论文信息
论文题目:Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion(Text-IF:利用语义文本指导退化感知和交互式图像融合)
会议:CVPR2024
摘要:图像融合的目的是将不同源图像的信息结合在一起,形成具有综合代表性的图像。现有的融合方法在处理低质量源图像的退化和对多种主客观需求的非交互性方面通常是无能的。为了解决这些问题,我们引入了一种新的方法,利用语义文本引导图像融合模型进行退化感知和交互式图像融合任务,称为TextIF。它创新性地将经典图像融合扩展到文本引导下的图像融合,并能够协调地解决融合过程中的退化和交互问题。通过文本语义编码器和语义交互融合解码器,实现了一体化的红外和可见光图像降解感知处理和交互式柔性融合结果。这样,Text-IF不仅实现了多模态图像融合,而且实现了多模态信息融合。大量的实验证明,本文提出的文本引导图像融合策略在图像融合性能和退化处理方面都比SOTA方法有明显的优势。
源码链接:https://github.com/XunpengYi/Text-IF
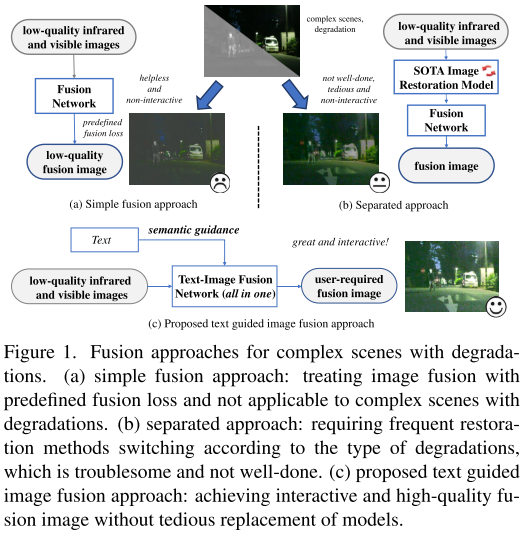
研究背景与问题
传统的图像融合方法,特别是红外和可见光图像融合,面临着两个关键挑战:
退化处理困难:当源图像存在低光照、过曝、噪声、低对比度等退化问题时,现有融合方法无法有效处理,导致融合质量低下。
缺乏交互性:现有方法只能产生相对固定的融合结果,无法根据用户的主观需求和客观应用任务进行灵活调整。
现有的解决方案通常需要先使用不同的图像修复模型处理各种退化,再进行融合,这种分离式方法不仅繁琐,还难以在增强和融合之间达到和谐统一。
核心创新点
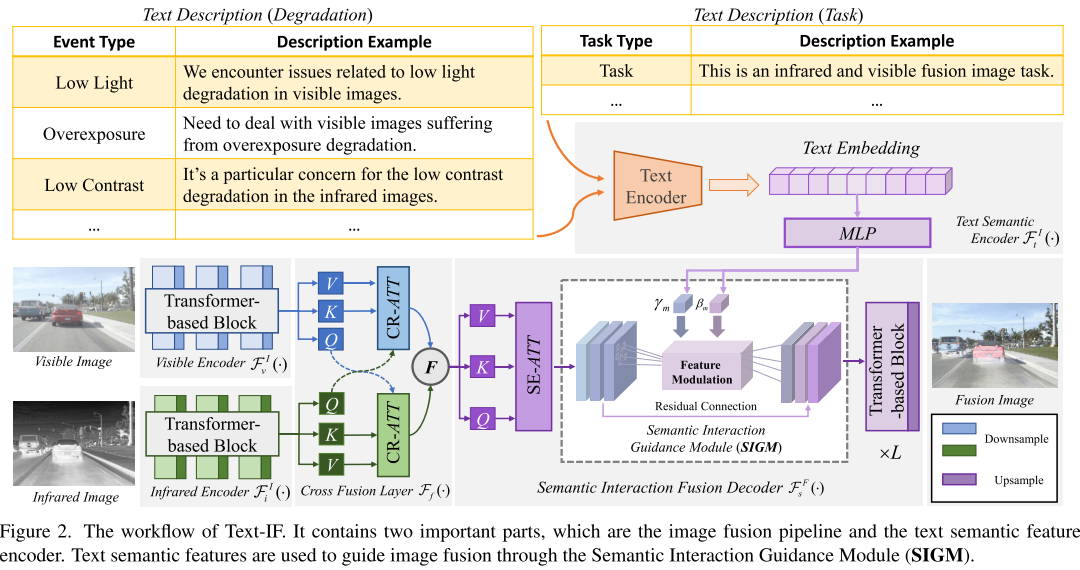
1. 首次引入文本引导的图像融合范式
Text-IF开创性地将传统的图像融合任务扩展为文本引导的图像融合,将融合公式从:
![]()
扩展为:
![]()
这种范式转变使得用户可以通过简单的文本描述来指定融合需求和处理退化类型。I表示为图像(可见与红外),θ为网络,F为函数。
2. 一体化退化感知处理
与需要针对不同退化类型切换多个修复模型的传统方法不同,Text-IF使用相同的模型参数处理所有退化场景,包括:
- 可见光图像的低光照、过曝问题
- 红外图像的噪声、低对比度问题
3. 语义交互引导模块(SIGM)
设计了专门的语义交互引导模块,通过特征调制将文本语义信息与图像融合特征耦合:
![]()
其中γ_m和β_m是从文本语义中提取的语义参数。
4. 基于Transformer的融合架构
采用Transformer/Restormer作为基础特征提取器,结合交叉融合层和语义交互融合解码器,实现高质量的多模态信息融合。
实验结果与性能表现
数据集和实验设置
- 使用MSRS、MFNet、RoadScene、LLVIP等主流数据集
- 训练集:3618个图像对,测试集:1135个图像对
- 评估指标:SCD、SD、EN、VIF、QAB/F、CLIP-IQA、NIQE、MUSIQ、BRISQUE、SF

定量性能结果
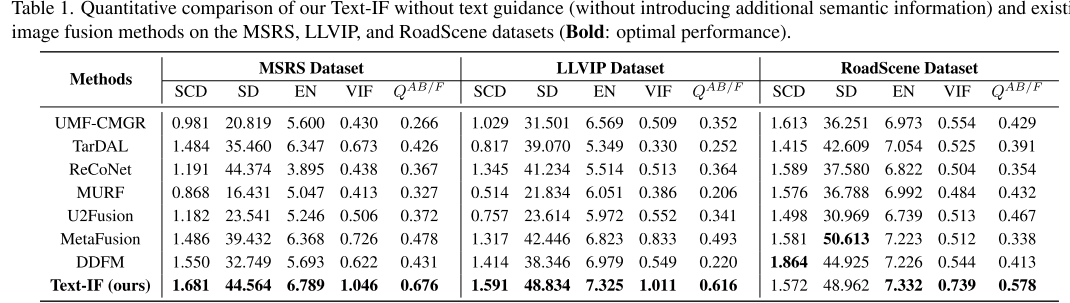
1. 无文本引导的性能比较 在MSRS数据集上,Text-IF在所有5个指标上都达到最佳性能:
- SCD: 1.681(最高)
- SD: 44.564(最高)
- EN: 6.789(最高)
- VIF: 1.046(最高)
- QAB/F: 0.676(最高)
在LLVIP数据集上同样表现优异:
- SCD: 1.591, SD: 48.834, EN: 7.325, VIF: 1.011, QAB/F: 0.616
2. 文本引导下的退化处理性能 在各种退化场景下,Text-IF都显著优于"SOTA修复方法+融合方法"的组合:
- 在MSRS低光照场景:CLIP-IQA达到0.132(最高)
- 在RoadScene过曝场景:SF指标达到17.766
- 在MFNet低对比度场景:MUSIQ达到48.625
高级任务性能验证
在LLVIP数据集上进行的目标检测实验中,使用YOLOv8作为检测backbone,Text-IF融合结果取得了最佳检测性能:
- mAP@0.50: 0.941
- mAP@0.75: 0.676
- mAP@0.50:0.95: 0.602
定性结果分析
实验结果显示Text-IF在以下三个方面表现突出:
- 热目标突出显示:融合结果中热目标的像素强度最高,目标最为突出
- 亮度和细节处理:展现更合适的亮度并提供更多细节信息
- 色彩保真度:呈现更生动自然的颜色,更符合视觉感知
消融实验结果
论文对损失函数的各个组成部分进行了消融实验:
- 强度损失:保持热辐射目标的显著性
- 颜色损失:保持色彩一致性
- 最大梯度损失:提供清晰的纹理信息
- 结构相似性损失:确保结构保真度
完整的损失函数组合取得最佳的定性和定量评估结果,验证了方法的有效性。
技术优势与意义
- 实用性强:用户只需提供简单的文本描述就能处理复杂的退化场景
- 通用性好:一个模型处理多种退化类型,避免模型切换的繁琐
- 交互性强:支持用户自定义融合需求,提供灵活的融合控制
- 性能优异:在多个数据集和评估指标上都达到了最先进的性能
结论
Text-IF成功地将文本语义引导引入图像融合领域,不仅解决了现有方法在处理退化图像时的困难,还实现了用户交互式的个性化融合。这项工作为后续的文本引导图像融合研究提供了可行的方向,在实践应用和理论研究中都具有重要的促进作用。
该方法的创新性在于将多模态信息融合从传统的图像层面扩展到了文本-图像的跨模态层面,为图像融合技术的发展开辟了新的研究路径。

)





![[学习笔记-AI基础篇]03_Transfommer与GPT架构学习](http://pic.xiahunao.cn/[学习笔记-AI基础篇]03_Transfommer与GPT架构学习)











