作者:来自 Elastic Martijn Van Groningen

探索 TSDS 和 LogsDB 的最新增强功能,包括优化 I/O、提升合并性能等。
Elasticsearch 带来了许多新功能,帮助你为你的使用场景构建最佳搜索解决方案。通过我们的示例笔记本深入学习,开始免费云试用,或立即在本地机器上试用 Elastic。
Elasticsearch 存储引擎团队专注于提升存储效率、索引吞吐量和资源利用率。我们很高兴宣布在 Elasticsearch 8.19.0 和 9.1.0 版本中, Time Series Data Streams(TSDS)和 LogsDB 索引模式获得了多项增强。这些改进源于我们致力于帮助 DevOps、SRE 和安全团队更有效、更经济地管理海量日志和指标数据。
LogsDB 和 TSDS 的最新改进自动解决了成本和规模的挑战,实现了显著的性能和效率提升:
-
通过优化恢复源数据处理,摄取期间的磁盘 I/O 降低了 50%,带来更高的索引吞吐量和更低的资源消耗。
-
提升带有数组的文档(如 IP 地址列表)的存储效率,进一步减少磁盘使用并加快索引速度。
-
doc_values 的段合并性能提升最高达 40%。段合并是一个资源密集型的后台过程,在数据摄取时持续运行。大多数字段启用了 doc_values 和倒排索引等数据结构,这降低了索引时的整体 CPU 使用率。
-
通过用更高效的跳表实现替换 BKD 树(仅在 9.1.0 版本提供),_seq_no 字段的存储减少约 50%。这导致整体存储使用减少,具体减少量取决于每个文档的字段数量;在我们的内部时间序列数据基准测试中,总存储使用减少约 10%。
在我们的内部 LogsDB 基准测试中,这些改进相比 Elasticsearch 8.17.0 版本发布时的 LogsDB,实现了约 16% 的存储减少和约 19% 的中位索引吞吐量提升。
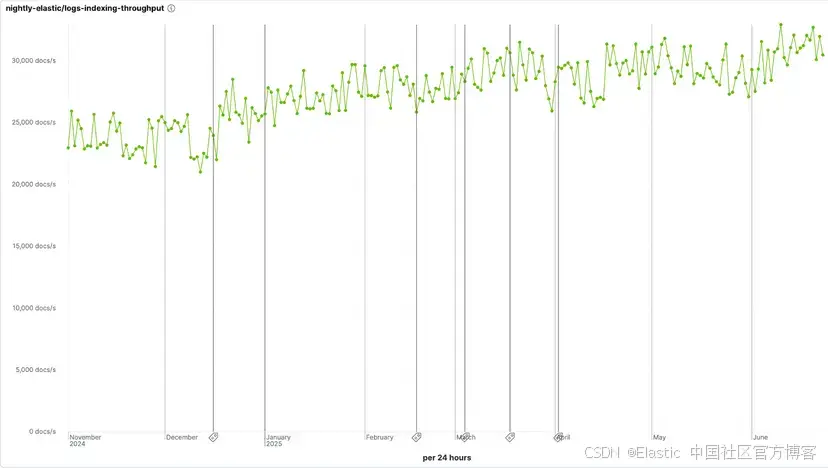
总的来说,与 8.17 版本中的标准模式相比,LogsDB 现在的存储效率提升最高达 4 倍,而索引吞吐量的损失最多仅为 10%。
| Compared to 8.17 standard | 8.19 logsdb basic | 8.19 logsdb enterprise | 9.1 logsdb basic | 9.1 logsdb enterprise |
|---|---|---|---|---|
| Median indexing throughput overhead | 11.00% | 10.02% | 11.64% | 4.94% |
| Storage (cost) improvement | 2.68x | 3.65x | 2.87x | 3.83x |
除了存储效率,我们还持续关注索引吞吐量的开销,因为我们认识到这是采用 LogsDB 的关键考量。对此,我们已将该开销(overhead)降低至 10% 以内(9.1 企业版中甚至低于 5%),使 LogsDB 能够适用于各种日志管理场景,包括高吞吐量的数据摄取。
基础:LogsDB 和 TSDS 如何优化存储
在深入了解新功能之前,让我们回顾一下 LogsDB 和 TSDS 在管理日志和指标数据方面如此强大的核心原理。这两种模式都会自动触发一系列优化,以提升存储效率,其中两个最重要的优化是 synthetic _source 和索引排序(index sorting)。
-
索引排序(Index Sorting):该功能确保文档以特定顺序存储在磁盘上。通过对数据排序(例如按 host.name 和 @timestamp 排序),相似数据被聚集在一起,使现有压缩技术更为高效,并启用专门的、依赖顺序的编解码器(如 delta of deltas 和运行长度编码)。这能进一步减少存储使用,代价是在索引过程中略微增加 CPU 消耗。
-
synthetic _source:默认情况下,Elasticsearch 在 _source 字段中存储索引时发送的原始 JSON 文档。而 synthetic _source 的做法是不存储 _source,而是从其他已索引的数据结构(如 doc values)实时重建 _source。其权衡是显著减少存储空间使用,代价是重建后的 _source 可能在细节上略有不同(例如字段顺序可能变化)。这是 LogsDB 和 TSDS 实现存储节省的核心功能之一。注意:该功能仅对 Elastic Cloud 无服务器客户和拥有 Enterprise 许可证的组织开放。
这些基础功能已经带来了极大的价值,而最新更新则在此基础上进一步提升了效率。
通过移除恢复源大幅减少磁盘 I/O
即使启用了 synthetic _source,旧版本的 Elasticsearch 仍会将原始 source 写入磁盘的一个特殊字段,用于确保副本分片可以通过主分片重放数据来恢复。然而,即使这些原始数据最终会被丢弃,临时存储它们也会带来显著的磁盘 I/O 开销。
从 8.19.0 和 9.1.0 版本开始,我们已完全移除这一步骤。Elasticsearch 不再写入这个临时恢复源,从而极大提升了索引性能。仅此一项更改,在我们的 TSDS 基准测试中,将写入时的磁盘 I/O 降低了约 50%。
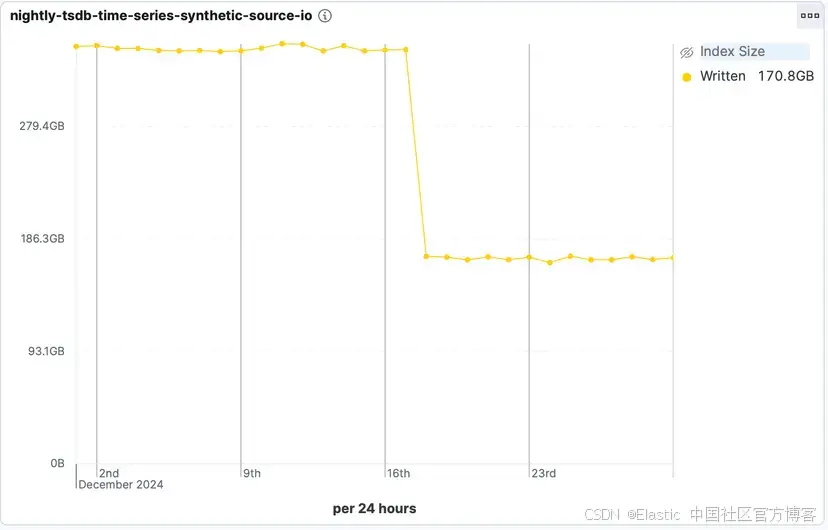
这种磁盘 I/O 的大幅减少直接带来了 16% 的中位索引吞吐量提升,让你能够更快地摄取更多数据。
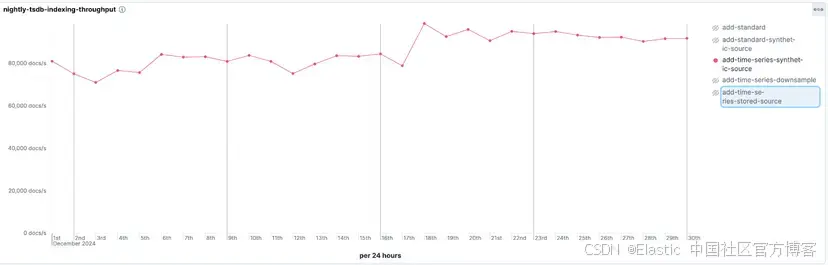
加速段合并以降低 CPU 开销
Lucene 的 doc values 在 Elasticsearch 中作为列式存储使用,支撑了排序、聚合和过滤等多种功能(当没有倒排索引或 BKD 树时)。启用索引排序后,将数据刷新到磁盘以及段合并的开销会增加,因为所有数据结构(包括倒排索引、doc values 和存储字段,例如 source)都需要按照排序配置进行排序。
我们对这个过程进行了重大优化。此前,每个字段在合并时需多次遍历文档(最多四次),每次遍历都执行一次合并排序,这是一项 CPU 密集型操作。
从 8.19.0 和 9.1.0 版本开始,我们将这个流程优化为每个字段只需一次遍历即可完成合并。这一更改使 doc values 的段合并速度提升最多达 40%。结果是索引过程中的整体 CPU 占用显著下降,特别适合高摄取场景,在这些场景下系统需要持续合并段。
更智能的数组处理,实现更高的存储效率
此前,synthetic _source 无法重建数组中值的顺序,因此必须将整个数组存储在一个名为 _ignored_source 的单独字段中。这意味着对于包含数组的字段(如安全标签列表或 IP 地址列表),数据被存储了两次:一次在 doc_values 中,另一次在 _ignored_source 中。
现在,我们改进了对基本类型数组的处理方式。在 8.19.0 和 9.1.0 版本中,叶子(leaf)数组字段的顺序被保存在一个专门的 doc_values 字段中。这消除了将数据存储在 _ignored_source 中的需求,减少了存储使用,并提升了包含大量数组字段的文档的索引性能。
用跳表替代 BKD 树,实现最终的存储压缩
Elasticsearch 中的每个文档都有一个 sequence number,存储在 _seq_no 元数据字段中。该字段原本使用 BKD 树进行索引,以支持高效的范围查询,这对副本同步非常关键。例如,副本分片会请求 _seq_no 在 X 和 Y 之间的操作。然而,BKD 树构建代价高,且占用大量磁盘空间。
在 9.1.0 及更高版本中,LogsDB 和 TSDS 已将 _seq_no 字段的 BKD 树替换为 Lucene 的新 doc value skippers(基于 doc_values 的轻量跳表实现)。这一变更提升了索引性能,使 _seq_no 字段的存储减少约 50%,并在我们的时间序列数据内部基准测试中,整体存储使用进一步降低约 10%。代价是范围查询性能略有下降,这些查询用于主分片到副本分片的复制操作。
整合一切:今天就开始吧
Elasticsearch 8.19.0 和 9.1.0 的最新增强功能,为你的日志和时间序列数据带来了强大的存储节省和性能提升。通过优化 I/O、提升合并性能、更智能地处理数组以及精简元数据,我们让你比以往任何时候都更轻松、更经济地长期保留并分析关键的运维数据。
想要获得这些自动优化带来的好处,今天就升级到 Elastic 8.19.0 或 9.1.0 吧。
准备好深入了解如何优化你的数据存储了吗?
-
如果你还没有账号,注册 Elastic Cloud
-
查看 LogsDB 文档
-
深入了解 Time Series Data Streams(TSDS)
-
享受存储节省带来的收益
原文:LogsDB and TSDS performance and storage improvements in Elasticsearch 8.19.0 and 9.1.0 - Elasticsearch Labs
)


关于bosststrap.yml与@RefreshScope)
![[Qt]QString 与Sqlite3 字符串互动[汉字不乱码]](http://pic.xiahunao.cn/[Qt]QString 与Sqlite3 字符串互动[汉字不乱码])











上海AI研究院7月22日关闭事件)
)
底层实现原理详细介绍)
