1. 用途
1.1 存储数据
为了成功地将数据加到 Filecoin 网络, 需要成功完成以下步骤:
- 客户端导入数据生成CAR文件: 数据必须打包成 CAR file (内容可寻址档案) - CAR是IPLD规范的序列化归档文件.
- 存储交易: 存储供应商和客户之间的存储交易必须由客户发起, 并由存储供应商接受。
- 传输CAR文件: 数据必须传输给存储供应商。
- 存储供应商必须将数据放在一个扇区(Sector)中,封包并提交证明给Filecoin网络
存储时的数据表示:
要存储的文件 -> IPLD DAG -> 序列化为CAR文件(它的Payload就是IPLD DAG) -> 生成Piece(包含PayloadCID, Payload和Zero-Padding) -> 派生PieceCID(也叫CommP,是Payload+Zero-Padding的Merkle 根哈希) -> 若干个Piece 组成UnsealedSector -> CommD(Pieces的 Merkle 根) -> SealedSector(密封该扇区) -> CommRLast(sealedSector的Merkle 根) 和 CommC(lable的Merkle 根哈希) -> CommR(复制承诺) = Hash(CommC || CommRLast)
- *
PayloadCID*在 CAR’ed 和 un-CAR’ed 结构之间是通用的- CAR文件用于存储和网络传输 IPLD数据块
- 生成的 .car 文件用额外的零位填充,以便文件生成二叉 Merkle 树。要获得干净的二进制 Merkle 树,.car 文件大小必须是二的某个幂 (^2) 。一个名为 的填充过程
Fr32 padding将每 256 位中的每 254 位添加2个零位应用于输入文件。- *检索交易是根据
PayloadCID*协商的

该图显示了 Piece 及其证明树的详细组成,包括完整和带宽优化的 Piece 数据结构。
1.2 检索数据
检索市场基于PayloadCID。PayloadCID代表文件UnixFS版本的 IPLD DAG根的哈希。在此阶段,该文件是具有IPFS样式表示形式的原始系统文件。为了使客户能够在检索市场上请求一些数据,他们必须知道PayloadCID。
检索时的数据表示:
要检索的文件的PayloadCID -> 未密封文件(可能需要解封获得) -> un-CAR’ed 文件 -> 按IPLD DAG传输 -> 得到目标文件
1.3 数据传输
- JS GraphSync 是 JavaScript 中 GraphSync 协议的实现。当用户想要在 Filecoin 网络中存储数据时,在数据传输过程中使用了 GraphSync。GraphSync 允许本地节点请求远程节点以获取远程节点 IPLD 数据的结果。
- Filecoin 可以使用 GraphSync 来同步区块链并以去信任的方式传输 DAG 化的内容。对于网络参与者来说,JS GraphSync的实现可以实现网页上的点对点同步,使浏览器能够完成IPFS数据同步。
2. IPLD原理
2.1 IPLD的协议组成
- CID(Self-describing content-addressed identifiers for distributed systems):基于内容寻址的自我描述标识
- IPLD tree:基于 JSON、Protobuf和路径导航的跨协议的数据模型
- IPLD Resolvers: IPLD转换器,可以添加新的协议到IPLD里面
2.2 IPLD对象由两个部分组成
- Data — 大小 < 256 kB 的非结构化二进制数据块。
- Links — 链接结构数组。这些是指向其他 IPFS 对象的链接。每个 IPLD 链接有 3 个部分:
- Name — 链接的名称
- Hash — 链接的 IPFS 对象的哈希
- Size——链接的 IPFS 对象的累积大小,包括跟随它的链接
2.3 Merkle DAG
IPLD使用 Merkle DAG(又名有向循环图) 数据结构来链接数据块
IPLD 是一组标准和实现,用于创建可普遍寻址和链接的去中心化数据结构。这些结构允许我们为数据做 URL, 就像超链接为 HTML 网页所做的事情。
Merkle DAG 提供了一种实现重复数据删除的直接方法,通过将冗余部分编码为链接来有效地存储数据。

Merkle DAG 是许多不同项目的基本构建块:Git 等版本控制系统、以太坊等区块链、IPFS 等去中心化网络协议以及 Filecoin 等分布式存储网络都使用Merkle DAG 用于存储和通信数据!
可以解析 IPLD 数据和 CID 的系统可以引用来自其他系统的内容:例如,我们可以有一个引用 IPFS 中数据 blob 的 Filecoin 交易,或者一个引用特定 Git 提交的基于区块链的智能合约!CID 使我们能够为每条数据提供唯一的全球地址;Merkle DAG 和 IPLD 为我们提供了一种遍历和理解数据结构的方法。它们共同构成了一个由相互关联和相互理解的数据生态系统组成的全球网络的基础。
3. 支持链接类型
参考: 深入理解IPFS(2/6):什么是星际关联数据(IPLD)?
3.1 链接数据
IPLD 允许我们将所有散列链接的数据结构视为统一信息空间的子集,将所有通过散列链接数据的数据模型统一为 IPLD 的实例。这意味着可以从全局命名空间中完全不同的数据结构链接和引用数据。在 Filecoin 中被广泛使用:
- 所有系统数据结构都使用 DAG-CBOR(IPLD 编解码器)存储。
- 存储在 Filecoin 网络上的文件和数据也使用各种 IPLD 编解码器(不一定是 DAG-CBOR)存储。
因为 IPLD 是为内容寻址数据设计的,所以它还在其数据模型中包含一个“链接”原语。实际上,链接使用 CID规范。IPLD 数据被组织成“块”,其中一个块由 原始编码数据 及其 内容地址 或 CID 表示。每个内容可寻址的数据块都可以表示为一个块,这些块一起可以形成一个连贯的图或 Merkle DAG。
3.2 IPLD 选择器
IPLD 选择器还可用于寻址链接数据结构中的特定节点。
–> 3.3 已能链接的异构数据
通过 IPLD,*可以跨协议遍历链接,让您可以探索数据,而无需考虑底层协议*。
- Git
- Bitcoin
- Ethereum
- IPFS

4. 支持可验证性
可通过CID来验证一棵 Merkle DAG 树
通过 Ipld 数据结构持久化这种状态以及通过使用检查状态并可能纠正错误的初始化例程来实现的。
所有系统数据结构都使用 DAG-CBOR(IPLD 编解码器)存储。DAG-CBOR 是 CBOR 的一个更严格的子集,具有预定义的标记方案,专为哈希链接数据 DAG 的存储、检索和遍历而设计。与 CBOR 相比,DAG-CBOR 可以保证确定性。
5. 不支持错误恢复-纠删码(Erasure Code)
参考: EC纠删码原理
什么是Erasure Code ?
Erasure Code(EC),即纠删码,是一种前向错误纠正技术(Forward Error Correction,FEC,说明见后附录),主要应用在网络传输中避免包的丢失, 存储系统利用它来提高 存储 可靠性。相比多副本复制而言, 纠删码能够以更小的数据冗余度获得更高数据可靠性, 但编码方式较复杂,需要大量计算 。纠删码只能容忍数据丢失,无法容忍数据篡改,纠删码正是得名与此。
EC的定义
Erasure Code是一种编码技术,它可以将n份原始数据,增加m份数据,并能通过n+m份中的任意n份数据,还原为原始数据。即如果有任意小于等于m份的数据失效,仍然能通过剩下的数据还原出来。
EC的分类
纠删码技术在[分布式存储](http://www.chinabyte.com/keyword/分布式存储/ //t _blank) 系统中的应用主要有三类: 阵列纠删码(Array Code: RAID5、RAID6等)、RS(Reed-Solomon)里德-所罗门类纠删码和LDPC(LowDensity Parity Check Code)低密度奇偶校验纠删码。
- 磁盘阵列存储(RAID 5、RAID 6)
- 云存储(RS): 涉及到矩阵求逆,采用高斯消元法
- LDPC码目前主要用于通信、视频和音频编码等领域。与RS编码相比,LDPC编码效率要略低,但编码和解码性能要优于RS码以及其他的纠删码,主要得益于编解码采用的相对较少并且简单的异或操作。
RS Code
-
编码:给定n个数据块(Data block)D1、D2……Dn,和一个正整数m,RS根据n个数据块生成m个编码块(Code block),C1、C2……Cm。

上图最左边是编码矩阵(柯西矩阵),编码矩阵需要满足任意n * n子矩阵可逆。编码矩阵上部是单位阵(n行n列),下部是m行n列矩阵。下部矩阵可以选择范德蒙德矩阵或柯西矩阵。
-
解码:对于任意的n和m,从n个原始数据块和m个编码块中任取n块就能解码出原始数据,即RS最多容忍m个数据块或者编码块同时丢失。
-
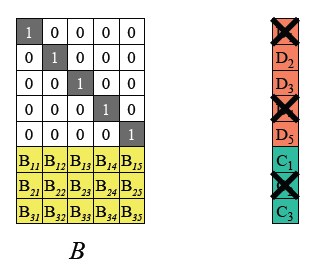
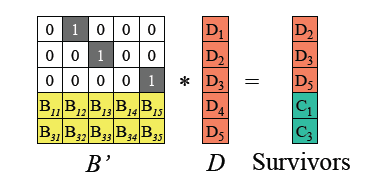
假设D1、D4、C2丢失,从编码矩阵中删掉丢失的数据块/编码块对应的行。
-
由于B’ 是可逆的,记B’的逆矩阵为 (B’^-1),则B’ * (B’^-1) = I 单位矩阵。两边左乘B’ 逆矩阵。
-
恢复原始数据D, 对D重新编码,可得到丢失的编码码
-

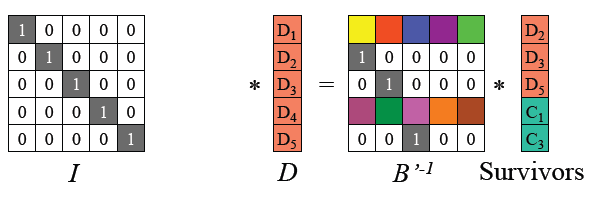

EC vs RAID
正如许多分布式存储那样,三副本的容量利利 用率始终是个问题,特别是对于海量⾮结构化数据和冷存储这些在意性价比的应用来说。相比之下,纠删码(Erasure Code)能够提供接近于本地 RAID 5/6 的有效磁盘空间,代价是牺牲了性能。纠删码在随机写⼊,特别是改写和重构(Rebuild)时产生的 I/O 惩罚较大,对应的集群网络流量比副本保护模式要大。
结论
- IPLD支持链接类型, 所以它的块数据可以是要链接的CID (即要链接的数据可以不在本地), 所以才叫内容可寻址数据结构
- IPLD已支持的异构数据: Git, Bitcoin,Ethereum,IPFS. 不确定支不支持filecoin上的sector数据
- IPLD本身不包含纠删码技术, 得自己在存储底层实现. (如采用22+2的纠删码技术,将空间利用率提升到了90%以上,相较于3副本策略,硬件成本缩减超过50%)

附录
名词解释
CID
IPFS 使用的内容标识符. CID 是一个散列摘要,其前缀是其散列函数和编解码器的标识符。这意味着您可以仅使用此标识符来验证和解码数据。
IPLD
IPLD (InterPlanetary Linked Data ), IPLD 是为内容寻址数据设计的,所以它还在其数据模型中包含一个“链接”原语。实际上,链接使用 CID规范。IPLD 数据被组织成“块”,其中一个块由原始编码数据及其内容地址或 CID 表示。每个内容可寻址的数据块都可以表示为一个块,块一起可以形成一个连贯的图,或 Merkle DAG。
-
IPFS 使用IPLD 来管理和链接所有数据块**。**
-
Filecoin 节点的 IPLD 存储是哈希链接数据的本地存储
UnixFS
建立在 IPLD Merkle-Dags 之上的文件格式
DAG-CBOR
Filecoin 系统数据结构都使用 DAG-CBOR(一种 IPLD 编解码器)存储, 具有预定义的标记方案,专为哈希链接数据 DAG 的存储、检索和遍历而设计。
Filecoin上, IPLD DAG 经 DAG-CBOR 序列化到 CAR文件
DAG-PB
IPFS中 IPLD 序列化为CAR文件的编解码器
CAR
CAR格式(Content Addressable aRchives)可用于将IPLD块数据形式的内容可寻址对象存储为字节序列;通常在具有.car文件扩展名的文件中。
Piece
Piece是用户想要存储在 Filecoin 上的数据的主要记账单位和协商单位。 Piece不是一个存储单元,它没有特定的大小,而是以Sector的大小为上限。一个 Filecoin Piece 可以是任何大小,但如果一个 Piece 大于矿工支持的 Sector 的大小,则必须将它分成更多的 Pieces,以便每个 Piece 适合一个 Sector。
每个 Filecoin Piece 是一个 CAR 文件,包含一个IPLD DAG,有对应的数据CID和piece CID。
Bitswap
IPFS 中的数据传输算法
GraphSync
Filecoin 中的数据传输算法, 使用 GraphSync 来同步区块。

数据可用性
数据可用性(Data Availability)是指发生了各种物理上的故障,系统仍然可用,数据不会丢失,一般通过RAID、副本、纠删码等技术实现。IPFS本身是不对可用性做保障的。因为添加的文件,默认只会放到本地节点。其他节点访问了相关的文件,才会在自己的机器上面存一份。但对于企业应用来说,数据一经写入,一般来说就需要有冗余,以防止各种意外情况导致数据损坏。从白皮书来看,Filecoin会使用副本或者纠删码来实现相关的功能。其他基于存储的区块链项目,也或多或少要涉及到这块才有价值。如果使用原生IPFS,那基于ipfs-cluster可以实现数据的自动冗余,但每个节点都存一份数据开销的确非常大。因此,基于IPFS提高数据可靠性方面的努力,是反映IPFS方案厂商技术实力的重要方面。
Filecoin的纠删码技术没找到
七牛云KODO存储集群

出盘率可提高到*90%*以上,同时提供多副本的容错能力。多种纠删码(EC)方案灵活部署,满足各种规模存储的建设需要。提供SDK、文件接口等对接方案,适配各种算力方案。完整的数据防误删除,数据恢复机制,保证数据安全可靠。
优化了存储性能,全面提升扇区读写效率。采用了对象存储模型,从key直接到value,无目录树查找损耗,满足千亿文件数低延迟访问。
针对时空证明PoST, 对WindowPoST利用元数据服务快速定位数据,将多个查询请求合并,单个Partition(2349个32G扇区的情况下)可在18.8秒完成读取。对WinningPoST,将读请求合并,66*9次随机读合并为一个请求,大幅降低IO消耗和证明时间。
**灵活应对存储小集群、大集群。**根据出盘率、故障容忍性与存储容量和性能需求,设计集群规模和EC模型,如6+2,8+2,15+3等,支持一定数目的机器故障,不影响数据写入与时空证明。
**扩容方案最小支持单存储节点。**推荐根据当前EC规则扩容对应的数量,同时也可以根据需求更改EC,满足提升出盘率、容错性的新需求,应对算力爆发式增长等场景。
参考
- 深入理解IPFS(2/6):什么是星际关联数据(IPLD)?
- EC纠删码原理
- 杉岩对象存储当底座,IPFS:这下稳了
- 往期精彩回顾:
- 区块链知识系列
- 密码学系列
- 零知识证明系列
- 共识系列
- 公链调研系列
- BTC系列
- 以太坊系列
- EOS系列
- Filecoin系列
- 联盟链系列
- Fabric系列
- 智能合约系列
- Token系列



 快速入门 - 用户管理(下))






)







- 性能优化)
