前言
博主因为这个数据集踩了好多坑,浪费了好几天时间,最近终于找到了高效的办法,写此篇文章来记录具体操作方法,也希望可以帮助到有需要的人。(主要是在云服务器是使用)
下载数据集
一共下载三个文件,力求高效,也不要纠结在官网下载了(官网需要学校邮箱),下载的文件和官网一样的。
在Linux上直接用命令行进行下载:
1.训练集(ILSVRC2012_img_train.tar):【费时3h+】
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_train.tar --no-check-certificate
2.验证集(ILSVRC2012_img_val.tar):【费时40min+】
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar --no-check-certificate
3.标签映射文件(ILSVRC2012_devkit_t12.tar.gz):【费时几秒】
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_devkit_t12.tar.gz --no-check-certificate
下载好后是这样的

解压数据集
1.在当前目录下执行命令,解压ILSVRC2012_devkit_t12.tar.gz这个文件:
tar -xzf ILSVRC2012_devkit_t12.tar.gz
会得到文件夹ILSVRC2012_devkit_t12,该文件中记录着验证集中的图像名及其类别标签之间的映射关系。
2.在当前目录下创建val文件夹,使用命令解压。执行命令,将验证集图像解压到 val 目录下:
tar xvf ILSVRC2012_img_val.tar -C ./val
此时 val 目录下是50000张图像,并没有被分类到1000个文件夹下。因此需要将验证集中的图像进行分类存放。【稍后会讲怎么操作】
3.在当前目录下创建img文件夹,存ILSVRC2012_img_train.tar解压后的1000个.tar文件。执行命令,将训练集解压到文件夹 img目录下:
tar xvf ILSVRC2012_img_train.tar -C ./img
用脚本检查是不是有1000个.tar文件,执行脚本代码如下【将代码保存为.py文件】(可选)
import osdef count_tar_files():count = 0for root, dirs, files in os.walk('.'):for file in files:if file.endswith('.tar'):count += 1return countif __name__ == "__main__":tar_file_count = count_tar_files()print(f"当前目录及其子目录下共有 {tar_file_count} 个.tar 文件。")在当前目录下创建train文件夹,存1000个.tar文件解压后的图片。
执行脚本代码如下【将代码保存为.py文件】
import os
import tarfile
from pathlib import Pathdef batch_extract_tar():"""批量解压目录下的所有.tar文件解压后的文件将保存到知道目录中"""# 指定绝对路径【换成你自己的】source_dir = "/root/lanyun-tmp/img"target_dir = "/root/lanyun-tmp/train"# 验证源目录是否存在source_path = Path(source_dir)if not source_path.exists() or not source_path.is_dir():print(f"错误: 源目录 '{source_dir}' 不存在或不是目录")return# 创建目标目录(如果不存在)target_path = Path(target_dir)target_path.mkdir(parents=True, exist_ok=True)# 统计解压的文件数量extracted_count = 0failed_count = 0# 直接遍历源目录中的所有文件for item in source_path.iterdir():if item.is_file() and item.suffix.lower() == '.tar':try:print(f"正在解压: {item}")# 获取tar文件名(不含扩展名),用于创建子目录tar_name = item.stem # 例如:n01440764.tar → n01440764target_subdir = target_path / tar_nametarget_subdir.mkdir(exist_ok=True)# 打开tar文件并解压到目标子目录with tarfile.open(item, 'r') as tar:tar.extractall(path=target_subdir)print(f"成功解压到: {target_subdir}")extracted_count += 1except Exception as e:print(f"错误: 解压文件 '{item}' 失败: {e}")failed_count += 1print(f"解压完成: 成功 {extracted_count} 个,失败 {failed_count} 个")if __name__ == "__main__":# 直接调用函数,无需解析命令行参数batch_extract_tar()
处理val文件夹
解压后的val文件夹是全部图片在一个文件夹,需要把他们按类别分开,分类后是和训练集train一样的显示格式,1000个文件夹的名字和顺序都是完全一致的。
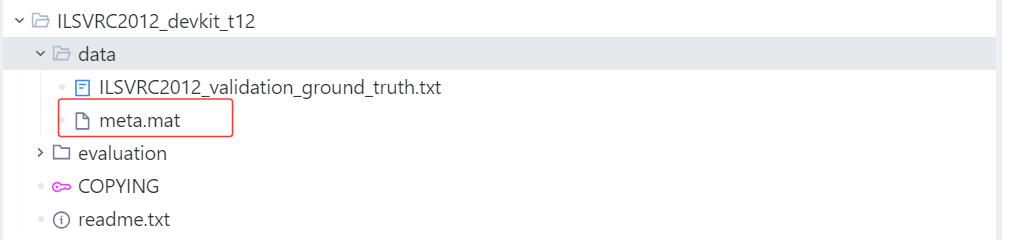
具体是需要用到文件夹ILSVRC2012_devkit_t12下的文件
先执行命令安装scipy包
pip install scipy # 用于解析 .mat 文件
执行脚本代码如下【将代码保存为.py文件】
from scipy import io
import os
import shutildef move_valimg(val_dir='./val', devkit_dir='./ILSVRC2012_devkit_t12'):"""move valimg to correspongding folders.val_id(start from 1) -> ILSVRC_ID(start from 1) -> WINDorganize like:/val/n01440764images/n01443537images....."""# load synset, val ground truth and val images listsynset = io.loadmat(os.path.join(devkit_dir, 'data', 'meta.mat'))ground_truth = open(os.path.join(devkit_dir, 'data', 'ILSVRC2012_validation_ground_truth.txt'))lines = ground_truth.readlines()labels = [int(line[:-1]) for line in lines]root, _, filenames = next(os.walk(val_dir))for filename in filenames:# val image name -> ILSVRC ID -> WINDval_id = int(filename.split('.')[0].split('_')[-1])ILSVRC_ID = labels[val_id-1]WIND = synset['synsets'][ILSVRC_ID-1][0][1][0]print("val_id:%d, ILSVRC_ID:%d, WIND:%s" % (val_id, ILSVRC_ID, WIND))# move val imagesoutput_dir = os.path.join(root, WIND)if os.path.isdir(output_dir):passelse:os.mkdir(output_dir)shutil.move(os.path.join(root, filename), os.path.join(output_dir, filename))if __name__ == '__main__':move_valimg()
到此,恭喜你已经完成了全部工作。
尾声
一些碎碎念念。博主一开始在官网下载不了数据集,在咸🐟上花几块钱买了百度网盘资源,先把资源下载在本地之后又通过FileZilla来把资源上传到云服务器上【因为网络传输的不稳定,FileZilla还经常传输失败】,花了好几天终于完成了数据集的下载与上传工作,结果处理val验证集成功之后发现他的1000个文件夹与train的1000个文件夹名有一些对不上【具体来说就是train文件夹中有两个文件夹是完全重复的一个是XXX.tar文件另外一个是XXX(1).tar文件,然后val中的最后一个文件,train中没有。】,博主的心情五味杂陈,这证明train文件有错,博主前面的工作都白费了那些资源根本用不了,咸鱼上的ImageNet的网盘资源大家还是不要随便相信了。

![Nacos中feign.FeignException$BadGateway: [502 Bad Gateway]](http://pic.xiahunao.cn/Nacos中feign.FeignException$BadGateway: [502 Bad Gateway])



 ---驱动与内核交互)
)


 函数在 Java、JavaScript 和 Python 区别)


)
![[每日随题15] 前缀和 - 拓扑排序 - 树状数组](http://pic.xiahunao.cn/[每日随题15] 前缀和 - 拓扑排序 - 树状数组)


 如何迁移数据库到新服务器?)


