“基于森林的分类与回归”,它可以帮助分析师有效地设计、测试和部署预测模型。
基于森林的分类与回归应用了 Leo Breiman 的随机森林算法,这是一种用于分类和预测的流行监督机器学习方法。该工具允许分析师轻松整合表格属性、基于距离的要素和解释栅格来构建预测模型,并扩展预测模型,使其可供所有 GIS 用户使用。
为了展示基于森林的分类与回归模型的潜力,我们解决了数据科学界的一个热门问题:预测房屋售价。让我们来看一个基础练习,构建一个融入空间因素的模型,以帮助改进加州房屋售价的预测。
预测加州房价
我们将首先使用 Kaggle 上流行的加州住房数据集,其中包含加州的各个地区以及每个地区房屋的一系列聚合属性。
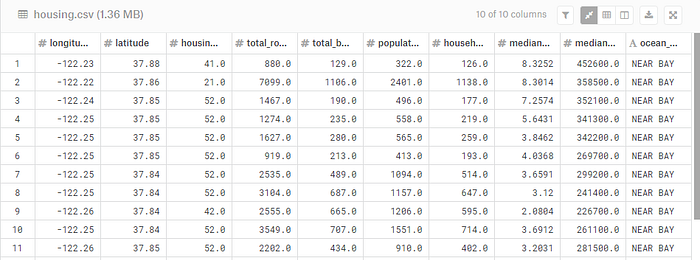
仅通过查看上表很难做出任何有意义的事情,因此让我们绘制每个区域的地图,并用每个地点的平均房屋销售价值来表示:
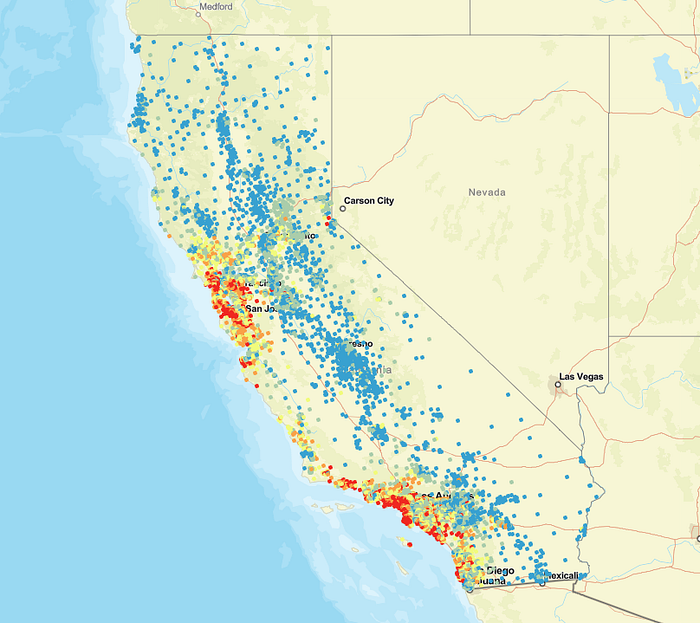
加州各地区房屋销售价值
在这张地图中,每个点都代表加利福尼亚州某个区域的质心。颜色范围代表该区域内所有房屋的平均售价。蓝色代表低售价,黄色代表中等售价,红色代表最高售价。
仅从这张地图来看,您是否注意到了任何一般模式?
您可能会注意到,价格较高的房屋通常位于最大的都市区附近。您还可能会注意到,价格较高的房屋通常位于海岸线附近。ArcGIS Pro 中的快速探索性图表可帮助我们探索这些模式:
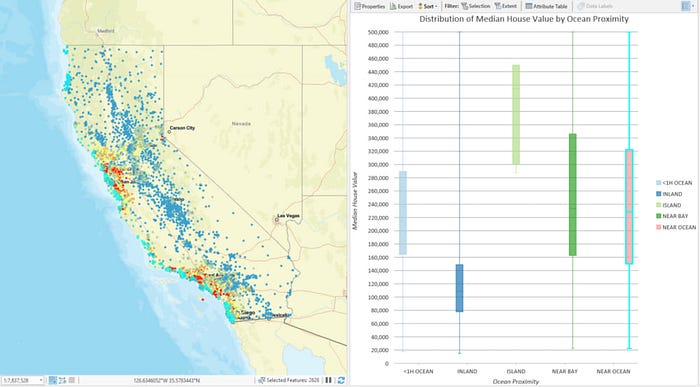
房屋中位价按距离海洋的分布
让我们查看所提供表格中的其余数据。每条记录包含该区域内所有房屋的一些基本数据点:
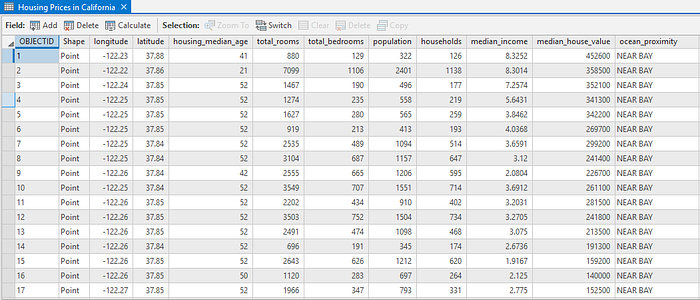
每个区域的房屋中位价是我们要预测的变量,这些属性对于帮助估计每个价值可能很重要。
我们将首先参考 Aurélien Geron 在其著作《使用 Scikit-Learn 和 TensorFlow 进行机器学习》中提供的示例,该书主要使用非空间因素(即上表中所示的属性)构建了一个随机森林模型。我们将此模型与第二个模型进行比较,在该模型中,我们开始引入其他 GIS 图层,以评估每个区域与感兴趣地点的距离如何帮助该模型在估算房屋中位价时有所改进。
非空间模型
我们的第一个模型将遵循使用 Scikit-Learn 和 TensorFlow 进行机器学习的示例,对每个道记录使用以下特征:
- 中位数收入
- 住房平均年龄
- 客房总数
- 卧室总数
- 人口
- 家庭
- 靠近海洋
让我们打开基于森林的分类和回归工具并开始吧:
第一个参数指定要执行的运行类型。对于此基础探索,我们希望评估模型诊断(即预测性能),并在引入和测试因子组合时监测变化。因此,我们将此参数保留为“仅训练”。
我们将指定输入训练特征,使用“median_house_value”属性传递加利福尼亚州各区域的 GIS 图层作为预测变量,然后在“解释训练变量”参数部分中,通过选择输入数据中相应的列来指定模型将使用哪些属性。完成后,您的地理处理工具输入应如下所示:
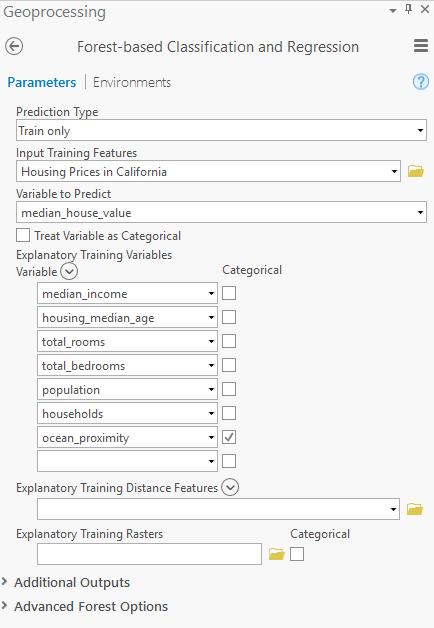
执行模型后,该工具会构建一个森林,用于建立解释变量与指定要预测的变量之间的关系。有关此工具工作原理的更多信息,请务必阅读此内容。
一旦工具完成运行,您应该收到有关模型性能的详细诊断:
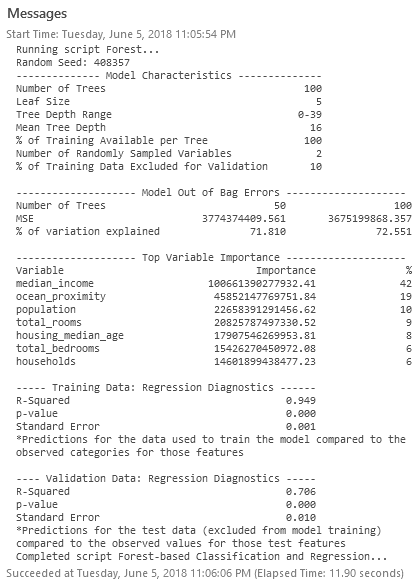
对主要变量重要性的评估可以大致了解哪些因素对模型有帮助(中位数收入和海洋距离非常重要)。现在,让我们记下 R 平方值:0.706(实际执行时可能会略有不同)。
请注意:要创建一个每次运行都不会发生变化的模型,可以在随机数生成器环境设置中设置种子。模型中仍然会存在随机性,但该随机性在每次运行之间保持一致。
空间模型
既然我们已经尝试了主要使用非空间因素的房屋销售价值估算方法,那么让我们来探索一下,随着引入基于距离的训练特征,模型会发生怎样的变化。目标是计算每个地块与一系列与房价相关的潜在重要特征之间的距离。为了进行简单的探索性练习,我们引入了高尔夫球场、学校、医院、休闲区和墓地等点要素类。我们还将引入加州海岸线的折线要素类。
为了计算所有这些距离,您可以构思一个脚本来迭代每个记录并运行一些邻近函数来确定每个几何记录之间的距离……或者您可以简单地打开基于森林的分类和回归工具并将每个要素类拖放到解释训练距离要素参数中:

加载完每个距离要素后,我们就可以运行该工具了。此时我们的参数如下所示:
请随意尝试您自己的潜在解释训练因素!举个简单的例子:您能否找到一个公共交通站点位置的数据集,将其导入 ArcGIS Pro 项目,并将这些位置加载到“解释训练距离要素”参数中?这个因素会如何改变您的模型?
一旦工具运行,我们就可以评估我们的诊断并与原始模型进行比较:
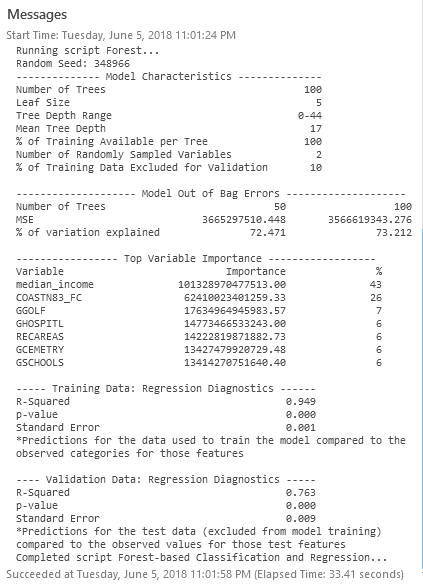
新的回归诊断结果的 R 平方为 0.763。有趣的是,一个主要考虑距离因素的基础模型的表现比主要考虑房屋非空间特征(例如浴室数量等)的原始模型略好。总而言之,这证明了“位置、位置、位置”这句格言的真实性!
该工具的运行还将提供输入数据的模型输出:
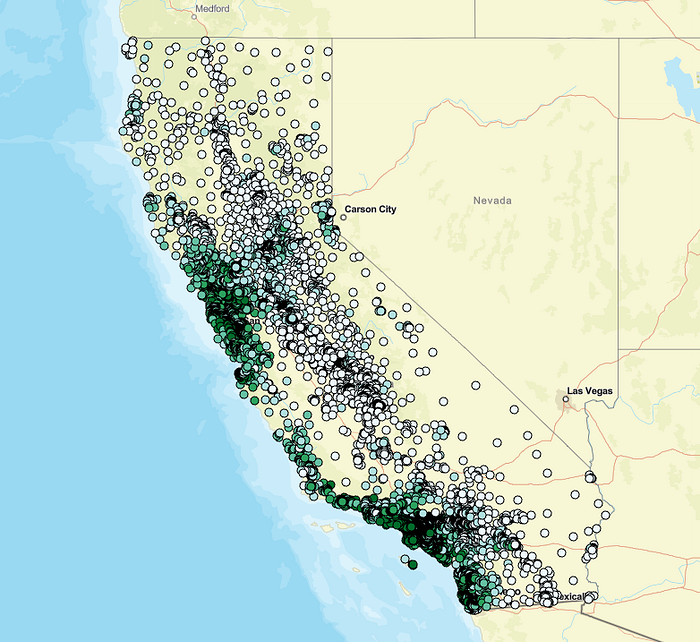
由于我们基本上是基于已知值的记录进行预测,因此这本身并没有什么用处,但它有助于了解基于距离的特征如何影响模型性能。更棒的是,能够以如此快速直观的方式将现有的额外 GIS 数据整合到模型的邻近性考量中,这非常有用。
注意:基于森林的分类与回归的另一个重要方面是,候选解释因素中的多重共线性效应不会妨碍您创建有效的模型。为了了解随机森林如何缓解多重共线性问题,我建议您进一步探索工具文档和其他随机森林文档。
结论和资源
执行分析以预测任何事件或值必然是一项探索性、迭代性、混乱且耗时的工作。为了支持这些工作流程,我们需要能够快速整合空间数据、支持测试、快速评估结果并允许重复操作直至获得满意结果的工具。
基于森林的分类和回归扩展了强大的随机森林机器学习算法的实用性,它不仅能够考虑模型中的属性数据,还能考虑基于距离的训练特征和解释栅格,以便在分析中利用位置。

网络协议封装)
)
/夏令营:让AI理解列车排期表(Task3))






)
数据结构动态链表list)






:Pandas 在机器学习中的应用)
