文章目录
- 前言
- 一、摘要与引言
- 二、Related Word
- 2.1 可解释的端到端架构
- 2.2 鸟瞰图
- 2.3 未来预测
- 2.4 规划
- 三、方法
- 3.1 感知bev特征积累
- 3.1.1 空间融合(帧的对齐)
- 3.1.2 时间融合
- 3.2 预测:双路径未来建模
- 3.3 规划:先验知识的整合与提炼
- 4. 端到端学习的Overall Loss
- 4.1 感知loss
- 4.2 预测loss
- 4.3 Planning Loss:两阶段 + 排名 + 回归
前言
题目:ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning
2022年的视觉端到端论文。
SV(Surrounding Vehicle)
ego-motion:自身运动
真的好难 :(
一、摘要与引言
提出了一种联合时空特征学习的端到端方法,明确设计网络中的中间表示,同时为感知、预测和规划任务提供一组更具代表性的特征,具体而言:
- 提出了一种以自我为中心的对齐累积技术,在鸟瞰图转换之前保留3D空间中的几何信息以进行感知。
- 双路径建模,以考虑过去的运动变化,用于未来的预测。
- 引入了一种基于时间的细化单元,用于补偿识别基于视觉的元素以进行规划。
首次对version-based端到端自动驾驶的每个部分进行拆分研究,实验证明我们最好。
基于激光雷达的[5,56,55,16]和基于视觉的[26,42,51]。
4. Lidar-based
[5] Casas, S., Sadat, A., Urtasun, R.: Mp3: A unified model to map, perceive, predict and plan. In: CVPR (2021)
[56] Zeng, W., Wang, S., Liao, R., Chen, Y., Yang, B., Urtasun, R.: Dsdnet: Deep structured self-driving network. In: ECCV (2020) 2, 3, 4, 5, 6
[55] Zeng, W., Luo, W., Suo, S., Sadat, A., Yang, B., Casas, S., Urtasun, R.: End-to-end interpretable neural motion planner. In: CVPR (2019)
[16] Casas, S., Sadat, A., Urtasun, R.: Mp3: A unified model to map, perceive, predict and plan. In: CVPR (2021)
5. version-based
[26] Hu, A., Murez, Z., Mohan, N., Dudas, S., Hawke, J., Badrinarayanan, V., Cipolla, R., Kendall, A.: Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras. In: ICCV (2021) 2, 3, 5, 6, 8, 10, 12, 13, 22
[42] Philion, J., Fidler, S.: Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: ECCV (2020) 2, 3, 5, 6, 10, 12
[51] Wang, H., Cai, P., Sun, Y., Wang, L., Liu, M.: Learning interpretable end-to-end vision-based motion planning for autonomous driving with optical flow distillation. In: ICRA (2021) 2, 3, 5, 6, 10, 12
Lidar-based method通常与HDmap决定,但是高精地图存在各种弊端。
Vision-based method的关键挑战,对应三个模块和核心创新点:
- 将特征表示从透视图转化到鸟瞰图空间。LSS method [42] 从多视图中提取透视特征,通过深度估计到3D并融合到BEV空间中。同时LSS把时间纳入框架,将过去帧的特征投影到当前的坐标视图上,这些技术由数据集提供,或光流中学习。但LSS孤立的逐帧投影特征,我们是在3D空间中对齐积累所有的特征。
[42] Philion, J., Fidler, S.: Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: ECCV (2020) 2, 3, 5, 6, 10, 12 - 在BEV空间中Equipped with代表性特征(物体位置、速度),我们将预测任务 formulate as 对未来时刻的每个物体实例进行分割,像FIERY [26] 一样。
但提高未来预测的准确性,需要考虑过去的运动变化 [24],这在FIERY[26]中缺失了。
[24] Hu, A., Cotter, F., Mohan, N., Gurau, C., Kendall, A.: Probabilistic future prediction for video scene understanding. In: ECCV (2020) 5
[26] Hu, A., Murez, Z., Mohan, N., Dudas, S., Hawke, J., Badrinarayanan, V., Cipolla, R., Kendall, A.: Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras. In: ICCV (2021) 2, 3, 5, 6, 8, 10, 12, 13, 22。 - 规划模块在感知预测输出的候选轨迹(采样生成) 和 语义信息的基础上生成 自车的最优行驶轨迹(通过 学习based 或 规则based 的方法,计算每个候选轨迹的可信度),同时去除HDmap并 向网络提供高级命令,这是抄的MP5 [5] 。但是MP5视觉识别模块是现成的、预训练的,没有进行特别定制或优化。所以我们将视觉信息集成到同一网络中的轻量级 GRU 单元中(GRU:递归神经网络模型,用于处理 时序数据 和 连续性信息,它可以帮助系统 更好地理解动态变化的环境)
[5] Casas, S., Sadat, A., Urtasun, R.: Mp3: A unified model to map, perceive, predict and plan. In: CVPR (2021) 2, 3, 4, 5, 6, 9
ST-P3网络架构图:
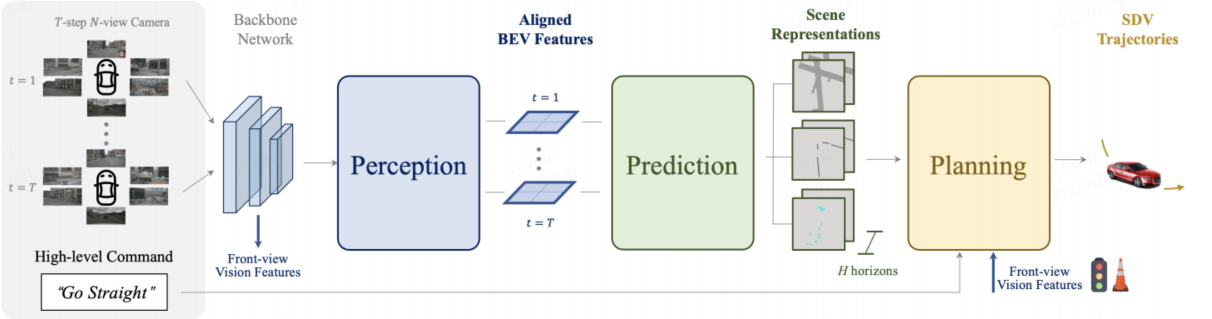
感知:自我中心对齐累积保证了特征(过去和现在)在3D空间中对齐和聚合,以在BEV变换之前保留几何信息。
预测:引入了双路径方案(现在的和过去的),以引入过去的变化来追求未来的预测。
规划:先验知识被输入到一个细化单元中,以生成最终轨迹,该轨迹具有集成的成本量和来自高级命令的采样器。
综上所述,ST-P3做出了如下贡献:
- 提出了一个新的端到端框架ST-P3,包括三个新的改进:感知自我中心对齐累积、预测双路径建模和预测模块先验知识细化。
- 系统地研究了自动驾驶任务的可解释端到端系统的每个部分,这是视觉模块化端到端的开创性文章。
- 实验无敌。
二、Related Word
2.1 可解释的端到端架构
Lidar-based较多,但vision-based较少。总的来说,基于激光雷达的方法在具有挑战性的城市场景中表现良好。不幸的是,这些工作中的数据集和基线并没有发布进行比较;而lidar-based的方法同时比较依赖HDmap,Casas等人(MP3)[5]根据分割以及其他代理的当前和未来状态构建了一个在线地图。
2.2 鸟瞰图
鸟瞰图(BEV)表示法非常适合规划和控制任务[38,57,40,12,1]。
尽管激光雷达和高清地图中的信息可以很容易地在BEV中表示,但如何将视觉输入从相机视图投影到BEV空间是一个不小的问题。
方法概述:
基于学习的投影方法通常无法保证质量,因为BEV没有真实数据来监督投影过程;
Loukkal等人[34]明确地使用图像和BEV平面之间的单应性将图像投影到BEV中;
[32,10]通过空间交叉注意力和预定义的BEV查询获取BEV特征;
LSS[42]和FIERY[26]以估计的深度和图像内参进行投影,表现出令人印象深刻的性能(你“融合”的他俩-,-);
但FIERY用的过去的特征帧,俺们用的过去所有的3D特征(Fastlio),然后是独创的自我中心对齐,积累对齐的特征。
2.3 未来预测
当前通常输入为:地面真实感知信息和HDmap。但如果这个感知输入来自其他模块,很容易产生累计误差。
而端到端输入:raw传感器数据。
受视频未来预测的启发[24],我们将概率不确定性与过去的动态相结合,以预测多样化和合理的未来场景。
2.4 规划
隐式方法:网络直接生成轨迹或控制命令,即系统输出的是最终的动作或路径。这种方法缺乏可解释性和鲁棒性。
显式方法:通常通过 轨迹采样器(sampling)生成多个候选轨迹,然后使用代价地图(cost map)来评估每个轨迹的优劣,选择最低成本的轨迹。显式方法可以精细调整候选轨迹,但相对来说也更复杂。
代价地图可以基于分割和HDmap等中间表示,用手工制作的规则[48,5,16]构建;或者可以直接从网络中学习[55]。
DSDNet [56] 结合了手工制作和基于学习的成本,以获得综合成本量。我们采用这种组合来选择最佳轨迹。
[56] Zeng, W., Wang, S., Liao, R., Chen, Y., Yang, B., Urtasun, R.: Dsdnet: Deep structured self-driving network. In: ECCV (2020) 2, 3, 4, 5, 6
然而,我们通过添加一个带有导航信号的额外GRU细化单元来修改管道,以进一步调整和优化所选轨迹。
三、方法
3.1 感知bev特征积累
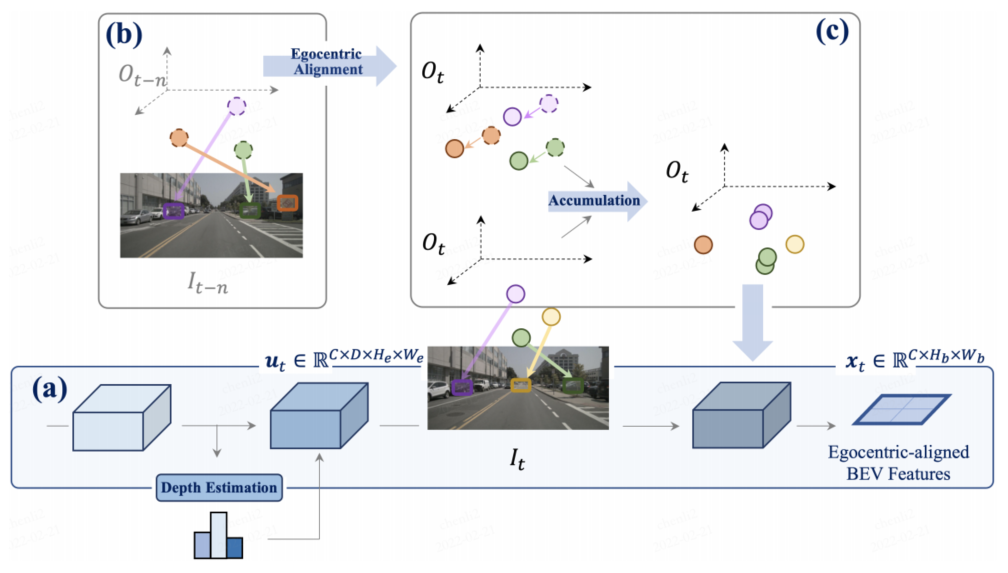
以自我为中心的感知积累:
(a)通过深度估计将当前时间戳的特征提升到3D,并在对齐后合并为BEV特征xt;
(b-c)将先前帧中的3D特征与当前视图对齐,并与所有过去和当前状态融合,从而增强特征表示。(空间和时间的融合)
空间融合:对所有时间戳的多视图图像进行处理,并将其转换为当前以自我为中心的3D空间;
时间融合:以累积的方式增强静态元素和运动对象的特征鉴别,并采用时间模型来实现最终的融合。
3.1.1 空间融合(帧的对齐)
每个摄像头图像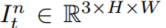 通过backbone网络获取特征
通过backbone网络获取特征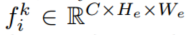 和深度信息
和深度信息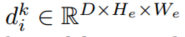 ,特征点深度信息由[42]计算,其中C是特征通道的数量,D表示离散深度的数量,(He,We)表示空间大小。
,特征点深度信息由[42]计算,其中C是特征通道的数量,D表示离散深度的数量,(He,We)表示空间大小。
由于无法获得确切的深度信息,我们将特征和深度整合到全局3D frame中,特征和深度的外积表示他们之间的关系被u联合表示。
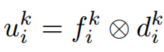
然后,使用相机内外参将相机特征frustums ui∈{u1i,…,un-i} 转换为全局3D坐标,其原点位于时间i时自我车辆的惯性中心。
另一方面,空间融合需要将过去的特征与当前帧对齐,以便进行下游预测和规划任务。
3.1.2 时间融合
目的:为了增强对静态物体的感知能力。
核心思想:多帧融合,把历史信息加权到当前帧,以强化静态特征。
实现:经典method一般直接利用具有堆叠BEV特征的3D卷积。但考虑到地面上的禁止物体(车道和禁止的车辆),各个立方体相同位置的特征应该相似,所以
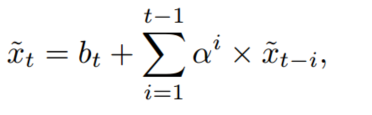
其中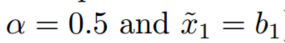
xt:t帧融合后的特征图
bt:t帧原始 BEV 特征图(未融合的当前帧)
ai:权重衰减系数,每往前一帧,权重衰减一半
融合方式:当前帧的 BEV 特征 加上 所有历史帧 BEV 特征的加权和。(第一帧直接等于它自己的特征)
为了更准确地感知动态对象,我们将这些特征输入到通过3D卷积实现的时间融合网络中。为了补偿自我车辆运动引起的偏差,我们通过在空间通道中连接运动矩阵来将其添加到特征中。
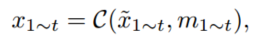
其中m1∼t表示自我运动矩阵(ego-motion matrix),C表示3D卷积网络。这个自我运动矩阵通常表示 相邻时间帧之间自车(ego-vehicle)的姿态变化。此时序融合网络(3D Conv + ego-motion)会参与端到端训练和整体优化,在预测之前,它直接影响模型的中间特征。它的输出会继续送到后续的感知、预测、规划任务模块。有梯度回传,训练时权重会被更新。
思考:为什么不直接用SE(3)做补偿,而要放到网络里?一句话总结: SE(3) 只能做“死板”的几何对齐,而我们要融合的是含噪位姿、语义化高维特征和动态场景的对齐,所以交给网络完成。
传统SLAM的逻辑:
直接对稠密/稀疏点云或图像做 几何变换(warp),通过SE(3)将前后帧对齐。输入是观测,输出是状态(位姿),再拼接地图。
端到端BEV网络的逻辑:
Backbone 提取的是高维特征图(feature map),而不是稠密几何。
想把前几帧特征融合到当前帧,就要对齐这些高维特征。
这时,可以用几何位姿去 warp 特征,但 warp 后是否最佳?深度学习倾向于再学一个小网络(例如3D卷积)去做“补偿+融合”,理由:
- 特征并非严格几何空间点,可能包含语义/时间信息 → 直接warp可能信息丢失。
- 动态物体问题(warp后,其他车辆的位置不一样)。
- 有时位姿信息本身有噪声,网络可以学到鲁棒融合。
3.2 预测:双路径未来建模
在动态驾驶环境中,传统的运动预测算法[53,20,17]通常将未来的轨迹预测为确定性或多模态结果,但这无法覆盖未来的所有可能性,特别是由于 多方交互(例如驾驶行为、交通要素和道路环境)。
为了解决 未来预测的不确定性,这个方法通过 建模条件不确定性 来改进预测模型。
未来轨迹预测 的 双路径建模
历史特征(x1, …, xt):表示从时刻1到 t 的过去观测数据,用于模型的初步预测。
未来的不确定性分布:这是基于 高斯分布 的模型,包含了未来的不确定性。这个分布有 均值 和 方差,通过采样生成未来的不确定性特征。人话版:这个 μ 是 BEV 场景特征经过编码后得到的“未来可能场景的压缩表示”,它不是像素,而是一个隐藏特征向量,代表预测模块对未来的最佳猜测。
双路径建模:模型有两个路径来处理输入:
路径一:使用 历史特征(x1,…,xt)作为 GRU(门控循环单元,Gated Recurrent Unit) 的输入进行预测,x1是初始的隐状态。
路径二:使用来自未来不确定性分布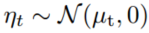 的样本和初始隐藏状态xt 作为 GRU 的输入(ii)
的样本和初始隐藏状态xt 作为 GRU 的输入(ii)
混合高斯预测:通过结合历史特征和未来不确定性的预测结果,生成未来时刻的特征。
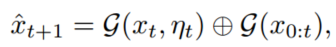
其中G表示GRU的过程。对偶建模递归预测未来的状态(xˆt+1,…,xˆt+H)。
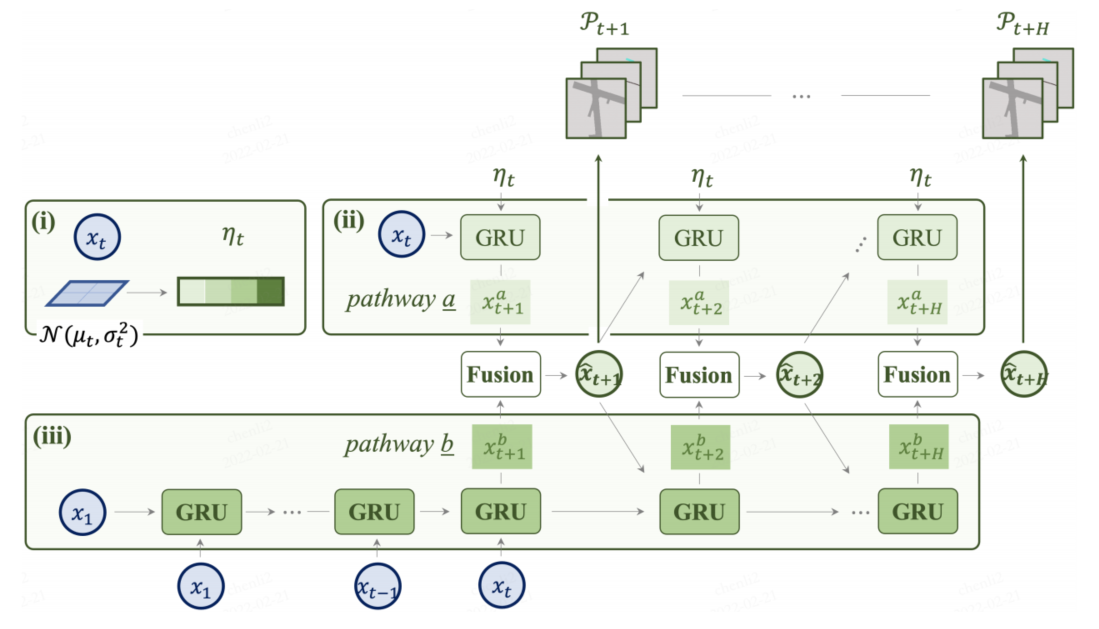
所有特征(x1,…,xt)和 未来的状态(xˆt+1,…,xˆt+H)输入到解码器D中。此解码器有多个输出头(multi-head),每个 head 对应一个特定任务,最终输出多个可解释的场景元素:
✅ 实例分割 Head
输出:Instance centerness(实例中心度)Offset(实例偏移)Future flow(未来运动流场)
作用:用于表示动态目标的位置与未来运动趋势。
✅ 语义分割 Head
输出:车辆、行人等主要参与者的语义类别。
作用:明确哪些区域由关键目标占据。
✅ HD Map 生成 Head
输出:可行驶区域(Drivable area)车道线(Lanes)
作用:提供结构化地图信息,增强规划可解释性。
✅ Cost Volume Head(代价体积)
输出:每个位置在规划时间范围内的代价(即 SDV 选择该位置的难度或风险)
作用:供规划模块评估最优轨迹。
✅ Past Frame Decoding Head(历史特征精细化)
目的:提高历史特征的准确性,增强 Dual Modelling(历史-未来双向建模)性能。
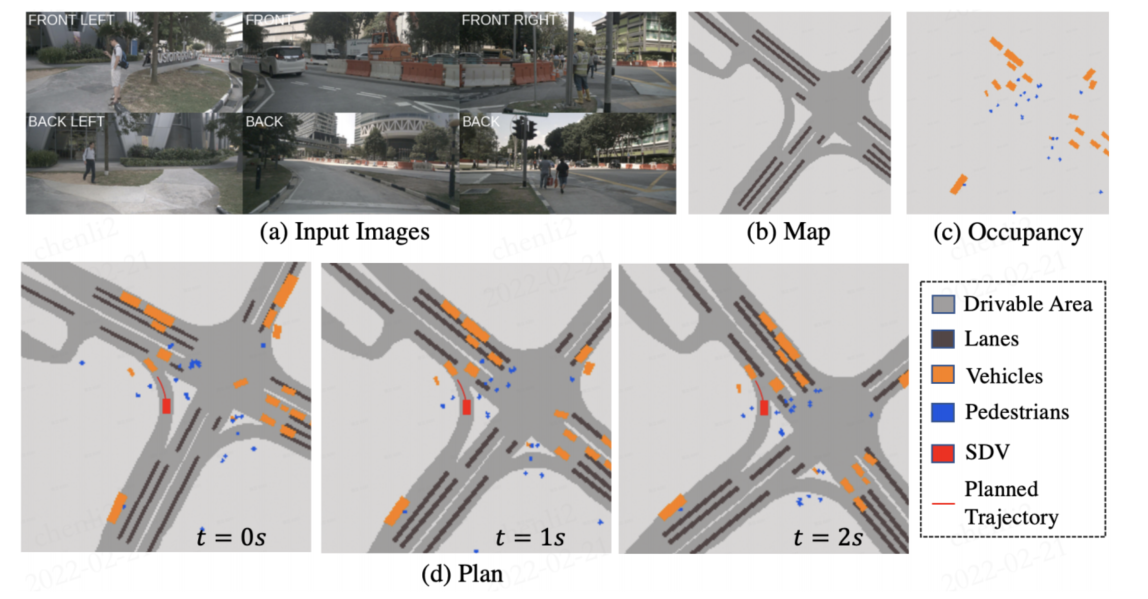
SDV成功地生成了一个安全的轨迹,可以在不与路边或前方车辆碰撞的情况下进行左转。
留一个坑:

SDMap 输入模型,用于特征融合(提升 BEV 语义)
- 该方法通过 双路径建模 来捕捉 不确定性,考虑 多模态未来预测。
- 历史特征 和 未来不确定性 共同影响最终的预测结果,使得 轨迹预测 更加鲁棒,能够处理复杂的环境交互。
- 通过 混合高斯分布 和 递归预测,能够 连续预测未来状态,而不仅仅是静态的轨迹。
- 解码器生成多个输出,有助于 可解释性,如输出未来的 车辆轨迹、障碍物位置、可驾驶区域等。
3.3 规划:先验知识的整合与提炼
设计了一个运动规划器,该规划器对一组不同的轨迹进行采样,并选择一个最小化学习成本函数的轨迹(抄的[55,48,5])
区别:通过一个额外的优化步骤与它们区分开来,该步骤使用时间模型来整合目标点和交通灯的信息
输入:
SDV 当前动态状态(位置、速度、航向)
预测模块的输出:Occupancy Probability Field(预测占用概率场)、Cost Volume(学习到的规划代价体积)。不依赖HD Map。
高层命令:Forward / Turn Left / Turn Right
相机特征(通过 GRU,用于推断交通灯状态)
f 表示轨迹代价函数(trajectory cost function),用于评估每一条候选轨迹 𝜏,并最终选择代价最小的轨迹 𝜏∗
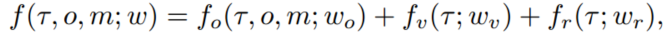
𝜏:一条候选轨迹(通过 bicycle model 采样),这些轨迹不是端到端网络直接预测的,而是根据物理模型和控制输入随机/系统采样出来的
o:预测模块输出的占用概率场(occupancy predictions)
m:地图表示(这里是预测模块输出的HD map 结构,如 drivable area 和 lanes)
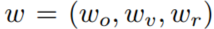 :各部分代价函数的可学习权重
:各部分代价函数的可学习权重
三个代价函数的详细介绍:
第一个部分:Rule-based / Protocol cost
检查轨迹是否与预测占用概率 o 或地图约束(车道、drivable area)冲突
逻辑:
如果轨迹穿过其他 agent 占用区域 → 高惩罚
维持一定安全距离 → 减少碰撞风险
作用:保证安全性
第二个部分:Learning-based Cost Volume
来自预测模块学习到的 Cost Volume Head
Cost Volume 表示“每个位置在未来是否适合 SDV 到达”,是学习得到的规划代价图
好处:模型自动学习复杂场景代价(例如交叉口风险),而非手写规则
第三个部分:Regularization Cost
舒适性 → 惩罚过大横向加速度、曲率、加加速度(jerk)
进度 → 奖励前进,惩罚停滞
作用:让轨迹不仅安全,还平滑、符合驾驶体验
在采样得到的一组轨迹 中,通过计算 f(),选出代价最小的轨迹:
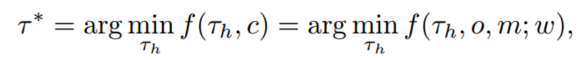
𝜏∗是最优轨迹。
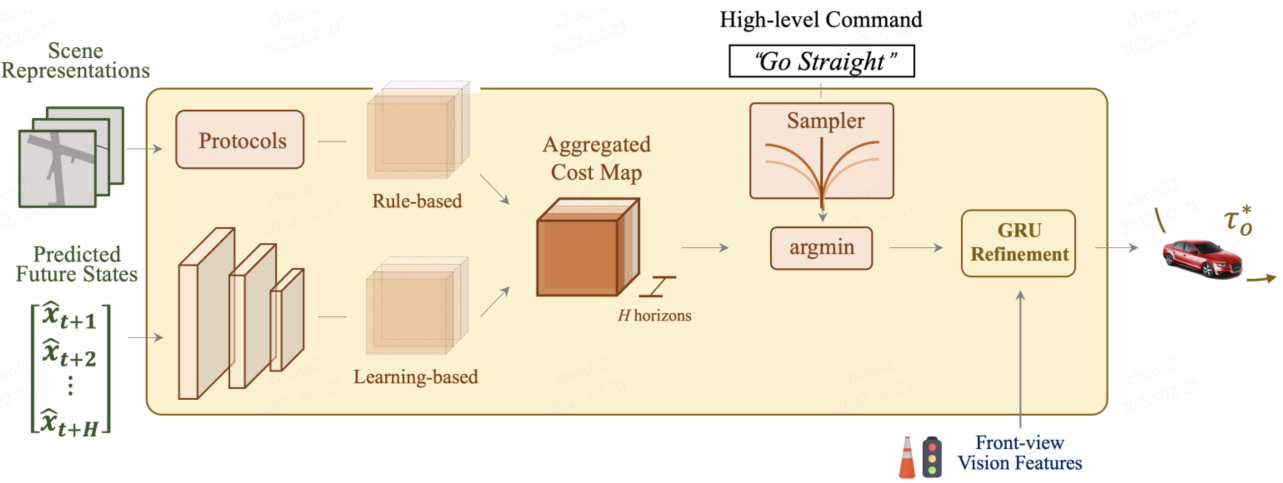 模型用 Rule-based 和 Learning-based 两种代价源,生成统一的 Cost Map,采样轨迹并选择代价最小的轨迹,再用 GRU 融合交通灯信息优化,输出最终轨迹。
模型用 Rule-based 和 Learning-based 两种代价源,生成统一的 Cost Map,采样轨迹并选择代价最小的轨迹,再用 GRU 融合交通灯信息优化,输出最终轨迹。
- 预测输出 → Cost Volume(学习型代价图)
- 规划模块:
接收 Cost Volume
结合 Rule-based protocols(安全、车道约束)
加上 comfort/progress cost
聚合成 Aggregated Cost Map - 轨迹采样 + argmin 选最优
思考: Rule-based 的存在是否影响整个系统端到端的形式(暂时思考,不知道是否正确)
从“数据流”角度:
模型仍旧从传感器输入走完整管线输出控制动作,中间没有人类在线干预。因此推理链路仍是端到端。
从“训练/优化”角度:
Rule-based 部分不需要学习(或只学习权重
Learning-based Cost Volume、语义/占用预测、GRU refinement 是学习型;
最终由综合代价挑轨迹。因此这是学习与规则融合的端到端规划。
从“安全落地”角度:
纯神经网络输出轨迹很难直接上车;引入规则 = 给神经网络加保险带。很多工业界方案(Waymo/特斯拉过渡阶段论文、ChauffeurNet 风格、Learning-from-Plans 框架等)都用了类似思想:学模型 + 规则安全层。
不使用Rule-based

4. 端到端学习的Overall Loss
整体训练结构:
多帧图像/传感器输入 ─┐
│→ 编码器 & BEV特征对齐共享主干
│
├─ Perception Head (当前&历史分割/实例、车道、可行驶区、映射、辅助深度)
│
├─ Prediction Head (未来时间序列的语义/实例预测;基于共享BEV特征+时序建模)
│
└─ Planning Head
· 轨迹采样 τ (基于动力学模型/栅格候选)
· 上下文评分 f(τ, c) (c 来自感知+预测生成的上下文/Cost map 等)
· 选最优 τ*(训练时用排名/hinge损避免不可导 argmin)
· GRU 精修 → 输出 τ*_o
我们通过利用以下损失函数,以端到端的方式通过感知、预测和规划来优化我们的模型:
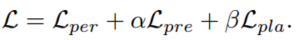
其中权重α、β是可学习的(非手调),以根据相应任务损失的梯度来平衡不同任务中的规模。
4.1 感知loss
监督目标来自数据集中已标注或可预处理得到的 BEV 语义、实例、车道、可行驶区、深度等:
语义分割(当前 & 过去帧):Top-k Cross-Entropy
BEV 中背景像素极多,直接 CE 会被背景主导;Top-k 只对损失最高的前 k% 像素反向传播,使前景学习更有效。
实例分割(中心 / offset / flow)
中心度 supervision:L2 损失。
offset & flow:L1 损失(更鲁棒于异常大误差)。
车道 & Drivable 区域:Cross-Entropy。
映射(mapping):通常也是栅格分类/回归任务(视论文定义,可归入上面几类或独立项)。
辅助深度损失:
许多现有工作只通过下游规划间接学深度(弱监督,且依赖最终损失设计,解释性差)。这里作者先用 外部网络预估深度(可视为 pseudo GT),然后对本模型深度分支直接监督,使 BEV 几何一致性更可控。
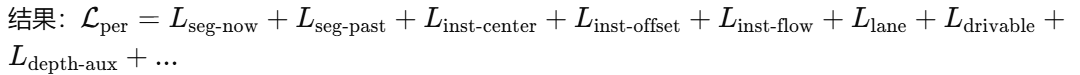
4.2 预测loss
预测模块要输出 未来多时刻 的语义 & 实例结果(同上面 Perception 类型的表示,但沿时间轴往前看)。
同样使用 Top-k Cross-Entropy(语义类)与相应实例分支损失形式,保持任务一致性。
时间折扣(exponential discount):越远的未来不确定性越大 → 给更远时刻的损失乘以γ (0<γ<1),或论文设定的指数衰减权重,使训练集中于近未来、又不完全忽略远期趋势。
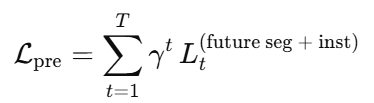
4.3 Planning Loss:两阶段 + 排名 + 回归
(a) 样本轨迹集 τ 的生成
根据车辆运动学(如自行车模型)、速度/转向采样、时间长度等,离散生成一批候选轨迹 {𝜏}。这些是 固定的“proposal”轨迹,不需要可导;后续网络通过评分区分它们。
(b) 轨迹评分与选择
用感知+预测输出融合成的上下文(cost map、静态地图、动态障碍、车道、预测占用等)记为c。规划网络学习一个评分函数f(),用来反映轨迹与上下文/安全/规则/目标之间的匹配度。
训练时不能直接对 argmin 做反传,因此引入 max-margin (hinge) 排名损:
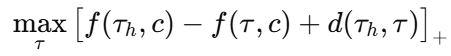
𝜏h:专家(人类驾驶)轨迹。
对每个负例轨迹 𝜏(采样集里非专家的候选),希望专家比它“好”一个 margin;margin 与两轨迹的距离d(𝜏,𝜏h)成正比(更差的候选要留更大间隔)。
[ ]+:ReLU/hinge,若专家已优于负例超过 margin,则不产生梯度;否则反向推动网络调节f()
© 精修 (Refinement)
真实部署时,模型先在候选集中找到得分最优的 𝜏∗,再送入一个 GRU-based refinement module,输出更平滑/动态可行/高分辨的最终轨迹
𝜏𝑜∗,为保证输出贴近专家轨迹,再加一个 L1 回归损:
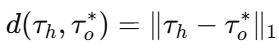
(d) 合成规划损–文章公式8
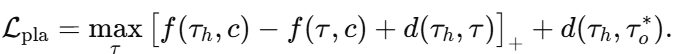

 的弊端及修复方式)

)
提取知识三元组并构建可视化知识图谱:从文本到图谱的完整实现)
基于 Go 和 gopacket+Fyne 的跨平台网络抓包工具开发实录)





)



的小样本故障诊断模型)


)
