是,尽管仅在9个机器学习任务上进行训练,但我们的7B规模的ML-Agent在性能上超越了671B规模的DeepSeek-R1代理。此外,它还实现了持续的性能改进,并展现出卓越的跨任务泛化能力。
文章链接:
https://arxiv.org/pdf/2505.23723
06
GAM-Agent: Game-Theoretic and Uncertainty-Aware Collaboration for Complex Visual Reasoning
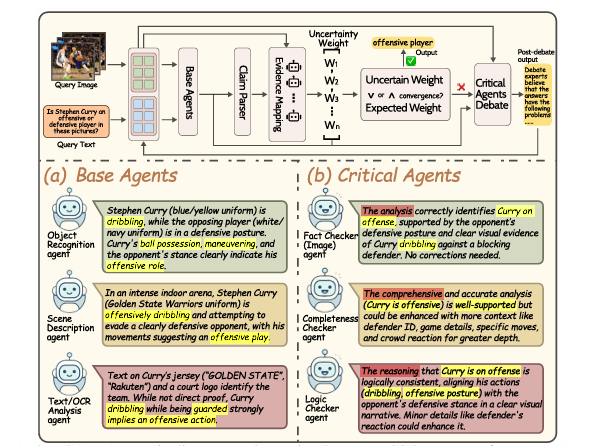
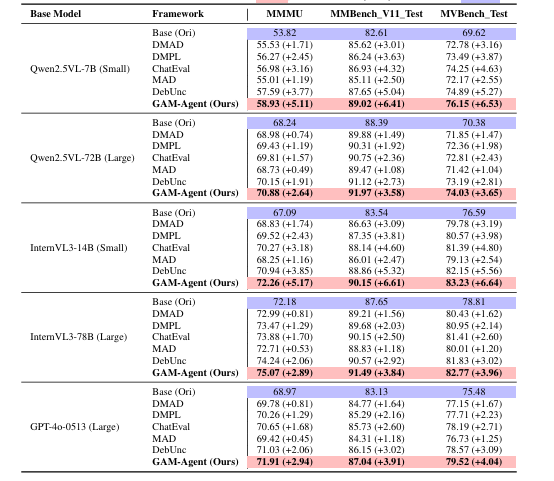
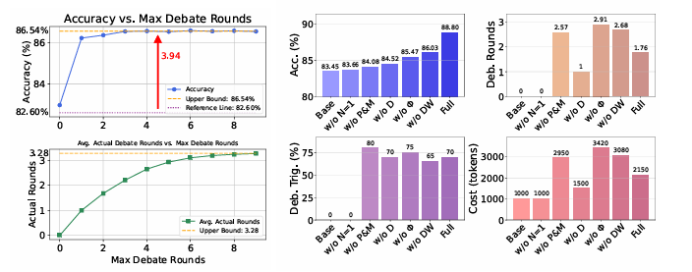
本文提出了一种名为GAM-Agent的博弈论多智能体框架,用于增强视觉语言推理能力。与以往的单智能体或单一模型方法不同,GAM-Agent将推理过程建模为基线智能体(每个智能体专注于视觉感知子任务)和关键智能体(验证逻辑一致性和事实正确性)之间的非零和博弈。智能体通过结构化的声明、证据和不确定性估计进行通信。该框架引入了一个不确定性感知控制器,用于动态调整智能体协作,在检测到分歧或模糊性时触发多轮辩论,从而得出更稳健、更具可解释性的预测结果。在MMMU、MMBench、MVBench和V*Bench四个具有挑战性的基准测试中,实验结果表明,GAM-Agent显著提升了各种视觉语言模型(VLM)骨干的性能。特别是对于中小规模模型(例如Qwen2.5-VL-7B、InternVL3-14B),其准确率提高了5% - 6%,而对于强大的模型如GPT-4o,准确率最高可提升2% - 3%。该方法具有模块化、可扩展性和通用性,为可靠且可解释的多智能体多模态推理提供了一种路径。
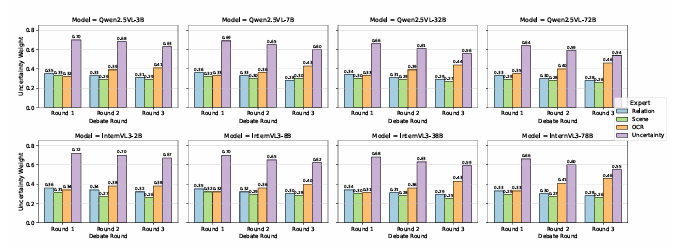
文章链接:
https://arxiv.org/pdf/2505.23399
07
From Token to Action: State Machine Reasoning to Mitigate Overthinking in Information Retrieval
链式推理(CoT)提示使大型语言模型(LLMs)能够进行复杂推理,包括在信息检索(IR)中的应用。然而,它常常导致过度思考,即模型产生过长且语义冗余的推理痕迹,几乎没有或根本没有好处。本文识别出信息检索中的两个关键挑战:重复轨迹,即反复访问类似状态;以及误导性推理,即偏离用户意图的推理。为了解决这些问题,本文提出了一种基于状态转换的推理框架——状态机推理(SMR),该框架由离散动作(REFINE、RERANK、STOP)组成,支持提前停止和细粒度控制。在BEIR和BRIGHT基准测试上的实验表明,SMR在提高检索性能(nDCG@10)方面提高了3.4%,同时减少了74.4%的令牌使用量。它可以在不需要针对特定任务进行调整的情况下,广泛应用于各种LLMs和检索器,为传统的CoT推理提供了一种实用的替代方案。
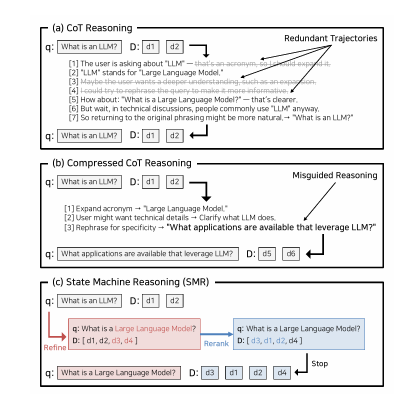
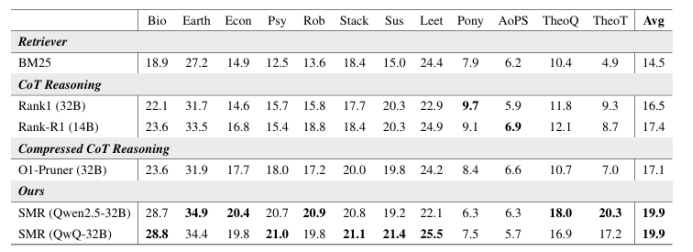
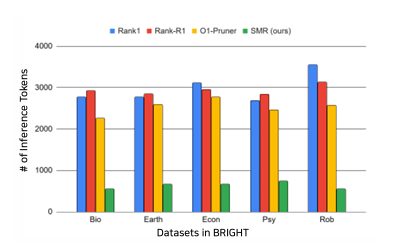
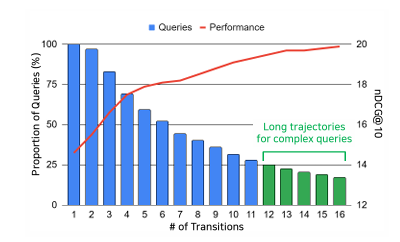
文章链接:
https://arxiv.org/pdf/2505.23059
本期文章由陈研整理
近期活动分享

ICML 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!






操作函数remap())






丨源码+详解)





)