MelGAN
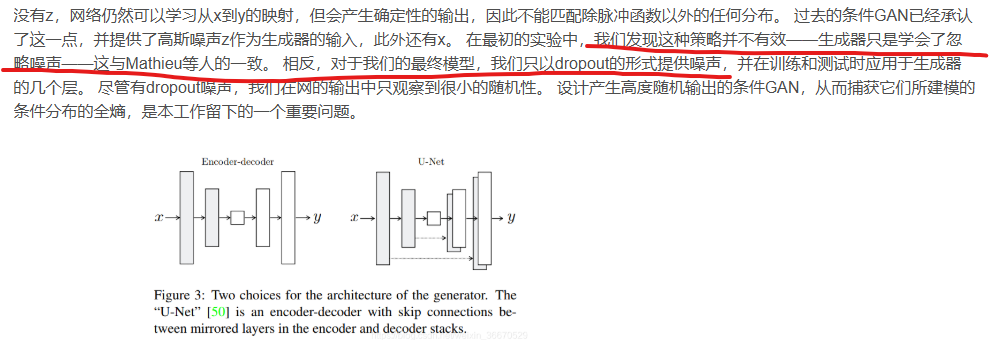
论文MelGAN针对的是从mel谱生成语音,里面说当条件很强的时候,随机噪声就没啥用了,因此没将noise注入到生成器中;

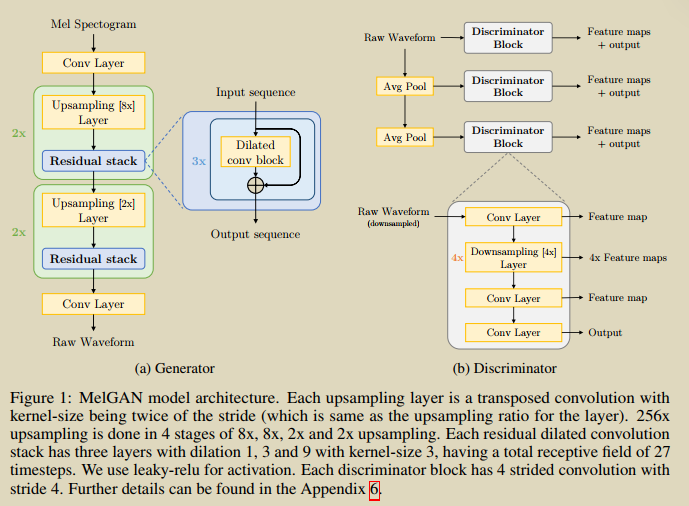
运用的判别器也仅有1个输入,不是cGAN的形式
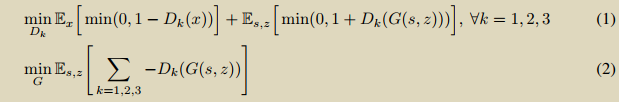
image-to-image translation with conditional adversarial networks
主要针对图片到图片的转换任务,例如:给定轮廓,利用NN补充细节。也说随机噪声作用不大。文中仅以dropout的形式实现随机噪声,但本文也称自己为GAN。

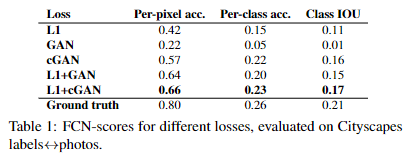
仅使用L1会得到模糊结果(文中其他地方说用L2会更模糊),仅使用GAN会得到清晰但是有artifact的结果,联合使用L1+GAN效果最好;


L1loss和L2loss在图像问题上会导致模糊现象,但是这两个loss都捕捉到了低频信息。


采用GAN的目的是仅对高频进行建模,L1用来最低频做建模

如下结果表明:相较于GAN,cgan还是有优势的。cgan和gan的区别就是是否将原始特征输入x中;

Day10)


——联合体)
![[python][flask]Flask-Login 使用详解](http://pic.xiahunao.cn/[python][flask]Flask-Login 使用详解)


)

)




)



