1、Elasticsearch的JAVA客户端选择
Elasticsearch官方支持的客户端
| 客户端名称 | 简介 | 使用建议 |
|---|---|---|
| Elasticsearch Java API Client(新客户端) | 官方推荐的新客户端,基于 JSON Mapping(如 ElasticsearchClient 类),从 Elasticsearch 7.15 开始推出。 | ✅推荐用于 Spring Boot 3+,Elasticsearch 8+ |
| RestHighLevelClient(已废弃) | 基于 REST 的高级客户端,是 ES 6 ~ 7 的主力客户端,ES 8 中已标记为 deprecated。 | ❌不推荐新项目使用 |
| Low Level REST Client | 底层客户端,只提供 HTTP 封装,不解析 JSON。 | 🔧适合自定义协议或处理特殊 JSON 请求场景 |
Spring官方对Elasticsearch的封装
| 客户端名称 | 简介 | 特点 |
|---|---|---|
| Spring Data Elasticsearch | Spring 官方对 Elasticsearch 的数据访问封装,支持 Repository 风格的接口编程。 | 👍开发效率高、和 JPA 风格一致,但功能不如原生客户端全 |
easy-es(dromara团队),国人之光!
| 客户端名称 | 简介 | 特点 |
|---|---|---|
| easy-es | 风格类似 MyBatis-Plus,一致的 API 和分页查询方式,Java 开发者易于理解。 | 👍开发效率高、但是是对RestHighLevelClient的深层封装,容易受版本影响,小团队维护 |
总结:
RestHighLevelClient 是ES7中使用最多的客户端,但是在ES8中已经废弃。
easy-es 是基于RestHighLevelClient封装的,会比较重,代码风格类似 MyBatis-Plus,熟悉MP的同学容易上手,但是容易受RestHighLevelClient和Elasticsearch版本的限制,并且目前社区虽然活跃,但项目主要靠小团队维护,不如官方客户端那样稳定长期。
Elasticsearch Java API Client 是 Elasticsearch 7.15 开始推出最新的客户端,能使用Elasticsearch中所有功能,首选首选!!!!!!
Spring Data Elasticsearch 是Spring 官方对 Elasticsearch的封装,Springboot3中已经弃用了RestHighLevelClient,选择引用了Elasticsearch Java API Client,直接解决了依赖版本冲突的问题,Spring社区强大,所以...不用我说了吧....选我!!!!!
2、Spring Data Elasticsearch 官方文档
Elasticsearch Clients :: Spring Data Elasticsearch
3、Springboot3整合Spring Data Elasticsearch
tips:我使用的是Springboot3.3.4版本
3.1 maven引入
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>引入成功之后可以看到:
elasticsearch的新客户端elasticsearch-java也被引入了进来。
3.2 配置
yml配置文件
spring:application:name: cloud-elasticsearchelasticsearch:uris: http://127.0.0.1:9200 # 这里还要注意是https还是http协议
# username: elastic #如果有账号密码就要配置账号密码,否则可以不配置
# password: 123456server:port: 200004、【简单使用】Spring Data Elasticsearch
4.1 创建ES实体类
创建完实体类后,启动项目Spring会自动根据注解,来创建ES的索引(index)和映射(mapping)
@Data
@Document(indexName = "news")
@JsonIgnoreProperties(ignoreUnknown = true)
@AllArgsConstructor
@NoArgsConstructor
public class EsNews {@Idprivate String id;@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer = "ik_smart")private String title;//标题@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer = "ik_smart")private String content;//内容@Field(type = FieldType.Keyword)private String author;//作者@Field(type = FieldType.Keyword)private List<String> tags;//标签@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")@Field(type = FieldType.Date,pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd")@JsonProperty("publish_date")private Date publishDate;//发布时间@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")@Field(type = FieldType.Date,pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd")@JsonProperty("create_time")private Date createTime;//创建时间@Field(type = FieldType.Long)@JsonProperty("view_count")private Long viewCount;//阅读量}注解解析:
@Document(indexName = "news")
该实体对应的索引名称为:news
@Id
ES的唯一标识
@Field
@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer = "ik_smart")
Field(字段名) , type = FieldType.Text(字段类型为TEXT) ,analyzer = "ik_max_word"(存入时的分词器为ik_max_word),searchAnalyzer = "ik_smart"(搜索时的分词器为ik_smart)
@JsonProperty("publish_date")
ES中JSON字段,迎来进行序列化映射
tips:实际开发中业务实体类和ES实体类最好是分开的,业务实体类主要用来做数据库操作,ES实体类只用来做ES检索
4.2 继承ElasticsearchRepository接口
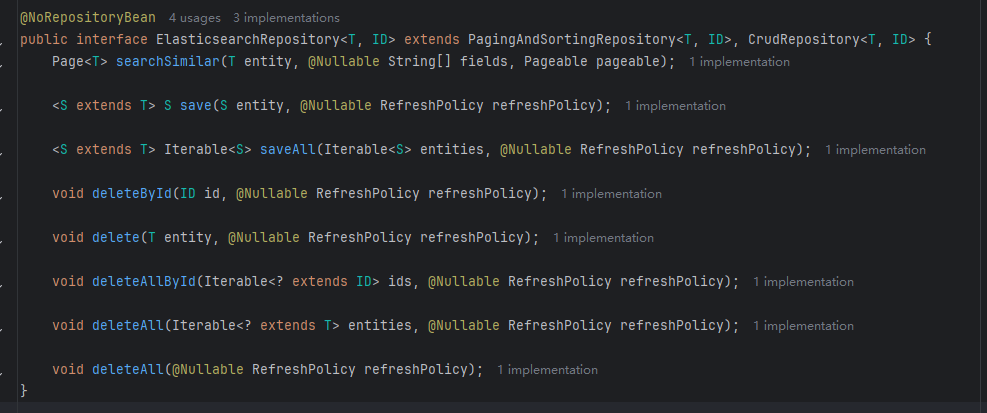
public interface EsNewsRepository extends ElasticsearchRepository<EsNews,String> {}查看ElasticsearchRepository源码可以看到
ElasticsearchRepository也继承了PagingAndSortingRepository(分页和排序接口)、CrudRepository(常用基础crud接口)
当你的类接口继承了ElasticsearchRepository后,你输入find,你会看到Spring帮你生成的所有常用简单的查询语句。
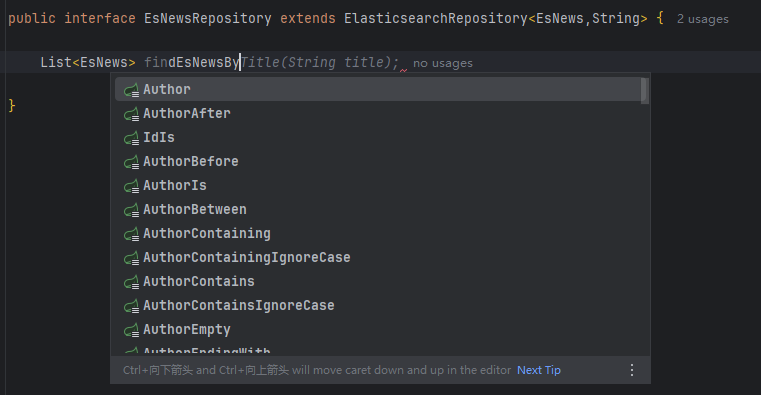
大部分关键词用法:
| 关键词 | 说明 | 等价 Elasticsearch 查询类型 |
|---|---|---|
findBy | 查询开始(必须) | - |
And / Or | 条件连接符 | bool 查询 |
Is / Equals | 等于 | term |
Between | 在两个值之间 | range |
LessThan | 小于 | range |
LessThanEqual | 小于等于 | range |
GreaterThan | 大于 | range |
GreaterThanEqual | 大于等于 | range |
After | 大于(时间) | range |
Before | 小于(时间) | range |
IsNull | 字段为 null | must_not exists |
IsNotNull / NotNull | 字段非 null | exists |
Like | 类似(不建议用,Elasticsearch 中更推荐 Containing) | match (部分分词匹配) |
NotLike | 不类似 | bool + must_not |
StartingWith | 以…开头(需要 keyword 类型字段,match 不支持) | prefix / wildcard |
EndingWith | 以…结尾(需 keyword 类型字段) | wildcard |
Containing / Contains | 包含(常用于全文检索) | match |
NotContaining | 不包含 | bool + must_not |
In | 包含在列表中 | terms |
NotIn | 不包含在列表中 | bool + must_not terms |
True / False | 布尔值判断 | term |
OrderBy | 排序 | sort |
4.3 CRUD接口使用
使用SpringBoot单元测试
4.3.1 新增
文档单个新增(save):
@Test@DisplayName("新增单个文档")void saveDoc(){EsNews news = new EsNews();news.setId("1");//如果不设置ID,Spring则会帮你生成一个ES风格的随机IDnews.setTitle("电影《不能说的秘密》热映");news.setContent("内容:不能说的秘密............牛X..");news.setAuthor("周杰伦");news.setTags(Arrays.asList("电影", "国产"));news.setPublishDate(new Date());news.setCreateTime(new Date());news.setViewCount(100L);esNewsRepository.save(news);}文档批量新增(saveAll):
@Test@DisplayName("批量新增文档")void saveBatchDoc(){List<EsNews> newsList = new ArrayList<>();for (int i = 1; i <= 11; i++) {EsNews news = new EsNews();news.setId(String.valueOf(i));news.setTitle("电影《CPW的奇幻世界 " + i + "》");news.setContent("内容 " + i);news.setAuthor("作者" + i);news.setTags(Arrays.asList("电影", "奇幻"));news.setPublishDate(new Date());news.setCreateTime(new Date());news.setViewCount(100L + i);newsList.add(news);}esNewsRepository.saveAll(newsList);}4.3.3 修改
!!!ElasticsearchRepository!!!的修改跟新增是同一个接口,如果你的对象携带ID,那么ES会先查询文档库里是有存在这么一个ID,如果存在的话则进行 先删除 然后 覆盖!!
@Test@DisplayName("新增单个文档")void saveDoc(){EsNews news = new EsNews();news.setId("1");//ES会先找文档库里是否存在改ID,先删除再覆盖news.setTitle("电影《不能说的秘密》热映");news.setContent("内容:不能说的秘密........牛X..更新覆盖操作");news.setAuthor("周杰伦");news.setTags(Arrays.asList("电影", "国产"));news.setPublishDate(new Date());news.setCreateTime(new Date());news.setViewCount(100L);esNewsRepository.save(news);}如果你想做到只修改文档中其中一条数据,比如只把作者周杰伦修改成CPW,那就需要用到第五节【高阶用法】Elasticsearch Java API Client
4.3.3 查询
需求:我要查询文档编号为999的文档
tips:简单的查询,比如根据ID查询文档,ElasticsearchRepository已经自己封装好了,不用另外写。(findById)
@Test@DisplayName("根据ID查询文档")void searchByID(){Optional<EsNews> news = esNewsRepository.findById("999");System.out.println(news);}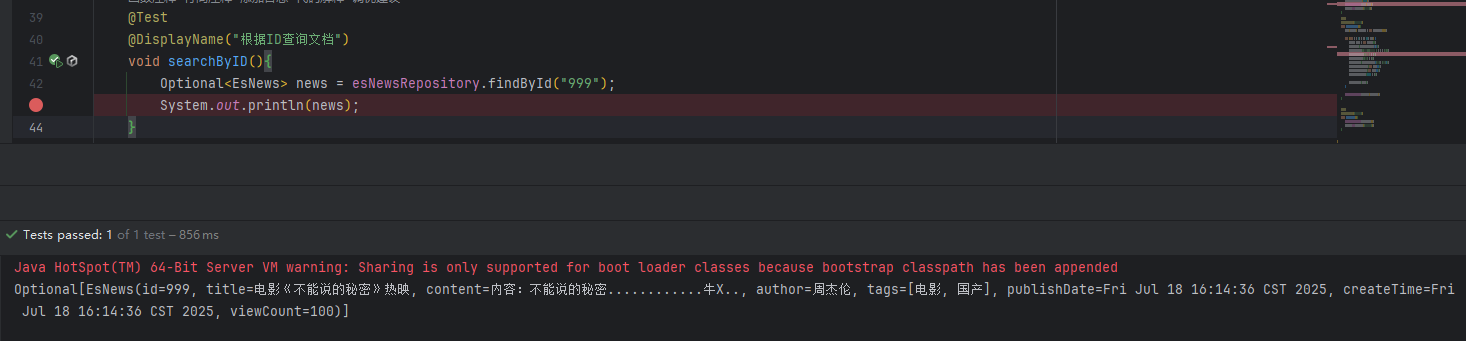
需求:我要分页查询,标题包含【奇幻世界】,作者精准是【作者1】的文档
tips:这种复杂多条件的就需要我们自己写,如果是模糊查询的则用Containing
1、EsNewsRepository新增接口findByTitleContainingOrAuthor:
public interface EsNewsRepository extends ElasticsearchRepository<EsNews,String> {Page<EsNews> findByTitleContainingOrAuthor(String Title, String Author,Pageable pageable);}2、使用
@Test@DisplayName("分页查询条件")void searchAll(){Pageable pageable = PageRequest.of(0, 10);Page<EsNews> pageList = esNewsRepository.findByTitleContainingOrAuthor("奇幻世界","作者1",pageable);for (EsNews news : pageList) {System.out.println(news);}}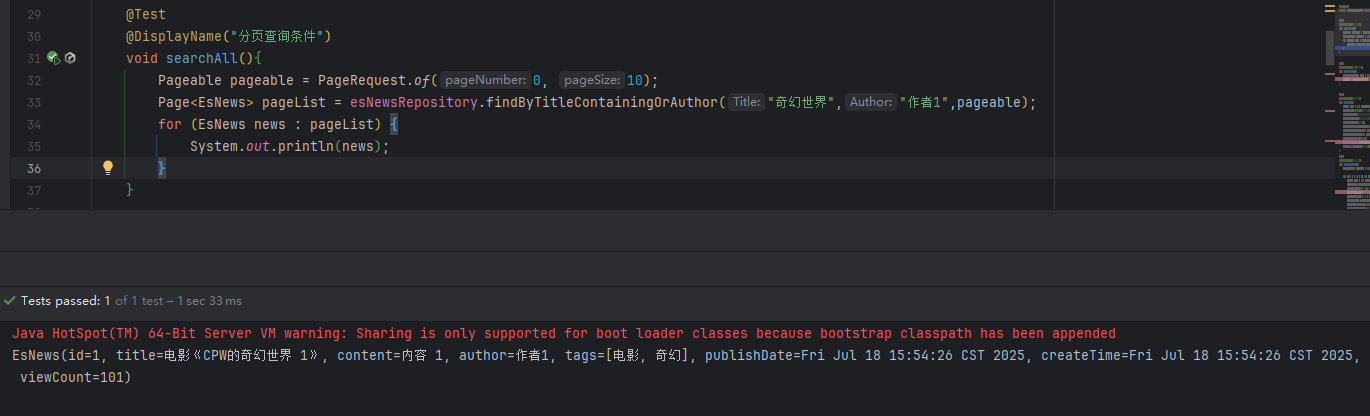
根据4.2中的关键词,还有更多的用法例如过滤、排序
4.3.4 删除
删除就没什么好说的了,直接上代码!
@Test@DisplayName("根据ID删除文档")void deleteDocById(){esNewsRepository.deleteById("1");System.out.println("ID为1的文档删除成功");}@Test@DisplayName("批量删除文档")void deleteBatchDoc(){esNewsRepository.deleteAll();System.out.println("文档批量删除成功");}@Test@DisplayName("根据ID批量删除文档")void deleteBatchDocByIds(){List<String> idList = Arrays.asList("1", "2");esNewsRepository.deleteAllById(idList);System.out.println("根据ID批量删除文档删除成功");}5、【高阶用法】Elasticsearch Java API Client
一句话:Spring Data Elasticsearch不能实现的,再用Elasticsearch Java API Client,例如只更新数据中的个别字段数据,高级查询(聚合查询),bulk函数等。。
Elasticsearch Java API Client对熟悉ES语句的同学非常友好,学会基本代码用法跟写语句一样丝滑。
不熟悉语句建议看一下ES入门教程:Elasticsearch8(ES)保姆级菜鸟入门教程-CSDN博客
建议看着文档配合服用~
5.1 ElasticsearchClient
@Autowiredprivate ElasticsearchClient elasticsearchClient;所有的ES8功能都在ElasticsearchClient中,先来看看有哪些方法:
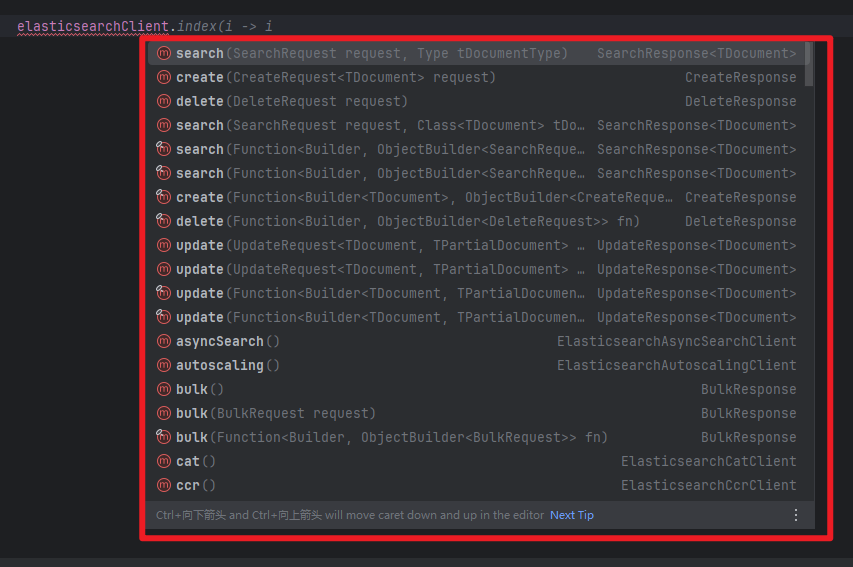
可以看出CRUD的方法和参数,分别不同:
查询的语句用的是SearchRequest
更新的语句用的是UpdateRequest
新增的语句用的是CreateRequest
删除的语句用的是DeleteRequest
批量操作语句用的是BulkRequest
5.2 更新数据个别字段
需求:更新999号文档,将作者名修改为CPW,标题修改为:CPW的《不能说的秘密》
@Test@DisplayName("更新数据的个别字段")void updateNews() throws IOException {UpdateRequest<Object, Object> updateRequest = UpdateRequest.of(u -> u.index("news").id("999").doc(Map.of("author", "CPW","title", "CPW的《不能说的秘密》")));elasticsearchClient.update(updateRequest, EsNews.class);}对比语句:
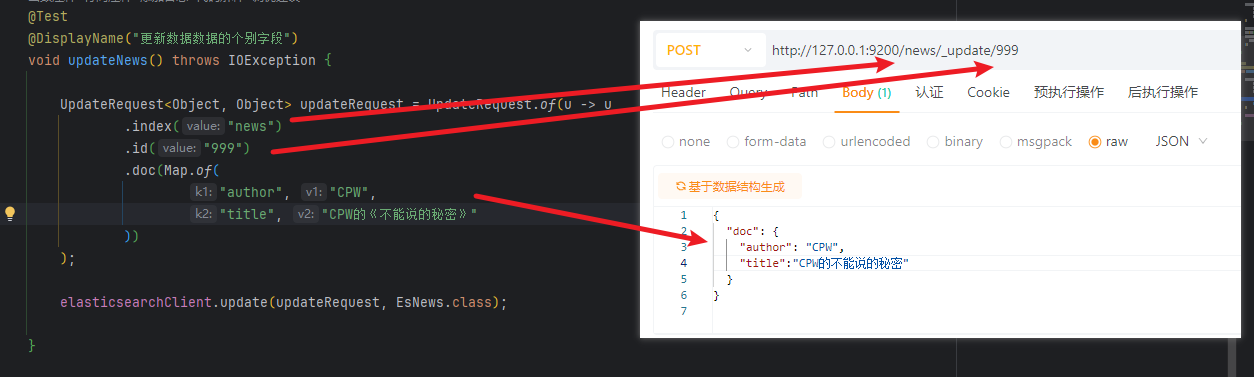
效果:

5.3 bulk(高性能批量操作)
例子:bulk的批量插入
@Test@DisplayName("bulk的批量使用")void bulkNews() throws IOException {//数据List<EsNews> newsList = new ArrayList<>();EsNews news1 = new EsNews("777", "CPW的Elasticsearch入门1", "CPW写的Elasticsearch入门教程,整合了Springboot3", "张三", Arrays.asList("教程", "入门"),new Date(), new Date(), 1000L);EsNews news2 = new EsNews("888", "CPW的Elasticsearch入门2", "CPW写的Elasticsearch入门教程,整合了Springboot3", "李四", Arrays.asList("教程", "入门"),new Date(), new Date(), 1000L);newsList.add(news1);newsList.add(news2);//构建bulkRequest请求BulkRequest.Builder builder = new BulkRequest.Builder();for (EsNews news : newsList) {builder.operations(op -> op.index(idx -> idx.index("news").id(news.getId()).document(news)));}BulkResponse bulk = elasticsearchClient.bulk(builder.build());if (bulk.errors()) {System.out.println("存在失败的操作:");bulk.items().forEach(item -> {if (item.error() != null) {System.out.println("失败项: " + item.error().reason());}});} else {System.out.println("批量新增成功,共新增: " + bulk.items().size() + " 条");}}需要使用到批量更新,删除,等操作直接修改builder.operations下的接口即可。
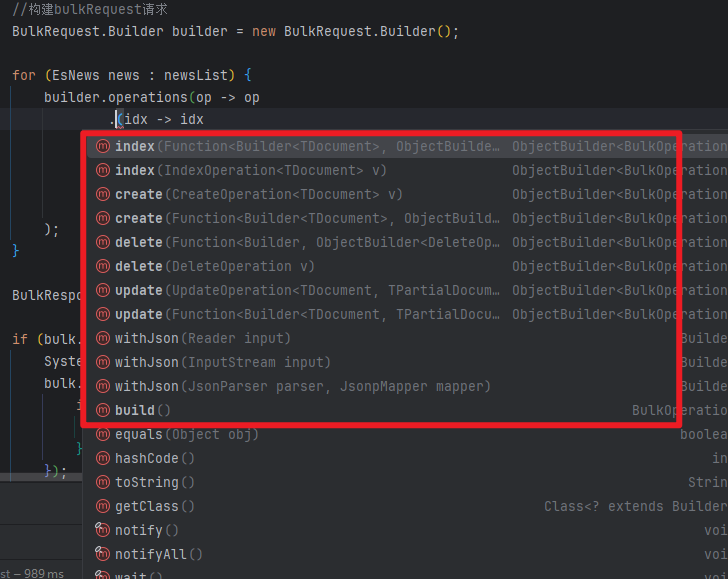
5.4 高亮查询
@Test@DisplayName("高亮查询")void highLightNews() throws IOException {SearchRequest searchRequest = SearchRequest.of(s -> s.index("news").query(q -> q.multiMatch(m -> m.query("CPW").fields("title", "content"))).highlight(h -> h.fields("title",f -> f)//f->f启动默认配置,等同于.preTags("<em>").postTags("</em>").fields("content",f -> f).preTags("<em style='color:red'>") // 自定义高亮前缀标签.postTags("</em>")));SearchResponse<EsNews> search = elasticsearchClient.search(searchRequest, EsNews.class);List<Hit<EsNews>> hits = search.hits().hits();hits.forEach(hit->{if(hit.highlight().containsKey("title") && hit.source() != null){hit.source().setTitle(hit.highlight().get("title").get((0)));}if(hit.highlight().containsKey("content") && hit.source() != null){hit.source().setContent(hit.highlight().get("content").get((0)));}System.out.println(hit.source());});}ES语句对比:
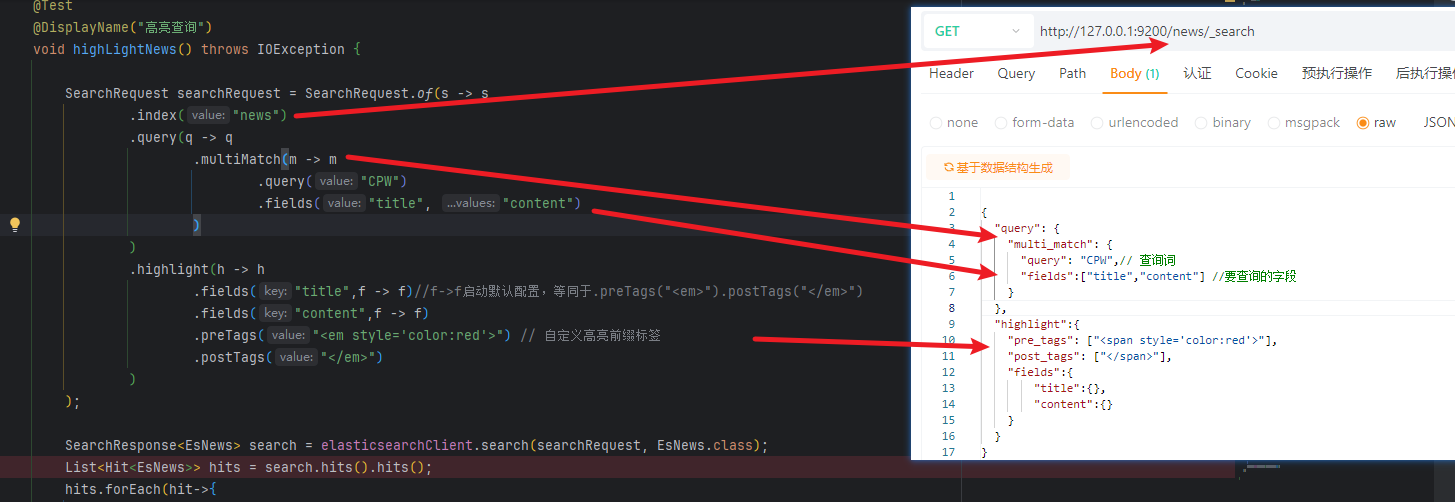
返回结果:

5.5 聚合查询
需求:查询每个作者,各自写了多少篇新闻。
@Test@DisplayName("聚合查询")void BucketingNews() throws IOException {SearchRequest searchRequest = SearchRequest.of(s -> s.index("news").size(0).aggregations("author_count",a -> a.terms(t -> t.field("author"))));SearchResponse<EsNews> search = elasticsearchClient.search(searchRequest, EsNews.class);List<StringTermsBucket> CountList = search.aggregations().get("author_count").sterms().buckets().array();System.out.println(CountList);}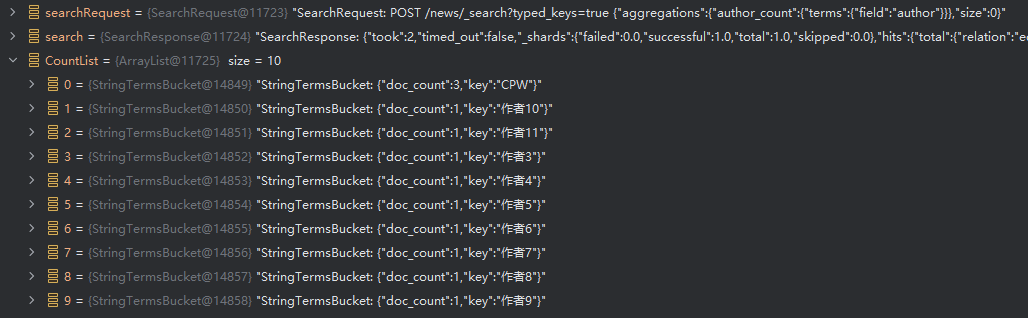
6、【最佳实践】Elasticsearch+消息队列(RabbitMQ)+数据库(MYSQL)
实际应用



















